У вас бывало, что вы залипаете в какую-то простенькую игру, думая, что с ней вполне бы мог справиться искусственный интеллект? У меня бывало, и я решил попробовать создать такого бота-игрока. Тем более, сейчас много инструментов для компьютерного зрения и машинного обучения, которые позволяют строить модели без глубокого понимания подробностей реализации. «Простые смертные» могут сделать прототип, не строя нейронные сети месяцами с нуля.

Под катом вы найдете процесс создания proof-of-concept бота для игры Clash Royale, в котором я использовал Scala, Python и CV-библиотеки. Используя компьютерное зрение и машинное обучение я попытался создать бота для игры, который взаимодействует как живой игрок.
Меня зовут Сергей Толмачев, я Lead Scala Developer в Waves Platform и преподаю курс по Scala в Binary District, а в свободное время занимаюсь изучением других технологий, таких как AI. А полученные навыки хотелось подкрепить каким-то практическим опытом. В отличие соревнований по AI, где ваш бот играет против ботов других пользователей, в Clash Royale можно играть против людей, что звучит забавно. Ваш бот может научиться обыгрывать настоящих игроков!
Механика у игры достаточно простая. У вас и вашего противника есть три здания: крепость и две башни. Игроки до игры собирают колоды — 8 доступных юнитов, которые затем используются в бою. Они имеют разные уровни, и их можно прокачивать, собирая больше карт этих юнитов и покупая обновления.
После начала игры можно ставить доступных юнитов на безопасном расстоянии от вражеских башен, тратя при этом единицы маны, которые медленно восстанавливаются по ходу игры. Юниты направляются на вражеские здания и отвлекаются на встречающихся по пути врагов. Игрок может управлять только начальным положением юнитов — на их дальнейшее перемещение и урон он может влиять только установкой других юнитов.
Еще есть заклинания, которыми можно сыграть в любой точке поля, обычно они наносят урон юнитам разными способами. Заклинания могут клонировать, заморозить или ускорить юнитов в какой-то области.
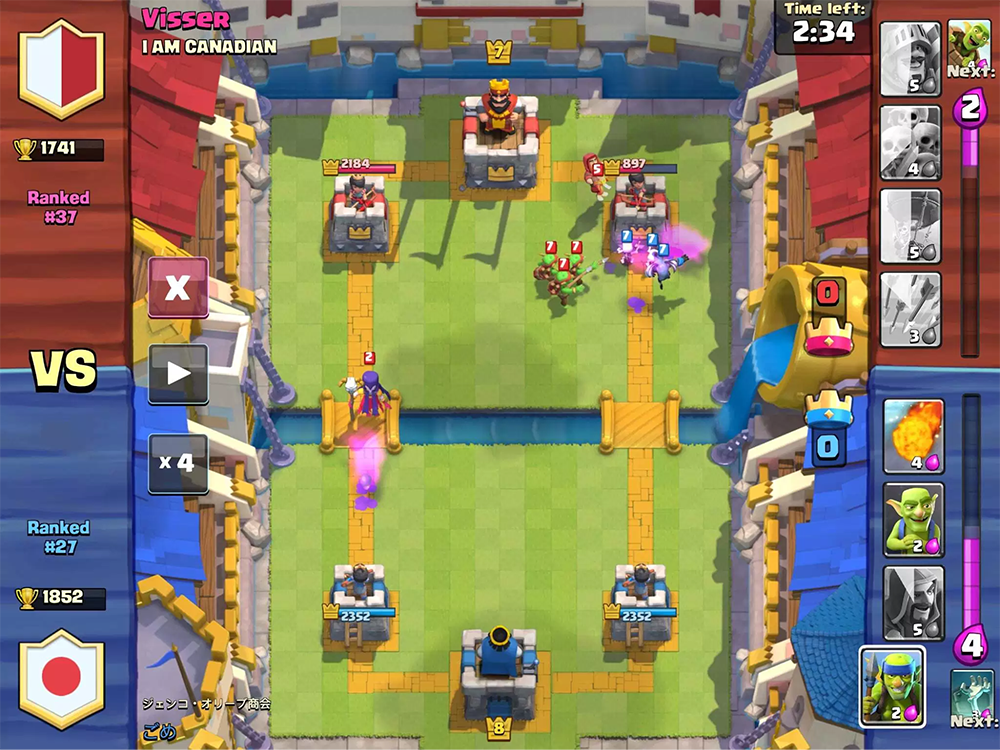
Цель игры — уничтожить здания противника. Для полной победы надо разрушить крепость или после двух минут игры уничтожить больше строений (правила зависят от игровых режимов, но в целом звучат так).
