Приветствую уважаемое сообщество!
Повторение — мать учения, а разбираться в синтаксическом анализе — очень полезный навык для любого программиста, поэтому хочу еще раз поднять эту тему и поговорить в этот раз про анализ методом рекурсивного спуска (LL), обойдясь без лишних формализмов (к ним потом всегда можно будет вернуться).
Как пишет великий Д. Строгов, «понять — значит упростить». Поэтому, чтобы понять концепцию синтаксического разбора методом рекурсивного спуска (оно же LL-парсинг), упростим задачу насколько можно и вручную напишем синтаксический анализатор формата, похожего на JSON, но более простого (при желании можно будет потом его расширить до анализатора полноценного JSON, если захочется поупражняться). Напишем его, взяв за основу идею нарезания строки.
В классических книгах и курсах по конструированию компиляторов обычно начинают объяснять тему синтаксического разбора и интерпретации, выделяя несколько фаз:
Я сейчас хочу использовать немного другой подход к этой же самой концепции (LL-разбора) и показать, как можно построить LL-анализатор, взяв за основу идею нарезания строки: от исходной строки в процессе разбора отрезаются фрагменты, она становится меньше, а затем разбору подвергается оставшаяся часть строки. В итоге мы придем к той же самой концепции рекурсивного спуска, но немного другим путем, чем это обычно делается. Возможно, этот путь окажется удобнее для понимания сути идеи. А если и нет, то это все равно возможность посмотреть на рекурсивный спуск с другого ракурса.
Начнем с более простой задачи: есть строка с разделителями, и хочется написать итерацию по ее значениям. Что-то вроде:
Как это можно сделать? Стандартный способ — преобразовать строку с разделителями в массив или список с помощью String.split (в Java), или names.split(",") (в javascript), и сделать итерацию уже по массиву. Но представим, что преобразование в массив использовать не хотим или не можем (например, ну вдруг если мы программируем на языке программирования AVAJ++, в котором нету структуры данных “массив”). Можно еще сканировать строку и отслеживать разделители, но этот способ я использовать тоже не буду, потому что он делает код цикла итерации громоздким и, главное, это идет вразрез с концепцией, которую я хочу показать. Поэтому мы будем относиться к строке с разделителями таким же образом, как относятся к спискам в функциональном программировании. А там для них всегда определяют функции head (получить первый элемент списка) и tail (получить остаток списка). Начиная еще с первых диалектов лиспа, где эти функции назывались совершенно ужасно и неинтуитивно: car и cdr (car = content of address register, cdr = content of decrement register. Преданья старины глубокой, да, эхехех.).
Наша строка — это строка с разделителями. Подсветим разделители фиолетовым:

А элементы списка подсветим желтым:

Будем считать, что наша строка мутабельна (ее можно изменять) и напишем функцию:
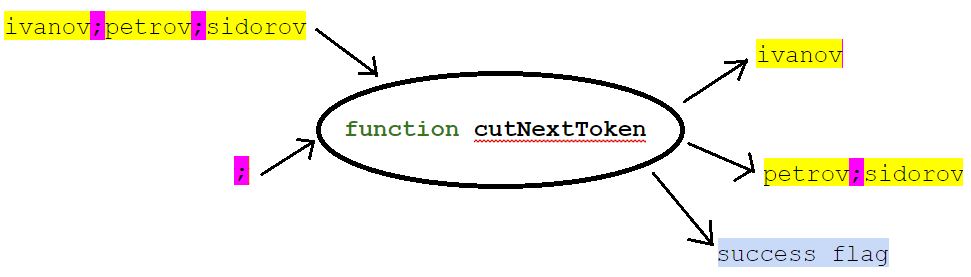
Ее сигнатура, например, может быть такой:
На вход функции даем список (в виде строки с разделителями) и, собственно, значение разделителя. На выходе функция выдает первый элемент списка (отрезок строки до первого разделителя), остаток списка и признак, удалось ли вернуть первый элемент. При этом остаток списка помещается в ту же переменную, где был исходный список.
В результате мы получили возможность написать вот так:
Выводит, как и ожидалось:
ivanov
petrov
sidorov
Мы обошлись без конвертации в ArrayList, но зато испортили переменную names, и в ней теперь пустая строка. Выглядит пока не очень полезно, как будто поменяли шило на мыло. Но давайте пойдем дальше. Там мы увидим, зачем это было надо и куда это нас приведет.
