Начинаем неделю с полезного материала приуроченного к запуску курса «Алгоритмы для разработчиков». Приятного прочтения.

1. Обзор
Хеширование — отличный практический инструмент, с интересной и тонкой теорией. Помимо использования в качестве словарной структуры данных, хеширование также встречается во многих различных областях, включая криптографию и теорию сложности. В этой лекции мы опишем два важных понятия: универсальное хеширование (также известное как универсальные семейства хеш-функций) и идеальное хеширование.
Материал, освещенный в этой лекции, включает в себя:
2. Вступление
Мы рассмотрим основную проблему со словарем, которую мы обсуждали до этого, и рассмотрим две версии: статическую и динамическую:
Для первой проблемы мы могли бы использовать отсортированный массив и двоичный поиск. Для второй мы могли бы использовать сбалансированное дерево поиска. Однако хеширование дает альтернативный подход, который зачастую является самым быстрым и удобным способом решения этих проблем. Например, предположим, что вы пишете программу для AI-поиска и хотите хранить ситуации, которые вы уже разрешили (позиции на доске или элементы пространства состояний), чтобы не повторять те же вычисления, при столкновении с ними снова. Хеширование обеспечивает простой способ хранения такой информации. Также существует множество применений в криптографии, сетях, теории сложности.
3. Основы хеширования
Формальная постановка для хеширования заключается в следующем.
Одним из замечательных свойств хеширования является то, что все словарные операции невероятно просты в реализации. Чтобы выполнить поиск ключа x, просто вычислите индекс i = h(x) и затем идите по списку в A[i], пока не найдете его (или не выйдете из списка). Чтобы вставить, просто поместите новый элемент в верхней части его списка. Чтобы удалить, нужно просто выполнить операцию удаления в связанном списке. Теперь мы переходим к вопросу: что нам нужно для достижения хорошей производительности?
Желательные свойства. Основные желательные свойства для хорошей схемы хеширования:
Учитывая это, время поиска элемента x равно O(размер списка A[h(x)]). То же самое верно для удалений. Вставки занимают время O(1) независимо от длины списков. Итак, мы хотим проанализировать, насколько большими получаются эти списки.
Базовая интуиция: один из способов красиво распределить элементы — это распределить их случайным образом. К сожалению, мы не можем просто использовать генератор случайных чисел, чтобы решить, куда направить следующий элемент, потому что тогда мы никогда не сможем найти его снова. Итак, мы хотим, чтобы h было чем-то «псевдослучайным» в некотором формальном смысле.
Сейчас мы изложим некоторые плохие новости, а затем некоторые хорошие.
Утверждение 1 (Плохие новости) Для любой хэш-функции h, если |U| ≥ (N −1) M +1, существует множество S из N элементов, которые в��е хешируются в одном месте.
Доказательство: по принципу Дирихле. В частности, чтобы рассмотреть контрапозиции, если бы каждое местоположение имело не более N — 1 элементов U, хэширующих его, то U мог бы иметь размер не более M (N — 1).
Отчасти поэтому хэширование кажется таким загадочным — как можно утверждать, что хэширование хорошо, если для любой хэш-функции вы можете придумать способы ее предотвращения? Один из ответов заключается в том, что существует множество простых хеш-функций, которые хорошо работают на практике для типичных множеств S. Но что, если мы хотим получить хорошую гарантию наихудшего случая?
Вот ключевая идея: давайте использовать рандомизацию в нашей конструкции h, по аналогии с рандомизированной быстрой сортировкой. (Само собой разумеется, h будет детерминированной функцией). Мы покажем, что для любой последовательности операций вставки и поиска (нам не нужно предполагать, что набор вставленных элементов S является случайным), если мы выберем h таким вероятностным способом, производительность h в этой последовательности будет хорошо в ожидании. Таким образом, это та же самая гарантия, что и в рандомизированной быстрой сортировке или ловушках. В частности, это идея универсального хеширования.
Как только мы разработаем эту идею, мы будем использовать ее для особенно приятного приложения под названием «идеальное хеширование».
