Мы – Big Data в МТС и это наш первый пост. Сегодня расскажем о том, какие технологии позволяют нам хранить и обрабатывать большие данные так, чтобы всегда хватало ресурсов для аналитики, и затраты на закупки железа не уходили в заоблачные дали.
О создании центра Big Data в МТС задумались в 2014 году: появилась необходимость масштабирования классического аналитического хранилища и BI-отчетности над ним. На тот момент движок для обработки данных и BI были SASовские – так сложилось исторически. И хотя потребности бизнеса в хранилище были закрыты, со временем функционал BI и ad-hoc-аналитики поверх аналитического хранилища разросся настолько, что нужно было решать вопрос увеличения производительности, учитывая, что с годами количество пользователей увеличилось в десятки раз и продолжало расти.
В результате конкурса в МТС появилась MPP-система Teradata, покрывающая потребности телекома на тот момент. Это стало толчком к тому, чтобы попробовать что-то более популярное и open source’вое.

На фото — команда Big Data МТС в новом офисе «Декарт» в Москве
Первый кластер был из 7 нод. Этого было достаточно для проверки нескольких бизнес-гипотез и набивания первых шишек. Старания не прошли даром: Big Data в МТС существует уже три года и сейчас анализ данных задействован почти во всех функциональных направлениях. Команда выросла из трех человек в две сотни.
Мы хотели иметь легкие процессы разработки, быстро проверять гипотезы. Для этого нужно три вещи: команда со стартаповским мышлением, легковесные процессы разработки и развитая инфраструктура. Про первое и второе много где можно почитать и послушать, а вот про развитую инфраструктуру стоит рассказать отдельно, ведь здесь важны legacy и источники данных, которые есть в телекоме. Развитая data-инфраструктура – это не только построение data lake, детального слоя данных и слоя витрин. Это еще и инструменты, и интерфейсы доступа к данным, изоляция вычислительных ресурсов под продукты и команды, механизмы доставки данных до потребителей – как в real-time, так и в batch-режиме. И многое-многое другое.