Давайте теперь разбирать что-нибудь поинтереснее: список из пар “ключ-значение”. Это тоже очень частая задача.
Вывод:
Тоже ожидаемо. И то же самое можно достичь с помощью String.split, без нарезания строк.
Но допустим, что теперь нам захотелось усложнить наш формат и от плоского key-value перейти к формату, допускающему вложенность, напоминающему JSON. Теперь мы хотим читать что-то такое:
По какому разделителю делать split? Если по запятой, то в одном из токенов у нас окажется строка
Явно не то, что нам нужно. Поэтому надо обратить внимание на структуру той строки, которую мы хотим разобрать.
Она начинается с фигурной скобки и заканчивается фигурной скобкой (парной к ней, что важно). Внутри этих скобок находится список пар 'ключ':'значение', каждая пара отделена от следующей пары запятой. Ключ и значение разделяется двоеточием. Ключ — это строка из букв, заключенная в апострофы. Значение может быть строкой символов, заключенных в апострофы, а может быть такой же структурой, начинающейся и заканчивающейся парными фигурными скобками. Назовем такую структуру словом “объект”, как и принято называть ее в JSON.
Только что мы в неформальной форме описали грамматику нашего, напоминающего JSON, формата. Обычно грамматики описываются наоборот, в формальной форме, и для их записи применяется BNF-нотация или ее вариации. Но сейчас я обойдусь без этого, и мы просто посмотрим, как можно “нарезать” эту строку, чтобы ее по правилам этой грамматики разобрать.
В самом деле, наш “объект” начинается с открывающей фигурной скобки и заканчивается парной ей закрывающей. Что может делать функция, разбирающая такой формат? Скорее всего, следующее:
Обратите внимание: появились слова “функция, разбирающая такой формат” и “функция, разбирающая список пар ‘ключ’:’значение’”. У нас появились две функции! Это те самые функции, которые в классическом описании алгоритма рекурсивного спуска называются “функции разбора нетерминальных символов”, и про которые говорится, что “для каждого нетерминального символа создается своя функция разбора”. Которая, собственно, его и разбирает. Мы могли бы их назвать, допустим, parseJsonObject и parseJsonPairList.
Также теперь нам надо обратить внимание, что у нас появилось понятие “парная скобка” в дополнение к понятию “разделитель”. Если для нарезания строки до следующего разделителя (двоеточие между ключом и значением, запятая между парами “ключ: значение”) нам было достаточно функции cutNextToken, то теперь, когда в качестве значения у нас может выступать не только строка, но и объект, нам понадобится функция “отрезать до следующей парной скобки”. Примерно такая:

Эта функция отрезает от строки фрагмент от открывающей скобки до парной ей закрывающей, учитывая вложенные скобки, если они есть. Конечно, можно не ограничиваться скобками, а использовать подобную функцию для отрезания разных блочных структур, допускающих вложенность: операторных блоков begin..end, if..endif, for..endfor и аналогичных им.
Нарисуем графически, что будет происходить со строкой. Бирюзовый цвет — это значит мы сканируем строку вперед на символ, выделенный бирюзовым, чтобы определить, что нам делать дальше. Фиолетовый — это “что отрезать, это когда мы отрезаем от строки фрагменты, выделенные фиолетовым, и то, что осталось, продолжаем разбирать дальше.

Для сравнения, вывод программы (текст программы приведен в приложении), разбирающей эту строку:
Демонстрация разбора JSON-подобной структуры
Мы в любой момент знаем, что мы ожидаем найти в нашей входной строке. Если мы вошли в функцию parseJsonObject, то мы ожидаем, что нам туда передали объект, и можем это проверить по наличию открывающей и закрывающей скобки в начале и в конце. Если мы вошли в функцию parseJsonPairList, то мы ожидаем там список пар “ключ: значение”, и после того, как мы “откусили” ключ (до разделителя “:”), мы ожидаем, что следующее, что мы “откусываем” — это значение. Мы можем посмотреть на первый символ значения, и сделать вывод о его типе (если апостроф — то значение имеет тип “строка”, если открывающая фигурная скобка — то значение имеет тип “объект”).
