Примечание. Сокращенный перевод, скорее пересказ своими словами.
UPD: как отметили в комментариях, примеры не идеальны. Автор не ищет лучшее решение задачи, его цель объяснить сложность алгоритмов «на пальцах».
Big O нотация нужна для описания сложности алгоритмов. Для этого используется понятие времени. Тема для многих пугающая, программисты избегающие разговоров о «времени порядка N» обычное дело.
Если вы способны оценить код в терминах Big O, скорее всего вас считают «умным парнем». И скорее всего вы пройдете ваше следующее собеседование. Вас не остановит вопрос можно ли уменьшить сложность какого-нибудь куска кода до n log n против n^2.
Структуры данных
Выбор структуры данных зависит от конкретной задачи: от вида данных и алгоритма их обработки. Разнообразные структуры данных (в .NET или Java или Elixir) создавались под определенные типы алгоритмов.
Часто, выбирая ту или иную структуру, мы просто копируем общепринятое решение. В большинстве случаев этого достаточно. Но на самом деле, не разобравшись в сложности алгоритмов, мы не можем сделать осознанный выбор. К теме структур данных можно переходить только после сложности алгоритмов.
Здесь мы будем использовать только массивы чисел (прямо как на собеседовании). Примеры на JavaScript.
Начнем с самого простого: O(1)
Возьмем массив из 5 чисел:
const nums = [1,2,3,4,5];
Допустим надо получить первый элемент. Используем для это индекс:
const nums = [1,2,3,4,5]; const firstNumber = nums[0];
Насколько это сложный алгоритм? Можно сказать: «совсем не сложный — просто берем первый элемент массива». Это верно, но корректнее описывать сложность через количество операций, выполняемых для достижения результата, в зависимости от ввода (операций на ввод).
Другими словами: насколько возрастет кол-во операций при увеличении кол-ва входных параметров.
В нашем примере входных параметров 5, потому что в массиве 5 элементов. Для получения результата нужно выполнить одну операцию (взять элемент по индексу). Сколько операций потребуется если элементов массива будет 100? Или 1000? Или 100 000? Все равно нужна только одна операция.
Т.е.: «одна операция для всех возможных входных данных» — O(1).
O(1) можно прочитать как «сложность порядка 1» (order 1), или «алгоритм выполняется за постоянное/константное время» (constant time).
Вы уже догадались что O(1) алгоритмы самые эффективные.
Итерации и «время порядка n»: O(n)
Теперь давайте найдем сумму элементов массива:
const nums = [1,2,3,4,5]; let sum = 0; for(let num of nums){ sum += num; }
Опять зададимся вопросом: сколько операций на ввод нам потребуется? Здесь нужно перебрать все элементы, т.е. операция на каждый элемент. Чем больше массив, тем больше операций.
Используя Big O нотацию: O(n), или «сложность порядка n (order n)». Так же такой тип алгоритмов называют «линейными» или что алгоритм «линейно масштабируется».
Анализ
Можем ли мы сделать суммирование более эффективным? В общем случае нет. А если мы знаем, что массив гарантированно начинается с 1, отсортирован и не имеет пропусков? Тогда можно применить формулу S = n(n+1)/2 (где n последний элемент массива):
const sumContiguousArray = function(ary){ //get the last item const lastItem = ary[ary.length - 1]; //Gauss's trick return lastItem * (lastItem + 1) / 2; } const nums = [1,2,3,4,5]; const sumOfArray = sumContiguousArray(nums);
Такой алгоритм гораздо эффективнее O(n), более того он выполняется за «постоянное/константное время», т.е. это O(1).
Фактически операций не одна: нужно получить длину массива, получить последний элемент, выполнить умножение и деление. Разве это не O(3) или что-нибудь такое? В Big O нотации фактическое кол-во шагов не важно, важно что алгоритм выполняется за константное время.
Алгоритмы с константным временем это всегда O(1). Тоже и с линейными алгоритмами, фактически операций может быть O(n+5), в Big O нотации это O(n).
Не самые лучшие решения: O(n^2)
Давайте напишем функцию которая проверяет массив на наличие дублей. Решение с вложенным циклом:
const hasDuplicates = function (num) { //loop the list, our O(n) op for (let i = 0; i < nums.length; i++) { const thisNum = nums[i]; //loop the list again, the O(n^2) op for (let j = 0; j < nums.length; j++) { //make sure we're not checking same number if (j !== i) { const otherNum = nums[j]; //if there's an equal value, return if (otherNum === thisNum) return true; } } } //if we're here, no dups return false; } const nums = [1, 2, 3, 4, 5, 5]; hasDuplicates(nums);//true
Мы уже знаем что итерирование массива это O(n). У нас есть вложенный цикл, для каждого элемента мы еще раз итерируем — т.е. O(n^2) или «сложность порядка n квадрат».
Алгоритмы с вложенными циклами по той же коллекции всегда O(n^2).