Во время игры нужно принимать во внимание перемещения юнитов, возможное число маны и текущие карты противника. Также нужно учитывать, как влияет установка юнита на игровое поле.
Clash Royale — мобильная игра, поэтому я решил запускать ее на Android и взаимодействовать с ней через ADB. Это позволило бы поддержать работу с симулятором или с реальным устройством.
Я решил, что бот, как и многие другие игровые ИИ, должен работать по алгоритму Восприятие-Анализ-Действие. Все окружение в игре отображается на экране, а взаимодействие с ним происходит с помощью нажатий на экран. Поэтому бот должен представлять из себя программу, на вход которой подается описание текущего состояния в игре: расположение и характеристики юнитов и зданий, текущие возможные карты и объем маны. На выходе бот должен отдавать массив координат, куда надо тапнуть юнита.
Но до создания самого бота нужно было решить проблему извлечения информации о текущем состоянии в игре из скриншота. По большому счету, этой задаче и посвящено дальнейшее содержание статьи.
Для решения этой проблемы я решил применить Computer Vision. Возможно, это не лучшее решение: CV без большого опыта и ресурсов явно имеет ограничения и не может распознавать все на уровне человека.
Точнее было бы брать данные из памяти, однако такого опыта у меня не было. Требуется Root и в целом такое решение выглядит сложнее. Также неясно, можно ли добиться здесь скорости около real time, если искать объекты с heap JVM внутри устройства. К тому же задачу CV мне хотелось решать больше, чем эту.
В теории можно было бы сделать прокси-сервер и брать информацию оттуда. Но сетевой протокол игры часто меняется, прокси-сервера в интернете попадаются, но быстро устаревают и не поддерживаются.
Для начала я решил ознакомиться с доступными материалами из игры. Я нашел клуб умельцев, достающих запакованные игровые ресурсы [1] [2]. В первую очередь меня интересовали картинки юнитов, но в распакованном игровом пакете они представлены в виде карты тайлов (кусочков, из которых состоит юнит).
Также я нашел склеенные (хоть и не идеально) с помощью скрипта кадры анимаций юнитов — они пригодились для обучения модели распознавания.

Кроме того, в ресурсах можно найти csv с различными игровыми данными — количество HP, урон юнитов разного уровня и т. п. Это полезно при создании логики бота. Например, из данных стало точно понятно, что поле поделено на 18 x 29 клеток, и ставить юнитов можно только на них. Еще там были все изображения карт юнитов, которые пригодятся нам позже.
После поиска доступных CV-решений стало понятно, что обучать их в любом случае придется на размеченном датасете. Я наделал скриншотов экрана и уже был готов разметить какое-то количество скриншотов руками. Это оказалось непростой задачей.
Поиск доступных программ для распознавания занял какое-то время. Я остановился на labelImg. Все найденные мной приложения для аннотирования были достаточно примитивны: многие не поддерживали комбинации клавиш, выбор объектов и их типов был сделан намного менее удобно, чем в labelImg.
Во время разметки оказалось полезным иметь исходный код приложения. Я делал скриншоты каждую пару секунд матча. На скриншотах бывает много объектов (например, армия скелетов), и я сделал модификацию в labelImg — по умолчанию при разметке следующего изображения брались метки из предыдущего. Часто их нужно было просто подвинуть под новое положение юнитов, удалить умерших юнитов и добавить несколько появившихся, а не размечать с нуля.

Процесс оказался ресурсоемким — за два дня в спокойном режиме я разметил около 200 скриншотов. Выборка выглядит совсем небольшой, но я решил начать экспериментировать. Всегда можно добавить больше примеров и улучшить качество модели.
На момент разметки я не знал, какой инструмент обучения буду использовать, поэтому решил сохранить результаты разметки в формате VOC — одном из консервативных и на вид универсальных.