Таким образом, отрезая от строки фрагменты, мы можем выполнить ее синтаксический разбор методом нисходящего анализа (рекурсивного спуска). А когда мы можем выполнить синтаксический разбор, то мы можем разбирать нужный нам формат. Или придумать свой, удобный нам формат и разбирать его. Или придумать DSL (Domain Specific Language) для нашей конкретной области и сконструировать интерпретатор для него. И сконструировать правильно, без вымученных решений на регекспах или самопальных state-машинах, которые возникают у программистов, которые пытаются решить какую-нибудь задачу, требующую синтаксического разбора, но не вполне владеют материалом.
Вот. Поздравляю всех с наступившим летом и желаю добра, любви и функциональных парсеров :)
Для дальнейшего чтения:
Идеологическое: пара длинных, но стоящих прочтения статей Стива Йегге (англ.):
Rich Programmer Food
Пара цитат оттуда:
Цитата оттуда:
LL and LR Parsing Demystified
LL and LR in Context: Why Parsing Tools Are Hard
И еще глубже в тему: как написать интерпретатор Лиспа на C++
Lisp interpreter in 90 lines of C++
Повторение — мать учения, а разбираться в синтаксическом анализе — очень полезный навык для любого программиста, поэтому хочу еще раз поднять эту тему и поговорить в этот раз про анализ методом рекурсивного спуска (LL), обойдясь без лишних формализмов (к ним потом всегда можно будет вернуться).
Как пишет великий Д. Строгов, «понять — значит упростить». Поэтому, чтобы понять концепцию синтаксического разбора методом рекурсивного спуска (оно же LL-парсинг), упростим задачу насколько можно и вручную напишем синтаксический анализатор формата, похожего на JSON, но более простого (при желании можно будет потом его расширить до анализатора полноценного JSON, если захочется поупражняться). Напишем его, взяв за основу идею нарезания строки.
В классических книгах и курсах по конструированию компиляторов обычно начинают объяснять тему синтаксического разбора и интерпретации, выделяя несколько фаз:
- Лексический анализ: разбиение исходного текста на массив подстрок (лексем, или токенов)
- Синтаксический анализ: построение из массива лексем дерева синтаксического разбора
- Интерпретация (или компиляция): обход полученного дерева в нужном (прямом или обратном) порядке и выполнение каких-то действий по интерпретации или кодогенерации на некоторых шагах этого обхода
на самом деле не совсем так,
потому что в процессе разбора мы получаем уже последовательность шагов, представляющих собой последовательность посещения узлов дерева, самого же дерева в явном виде может вообще не быть, но не будем пока углубляться. Для тех, кто хочет углубиться, в конце есть ссылки.
Я сейчас хочу использовать немного другой подход к этой же самой концепции (LL-разбора) и показать, как можно построить LL-анализатор, взяв за основу идею нарезания строки: от исходной строки в процессе разбора отрезаются фрагменты, она становится меньше, а затем разбору подвергается оставшаяся часть строки. В итоге мы придем к той же самой концепции рекурсивного спуска, но немного другим путем, чем это обычно делается. Возможно, этот путь окажется удобнее для понимания сути идеи. А если и нет, то это все равно возможность посмотреть на рекурсивный спуск с другого ракурса.
Начнем с более простой задачи: есть строка с разделителями, и хочется написать итерацию по ее значениям. Что-то вроде:
String names = "ivanov;petrov;sidorov"; for (String name in names) { echo("Hello, " + name); }
Как это можно сделать? Стандартный способ — преобразовать строку с разделителями в массив или список с помощью String.split (в Java), или names.split(",") (в javascript), и сделать итерацию уже по массиву. Но представим, что преобразование в массив использовать не хотим или не можем (например, ну вдруг если мы программируем на языке программирования AVAJ++, в котором нету структуры данных “массив”). Можно еще сканировать строку и отслеживать разделители, но этот способ я использовать тоже не буду, потому что он делает код цикла итерации громоздким и, главное, это идет вразрез с концепцией, которую я хочу показать. Поэтому мы будем относиться к строке с разделителями таким же образом, как относятся к спискам в функциональном программировании. А там для них всегда определяют функции head (получить первый элемент списка) и tail (получить остаток списка). Начиная еще с первых диалектов лиспа, где эти функции назывались совершенно ужасно и неинтуитивно: car и cdr (car = content of address register, cdr = content of decrement register. Преданья старины глубокой, да, эхехех.).
