Нравится ли вам при выполнении текущих задач отвлекаться на решение “срочных” вопросов в рабочих чатах? Думаем, что нет!
Представьте себе ситуацию: вы приступаете к задаче, но вас отвлекает уведомление в чатике, в котором вас срочно просят помочь с вопросом от пользователя. И вот вы уже участвуете в активном обсуждении и разбираетесь, баг это или фича.
А теперь представьте, что помимо вас в этом чатике присутствует весь отдел разработки, состоящий из 80+ человек, и каждый из участников вовлекается в эти обсуждения.
У нас в SuperJob техподдержка в любой непонятной ситуации сразу же писала в чаты в Slack и тем самым отвлекала всех участников от текущей деятельности. Поэтому мы — отдел тестирования — попробовали изменить процесс работы с багами от пользователей.

Раньше процесс работы с багами от пользователей у нас был такой:

В итоге получалось, что тратится много времени на обсуждение и перепроверку одной проблемы сразу несколькими специалистами. Также описание задачи не всегда позволяло быстро вникнуть в суть проблемы, поэтому приходилось открывать переписку техподдержки с пользователем, а затем еще тратить время на редактирование этой задачи.
Многие проблемы не являлись багами и вообще не должны были дойти до разработчиков. Но при этом разработчики уже включались в процесс обсуждения, отвлекаясь от своих задач.
Мы решили, что нам нужно изменить этот процесс и сделать техподдержку более самостоятельной.
Первое, что нам захотелось изменить — это избавиться от повторной перепроверки бага тестировщиком.
Решение было таким: мы описали workflow, по которому работают тестировщики, немного преобразовали его и передали специалистам техподдержки. Теперь они должны были проходить по нему при работе с проблемой от пользователя.
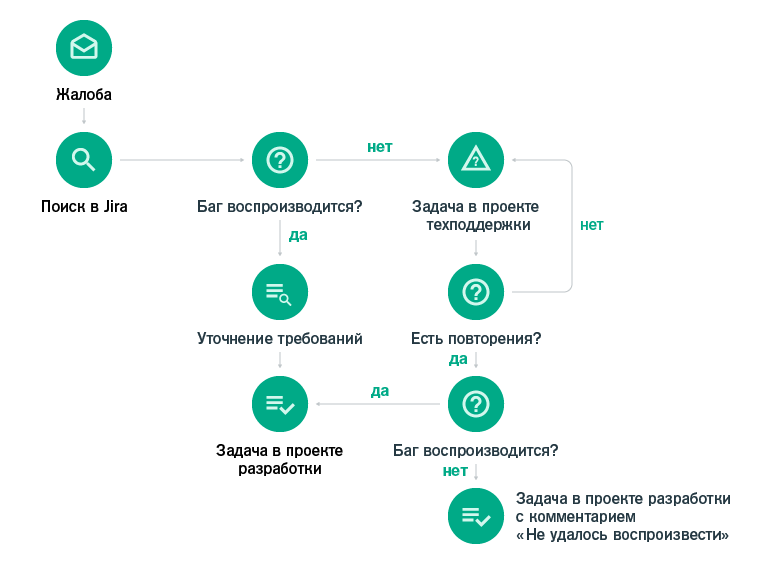
Если коротко описать этот workflow, то теперь специалист техподдержки самостоятельно перед заведением бага перепроверяет требования, обязательно воспроизводит ошибку и заводит задачу в проект разработки.
Если ситуация не воспроизводится, задача заводится в проекте техподдержки и “подвешивается” до следующего обращения пользователей. Если есть новые обращения от пользователей, техподу необходимо еще раз попробовать воспроизвести проблему, и если она воспроизводится, то перенести задачу в проект разработки.
Если повторная жалоба также не воспроизводится, то все равно задача переносится в проект разработки с обязательным комментарием о том, что проблему не удалось воспроизвести. Возможно в такой ситуации разработчики со своей стороны смогут разобраться и решить проблему.
Так мы не тратим много времени на единичные обращения и только в случае повторного обращения подключаем разработчиков.
Плюсы: мы экономим время специалиста по тестированию, а часто ещё и разработчиков, которые видели вопрос в чате и подключались к выяснениям.
Второй нашей проблемой было оформление самих багов, которые имели
неинформативное название, сумбурное, а порой и просто загадочное описание.
Например:

Решение: на примерах рассказали и показали, как мы составляем название для бага, используя принцип ”Что? Где? Когда?”.
Например, название задачи «трабла с “Вакансии на вашем сайте”» после переработки стало более прозрачным: «Не отображаются вакансии в блоке “Вакансии на вашем сайте” при переходе в раздел трансляции». Что за “трабла” произошла, стало уже всем понятно только из названия.
Договорились использовать шаблоны для описания. Они у нас добавлены в Jira. При создании бага необходимо выбрать нужный шаблон в зависимости от платформы и заполнить его.

