Очередной пользователь хочет записать на жесткий диск новый кусок данных, но ему не хватает свободного места для этого. Удалять тоже ничего не хочется, так как "все очень важное и нужное". И что нам с ним делать?
Такая проблема встает ни у него одного. На наших жестких дисках покоятся терабайты информации, и это количество не стремится уменьшаться. Но насколько она уникальна? В конце-концов, ведь все файлы это лишь наборы бит определенной длины и, скорее всего, новая не сильно отличается от той, что уже хранится.
Понятное дело, что искать уже хранящиеся куски информации на жестком диске — задача если не провальная, то как минимум не эффективная. С другой стороны, ведь если разница небольшая, то можно немного и подогнать...

TL;DR — вторая попытка рассказать о странном методе оптимизации данных с помощью JPEG-файлов, теперь в более понятной форме.
О битах и разнице
Если взять два полностью случайных куска данных, то в них совпадает в среднем половина содержащихся битов. И правда, среди возможных раскладов для каждой пары ('00, 01, 10, 11') ровно половина имеет совпадающие значения, тут все просто.
Но конечно, если мы просто возьмем два файла и подгоним один под второй, то мы лишимся одного из них. Если же будем сохранять изменения, то просто переизобретем дельта-кодирование, которое и без нас прекрасно существует, хоть и не используется обычно в таких же целях. Можно пытаться встроить меньшую последовательность в большую, но даже так мы рискуем потерей критических сегментов данных при необдуманном использовании со всем подряд.
Между чем и чем тогда можно разницу устранять? Ну то есть, записываемый пользователем новый файл — просто последовательность бит, с которой самой по себе мы ничего сделать не можем. Тогда надо просто найти на жестком диске такие биты, чтобы их можно было изменять без необходимости хранить разницу, чтобы можно было пережить их потерю без серьезных последствий. Да и изменять есть смысл не просто сам файл на ФС, но какую-то менее чувствительную информацию внутри него. Но какую и как?
Методы подгонки
На помощь приходят файлы, сжатые с потерями. Все эти jpeg, mp3 и прочие хоть и являются сжатием с потерями, содержат кучу бит, доступных для безопасного изменения. Можно использовать продвинутые техники, незаметным образом модифицирующие их составляющие на различных участках кодирования. Подождите. Продвинутые техники… незаметная модификация… одни биты в другие… да это же почти что стеганография!
И правда, встраивание одной информации в другую как ни что напоминает ее методы. Импонирует также незаметность проведенных изменений для человеческих органов чувств. Вот в чем пути расходятся — так это в секретности: наша задача сводится к внесению пользователем на свой жесткий диск дополнительной информации, ему она только повредит. Забудет еще.
Поэтому, мы хоть и можем использовать их, нужно провести некоторые модификации. И дальше я расскажу и покажу их на примере одного из существующих методов и распространенного формата файлов.
О шакалах
Если уж сжимать, то самое сжимаемое в мире. Речь идет, конечно же, о JPEG-файлах. Мало того, что существует тонна инструментария и существующих методов для встраивания в него данных, так он является самым популярным графическим форматом на этой планете.

Тем не менее, чтобы не заниматься собаководством, нужно ограничить свое поле деятельности в файлах этого формата. Никто не любит одноцветные квадратики, возникающие из-за излишнего сжатия, поэтому нужно ограничиться работой с уже сжатым файлом, избегая перекодирования. Конкретнее — с целочисленными коэффициентами, которые и остаются после операций, отвечающих за потери данных — ДКП и квантования, что прекрасно отображено на схеме кодирования (спасибо вики национальной библиотеки им. Баумана):

