Сравнительное тестирование многопоточных кэшей реализованных на C/C++ и описание как устроен LRU/MRU кэш серии O(n)Cache**RU
За десятки лет было разработано множество алгоритмов кэширования: LRU, MRU, ARC, и другие…. Однако когда понадобился кэш для многопоточной работы, гугление на эту тему дало полтора варианта, а вопрос на StackOverflow вообще остался без ответа. Нашел решение от Facebook которое опирается на потокобезопасные контейнеры репозитория Intel TBB. У последнего также есть многопоточный LRU кеш пока ещё в стадии бета-тестирования и поэтому для его использования требуется явно указать в проекте:
#define TBB_PREVIEW_CONCURRENT_LRU_CACHE true
Иначе компилятор покажет ошибку так как в Intel TBB коде стоит проверка:
#if ! TBB_PREVIEW_CONCURRENT_LRU_CACHE #error Set TBB_PREVIEW_CONCURRENT_LRU_CACHE to include concurrent_lru_cache.h #endif
Захотелось как-то сравнить производительность кэшей — какой выбрать? Или написать свой? Ранее, когда сравнивал однопоточные кэши (ссылка), получил предложения попробовать в других условиях с другими ключами и понял, что требуется более удобный расширяемый стенд для тестирования. Для того, чтобы было удобнее добавлять в тесты конкурирующие алгоритмы, решил оборачивать их в стандартный интерфейс:
class IAlgorithmTester { public: IAlgorithmTester() = default; virtual ~IAlgorithmTester() { } virtual void onStart(std::shared_ptr<IConfig> &cfg) = 0; virtual void onStop() = 0; virtual void insert(void *elem) = 0; virtual bool exist(void *elem) = 0; virtual const char * get_algorithm_name() = 0; private: IAlgorithmTester(const IAlgorithmTester&) = delete; IAlgorithmTester& operator=(const IAlgorithmTester&) = delete; };
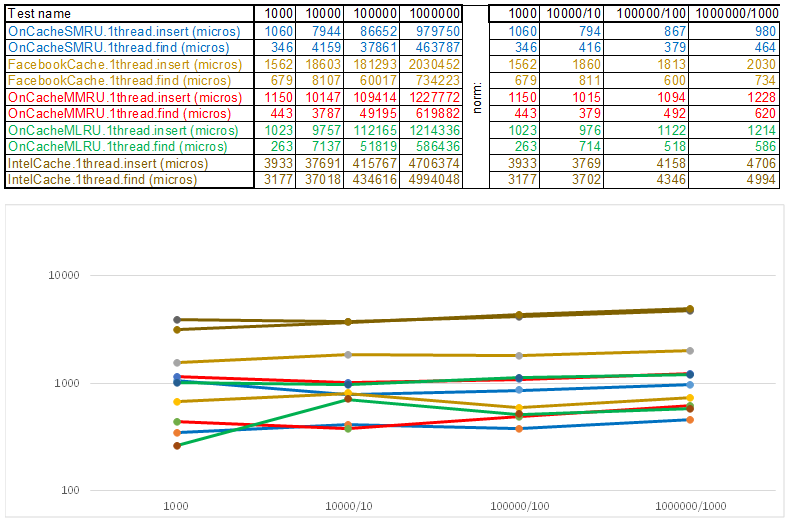
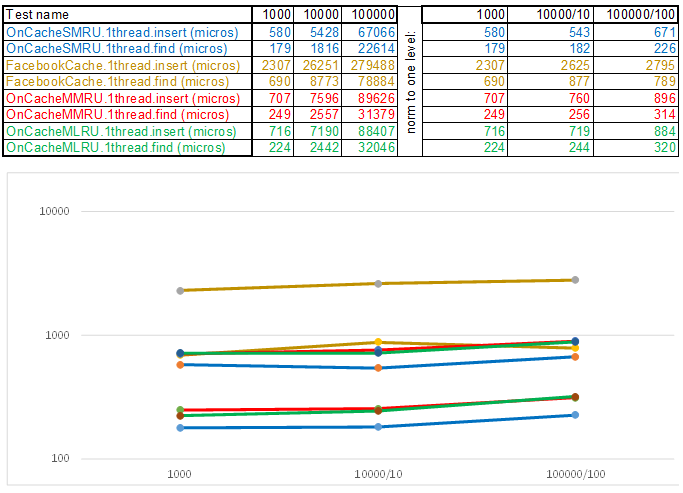
Аналогично в интерфейсы обвёрнуты: работа с операционной системой, получение настроек, тест-кейсы и др. Исходники выложены в репозиторий. Сейчас на стенде два тест-кейса: вставка/поиск до 1000000 элементов с ключом из случайно сгенерированных чисел и до 100000 элементов со строковым ключом (берётся из 10Мб строк wiki.train.tokens). Для оценки времени выполнения каждый тестируемый кэш сперва прогревается на целевой объем без временных замеров, затем семафор спускает с цепи потоки по добавлению и поиску данных. Количество потоков и настройки тест-кейсов задаются в assets/settings.json. Пошаговые инструкции по компиляции и описание JSON настроек описано в WiKi репозитория. Время засекается с момента спуска семафора и до остановки последней нити. Вот что получилось:
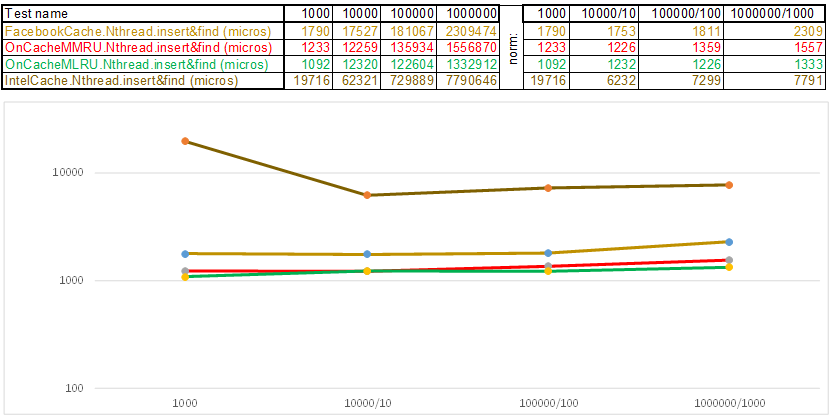
Тест-кейс1 — ключ в виде массива случайных чисел uint64_t keyArray[3]:
Тест-кейс2 — ключ в виде строки:
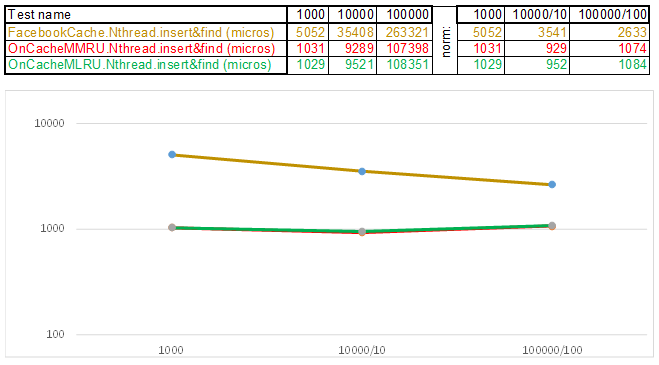
Обратите внимание на то что объём вставляемых/искомых данных на каждом шаге тест-кейса увеличивается в 10 раз. Затем время, которое ушло на обработку очередного объёма, я делю соответственно на 10, 100, 1000… Если алгоритм по временной сложности ведёт себя как O(n), то график времени будет оставаться примерно параллельным оси Х. Дальше раскрою сакральные знания, как удалось получить 3-5 кратное превосходство над кешем Facebook в алгоритмах серии O(n)Cache**RU при работе со строковым ключом:
- Хеш функция вместо того, чтобы считать каждую букву строки, просто кастит указатель на данные строки к uint64_t keyArray[3] и считает сумму целых чисел. То есть работает подобно передаче "Угадай мелодию" — а я угадаю мелодию по 3 нотам… 3 * 8 = 24 буквам если латиница, и это уже позволяет достаточно хорошо раскидать строки по хэш-корзинам. Да, в хэш-корзине может собраться много строк, и тут начинает давать ускорение алгоритм:
- Skip List в каждой корзине позволяет быстро двигаться скачками сперва по различающимся хэшам (id корзины = хэш % количество корзин, поэтому в одной корзине могут появиться разные хэши), затем в рамках одного хэша по вершинам:
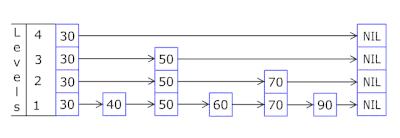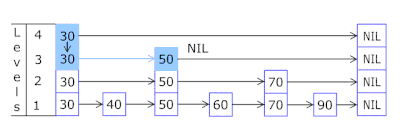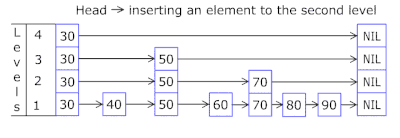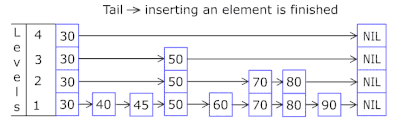
- Узлы в которых хранятся ключи и данные берутся из предварительно аллоцированного массива узлов, количество узлов совпадает с ёмкостью кэша. Atomic идентификатор указывает, какой узел брать следующим — если доходит до конца пула узлов, то начинает с 0 = так аллокатор ходит по кругу перезатирая старые узлы (LRU кэш в OnCacheMLRU).