Наша строка — это строка с разделителями. Подсветим разделители фиолетовым:
А элементы списка подсветим желтым:
Будем считать, что наша строка мутабельна (ее можно изменять) и напишем функцию:
Ее сигнатура, например, может быть такой:
public boolean cutNextToken(StringBuilder svList, String separator, StringBuilder token)
На вход функции даем список (в виде строки с разделителями) и, собственно, значение разделителя. На выходе функция выдает первый элемент списка (отрезок строки до первого разделителя), остаток списка и признак, удалось ли вернуть первый элемент. При этом остаток списка помещается в ту же переменную, где был исходный список.
В результате мы получили возможность написать вот так:
StringBuilder names = new StringBuilder("ivanov;petrov;sidorov"); StringBuilder name = new StringBuilder(); while(cutNextToken(names, ";", name)) { System.out.println(name); }
Выводит, как и ожидалось:
ivanov
petrov
sidorov
Мы обошлись без конвертации в ArrayList, но зато испортили переменную names, и в ней теперь пустая строка. Выглядит пока не очень полезно, как будто поменяли шило на мыло. Но давайте пойдем дальше. Там мы увидим, зачем это было надо и куда это нас приведет.
Давайте теперь разбирать что-нибудь поинтереснее: список из пар “ключ-значение”. Это тоже очень частая задача.
StringBuilder pairs = new StringBuilder("name=ivan;surname=ivanov;middlename=ivanovich"); StringBuilder pair = new StringBuilder(); while (cutNextToken(pairs, ";", pair)) { StringBuilder paramName = new StringBuilder(); StringBuilder paramValue = new StringBuilder(); cutNextToken(pair, "=", paramName); cutNextToken(pair, "=", paramValue); System.out.println("param with name \"" + paramName + "\" has value of \"" + paramValue + "\""); }
Вывод:
param with name "name" has value of "ivan" param with name "surname" has value of "ivanov" param with name "middlename" has value of "ivanovich"
Тоже ожидаемо. И то же самое можно достичь с помощью String.split, без нарезания строк.
Но допустим, что теперь нам захотелось усложнить наш формат и от плоского key-value перейти к формату, допускающему вложенность, напоминающему JSON. Теперь мы хотим читать что-то такое:
{'name':'ivan','surname':'ivanov','birthdate':{'year':'1984','month':'october','day':'06'}}
По какому разделителю делать split? Если по запятой, то в одном из токенов у нас окажется строка
'birthdate':{'year':'1984'
Явно не то, что нам нужно. Поэтому надо обратить внимание на структуру той строки, которую мы хотим разобрать.
Она начинается с фигурной скобки и заканчивается фигурной скобкой (парной к ней, что важно). Внутри этих скобок находится список пар 'ключ':'значение', каждая пара отделена от следующей пары запятой. Ключ и значение разделяется двоеточием. Ключ — это строка из букв, заключенная в апострофы. Значение может быть строкой символов, заключенных в апострофы, а может быть такой же структурой, начинающейся и заканчивающейся парными фигурными скобками. Назовем такую структуру словом “объект”, как и принято называть ее в JSON.
Только что мы в неформальной форме описали грамматику нашего, напоминающего JSON, формата. Обычно грамматики описываются наоборот, в формальной форме, и для их записи применяется BNF-нотация или ее вариации. Но сейчас я обойдусь без этого, и мы просто посмотрим, как можно “нарезать” эту строку, чтобы ее по правилам этой грамматики разобрать.
В самом деле, наш “объект” начинается с открывающей фигурной скобки и заканчивается парной ей закрывающей. Что может делать функция, разбирающая такой формат? Скорее всего, следующее:
- проверить, что переданная строка начинается с открывающей фигурной скобки
- проверить, что переданная строка заканчивается на парную закрывающую фигурную скобку
- если оба условия верны, отрезать открывающую и закрывающую скобку, и то, что осталось, передать в функцию, разбирающую список пар 'ключ':'значение'
Обратите внимание: появились слова “функция, разбирающая такой формат” и “функция, разбирающая список пар ‘ключ’:’значение’”. У нас появились две функции! Это те самые функции, которые в классическом описании алгоритма рекурсивного спуска называются “функции разбора нетерминальных символов”, и про которые говорится, что “для каждого нетерминального символа создается своя функция разбора”. Которая, собственно, его и разбирает. Мы могли бы их назвать, допустим, parseJsonObject и parseJsonPairList.