Может возникнуть вопрос: почему просто не искать попиксельно изображения юнитов по полному совпадению? Проблема в том, что для этого пришлось бы искать огромное количество различных кадров анимации разных юнитов. Вряд ли это бы сработало. Мне хотелось сделать универсальное решение, поддерживающее разные разрешения. Кроме того, юниты могут иметь разный окрас в зависимости от применяемого к ним эффекта — заморозка, ускорение.
Я начал исследовать возможные решения распознавания изображений. Посмотрел на применение различных алгоритмов: OpenCV, TensorFlow, Torch. Хотелось сделать распознавание как можно более быстрым, даже пожертвовав точностью, и получить POC как можно скорее.
Почитав статьи, я понял, что моя задача не вяжется с HOG/LBP/SVM/HAAR/… классификаторами. Хоть они и быстрые, но пришлось бы их применять очень много раз — по классификатору на каждого юнита — и потом по одному применять их к картинке для поиска. К тому же их принцип работы в теории давал бы плохие результаты: у юнитов может быть разная форма, например, при перемещении влево и вверх.
Теоретически, используя нейронную сеть, можно применить ее один раз к изображению и получить всех юнитов разных типов с их положением, поэтому я стал копать в сторону нейронных сетей. В TensorFlow нашлась поддержка Convolutional Neural Networks (CNN). Оказалось, что не обязательно обучать нейронные сети с нуля — можно переобучить уже имеющуюся мощную сеть.
Затем я нашел более практичный алгоритм YOLO, который обещает меньшую сложность и, следовательно, должен был обеспечивать высокую скорость алгоритма поиска, не сильно жертвуя точностью (а в некоторых случаях и превосходя другие модели).
На сайте YOLO обещают громадную разницу в скорости, используя модель «tiny» и меньшую оптимизированную сеть. YOLO также позволяет переобучить готовую нейронную сеть под свою задачу, причем darknet — opensource-фреймворк для использования различных нейронок, создатели которого разработали YOLO — является простым нативным приложением на C, и вся работа с ним происходит через его вызовы с параметрами.
TensorFlow, написанный на Python, является по факту Python-библиотекой и применяется с использованием самописных скриптов, в которых надо разобраться или подточить их под свои нужды. Вероятно, для кого-то гибкость TensorFlow — это плюс, но, не вникая в подробности, вряд ли можно быстро взять его и использовать. Поэтому в моем проекте выбор пал на YOLO.
Для работы над обучением модели я установил Ubuntu 18.10, доставил пакеты для сборки, пакет OpenCL от NVIDIA и другие зависимости, собрал darknet.
На Github есть раздел с простыми шагами по переобучению модели YOLO: нужно скачать модель и конфиги, поменять их и запустить переобучение.
Сначала я хотел попробовать переобучить простую YOLO-модель, потом Tiny и сравнить их. Однако оказалось, что для обучения простых моделей нужно 4 ГБ памяти видеокарты, а у меня была только купленная для игр видеокарта NVIDIA GeForce GTX 1060 с 3 ГБ. Поэтому я смог сразу обучать только Tiny-модель.
Разметка юнитов на изображениях у меня была в формате VOC, а YOLO работал со своим форматом, поэтому я использовал утилиту convert2Yolo для преобразования файлов аннотаций.
После ночи обучения на моих 200 скриншотах я получил первые результаты, и они меня удивили — модель действительно смогла кое-что распознать правильно! Я понял, что двигаюсь в верном направлении, и решил сделать больше обучающих примеров.

Продолжать размечать скриншоты мне не хотелось, и я вспомнил про кадры из анимаций юнитов. Я разметил все маленькие картинки их классами и попробовал обучить сеть на этом наборе. Результат был совсем плохим. Предполагаю, что модель не могла выделить правильные паттерны из маленьких картинок для использования на больших изображениях.
После этого я решил разместить их на готовые фоны боевых арен и программно создать файл разметки VOC. Получался такой синтетический скриншот с автоматической 100% точной разметкой.
Я написал скрипт на Scala, который делит скриншот на 16 квадратов 4x4 и устанавливает в их центр юнитов, чтобы они не пересекались друг с другом. Скрипт также позволил мне кастомизировать создание обучающих примеров — при получении урона юниты окрашиваются в цвет их команды (красный/синий), и при классификации я отдельно распознаю юниты разных цветов. Помимо окрашивания, получившие урон юниты разных команд имеют небольшие различия в одежде. Также я случайным образом немного увеличивал и уменьшал юнитов, чтобы модель научилась не сильно зависеть от размера юнита. В итоге я научился создавать десятки тысяч обучающих примеров, приблизительно похожих на реальные скриншоты.

