Вероятно, все уже слышали, что ИИ под названием AlphaStar от компании Google Deepmind размазал профессионалов в стратегии реального времени Starcraft 2. Это беспрецедентный случай в исследованиях Искусственного интеллекта. Но хочу высказать конструктивную критику по поводу этого достижения.
Постараюсь убедительно доказать следующее:
Прежде всего хочу уточнить, что я непрофессионал. Я много лет следил за развитием ИИ и сценой Starcraft 2, но не претендую на роль эксперта. Если вы заметите какие-то заблуждения, пожалуйста, укажите на них. Я всего лишь фанат и всё это невероятно увлекательно для меня. В статье много спекуляций, и я признаю, что не могу окончательно доказать основные претензии. Со всеми оговорками, если вы прочитаете статью и не согласитесь со мной, пожалуйста, аргументируйте конструктивно. Очень хочу, чтобы вы меня разубедили.
В конце концов, AlphaStar — удивительное достижение. На мой взгляд, величайшее достижение Deepmind на сегодняшний день, и я с нетерпением жду, как ещё усовершенствуют эту программу. Спасибо за ваше терпение. Итак, поехали.
Здесь ведущий проектировщик ИИ делает важное заявление (с 1:39)
В 2018 году на сцене Starcraft 2 доминировал Serral. Он действующий чемпион мира и выиграл семь из девяти крупных турниров, в которых участвовал, что привело к одному их самых мощных примеров доминирования одного игрока в истории Starcraft 2. Парень очень быстрый. Возможно, самый быстрый в мире.
Вид от первого лица (с 13:00):
Взгляните на его APM в левом верхнем углу. Это сокращение для количества действий в минуту. По сути это число отражает, как быстро игрок нажимает на кнопки мыши и клавиатуры. Ни разу Serral не может надолго удержать APM более 500. Есть один всплеск до APM 800, но только на долю секунды и, скорее всего, в результате спам-кликов, о которых я скоро расскажу.
Итак, самый быстрый в мире игрок способен удержать впечатляющий уровень APM 500, но у AlphaStar были всплески до 1500+. Эти нечеловеческие показатели более APM 1000 иногда длились пять секунд и полны осмысленных действий. 1500 действий в минуту — это 25 действий в секунду. Это физически невозможно для человека. Также прошу учесть, что в игре Starcraft пять секунд — большой срок, особенно в самом начале большого сражения. Если сверхчеловеческий показатель в первые пять секунд даёт ИИ преимущество, то он легко выиграет сражение благодаря эффекту снежного кома. Вот завязка битвы AlphaStar в третьей игре против MaNa (с 59:30):
AlphaStar удерживает APM 1000+ в течение пяти секунд. Ещё одна завязка в четвёртой игре с заоблачным APM 1500+ (c 2:11:32):
Один из комментаторов указывает на приемлемый показатель среднего APM. Но совершенно очевидно, что указанные всплески намного выше человеческих способностей.
Большинство игроков проявляет склонность к спам-кликам. Бессмысленные клики, которые ни на что не влияют. Например, человек перемещает армию и зачем-то щёлкает несколько раз в точке назначения. Какой эффект? Никакого. Армия не пойдёт быстрее. Одного клика было достаточно. Тогда зачем он это делает? Есть две причины:
Помните, Serral'а? Его впечатляющая мощь на самом деле не в скорости нажатий, а в точности. У него не только действительно высокий APM, но и потрясающе эффективный (общее количество кликов в минуту, кроме спам-кликов). С этого момента я буду сокращать эффективный APM как EPM. Важно помнить, что EPM учитывает только значимые действия.
Взгляните, как бывший профессионал потерял рассудок в твиттере, узнав EPM Serral'а:
Его EPM 344 — практически нереальный показатель. Он настолько высок, что мне до сих пор трудно поверить, что это правда. Разница между APM и EPM повлияла также на AlphaStar. Если ИИ может играть без спам-кликов, не означает ли это, что его пиковый EPM временами равен пиковому APM? Это делает всплески до 1000+ еще более нечеловеческими. Когда мы принимаем во внимание, что AlphaStar играет с идеальной точностью, то его механические возможности кажутся совершенно абсурдными. Он всегда нажимает именно там, где он хочет нажать. Люди промахиваются, а AlphaStar в нужные моменты начинает работать в четыре раза быстрее, чем самый быстрый игрок в мире — с точностью, о которой человек может только мечтать.
