
Прошлого декабря прошла волна новостей о невероятной силы нового шахматного движка использующего искусственный интеллект AlphaZero компнании DeepMind. Сегодня они выпустили потрясающие результаты обновленной версии этого движка.
Результаты снова не оставляют никаких сомнений в том, что AlphaZero является одним из сильнейших шахматных движков в мире.
Обновленный AlphaZero разгромил Stockfish 8 в новом матче с 1000 партий с результатом: 155 побед, 6 поражений, 839 ничьих.
AlphaZero также переиграл Stockfish в серии партий с неравным контролем времени, побеждая традиционный движок даже при форе во времени в 10 раз.
По словам DeepMind, в дополнительных матчах новый AlphaZero превзошел «последнюю разрабатываемаю версию» Stockfish от 13 января 2018, показав практически идентичные результаты, как и в матче против Stockfish 8.
По словам DeepMind, их механизм машинного обучения также выиграл все матчи против «варианта Stockfish, который использует сильную дебютною книгу». Добавление дебютной книги, похоже, помогло Stockfish, который, наконец, выиграл значительное количество игр, когда AlphaZero играл черным, но недостаточно, чтобы выиграть матч.
Результаты были опубликованы в статье в журнале Science и предоставлены выбранным шахматным медиа.
Матч в 1000 игр был проведен в начале 2018 года. В матче AlphaZero и Stockfish были даны три часа каждой игры плюс 15-секундный прирост за ход. Этот контроль времени, по-видимому, сделает устаревшим один из самых больших аргументов против резутатов прошлогоднего матча, а именно то, что в 2017 году контроль времени на одну минуту за ход был сильным преимуществом для AlphaZero.
