В статье описывается вариант обеспечения доступности развернутого в облаке веб-сервиса при возникновении сбоев в работе дата-центра. Предлагаемое решение основано на компромиссе, состоящем в частичном дублировании: в другом дата-центре разворачивается резервная система, которая может работать в режиме ограниченной функциональности при недоступности основного ЦОДа. Данная схема в первую очередь нацелена на применение при кратковременных сбоях, но также предусматривает возможность быстрого превращения дублирующей системы в основную в случае масштабных проблем.

В прошлом году нас коснулся инцидент в дата-центре известного облачного провайдера — один из наших сервисов полчаса был недоступен для пользователей. Тогда мы воочию убедились, что в случае проблем в ЦОДе облака рычаги для восстановления работоспособности приложения практически отсутствуют и для команды, ответственной за приложение, ничего не остается, кроме как смириться и ждать. Этот опыт заставил нас серьезно задуматься над использованием облаков для своих продуктов.
Что именно случилось в тот день, так и не удалось выяснить. Мы привыкли воспринимать облака как некий нерушимый форпост, но это не так. Правда состоит в том, что нет стопроцентной гарантии доступности сервиса в облаке, как и в любом другом месте. Облака — это абстракция, за которой скрываются все те же стойки с железом в дата-центрах и человеческий фактор. Любое железо рано или поздно выходит из строя (хотя для дата-центров аппаратные сбои — это скорее штатная ситуация). Помимо этого, известны случаи более серьезных проблем, приводящих к недоступности дата-центров: пожары, DDoS-атаки, стихийные бедствия, перебои с электричеством и интернетом и т. п.
Если говорить о человеческом факторе, то это не самая последняя причина аварий: «по статистике, в 80% сбоев сетевой инфраструктуры виноват человек». Люди, какими бы благими намерениями они ни руководствовались, ненадежны. Даже вы и ваши коллеги — лица, напрямую заинтересованные в стабильности поддерживаемых продуктов, — наверняка допускали ошибки, не говоря уже о персонале чужой компании, для которого ваши инстансы ничем не отличаются от тысяч других. Какая бы профессиональная команда ни стояла за инфраструктурой, новый сбой — это вопрос времени.
Всё имеет свою цену. При переезде в облако вы получаете простую абстракцию, с которой удобно работать, слабую зависимость от своего отдела operations взамен полного контроля над ситуацией. В этом случае, если вы не позаботитесь о себе заранее, предусмотрев возможность чужих ошибок, этого не сделает никто.
Для нас недоступность сервиса даже в течение нескольких минут уже критична. Поэтому мы решили найти способ подстраховаться от аналогичных проблем в будущем, не отказываясь от облаков.
Приступая к решению проблемы доступности сервиса в облаке, стоит иметь в виду, что доступность довольно широкое понятие и в зависимости от того, что под ним подразумевают, рассматриваются и разные сценарии ее обеспечения. Хотя в данной статье обсуждается только проблема доступности в результате отказа дата-центра, уместно будет сказать пару слов о решениях других проблем доступности.
Доступность как техническая возможность предоставить доступ к ресурсу за конкретное время при определенной нагрузке. Проблема возникает, когда сервис работает, но из-за ограниченности ресурсов и архитектурных рамок системы не все пользователи могут получить к нему доступ за определенное время ответа. Задача чаще всего решается разворачиванием дополнительных инстансов с приложением. С таким масштабированием облака прекрасно справляются.
Доступность как доступность веб-сервиса для пользователей из определенного региона. Здесь очевидным решением является шардирование. Другими словами, разбиение системы на несколько независимых приложений в разных дата-центрах со своими данными и закрепление каждого пользователя за своим инстансом системы, например, на основе его геопозиции. При шардировании выход из строя одного дата-центра в худшем случае приведет к недоступности сервиса только для части привязанных к данному дата-центру пользователей. Не последний аргумент в пользу шардирования — это разное время пинга до дата-центра в различных регионах.
Впрочем, часто накладывание ограничений на работу с облаком и необходимость децентрализации — это законодательные требования, которые обычно учитывают еще на этапе проектирования системы. К таким требованиям можно отнести: закон Яровой — хранение персональных данных (ПД) пользователей в России; Общий регламент по защите данных (GDPR) — ограничения на трансграничную передачу ПД пользователей ЕС в некоторые страны; и китайская интернет-цензура, где ВСЕ коммуникации и ВСЕ части приложения должны находиться на территории Китая и, желательно, на их серверах.