Для случая, когда необходимо, чтобы в кэше сохранялись самые популярные в поисковых запросах элементы, создан второй класс OnCacheMMRU, алгоритм следующий: в конструктор класса кроме ёмкости кэша передаётся вторым параметром uint32_t uselessness граница популярности — если количество поисковых запросов возжелавших текущий узел из циклического пула меньше границы uselessness, то узел переиспользуется под следующую операцию вставки (будет evicted). Если на данном круге популярность узла (std::atomic<uint32_t> used { 0 }) высока, то в момент запроса аллокатора из циклического пула узел сможет выжить, но счётчик популярности будет сброшен в 0. Так узел будет существовать ещё один круг прохода аллокатора по пулу узлов и получит шанс снова набрать популярность, чтобы продолжить существование. То есть это смесь алгоритмов MRU (где самые популярные зависают в кэше навечно) и MQ (где отслеживается время жизни). Кэш постоянно обновляется и при этом работает очень быстро — вместо 10 серверов можно будет поставить 1..
По-крупному алгоритм кэширования тратит время на следующее:
- Поддержание инфраструктуры кэша (контейнеры, аллокаторы, отслеживание времени жизни и популярности элементов)
- Расчёт хэша и операции сравнения ключа при добавлении/поиске данных
- Алгоритмы поиска: Red-Black Tree, Hash Table, Skip List, ...
Требовалось просто уменьшить время работы каждого из этих пунктов, учитывая тот факт, что максимально простой алгоритм оказывается по временной сложности зачастую максимально эффективным, так как любая логика занимает такты CPU. То есть что бы Вы ни написали — это операции, которые должны окупиться во времени в сравнении с методом простого перебора: пока происходит вызов очередной функции, перебор успеет пройти ещё сотню-другую узлов. В этом свете многопоточные кэши будут всегда проигрывать однопоточным, так как защита корзин через std::shared_mutex и узлов через std::atomic_flag in_use — это не бесплатно. Поэтому для выдачи на сервере я использую однопоточный кэш OnCacheSMRU в главном потоке Epoll сервера (в параллельные рабочие потоки вынесены только длительные операции по работе с СУБД, диском, криптография). Для сравнительной оценки используется однопоточный вариант тест-кейсов:
Тест-кейс1 — ключ в виде массива случайных чисел uint64_t keyArray[3]:
Тест-кейс2 — ключ в виде строки:
В завершение хочу рассказать, чего ещё интересного можно извлечь из исходников тестового стенда:
- Библиотека парсинга JSON, состоящая из одного файла specjson.h — маленький простой быстрый алгоритм для тех, кто не хочет тащить в свой проект несколько мегабайт чужого кода ради того, чтобы распарсить файл настроек или входящие JSON известного формата.