С тремя часами плюс 15-секундный прирост, такой аргумент не имеет смысла, так как это огромное количество игрового времени для любого шахматного движка. В играх с неравным временем, AlphaZero доминировал даже при соотношении времени 10-к-1. Stockfish начал побеждать только при соотношении 30-к-1.
Результаты AlphaZero в партиях с неравным временем показывают, что он не только намного сильнее, чем любой традиционный шахматный движок, но также использует гораздо более эффективный поиск ходов. Согласно DeepMind, AlphaZero использует поиск по дереву Монте-Карло и изучает около 60 000 позиций в секунду, по сравнению с 60 миллионами для Stockfish.
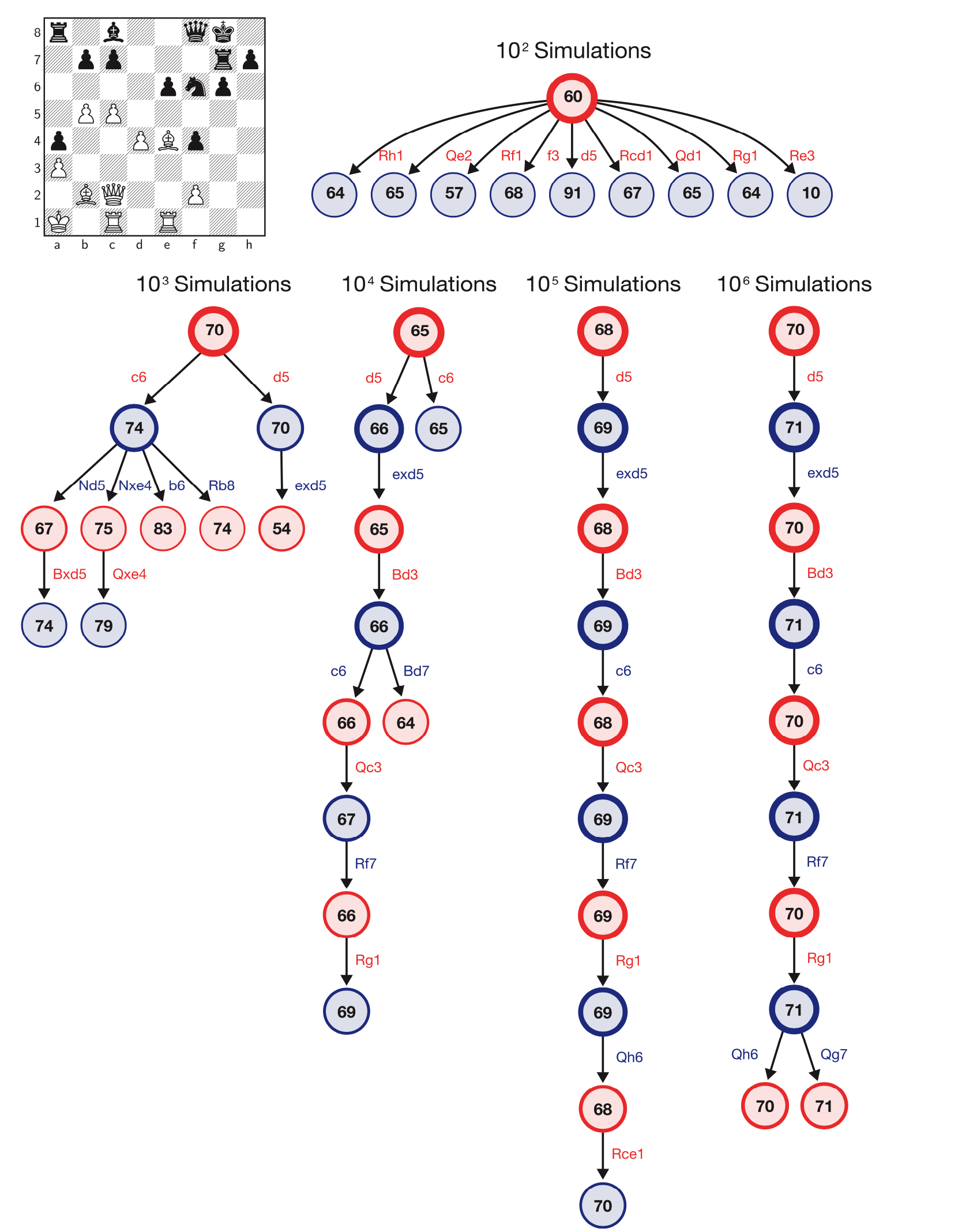
Иллюстрация алгоритма поиска ходов AlphaZero. Изображение DeepMind из статьи в Science.
Согласно статье, обновленный алгоритм AlphaZero идентичен в трех сложных играх: шахматах, сёги и го. Эта версия AlphaZero смогла победить лучших компьютерных движков всех трех игр после нескольких часов самообучения, начиная с простых правил игры.
DeepMind выпустили 210 игр из матча, которые вы можете скачать здесь.
Новая версия AlphaZero обучила себя играть в шахматы, начиная с правил игры, используя методы машинного обучения, чтобы постоянно обновлять свои нейронные сети. По данным DeepMind, для генерации первого набора игр для самостоятельной игры использовалось 5000 TPU (тензорный процессор Google, специализированная интегральная схема для ИИ), а затем 16 TPU использовались для обучения нейронных сетей.
Общее время обучения в шахматах заняло девять часов с нуля. Согласно DeepMind, новый AlphaZero потребовал всего четыре часа обучения, чтобы превзойти Stockfish; за девять часов он намного опередил чемпиона мира среди шахматных движков.
Для самих игр, Stockfish использовал 44 процессора, а AlphaZero использовал одну машину с четырьмя TPU и 44 ядрами процессора.