Практически все в сообществе согласны, что AlphaStar выполнял последовательности, которые ни один человек не способен повторить. Он был быстрее и точнее, чем это возможно физически. Самый быстрый в мире профессионал действует в несколько раз медленнее. Точность невозможно даже сравнить.
Утверждение Дэвида Сильвера, что AlphaStar может выполнять только действия, которые способен воспроизвести человек, просто не соответствует действительности.
Почему Deepmind хочет ограничить агента, чтобы он играл как человек? Почему бы просто не пустить его во все тяжкие без каких-либо ограничений? Причина в том, что в Starcraft 2 механические суперспособности портят геймплей. В этом видео бот несколькими зерглингами атакует группу танков, реализуя идеальную микротактику. Обычно зерглинги почти ничего не могут сделать против танков, но благодаря роботам микротактика становится гораздо более смертоносной: они уничтожают танки с минимальными потерями. С таким хорошим управлением юнитами ИИ не нужно изучать стратегию. Deepmind ведь не заинтересован в создании ИИ, который просто побеждает профессионалов Starcraft, на самом деле они хотят использовать этот проект в качестве ступеньки в продвижении общих исследований ИИ. Очень грустно, что один из руководителей проекта заявляет об ограничениях наравне с человеческими способностями, когда агент явно их нарушает и выигрывает свои игры именно благодаря сверхчеловеческому исполнению.
AlphaStar превосходит людей в управлением юнитами — этот фактор не был принят во внимание, когда разработчики тщательно балансировали игру. Этот нечеловеческий контроль способен испортить любое стратегическое мышление, которое освоил ИИ. Он даже может сделать стратегическое мышление совершенно ненужным. Программа не просто застряла на локальном максимуме. Если игра ведётся с нечеловеческой скоростью и точностью, то злоупотребление идеальным контролем юнитов, скорее всего, будет лучшим, наиболее эффективным и надёжным способом выиграть. Как бы грустно это не звучало.
Вот что сказал о сильных и слабых сторонах AlphaStar один из профессионалов, проиграв ему со счётом 1-5:
Среди поклонников Starcraft почти единодушное мнение, что AlphaStar выиграл почти исключительно из-за своей сверхчеловеческой скорости, времени реакции и точности. Профи, которые играли против него, похоже, согласны с этим. Один из сотрудников Deepmind играл против AlphaStar, прежде чем программу поставили против профессионалов. Скорее всего, он тоже согласится с такой оценкой. Дэвид Сильвер и Ориол Виньялс повторяют мантру, что AlphaStar способен делать только то, что и человек, но мы уже видели, что это просто не так.
Непохоже, что AlphaStar «делает всё правильно», как говорит Дэвид (с 1:38):
Что-то здесь явно не так.
Наконец, перейдём к главному. Спасибо, что дочитали до этого места. Но сначала подведём итоги.
Принимая во внимание все эти моменты, почему Deepmind вообще позволил ИИ явно обойти ограничения человеческого тела?
Это чистая спекуляция с моей стороны и я не утверждаю, что знаю точно историю. Но подозреваю, что произошло следующее:
В самом начале проекта Deepmind согласовала жёсткие лимиты. В этот момент AlphaStar запретили сверхчеловеческие всплески APM, которые мы видели в демонстрации. Если бы я проектировал систему, то установил бы такие ограничения:
Некоторые предлагают добавить элемент случайности в точность кликов, но я подозреваю, что это слишком снизит скорость обучения.