Все эта работа у нас выделилась в отдельное направление, которое занимается разработкой коммунальных сервисов и инструментов по работе с данными. Это направление называется ИТ-платформой Big Data.
В МТС достаточно много источников данных. Один из основных — базовые станции, мы обслуживаем абонентскую базу более 78 млн абонентов в России. Также у нас много сервисов и услуг, которые не относятся к телекому и позволяют получать более разносторонние данные (электронная коммерция, системная интеграция, интернет вещей, облачные сервисы и др. — весь “нетелеком” приносит уже около 20% от всей выручки).
Кратко нашу архитектуру можно представить в виде такого графика:
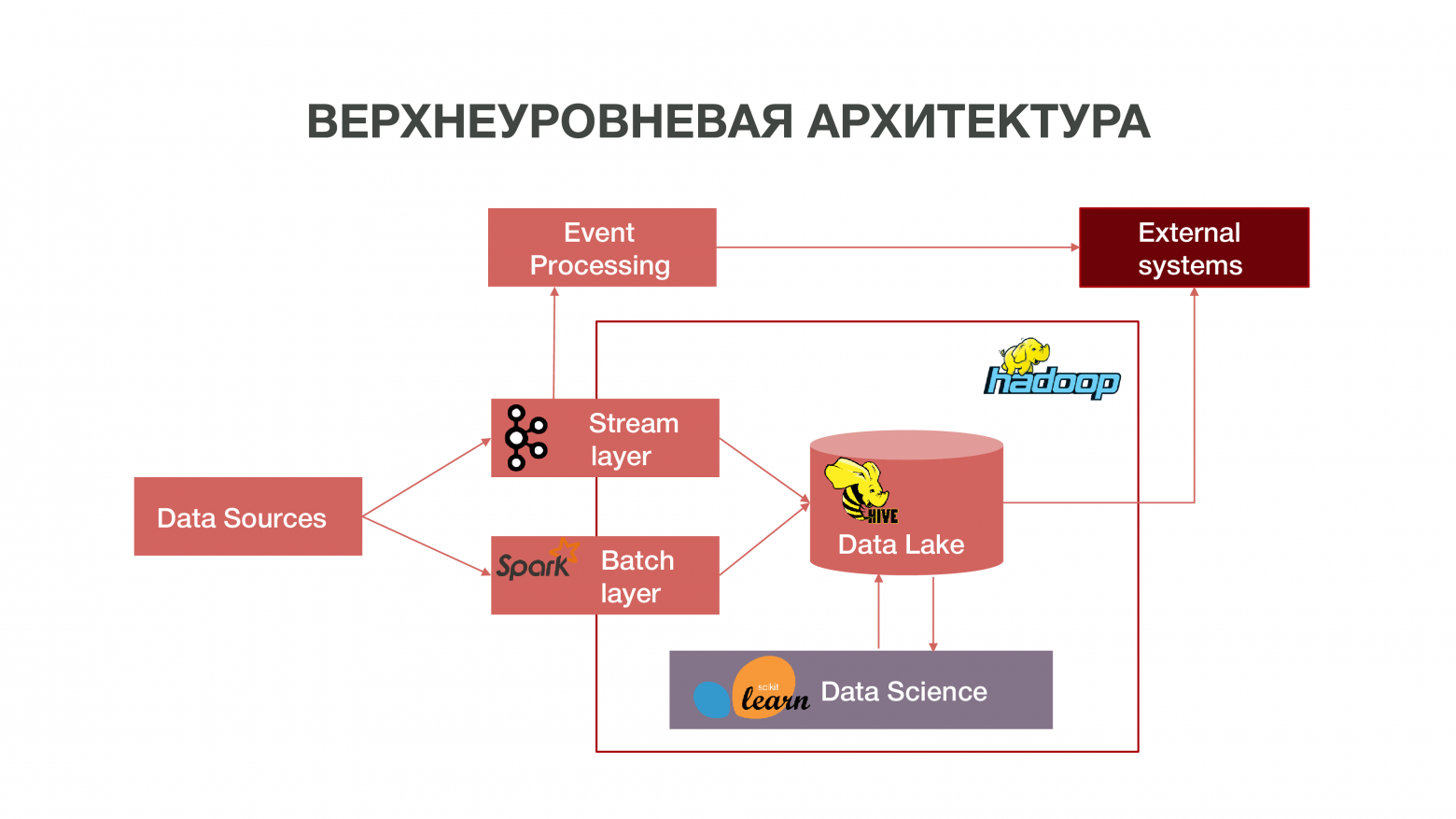
Как видно на графике, Dаta Sources могут отдавать информацию в режиме реального времени. Мы используем stream layer – можем обрабатывать информацию real-time, извлекать из нее какие-то события, которые нам интересны, и на этом строить аналитику. Для того, чтобы обеспечить такой процессинг событий, — мы разработали достаточно стандартную реализацию (с точки зрения архитектуры) с использованием Apache Kafka, Apache Spark и кода на языке Scala. Информация, получаемая в результате такого анализа, может потребляться как внутри МТС, так и в будущем вовне: бизнесу часто интересен сам факт совершения определенных действий абонентов.
Есть еще режим загрузки данных пачками – batch layer. Обычно загрузка происходит раз в час по расписанию, в качестве планировщика у нас используется Apache Airflow, а сами процессы batch-загрузки у нас реализованы на python. В этом случае в Data Lake загружается значительно бОльший объем данных, необходимый для наполнения Big Data историческими данными, на которых должны обучаться наши Data Science-модели. В результате формируется профиль абонента в историческом разрезе на основе данных о его сетевой активности. Это позволяет получить предсказательную статистику и строить модели поведения человека, даже создавать его психологический портрет – есть у нас такой отдельный продукт. Эта информация очень полезна, например, для маркетинговых компаний.
