Latency Numbers Every Programmer Should Know — таблица «задержек, которые должен знать каждый программист». Там собраны средние значения времени для выполнения базовых операций компьютера в 2012-м году. Для этой таблицы есть несколько альтернативных представлений и вот одно из них.
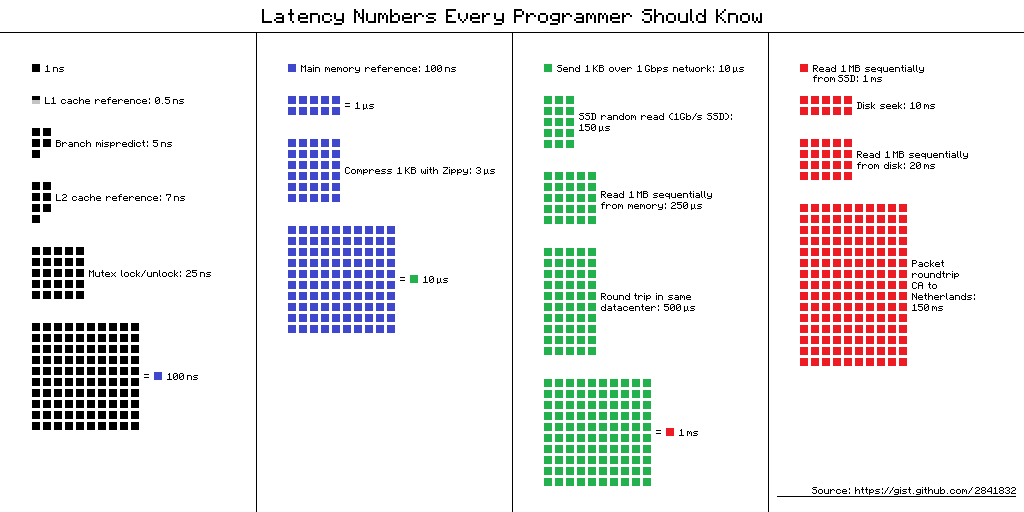
Ссылка на источник схемы
Но какая польза мобильным разработчикам от этой информации в 2019? Кажется, что никакой, но Дмитрий Куркин (SClown) из команды Яндекс.Навигатора задумался: «А как бы таблица выглядела для современного iPhone?». Что из этого получилось, в переработанной текстовой версии доклада Дмитрия на AppsConf.
Почему же программисты должны знать эти числа? И актуальны ли они для мобильных разработчиков? Можно выделить две основные задачи, которые можно решать при помощи этих чисел.
Возьмем простую ситуацию — телефонный разговор. Мы легко можем сказать, когда этот процесс быстрый, а когда долгий: пара секунд — очень быстро, несколько минут — средний разговор, а час и больше — очень длинный. С загрузкой страниц аналогично: меньше, чем за секунду — быстро, несколько секунд — терпимо, а минута — это катастрофа, пользователь может не дождаться загрузки.
Но что можно сказать о таких операциях, как добавление числа в массив – та самая «быстрая вставка», о которой иногда любят говорить на собеседованиях? Сколько это занимает на смартфоне? Наносекунды, микросекунды или миллисекунды? Я встречал мало людей, кто мог бы сказать, что 1 миллисекунда — это долго, но в нашем случае это именно так.
Время выполнения операций на различных устройствах может отличаться в десятки и сотни раз. Например время обращения к оперативной памяти отличается от обращения к кешу L1 в 100 раз. Это большая разница, но не бесконечная. Если у нас есть для этого конкретные значение, то при оптимизации своих приложений мы можем оценить — будет ли выигрыш по времени или нет.

Когда я увидел эти числа, то заинтересовался разницей между кэшем и обращением к памяти. Если я аккуратно сложу свои данные в 64 Кбайта, что не так мало, то мой код будет работать в 100 раз быстрее – это быстро, полетит все!

Сразу захотелось все это проверить, показать коллегам, и применить везде где только можно. Начать я решил с типового инструмента, который предлагает Apple — XCTest c measureBlock-ом. Тест организовал так: выделил массив, заполнил числами, их XOR’ил и повторил алгоритм 10 раз, чтобы наверняка. После этого смотрел, сколько времени уходит на один элемент.
Размер буфера увеличился в 100 раз, а время на операцию не только не увеличилось в 100 раз, а уменьшилось почти в 2 раза. Господа офицеры, нас предали?!
После такого результата у меня закрались большие сомнения, что эти числа можно увидеть в реальной жизни. Возможно, для обычного приложения невозможно ощутить эту разницу. Или может быть на мобильной платформе все иначе.
Я стал искать способ увидеть разницу в работе между кэшами и основной памятью. Во время поиска мне попалась статья, где автор жаловался, что у него на Mac и на iPhone работает некий бенчмарк и не показывает эти задержки. Я взял этот инструмент и получил результат – точно как в аптеке. Время обращения к памяти довольно четко увеличивалось, когда размер буфера превышал размер соответствующего кеша.

Получить такие результаты мне помог LMbench. Это бенчмарк, созданный Larry McVoy, одним из разработчиков ядра Linux, который позволяет измерять время обращения к памяти, затраты на переключение потоков и операции с файловой системой, и даже время, которое занимают основные операции процессора: сложение, вычитание и пр. По этому бенчмарку Texas Instruments представил интересные данные замеров для своих процессоров. LMBench написан на C, поэтому было не сложно запустить его на iOS.
Вооружившись таким прекрасным инструментом, я решил сделать аналогичные замеры, но для актуального мобильного устройства — для iPhone. Основные замеры производил на 5S, а дальше добирал результаты по мере того, как другие устройства попадали в руки. Поэтому если не указано устройство, то это 5S.
Для этого теста используется специальный массив, который наполнен элементами, ссылающимися друг на друга. Каждый из элементов — это указатель на другой элемент. Обход массива происходит не по индексу, а переходами от одного узла к другому. Эти элементы разбросаны по массиву так, чтобы, при обращении к новому элементу, как можно чаще он был не в кэше, а выгружался из оперативной памяти. Такое расположение максимально мешает работе кэшей.
Предварительный результат вы уже видели. В случае кэша L1 — меньше 10 наносекунд, для L2 — пара десятков наносекунд, а в случае основной памяти время поднимается до сотен наносекунд.