Генерация была не идеальной. Часто юниты ставились поверх зданий, хотя в игре они были бы за ними; не было примеров перекрытия части юнита, хотя в игре это нередкая ситуация. Но всем этим я пока решил пренебречь.

Модель, полученная после нескольких ночей обучения на смеси из 200 реальных скриншотов и 5000 сгенерированных изображений, которые пересоздавались в процессе обучения раз в день, при проверке на настоящих скриншотах давала плохие результаты. Неудивительно, ведь сгенерированные картинки имеют достаточно много отличий от настоящих.
Поэтому полученную модель я поставил дообучаться на скупой выборке, в которой было только 200 моих скриншотов. После этого она стала работать гораздо лучше.
Бота я решил писать на Python — у него есть много доступных инструментов для ML. Свою модель я решил использовать с OpenCV, который с 3.5 научился использовать модели нейронных сетей, и я даже нашел простой пример. Попробовав несколько библиотек для работы с ADB, я выбрал pure-python-adb — там просто реализовано все, что мне надо: функция получения экрана 'screencap' и выполнение операции на устройстве 'shell'; тапаю я, используя 'input tap'.
Итак, получив скриншот игры, распознав на нем юнитов и потыкав на экран, я продолжил работать над распознаванием игрового состояния. Кроме юнитов, мне нужно было сделать распознавание текущего уровня маны и доступных игроку карт.
Уровень маны в игре отображается в виде прогресс-бара и цифры. Недолго думая, я стал вырезать цифру, инвертировать и распознавать с помощью pytesseract.
Для определения доступных карт и их положения я использовал keypoint detector KAZE из OpenCV. Мне пока не хотелось снова возвращаться к обучению нейронной сети, и я выбрал способ, который был быстрее и проще, хоть у него в итоге и оказалась минимально достаточная точность в случае, когда нужно искать много объектов.
При запуске бота я считал keypoints для всех картинок карт (всего их несколько десятков), а во время игры искал совпадения всех карт с областью карт игрока для уменьшения количества ошибок и увеличения скорости. Их сортировка происходила по точности и по координате x для получения порядка карт — информации о том, как они располагаются на экране.
Немного поигравшись с параметрами, на практике я получил много ошибок, хотя какие-то сложные картинки карт, которые иногда алгоритмом ошибочно принимались за другие, распознавались с большой точностью. Пришлось добавить буфер из трех элементов: если три распознавания подряд мы получаем одни и те же значения, то условно считаем, что мы можем им доверять.

После получения всей необходимой информации (юниты и их примерное положение, доступная мана и карты) можно принимать какие-то решения.
Для начала я решил взять что-то простое: например, если хватает маны на доступную карту, сыграть ею на поле. Но бот еще не умеет «играть» карты — он знает, какие у нас карты, где поле, надо нажать на нужную карту, а затем на нужную клетку на поле.
Зная разрешение скриншота, можно понять координаты карты и нужной клетки поля. Сейчас я завязался на точное разрешение экрана, но при необходимости от этого можно абстрагироваться. Функция принятия решения будет возвращать массив нажатий, которые нужно сделать в ближайшее время. В общем виде наш бот будет являться бесконечным циклом (упрощенно):
Пока бот умеет только ставить юнитов в одну точку, но уже имеет достаточно информации, чтобы построить более сложную стратегию.
В реальности я столкнулся с неожиданной и очень неприятной проблемой. Создание скриншота через ADB занимает около 100 мс, что вносит значительную задержку — я рассчитывал на такую максимальную задержку, учитывая все расчеты и выбор действия, но не на одном шаге создания скриншота. Простого и быстрого решения найти не удалось. В теории, используя эмулятор Android, можно снимать скриншоты прямо с окна приложения, или можно сделать утилиту для стриминга изображения с телефона со сжатием через UDP и подключиться ботом к ней, но быстрых решений тут я тоже не нашел.
Трезво оценив состояние моего проекта, на этой модели я решил пока остановиться. Я потратил на это несколько недель своего свободного времени, а ведь распознавание юнитов — это только часть игрового процесса.