Также у нас есть большой объем данных, которые составляют классическое хранилище. То есть мы агрегируем информацию по различным событиям – как пользовательским, так и сетевым. Все эти обезличенные данные также помогают более точно предсказывать интересы пользователей и события, важные для компании – например, прогнозировать возможные сбои оборудования и вовремя устранять неполадки.
Если смотреть в прошлое и вспоминать, как вообще появились большие данные, то нужно отметить, что в основном накапливание данных производилось в маркетинговых целях. Нет такого четкого определения, что такое большие данные – это гигабайт, терабайт, петабайт. Невозможно провести черту. Для одних большие данные – это десятки гигабайт, для других – петабайты.
Так сложилось, что с течением времени во всем мире накопилось очень много данных. И для того, чтобы провести какую-то более-менее значимую аналитику этих данных, обычных хранилищ, которые развивались с 70-х годов прошлого века, оказывалось уже недостаточно. Когда начался вал информации в 2000-е, 10-е годы и когда появилось очень много устройств, которые имели выход в интернет, когда появился интернет вещей, эти хранилища уже просто концептуально не справлялись. В основе этих хранилищ лежала реляционная теория. То есть были реляции разных форм, которые взаимодействовали друг с другом. Была система описания, как строить и проектировать хранилища.
Когда не справляются старые технологии – появляются новые. В современном проблема аналитики больших данных решается двумя путями:
Создание своего фреймворка, которое позволяет обрабатывать большие объемы информации. Обычно это распределенное приложение из многих сотнях тысяч серверов – как у Google, Яндекс, которые создали свои распределенные базы данных, позволяющие работать с таким объемом информации.
Развитие технологии Hadoop – фреймворк для распределенных вычислений, распределенная файловая система, которая может хранить и обрабатывать очень большой объем информации. Инструменты Data Science в основном совместимы с Hadoop и такая совместимость открывает много возможностей для продвинутого анализа данных. Многие компании, в том числе и мы, идут в сторону open source Hadoop экосистемы.
Центральный Hadoop-кластер у нас находится в Нижнем Новгороде. Там аккумулируется информация практически со всех регионов страны. По объему сейчас туда можно загрузить около 8,5 петабайт данных. Также в Москве у нас есть отдельные RND кластеры, где мы проводим эксперименты.
Так как у нас в разных регионах около тысячи серверов, где мы проводим аналитику, а также планируется расширение – то возникает вопрос о правильном выборе оборудования для распределенных аналитических систем. Можно купить оборудование, достаточное для хранения данных, но которое окажется непригодным для аналитики – просто потому, что не будет хватать ресурсов, количества ядер CPU и свободной оперативной памяти на узлах. Важно найти баланс, чтобы получить хорошие возможности для аналитики и не очень высокую стоимость оборудования.
Компания Intel предложила нам разные варианты, как можно оптимизировать работу с распределенной системой для того, чтобы аналитику по нашему объему данных можно было получать за приемлемые деньги. Intel развивает технологию твердотельных накопителей NAND SSD. Она в сотни раз быстрее, чем обычный HDD. Чем нам это хорошо: SSD, особенно с NVMe интерфейсом, обеспечивает достаточно быстрый доступ к данным.
Плюс Intel выпустила серверные твердотельные накопители Intel Optane SSD на основе нового типа энергонезависимой памяти Intel 3D XPoint. Они справляются с интенсивными смешанными нагрузками на систему хранения, и обладают бОльшим ресурсом, чем обычные NAND SSD. Чем нам это хорошо: Intel Optane SSD позволяет стабильно работать под большими нагрузкам с малой задержкой. Мы изначально рассматривали NAND SSD как замену традиционных жестких дисков, потому что у нас очень большой объем данных перемещается между жестким диском и оперативной памятью – и нам нужно было оптимизировать данные процессы.
