Введение
Как узнать, что человек понял, что такое монады? Он сам вам об этом расскажет в первые 5 минут общения и обязательно попробует объяснить. А ещё напишет об этом текст и по возможности где-нибудь его опубликует, чтобы все остальные тоже поняли, что такое монады.
Среди функциональных программистов, особенно на Haskell, монады стали чем-то вроде локального мема. Их часто пытаются объяснить, отталкиваясь от частных случаев и сразу приводя примеры использования. Из-за этого слушатель может не уловить основную суть понятия, а монады так и останутся чёрной магией, ну или просто средством костылизации побочных эффектов в чисто функциональных языках.
Я сначала расскажу про базовые понятия теории категорий, а затем мы с практической точки зрения подойдём к определению монады и увидим, что на самом деле очень многие программисты пользуются этой мощной абстракцией в одном из её проявлений.
Моё изложение во многом основывается на книге Бартоша Милевски "Теория категорий для программистов", которая создавалась как серия блогпостов, доступна в PDF, а недавно вышла в бумаге.
Примеры приводятся на Haskell, предполагается, что читатель знаком с синтаксисом и основными понятиями языка. В упомянутой книге есть примеры и на С++, можете сравнить чистоту и понятность кода.

Категории
Определение
Категории сами по себе — очень простые конструкции. Категория — это набор объектов и морфизмов между ними. Морфизмы можно рассматривать как однонаправленные стрелки, соединяющие объекты. В общем случае про сущность самих объектов ничего не известно. Теория категорий работает не с объектами, а с морфизмами, точнее — с их композицией.
Используется следующая нотация:
- ObC — объекты категории C;
- HomC(A, B) — морфизмы из A в B;
- g ∘ f — композиция морфизмов f и g.
В определении категории на морфизмы накладываются дополнительные ограничения:
- Для пары морфизмов f и g, если f — морфизм из A в B (f ∈ Hom(A, B)), g — морфизм из B в C (g ∈ Hom(B, C)), то существует их композиция g ∘ f — морфизм из A в C (g ∘ f ∈ Hom(A, C)).
- Для каждого объекта задан тождественный морфизм idA ∈ Hom(A, A).
Существуют два важных свойства, которым должна удовлетворять любая категория (аксиомы теории категорий):
- Ассоциативность композиции: h ∘ (g ∘ f) = (h ∘ g) ∘ f;
- Композиция с тождественным морфизмом: если f ∈ Hom(A, B), то f ∘ idA = idB ∘ f = f.
Категории очень легко и естественно визуализируются как ориентированные графы. В принципе, любой ориентированный граф можно достроить до категории, добавив композиции морфизмов и тождественные морфизмы, если необходимо.

Для любой категории можно определить двойственную категорию (обозначается Cop, в которой морфизмы получены разворотом стрелок исходной категории, а объекты — те же самые. Это позволяет формулировать двойственные утверждения и теоремы, истинность которых не меняется при обращении стрелок.
Объекты и морфизмы не обязательно образуют множества (в классическом смысле из теории множеств), поэтому в общем случае используется словосочетание "класс объектов". Категории, в которых классы объектов и морфизмов всё-таки являются множествами, называются малыми категориями. Далее мы будем работать только с ними.
Типы и функции
Рассмотрим категорию, в которой объектами являются типы языка Haskell, а морфизмами — функции. Например, типы Int и Bool — это примеры объектов, а функция типа Int -> Bool — морфизм.
Тождественным морфизмом является функция id, возвращающая свой аргумент:
id :: a -> a id x = x
Композиция морфизмов — это композиция функций, причём синтаксис этой операции на Haskell почти идентичен математической нотации:
f :: a -> b g :: b -> c g . f :: a -> c (g . f) x = g (f x)
Категория, в которой объекты представляют собой множества, а морфизмы — отображения, называется Set. Типы также можно рассматривать как множества допустимых значений, а функции — как отображения множеств, но с одной оговоркой: вычисления могут не завершиться. Для обозначения такой ситуации вводится специальный тип bottom, обозначаемый _|_. Считается, что любая функция либо возвращает значение типа, указанного в сигнатуре, либо значение типа bottom. Категория типов языка Haskell, в которой учитывается эта особенность, называется Hask. Для упрощения изложения мы будем работать с ней так же, как с категорией Set. Любопытно, что в этой категории морфизмы между двумя объектами в свою очередь образуют множество, которое является объектом в этой же категории: HomC(A, B) ∈ C. Действительно, функциональный тип a -> b — это тоже тип языка Haskell.