Я решил развивать части бота постепенно — сделать базовую логику восприятия, затем простую логику игры и взаимодействия с игрой, а потом уже можно будет улучшать отдельные проседающие части бота. Когда уровень модели распознавания юнитов станет достаточным, добавление информации о HP и уровне юнитов может вывести развитие игрового бота на качественно новый этап. Возможно, это станет следующей целью, но сейчас точно не стоит зацикливаться на этой задаче.
Репозиторий проекта на Github
Я потратил на проект достаточно много времени и, честно говоря, устал от него, но ни капли не жалею — я получил новый опыт в ML/CV.
Может быть, я вернусь к нему позже — буду рад, если кто-то присоединится ко мне. Если вам это интересно, вступайте в группу в Telegram, а также приходите на мой курс по Scala.
Под катом вы найдете процесс создания proof-of-concept бота для игры Clash Royale, в котором я использовал Scala, Python и CV-библиотеки. Используя компьютерное зрение и машинное обучение я попытался создать бота для игры, который взаимодействует как живой игрок.
Меня зовут Сергей Толмачев, я Lead Scala Developer в Waves Platform и преподаю курс по Scala в Binary District, а в свободное время занимаюсь изучением других технологий, таких как AI. А полученные навыки хотелось подкрепить каким-то практическим опытом. В отличие соревнований по AI, где ваш бот играет против ботов других пользователей, в Clash Royale можно играть против людей, что звучит забавно. Ваш бот может научиться обыгрывать настоящих игроков!
Игровая механика в Clash Royale
Механика у игры достаточно простая. У вас и вашего противника есть три здания: крепость и две башни. Игроки до игры собирают колоды — 8 доступных юнитов, которые затем используются в бою. Они имеют разные уровни, и их можно прокачивать, собирая больше карт этих юнитов и покупая обновления.
После начала игры можно ставить доступных юнитов на безопасном расстоянии от вражеских башен, тратя при этом единицы маны, которые медленно восстанавливаются по ходу игры. Юниты направляются на вражеские здания и отвлекаются на встречающихся по пути врагов. Игрок может управлять только начальным положением юнитов — на их дальнейшее перемещение и урон он может влиять только установкой других юнитов.
Еще есть заклинания, которыми можно сыграть в любой точке поля, обычно они наносят урон юнитам разными способами. Заклинания могут клонировать, заморозить или ускорить юнитов в какой-то области.
Цель игры — уничтожить здания противника. Для полной победы надо разрушить крепость или после двух минут игры уничтожить больше строений (правила зависят от игровых режимов, но в целом звучат так).
Во время игры нужно принимать во внимание перемещения юнитов, возможное число маны и текущие карты противника. Также нужно учитывать, как влияет установка юнита на игровое поле.
Строим решение
Clash Royale — мобильная игра, поэтому я решил запускать ее на Android и взаимодействовать с ней через ADB. Это позволило бы поддержать работу с симулятором или с реальным устройством.
Я решил, что бот, как и многие другие игровые ИИ, должен работать по алгоритму Восприятие-Анализ-Действие. Все окружение в игре отображается на экране, а взаимодействие с ним происходит с помощью нажатий на экран. Поэтому бот должен представлять из себя программу, на вход которой подается описание текущего состояния в игре: расположение и характеристики юнитов и зданий, текущие возможные карты и объем маны. На выходе бот должен отдавать массив координат, куда надо тапнуть юнита.
Но до создания самого бота нужно было решить проблему извлечения информации о текущем состоянии в игре из скриншота. По большому счету, этой задаче и посвящено дальнейшее содержание статьи.
Для решения этой проблемы я решил применить Computer Vision. Возможно, это не лучшее решение: CV без большого опыта и ресурсов явно имеет ограничения и не может распознавать все на уровне человека.
Точнее было бы брать данные из памяти, однако такого опыта у меня не было. Требуется Root и в целом такое решение выглядит сложнее. Также неясно, можно ли добиться здесь скорости около real time, если искать объекты с heap JVM внутри устройства. К тому же задачу CV мне хотелось решать больше, чем эту.
В теории можно было бы сделать прокси-сервер и брать информацию оттуда. Но сетевой протокол игры часто меняется, прокси-сервера в интернете попадаются, но быстро устаревают и не поддерживаются.
