Тема отказоустойчивости в системах хранения данных всегда является актуальной, поскольку в наш век повсеместной виртуализации и консолидации ресурсов СХД является тем звеном, отказ которого приведет не просто к заурядной аварии, а к длительным простоям сервисов. Поэтому современные СХД имеют в своем составе множество дублированных компонент (вплоть до контроллеров). Но достаточна ли такая защита?

Абсолютно все вендоры, перечисляя характеристики СХД, обязательно упоминают о высокой отказоустойчивости своих решений, непременно добавляя термин «без единой точки отказа». Взглянем повнимательнее на типичную систему хранения данных. Для исключения простоя в обслуживании в СХД дублируются блоки питания, модули охлаждения, порты ввода/вывода, накопители (имеем ввиду RAID) и конечно же контроллеры. Если внимательно присмотреться к данной архитектуре, можно заметить, как минимум, две потенциальные точки отказа, о которых скромно умалчивают:
- Наличие единого бэкплейна (backplane)
- Наличие одной копии данных
Бэкплейн – технически сложное устройство, которое обязательно подвергается серьезному тестированию при производстве. И поэтому крайне редко встречаются случаи, когда он целиком выходи�� из строя. Однако даже в случае частичных неполадок вроде неработающего слота накопителя потребуется его замена с полным отключением СХД.
Создание нескольких копий данных тоже на первый взгляд не является проблемой. Так, например, функционал Clone в СХД, позволяющий актуализировать с некоторой периодичностью полную копию данных, распространен достаточно широко. Однако в случае проблем с тем же бэкплейном копия будет так же недоступна, как и оригинал.
Вполне очевидный выход для преодоления данных недостатков – это репликация на другую СХД. Если закрыть глаза на вполне ожидаемое удвоение стоимости «железа» (все же мы предполагаем, что выбирающие подобное решение люди адекватно мыслят и заранее принимают этот факт), останутся еще возможные расходы на организацию репликации в виде лицензий, дополнительного программного и аппаратного обеспечения. И главное – потребуется каким-то образом обеспечить консистентность реплицируемых данных. Т.е. строить виртуализатор СХД/vSAN/пр., что также требует денежных и временных ресурсов.
AccelStor при создании своих High Availability систем поставили целью избавиться от упомянутых выше недостатков. Так появилась интерпретация технологии Shared Nothing, что в вольном переводе означает «без использования общих устройств».
Концепция Shared Nothing архитектуре представляет собой использование двух независимых нод (контроллеров), каждая из которых имеет свой набор данных. Между нодами производится синхронная репликация через интерфейс InfiniBand 56G абсолютно прозрачно для программного обеспечения, работающего поверх системы хранения. В результате не требуется применения виртуализаторов СХД, программных агентов и пр.
Физически двухнодовое решение от AccelStor может быть выполнено в двух моделях:
- H510 — на базе Twin серверов в корпусе 2U, если требуются умеренная производительность и емкость до 22ТБ;
- H710 — на базе отдельных 2U серверов, если требуется высокая производительность и большая емкость (до 57ТБ).