Всю информацию зафиксировали в инструкции в Confluence, к которой всегда можно обращаться.
Плюсы: баги стало легче искать в Jira, а по названию сразу можно определить, в чем суть, не заходя в задачу. Описание стало структурированным и более понятным для разработчиков.
Третий отвлекающий всех фактор — это наличие нескольких чатиков с техподдержкой.
Решение: «Ещё больше чатиков!»

Мы решили сделать только один чат #support, а все остальные закрыть. В него теперь скидывают найденные проблемы все внутренние сотрудники, а отвечают там только ребята из техподдержки. Они же проводят перепроверки и заводят задачи.
Плюсы: теперь есть одна точка входа, куда можно сообщить о найденной проблеме.
Раньше разработчики могли увидеть какой-то баг, но просто не знали, куда о нем сообщить. Для начала нужно было разобраться, в какой чат это скинуть. Сложно… Поэтому некоторые просто не заморачивались и оставлять все как есть (ну или особо сознательные скидывали тестировщикам).
Но, конечно, не обошлось и без определенных сложностей при внедрении такого подхода. Например, специалист техподдержки не всегда может правильно локализовать проблему, определить, это backend или frontend. И из-за этого есть риск завести баг не в том проекте или не на ту команду, а потом снова потерять время на переносе задач из одного раздела в другой.
До сих пор есть ошибки в описаниях и названиях багов. Поэтому пока приходится отсматривать задачи для устранения этих недочетов, но их количество не такое критичное.
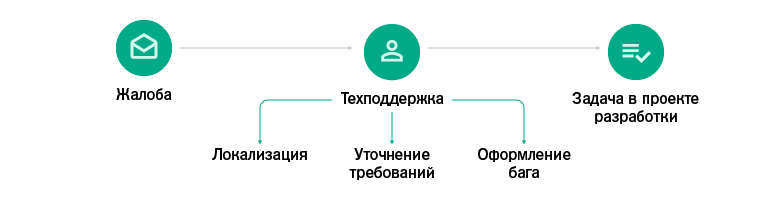
После всех нововведений наш workflow выглядит так:

А как у вас в компании устроен процесс работы с багами от пользователей? Делитесь своими примерами :)
Представьте себе ситуацию: вы приступаете к задаче, но вас отвлекает уведомление в чатике, в котором вас срочно просят помочь с вопросом от пользователя. И вот вы уже участвуете в активном обсуждении и разбираетесь, баг это или фича.
А теперь представьте, что помимо вас в этом чатике присутствует весь отдел разработки, состоящий из 80+ человек, и каждый из участников вовлекается в эти обсуждения.
У нас в SuperJob техподдержка в любой непонятной ситуации сразу же писала в чаты в Slack и тем самым отвлекала всех участников от текущей деятельности. Поэтому мы — отдел тестирования — попробовали изменить процесс работы с багами от пользователей.
Раньше процесс работы с багами от пользователей у нас был такой:
- в обратную связь поступала жалоба от пользователя и передавалась специалисту техподдержки;
- специалист техподдержки выяснял подробности, но не воспроизводил проблему, а сразу заводил задачу в Jira в проекте техподдержки;
- задача скидывалась в отдельный чатик в Slack (а чатиков таких, к слову, у нас было 6: по проблемам соискателей, работодателей и для каждой платформы в приложениях);
- в чате эту задачу брал тестировщик и начинал разбираться, локализовывать проблему и выяснять, как должно работать;
- кроме тестировщика в чат заходили также неравнодушные разработчики и принимали активное участие в обсуждении;
- после всех выяснений тестировщик переносил задачу в нужный проект разработки, менял название, корректировал описание.
В итоге получалось, что тратится много времени на обсуждение и перепроверку одной проблемы сразу несколькими специалистами. Также описание задачи не всегда позволяло быстро вникнуть в суть проблемы, поэтому приходилось открывать переписку техподдержки с пользователем, а затем еще тратить время на редактирование этой задачи.
Многие проблемы не являлись багами и вообще не должны были дойти до разработчиков. Но при этом разработчики уже включались в процесс обсуждения, отвлекаясь от своих задач.
Мы решили, что нам нужно изменить этот процесс и сделать техподдержку более самостоятельной.
Первое, что нам захотелось изменить — это избавиться от повторной перепроверки бага тестировщиком.
Решение было таким: мы описали workflow, по которому работают тестировщики, немного преобразовали его и передали специалистам техподдержки. Теперь они должны были проходить по нему при работе с проблемой от пользователя.
Если коротко описать этот workflow, то теперь специалист техподдержки самостоятельно перед заведением бага перепроверяет требования, обязательно воспроизводит ошибку и заводит задачу в проект разработки.
Если ситуация не воспроизводится, задача заводится в проекте техподдержки и “подвешивается” до следующего обращения пользователей. Если есть новые обращения от пользователей, техподу необходимо еще раз попробовать воспроизвести проблему, и если она воспроизводится, то перенести задачу в проект разработки.
Если повторная жалоба также не воспроизводится, то все равно задача переносится в проект разработки с обязательным комментарием о том, что проблему не удалось воспроизвести. Возможно в такой ситуации разработчики со своей стороны смогут разобраться и решить проблему.
Так мы не тратим много времени на единичные обращения и только в случае повторного обращения подключаем разработчиков.
Плюсы: мы экономим время специалиста по тестированию, а часто ещё и разработчиков, которые видели вопрос в чате и подключались к выяснениям.
Второй нашей проблемой было оформление самих багов, которые имели
неинформативное название, сумбурное, а порой и просто загадочное описание.
Например:
Решение: на примерах рассказали и показали, как мы составляем название для бага, используя принцип ”Что? Где? Когда?”.
Например, название задачи «трабла с “Вакансии на вашем сайте”» после переработки стало более прозрачным: «Не отображаются вакансии в блоке “Вакансии на вашем сайте” при переходе в раздел трансляции». Что за “трабла” произошла, стало уже всем понятно только из названия.
Договорились использовать шаблоны для описания. Они у нас добавлены в Jira. При создании бага необходимо выбрать нужный шаблон в зависимости от платформы и заполнить его.
Всю информацию зафиксировали в инструкции в Confluence, к которой всегда можно обращаться.
Плюсы: баги стало легче искать в Jira, а по названию сразу можно определить, в чем суть, не заходя в задачу. Описание стало структурированным и более понятным для разработчиков.
Третий отвлекающий всех фактор — это наличие нескольких чатиков с техподдержкой.
Решение: «Ещё больше чатиков!»
Мы решили сделать только один чат #support, а все остальные закрыть. В него теперь скидывают найденные проблемы все внутренние сотрудники, а отвечают там только ребята из техподдержки. Они же проводят перепроверки и заводят задачи.
Плюсы: теперь есть одна точка входа, куда можно сообщить о найденной проблеме.
Раньше разработчики могли увидеть какой-то баг, но просто не знали, куда о нем сообщить. Для начала нужно было разобраться, в какой чат это скинуть. Сложно… Поэтому некоторые просто не заморачивались и оставлять все как есть (ну или особо сознательные скидывали тестировщикам).
Но, конечно, не обошлось и без определенных сложностей при внедрении такого подхода. Например, специалист техподдержки не всегда может правильно локализовать проблему, определить, это backend или frontend. И из-за этого есть риск завести баг не в том проекте или не на ту команду, а потом снова потерять время на переносе задач из одного раздела в другой.
До сих пор есть ошибки в описаниях и названиях багов. Поэтому пока приходится отсматривать задачи для устранения этих недочетов, но их количество не такое критичное.
После всех нововведений наш workflow выглядит так:
- специалисты техподдержки стали более самостоятельными, им не нужно ждать перепроверки бага тестировщиками;
- баг от пользователя заводится в Jira быстрее и может быть раньше взят в разработку;
- тестировщики и разработчики не отвлекаются от своих задач;
- разработчики теперь могут
устраивать холиваробщаться в чатиках на более интересные темы.
А как у вас в компании устроен процесс работы с багами от пользователей? Делитесь своими примерами :)