4. Универсальное хеширование
Определение 1. Рандомизированный алгоритм H для построения хеш-функций h: U → {1, …, М}
универсален, если для всех x != y в U имеем
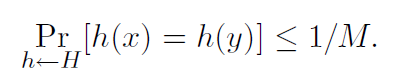
Мы также можем сказать, что множество H хеш-функций является универсальным семейством хеш-функций, если процедура «выбрать h ∈ H наугад» универсальна. (Здесь мы отождествляем множество функций с равномерным распределением по множеству.)
Теорема 2. Если H универсален, то для любого множества S ⊆ U размера N, для любого x ∈ U (например, который мы могли бы искать), если мы строим h случайным образом в соответствии с H, ожидаемое число коллизий между х и другими элементами в S не более N/M.
Доказательство: у каждого y ∈ S (y != x) есть не более 1 / M шанса столкновения с x по определению «универсального». Так,
Теперь мы получаем следующее следствие.
Следствие 3. Если H универсален, то для любой последовательности операций L вставки, поиска и удаления, в которых в системе одновременно может быть не более M элементов, ожидаемая общая стоимость L операций для случайного h ∈ H равна только O (L) (просмотр времени для вычисления h как константы).
Доказательство: для любой данной операции в последовательности ее ожидаемая стоимость постоянна по теореме 2, поэтому ожидаемая общая стоимость L операций равна O (L) по линейности ожидания.
Вопрос: можем ли мы на самом деле построить универсальную H? Если нет, то это все довольно бессмысленно. К счастью, ответ — да.
4.1. Создание универсального хеш-семейства: матричный метод
Допустим, ключи имеют длину u-бит. Скажем, размер таблицы M равен степени 2, поэтому индекс длиной b-битов с M = 2b.
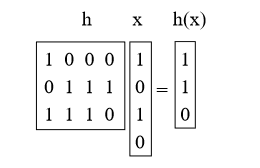
Что мы сделаем, это выберем h в качестве случайной матрицы 0/1 b-by-u и определим h (x) = hx, где мы добавим mod 2. Эти матрицы короткие и толстые. Например:
Утверждение 4. Для x != y Prh [h (x) = h (y)] = 1 / M = 1 / 2b.
Доказательство: во-первых, что означает умножение h на x? Мы можем думать об этом как о добавлении некоторых из столбцов h (делая векторное сложение mod 2), где 1 бит в x указывает, какие из них добавить. (например, мы добавили 1-й и 3-й столбцы h выше)
Теперь возьмем произвольную пару ключей x, y такую, что x != y. Они должны где-то отличаться, так что, скажем, они различаются по i-й координате, а для конкретности скажем xi = 0 и yi = 1. Представьте, что сначала мы выбрали все h, кроме i-го столбца. По оставшимся выборкам i-го столбца h (x) является фиксированным. Однако каждая из 2b различных настроек i-го столбца дает различное значение h (y) (в частности, каждый раз, когда мы переворачиваем бит в этом столбце, мы переворачиваем соответствующий бит в h (y)). Таким образом, есть точно 1 / 2b шанс, что h (x) = h (y).
Существуют и другие методы построения универсальных хеш-семейств, основанных также на умножении простых чисел (см. Раздел 6.1).
Следующий вопрос, который мы рассмотрим: если мы исправим множество S, сможем ли мы найти хеш-функцию h такую, что все поиски будут иметь постоянное время? Ответ — да, и это приводит к теме идеального хеширования.
5. Идеальное хеширование
Мы говорим, что хеш-функция является идеальной для S, если все поиски происходят за O(1). Вот два способа построения идеальных хеш-функций для заданного множества S.
5.1 Метод 1: решение в пространстве O(N2)
Скажем, мы хотим иметь таблицу, размер которой квадратичен по размеру N нашего словаря S. Тогда вот простой метод построения идеальной хеш-функции. Пусть H универсален и M = N2. Тогда просто выберите случайный h из H и попробуйте! Утверждение состоит в том, что есть по крайней мере 50% шанс, что у нее не будет коллизий.
Утверждение 5. Если H универсален и M = N2, то Prh∼H (нет коллизий в S) ≥ 1/2.
Доказательство:
• Сколько пар (x, y) есть в S? Ответ:
• Для каждой пары вероятность их столкновения составляет ≤ 1 / M по определению универсальности.
• Итак, Pr (существует коллизия) ≤ / M <1/2.