Рассмотрим несколько примеров типов с точки зрения теории категорий.
Пустому множеству соответствует тип Void, у которого нет значений (такой тип называется ненаселённым). Существует даже полиморфная функция absurd, которую можно определить, но невозможно вызвать, поскольку для вызова ей нужно передать значение типа Void, а таких значений нет:
absurd :: Void -> a
Множеству из одного элемента соответствует тип Unit, единственное значение которого — пустой кортеж, также обозначаемый (). Полиморфная функция unit возвращает это значение, принимая на вход любой другой тип:
unit :: a -> Unit unit _ = ()
Множество из двух элементов — логический тип Bool:
data Bool = True | False
Построим категорию, объектами в которой являются типы Void, Unit и Bool.
Из Void выходят только морфизмы, соответствующие функции absurd, один в Bool, один в Unit. В обратную сторону морфизмов нет, поскольку мы никак не можем получить значения ненаселённого типа Void, просто потому что их не существует, а значит и не можем определить тело этой функции.
Функция типа Bool -> Unit может быть только одна, unit, поскольку независимо от входного значения мы можем вернуть только пустой кортеж. А вот для реализации функции типа Unit -> Bool возможны варианты. Такая функция в любом случае будет принимать значение (), но вернуть можно либо True, либо False. Таким образом, получили два морфизма из Unit в Bool:
true, false :: a -> Bool true _ = True false _ = False
Морфизмы из Bool в Bool — это булевы функции от одного аргумента, которых 4 штуки (в общем случае количество булевых функций от n аргументов — 22n): id, true и false, которые мы уже определяли выше, а также функция not:
not :: Bool -> Bool not True = False not False = True
Добавив тождественные морфизмы, получим следующую категорию:

В дальнейшем изложении будем использовать Haskell-подобную нотацию сигнатуры типов для обозначения морфизмов.
Функторы
Функтор — это отображение категорий. Для двух категорий, C и D, функтор F осуществляет два вида преобразований. Во-первых, функтор преобразует объекты из категории C в объекты из категории D. Если a — объект из категории C, то F a — соответствующий ему объект из категории D, полученный в результате применения функтора. Во-вторых, функтор действует на морфизмы: морфизм f :: a -> b в категории C преобразуется в морфизм F f :: F a -> F b в категории D.
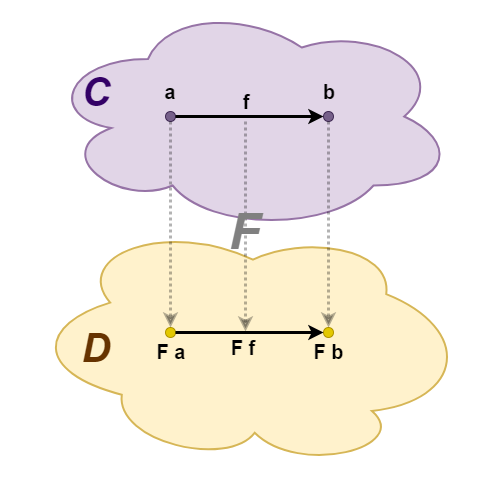
Кроме того, должны выполняться "законы сохранения" композиции и тождественного морфизма:
- Если h = g ∘ f, то F h = F g ∘ F f.
- Если ida — тождественный морфизм для объекта a, то F ida = idF a — тождественный морфизм для объекта F a.
Таким образом, функтор не "ломает" структуру категории: то, что было связано морфизмом в исходной категории, будет связано и в результирующей. Это верно и для крайних случаев, например, когда результирующая категория состоит из одного объекта и одного (тождественного) морфизма. Тогда все морфизмы исходной категории отобразятся в тождественный морфизм для этого объекта, но упомянутые выше законы нарушены не будут.
Функторы можно комбинировать аналогично функциям. Для двух функторов, F :: C -> D и G :: D -> E можно определить композицию G . F :: C -> E. Кроме того, для каждой категории несложно построить тождественный функтор, который будет переводить как объекты, так и морфизмы, в самих себя. Обозначим их IdC, IdD и IdE. Функторы, действующие из категории в неё саму, называются эндофункторы.