Первый тест мы провели в 2016 году. Мы просто взяли и попытались заменить HDD на быстрый NAND SSD. Для этого мы заказали семплы нового накопителя Intel – на тот момент это был DC P3700. И прогнали стандартный тест Hadoop – экосистемы, которая позволяет оценить, как изменяется перфоманс в разных условиях. Это стандартизированные тесты TeraGen, TeraSort, TeraValidate.

TeraGen позволяет «нагенерить» искусственных данных определенного объема. Мы для примера взяли 1 ГБ и 1 ТБ. С помощью TeraSort мы отсортировали этот объем данных в Hadoop. Это довольно ресурсоемкая операция. И последний тест – TeraValidate – позволяет убедиться, что данные отсортированы в нужном порядке. То есть мы проходим по ним второй раз.

В качестве эксперимента мы взяли машинки только с SSD – то есть Hadoop установили только на SSD без использования жестких дисков. Во втором варианте SSD мы использовали для хранения временных файлов, HDD – для хранения основных данных. И в третьем варианте жесткие диски использовались и для того, и для другого.
Результаты этих экспериментов нас не очень обрадовали, потому что разница в показателях эффективности не превышала 10-20%. То есть мы поняли, что Hadoop не очень дружит с SSD в плане хранения, потому что изначально система была создана для хранения больших данных на HDD, и никто ее особенно не оптимизировал под быстрые и дорогие SSD. А так как стоимость SSD на тот момент была достаточно высокой, мы решили пока в эту историю не идти и обойтись жесткими дисками.
Затем у Intel появились новые серверные Intel Optane SSD на базе памяти 3D XPoint. Они вышли в конце 2017 года, но семплы нам были доступны ранее. Характеристики памяти 3D XPoint позволяют использовать Intel Optane SSD в качестве расширения оперативной памяти в серверах. Так как мы уже поняли, что решить проблему производительности IO Hadoop на уровне устройств блочного хранения будет непросто, то решили попробовать новый вариант – расширение оперативной памяти с помощью технологии Intel Memory Drive Technology (IMDT). И в начале этого года мы одни из первых в мире её протестировали.