Измеряются три основных операции:
При работе с буфером используются 2 подхода: в первом случае используется только каждый четвертый элемент, а во втором последовательно все элементы.
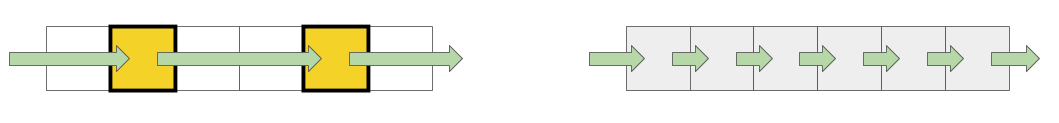
Самая высокая скорость получается при малом размере буфера, а дальше идут четкие ступеньки, по размерам кэшей L1 и L2. Самое интересное, что когда данные читаются последовательно, никакого снижения скорости не происходит. А вот в случае пропусков видны четкие ступеньки.
При последовательном чтении ОС успевает подгрузить необходимые данные в кэш, поэтому при любом размере буфера мне не нужно обращаться к памяти — все нужные данные получаются из кэша. Это объясняет, почему я не увидел разницы по времени в моем базовом тесте.
Результаты замеров операций чтения и записи показали, что в обычном приложении довольно сложно получить предполагаемое ускорение в 100 раз. С одной стороны, система сама достаточно хорошо кэширует данные, и даже при больших массивах мы с высокой вероятностью находим данные в кэше. А с другой стороны, работа с различными переменными легко может потребовать обращения к памяти и потере выигранных сотен наносекунд.
Дальше я хотел получить аналогичные данные для работы с потоками, чтобы понять цену использования многопоточности: сколько стоит создать поток и переключиться от одного потока к другому. Для нас это частые операции, и хочется понимать потери.
Для отслеживания работы потоков в приложении очень здорово помогает System Trace. Про этот инструмент довольно подробно рассказывали на WWDC 2016. Инструмент помогает увидеть переходы по состояниям потока и представляет данные по потокам в трех основных категориях: системные вызовы, работа с памятью и состояния потока.

Первый тест — это выполнение задачи в новом потоке. Создаем поток с некой процедурой и ждем, когда она завершит работу. Сравнив итоговое время со временем на саму процедуру, получаем, итоговую потерю на запуск процедуры в новом потоке.
В System Trace хорошо видно, как все происходит на самом деле:

В итоге создание потока требует довольно значительных затрат: iPhone 5S – 230 микросекунд, на 6S – 50 микросекунд. Завершение потока занимает почти в 2 раза больше времени, чем создание, join тоже отнимает ощутимое время. При работе с памятью мы получили сотни наносекунд, что в 100 раз меньше, чем десятки микросекунд.
Следующий тест — это замеры на работу семафора. У нас есть 2 заранее созданных потока, и для каждого из них есть семафор. Потоки поочередно сигналят семафору соседа и ждут свой. Передавая друг другу сигналы, потоки играют в «пинг-понг», оживляют друг друга. Такая двойная итерация дает двойное время переключения семафора.

В System Trace все выглядит аналогично:

Время переключения получилось в пределах 10 микросекунд. Разница с созданием потока в 50 раз – это именно та причина, по которой создаются пулы потоков, а не новый поток на каждую процедуру.
В предыдущих двух тестах передача управления между потоками была полностью контролируема — мы четко понимали откуда и куда должен произойти переход. Однако намного чаще бывает так, что система сама переключается от одного потока к другому. Когда мы запускаем параллельно больше задач, чем ядер в устройстве, операционная система должна уметь сама переключаться, чтобы обеспечить всех процессорным временем.
В этом тесте я хотел измерить потери от запуска слишком большого количества потоков. Для этого создается пул из 16 потоков, каждый из которых ждет семафор, и, как только получает сигнал, выполняет некую процедуру и сигналит семафор обратно. Основной поток запускает весь пул, подавая 16 сигналов, и после этого ждет 16 сигналов в ответ.
В System Trace видно, что блоки разбросаны хаотично, некоторые из них значительно длиннее, чем остальные. Если многократные переключения приводят к росту времени выполнения операции, то в итоге должно расти среднее время исполнения.
Однако с ростом количества потоков среднее время выполнения операции не увеличивается.
В теории среднее время должно сохраняться, пока нагрузка соответствует вычислительной мощности. То есть количество задач соответствует количеству ядер.

Если же запустить много задач параллельно, то ОС, переключаясь с одной задачи на другую, будет привносить дополнительные задержки. Это должно отразиться на результате.

На практике же на устройстве работает не только наше приложение, но у него еще много параллельных и системных процессов. Даже на единственном потоке в нашем приложении будут сказываться переключения, которые приводят к прерываниям и задержкам. Поэтому во всех ситуациях присутствуют задержки, и нет никакой разницы – выстраивать задачи последовательно или запускать параллельно.

Ниже наша таблица «Latency Numbers» с данными по потокам и семафору.
У нас уже есть память и потоки — для полноты картины нам не хватает только операций с файловой системой.
Первый тест — скорость чтения — сколько стоит прочитать файл. Тест состоит из двух частей. В первой — измеряем скорость чтения с учетом открытия, чтения и закрытия файла. Во второй — предполагаем, что файл открыт постоянно: мы позиционируемся куда-то и читаем, сколько хотим.
Результаты корректно рассматривать с двух точек зрения. Когда файл маленький, есть некоторое минимальное время на чтение данных из файла. До одного килобайта это 5,3 микросекунды — не важно: 1 байт, 2 или 1 Кб — на всё 5,3 мкс. Поэтому о скорости можно говорить только в случае больших файлов, когда фиксированным временем уже можно пренебречь. Операция по открытию и закрытию файла занимает приблизительно одинаковое время при любом размере файла — в случае 5S, порядка 50 микросекунд.

Для скорости чтения получаются такие графики.
Для iPhone X и файла в 1 Мб, скорость может достигать 20 Мб/с. Интересно, что эффективнее оказывается чтение файла размером 1 Мб. При больших размерах файлов, судя по всему, влияют размеры кэшей. Именно поэтому дальше скорость падает и в районе 10 Мб выравнивается.
Тест состоит из этапа создания файла и записи данных, и удаления созданных файлов. Результат ступенчатый: на малых размерах время стабильное — около 7 мкс, и дальше растет. Шкала логарифмическая.