Итак, установили лимиты. Что дальше? Затем Deepmind запустил имитационное обучение на тысячах видеозаписей любительских игр высокого класса. На данном этапе агент просто пытается имитировать то, что делают люди — и он осваивает спам-клики. Это весьма вероятно, потому что люди очень часто их делают. Это почти самая повторяющаяся модель поведения у людей, поэтому она должна очень глубоко укорениться в поведении агента.
Максимальные всплески APM у AlphaStar изначально близки к установленным лимитам. Но большинство кликов AlphaStar оказались спам-кликами, так что его APM оказался недостаточным для нормального боя. Но без экспериментов нет обучения. Вот что сказал один из разработчиков во вчерашнем AMA: думаю, он немного замазан в этой афере:
Чтобы ускорить обучение, разработчики повышают лимиты APM, разрешив кратковременные всплески. Вот ограничения APM, которые действовали для AlphaStar в демонстрационном матче:
Если вы не очень хорошо знакомы со Starcraft, то такие лимиты выглядят разумными, однако они допускают сверхчеловеческие всплески APM, о которых мы говорили ранее, а также сверхчеловеческую точность.
Существует ограничение на максимальное количество спам-кликов. Обычно это команды перемещения или атаки, когда совершается щелчок по карте. Попробуйте, насколько быстро вы сможете нажимать кнопку мыши. Агент обучился спам-кликам у игроков и не будет щёлкать быстрее человека. То есть дополнительные клики APM на сверхчеловеческой скорости являются «произвольными» для экспериментов.
Произвольный APM используется для экспериментов в битвах. Такое взаимодействие часто происходит во время тренировки. AlphaStar начинает изучать новый тип поведения, который приводит к лучшим результатам, и доля спама в кликах снижается.
Если агент усвоил полезные действия, почему Deepmind не вернулся к первоначальным более жёстким, более гуманным ограничениям на APM? Наверняка они поняли, что ИИ демонстрирует сверхчеловеческие способности. Сообщество Starcraft почти единодушно признало нечеловеческий микроменеджмент AlphaStar. Профи сказали в AMA, что главная сила AlphaStar — контроль над юнитамии, а основная слабость — стратегическое мышление. Должно быть, разработчики Deepmind пришли к тому же выводу. Вероятно, причина в том, что агент не смог избавиться от спам-кликов. Хотя большую часть времени он действует чётко, но всё равно регулярно сваливается в спам-клики. Это очевидно в первой игре против MaNa, когда Alphastar поднимается вверх по рампе (с 39:30):
Внимательно смотрите на синие кружки с выделением юнитов
Агент спам-кликал команды на перемещение юнитов со скоростью 800 APM. Он так и не отучился полностью от человеческих глупостей, хотя эти действия совершенно бесполезны и съедают его лимит APM. Баг особенно опасен во время больших сражений. Вероятно, лимит APM подняли, чтобы исправить косяк и позволить агенту нормально работать в такие моменты.
Подозреваю, что агент не смог избавиться от спам-кликов, которые усвоил во время имитационного обучения на людях. Deepmind пришлось повозиться с лимитом APM, чтобы стали возможными эксперименты и дальнейший прогресс. Однако проявился неприятный побочный эффект сверхчеловеческой игры, из-за которой по сути агент нарушает правила, будучи в состоянии реализовать стратегии, которые ему изначально запретили.