Чем нам это хорошо: это дешевле, чем оперативная память, что позволяет собирать сервера, которые обладают терабайтами оперативной памяти. А так как оперативная память достаточно быстро работает – в нее можно загружать большие дата-сеты и анализировать их. Напомню, что особенность нашего аналитического процесса в том, что мы несколько раз обращаемся к данным. Для того чтобы какой-то анализ сделать, мы должны как можно больше данных загрузить в память и «прокрутить» несколько раз какую-то аналитику этих данных.
Английская лаборатория Intel в г. Суиндон выделила нам кластер из трех серверов, который в ходе тестов мы сравнили с нашим тестовым кластером, расположенными в МТС.

Как видно из графика, по итогам теста мы получили достаточно хорошие результаты.
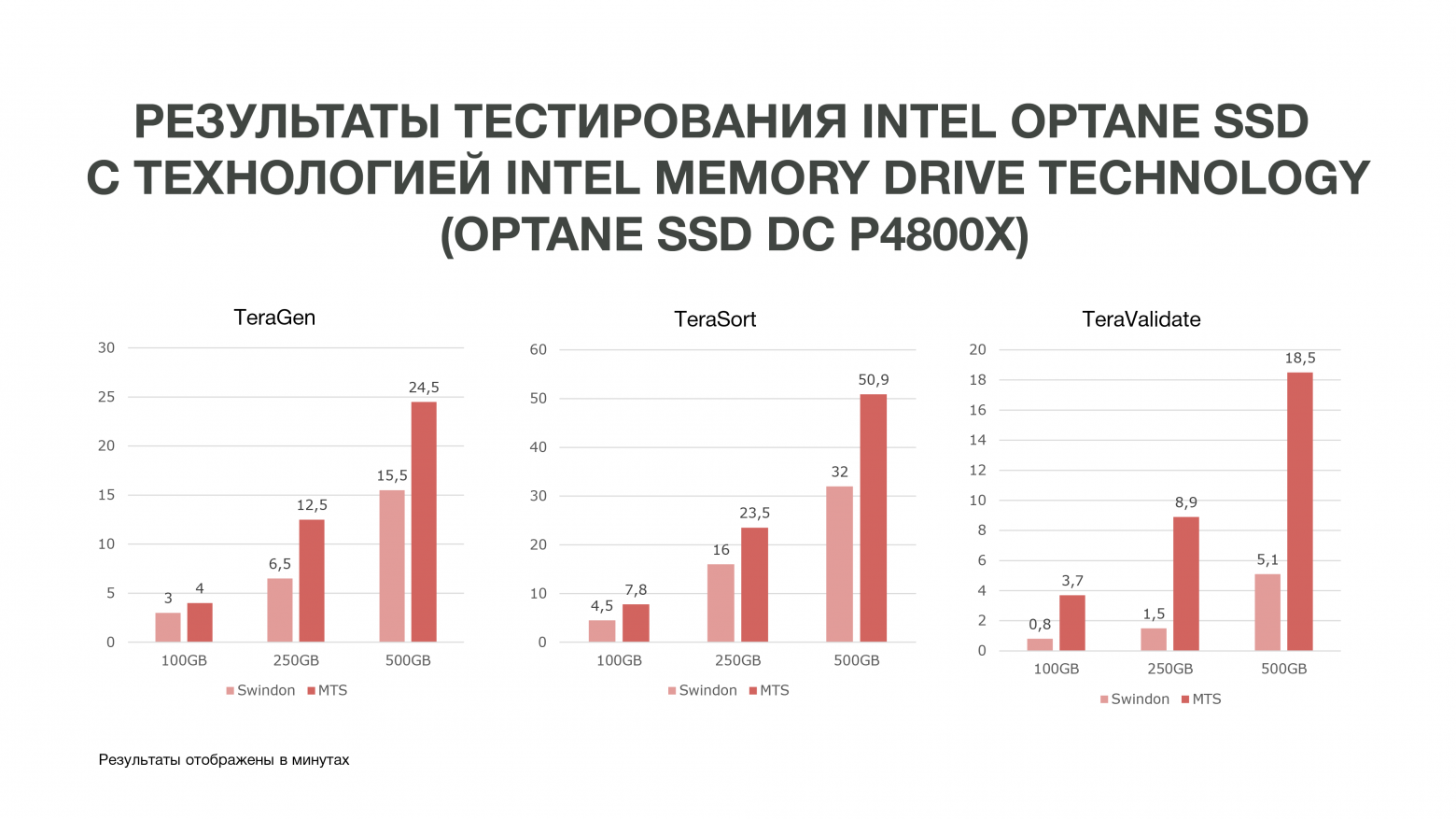
Тот же TeraGen показал увеличение производительности практически в два раза, TeraValidate – на 75%. Это очень хорошо для нас, потому что, как я уже сказал, мы несколько раз обращаемся к данным, которые у нас находятся в памяти. Соответственно, если мы получаем такой прирост по производительности, это нам особенно хорошо поможет в анализе данных, особенно в реал-тайме.
Мы провели три теста при разных условиях. 100 ГБ, 250 ГБ и 500 ГБ. И чем больше мы использовали памяти, тем Intel Optane SSD с Intel Memory Drive Technology лучше показывали себя. То есть чем больше данных мы анализируем, тем больше получаем эффективности. Аналитика, которая проходила на большем количестве узлов, может проходить на меньшем их количестве. И еще мы получаем достаточно большой объем памяти на наших машинах, что очень хорошо для Data Science-задач. По итогам тестов мы приняли решение закупить эти накопители для работы в МТС.
Если вам тоже приходилось выбирать и тестировать железо для хранения и обработки большого объема данных – нам будет интересно почитать, с какими трудностями вы при этом столкнулись и к каким результатам в итоге пришли: пишите в комментариях.