Я был удивлен тем, что время на удаление большого файла соизмеримо со временем на создание, так как предполагал, что удаление – быстрая операция. Оказывается нет, для iPhone удаление по времени сопоставимо с созданием файла. Итоговая таблица выглядит так.
На основе этих замеров мы теперь имеем представление, сколько времени требуют базовые операции iOS: обращение к памяти — это наносекунды, работа с файлами — микросекунды, создание потока — десятки микросекунд, а переключение — всего несколько микросекунд.
Чтобы получить в приложении физически заметное подвисание, время выполнения процедуры должно превышать 15 миллисекунд (время обновление экрана при 60fps). Это почти в тысячу раз больше, чем большинство полученных в статье замеров. В таких масштабах миллисекунда – это довольно много, а секунда — это уже «целая вечность».
Проведенные тесты показали, что несмотря на наличие большой разницы во времени обращения к памяти и к кэшам, непосредственно воспользоваться этим соотношением довольно сложно. Прежде чем компоновать все свои данные под L1, необходимо убедиться, что в вашем случае это действительно даст результат.
По тестам операций с потоками мы смогли убедиться, что создание и уничтожение потоков требует значительного времени, а вот выполнение большого количества параллельных операций не приносит дополнительных расходов.
Ну и в завершение хотел бы вам напомнить самое важное правило при работе над производительностью – сначала замеры и только потом оптимизации!
Профиль спикера Дмитрия Куркина на GitHub.
Ссылка на источник схемы
Но какая польза мобильным разработчикам от этой информации в 2019? Кажется, что никакой, но Дмитрий Куркин (SClown) из команды Яндекс.Навигатора задумался: «А как бы таблица выглядела для современного iPhone?». Что из этого получилось, в переработанной текстовой версии доклада Дмитрия на AppsConf.
Для чего это нужно?
Почему же программисты должны знать эти числа? И актуальны ли они для мобильных разработчиков? Можно выделить две основные задачи, которые можно решать при помощи этих чисел.
Представление о масштабе времени в компьютере
Возьмем простую ситуацию — телефонный разговор. Мы легко можем сказать, когда этот процесс быстрый, а когда долгий: пара секунд — очень быстро, несколько минут — средний разговор, а час и больше — очень длинный. С загрузкой страниц аналогично: меньше, чем за секунду — быстро, несколько секунд — терпимо, а минута — это катастрофа, пользователь может не дождаться загрузки.
Но что можно сказать о таких операциях, как добавление числа в массив – та самая «быстрая вставка», о которой иногда любят говорить на собеседованиях? Сколько это занимает на смартфоне? Наносекунды, микросекунды или миллисекунды? Я встречал мало людей, кто мог бы сказать, что 1 миллисекунда — это долго, но в нашем случае это именно так.
Соотношение скорости работы различных компонент компьютера
Время выполнения операций на различных устройствах может отличаться в десятки и сотни раз. Например время обращения к оперативной памяти отличается от обращения к кешу L1 в 100 раз. Это большая разница, но не бесконечная. Если у нас есть для этого конкретные значение, то при оптимизации своих приложений мы можем оценить — будет ли выигрыш по времени или нет.
«Latency numbers» в реальной жизни
Когда я увидел эти числа, то заинтересовался разницей между кэшем и обращением к памяти. Если я аккуратно сложу свои данные в 64 Кбайта, что не так мало, то мой код будет работать в 100 раз быстрее – это быстро, полетит все!
Сразу захотелось все это проверить, показать коллегам, и применить везде где только можно. Начать я решил с типового инструмента, который предлагает Apple — XCTest c measureBlock-ом. Тест организовал так: выделил массив, заполнил числами, их XOR’ил и повторил алгоритм 10 раз, чтобы наверняка. После этого смотрел, сколько времени уходит на один элемент.
| Размер буфера | Общее время | Время на операцию |
| 50 кб | 1,5 мс | 30 нс |
| 500 кб | 12 мс | 24 нс |
| 5000 кб | 85 мс | 17 нс |
Размер буфера увеличился в 100 раз, а время на операцию не только не увеличилось в 100 раз, а уменьшилось почти в 2 раза. Господа офицеры, нас предали?!
После такого результата у меня закрались большие сомнения, что эти числа можно увидеть в реальной жизни. Возможно, для обычного приложения невозможно ощутить эту разницу. Или может быть на мобильной платформе все иначе.
Я стал искать способ увидеть разницу в работе между кэшами и основной памятью. Во время поиска мне попалась статья, где автор жаловался, что у него на Mac и на iPhone работает некий бенчмарк и не показывает эти задержки. Я взял этот инструмент и получил результат – точно как в аптеке. Время обращения к памяти довольно четко увеличивалось, когда размер буфера превышал размер соответствующего кеша.
Получить такие результаты мне помог LMbench. Это бенчмарк, созданный Larry McVoy, одним из разработчиков ядра Linux, который позволяет измерять время обращения к памяти, затраты на переключение потоков и операции с файловой системой, и даже время, которое занимают основные операции процессора: сложение, вычитание и пр. По этому бенчмарку Texas Instruments представил интересные данные замеров для своих процессоров. LMBench написан на C, поэтому было не сложно запустить его на iOS.
Затраты на работу с памятью
Вооружившись таким прекрасным инструментом, я решил сделать аналогичные замеры, но для актуального мобильного устройства — для iPhone. Основные замеры производил на 5S, а дальше добирал результаты по мере того, как другие устройства попадали в руки. Поэтому если не указано устройство, то это 5S.