Это важная вещь, потому что подобное избиение профессионалов прямо противоречит миссии, которую неоднократно заявляла Deepmind. Из-за чего этот график оставляет во рту кислый привкус лицемерия:
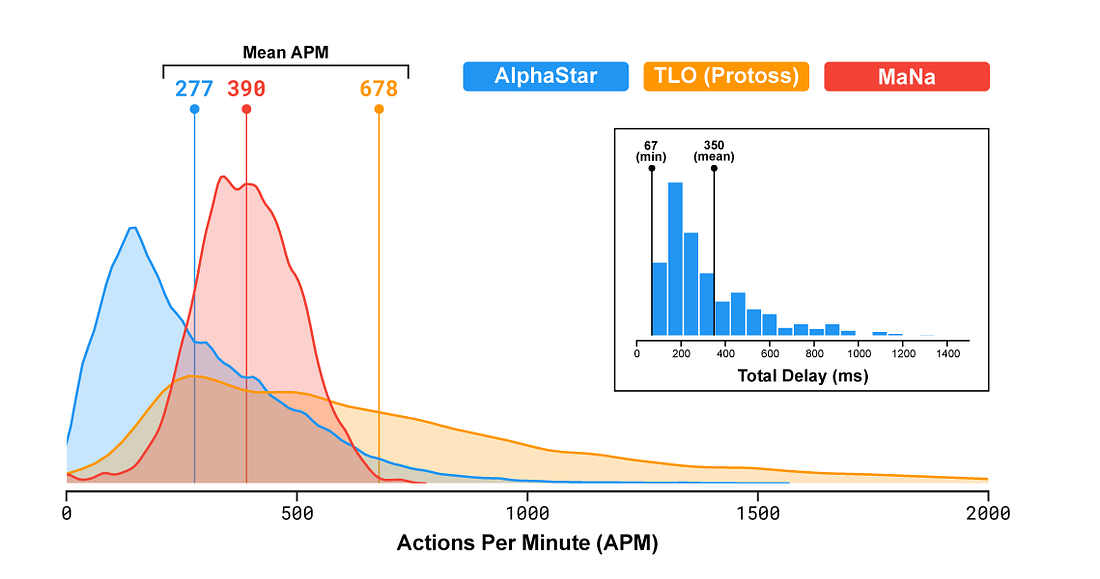
Это изображение Deepmind опубликовала в своём блоге
Похоже, график рассчитан на то, чтобы ввести в заблуждение людей, незнакомых со Starcraft 2. Он изображает якобы приемлемый APM у AlphaStar. Посмотрите на APM MaNa и сравните его с AlphaStar. Хотя среднее значение выше у MaNa, хвост AlphaStar выходит далеко за пределы человеческих возможностей. Обратите внимание, что пиковый APM у MaNa составляет около 750, в то время как у AlphaStar выше 1500. Теперь учтите, что у человека APM более чем наполовину состоит из спам-кликов, а EPM AlphaStar — это идеально точные нажатия.
Теперь взгляните на APM у TLO. Хвост уходит на 2000. Подумайте об этом на секунду. Как такое возможно? Это стало возможным благодаря трюку под названием «быстрый огонь». TLO не щёлкает супербыстро. Он просто держит кнопку — и игра регистрирует это как 2000 APM. Единственное, что вы можете сделать с быстрым огнём — это спамить с сумасшедшей скоростью. Вот и всё. TLO просто использует это по какой-то причине. Но при этом маскируются сверхчеловеческие всплески APM у AlphaStar — и цифры выглядят реалистично для людей, которые не знакомы со Starcraft.
Сообщение в блоге Deepmind не пытается объяснить абсурдные цифры TLO. Если они не объясняют дутые показатели TLO, то не должны включать их в график. Точка.
Такая статистика опасно приближается к вранью. Deepmind следовало бы придерживаться более высоких стандартов.
Постараюсь убедительно доказать следующее:
- AlphaStar играл со сверхчеловеческой скоростью и точностью.
- Deepmind утверждает, что запретила ИИ выполнять действия, которые физически невозможны для человека. Разработчики не преуспели в этом и, вероятно, знают о своём косяке.
- Причина, по которой AlphaStar играет на сверхчеловеческих скоростях, скорее всего, связана с его неспособностью избавиться от приобретённого навыка спам-кликов. Подозреваю, что разработчики хотели сделать программу более гуманной, но не смогли. Потребуется время, чтобы подойти к данному тезису. Но это главная причина, почему я написал статью, так что прошу проявить терпение.
Прежде всего хочу уточнить, что я непрофессионал. Я много лет следил за развитием ИИ и сценой Starcraft 2, но не претендую на роль эксперта. Если вы заметите какие-то заблуждения, пожалуйста, укажите на них. Я всего лишь фанат и всё это невероятно увлекательно для меня. В статье много спекуляций, и я признаю, что не могу окончательно доказать основные претензии. Со всеми оговорками, если вы прочитаете статью и не согласитесь со мной, пожалуйста, аргументируйте конструктивно. Очень хочу, чтобы вы меня разубедили.