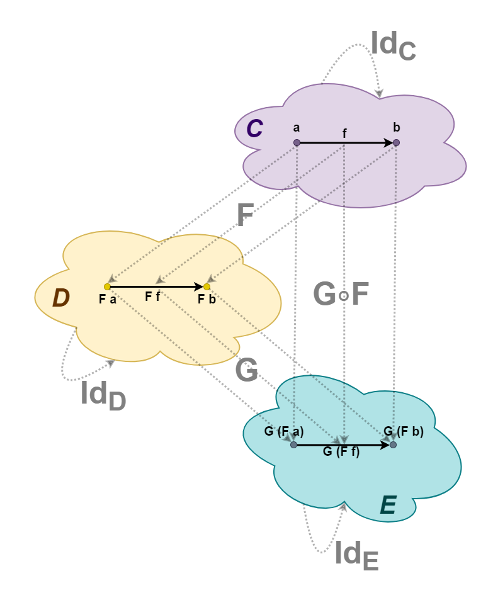
Посмотрим на эту картинку сильно издалека, так, чтобы сами категории превратились в точки-объекты, а функторы — в стрелки между ними (морфизмы). Получим категорию малых категорий, которая называется Cat (название периодически порождает сложные мемы с кошками).
Вернёмся к категории типов языка Haskell и будем работать с эндофункторами в этой категории. Они преобразуют типы в другие типы и, кроме того, каким-то образом преобразуют функции, работающие с этими типами.
Конструктор типа Maybe является примером такого функтора, он преобразует тип a в тип Maybe a (сам по себе Maybe не является типом!):
data Maybe a = Nothing | Just a
Для преобразования морфизмов, необходимо уметь получать из функции f :: a -> b функцию F f :: Maybe a -> Maybe b. Это действие можно записать в виде функции высшего порядка fmap. Обратите внимание, что тип этой функции как раз наглядно описывает преобразование морфизмов (из одной функции получаем другую):
-- f F f -- /------\ /------------------\ fmap :: (a -> b) -> (Maybe a -> Maybe b) fmap _ Nothing = Nothing fmap f (Just x) = Just (f x)
Конечно, Maybe — не единственный функтор. Существует целый класс типов, который так и называется, Functor. Единственным методом этого класса является функция fmap, показывающая, как преобразуются морфизмы (а преобразование объектов — это применение конструктора типа к конкретным типам):
class Functor f where fmap :: (a -> b) -> f a -> f b
В более прикладном смысле функторы — это контейнеры, которые хранят значения других типов, а функция fmap позволяет преобразовывать объекты внутри этих контейнеров. Если опустить скобки вокруг f a -> f b, как это сделано в определении выше, то такая сигнатура лучше подойдёт для описания функторов как контейнеров.
Монады
Все функции, которые были рассмотрены до этого, были чистыми, т.е. предполагалось, что у них нет побочных эффектов. Это функции в математическом смысле: результат чистой функции зависит только от значения её аргумента, он не меняется из-за места или времени вызова.
Поставим перед собой задачу логгировать вызовы функций. На императивном языке проще всего было бы хранить лог как глобальное состояние, которое изменяется в теле каждой функции. Программирование на функциональных языках не располагает к использованию глобального состояния, поэтому будем решать поставленную задачу, оперируя имеющимися у нас чистыми функциями — морфизмами в категории типов языка Haskell.
В качестве примера возьмём функции для преобразования строк: upCase, переводящую все символы строки в верхний регистр, и toWords, разбивающую строки на слова. Пока что их реализация всего лишь использует встроенные функции toUpper и words:
upCase :: String -> String upCase = map toUpper toWords :: String -> [String] toWords = words
Типы функций позволяют составить их композицию:
processString :: String -> [String] processString = toWords . upCase
Чтобы не отвлекаться на сложности реализации, в качестве представления лога возьмём просто строку. Мы хотим, чтобы после применения функции processString в логе содержалась запись "upCase toWords".