Это как другая сторона «парадокса дня рождения». Если количество дней намного больше, чем количество людей в квадрате, то есть разумный шанс, что ни у одной пары не будет одинакового дня рождения.
Итак, мы просто выбираем случайную h из H, и если возникают какие-либо коллизии, мы просто выбираем новую h. В среднем нам нужно будет сделать это только дважды. Теперь, что если мы хотим использовать только пространство O(N)?
5.2 Метод 2: решение в пространстве O(N)
Вопрос о том, можно ли достичь идеального хеширования в пространстве O(N), был в течение некоторого времени открытым: «Должны ли таблицы быть отсортированы?». То есть для фиксированного набора можно получить постоянное время поиска только с линейным пространством? Была серия все более и более сложных попыток, пока, наконец, она не была решена с использованием хорошей идеи универсальных хеш-функций в двухуровневой схеме.
Способ заключается в следующем. Сначала мы будем хэшировать в таблицу размера N, используя универсальное хеширование. Это приведет к некоторым коллизиям (если только нам не повезет). Однако затем мы перехешируем каждую корзину, используя метод 1, возводя в квадрат размер корзины, чтобы получить нулевые коллизии. Таким образом, схема состоит в том, что у нас есть хеш-функция первого уровня h и таблица A первого уровня, а затем N хеш-функций второго уровня h1,…, hN и N таблицы второго уровня A1,…, А.Н… Чтобы найти элемент x, мы сначала вычисляем i = h (x), а затем находим элемент в Ai [hi (x)]. (Если бы вы делали это на практике, вы могли бы установить флаг так, чтобы вы делали второй шаг, только если на самом деле были коллизии с индексом i, а в противном случае просто помещали бы сам x в A [i], но давайте не будем об этом беспокоиться здесь .)
Скажем, хеш-функция h хеширует n элементов S в местоположение i. Мы уже доказывали (анализируя метод 1), что мы можем найти h1,…, hN, так что общее пространство, используемое во вторичных таблицах, равно Pi (ni) 2. Осталось показать, что мы можем найти функцию первого уровня h такую, что Pi (ni) 2 = O (N). На самом деле, мы покажем следующее:
Теорема 6. Если мы выберем начальную точку h из универсального множества H, то
Доказательство. Докажем это, показав, что E [Pi (ni) 2] <2N. Это подразумевает то, что мы хотим от неравенства Маркова. (Если бы была вероятность даже 1/2, что сумма могла быть больше чем 4N, то этот факт сам по себе означал бы, что ожидание должно было быть больше чем 2N. Таким образом, если ожидание меньше чем 2N, вероятность отказа должна быть менее 1/2.)
Теперь, хитрый трюк заключается в том, что один из способов подсчитать это количество — подсчитать количество упорядоченных пар, у которых возникает коллизия, включая коллизии с самим собой. Например, если корзина имеет {d, e, f}, то у d возникнет коллизия с каждым из {d, e, f}, у e возникнет коллизия с каждым из {d, e, f}, и у f возникнет коллизия с каждым из {d, e, f}, поэтому мы получаем 9. Итак, мы имеем:
Итак, мы просто пробуем случайное h из H, пока не найдем такое, что Pi n2 i <4N, а затем, фиксируя эту функцию h, найдем N вторичных хеш-функций h1,…, hN как в методе 1.
6. Дальнейшее обсуждение
6.1 Еще один метод универсального хеширования
Вот еще один метод построения универсальных хеш-функций, который немного более эффективен, чем матричный метод, приведенный ранее.