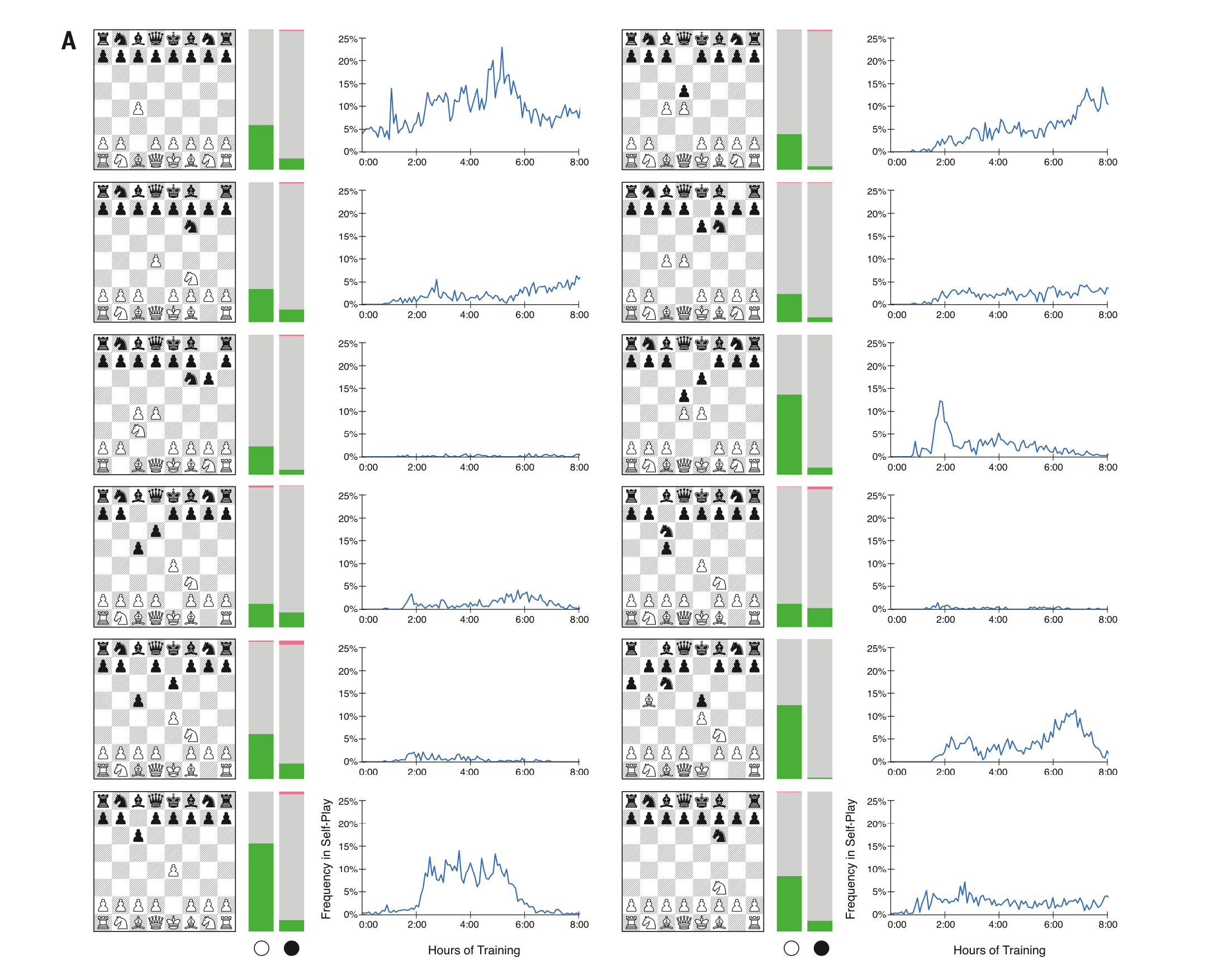
Результаты AlphaZero против Stockfish в самых популярных дебютах. Слева AlphaZero играет белыми; справа — черными.
DeepMind сами отметили уникальный стиль игры своей программы в статье:
«В нескольких играх AlphaZero пожертвовал фиграми для долгосрочного стратегического преимущества, предполагая, что он имеет более зависящую от контекста позиционную оценку, чем оценки, основанные на правилах, используемые в предыдущих шахматных программах», — сказали исследователи DeepMind.
Компания AI также подчеркнула важность использования той же версии AlphaZero в трех разных играх, рекламируя ее как прорыв в общем игровом интеллекте:
«Эти результаты приближают нас к выполнению многолетних амбиций искусственного интеллекта: общей игровой системы, которая может научиться освоить любую игру», — сказали исследователи DeepMind.