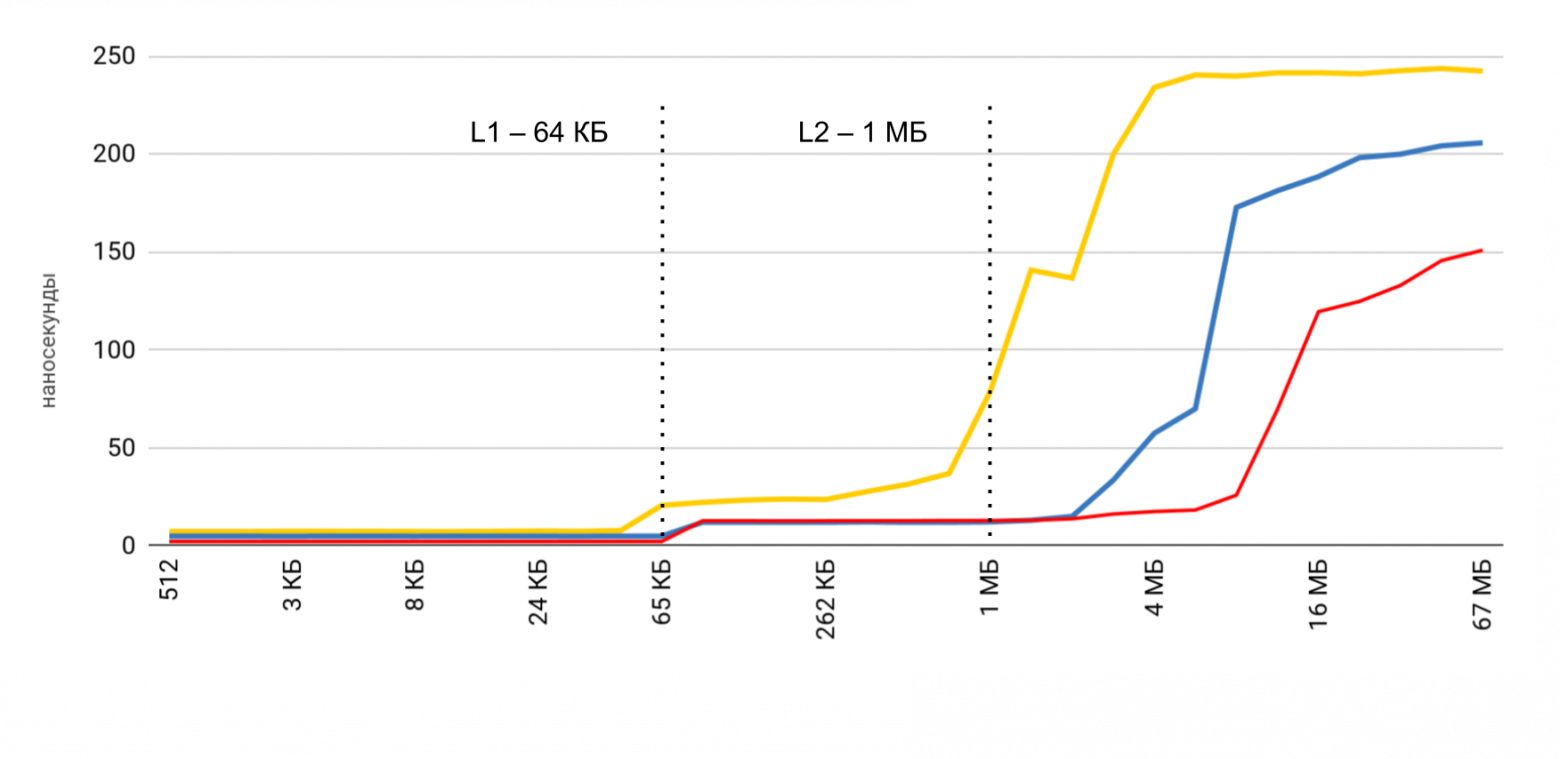
Доступ к памяти
Для этого теста используется специальный массив, который наполнен элементами, ссылающимися друг на друга. Каждый из элементов — это указатель на другой элемент. Обход массива происходит не по индексу, а переходами от одного узла к другому. Эти элементы разбросаны по массиву так, чтобы, при обращении к новому элементу, как можно чаще он был не в кэше, а выгружался из оперативной памяти. Такое расположение максимально мешает работе кэшей.
Предварительный результат вы уже видели. В случае кэша L1 — меньше 10 наносекунд, для L2 — пара десятков наносекунд, а в случае основной памяти время поднимается до сотен наносекунд.
Скорость чтения и записи
Измеряются три основных операции:
- чтение (p[i]+) — считываем элементы и складываем в общую сумму;
- запись (p[i] = 1) — в каждый элемент записываем константное число;
- чтение и запись (p[i] = p[i] * 2) — вынимаем элемент, меняем его и записываем новое значение обратно.
При работе с буфером используются 2 подхода: в первом случае используется только каждый четвертый элемент, а во втором последовательно все элементы.
Самая высокая скорость получается при малом размере буфера, а дальше идут четкие ступеньки, по размерам кэшей L1 и L2. Самое интересное, что когда данные читаются последовательно, никакого снижения скорости не происходит. А вот в случае пропусков видны четкие ступеньки.
При последовательном чтении ОС успевает подгрузить необходимые данные в кэш, поэтому при любом размере буфера мне не нужно обращаться к памяти — все нужные данные получаются из кэша. Это объясняет, почему я не увидел разницы по времени в моем базовом тесте.
Результаты замеров операций чтения и записи показали, что в обычном приложении довольно сложно получить предполагаемое ускорение в 100 раз. С одной стороны, система сама достаточно хорошо кэширует данные, и даже при больших массивах мы с высокой вероятностью находим данные в кэше. А с другой стороны, работа с различными переменными легко может потребовать обращения к памяти и потере выигранных сотен наносекунд.
| L1 | L2 | Memory | |
| Latency numbers | 1 нс | 7 нс | 100 нс |
| iPhone 5s | 7 нс | 30 нс | 240 нс |
| iPhone 6s Plus | 5 нс | 12 нс | 200 нс |
| iPhone X | 2 нс | 12 нс | 146 нс |
Затраты на работу с потоками
Дальше я хотел получить аналогичные данные для работы с потоками, чтобы понять цену использования многопоточности: сколько стоит создать поток и переключиться от одного потока к другому. Для нас это частые операции, и хочется понимать потери.