Проблема технической недоступности дата-центра решается дублированием сервиса в другом дата-центре. Это непростая техническая задача. Основным препятствием в параллельном развертывании сервисов в разных дата-центрах является база данных. Обычно для небольших систем используется архитектура с одним мастером. В этом случае выход из строя дата-центра с мастером делает нерабочей всю систему. Схема репликации «мастер-мастер» возможна, но она накладывает сильные ограничения, которые не все понимают. По факту она не масштабирует запись в базу данных, а даже дает небольшой временной штраф, так как необходимо подтверждение всех узлов о том, что транзакция принята. Время операции записи еще больше возрастает, когда ноды должны быть разнесены по разным дата-центрам.
Анализ нагрузки на наш сервис показал, что в среднем около 70 % обращений к API приходится на GET-методы. Эти методы используют базу только для чтения данных.
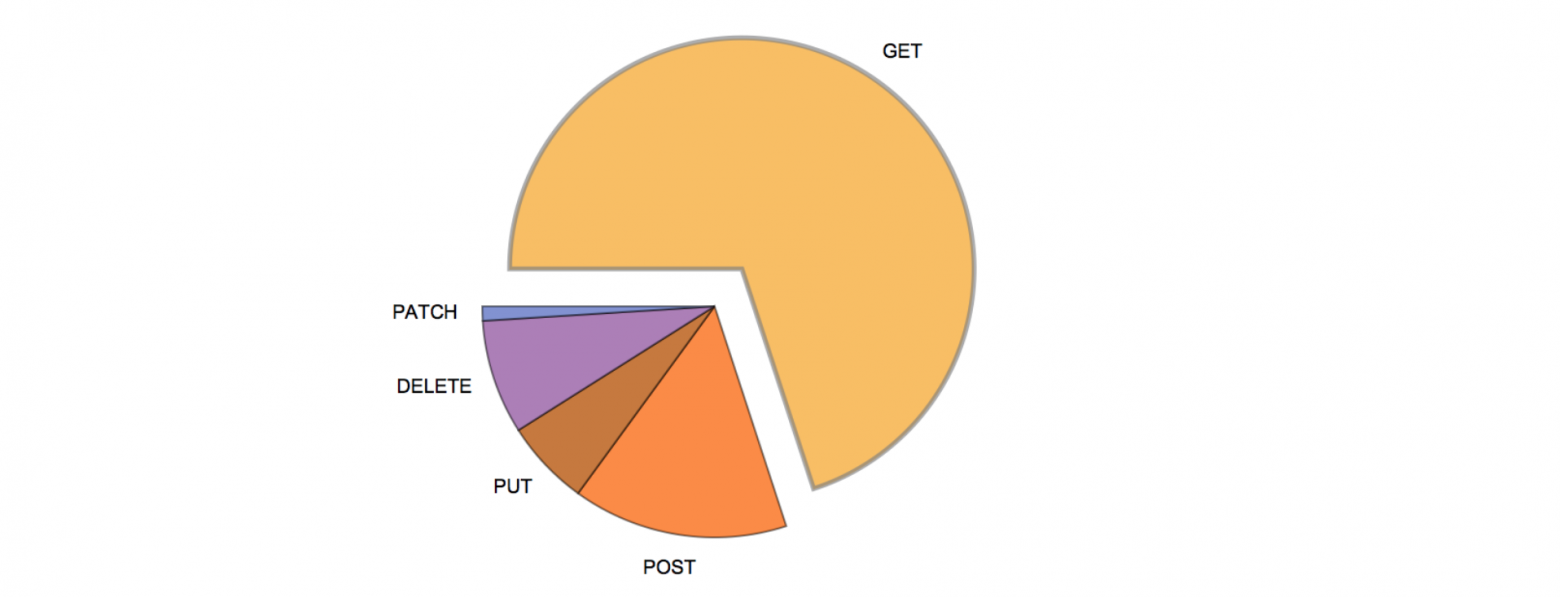
Распределение вызовов HTTP-методов веб-сервиса
Думаю, эти результаты отражают картину в целом по общедоступным веб-сервисам. Поэтому можно сказать, что в среднестатистическом API веб-сервиса методы чтения вызываются намного чаще методов записи.
Второе утверждение, которое я хотел бы выдвинуть, состоит в том, что если говорить о стопроцентной доступности, то клиентам сервиса на самом деле нужна такая доступность не всего богатства имеющихся методов API, а только тех, которые необходимы для продолжения «обычной» работы с системой и выполнения «обычных» запросов. Никто сильно не огорчится, если несколько минут будет недоступен метод, к которому обращаются пару раз в месяц. Зачастую «обычный» флоу покрывается методами чтения.