В конце концов, AlphaStar — удивительное достижение. На мой взгляд, величайшее достижение Deepmind на сегодняшний день, и я с нетерпением жду, как ещё усовершенствуют эту программу. Спасибо за ваше терпение. Итак, поехали.
Сверхчеловеческая скорость AlphaStar
Дэвид Сильвер, соруководитель команды AlphaStar: «AlphaStar не может реагировать быстрее и не может сделать больше кликов, чем живой игрок».
Здесь ведущий проектировщик ИИ делает важное заявление (с 1:39)
В 2018 году на сцене Starcraft 2 доминировал Serral. Он действующий чемпион мира и выиграл семь из девяти крупных турниров, в которых участвовал, что привело к одному их самых мощных примеров доминирования одного игрока в истории Starcraft 2. Парень очень быстрый. Возможно, самый быстрый в мире.
Вид от первого лица (с 13:00):
Взгляните на его APM в левом верхнем углу. Это сокращение для количества действий в минуту. По сути это число отражает, как быстро игрок нажимает на кнопки мыши и клавиатуры. Ни разу Serral не может надолго удержать APM более 500. Есть один всплеск до APM 800, но только на долю секунды и, скорее всего, в результате спам-кликов, о которых я скоро расскажу.
Итак, самый быстрый в мире игрок способен удержать впечатляющий уровень APM 500, но у AlphaStar были всплески до 1500+. Эти нечеловеческие показатели более APM 1000 иногда длились пять секунд и полны осмысленных действий. 1500 действий в минуту — это 25 действий в секунду. Это физически невозможно для человека. Также прошу учесть, что в игре Starcraft пять секунд — большой срок, особенно в самом начале большого сражения. Если сверхчеловеческий показатель в первые пять секунд даёт ИИ преимущество, то он легко выиграет сражение благодаря эффекту снежного кома. Вот завязка битвы AlphaStar в третьей игре против MaNa (с 59:30):
AlphaStar удерживает APM 1000+ в течение пяти секунд. Ещё одна завязка в четвёртой игре с заоблачным APM 1500+ (c 2:11:32):
Один из комментаторов указывает на приемлемый показатель среднего APM. Но совершенно очевидно, что указанные всплески намного выше человеческих способностей.
Спам-клики, APM и хирургическая точность роботов
Большинство игроков проявляет склонность к спам-кликам. Бессмысленные клики, которые ни на что не влияют. Например, человек перемещает армию и зачем-то щёлкает несколько раз в точке назначения. Какой эффект? Никакого. Армия не пойдёт быстрее. Одного клика было достаточно. Тогда зачем он это делает? Есть две причины:
- Спам-клик — естественный побочный эффект, когда человек старается кликнуть как можно быстрее.
- Помогает разогреть пальцы.
Помните, Serral'а? Его впечатляющая мощь на самом деле не в скорости нажатий, а в точности. У него не только действительно высокий APM, но и потрясающе эффективный (общее количество кликов в минуту, кроме спам-кликов). С этого момента я буду сокращать эффективный APM как EPM. Важно помнить, что EPM учитывает только значимые действия.
Взгляните, как бывший профессионал потерял рассудок в твиттере, узнав EPM Serral'а:
Его EPM 344 — практически нереальный показатель. Он настолько высок, что мне до сих пор трудно поверить, что это правда. Разница между APM и EPM повлияла также на AlphaStar. Если ИИ может играть без спам-кликов, не означает ли это, что его пиковый EPM временами равен пиковому APM? Это делает всплески до 1000+ еще более нечеловеческими. Когда мы принимаем во внимание, что AlphaStar играет с идеальной точностью, то его механические возможности кажутся совершенно абсурдными. Он всегда нажимает именно там, где он хочет нажать. Люди промахиваются, а AlphaStar в нужные моменты начинает работать в четыре раза быстрее, чем самый быстрый игрок в мире — с точностью, о которой человек может только мечтать.