В матричном методе мы рассматривали ключ как вектор битов. В этом методе вместо этого мы будем рассматривать ключ x как вектор целых чисел [x1, x2,…, xk] с единственным требованием, чтобы каждый xi находился в диапазоне {0, 1,..., М-1}. Например, если мы хешируем строки длиной k, то xi может быть i-м символом (если размер нашей таблицы не менее 256) или i-й парой символов (если размер нашей таблицы не менее 65536). Кроме того, мы будем требовать, чтобы размер нашей таблицы M был простым числом. Чтобы выбрать хеш-функцию h, мы выберем k случайных чисел r1, r2,…, рк из {0, 1,…, M — 1} и определить:
Доказательство того, что этот метод универсален, строится точно так же, как доказательство матричного метода. Пусть x и y два разных ключа. Мы хотим показать, что Prh (h (x) = h (y)) ≤ 1 / M. Поскольку x != y, должен быть случай, когда существует некоторый индекс i такой, что xi != yi. Теперь представьте, что сначала вы выбрали все случайные числа rj для j != i. Пусть h ′ (x) = Pj6 = i rjxj. Итак, выбрав ri, мы получим h (x) = h ′ (x) + rixi. Это означает, что у нас возникает коллизия между x и y именно тогда, когда
Поскольку M — простое, деление на ненулевое значение mod M является допустимым (каждое целое число от 1 до M −1 имеет мультипликативный обратный по модулю M), что означает, что существует ровно одно значение ri по модулю M, для которого выполняется приведенное выше уравнение истина, а именно ri = (h ′ (y) — h ′ (x)) / (xi — yi) mod M. Таким образом, вероятность этого происшествия равна точно 1 / M.
6.2 Другое использование хеширования
Предположим, у нас есть длинная последовательность элементов, и мы хотим увидеть, сколько разных элементов находятся в списке. Есть ли хороший способ сделать это?
Одним из способов является создать хеш-таблицу, а затем сделать один проход по последовательности, сделав для каждого элемента поиск и затем вставку, если его еще нет в таблице. Количество отдельных элементов — это просто количество вставок.
А теперь, что если список действительно огромен и у нас нет места для его хранения, но нам подойдёт приблизительный ответ. Например, представьте, что мы являемся маршрутизатором и наблюдаем, как проходит много пакетов, и мы хотим (приблизительно) увидеть, сколько существует различных IP-адресов источника.
Вот хорошая идея: скажем, у нас есть хеш-функция h, которая ведет себя как случайная функция, и давайте представим, что h (x) — действительное число от 0 до 1. Одна вещь, которую мы можем сделать, это просто отслеживать минимальный хеш стоимость произведена до сих пор (поэтому у нас не будет таблицы вообще). Например, если ключи 3,10,3,3,12,10,12 и h (3) = 0,4, h (10) = 0,2, h (12) = 0,7, то мы получим 0,2.
Дело в том, что если мы выберем N случайных чисел в [0, 1], ожидаемое значение минимума будет 1 / (N + 1). Кроме того, есть хороший шанс, что он довольно близок (мы можем улучшить нашу оценку, запустив несколько хеш-функций и взяв медиану минимумов).
Вопрос: зачем использовать хеш-функцию, а не просто выбирать случайное число каждый раз? Это потому, что мы заботимся о количестве различных элементов, а не только об общем количестве элементов (эта проблема намного проще: просто используйте счетчик...).
Друзья, была ли эта статья полезной для вас? Пишите в комментарии и присоединяйтесь ко дню открытых дверей, который пройдет уже 25 апреля.
1. Обзор
Хеширование — отличный практический инструмент, с интересной и тонкой теорией. Помимо использования в качестве словарной структуры данных, хеширование также встречается во многих различных областях, включая криптографию и теорию сложности. В этой лекции мы опишем два важных понятия: универсальное хеширование (также известное как универсальные семейства хеш-функций) и идеальное хеширование.
Материал, освещенный в этой лекции, включает в себя:
- Формальная постановка и общая идея хеширования.
- Универсальное хеширование.
- Идеальное хеширование.
2. Вступление
Мы рассмотрим основную проблему со словарем, которую мы обсуждали до этого, и рассмотрим две версии: статическую и динамическую:
- Статическая: дано множество элементов S, мы хотим хранить его таким образом, чтобы можно было быстро выполнять поиск.
- Например, фиксированный словарь.
- Динамическая: здесь у нас есть последовательность запросов на вставку, поиск и, возможно, удаление. Мы хотим сделать все это эффективно.
Для первой проблемы мы могли бы использовать отсортированный массив и двоичный поиск. Для второй мы могли бы использовать сбалансированное дерево поиска. Однако хеширование дает альтернативный подход, который зачастую является самым быстрым и удобным способом решения этих проблем. Например, предположим, что вы пишете программу для AI-поиска и хотите хранить ситуации, которые вы уже разрешили (позиции на доске или элементы пространства состояний), чтобы не повторять те же вычисления, при столкновении с ними снова. Хеширование обеспечивает простой способ хранения такой информации. Также существует множество применений в криптографии, сетях, теории сложности.