- Подход с инжектированием реализации платформенно-зависимых операций в виде ( class LinuxSystem: public ISystem {… } ) вместо традиционного ( #ifdef _WIN32 ). Так удобнее оборачивать, например, семафоры, работу с динамически подключаемыми библиотеками, сервисами — в классах только код и заголовки от конкретной операционной системы. Если нужна другая операционная система — инжектируешь другую реализацию (class WindowsSystem: public ISystem {… } ).
- Стенд собирается CMake — проект CMakeLists.txt удобно открывать в Qt Creator или Microsoft Visual Studio 2017. Работа с проектом через CmakeLists.txt позволяет автоматизировать некоторые подготовительные операции — например скопировать файлы тест-кейсов и настроечные файлы в инсталляционный каталог:
# Coping assets (TODO any change&rerun CMake to copy): FILE(MAKE_DIRECTORY ${CMAKE_RUNTIME_OUTPUT_DIRECTORY}/assets) FILE(GLOB_RECURSE SpecAssets ${CMAKE_CURRENT_SOURCE_DIR}/assets/*.* ${CMAKE_CURRENT_SOURCE_DIR}/assets/* ) FOREACH(file ${SpecAssets}) FILE(RELATIVE_PATH ITEM_PATH_REL ${CMAKE_CURRENT_SOURCE_DIR}/assets ${file} ) GET_FILENAME_COMPONENT(dirname ${ITEM_PATH_REL} DIRECTORY) FILE(MAKE_DIRECTORY ${CMAKE_RUNTIME_OUTPUT_DIRECTORY}/assets/${dirname}) FILE(COPY ${file} DESTINATION ${CMAKE_RUNTIME_OUTPUT_DIRECTORY}/assets/${dirname}) ENDFOREACH()
- Для тех, кто осваивает новые возможности C++17, это пример работы с std::shared_mutex, std::allocator<std::shared_mutex>, static thread_local в шаблонах (есть нюансы — где аллоцировать?), запуск большого числа тестов в потоках разными способами с замером времени исполнения:
//Prepare insert threads: for (i = cnt_insert_threads; i; --i) { std::promise<InsertResults> prom; fut_insert_results.emplace_back(prom.get_future()); threads.emplace_back(std::thread (&TestCase2::insert_in_thread, this, curSize, std::move(prom), p_tester)); } // for insert //Prepare find threads: for (i = cnt_find_threads; i; --i) { std::packaged_task<FindResults(TestCase2 *i, int, IAlgorithmTester *)> ta( [](TestCase2 *i, int count, IAlgorithmTester *p_tester){ return i->find_in_thread(count, p_tester); }); fut_find_results.emplace_back(ta.get_future()); threads.emplace_back( std::thread (std::move(ta), this, curSize, p_tester)); } // for find //Banzai!!! auto start = std::chrono::high_resolution_clock::now(); l_cur_system.get()->signal_semaphore(cnt_find_threads + cnt_insert_threads); std::for_each(threads.begin(), threads.end(), std::mem_fn(&std::thread::join)); auto end = std::chrono::high_resolution_clock::now();
- Пошаговая инструкция как скомпилировать, настроить и запустить этот тестовый стенд — WiKi.
Если для удобной Вам операционной системы ещё нет пошаговой инструкции, то буду признателен за вклад в репозиторий за реализацию ISystem и пошаговую инструкцию по компиляции (для WiKi)… Или просто напишите мне — постараюсь найти время, чтобы поднять виртуалку и описать шаги по сборке.