Instruments. System Trace
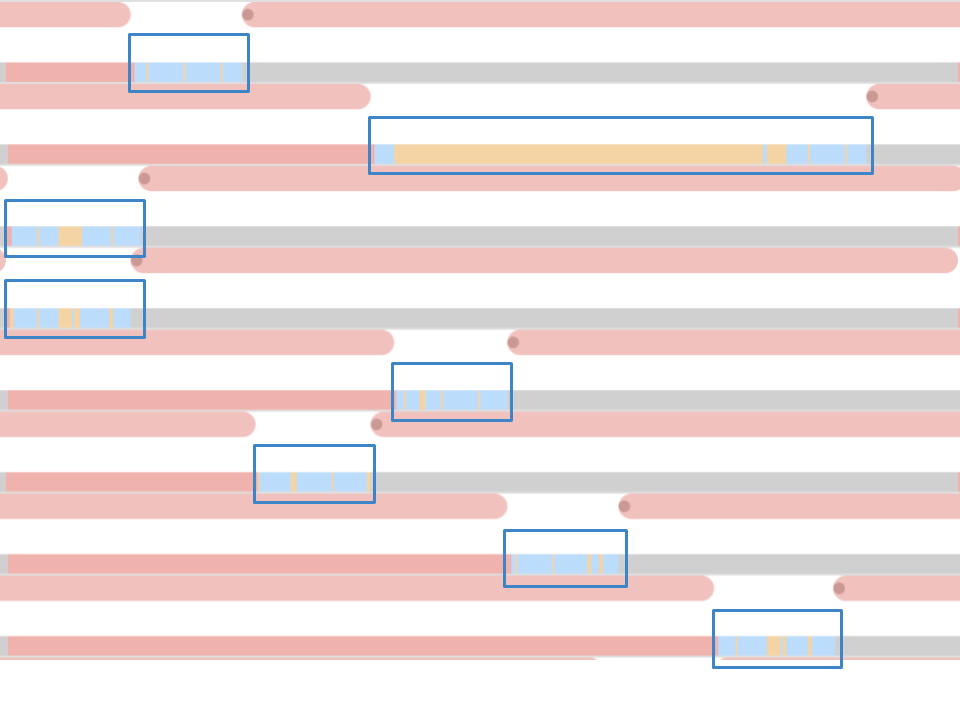
Для отслеживания работы потоков в приложении очень здорово помогает System Trace. Про этот инструмент довольно подробно рассказывали на WWDC 2016. Инструмент помогает увидеть переходы по состояниям потока и представляет данные по потокам в трех основных категориях: системные вызовы, работа с памятью и состояния потока.
- Системные вызовы. Они представлены в виде красных «колбасок». Когда на них наводишь, видно имя системного метода и длительность исполнения. Зачастую в прикладных приложениях такой системный вызов происходит не напрямую: мы что-то используем, что в свою очередь уже вызывает системный метод. Не стоит рассчитывать на то, что тут будут видны методы из вашего кода.
- Операции по работе с памятью. Они представлены в виде синих «колбасок». Сюда входят такие операции как выделение памяти, освобождение, обнуление и пр.
- Состояние потока. Синий цвет — поток работает, какой-то из процессоров выполняет код из этого потока. Серый — поток по какой-то причине заблокирован и не может продолжать исполнение. Красный — поток готов работать, но в этот момент нет свободного ядра, чтобы исполнять его код. Оранжевый цвет — поток прерван на более приоритетную работу.
- Точки интереса. Это специальные метки, которые можно расставить по коду при помощи вызова
kdebug_signpost. Метки могут быть одинарные (конкретное место в коде) или в виде диапазона (для выделения целой процедуры). При помощи таких меток получается значительно легче соотносить микросекунды и системные вызовы со своим приложением.
Затраты на создание потока
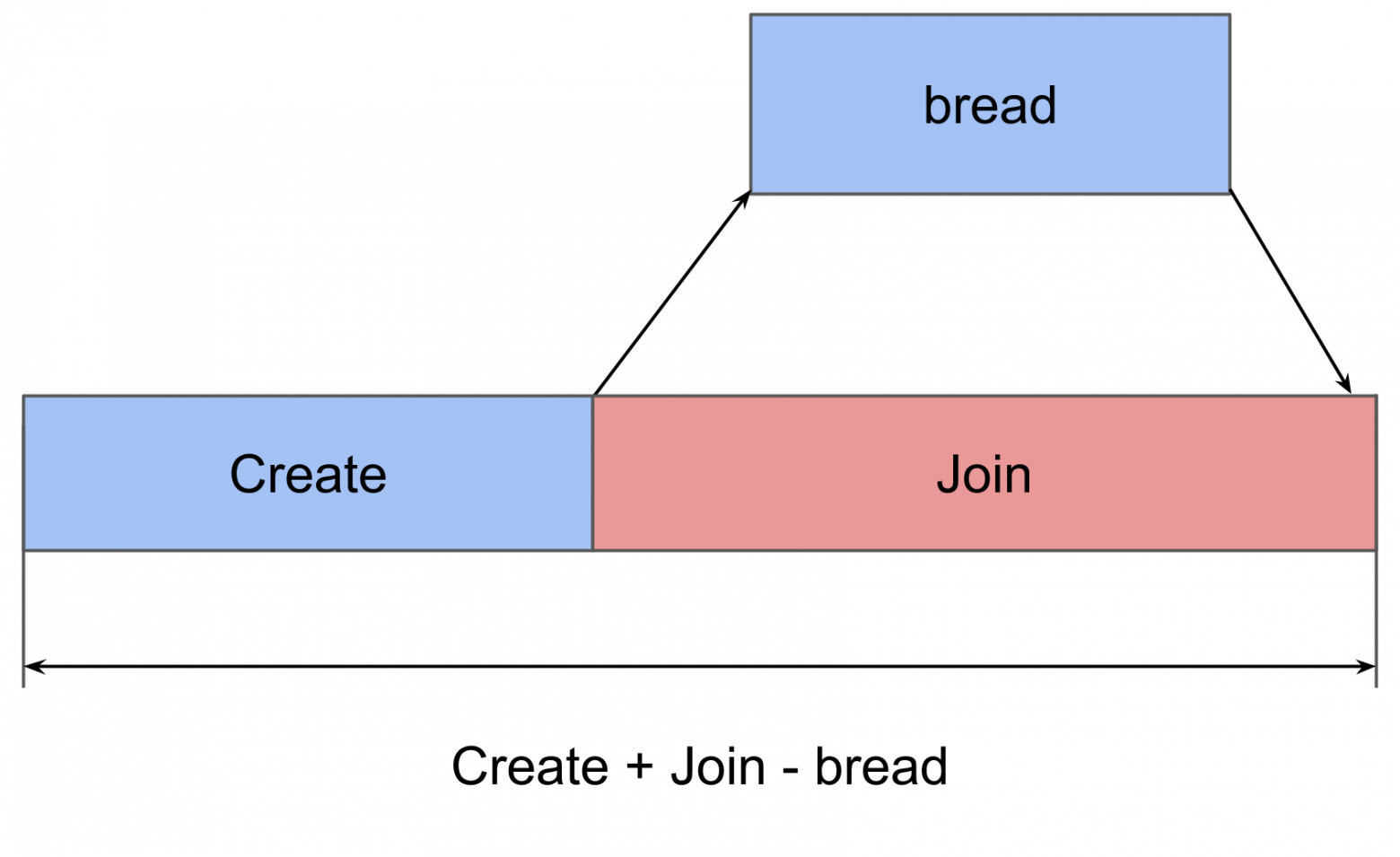
Первый тест — это выполнение задачи в новом потоке. Создаем поток с некой процедурой и ждем, когда она завершит работу. Сравнив итоговое время со временем на саму процедуру, получаем, итоговую потерю на запуск процедуры в новом потоке.