Практически все в сообществе согласны, что AlphaStar выполнял последовательности, которые ни один человек не способен повторить. Он был быстрее и точнее, чем это возможно физически. Самый быстрый в мире профессионал действует в несколько раз медленнее. Точность невозможно даже сравнить.
Утверждение Дэвида Сильвера, что AlphaStar может выполнять только действия, которые способен воспроизвести человек, просто не соответствует действительности.
Делать всё правильно или просто включить скорость?
Ориол Виньялс, ведущий архитектор AlphaStar: «Важно осваивать игры, признанные «фундаментальными проблемами для ИИ». Мы пытаемся создать интеллектуальные системы, которые перенимают наши удивительные возможности, поэтому очень важно, чтобы они обучались максимально „по-человечески”. Как бы круто ни звучало, но достижение максимальных показателей в игре, вроде очень высоких APM, на самом деле не помогает нам измерить возможности и прогресс наших агентов, что делает бенчмарк бесполезным».
Почему Deepmind хочет ограничить агента, чтобы он играл как человек? Почему бы просто не пустить его во все тяжкие без каких-либо ограничений? Причина в том, что в Starcraft 2 механические суперспособности портят геймплей. В этом видео бот несколькими зерглингами атакует группу танков, реализуя идеальную микротактику. Обычно зерглинги почти ничего не могут сделать против танков, но благодаря роботам микротактика становится гораздо более смертоносной: они уничтожают танки с минимальными потерями. С таким хорошим управлением юнитами ИИ не нужно изучать стратегию. Deepmind ведь не заинтересован в создании ИИ, который просто побеждает профессионалов Starcraft, на самом деле они хотят использовать этот проект в качестве ступеньки в продвижении общих исследований ИИ. Очень грустно, что один из руководителей проекта заявляет об ограничениях наравне с человеческими способностями, когда агент явно их нарушает и выигрывает свои игры именно благодаря сверхчеловеческому исполнению.
AlphaStar превосходит людей в управлением юнитами — этот фактор не был принят во внимание, когда разработчики тщательно балансировали игру. Этот нечеловеческий контроль способен испортить любое стратегическое мышление, которое освоил ИИ. Он даже может сделать стратегическое мышление совершенно ненужным. Программа не просто застряла на локальном максимуме. Если игра ведётся с нечеловеческой скоростью и точностью, то злоупотребление идеальным контролем юнитов, скорее всего, будет лучшим, наиболее эффективным и надёжным способом выиграть. Как бы грустно это не звучало.
Вот что сказал о сильных и слабых сторонах AlphaStar один из профессионалов, проиграв ему со счётом 1-5:
MaNa: «Я бы сказал, что его лучшее качество — это управление юнитами. Во всех играх с примерно одинаковым количеством юнитов победил AlphaStar. Худший аспект по итогу небольшого количества игр — упрямый отказ апгрейдиться. Он был настолько убеждён в победе базовыми юнитами, что практически ничего не апгрейдил, за что в итоге поплатился в выставочном матче [последняя игра с MaNa, где ИИ проиграл — прим. пер.]. В принятии решений было не так много решающих моментов, поэтому я бы сказал, что причиной победы стала механика».
Среди поклонников Starcraft почти единодушное мнение, что AlphaStar выиграл почти исключительно из-за своей сверхчеловеческой скорости, времени реакции и точности. Профи, которые играли против него, похоже, согласны с этим. Один из сотрудников Deepmind играл против AlphaStar, прежде чем программу поставили против профессионалов. Скорее всего, он тоже согласится с такой оценкой. Дэвид Сильвер и Ориол Виньялс повторяют мантру, что AlphaStar способен делать только то, что и человек, но мы уже видели, что это просто не так.
Непохоже, что AlphaStar «делает всё правильно», как говорит Дэвид (с 1:38):
Что-то здесь явно не так.