3. Основы хеширования
Формальная постановка для хеширования заключается в следующем.
- Ключи принадлежат некоторому большому множеству U. (Например, представьте, что U — набор всех строк длиной не более 80 символов ascii.)
- Есть некоторое множество ключей S в U, которое нам на самом деле нужно (ключи могут быть как статическими, так и динамическими). Пусть N = |S|. Представьте, что N гораздо меньше, чем размер U. Например, S — это множество имен учеников в классе, которое намного меньше, чем 128^80.
- Мы будем выполнять вставки и поиск с помощью массива A некоторого размера M и хеш-функции h: U → {0,…, М — 1}. Дан элемент x, идея хеширования состоит в том, что мы хотим хранить его в A[h(x)]. Обратите внимание, что если бы U было маленьким (например, 2-символьные строки), то можно было бы просто сохранить x в A[x], как в блочной сортировке. Проблема в том, что U большое, поэтому нам нужна хеш-функция.
- Нам нужен метод для разрешения коллизий. Коллизия — это когда h(x) = h(y) для двух разных ключей x и y. В этой лекции мы будем обрабатывать коллизии, определяя каждый элемент A как связанный список. Есть ряд других методов, но для проблем, на которых мы сосредоточимся здесь, это самый подходящий. Этот метод называется методом цепочек. Чтобы вставить элемент, мы просто помещаем его в начало списка. Если h — хорошая хеш-функция, то мы надеемся, что списки будут небольшими.
Одним из замечательных свойств хеширования является то, что все словарные операции невероятно просты в реализации. Чтобы выполнить поиск ключа x, просто вычислите индекс i = h(x) и затем идите по списку в A[i], пока не найдете его (или не выйдете из списка). Чтобы вставить, просто поместите новый элемент в верхней части его списка. Чтобы удалить, нужно просто выполнить операцию удаления в связанном списке. Теперь мы переходим к вопросу: что нам нужно для достижения хорошей производительности?
Желательные свойства. Основные желательные свойства для хорошей схемы хеширования:
- Ключи хорошо рассредоточены, чтобы у нас не было слишком много коллизий, так как коллизии влияют на время выполнения поиска и удаления.
- M = O(N): в частности, мы бы хотели, чтобы наша схема достигла свойства (1) без необходимости, чтобы размер таблицы M был намного больше, чем число элементов N.
- Функция h должна быстро вычисляться. В нашем сегодняшнем анализе мы будем рассматривать время для вычисления h(x) как константу. Тем не менее, стоит помнить, что она не должна быть слишком сложной, потому что это влияет на общее время выполнения.
Учитывая это, время поиска элемента x равно O(размер списка A[h(x)]). То же самое верно для удалений. Вставки занимают время O(1) независимо от длины списков. Итак, мы хотим проанализировать, насколько большими получаются эти списки.
Базовая интуиция: один из способов красиво распределить элементы — это распределить их случайным образом. К сожалению, мы не можем просто использовать генератор случайных чисел, чтобы решить, куда направить следующий элемент, потому что тогда мы никогда не сможем найти его снова. Итак, мы хотим, чтобы h было чем-то «псевдослучайным» в некотором формальном смысле.
Сейчас мы изложим некоторые плохие новости, а затем некоторые хорошие.
Утверждение 1 (Плохие новости) Для любой хэш-функции h, если |U| ≥ (N −1) M +1, существует множество S из N элементов, которые в��е хешируются в одном месте.
Доказательство: по принципу Дирихле. В частности, чтобы рассмотреть контрапозиции, если бы каждое местоположение имело не более N — 1 элементов U, хэширующих его, то U мог бы иметь размер не более M (N — 1).
Отчасти поэтому хэширование кажется таким загадочным — как можно утверждать, что хэширование хорошо, если для любой хэш-функции вы можете придумать способы ее предотвращения? Один из ответов заключается в том, что существует множество простых хеш-функций, которые хорошо работают на практике для типичных множеств S. Но что, если мы хотим получить хорошую гарантию наихудшего случая?