Также теперь нам надо обратить внимание, что у нас появилось понятие “парная скобка” в дополнение к понятию “разделитель”. Если для нарезания строки до следующего разделителя (двоеточие между ключом и значением, запятая между парами “ключ: значение”) нам было достаточно функции cutNextToken, то теперь, когда в качестве значения у нас может выступать не только строка, но и объект, нам понадобится функция “отрезать до следующей парной скобки”. Примерно такая:
Эта функция отрезает от строки фрагмент от открывающей скобки до парной ей закрывающей, учитывая вложенные скобки, если они есть. Конечно, можно не ограничиваться скобками, а использовать подобную функцию для отрезания разных блочных структур, допускающих вложенность: операторных блоков begin..end, if..endif, for..endfor и аналогичных им.
Нарисуем графически, что будет происходить со строкой. Бирюзовый цвет — это значит мы сканируем строку вперед на символ, выделенный бирюзовым, чтобы определить, что нам делать дальше. Фиолетовый — это “что отрезать, это когда мы отрезаем от строки фрагменты, выделенные фиолетовым, и то, что осталось, продолжаем разбирать дальше.
Для сравнения, вывод программы (текст программы приведен в приложении), разбирающей эту строку:
Демонстрация разбора JSON-подобной структуры
ok, about to parse JSON object {'name':'ivan','surname':'ivanov','birthdate':{'year':'1984','month':'october','day':'06'}} ok, about to parse pair list 'name':'ivan','surname':'ivanov','birthdate':{'year':'1984','month':'october','day':'06'} found KEY: 'name' found VALUE of type STRING:'ivan' ok, about to parse pair list 'surname':'ivanov','birthdate':{'year':'1984','month':'october','day':'06'} found KEY: 'surname' found VALUE of type STRING:'ivanov' ok, about to parse pair list 'birthdate':{'year':'1984','month':'october','day':'06'} found KEY: 'birthdate' found VALUE of type OBJECT:{'year':'1984','month':'october','day':'06'} ok, about to parse JSON object {'year':'1984','month':'october','day':'06'} ok, about to parse pair list 'year':'1984','month':'october','day':'06' found KEY: 'year' found VALUE of type STRING:'1984' ok, about to parse pair list 'month':'october','day':'06' found KEY: 'month' found VALUE of type STRING:'october' ok, about to parse pair list 'day':'06' found KEY: 'day' found VALUE of type STRING:'06'
Мы в любой момент знаем, что мы ожидаем найти в нашей входной строке. Если мы вошли в функцию parseJsonObject, то мы ожидаем, что нам туда передали объект, и можем это проверить по наличию открывающей и закрывающей скобки в начале и в конце. Если мы вошли в функцию parseJsonPairList, то мы ожидаем там список пар “ключ: значение”, и после того, как мы “откусили” ключ (до разделителя “:”), мы ожидаем, что следующее, что мы “откусываем” — это значение. Мы можем посмотреть на первый символ значения, и сделать вывод о его типе (если апостроф — то значение имеет тип “строка”, если открывающая фигурная скобка — то значение имеет тип “объект”).
Таким образом, отрезая от строки фрагменты, мы можем выполнить ее синтаксический разбор методом нисходящего анализа (рекурсивного спуска). А когда мы можем выполнить синтаксический разбор, то мы можем разбирать нужный нам формат. Или придумать свой, удобный нам формат и разбирать его. Или придумать DSL (Domain Specific Language) для нашей конкретной области и сконструировать интерпретатор для него. И сконструировать правильно, без вымученных решений на регекспах или самопальных state-машинах, которые возникают у программистов, которые пытаются решить какую-нибудь задачу, требующую синтаксического разбора, но не вполне владеют материалом.