Почему Deepmind допустила сверхчеловеческую скорость AlphaStar?
Наконец, перейдём к главному. Спасибо, что дочитали до этого места. Но сначала подведём итоги.
- Мы знаем, что такое APM, EPM и спам-клики.
- У нас есть некоторое понимание максимальных возможностей человека.
- Игра AlphaStar прямо противоречит утверждениям разработчиков о его ограничениях.
- Сообщество Starcraft 2 сошлось во мнении, что AlphaStar выиграл благодаря нечеловеческому контролю юнитов и даже не нуждался в превосходном стратегическом мышлении.
- Deepmind не ставит задачу создать быстрого бота, поэтому он не должен был так играть.
- Очень маловероятно, что никто из команды Starcraft AI не подумал, что человек не способен повторить всплески APM 1500+. Их спец по Starcraft должен знать о Starcraft побольше моего. Они тесно сотрудничают с Blizzard, которая владеет интеллектуальной собственностью на StarCraft. В их интересах (см. предыдущий пункт, а также заявления Сильвера и Виньялса) заставить бота действовать как можно ближе к человеку.
Принимая во внимание все эти моменты, почему Deepmind вообще позволил ИИ явно обойти ограничения человеческого тела?
Это чистая спекуляция с моей стороны и я не утверждаю, что знаю точно историю. Но подозреваю, что произошло следующее:
В самом начале проекта Deepmind согласовала жёсткие лимиты. В этот момент AlphaStar запретили сверхчеловеческие всплески APM, которые мы видели в демонстрации. Если бы я проектировал систему, то установил бы такие ограничения:
- Максимальный средний APM на протяжении всей игры.
- Максимальный кратковременный всплеск APM. Думаю, что разумно установить его на уровне 4-6 кликов в секунду. Помните Serral'а и его EPM 344, что на голову выше конкурентов? Это меньше шести кликов в секунду. Против MaNa программа выдавала 25 кликов в секунду в течение длительных периодов времени. Это намного быстрее, чем даже самые быстрые спам-клики человека, так что вряд ли исходные ограничения разрешали такое.
- Минимальное время между кликами. Даже если ограничить максимальную скорость во время всплесков, бот может очень быстро кликать в краткий момент во время разрешённого интервала, на что не способен человек.
Некоторые предлагают добавить элемент случайности в точность кликов, но я подозреваю, что это слишком снизит скорость обучения.
Итак, установили лимиты. Что дальше? Затем Deepmind запустил имитационное обучение на тысячах видеозаписей любительских игр высокого класса. На данном этапе агент просто пытается имитировать то, что делают люди — и он осваивает спам-клики. Это весьма вероятно, потому что люди очень часто их делают. Это почти самая повторяющаяся модель поведения у людей, поэтому она должна очень глубоко укорениться в поведении агента.
Максимальные всплески APM у AlphaStar изначально близки к установленным лимитам. Но большинство кликов AlphaStar оказались спам-кликами, так что его APM оказался недостаточным для нормального боя. Но без экспериментов нет обучения. Вот что сказал один из разработчиков во вчерашнем AMA: думаю, он немного замазан в этой афере:
Ориол Виньялс, ведущий архитектор AlphaStar: «Обучать ИИ играть с низким APM довольно интересно. В первые дни наши агенты обучались с очень низкими APM и оказались вообще не способны к микроменеджменту».
Чтобы ускорить обучение, разработчики повышают лимиты APM, разрешив кратковременные всплески. Вот ограничения APM, которые действовали для AlphaStar в демонстрационном матче:
Ориол Виньялс: «В частности, мы установили лимит 600 APM в интервалах 5 секунд, 400 APM в интервалах 15 секунд, 320 на 30 секунд и 300 на 60 секунд. Если агент выдаёт больше действий в эти интервалы, мы их отбрасываем/игнорируем. Эти значения взяты из человеческой статистики».
Если вы не очень хорошо знакомы со Starcraft, то такие лимиты выглядят разумными, однако они допускают сверхчеловеческие всплески APM, о которых мы говорили ранее, а также сверхчеловеческую точность.