Поэтому обеспечение стопроцентной доступности только методов чтения уже можно рассматривать как возможный вариант кратковременного решения проблемы доступности системы при отказе дата-центра.
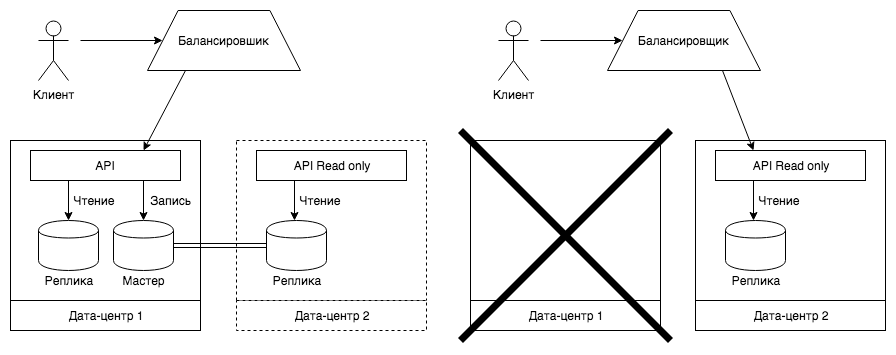
При сбоях в дата-центре мы хотели бы переключать трафик на дублирующую систему в другом дата-центре. В дублирующей системе должны быть доступны все методы чтения, а при вызове оставшихся методов, если без записи в базу данных никак нельзя обойтись, должна выводиться корректная ошибка.
В нормальном режиме работы запрос пользователя поступает на балансировщик, который в свою очередь перенаправляет его на основной API. В случае недоступности основного сервиса балансировщик определяет этот факт и перенаправляет запросы на дублирующую систему, работающую в режиме ограниченной функциональности. В это время команда анализирует проблему и принимает решение ждать восстановления работы дата-центра или переключать дублирующую систему в режим основной.
Нельзя создать систему, устойчивую ко всем видам сбоев. Тем не менее защититься от определенных видов — вполне посильная задача. Описанное в статье решение, позволяющее обеспечить доступность приложения при сбоях в работе дата-центра, может быть интересно и полезно в практическом применении во многих случаях.
Преобразовывать обычный веб-сервис в полностью распределенную систему ради защиты от гипотетических сбоев в дата-центре, скорее всего, нецелесообразно. На первый взгляд, даже предложенная схема кажется избыточной и «тяжелой», но эти минусы с лихвой перекрываются ее преимуществами и простотой имплементации. Можно провести аналогию со страхованием от несчастных случаев: существует большая вероятность, что такая страховка вам никогда не понадобится, однако если несчастный случай произойдет, она будет как нельзя более кстати. С предлагаемой схемой вы будете уверены, что у вас всегда наготове резервная система, которая при кратковременных проблемах обеспечит доступность большинства методов сервиса, а при долгих сбоях может полностью превратиться в основную в считаные минуты. Многие согласятся заплатить эту цену за такую уверенность.
Каждая система обладает своими уникальными параметрами нагрузки и требованиями к доступности. Вот почему не существует правильного или неправильного ответа на вопрос: «Можно ли всецело доверять Google Cloud или AWS?» — в каждой конкретной ситуации он будет свой.
Описание проблемы
В прошлом году нас коснулся инцидент в дата-центре известного облачного провайдера — один из наших сервисов полчаса был недоступен для пользователей. Тогда мы воочию убедились, что в случае проблем в ЦОДе облака рычаги для восстановления работоспособности приложения практически отсутствуют и для команды, ответственной за приложение, ничего не остается, кроме как смириться и ждать. Этот опыт заставил нас серьезно задуматься над использованием облаков для своих продуктов.
Что именно случилось в тот день, так и не удалось выяснить. Мы привыкли воспринимать облака как некий нерушимый форпост, но это не так. Правда состоит в том, что нет стопроцентной гарантии доступности сервиса в облаке, как и в любом другом месте. Облака — это абстракция, за которой скрываются все те же стойки с железом в дата-центрах и человеческий фактор. Любое железо рано или поздно выходит из строя (хотя для дата-центров аппаратные сбои — это скорее штатная ситуация). Помимо этого, известны случаи более серьезных проблем, приводящих к недоступности дата-центров: пожары, DDoS-атаки, стихийные бедствия, перебои с электричеством и интернетом и т. п.