В System Trace хорошо видно, как все происходит на самом деле:
- Создание потока.
- Новый поток, в котором исполняется наша процедура. Красная зона в начале говорит, что поток был создан, но некоторое время не мог исполняться, поскольку не было свободного ядра.
- Завершение потока. Интересно, что сама процедура завершения потока даже больше, чем его создание. Хотя кажется, что удалять всегда быстрее.
- Ожидание завершения процедуры, которое было в исходной схеме, и оно заканчивается после завершения потока — еще некоторое время метод это осознает и, после, сообщает. Это время чуть больше, чем завершение потока.
В итоге создание потока требует довольно значительных затрат: iPhone 5S – 230 микросекунд, на 6S – 50 микросекунд. Завершение потока занимает почти в 2 раза больше времени, чем создание, join тоже отнимает ощутимое время. При работе с памятью мы получили сотни наносекунд, что в 100 раз меньше, чем десятки микросекунд.
| overhead | create | end | join | |
| iPhone 5s | 230 мкс | 40 мкс | 70 мкс | 30 мкс |
| iPhone 6s Plus | 50 мкс | 12 мкс | 20 мкс | 7 мкс |
Время переключения семафора
Следующий тест — это замеры на работу семафора. У нас есть 2 заранее созданных потока, и для каждого из них есть семафор. Потоки поочередно сигналят семафору соседа и ждут свой. Передавая друг другу сигналы, потоки играют в «пинг-понг», оживляют друг друга. Такая двойная итерация дает двойное время переключения семафора.
В System Trace все выглядит аналогично:
- Подается сигнал для семафора второго потока. Видно, что это операция очень короткая.
- Разблокируется второй поток, завершается ожидание на его семафоре.
- Подается сигнал для семафора первого потока.
- Разблокируется первый поток, завершается ожидание на его семафоре.
Время переключения получилось в пределах 10 микросекунд. Разница с созданием потока в 50 раз – это именно та причина, по которой создаются пулы потоков, а не новый поток на каждую процедуру.
Потери на системное переключение контекста потока
В предыдущих двух тестах передача управления между потоками была полностью контролируема — мы четко понимали откуда и куда должен произойти переход. Однако намного чаще бывает так, что система сама переключается от одного потока к другому. Когда мы запускаем параллельно больше задач, чем ядер в устройстве, операционная система должна уметь сама переключаться, чтобы обеспечить всех процессорным временем.
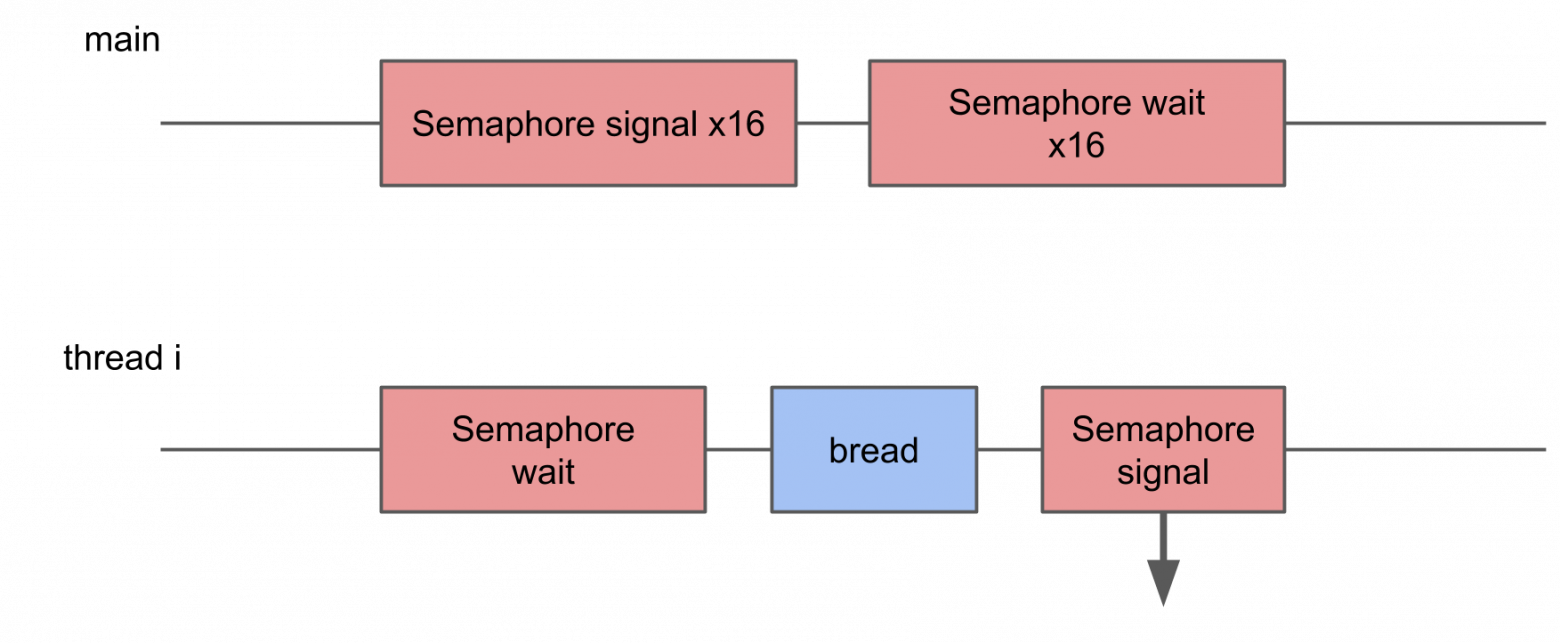
В этом тесте я хотел измерить потери от запуска слишком большого количества потоков. Для этого создается пул из 16 потоков, каждый из которых ждет семафор, и, как только получает сигнал, выполняет некую процедуру и сигналит семафор обратно. Основной поток запускает весь пул, подавая 16 сигналов, и после этого ждет 16 сигналов в ответ.