Существует ограничение на максимальное количество спам-кликов. Обычно это команды перемещения или атаки, когда совершается щелчок по карте. Попробуйте, насколько быстро вы сможете нажимать кнопку мыши. Агент обучился спам-кликам у игроков и не будет щёлкать быстрее человека. То есть дополнительные клики APM на сверхчеловеческой скорости являются «произвольными» для экспериментов.
Произвольный APM используется для экспериментов в битвах. Такое взаимодействие часто происходит во время тренировки. AlphaStar начинает изучать новый тип поведения, который приводит к лучшим результатам, и доля спама в кликах снижается.
Если агент усвоил полезные действия, почему Deepmind не вернулся к первоначальным более жёстким, более гуманным ограничениям на APM? Наверняка они поняли, что ИИ демонстрирует сверхчеловеческие способности. Сообщество Starcraft почти единодушно признало нечеловеческий микроменеджмент AlphaStar. Профи сказали в AMA, что главная сила AlphaStar — контроль над юнитамии, а основная слабость — стратегическое мышление. Должно быть, разработчики Deepmind пришли к тому же выводу. Вероятно, причина в том, что агент не смог избавиться от спам-кликов. Хотя большую часть времени он действует чётко, но всё равно регулярно сваливается в спам-клики. Это очевидно в первой игре против MaNa, когда Alphastar поднимается вверх по рампе (с 39:30):
Внимательно смотрите на синие кружки с выделением юнитов
Агент спам-кликал команды на перемещение юнитов со скоростью 800 APM. Он так и не отучился полностью от человеческих глупостей, хотя эти действия совершенно бесполезны и съедают его лимит APM. Баг особенно опасен во время больших сражений. Вероятно, лимит APM подняли, чтобы исправить косяк и позволить агенту нормально работать в такие моменты.
Что в этом такого важного?
Подозреваю, что агент не смог избавиться от спам-кликов, которые усвоил во время имитационного обучения на людях. Deepmind пришлось повозиться с лимитом APM, чтобы стали возможными эксперименты и дальнейший прогресс. Однако проявился неприятный побочный эффект сверхчеловеческой игры, из-за которой по сути агент нарушает правила, будучи в состоянии реализовать стратегии, которые ему изначально запретили.
Это важная вещь, потому что подобное избиение профессионалов прямо противоречит миссии, которую неоднократно заявляла Deepmind. Из-за чего этот график оставляет во рту кислый привкус лицемерия:
Это изображение Deepmind опубликовала в своём блоге
Похоже, график рассчитан на то, чтобы ввести в заблуждение людей, незнакомых со Starcraft 2. Он изображает якобы приемлемый APM у AlphaStar. Посмотрите на APM MaNa и сравните его с AlphaStar. Хотя среднее значение выше у MaNa, хвост AlphaStar выходит далеко за пределы человеческих возможностей. Обратите внимание, что пиковый APM у MaNa составляет около 750, в то время как у AlphaStar выше 1500. Теперь учтите, что у человека APM более чем наполовину состоит из спам-кликов, а EPM AlphaStar — это идеально точные нажатия.
Теперь взгляните на APM у TLO. Хвост уходит на 2000. Подумайте об этом на секунду. Как такое возможно? Это стало возможным благодаря трюку под названием «быстрый огонь». TLO не щёлкает супербыстро. Он просто держит кнопку — и игра регистрирует это как 2000 APM. Единственное, что вы можете сделать с быстрым огнём — это спамить с сумасшедшей скоростью. Вот и всё. TLO просто использует это по какой-то причине. Но при этом маскируются сверхчеловеческие всплески APM у AlphaStar — и цифры выглядят реалистично для людей, которые не знакомы со Starcraft.
Сообщение в блоге Deepmind не пытается объяснить абсурдные цифры TLO. Если они не объясняют дутые показатели TLO, то не должны включать их в график. Точка.
Такая статистика опасно приближается к вранью. Deepmind следовало бы придерживаться более высоких стандартов.

