Unit-тестирование — это замечательно, но его одного бывает недостаточно. Часто хочется дополнительно убедиться, что запущенное приложение будет работать. На помощь приходит интеграционное тестирование. Оно все чаще применяется для тестирования сервисов, а Docker позволяет удобно управлять тестовым окружением. Но, как всегда, не все так просто, когда микросервисов и зависимостей становится намного больше.
Юрий Бадальянц на РИТ++ рассказал, как в 2ГИС тестируют связку из большого числа сервисов и целого зоопарка технологий. Под катом дополненная и актуализированная под тщательным присмотром спикера версия этого доклада: какие варианты пробовали, к чему пришли, какие проблемы теперь вам не придется решать. Будет про Docker, Testcontainers, а также про Scala.
О спикере: Юрий Бадальянц (@LMnet) начал свою карьеру в 2011 году как веб-разработчик, работал с PHP, JavaScript и Java. Сейчас пишет на Scala в 2ГИС.
2ГИС уже 20 лет предоставляет удобные карты городов и справочники предприятий, а недавно у нас появилась новая версия с безграничной картой России. Расскажу об опыте, полученном, пока я работал в команде Casino. Эта команда занимается тремя основными направлениями:
Эти три направления являются основными задачами, которые, в свою очередь, имеют большое количество подзадач. В настоящий момент это более 25 микросервисов, написанных на Scala. Это исключительно наш код, однако мы также используем сторонние системы, например, PostgreSQL, Cassandra и Kafka. Данные храним в Hadoop и обрабатываем их в Spark. Кроме того, используются методы машинного обучения, которые нам предоставляет команда Data Science.
В итоге мы имеем большое количество сервисов и микросервисов, большое количество зависимостей, и, естественно, все это нужно каким-то образом тестировать.
Конечно, мы пишем unit-тесты. Однако, даже если все тесты зелёные, это ещё не означает, что всё работает. На этапе интеграции компонентов или микросервисов что-то может пойти не так. Поэтому мы пишем интеграционные тесты.
Каждый микросервис, который разрабатывает команда Casino, решает свою бизнес-задачу и располагается в отдельном репозиторий в GitLab. В рамках этой статьи речь пойдет об интеграционном тестировании в рамках одного такого репозитория (микросервиса) с замоканными зависимостями, которое является ответственностью самих разработчиков. Тестированием взаимодействия микросервисов занимается команда QA, и этой темы я касаться не буду.
Когда я только пришел в команду, в конце 2016 года, существовала примерно следующая схема интеграционных тестов:

Что можно сказать про такую схему? Главное, это работает. Когда всё настроено, тесты запустить легко, так как они похожи на unit-тесты. Но на этом плюсы заканчиваются.
И начинаются минусы. CI окружение всегда включено, а это лишняя трата ресурсов. Так как Chef — это статическая конфигурация, нужно всегда иметь какую-то машину, где будут настроены все зависимости, где приложения будут разворачиваться самостоятельно. Такая машина будет потреблять лишние ресурсы, так как тесты прогоняются время от времени, а машина все время должна быть готова. Кроме того, CI-окружение включено со всеми зависимостями.
Невозможно запустить тесты двух веток одновременно. Это вытекает из предыдущего пункта: так как у нас одно окружение, мы просто не можем запустить их параллельно.
Невозможно тестировать старт, стоп и рестарт. Объясню, для чего это нужно: все наши приложения подчиняются логике так называемого graceful shutdown, то есть когда мы получаем SIGTERM, мы не останавливаем процесс на середине, а перехватываем этот сигнал и понимаем, что нужно выключить программу. В этот момент включается определенная логика, например, обрабатываются те HTTP-запросы, которые «в полете», или если мы работаем с Kafka, то коммитим все offset’ы — иными словами, совершаем определенные действия, чтобы можно было спокойно завершить работу, а потом, когда все сделано, выключаемся.
Эта логика не всегда простая, и тестировать ее при такой схеме можно только вручную, потому что из тестов мы не управляем жизненным циклом приложений. Получается, что TeamCity через Chef каким-то образом что-то развернул, а тесты при этом находятся на другой стадии и не знают, как развернуто приложение.