В System Trace видно, что блоки разбросаны хаотично, некоторые из них значительно длиннее, чем остальные. Если многократные переключения приводят к росту времени выполнения операции, то в итоге должно расти среднее время исполнения.
Однако с ростом количества потоков среднее время выполнения операции не увеличивается.
В теории среднее время должно сохраняться, пока нагрузка соответствует вычислительной мощности. То есть количество задач соответствует количеству ядер.
Если же запустить много задач параллельно, то ОС, переключаясь с одной задачи на другую, будет привносить дополнительные задержки. Это должно отразиться на результате.
На практике же на устройстве работает не только наше приложение, но у него еще много параллельных и системных процессов. Даже на единственном потоке в нашем приложении будут сказываться переключения, которые приводят к прерываниям и задержкам. Поэтому во всех ситуациях присутствуют задержки, и нет никакой разницы – выстраивать задачи последовательно или запускать параллельно.
Ниже наша таблица «Latency Numbers» с данными по потокам и семафору.
| L1 | L2 | Memory | Semaphore | |
| Latency numbers | 1 нс | 7 нс | 100 нс | 25 нс |
| iPhone 5s | 7 нс | 30 нс | 240 нс | 8 мкс |
| iPhone 6s Plus | 5 нс | 12 нс | 200 нс | 5 мкс |
| iPhone X | 2 нс | 12 нс | 146 нс | 3,2 мкс |
Затраты на работу с файлами
У нас уже есть память и потоки — для полноты картины нам не хватает только операций с файловой системой.
Чтение файла
Первый тест — скорость чтения — сколько стоит прочитать файл. Тест состоит из двух частей. В первой — измеряем скорость чтения с учетом открытия, чтения и закрытия файла. Во второй — предполагаем, что файл открыт постоянно: мы позиционируемся куда-то и читаем, сколько хотим.
Результаты корректно рассматривать с двух точек зрения. Когда файл маленький, есть некоторое минимальное время на чтение данных из файла. До одного килобайта это 5,3 микросекунды — не важно: 1 байт, 2 или 1 Кб — на всё 5,3 мкс. Поэтому о скорости можно говорить только в случае больших файлов, когда фиксированным временем уже можно пренебречь. Операция по открытию и закрытию файла занимает приблизительно одинаковое время при любом размере файла — в случае 5S, порядка 50 микросекунд.
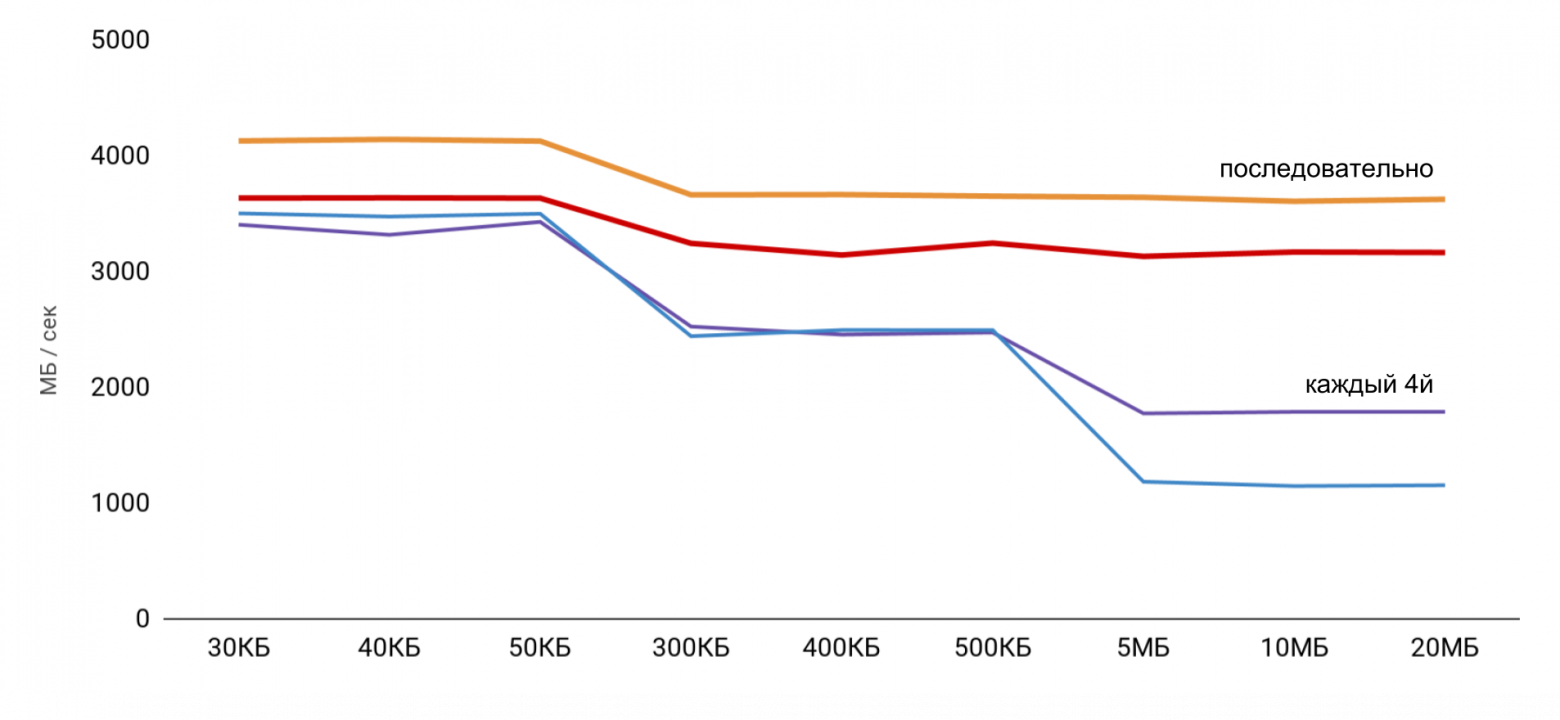
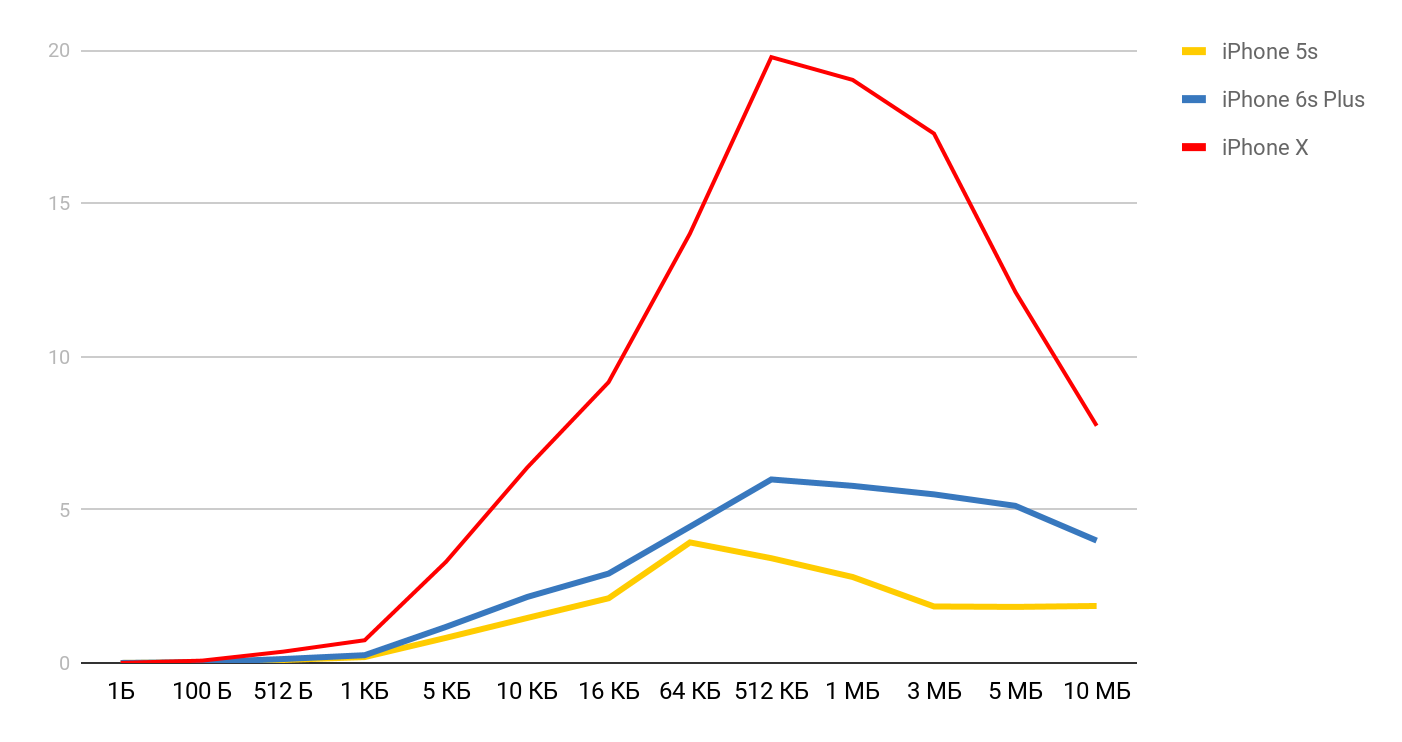
Для скорости чтения получаются такие графики.
Для iPhone X и файла в 1 Мб, скорость может достигать 20 Мб/с. Интересно, что эффективнее оказывается чтение файла размером 1 Мб. При больших размерах файлов, судя по всему, влияют размеры кэшей. Именно поэтому дальше скорость падает и в районе 10 Мб выравнивается.