Модель H510 на базе Twin сервера
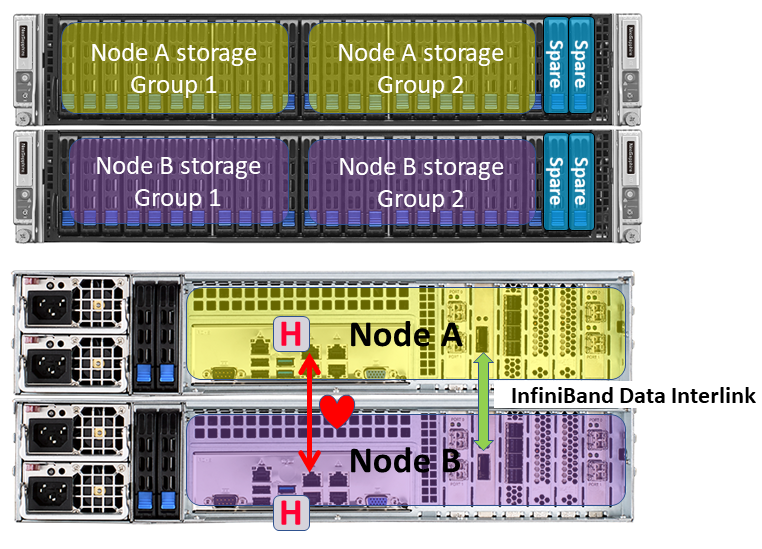
Модель H710 на базе отдельных серверов
Использование разных форм-факторов обусловлено необходимостью в разном количестве SSD для достижения заданного объема и производительности. Плюс, Twin платформа дешевле и позволяет предлагать более доступные по цене решения, хоть и с некоторым условным «недостатком» в виде единого бэкплейна. Все остальное, включая принципы работы, у обоих моделей полностью идентично.
Набор данных у каждой ноды имеет две группы FlexiRemap, плюс 2 hot spare. Каждая группа способна выдержать отказ одного SSD. Все поступающие запросы на запись нода в соответствии с идеологией FlexiRemap перестраивает в последовательные цепочки с блоками 4КБ, которые затем записываются на SSD в максимально комфортном для них режиме (последовательная запись). Причем хосту подтверждение записи выдается только после физического размещения данных на SSD, т.е. без кэширования в RAM. В результате достигается весьма впечатляющая производительность до 600K IOPS на запись и 1M+ IOPS на чтение (модель H710).
Как уже упоминалось ранее, синхронизация наборов данных происходит в режиме реального времени через интерфейс InfiniBand 56G, обладающий высокой пропускной способностью и низкими задержками. Для того, чтобы максимально эффективно использовать канал связи при передаче малых пакетов. Т.к. канал связи один, для дополнительной проверки пульса используется выделенный 1GbE линк. Через него передается только heartbeat, поэтому требований к скоростным характеристикам не предъявляются.
В случае увеличения емкости системы (до 400+ТБ) за счет полок расширения они также подключаются парами для соблюдения концепции «без единой точки отказа».
Для дополнительной защиты данных (помимо того, что у AccelStor и так две копии) используется особый алгоритм поведения в случае отказа какого-либо SSD. Если SSD выйдет из строя, нода начнет ребилд данных на один из накопителей hot spare. Группа FlexiRemap, находящаяся в состоянии degraded, перейдет в режим read only. Делается это для исключения интерференций операций записи и ребилда на резервный диск, что в итоге ускоряет процесс восстановления и сокращает время, когда система потенциально уязвима. По завершению ребилда нода снова переходит в нормальный режим работы read-write.
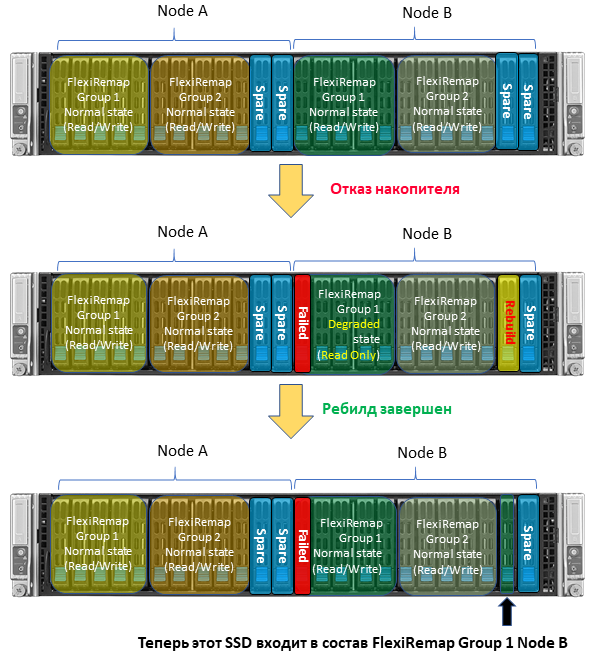
Конечно, как и у прочих систем, во время ребилда снижается общая производительность (ведь на запись не работает одна из групп FlexiRemap). Но сам процесс восстановления происходит максимально быстро, что выгодно отличает системы AccelStor от решений прочих вендоров.
Еще одним полезным свойством технологии Nothing Shared архитектуре работа нод в так называемом режиме true active-active. В отличие от «классической» архитектуры, где конкретным томом/пулом владеет только один контроллер, а второй просто выполняет операции ввода/вывода, в системах AccelStor каждая нода работает со своим набором данных и не передает запросы «соседке». В результате повышается общая производительность системы за счет параллельной обработки запросов ввода/вывода нодами и доступа к накопителям. Также фактически отсутствует такое понятие, как failover, поскольку передавать управление томами другой ноде в случае сбоя просто не нужно.
Если сравнивать технологию Nothing Shared архитектуры с полноценным дублированием СХД, то она, на первый взгляд, немного уступит полноценной реализации disaster recovery в гибкости. Особенно это касается организации линии связи между системами хранения. Так, в модели H710 возможно разнести ноды на расстояние до 100м за счет использования не совсем дешевых активных оптических кабелей InfiniBand. Но даже если сравнивать с обычной реализацией синхронной репликации у других вендоров через доступный FibreChannel даже на бОльшие расстояния, решение от AccelStor окажется дешевле и проще в инсталляции/эксплуатации, т.к. нет необходимости устанавливать виртуализаторы СХД и/или производить интеграцию с программным обеспечением (что далеко не всегда возможно в принципе). Плюс, не забываем, что решения AccelStor – это All Flash массивы с производительностью выше, чем у «классических» СХД с SSD only.

При использовании технологии Nothing Shared архитектуре от AccelStor реально получить доступность системы хранения на уровне 99.9999% за вполне разумную стоимость. Вместе с высокой надежностью решения, в том числе за счет использования двух копий данных, и впечатляющей производительности благодаря фирменным алгоритмам FlexiRemap, решения от AccelStor являются отличными кандидатами на ключевые позиции при построении современного датацентра.