Доступные игровые ресурсы
Для начала я решил ознакомиться с доступными материалами из игры. Я нашел клуб умельцев, достающих запакованные игровые ресурсы [1] [2]. В первую очередь меня интересовали картинки юнитов, но в распакованном игровом пакете они представлены в виде карты тайлов (кусочков, из которых состоит юнит).
Также я нашел склеенные (хоть и не идеально) с помощью скрипта кадры анимаций юнитов — они пригодились для обучения модели распознавания.
Кроме того, в ресурсах можно найти csv с различными игровыми данными — количество HP, урон юнитов разного уровня и т. п. Это полезно при создании логики бота. Например, из данных стало точно понятно, что поле поделено на 18 x 29 клеток, и ставить юнитов можно только на них. Еще там были все изображения карт юнитов, которые пригодятся нам позже.
Computer Vision для ленивых
После поиска доступных CV-решений стало понятно, что обучать их в любом случае придется на размеченном датасете. Я наделал скриншотов экрана и уже был готов разметить какое-то количество скриншотов руками. Это оказалось непростой задачей.
Поиск доступных программ для распознавания занял какое-то время. Я остановился на labelImg. Все найденные мной приложения для аннотирования были достаточно примитивны: многие не поддерживали комбинации клавиш, выбор объектов и их типов был сделан намного менее удобно, чем в labelImg.
Во время разметки оказалось полезным иметь исходный код приложения. Я делал скриншоты каждую пару секунд матча. На скриншотах бывает много объектов (например, армия скелетов), и я сделал модификацию в labelImg — по умолчанию при разметке следующего изображения брались метки из предыдущего. Часто их нужно было просто подвинуть под новое положение юнитов, удалить умерших юнитов и добавить несколько появившихся, а не размечать с нуля.
Процесс оказался ресурсоемким — за два дня в спокойном режиме я разметил около 200 скриншотов. Выборка выглядит совсем небольшой, но я решил начать экспериментировать. Всегда можно добавить больше примеров и улучшить качество модели.
На момент разметки я не знал, какой инструмент обучения буду использовать, поэтому решил сохранить результаты разметки в формате VOC — одном из консервативных и на вид универсальных.
Может возникнуть вопрос: почему просто не искать попиксельно изображения юнитов по полному совпадению? Проблема в том, что для этого пришлось бы искать огромное количество различных кадров анимации разных юнитов. Вряд ли это бы сработало. Мне хотелось сделать универсальное решение, поддерживающее разные разрешения. Кроме того, юниты могут иметь разный окрас в зависимости от применяемого к ним эффекта — заморозка, ускорение.
Почему я выбрал YOLO
Я начал исследовать возможные решения распознавания изображений. Посмотрел на применение различных алгоритмов: OpenCV, TensorFlow, Torch. Хотелось сделать распознавание как можно более быстрым, даже пожертвовав точностью, и получить POC как можно скорее.
Почитав статьи, я понял, что моя задача не вяжется с HOG/LBP/SVM/HAAR/… классификаторами. Хоть они и быстрые, но пришлось бы их применять очень много раз — по классификатору на каждого юнита — и потом по одному применять их к картинке для поиска. К тому же их принцип работы в теории давал бы плохие результаты: у юнитов может быть разная форма, например, при перемещении влево и вверх.
Теоретически, используя нейронную сеть, можно применить ее один раз к изображению и получить всех юнитов разных типов с их положением, поэтому я стал копать в сторону нейронных сетей. В TensorFlow нашлась поддержка Convolutional Neural Networks (CNN). Оказалось, что не обязательно обучать нейронные сети с нуля — можно переобучить уже имеющуюся мощную сеть.
Затем я нашел более практичный алгоритм YOLO, который обещает меньшую сложность и, следовательно, должен был обеспечивать высокую скорость алгоритма поиска, не сильно жертвуя точностью (а в некоторых случаях и превосходя другие модели).
На сайте YOLO обещают громадную разницу в скорости, используя модель «tiny» и меньшую оптимизированную сеть. YOLO также позволяет переобучить готовую нейронную сеть под свою задачу, причем darknet — opensource-фреймворк для использования различных нейронок, создатели которого разработали YOLO — является простым нативным приложением на C, и вся работа с ним происходит через его вызовы с параметрами.