Создание и удаление файлов
Тест состоит из этапа создания файла и записи данных, и удаления созданных файлов. Результат ступенчатый: на малых размерах время стабильное — около 7 мкс, и дальше растет. Шкала логарифмическая.
Я был удивлен тем, что время на удаление большого файла соизмеримо со временем на создание, так как предполагал, что удаление – быстрая операция. Оказывается нет, для iPhone удаление по времени сопоставимо с созданием файла. Итоговая таблица выглядит так.
| L1 | L2 | Memory | Semaphore | Disk | |
| Latency numbers | 1 нс | 7 нс | 100 нс | 25 нс | 150 мксs |
| iPhone 5s | 7 нс | 30 нс | 240 нс | 8 мкс | 5 мкс |
| iPhone 6s Plus | 5 нс | 12 нс | 200 нс | 5 мкс | 4 мкс |
| iPhone X | 2 нс | 12 нс | 146 нс | 3,2 мкс | 1,3 мкс |
Заключение
На основе этих замеров мы теперь имеем представление, сколько времени требуют базовые операции iOS: обращение к памяти — это наносекунды, работа с файлами — микросекунды, создание потока — десятки микросекунд, а переключение — всего несколько микросекунд.
Чтобы получить в приложении физически заметное подвисание, время выполнения процедуры должно превышать 15 миллисекунд (время обновление экрана при 60fps). Это почти в тысячу раз больше, чем большинство полученных в статье замеров. В таких масштабах миллисекунда – это довольно много, а секунда — это уже «целая вечность».
Проведенные тесты показали, что несмотря на наличие большой разницы во времени обращения к памяти и к кэшам, непосредственно воспользоваться этим соотношением довольно сложно. Прежде чем компоновать все свои данные под L1, необходимо убедиться, что в вашем случае это действительно даст результат.
По тестам операций с потоками мы смогли убедиться, что создание и уничтожение потоков требует значительного времени, а вот выполнение большого количества параллельных операций не приносит дополнительных расходов.
Ну и в завершение хотел бы вам напомнить самое важное правило при работе над производительностью – сначала замеры и только потом оптимизации!
Профиль спикера Дмитрия Куркина на GitHub.
Переработка и превращение докладов AppsConf 2018 в статьи идет параллельным курсом с подготовкой совсем новой конференции 2019 года. Пока в списке принятых докладов только 7 тем, но этот список будет все время расширяться, чтобы 22-23 апреля случилась классная конференция для мобильных разработчиков.
Следите за публикациями, подписывайтесь на youtube-канал и на рассылку и это время пролетит незаметно.