Вот ключевая идея: давайте использовать рандомизацию в нашей конструкции h, по аналогии с рандомизированной быстрой сортировкой. (Само собой разумеется, h будет детерминированной функцией). Мы покажем, что для любой последовательности операций вставки и поиска (нам не нужно предполагать, что набор вставленных элементов S является случайным), если мы выберем h таким вероятностным способом, производительность h в этой последовательности будет хорошо в ожидании. Таким образом, это та же самая гарантия, что и в рандомизированной быстрой сортировке или ловушках. В частности, это идея универсального хеширования.
Как только мы разработаем эту идею, мы будем использовать ее для особенно приятного приложения под названием «идеальное хеширование».
4. Универсальное хеширование
Определение 1. Рандомизированный алгоритм H для построения хеш-функций h: U → {1, …, М}
универсален, если для всех x != y в U имеем
Мы также можем сказать, что множество H хеш-функций является универсальным семейством хеш-функций, если процедура «выбрать h ∈ H наугад» универсальна. (Здесь мы отождествляем множество функций с равномерным распределением по множеству.)
Теорема 2. Если H универсален, то для любого множества S ⊆ U размера N, для любого x ∈ U (например, который мы могли бы искать), если мы строим h случайным образом в соответствии с H, ожидаемое число коллизий между х и другими элементами в S не более N/M.
Доказательство: у каждого y ∈ S (y != x) есть не более 1 / M шанса столкновения с x по определению «универсального». Так,
- Пусть Cxy = 1, если x и y сталкиваются, и 0 в противном случае.
- Пусть Cx обозначает общее количество столкновений для x. Итак, Cx = Py∈S, y != x Cxy.
- Мы знаем, что E [Cxy] = Pr (x и y сталкиваются) ≤ 1 / M.
- Таким образом, по линейности ожидания E [Cx] = Py E [Cxy] <N / M.
Теперь мы получаем следующее следствие.
Следствие 3. Если H универсален, то для любой последовательности операций L вставки, поиска и удаления, в которых в системе одновременно может быть не более M элементов, ожидаемая общая стоимость L операций для случайного h ∈ H равна только O (L) (просмотр времени для вычисления h как константы).
Доказательство: для любой данной операции в последовательности ее ожидаемая стоимость постоянна по теореме 2, поэтому ожидаемая общая стоимость L операций равна O (L) по линейности ожидания.
Вопрос: можем ли мы на самом деле построить универсальную H? Если нет, то это все довольно бессмысленно. К счастью, ответ — да.
4.1. Создание универсального хеш-семейства: матричный метод
Допустим, ключи имеют длину u-бит. Скажем, размер таблицы M равен степени 2, поэтому индекс длиной b-битов с M = 2b.
Что мы сделаем, это выберем h в качестве случайной матрицы 0/1 b-by-u и определим h (x) = hx, где мы добавим mod 2. Эти матрицы короткие и толстые. Например:
Утверждение 4. Для x != y Prh [h (x) = h (y)] = 1 / M = 1 / 2b.
Доказательство: во-первых, что означает умножение h на x? Мы можем думать об этом как о добавлении некоторых из столбцов h (делая векторное сложение mod 2), где 1 бит в x указывает, какие из них добавить. (например, мы добавили 1-й и 3-й столбцы h выше)
Теперь возьмем произвольную пару ключей x, y такую, что x != y. Они должны где-то отличаться, так что, скажем, они различаются по i-й координате, а для конкретности скажем xi = 0 и yi = 1. Представьте, что сначала мы выбрали все h, кроме i-го столбца. По оставшимся выборкам i-го столбца h (x) является фиксированным. Однако каждая из 2b различных настроек i-го столбца дает различное значение h (y) (в частности, каждый раз, когда мы переворачиваем бит в этом столбце, мы переворачиваем соответствующий бит в h (y)). Таким образом, есть точно 1 / 2b шанс, что h (x) = h (y).
Существуют и другие методы построения универсальных хеш-семейств, основанных также на умножении простых чисел (см. Раздел 6.1).
Следующий вопрос, который мы рассмотрим: если мы исправим множество S, сможем ли мы найти хеш-функцию h такую, что все поиски будут иметь постоянное время? Ответ — да, и это приводит к теме идеального хеширования.
5. Идеальное хеширование
Мы говорим, что хеш-функция является идеальной для S, если все поиски происходят за O(1). Вот два способа построения идеальных хеш-функций для заданного множества S.