TensorFlow, написанный на Python, является по факту Python-библиотекой и применяется с использованием самописных скриптов, в которых надо разобраться или подточить их под свои нужды. Вероятно, для кого-то гибкость TensorFlow — это плюс, но, не вникая в подробности, вряд ли можно быстро взять его и использовать. Поэтому в моем проекте выбор пал на YOLO.
Построение модели
Для работы над обучением модели я установил Ubuntu 18.10, доставил пакеты для сборки, пакет OpenCL от NVIDIA и другие зависимости, собрал darknet.
На Github есть раздел с простыми шагами по переобучению модели YOLO: нужно скачать модель и конфиги, поменять их и запустить переобучение.
Сначала я хотел попробовать переобучить простую YOLO-модель, потом Tiny и сравнить их. Однако оказалось, что для обучения простых моделей нужно 4 ГБ памяти видеокарты, а у меня была только купленная для игр видеокарта NVIDIA GeForce GTX 1060 с 3 ГБ. Поэтому я смог сразу обучать только Tiny-модель.
Разметка юнитов на изображениях у меня была в формате VOC, а YOLO работал со своим форматом, поэтому я использовал утилиту convert2Yolo для преобразования файлов аннотаций.
После ночи обучения на моих 200 скриншотах я получил первые результаты, и они меня удивили — модель действительно смогла кое-что распознать правильно! Я понял, что двигаюсь в верном направлении, и решил сделать больше обучающих примеров.
Продолжать размечать скриншоты мне не хотелось, и я вспомнил про кадры из анимаций юнитов. Я разметил все маленькие картинки их классами и попробовал обучить сеть на этом наборе. Результат был совсем плохим. Предполагаю, что модель не могла выделить правильные паттерны из маленьких картинок для использования на больших изображениях.
После этого я решил разместить их на готовые фоны боевых арен и программно создать файл разметки VOC. Получался такой синтетический скриншот с автоматической 100% точной разметкой.
Я написал скрипт на Scala, который делит скриншот на 16 квадратов 4x4 и устанавливает в их центр юнитов, чтобы они не пересекались друг с другом. Скрипт также позволил мне кастомизировать создание обучающих примеров — при получении урона юниты окрашиваются в цвет их команды (красный/синий), и при классификации я отдельно распознаю юниты разных цветов. Помимо окрашивания, получившие урон юниты разных команд имеют небольшие различия в одежде. Также я случайным образом немного увеличивал и уменьшал юнитов, чтобы модель научилась не сильно зависеть от размера юнита. В итоге я научился создавать десятки тысяч обучающих примеров, приблизительно похожих на реальные скриншоты.
Генерация была не идеальной. Часто юниты ставились поверх зданий, хотя в игре они были бы за ними; не было примеров перекрытия части юнита, хотя в игре это нередкая ситуация. Но всем этим я пока решил пренебречь.
Модель, полученная после нескольких ночей обучения на смеси из 200 реальных скриншотов и 5000 сгенерированных изображений, которые пересоздавались в процессе обучения раз в день, при проверке на настоящих скриншотах давала плохие результаты. Неудивительно, ведь сгенерированные картинки имеют достаточно много отличий от настоящих.
Поэтому полученную модель я поставил дообучаться на скупой выборке, в которой было только 200 моих скриншотов. После этого она стала работать гораздо лучше.
Чертов стыд
Прошу прощения за оперирование такими ненаучными мерами, как «гораздо лучше», но я не знаю, как быстро произвести кросс-валидацию по изображениям, поэтому пробовал несколько скриншотов не из обучающей выборки и смотрел, удовлетворяют ли меня результаты. Это же самое важное. Мы ведь ленивые и делаем прототип, верно?
Следующие шаги по улучшению модели были понятны — разметить руками больше настоящих скриншотов и обучить на них модель, предобученную на сгенерированных скриншотах.
Следующие шаги по улучшению модели были понятны — разметить руками больше настоящих скриншотов и обучить на них модель, предобученную на сгенерированных скриншотах.