«Сложность порядка log n»: O(log n)
В примере выше, вложенный цикл, сам по себе (если не учитывать что он вложенный) имеет сложность O(n), т.к. это перебор элементов массива. Этот цикл заканчивается как только будет найден нужный элемент, т.е. фактически не обязательно будут перебраны все элементы. Но в Big O нотации всегда рассматривается худший вариант — искомый элемент может быть самым последним.
Здесь вложенный цикл используется для поиска заданного элемента в массиве. Поиск элемента в массиве, при определенных условиях, можно оптимизировать — сделать лучше чем линейная O(n).
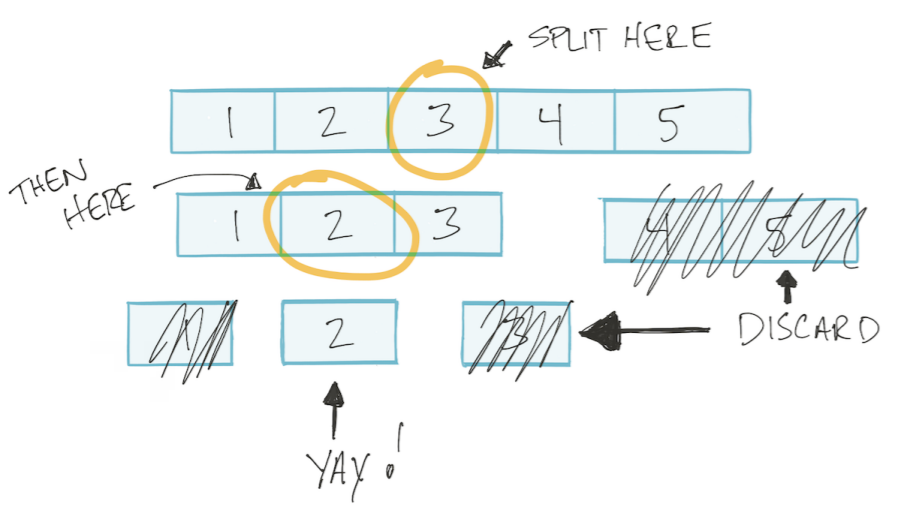
Пускай массив будет отсортирован. Тогда мы сможем использовать алгоритм «бинарный поиск»: делим массив на две половины, отбрасываем не нужную, оставшуюся опять делим на две части и так пока не найдем нужное значение. Такой тип алгоритмов называется «разделяй и влавствуй» Divide and Conquer.
Этот алгоритм основан на логарифме.
Быстрый обзор логарифмов
Рассмотрим пример, чему будет равен x?
x^3 = 8
Нужно взять кубический корень от 8 — это будет 2. Теперь посложнее
2^x = 512
С использованием логарифма задачу можно записать так
log2(512) = x
«логарифм по основанию 2 от 512 равен x». Обратите внимание «основание 2», т.е. мы мыслим двойками — сколько раз нужно перемножить 2 что бы получить 512.
В алгоритме «бинарный поиск» на каждом шаге мы делим массив на две части.
Мое дополнение. Т.е. в худшем случае делаем столько операций, сколько раз можем разделить массив на две части. Например, сколько раз мы можем разделить на две части массив из 4 элементов? 2 раза. А массив из 8 элементов? 3 раза. Т.е. кол-во делений/операций = log2(n) (где n кол-во элементов массива).
Получается, что зависимость кол-ва операций от кол-ва элементов ввода описывается как log2(n)
Таким образом, используя нотацию Big O, алгоритм «бинарный поиск» имеет сложность O(log n).
Улучшим O(n^2) до O(n log n)
Вернемся к задачке проверки массива на дубли. Мы перебирали все элементы массива и для каждого элемента еще раз делали перебор. Делали O(n) внутри O(n), т.е. O(n*n) или O(n^2).
Мы можем заменить вложенный цикл на бинарный поиск*. Т.е. у нас остается перебор всех элементов O(n), внутри делаем O(log n). Получается O(n * log n), или O(n log n).
const nums = [1, 2, 3, 4, 5]; const searchFor = function (items, num) { //use binary search! //if found, return the number. Otherwise... //return null. We'll do this in a later chapter. } const hasDuplicates = function (nums) { for (let num of nums) { //let's go through the list again and have a look //at all the other numbers so we can compare if (searchFor(nums, num)) { return true; } } //only arrive here if there are no dups return false; }
* ВНИМАНИЕ, во избежание Импринтинга. Использовать бинарный поиск для проверки массива на дубли — плохое решение. Здесь лишь показывается как в терминах Big O оценить сложность алгоритма показанного в листинге кода выше. Хороший алгоритм или плохой — для данной заметки не важно, важна наглядность.
Мышление в терминах Big O
- Получение элемента коллекции это O(1). Будь то получение по индексу в массиве, или по ключу в словаре в нотации Big O это будет O(1)
- Перебор коллекции это O(n)
- Вложенные циклы по той же коллекции это O(n^2)
- Разделяй и властвуй (Divide and Conquer) всегда O(log n)
- Итерации которые используют Divide and Conquer это O(n log n)
Самореклама
Делаю быстрый бесплатный редактор блок-схем и интеллект карт https://dgrm.net/