Если говорить о человеческом факторе, то это не самая последняя причина аварий: «по статистике, в 80% сбоев сетевой инфраструктуры виноват человек». Люди, какими бы благими намерениями они ни руководствовались, ненадежны. Даже вы и ваши коллеги — лица, напрямую заинтересованные в стабильности поддерживаемых продуктов, — наверняка допускали ошибки, не говоря уже о персонале чужой компании, для которого ваши инстансы ничем не отличаются от тысяч других. Какая бы профессиональная команда ни стояла за инфраструктурой, новый сбой — это вопрос времени.
Всё имеет свою цену. При переезде в облако вы получаете простую абстракцию, с которой удобно работать, слабую зависимость от своего отдела operations взамен полного контроля над ситуацией. В этом случае, если вы не позаботитесь о себе заранее, предусмотрев возможность чужих ошибок, этого не сделает никто.
Варианты решения
Для нас недоступность сервиса даже в течение нескольких минут уже критична. Поэтому мы решили найти способ подстраховаться от аналогичных проблем в будущем, не отказываясь от облаков.
Приступая к решению проблемы доступности сервиса в облаке, стоит иметь в виду, что доступность довольно широкое понятие и в зависимости от того, что под ним подразумевают, рассматриваются и разные сценарии ее обеспечения. Хотя в данной статье обсуждается только проблема доступности в результате отказа дата-центра, уместно будет сказать пару слов о решениях других проблем доступности.
Доступность как техническая возможность предоставить доступ к ресурсу за конкретное время при определенной нагрузке. Проблема возникает, когда сервис работает, но из-за ограниченности ресурсов и архитектурных рамок системы не все пользователи могут получить к нему доступ за определенное время ответа. Задача чаще всего решается разворачиванием дополнительных инстансов с приложением. С таким масштабированием облака прекрасно справляются.
Доступность как доступность веб-сервиса для пользователей из определенного региона. Здесь очевидным решением является шардирование. Другими словами, разбиение системы на несколько независимых приложений в разных дата-центрах со своими данными и закрепление каждого пользователя за своим инстансом системы, например, на основе его геопозиции. При шардировании выход из строя одного дата-центра в худшем случае приведет к недоступности сервиса только для части привязанных к данному дата-центру пользователей. Не последний аргумент в пользу шардирования — это разное время пинга до дата-центра в различных регионах.
Впрочем, часто накладывание ограничений на работу с облаком и необходимость децентрализации — это законодательные требования, которые обычно учитывают еще на этапе проектирования системы. К таким требованиям можно отнести: закон Яровой — хранение персональных данных (ПД) пользователей в России; Общий регламент по защите данных (GDPR) — ограничения на трансграничную передачу ПД пользователей ЕС в некоторые страны; и китайская интернет-цензура, где ВСЕ коммуникации и ВСЕ части приложения должны находиться на территории Китая и, желательно, на их серверах.
Проблема технической недоступности дата-центра решается дублированием сервиса в другом дата-центре. Это непростая техническая задача. Основным препятствием в параллельном развертывании сервисов в разных дата-центрах является база данных. Обычно для небольших систем используется архитектура с одним мастером. В этом случае выход из строя дата-центра с мастером делает нерабочей всю систему. Схема репликации «мастер-мастер» возможна, но она накладывает сильные ограничения, которые не все понимают. По факту она не масштабирует запись в базу данных, а даже дает небольшой временной штраф, так как необходимо подтверждение всех узлов о том, что транзакция принята. Время операции записи еще больше возрастает, когда ноды должны быть разнесены по разным дата-центрам.
Обоснование решения
Анализ нагрузки на наш сервис показал, что в среднем около 70 % обращений к API приходится на GET-методы. Эти методы используют базу только для чтения данных.
Распределение вызовов HTTP-методов веб-сервиса
Думаю, эти результаты отражают картину в целом по общедоступным веб-сервисам. Поэтому можно сказать, что в среднестатистическом API веб-сервиса методы чтения вызываются намного чаще методов записи.
Второе утверждение, которое я хотел бы выдвинуть, состоит в том, что если говорить о стопроцентной доступности, то клиентам сервиса на самом деле нужна такая доступность не всего богатства имеющихся методов API, а только тех, которые необходимы для продолжения «обычной» работы с системой и выполнения «обычных» запросов. Никто сильно не огорчится, если несколько минут будет недоступен метод, к которому обращаются пару раз в месяц. Зачастую «обычный» флоу покрывается методами чтения.
Поэтому обеспечение стопроцентной доступности только методов чтения уже можно рассматривать как возможный вариант кратковременного решения проблемы доступности системы при отказе дата-центра.