Авторы:
Руководитель центра компетенций прикладной архитектуры департамента Big Data МТС Григорий Коваль grigory_koval
Руководитель трайба управления данными департамента Big Data МТС Дмитрий Шостко zloi_diman
О создании центра Big Data в МТС задумались в 2014 году: появилась необходимость масштабирования классического аналитического хранилища и BI-отчетности над ним. На тот момент движок для обработки данных и BI были SASовские – так сложилось исторически. И хотя потребности бизнеса в хранилище были закрыты, со временем функционал BI и ad-hoc-аналитики поверх аналитического хранилища разросся настолько, что нужно было решать вопрос увеличения производительности, учитывая, что с годами количество пользователей увеличилось в десятки раз и продолжало расти.
В результате конкурса в МТС появилась MPP-система Teradata, покрывающая потребности телекома на тот момент. Это стало толчком к тому, чтобы попробовать что-то более популярное и open source’вое.
На фото — команда Big Data МТС в новом офисе «Декарт» в Москве
Первый кластер был из 7 нод. Этого было достаточно для проверки нескольких бизнес-гипотез и набивания первых шишек. Старания не прошли даром: Big Data в МТС существует уже три года и сейчас анализ данных задействован почти во всех функциональных направлениях. Команда выросла из трех человек в две сотни.
Мы хотели иметь легкие процессы разработки, быстро проверять гипотезы. Для этого нужно три вещи: команда со стартаповским мышлением, легковесные процессы разработки и развитая инфраструктура. Про первое и второе много где можно почитать и послушать, а вот про развитую инфраструктуру стоит рассказать отдельно, ведь здесь важны legacy и источники данных, которые есть в телекоме. Развитая data-инфраструктура – это не только построение data lake, детального слоя данных и слоя витрин. Это еще и инструменты, и интерфейсы доступа к данным, изоляция вычислительных ресурсов под продукты и команды, механизмы доставки данных до потребителей – как в real-time, так и в batch-режиме. И многое-многое другое.
Все эта работа у нас выделилась в отдельное направление, которое занимается разработкой коммунальных сервисов и инструментов по работе с данными. Это направление называется ИТ-платформой Big Data.
Откуда в МТС берется Big Data
В МТС достаточно много источников данных. Один из основных — базовые станции, мы обслуживаем абонентскую базу более 78 млн абонентов в России. Также у нас много сервисов и услуг, которые не относятся к телекому и позволяют получать более разносторонние данные (электронная коммерция, системная интеграция, интернет вещей, облачные сервисы и др. — весь “нетелеком” приносит уже около 20% от всей выручки).
Кратко нашу архитектуру можно представить в виде такого графика:
Как видно на графике, Dаta Sources могут отдавать информацию в режиме реального времени. Мы используем stream layer – можем обрабатывать информацию real-time, извлекать из нее какие-то события, которые нам интересны, и на этом строить аналитику. Для того, чтобы обеспечить такой процессинг событий, — мы разработали достаточно стандартную реализацию (с точки зрения архитектуры) с использованием Apache Kafka, Apache Spark и кода на языке Scala. Информация, получаемая в результате такого анализа, может потребляться как внутри МТС, так и в будущем вовне: бизнесу часто интересен сам факт совершения определенных действий абонентов.
Есть еще режим загрузки данных пачками – batch layer. Обычно загрузка происходит раз в час по расписанию, в качестве планировщика у нас используется Apache Airflow, а сами процессы batch-загрузки у нас реализованы на python. В этом случае в Data Lake загружается значительно бОльший объем данных, необходимый для наполнения Big Data историческими данными, на которых должны обучаться наши Data Science-модели. В результате формируется профиль абонента в историческом разрезе на основе данных о его сетевой активности. Это позволяет получить предсказательную статистику и строить модели поведения человека, даже создавать его психологический портрет – есть у нас такой отдельный продукт. Эта информация очень полезна, например, для маркетинговых компаний.
Также у нас есть большой объем данных, которые составляют классическое хранилище. То есть мы агрегируем информацию по различным событиям – как пользовательским, так и сетевым. Все эти обезличенные данные также помогают более точно предсказывать интересы пользователей и события, важные для компании – например, прогнозировать возможные сбои оборудования и вовремя устранять неполадки.