Запись в лог — побочное действие функций, мало относящееся к их основному функционалу. Хотелось бы во-первых, добавить информацию на уровне типов о том, что будет выполняться логгирование, и во-вторых, минимизировать дополнительные действия, которые придётся проделать сторонним разработчикам для работы с этими функциями.
Создадим новый тип данных, который будет помимо самих значений типа a хранить ещё и строку, в которую каждая вызванная функция будет добавлять своё имя.
newtype Writer a = Writer (a, String)
Заметим, что Writer — это функтор, мы легко можем описать для него функцию fmap:
instance Functor Writer where fmap f (Writer (x, s)) = Writer (f x, s)
Преобразуем функции upCase и toWords и сделаем так, чтобы они возвращали значение, "завёрнутое" в тип Writer:
upCase :: String -> Writer String upCase s = Writer (map toUpper s, "upCase ") toWords :: String -> Writer [String] toWords s = Writer (words s, "toWords ")
Теперь мы больше не можем записать композицию этих функций так же, как раньше, из-за несоответствия типов. Определим специальную функцию для композиции, которая сначала получает значение типа b и первую строку, передаёт это значение второй функции, получает значение типа c и вторую строку и в качестве финального результата возвращает значение типа c и конкатенацию строк, полученных при вычислении:
compose :: (a -> Writer b) -> (b -> Writer c) -> (a -> Writer c) compose f g = \x -> let Writer (y, s1) = f x Writer (z, s2) = g y in Writer (z, s1 ++ s2)
Реализация функции processString принимает вид:
processString :: String -> [String] processString = compose upCase toWords
Вернёмся к понятиям теории категорий. Мы можем заменить все функции (морфизмы) типа a -> b на a -> Writer b и получить новую категорию, в которой такие функции являются новыми морфизмами между a и b. Осталось только определить тождественный морфизм, т.е. функцию типа a -> Writer a:
writerId :: a -> Writer a writerId x = Writer (x, "")
Таким образом, мы получили новую категорию, основанную на Hask. В этой категории объектами являются те же типы, но морфизмом между типами a и b являются функции типа не a -> b, а a -> m b, т.е. возвращаемый тип "завёрнут" в какой-то другой фиксированный конструктор типа m. Такие функции мы будем называть обогащёнными (embellished). Композиция морфизмов и тождественный морфизм зависят от m, реализация для Writer — лишь частный случай.
Обобщим сказанное выше для любой категории C и эндофунктора m. Построим категорию K, состоящую из тех же объектов, что и категория C, т.е. ObK = ObC. Морфизм a -> b в категории K соответствует морфизму a -> m b в исходной категории C: HomK(a, b) = HomC(a, m b). Для типов и функций это будет означать, что функции, работающие с типами в категории K — обогащённые функции в категории C.
Для того, чтобы получить настоящую категорию с такими морфизмами, необходимо определить ассоциативную композицию морфизмов и тождественный морфизм для каждого объекта таким образом, чтобы соблюдались аксиомы теории категорий. Тогда полученная категория называется категорией Клейсли, а функтор m — монадой. На Haskell это определение выглядит так (везде далее используются типы из категории Hask):
class Monad m where -- композиция морфизмов категории Клейсли (>=>) :: (a -> m b) -> (b -> m c) -> (a -> m c) -- тождественный морфизм return :: a -> m a
Тип оператора >=>, который иногда называют "fish", показывает суть монад: это способ композиции обогащённых функций. Побочные эффекты, работа с состоянием, исключения — всё это лишь частные случаи, они не определяют, что такое монады, но являются хорошими примерами их использования. Writer — тоже монада, определённая нами функция compose — это композиция морфизмов >=>, а функция writerId — тождественный морфизм return.