Что мы хотим реализовать
При сбоях в дата-центре мы хотели бы переключать трафик на дублирующую систему в другом дата-центре. В дублирующей системе должны быть доступны все методы чтения, а при вызове оставшихся методов, если без записи в базу данных никак нельзя обойтись, должна выводиться корректная ошибка.
В нормальном режиме работы запрос пользователя поступает на балансировщик, который в свою очередь перенаправляет его на основной API. В случае недоступности основного сервиса балансировщик определяет этот факт и перенаправляет запросы на дублирующую систему, работающую в режиме ограниченной функциональности. В это время команда анализирует проблему и принимает решение ждать восстановления работы дата-центра или переключать дублирующую систему в режим основной.
Алгоритм реализации
Необходимые изменения в инфраструктуре
- Создание slave-репликации базы данных в другом дата-центре.
- Настройка деплоя веб-сервиса, сбор логов, метрик во втором дата-центре.
- Конфигурация балансировщика для переключения трафика на запасной дата-ценр в случае недоступности первого.
Изменения в коде:
- Добавление в веб-сервисе отдельного коннекта к реплике.
- Перенос всех роутов API, использующих только чтение, на реплику.
- Для оставшихся методов введение режима read only через переменную окружения или иной триггер, в котором они вместо записи в базу будут отрабатывать частично либо, если их функциональность ломается без записи в базу данных, выдавать корректную ошибку.
- Доработки на фронтенде для вывода корректной ошибки при вызове методов записи.
Плюсы и минусы описанного решения
Преимущества
- Основным достоинством предлагаемой схемы является то, что всегда есть дублирующий сервис, в любой момент готовый к обслуживанию пользователей. В случае проблем с основным дата-центром не придется на коленках писать сценарии деплоя в какую-то другую инфраструктуру и запускать все на скорую руку.
- Решение дешево в реализации и обслуживании. Если у вас микросервисная архитектура и для работы продукта нужен не один, а множество сервисов, то и в этом случае не должно возникнуть особых проблем с переводом всех микросервисов на данную схему.
- Отсутствует угроза потери данных, так как всегда имеется полная копия базы на реплике в другом дата-центре.
- Решение предназначено прежде всего для временного переключения трафика, до получаса. Именно этого получаса и не хватает, чтобы сориентироваться в случае проблем с инфраструктурой. Если в течение этого срока не происходит восстановления первого дата-центра, то slave-реплика базы данных превращается в мастер, а дублирующий сервис — в основной.
- В предложенной схеме приложение и база данных находятся в одном дата-центре. Если у вас API и база в разных дата-центрах, то лучше всего перенести их в один: это существенно сократит время выполнения запроса. Например, наши измерения показали, что для Google Cloud запрос от API к базе данных в пределах одного ЦОДа в среднем составляет 6 мс, а при походе за данными в другой дата-центр время возрастает на десятки миллисекунд.
Недостатки
- Главный недостаток всей схемы состоит в том, что для мгновенного переключения трафика требуется наличие балансировщика, не находящегося в одном дата-центре с основным сервисом. Балансировщик является точкой отказа: если откажет дата-центр с балансировщиком, то ваш сервис становится недоступен в любом случае.
- Необходимость деплоить код еще на один сервер, ставить под мониторинг дополнительные ресурсы — например, следить за репликой, чтобы не было отставания.
Заключение
Нельзя создать систему, устойчивую ко всем видам сбоев. Тем не менее защититься от определенных видов — вполне посильная задача. Описанное в статье решение, позволяющее обеспечить доступность приложения при сбоях в работе дата-центра, может быть интересно и полезно в практическом применении во многих случаях.
Преобразовывать обычный веб-сервис в полностью распределенную систему ради защиты от гипотетических сбоев в дата-центре, скорее всего, нецелесообразно. На первый взгляд, даже предложенная схема кажется избыточной и «тяжелой», но эти минусы с лихвой перекрываются ее преимуществами и простотой имплементации. Можно провести аналогию со страхованием от несчастных случаев: существует большая вероятность, что такая страховка вам никогда не понадобится, однако если несчастный случай произойдет, она будет как нельзя более кстати. С предлагаемой схемой вы будете уверены, что у вас всегда наготове резервная система, которая при кратковременных проблемах обеспечит доступность большинства методов сервиса, а при долгих сбоях может полностью превратиться в основную в считаные минуты. Многие согласятся заплатить эту цену за такую уверенность.
Каждая система обладает своими уникальными параметрами нагрузки и требованиями к доступности. Вот почему не существует правильного или неправильного ответа на вопрос: «Можно ли всецело доверять Google Cloud или AWS?» — в каждой конкретной ситуации он будет свой.