Существует множество возможных методов оптимизации jpeg-файлов. Есть оптимизация без потерь (jpegtran), есть оптимизация "без потерь", которые на самом деле еще какие вносят, но нас они не волнуют. Ведь если пользователь готов встраивать одну информацию в другую ради увеличения свободного места на диске, то он свои изображения либо давно оптимизировал, либо совсем этого делать не хочет из-за боязни потери качества.
F5
Под такое условия подходит целое семейство алгоритмов, с которым можно ознакомиться в этой хорошей презентации. Самым продвинутым из них является алгоритм F5 за авторством Андреаса Вестфелда, работающий с коэффициентами компоненты яркости, так как человеческий глаз наименее чувствителен именно к ее изменениям. Более того, он использует методику встраивания, основанную на кодировании матрицы, благодаря чему позволяет можно совершать тем меньше их изменений при встраивании одного и того же количества информации, чем больше размер используемого контейнера.
Сами изменения при этом сводятся к уменьшению абсолютного значения коэффициентов на единицу в определенных условиях (то есть, не всегда), что и позволяет использовать F5 для оптимизации хранения данных на жестком диске. Дело в том, что коэффициент после такого изменения, скорее всего, будет занимать меньшее число бит после проведения кодирования Хаффмана из-за статистического распределения значений в JPEG, а новые нули дадут выигрыш при кодировании их с помощью RLE.
Необходимые модификации сводятся к устранению части, отвечающей за секретность (парольной перестановки), которая позволяет экономить ресурсы и время выполнения, и добавления механизма работы с множеством файлов вместо одного за раз. Более подробно процесс изменения читателю вряд ли будет интересен, поэтому переходим к описанию реализации.
Высокие технологии
Для демонстрации работы такого подхода я реализовал метод на чистом Си и провел ряд оптимизаций как по скорости выполнения, так и по памяти (вы не представляете, сколько эти картиночки весят без сжатия даже до DCT). Кросс-платформенность достигнута использованием комбинации библиотек libjpeg, pcre и tinydir, за что им спасибо. Все это собирается 'make''ом, поэтому пользователи Windows для оценки хотят установить себе какой-нибудь Cygwin, либо разбираться с Visual Studio и библиотеками самостоятельно.
Реализация доступна в форме консольной утилиты и библиотеки. Подробнее про использование последней желающие могут ознакомиться в ридми в репозитории на гитхабе, ссылку на который я приложу в конце поста.
Как использовать?
С осторожностью. Используемые для упаковки изображения выбираются поиском по регулярному выражению в заданной корневой директории. По завершению файлы можно перемещать, переименовывать и копировать по желанию в ее пределах, менять файловую и операционные системы и пр. Однако, стоит быть крайне аккуратным и никак не изменять непосредственное содержимое. Потеря значения даже одного бита может привести к невозможности восстановления информации.
По завершению работы утилита оставляет специальный файл архива, содержащий всю необходимую для распаковки информацию, включая данные об использованных изображениях. Сам по себе он весит порядка пары килобайт и хоть сколько существенного влияния на занятое дисковое пространство не оказывает.
Можно анализировать возможную вместимость помощью флага '-a': './f5ar -a [папка поиска] [Perl-совместимое регулярное выражение]'. Упаковка производится командой './f5ar -p [папка поиска] [Perl-совместимое регулярное выражение] [упаковываемый файл] [имя архива]', а распаковка с помощью './f5ar -u [файл архива] [имя восстановленного файла]'.
Демонстрация работы
Чтобы показать эффективность работы метода, я загрузил коллекцию из 225 абсолютно бесплатных фотографий собак с сервиса Unsplash и отрыл в документах большую pdf-ку на 45 метров второго тома Искусства Программирования Кнута.
Последовательность довольно прост:
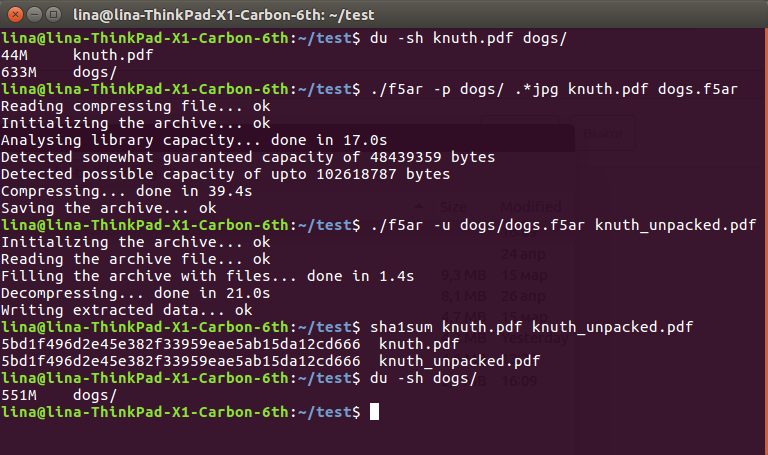
$ du -sh knuth.pdf dogs/ 44M knuth.pdf 633M dogs/ $ ./f5ar -p dogs/ .*jpg knuth.pdf dogs.f5ar Reading compressing file... ok Initializing the archive... ok Analysing library capacity... done in 17.0s Detected somewhat guaranteed capacity of 48439359 bytes Detected possible capacity of upto 102618787 bytes Compressing... done in 39.4s Saving the archive... ok $ ./f5ar -u dogs/dogs.f5ar knuth_unpacked.pdf Initializing the archive... ok Reading the archive file... ok Filling the archive with files... done in 1.4s Decompressing... done in 21.0s Writing extracted data... ok $ sha1sum knuth.pdf knuth_unpacked.pdf 5bd1f496d2e45e382f33959eae5ab15da12cd666 knuth.pdf 5bd1f496d2e45e382f33959eae5ab15da12cd666 knuth_unpacked.pdf $ du -sh dogs/ 551M dogs/
Распакованный файл все еще можно и нужно читать:

Как видно, с исходных 633 + 36 == 669 мегабайт данных на жестком диске мы пришли к более приятным 551. Такая радикальная разница объясняется тем самым уменьшением значений коэффициентов, влияющим на их последующее сжатие без потерь: уменьшение одного всего лишь на единичку может спокойно "срезать" парочку байт с итогового файла. Тем не менее, это все равно потери данных, пусть и крайне небольшие, с которыми придется мириться.
К счастью, для глаза они не заметны абсолютно. Под спойлером (так как habrastorage не умеет в большие файлы) читатель может оценить разницу как на глаз, так и их интенсивность, полученную вычитанием значений измененной компоненты из оригинальной: оригинал, с информацией внутри, разница (чем тусклее цвет, тем меньше различие в блоке).
Вместо заключения
Смотря на все эти сложности, купить жесткий диск или залить все в облако может показаться куда более простым решением проблемы. Но хоть сейчас мы и живем в такое прекрасное время, нет никаких гарантий, что завтра все еще можно будет выйти в интернет и залить куда-нибудь все свои лишние данные. Или придти в магазин и купить себе очередной жесткий диск на тысячу терабайт. А вот использовать уже лежащие дома можно всегда.
-> GitHub
-> Зеркало на английском