Начнём реализовывать оператор >=> в общем виде. Результатом композиции двух обогащённых функций должна быть тоже функция, поэтому в реализации используем лямбда-выражение. Аргумент этого выражения имеет тип a, и у нас есть функция f, которую к нему можно применить, а дальше работать с результатом её вычисления во вспомогательной функции, которую назовём bind:
f >=> g = \a -> let mb = f a in (bind mb g) where bind :: m b -> (b -> m c) -> m c
Функция bind получает значение типа b "в контейнере" m и функцию, которая принимает на вход аргумент типа b и возвращает m c. Тип результата у неё совпадает с типом результата >=>. Мы получили следующую сигнатуру типов: m b -> (b -> m c) -> m c. Эту функцию необходимо реализовать для каждой монады, чтобы описать способ композиции обогащённых функций. Мы подошли к "классическому" определению монад в Haskell в виде класса типов с методами >>=, или bind, и return:
class Monad m where (>>=) :: m a -> (a -> m b) -> m b return :: a -> m a
Теперь попробуем продолжить реализацию в общем виде, для чего каким-то образом нужно применить функцию типа b -> m c к значению типа b, но у нас есть только значение типа m b. Вспомним, что изначально мы работаем с эндофунктором m, поэтому можем воспользоваться функцией fmap, которая в данном случае будет типа (a -> m b) -> m a -> m (m b). Для завершения реализации >>= необходимо преобразовать значение типа m (m b) к m b, "схлопнув" контейнеры, но это уже невозможно сделать в общем виде. Выразим это преобразование как функцию join:
ma >>= g = join (fmap g ma) where join :: m (m a) -> m a
Например, для типа Writer реализация будет следующей:
join :: Writer (Writer a) -> Writer a join (Writer ((Writer (x, s2)), s1)) = Writer (x, s1 ++ s2)
Мы пришли к третьему определению класса Monad:
class Functor m => Monad m where join :: m (m a) -> m a return :: a -> m a
Здесь присутствует явное требование на то, чтобы m был функтором. Это ограничение не было нужно для предыдущих определений, поскольку функция fmap реализуется через >>=:
fmap :: (a -> b) -> m a -> m b fmap f ma = ma >>= (\a -> return (f a))
Практическое применение монад
Приведём примеры практического применения монад для решения задач, которые традиционно решаются с использованием "нечистых" функций и побочных эффектов.
Недетерминированные вычисления
Абстракция недетерминированных вычислений (т.е. таких, у которых может быть несколько возможных результатов) реализуется с помощью списков.
Композиция обогащённых функций должна иметь тип (a -> [b]) -> (b -> [c]) -> (a -> [c]). Достаточно опытному программисту реализация может быть понятна из одной этой сигнатуры:
(>=>) :: (a -> [b]) -> (b -> [c]) -> (a -> [c]) f >=> g = \x -> concat (map g (f x))
Типы практически не оставляют возможности сделать неверный шаг. Получив значение типа a, единственное, что можно с ним сделать — это применить функцию f и получить список [b]. Далее всё, что мы умеем делать со значениями типа b — применить функцию g к каждому из них в списке и получить в результате список списков: map g (f x) :: [[c]]. Чтобы получить нужный результат, конкатенируем их.
Тогда оператор >>= можно записать так:
(>>=) :: [a] -> (a -> [b]) -> [b] xs >>= f = concat (map f xs)
Осталось реализовать функцию return :: a -> [a]. Здесь реализация снова выводится из типа:
return :: a -> [a] return x = [x]
Резюмируем эти реализации в классическом определении класса Monad:
instance Monad [] where xs >>= f = concat (map f xs) return x = [x]
Конечно, список как результат функции не обязательно обозначает недетерминированность вычислений. Хорошим примером, когда это действительно так, является реализация искусственного интеллекта для игр. Список может представлять возможные результаты хода игрока, ответных ходов может быть тоже несколько — всё время приходится работать со списками, списками списков и т.д.
Исключения
Простейшая реализация обработки исключений в чистых функциях состоит в добавлении в тип возвращаемого значения специального варианта, обозначающего, что что-то пошло не так.