Hadoop
Если смотреть в прошлое и вспоминать, как вообще появились большие данные, то нужно отметить, что в основном накапливание данных производилось в маркетинговых целях. Нет такого четкого определения, что такое большие данные – это гигабайт, терабайт, петабайт. Невозможно провести черту. Для одних большие данные – это десятки гигабайт, для других – петабайты.
Так сложилось, что с течением времени во всем мире накопилось очень много данных. И для того, чтобы провести какую-то более-менее значимую аналитику этих данных, обычных хранилищ, которые развивались с 70-х годов прошлого века, оказывалось уже недостаточно. Когда начался вал информации в 2000-е, 10-е годы и когда появилось очень много устройств, которые имели выход в интернет, когда появился интернет вещей, эти хранилища уже просто концептуально не справлялись. В основе этих хранилищ лежала реляционная теория. То есть были реляции разных форм, которые взаимодействовали друг с другом. Была система описания, как строить и проектировать хранилища.
Когда не справляются старые технологии – появляются новые. В современном проблема аналитики больших данных решается двумя путями:
Создание своего фреймворка, которое позволяет обрабатывать большие объемы информации. Обычно это распределенное приложение из многих сотнях тысяч серверов – как у Google, Яндекс, которые создали свои распределенные базы данных, позволяющие работать с таким объемом информации.
Развитие технологии Hadoop – фреймворк для распределенных вычислений, распределенная файловая система, которая может хранить и обрабатывать очень большой объем информации. Инструменты Data Science в основном совместимы с Hadoop и такая совместимость открывает много возможностей для продвинутого анализа данных. Многие компании, в том числе и мы, идут в сторону open source Hadoop экосистемы.
Центральный Hadoop-кластер у нас находится в Нижнем Новгороде. Там аккумулируется информация практически со всех регионов страны. По объему сейчас туда можно загрузить около 8,5 петабайт данных. Также в Москве у нас есть отдельные RND кластеры, где мы проводим эксперименты.
Так как у нас в разных регионах около тысячи серверов, где мы проводим аналитику, а также планируется расширение – то возникает вопрос о правильном выборе оборудования для распределенных аналитических систем. Можно купить оборудование, достаточное для хранения данных, но которое окажется непригодным для аналитики – просто потому, что не будет хватать ресурсов, количества ядер CPU и свободной оперативной памяти на узлах. Важно найти баланс, чтобы получить хорошие возможности для аналитики и не очень высокую стоимость оборудования.
Компания Intel предложила нам разные варианты, как можно оптимизировать работу с распределенной системой для того, чтобы аналитику по нашему объему данных можно было получать за приемлемые деньги. Intel развивает технологию твердотельных накопителей NAND SSD. Она в сотни раз быстрее, чем обычный HDD. Чем нам это хорошо: SSD, особенно с NVMe интерфейсом, обеспечивает достаточно быстрый доступ к данным.
Плюс Intel выпустила серверные твердотельные накопители Intel Optane SSD на основе нового типа энергонезависимой памяти Intel 3D XPoint. Они справляются с интенсивными смешанными нагрузками на систему хранения, и обладают бОльшим ресурсом, чем обычные NAND SSD. Чем нам это хорошо: Intel Optane SSD позволяет стабильно работать под большими нагрузкам с малой задержкой. Мы изначально рассматривали NAND SSD как замену традиционных жестких дисков, потому что у нас очень большой объем данных перемещается между жестким диском и оперативной памятью – и нам нужно было оптимизировать данные процессы.
Первый тест
Первый тест мы провели в 2016 году. Мы просто взяли и попытались заменить HDD на быстрый NAND SSD. Для этого мы заказали семплы нового накопителя Intel – на тот момент это был DC P3700. И прогнали стандартный тест Hadoop – экосистемы, которая позволяет оценить, как изменяется перфоманс в разных условиях. Это стандартизированные тесты TeraGen, TeraSort, TeraValidate.