Следующий минус заключается в том, что очень тяжело все это настроить локально. То есть, существует много зависимостей, у них есть свои конфиги, их нужно поднять на локальной машине. У самого приложения тоже есть свой конфигурационный файл, в котором множество значений. У самих тестов есть конфиг, который нужно согласовать с конфигом приложения, и там тоже может быть не одно конфигурационное значение. Вроде бы все это звучит не так страшно, типа «пойди и поправь конфиги в трех местах», но в действительности у новых сотрудников на это могут уходить часы.
Со временем эта схема преобразовалась в другую: GitLab CI и Docker. Это произошло не потому, что предыдущая схема была не идеальной, а потому что компания немного изменила курс в плане административной организации.
Раньше каждая команда, а их у нас много, как хотела или как умела, так и разворачивала свою работу. Например, у нас был TeamCity, Chef, а другие команды могли использовать Jenkins или Ansible.
Сейчас же мы движемся в сторону локального облака и Kubernetes, и есть отдельная команда, которая всем этим управляет, как GitLab CI, так и Kubernetes. Другие команды просто используют это как сервис. Это намного удобнее, так как не нужно все это администрировать вручную.
Используя Kubernetes, мы развернули следующую схему:
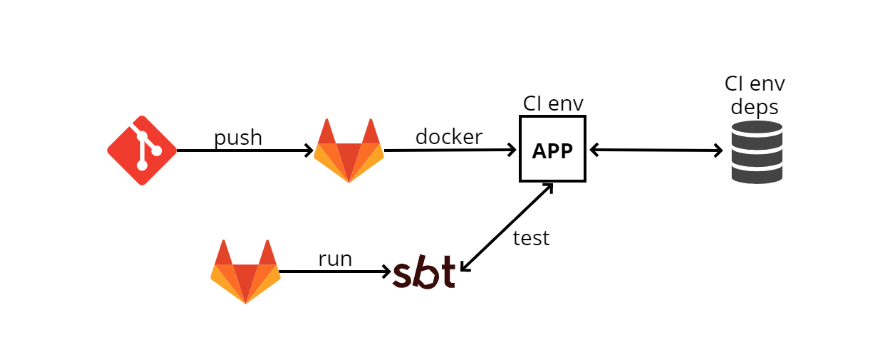
Все достаточно похоже на предыдущую схему и принципиально от нее не отличается, то есть даже плюсы и минусы будут точно такие же, но появляется Docker.
С докером можно делать разные более прикольные штуки и одна из них — docker-compose.
Это своеобразная «накладка» на Docker, которая позволяет запускать несколько docker-образов как единую сущность.
Хороший пример, когда docker-compose очень выручает, — это Kafka. Для запуска ей нужен ZooKeeper. Если поднимать Kafka и ZooKeeper без docker-compose, то нужно отдельно поднять ZooKeeper в докере, отдельно — Kafka, и держать эти два docker-контейнера согласованными. Это не очень удобно, а docker-compose позволяет в одном docker-compose.yml файле описать оба контейнера и простой командой
На docker-compose можно построить интеграционные тесты. Посмотрим, как это будет выглядеть.

Благодаря такой схеме, не нужно держать отдельное окружение и зависимости, потому что все проходит непосредственно в GitLab CI runner, где просто должны быть docker и docker-compose. Во время старта он подкачает нужные образы и запустит их.
Кроме того, можно тестировать разные ветки одновременно, потому что все происходит на runner.
Теперь окружение стало проще настроить локально, но все еще нужно согласовывать несколько мест. Речь идет о том, что теперь, когда мы делаем локальную настройку, нам не нужно все ставить на локальную машину, все прописано в docker-compose.yml файле. Таким образом, конфигурировать приходится в двух разных местах — это docker-compose.yml и конфиг наших тестов.
Что касается минусов, все еще невозможно тестировать старт, стоп и рестарт, потому что из SBT, из тестов, мы не управляем жизненным циклом приложения. Им управляет docker-compose, он запускает SBT и внутри SBT запускаются тесты. Таким образом, полноценного управления жизненным циклом приложения нет. Также есть сложности с запуском, про которые мне бы хотелось рассказать подробнее.
Во времена docker-compose 2 docker-compose.yml файл выглядел так:
Здесь прописаны сервисы (services), то есть то, что мы будем поднимать в рамках этого docker-compose. В данном случае я просто взял пример из документации docker-compose. Тут есть три сервиса: web, redis и db (база данных).
