
Работа с данными — работа с алгоритмами обработки данных.
И мне приходилось работать с самыми разнообразными на ежедневной основе, так что я решил составить список наиболее востребованных в серии публикаций.
Эта статья посвящена наиболее распространённым способам сэмплинга при работе с данными.
Простой случайный сэмплинг
Допустим, если вы хотите сделать выборку, где каждый элемент имеет равную вероятность быть выбранным.
Ниже мы выбираем 100 таких элементов из датасета.
sample_df = df.sample(100)
Стратифицированный сэмплинг

Допустим, нам нужно оценить среднее количество голосов за каждого кандидата на выборах. Голосование проходит в трёх городах:
В городе A живёт 1 миллион рабочих
В городе B живёт 2 миллиона художников
В городе C живёт 3 миллиона пенсионеров
Если мы попытаемся взять равновероятные выборки по 60 человек среди всего населения, то они наверняка будут разбалансированы относительно разных городов, а потому предвзяты, что приведёт к серьёзной ошибке в предсказаниях.
Если же мы специально сделаем выборку из 10, 20 и 30 человек из городов A, B и C соответственно, то ошибка будет минимальной.
На Python это можно сделать так:
from sklearn.model_selection import train_test_split X_train, X_test, y_train, y_test = train_test_split(X, y, stratify=y, test_size=0.25)
Резервуарный сэмплинг

Мне нравится такая формулировка задачи:
Допустим, у вас есть поток элементов большого неизвестного размера, по которым можно итерироваться только один раз.
Создайте алгоритм, произвольно выбирающий элемент из потока так, как если бы любой элемент мог быть выбран с равной вероятностью.
Как это сделать?
Допустим, нам надо выбрать 5 объектов из бесконечного потока, так чтобы каждый элемент в потоке мог быть выбран равновероятно.
import random def generator(max): number = 1 while number < max: number += 1 yield number # Создаём генератор потока stream = generator(10000) # Делаем резервуарный сэмплинг k=5 reservoir = [] for i, element in enumerate(stream): if i+1<= k: reservoir.append(element) else: probability = k/(i+1) if random.random() < probability: # Сохраняем элемент из потока, удаляя ранее добавленный reservoir[random.choice(range(0,k))] = element print(reservoir) ------------------------------------ [1369, 4108, 9986, 828, 5589]
Доказать, что каждый элемент мог быть выбран равновероятно можно математически.
Как?
Когда дело доходит до математики, лучше попытаться начать решение с небольшого частного случая.
Так что давайте рассмотрим поток, состоящий из 3-х элементов, где нам нужно выбрать только 2.
Мы видим первый элемент, сохраняем его в списке, так как в резервуаре ещё есть место. Мы видим второй элемент, сохраняем его в списке, так как в резервуаре ещё есть место.
Мы видим третий элемент. Здесь становится интереснее. Мы сохраним третий элемент с вероятностью 2/3.
Давайте теперь посмотрим итоговую вероятность первого элемента быть сохранённым:
Вероятность вытеснения первого элемента из резервуара равна вероятности третьего элемента быть выбранным, умноженной на вероятность что именно первый элемент из двух будет выбран для вытеснения. То есть:
2/3 * 1/2 = 1/3
То есть конечная вероятность первого элемента быть сохранённым:
1 — 1/3 = 2/3
Абсолютно такую же логику можно применить и для второго элемента, распространив её в дальнейшем на большее количество элементов при увеличении резервуара.
То есть каждый элемент будет сохранён с вероятностью 2/3 или в общем случае k/n.
Случайный андерсэмплинг и оверсэмплинг
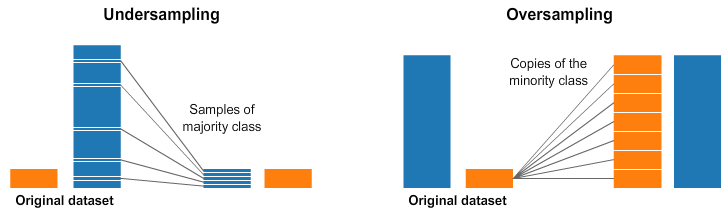
Слишком часто в жизни встречаются несбалансированные наборы данных.
Широко применяемый в таком случае способ называется ресэмплинг (в русском переводе иногда говорят «передискретизация» — прим. перев.). Его суть заключается либо в удалении элементов из слишком большого набора (андерсэмплинг) и/или добавлении большего количества элементов в недостаточно большой набор (оверсэмплинг).
Давайте для начала создадим какие-нибудь несбалансированные наборы.
from sklearn.datasets import make_classification X, y = make_classification( n_classes=2, class_sep=1.5, weights=[0.9, 0.1], n_informative=3, n_redundant=1, flip_y=0, n_features=20, n_clusters_per_class=1, n_samples=100, random_state=10 ) X = pd.DataFrame(X) X['target'] = y
Теперь случайный андерсэмплинг и оверсэмплинг мы можем выполнять вот так:
num_0 = len(X[X['target']==0]) num_1 = len(X[X['target']==1]) print(num_0,num_1) # случайный андерсэмплинг undersampled_data = pd.concat([ X[X['target']==0].sample(num_1) , X[X['target']==1] ]) print(len(undersampled_data)) # случайный оверсэмплинг oversampled_data = pd.concat([ X[X['target']==0] , X[X['target']==1].sample(num_0, replace=True) ]) print(len(oversampled_data)) ------------------------------------------------------------ OUTPUT: 90 10 20 180
Андерсэмплинг и оверсэмплинг с использованием imbalanced-learn
imbalanced-learn (imblearn) — это питоновская библиотека для борьбы с проблемами несбалансированных наборов данных.
Она содержит несколько различных методов для проведения ресэмплинга.
a. Андерсэмплинг с использованием Tomek Links:
Один из предоставляемых методов называется «Tomek Links». «Links» в данном случае — пары элементов из разных классов, находящиеся поблизости.
Используя алгоритм мы в конечном итоге удалим элемент пары из большего набора, что позволит классификатору отработать лучше.