TeraGen позволяет «нагенерить» искусственных данных определенного объема. Мы для примера взяли 1 ГБ и 1 ТБ. С помощью TeraSort мы отсортировали этот объем данных в Hadoop. Это довольно ресурсоемкая операция. И последний тест – TeraValidate – позволяет убедиться, что данные отсортированы в нужном порядке. То есть мы проходим по ним второй раз.
В качестве эксперимента мы взяли машинки только с SSD – то есть Hadoop установили только на SSD без использования жестких дисков. Во втором варианте SSD мы использовали для хранения временных файлов, HDD – для хранения основных данных. И в третьем варианте жесткие диски использовались и для того, и для другого.
Результаты этих экспериментов нас не очень обрадовали, потому что разница в показателях эффективности не превышала 10-20%. То есть мы поняли, что Hadoop не очень дружит с SSD в плане хранения, потому что изначально система была создана для хранения больших данных на HDD, и никто ее особенно не оптимизировал под быстрые и дорогие SSD. А так как стоимость SSD на тот момент была достаточно высокой, мы решили пока в эту историю не идти и обойтись жесткими дисками.
Второй тест
Затем у Intel появились новые серверные Intel Optane SSD на базе памяти 3D XPoint. Они вышли в конце 2017 года, но семплы нам были доступны ранее. Характеристики памяти 3D XPoint позволяют использовать Intel Optane SSD в качестве расширения оперативной памяти в серверах. Так как мы уже поняли, что решить проблему производительности IO Hadoop на уровне устройств блочного хранения будет непросто, то решили попробовать новый вариант – расширение оперативной памяти с помощью технологии Intel Memory Drive Technology (IMDT). И в начале этого года мы одни из первых в мире её протестировали.
Чем нам это хорошо: это дешевле, чем оперативная память, что позволяет собирать сервера, которые обладают терабайтами оперативной памяти. А так как оперативная память достаточно быстро работает – в нее можно загружать большие дата-сеты и анализировать их. Напомню, что особенность нашего аналитического процесса в том, что мы несколько раз обращаемся к данным. Для того чтобы какой-то анализ сделать, мы должны как можно больше данных загрузить в память и «прокрутить» несколько раз какую-то аналитику этих данных.
Английская лаборатория Intel в г. Суиндон выделила нам кластер из трех серверов, который в ходе тестов мы сравнили с нашим тестовым кластером, расположенными в МТС.
Как видно из графика, по итогам теста мы получили достаточно хорошие результаты.
Тот же TeraGen показал увеличение производительности практически в два раза, TeraValidate – на 75%. Это очень хорошо для нас, потому что, как я уже сказал, мы несколько раз обращаемся к данным, которые у нас находятся в памяти. Соответственно, если мы получаем такой прирост по производительности, это нам особенно хорошо поможет в анализе данных, особенно в реал-тайме.
Мы провели три теста при разных условиях. 100 ГБ, 250 ГБ и 500 ГБ. И чем больше мы использовали памяти, тем Intel Optane SSD с Intel Memory Drive Technology лучше показывали себя. То есть чем больше данных мы анализируем, тем больше получаем эффективности. Аналитика, которая проходила на большем количестве узлов, может проходить на меньшем их количестве. И еще мы получаем достаточно большой объем памяти на наших машинах, что очень хорошо для Data Science-задач. По итогам тестов мы приняли решение закупить эти накопители для работы в МТС.
Если вам тоже приходилось выбирать и тестировать железо для хранения и обработки большого объема данных – нам будет интересно почитать, с какими трудностями вы при этом столкнулись и к каким результатам в итоге пришли: пишите в комментариях.
Авторы:
Руководитель центра компетенций прикладной архитектуры департамента Big Data МТС Григорий Коваль grigory_koval
Руководитель трайба управления данными департамента Big Data МТС Дмитрий Шостко zloi_diman