Web — это наше приложение, а redis и db — какие-то зависимости.
В web-блоке есть пункт, который называется
Также, есть пункт
Что касается базы данных, у нее условие —
Например, мы используем PostgreSQL, в котором используется расширение PostGIS, а ему нужно некоторое время для инициализации. Когда мы запускаем docker-контейнер, мы не можем сразу работать с postgis-расширением — нужно дождаться инициализации расширения. Поэтому, мы просто шлем запросы
Когда вышел docker-compose 3, мы начали его использовать.
Но в документации к нему появился пункт об изменении логики depends_on. Разработчики docker решили, что достаточно описания графа зависимостей. Это значит, что при старте команды

Следующий пункт документации говорит о том, что в depends_on больше нет condition.
Таким образом, если вы все же хотите получить ту функциональность, которой пользовались во второй версии, вам придется взять все в свои руки.
На странице Controlling startup order предлагается несколько вариантов решений. Первый вариант — это использовать wait-for-it.sh.
Теперь docker-compose.yml выглядит немного по-другому:
В наших зависимостях мы переопределяем команду, то есть в docker-compose можно прикрепить команду, с помощью которой docker-контейнер стартует.
Там мы должны написать wait-for-it.sh, и еще что-то. Вместо трех точек в примере выше мы должны написать, чего нужно подождать, а также оригинальную команду, которая запускает docker-контейнер.
Чтобы это сделать, необходимо найти docker-файл, скопировать оттуда команду для redis и вставить ее, то же самое и для базы данных. Огромный минус заключается в том, что ломается абстракция — я не хочу знать, какой командой запускается docker-контейнер. Эти команды могут быть нетривиальными, довольно сложными, а я не хочу заморачиваться, я хочу просто ввести команду
Такое решение лично мне не очень нравится, но у нас была парочка сервисов, которые так работают.
Тогда я решил, что пришло время «велосипедостроения», и у меня появился docker-compose-run.sh:
Приведу полуреалистичный пример: есть postgres в docker-compose.yml, есть приложение my_service, которое зависит от postgres, и SBT, в котором прогоняются тесты и который зависит от моего сервиса.
Я запускаю программу не через
Во-первых, он сначала запускает самую глубокую зависимость, в моем случае это postgres. Скрипт запускает зависимость в режиме «демона», то есть не блокирует терминал:
Потом я жду выполнения условия функцией wait_until. Это практически то же самое, что и wait-for-it.sh, только, так скажем, в императивном стиле. Пока PostGIS инициализируется, терминал блокируется, то есть программа тоже ждет, а если не дожидается, то выбрасывается ошибка и работа тестов прекращается.
Когда PostGIS инициализирован, приступаем к следующему шагу и делаем то же самое с сервисом. Для него тест немного проще: должен быть привязан 80 порт.
Последний шаг — через команду run запустить SBT, в котором прогоняются тесты.
Таким образом, все поднято в правильном порядке, но вручную.
В конце вызывается функция
Такая схема работает, но плохо масштабируется. В каждом сервисе придётся описывать свой docker-compose-run.sh со своей логикой. Плюс, конфигурация запуска расползается между docker-compose-run.sh и docker-compose.yml. Ну и в целом, выглядит так, что мы не используем docker-compose, а боремся с его недостатками.
Когда предыдущая схема была создана, я подумал: если у меня и так все в докере, то почему бы не запускать его из кода. Я начал искать решение и нашел несколько вариантов.
Первый вариант — просто использовать docker-клиент. В JVM-мире есть два основных docker-клиента: docker-java и spotify docker-client.
Docker-клиент позволяет запускать docker-команды прямо из кода, используя API. То есть, вместо конкатенирования строк для построения команд типа
Такой способ хорошо работает, и, наверняка, им можно все сделать, однако, это очень низкий уровень. Мне пришлось бы создать свой аналог docker-compose, а это очень большая задача.
Следующий вариант — это библиотека docker-it-scala, которая оборачивает оба этих клиента и позволяет выбрать, какой бэкенд использовать. Она может запустить нужные вам контейнеры.
Но минус этой библиотеки в том, что у нее не очень гибкий API и нет контроля за жизненным циклом.