from imblearn.under_sampling import TomekLinks tl = TomekLinks(return_indices=True, ratio='majority') X_tl, y_tl, id_tl = tl.fit_sample(X, y)
b. Оверсэмплинг со SMOTE:
В SMOTE (Способ Передискретизации Синтезированных Меньшинств) мы создаём элементы в непосредственной близости от уже существующих в меньшем наборе.
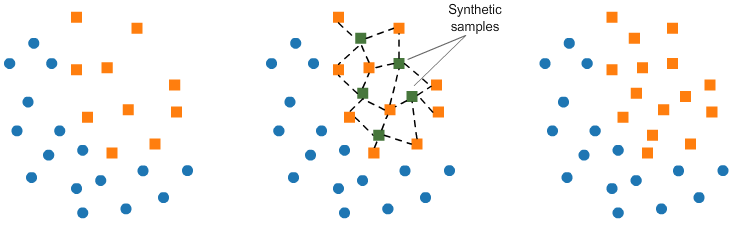
from imblearn.over_sampling import SMOTE smote = SMOTE(ratio='minority') X_sm, y_sm = smote.fit_sample(X, y)
Но в imblearn существуют и другие способы андерсэмплинга (Cluster Centroids, NearMiss, и т.д.) и оверсэмплинга (ADASYN и bSMOTE), которые тоже могут пригодиться.
Заключение
Алгоритмы — кровь науки о данных.
Сэмплинг — одна из важнейших областей в работе с данными и выше приведён только поверхностный обзор.
Хорошо выбранная стратегия сэмплинга может потянуть весь проект за собой. Выбранная плохо приведёт к ошибочным результатам. Поэтому выбор нужно делать с умом.