Вот. Поздравляю всех с наступившим летом и желаю добра, любви и функциональных парсеров :)
Для дальнейшего чтения:
Идеологическое: пара длинных, но стоящих прочтения статей Стива Йегге (англ.):
Rich Programmer Food
Пара цитат оттуда:
You either learn compilers and start writing your own DSLs, or your get yourself a better language
The first big phase of the compilation pipeline is parsingThe Pinocchio Problem
Цитата оттуда:
Type casts, narrowing and widening conversions, friend functions to bypass the standard class protections, stuffing minilanguages into strings and parsing them out by hand, there are dozens of ways to bypass the type systems in Java and C++, and programmers use them all the time, because (little do they know) they're actually trying to build software, not hardware.Техническое: две статьи, посвященных синтаксическому анализу, про отличие LL и LR-подходов (англ.):
LL and LR Parsing Demystified
LL and LR in Context: Why Parsing Tools Are Hard
И еще глубже в тему: как написать интерпретатор Лиспа на C++
Lisp interpreter in 90 lines of C++
Приложение. Пример программного кода (java), реализующего анализатор, описанный в статье:
package demoll; public class DemoLL { public boolean cutNextToken(StringBuilder svList, String separator, StringBuilder token) { String s = svList.toString(); if (s.trim().isEmpty()){ return false; } int sepIndex = s.indexOf(separator); if (sepIndex == -1) { // разделитель не найден, последний элемент списка token.setLength(0); token.append(s); svList.setLength(0); } else { String t = s.substring(0, sepIndex); String restOfString = s.substring(sepIndex + separator.length(), s.length()); svList.setLength(0); svList.append(restOfString); token.setLength(0); token.append(t); } return true; } // "{hello world}:again" -> "{hello world}", ":again" //"{'year':'1980','month':'october','day':'06'},'key1':'value1','key2':'value2'" -> "{'year':'1980','month':'october','day':'06'}", ",'key1':'value1','key2':'value2'" public void cutTillMatchingParen(StringBuilder sbSrc, String openParen, String closeParen, StringBuilder matchPart){ String src = sbSrc.toString(); matchPart.setLength(0); int openParenCount = 0; String state = "not_copying"; for (int i = 0; i < src.length(); i++){ String cs = String.valueOf(src.charAt(i)); // cs - current symbol if (state.equals("not_copying")){ if (cs.equals(openParen)) { state = "copying"; } } if (state.equals("copying")){ matchPart.append(cs); if (cs.equals(openParen)){ openParenCount = openParenCount + 1; } if (cs.equals(closeParen)) { openParenCount = openParenCount - 1; } if (openParenCount == 0) { break; } } } sbSrc.setLength(0); sbSrc.append(src.substring(matchPart.length(), src.length())); } public void parseJsonObject(String s) { System.out.println("ok, about to parse JSON object " + s); if (s.charAt(0) == '{' && s.charAt(s.length() - 1) == '}') { String pairList = s.substring(1, s.length() - 1).trim(); parseJsonPairList(pairList); } else { System.out.println("Syntax error: not a JSON object. Must start with { and end with }"); } } public void parseJsonPairList(String pairList) { pairList = pairList.trim(); if (pairList.isEmpty()) { //System.out.println("pairList is empty"); return; } System.out.println("ok, about to parse pair list " + pairList); if (pairList.charAt(0) != '\'') { System.out.println("syntax error: key must be of type STRING, input: + pairList"); return; } StringBuilder key = new StringBuilder(); StringBuilder sbPairList = new StringBuilder(pairList); this.cutNextToken(sbPairList, ":", key); // sbPairList стал короче, если был "name":"ivan"..., то остался "ivan"... System.out.println("found KEY: " + key); // checking type of value - may be String or Object StringBuilder value = new StringBuilder(); if (sbPairList.charAt(0) == '{') { cutTillMatchingParen(sbPairList, "{", "}", value); System.out.println("found VALUE of type OBJECT:" + value); parseJsonObject(value.toString()); StringBuilder emptyString = new StringBuilder(); cutNextToken(sbPairList, ",", emptyString); } else if (sbPairList.charAt(0) == '\'') { this.cutNextToken(sbPairList, ",", value); System.out.println("found VALUE of type STRING:" + value); } else { System.out.println("syntax error: VALUE must be either STRING or OBJECT"); return; } parseJsonPairList(sbPairList.toString()); } public static void main(String[] args){ DemoLL d = new DemoLL(); System.out.println("Демонстрация разбора пар \"ключ=значение\""); StringBuilder pairs = new StringBuilder("name=ivan;surname=ivanov;middlename=ivanovich"); StringBuilder pair = new StringBuilder(); while (d.cutNextToken(pairs, ";", pair)) { StringBuilder paramName = new StringBuilder(); StringBuilder paramValue = new StringBuilder(); d.cutNextToken(pair, "=", paramName); d.cutNextToken(pair, "=", paramValue); System.out.println("param with name \"" + paramName + "\" has value of \"" + paramValue + "\""); } System.out.println("Демонстрация разбора JSON-подобной структуры"); String s = "{'name':'ivan','surname':'ivanov','birthdate':{'year':'1984','month':'october','day':'06'}}"; d.parseJsonObject(s); } }