5.1 Метод 1: решение в пространстве O(N2)
Скажем, мы хотим иметь таблицу, размер которой квадратичен по размеру N нашего словаря S. Тогда вот простой метод построения идеальной хеш-функции. Пусть H универсален и M = N2. Тогда просто выберите случайный h из H и попробуйте! Утверждение состоит в том, что есть по крайней мере 50% шанс, что у нее не будет коллизий.
Утверждение 5. Если H универсален и M = N2, то Prh∼H (нет коллизий в S) ≥ 1/2.
Доказательство:
• Сколько пар (x, y) есть в S? Ответ:
• Для каждой пары вероятность их столкновения составляет ≤ 1 / M по определению универсальности.
• Итак, Pr (существует коллизия) ≤
/ M <1/2.Это как другая сторона «парадокса дня рождения». Если количество дней намного больше, чем количество людей в квадрате, то есть разумный шанс, что ни у одной пары не будет одинакового дня рождения.
Итак, мы просто выбираем случайную h из H, и если возникают какие-либо коллизии, мы просто выбираем новую h. В среднем нам нужно будет сделать это только дважды. Теперь, что если мы хотим использовать только пространство O(N)?
5.2 Метод 2: решение в пространстве O(N)
Вопрос о том, можно ли достичь идеального хеширования в пространстве O(N), был в течение некоторого времени открытым: «Должны ли таблицы быть отсортированы?». То есть для фиксированного набора можно получить постоянное время поиска только с линейным пространством? Была серия все более и более сложных попыток, пока, наконец, она не была решена с использованием хорошей идеи универсальных хеш-функций в двухуровневой схеме.
Способ заключается в следующем. Сначала мы будем хэшировать в таблицу размера N, используя универсальное хеширование. Это приведет к некоторым коллизиям (если только нам не повезет). Однако затем мы перехешируем каждую корзину, используя метод 1, возводя в квадрат размер корзины, чтобы получить нулевые коллизии. Таким образом, схема состоит в том, что у нас есть хеш-функция первого уровня h и таблица A первого уровня, а затем N хеш-функций второго уровня h1,…, hN и N таблицы второго уровня A1,…, А.Н… Чтобы найти элемент x, мы сначала вычисляем i = h (x), а затем находим элемент в Ai [hi (x)]. (Если бы вы делали это на практике, вы могли бы установить флаг так, чтобы вы делали второй шаг, только если на самом деле были коллизии с индексом i, а в противном случае просто помещали бы сам x в A [i], но давайте не будем об этом беспокоиться здесь .)
Скажем, хеш-функция h хеширует n элементов S в местоположение i. Мы уже доказывали (анализируя метод 1), что мы можем найти h1,…, hN, так что общее пространство, используемое во вторичных таблицах, равно Pi (ni) 2. Осталось показать, что мы можем найти функцию первого уровня h такую, что Pi (ni) 2 = O (N). На самом деле, мы покажем следующее:
Теорема 6. Если мы выберем начальную точку h из универсального множества H, то
Pr[X
i
(ni)2 > 4N] < 1/2.Доказательство. Докажем это, показав, что E [Pi (ni) 2] <2N. Это подразумевает то, что мы хотим от неравенства Маркова. (Если бы была вероятность даже 1/2, что сумма могла быть больше чем 4N, то этот факт сам по себе означал бы, что ожидание должно было быть больше чем 2N. Таким образом, если ожидание меньше чем 2N, вероятность отказа должна быть менее 1/2.)
Теперь, хитрый трюк заключается в том, что один из способов подсчитать это количество — подсчитать количество упорядоченных пар, у которых возникает коллизия, включая коллизии с самим собой. Например, если корзина имеет {d, e, f}, то у d возникнет коллизия с каждым из {d, e, f}, у e возникнет коллизия с каждым из {d, e, f}, и у f возникнет коллизия с каждым из {d, e, f}, поэтому мы получаем 9. Итак, мы имеем:
E[X
i
(ni)2] = E[X
x
X
y
Cxy] (Cxy = 1 if x and y collide, else Cxy = 0)
= N +X
x
X
y6=x
E[Cxy]
≤ N + N(N − 1)/M (where the 1/M comes from the definition of universal)
< 2N. (since M = N)
Итак, мы просто пробуем случайное h из H, пока не найдем такое, что Pi n2 i <4N, а затем, фиксируя эту функцию h, найдем N вторичных хеш-функций h1,…, hN как в методе 1.