Для этого подойдёт, к примеру, уже рассмотренный функтор Maybe. При штатной работе функции будут возвращать значение в конструкторе Just, при возникновении ошибки — значение Nothing. Композиция таких обогащённых функций должна работать таким образом, чтобы каждая следующая функция не вызывалась, если ошибка уже произошла в предыдущем вызове:
(>=>) :: (a -> Maybe b) -> (b -> Maybe c) -> (a -> Maybe c) f >=> g = \x -> case f x of Just y -> g y Nothing -> Nothing
Определение методов класса Monad для Maybe:
instance Monad Maybe where (Just x) >>= f = f x Nothing >>= f = Nothing return x = Just x
Недостаток этого подхода состоит в том, что исключение никак не конкретизируется. Мы просто знаем, что в какой-то из функций, участвовавшей в композиции, произошла какая-то ошибка. С этой точки зрения удобнее будет использовать тип Either String a, который представляет собой альтернативу двух значений: либо это строка с описанием ошибки, либо результат штатной работы функции. В общем виде тип определяется так:
data Either a b = Left a | Right b
Для классификации ошибок можно использовать перечислимый тип или любую другую структуру данных, подходящую для конкретной задачи. Мы в примерах продолжим использовать просто строку. Введём синоним типа для работы с исключениями:
type WithException a = Either String a
Композиция функций описывается аналогично случаю с использованием Maybe:
(>=>) :: (a -> WithException b) -> (b -> WithException c) -> (a -> WithException c) f >=> g = \x -> case f x of Right y -> g y err -> err
Определение экземпляра класса Monad уже не должно вызывать трудностей:
instance Monad WithException where (Right x) >>= f = f x err >>= f = err return x = Right x
Состояния
Пример с логгером, с которого мы начинали, реализует работу с write-only состоянием, но хотелось бы использовать состояние и для чтения. Модифицируем тип функции a -> b так, чтобы получить обогащённую функцию, работающую с состоянием. Добавим в тип функции один аргумент, обозначающий текущее состояние, а также изменим тип возвращаемого значения (теперь это пара, состоящая из самого значения и изменённого состояния):
a -> s -> (b, s)
Объявим синоним типа для работы с состоянием:
newtype State s a = State (s -> (a, s))
Фиксируем тип состояния s и покажем, что State s является функтором. Нам понадобится вспомогательная функция runState:
runState :: State s a -> s -> (a, s) runState (State f) s = f s
Реализация класса Functor:
instance Functor (State s) where fmap f state = State st' where st' prevState = let (a, newState) = runState state prevState in (f a, newState)
Таким образом, обогащённые функции из a в b, в которых ведётся работа с состоянием, имеют тип a -> State s b, причём State s — функтор. Попробуем превратить его в монаду, реализовав их композицию:
(>=>) :: (a -> State s b) -> (b -> State s c) -> (a -> State s c) f >=> g = \x -> State (\s -> let (y, s') = runState (f x) s in runState (g y) s')
Отсюда получим реализацию класса Monad. Тождественный морфизм, функция return, ничего не делает с состоянием, а просто добавляет свой аргумент в пару-результат:
instance Monad (State s) where stateA >>= f = State (\s -> let (a, s') = runState stateA s in runState (f a) s') return a = State (\s -> (a, s))
Функция для чтения состояния должна всегда возвращать текущее состояния, ей не нужны аргументы. Можно сказать, что это морфизм из Unit в s в категории Клейсли, поэтому функция должна иметь тип Unit -> State s s:
get :: Unit -> State s s get _ = State (\s -> (s, s))
Конечно, в реализации Unit можно опустить. Здесь он добавлен для того, чтобы показать эту операцию с точки зрения теории категорий.
Запись состояния, наоборот, принимает новое значение состояния и записывает его. Нам важен только побочный эффект, но не возвращаемое значение, поэтому соответствующий морфизм идёт в обратную сторону, из s в Unit, а функция имеет тип s -> State s Unit:
put :: s -> State s Unit put s = State (\_ -> ((), s))
Реализация работы с состоянием вышла чуть более сложной, чем предыдущие примеры, но на её основе можно создать формальную модель для работы с вводом/выводом. В ней предполагается, что "окружающий мир" реализован в виде некоторого типа RealWorld, о котором неизвестно никаких подробностей. При общении с внешним миром программа получает на вход объект типа RealWorld и производит какие-то действия, в результате которых получает нужный ей результат и изменяет внешний мир (например, выводит строку на экран или читает символ из потока ввода). Эту абстрактную концепцию можно реализовать с помощью состояния:
type IO a = State RealWorld a
Тип IO — один из первых, о котором узнаёт начинающий пользователь Haskell, и наверняка сразу встречает пугающее слово "монада". Такой упрощённый взгляд на этот тип как на состояние для работы с внешним миром может помочь понять, почему это так. Кончено, это описание очень поверхностно, но полноценный рассказ о том, как на самом деле реализован ввод-вывод, зависит от компилятора и выходит далеко за рамки статьи.