Приступим к боту
Бота я решил писать на Python — у него есть много доступных инструментов для ML. Свою модель я решил использовать с OpenCV, который с 3.5 научился использовать модели нейронных сетей, и я даже нашел простой пример. Попробовав несколько библиотек для работы с ADB, я выбрал pure-python-adb — там просто реализовано все, что мне надо: функция получения экрана 'screencap' и выполнение операции на устройстве 'shell'; тапаю я, используя 'input tap'.
Итак, получив скриншот игры, распознав на нем юнитов и потыкав на экран, я продолжил работать над распознаванием игрового состояния. Кроме юнитов, мне нужно было сделать распознавание текущего уровня маны и доступных игроку карт.
Уровень маны в игре отображается в виде прогресс-бара и цифры. Недолго думая, я стал вырезать цифру, инвертировать и распознавать с помощью pytesseract.
Для определения доступных карт и их положения я использовал keypoint detector KAZE из OpenCV. Мне пока не хотелось снова возвращаться к обучению нейронной сети, и я выбрал способ, который был быстрее и проще, хоть у него в итоге и оказалась минимально достаточная точность в случае, когда нужно искать много объектов.
При запуске бота я считал keypoints для всех картинок карт (всего их несколько десятков), а во время игры искал совпадения всех карт с областью карт игрока для уменьшения количества ошибок и увеличения скорости. Их сортировка происходила по точности и по координате x для получения порядка карт — информации о том, как они располагаются на экране.
Немного поигравшись с параметрами, на практике я получил много ошибок, хотя какие-то сложные картинки карт, которые иногда алгоритмом ошибочно принимались за другие, распознавались с большой точностью. Пришлось добавить буфер из трех элементов: если три распознавания подряд мы получаем одни и те же значения, то условно считаем, что мы можем им доверять.
После получения всей необходимой информации (юниты и их примерное положение, доступная мана и карты) можно принимать какие-то решения.
Для начала я решил взять что-то простое: например, если хватает маны на доступную карту, сыграть ею на поле. Но бот еще не умеет «играть» карты — он знает, какие у нас карты, где поле, надо нажать на нужную карту, а затем на нужную клетку на поле.
Зная разрешение скриншота, можно понять координаты карты и нужной клетки поля. Сейчас я завязался на точное разрешение экрана, но при необходимости от этого можно абстрагироваться. Функция принятия решения будет возвращать массив нажатий, которые нужно сделать в ближайшее время. В общем виде наш бот будет являться бесконечным циклом (упрощенно):
бесконечно: изображение = получить изображение если есть действия: сделать действие(первое действие) небольшая задержка для правдоподобности иначе: юниты = распознаем юнитов(изображение) карты = распознаем карты(изображение) мана = распознаем ману(изображение) действия += анализ(изображение, юниты, карты, мана)
Пока бот умеет только ставить юнитов в одну точку, но уже имеет достаточно информации, чтобы построить более сложную стратегию.
Первые проблемы
В реальности я столкнулся с неожиданной и очень неприятной проблемой. Создание скриншота через ADB занимает около 100 мс, что вносит значительную задержку — я рассчитывал на такую максимальную задержку, учитывая все расчеты и выбор действия, но не на одном шаге создания скриншота. Простого и быстрого решения найти не удалось. В теории, используя эмулятор Android, можно снимать скриншоты прямо с окна приложения, или можно сделать утилиту для стриминга изображения с телефона со сжатием через UDP и подключиться ботом к ней, но быстрых решений тут я тоже не нашел.
Итак
Трезво оценив состояние моего проекта, на этой модели я решил пока остановиться. Я потратил на это несколько недель своего свободного времени, а ведь распознавание юнитов — это только часть игрового процесса.
Я решил развивать части бота постепенно — сделать базовую логику восприятия, затем простую логику игры и взаимодействия с игрой, а потом уже можно будет улучшать отдельные проседающие части бота. Когда уровень модели распознавания юнитов станет достаточным, добавление информации о HP и уровне юнитов может вывести развитие игрового бота на качественно новый этап. Возможно, это станет следующей целью, но сейчас точно не стоит зацикливаться на этой задаче.
Репозиторий проекта на Github
Я потратил на проект достаточно много времени и, честно говоря, устал от него, но ни капли не жалею — я получил новый опыт в ML/CV.
Может быть, я вернусь к нему позже — буду рад, если кто-то присоединится ко мне. Если вам это интересно, вступайте в группу в Telegram, а также приходите на мой курс по Scala.