6. Дальнейшее обсуждение
6.1 Еще один метод универсального хеширования
Вот еще один метод построения универсальных хеш-функций, который немного более эффективен, чем матричный метод, приведенный ранее.
В матричном методе мы рассматривали ключ как вектор битов. В этом методе вместо этого мы будем рассматривать ключ x как вектор целых чисел [x1, x2,…, xk] с единственным требованием, чтобы каждый xi находился в диапазоне {0, 1,..., М-1}. Например, если мы хешируем строки длиной k, то xi может быть i-м символом (если размер нашей таблицы не менее 256) или i-й парой символов (если размер нашей таблицы не менее 65536). Кроме того, мы будем требовать, чтобы размер нашей таблицы M был простым числом. Чтобы выбрать хеш-функцию h, мы выберем k случайных чисел r1, r2,…, рк из {0, 1,…, M — 1} и определить:
h(x) = r1x1 + r2x2 + . . . + rkxk mod M.Доказательство того, что этот метод универсален, строится точно так же, как доказательство матричного метода. Пусть x и y два разных ключа. Мы хотим показать, что Prh (h (x) = h (y)) ≤ 1 / M. Поскольку x != y, должен быть случай, когда существует некоторый индекс i такой, что xi != yi. Теперь представьте, что сначала вы выбрали все случайные числа rj для j != i. Пусть h ′ (x) = Pj6 = i rjxj. Итак, выбрав ri, мы получим h (x) = h ′ (x) + rixi. Это означает, что у нас возникает коллизия между x и y именно тогда, когда
h′(x) + rixi = h′(y) + riyi mod M, or equivalently when
ri(xi − yi) = h′(y) − h′(x) mod M.Поскольку M — простое, деление на ненулевое значение mod M является допустимым (каждое целое число от 1 до M −1 имеет мультипликативный обратный по модулю M), что означает, что существует ровно одно значение ri по модулю M, для которого выполняется приведенное выше уравнение истина, а именно ri = (h ′ (y) — h ′ (x)) / (xi — yi) mod M. Таким образом, вероятность этого происшествия равна точно 1 / M.
6.2 Другое использование хеширования
Предположим, у нас есть длинная последовательность элементов, и мы хотим увидеть, сколько разных элементов находятся в списке. Есть ли хороший способ сделать это?
Одним из способов является создать хеш-таблицу, а затем сделать один проход по последовательности, сделав для каждого элемента поиск и затем вставку, если его еще нет в таблице. Количество отдельных элементов — это просто количество вставок.
А теперь, что если список действительно огромен и у нас нет места для его хранения, но нам подойдёт приблизительный ответ. Например, представьте, что мы являемся маршрутизатором и наблюдаем, как проходит много пакетов, и мы хотим (приблизительно) увидеть, сколько существует различных IP-адресов источника.
Вот хорошая идея: скажем, у нас есть хеш-функция h, которая ведет себя как случайная функция, и давайте представим, что h (x) — действительное число от 0 до 1. Одна вещь, которую мы можем сделать, это просто отслеживать минимальный хеш стоимость произведена до сих пор (поэтому у нас не будет таблицы вообще). Например, если ключи 3,10,3,3,12,10,12 и h (3) = 0,4, h (10) = 0,2, h (12) = 0,7, то мы получим 0,2.
Дело в том, что если мы выберем N случайных чисел в [0, 1], ожидаемое значение минимума будет 1 / (N + 1). Кроме того, есть хороший шанс, что он довольно близок (мы можем улучшить нашу оценку, запустив несколько хеш-функций и взяв медиану минимумов).
Вопрос: зачем использовать хеш-функцию, а не просто выбирать случайное число каждый раз? Это потому, что мы заботимся о количестве различных элементов, а не только об общем количестве элементов (эта проблема намного проще: просто используйте счетчик...).
Друзья, была ли эта статья полезной для вас? Пишите в комментарии и присоединяйтесь ко дню открытых дверей, который пройдет уже 25 апреля.