Этот вариант мне тоже не понравился, я продолжил поиски и нашел Testcontainers. Об этом я бы хотел рассказать немного подробнее.
Это своеобразная java-библиотека для запуска и тестирования docker-контейнеров. Там есть Scala-фасад, testcontainers-scala. Из коробки присутствует ряд популярных сервисов, например, PostgreSQL, MySQL, Nginx, Kafka, Selenium. Можно запускать любые другие контейнеры. У библиотеки довольно простой и гибкий API, на котором я остановлюсь подробнее.
Итак, как работать с Predefined containers, которые есть в библиотеке: на самом деле все довольно просто, так как контейнеры представляются в виде объектов:
В данном случае мы создаем
Это значит, что PostgreSQL «торчит» изнутри докера портом 5432, а Testcontainers видит этот порт и автоматически назначает на какой-то случайный порт. То есть из тестов мы видим, допустим, 32422. Назначение происходит автоматически.
Следующий вид, так называемый, кастомный контейнер тоже довольно прост:
Есть
Можно задать
Так как вы пишете HealthCheck просто в своем коде, можете использовать, во-первых, нормальный язык, а не bash, а, во-вторых, любые библиотеки, которые доступны из вашего кода: хотите сделать кастомный HealthCheck в Cassandra — берете драйвер и пишете любой HealthCheck.
А теперь немного о том, как запускать тесты:
Я буду рассказывать на примере ScalaTest — де-факто стандарта для тестирования в Scala-мире.
Например, мы хотим написать тесты для Postgres. Создаем тест
Затем нужно переопределить контейнер. Это можно сделать, переопределив свойство
Потом пишем тесты. В примере я создаю connection, беру jdbcUrl, username, password, пишу определенные тесты, посылаю запросы.
Обычно, для интеграционных тестов нужно несколько контейнеров. Я могу создать их с помощью
То есть, я создаю контейнеры, добавляю их в
Схема запуска тестов с Testcontainers выглядит следующим образом:

Плюсы этой схемы:
Выходит все подозрительно гладко и хорошо, но это только на первый взгляд, на самом деле мы столкнулись с рядом проблем.
Первая проблема, с которой мы столкнулись, это зависимые контейнеры. Допустим, есть какой-то тест:
Он запускает postgres и AppContainer. В AppContainer из postgres передаются jdbcUrl, имя пользователя и пароль для подключения. Далее создается MultipleContainers и описывается сам тест.
Запускаю программу и вижу ошибку:
Речь идет о том, что назначенный порт не может быть взят, пока контейнер не запущен. Почему это происходит?
Дело в том, что
Проблема в том, что сущность контейнера мутабельна: у нее есть несколько состояний. Например, она может быть выключена и включена.
Как решить данную проблему? Первый способ я бы назвал «ленивым».
Основная идея — создавать контейнеры, используя lazy val. Тогда они не будут инициализироваться сразу в конструкторе теста, а будут ожидать первого обращения. Инициализацию сделаем в методах
Однако, все равно возникает ошибка, что я не могу присоединиться к localhost:32787:
Казалось бы, мы использовали jdbcUrl, почему появляется localhost? Давайте посмотрим, как работает jdbcUrl:
Это просто конкатенация строк. С константами всё понятно, они сломаться не могут.
Рекомендация разработчиков Testcontainers: создать кастомный network для взаимодействия между контейнерами. Примерно так и работает docker-compose: он создает network и самостоятельно все решает.
Значит, нужно создать network.
Теперь нам приходится вручную формировать свой jdbcUrl. Также мы должны включить наши контейнеры в network, и задать alias для PostgreSQLContainer, чтобы внутри сети он был доступен по какому-то доменному имени. В конце нужно не забыть «убить» network.
Наконец, такая программа будет работать.
В последних версиях testcontainers-scala ленивая инциализация контейнеров поддерживается из коробки:
Можно снова использовать
Однако, все еще есть проблемы. Например моки. Иногда бывает не очень удобно создавать какую-то зависимость в docker-контейнере. Мы используем Spark JobServer, который создает Spark job’ы и контролирует их жизненный цикл в Spark. Мы используем два его метода: «создать» и «дать статус».
Чтобы запустить Spark JobServer внутри docker. Нужно поднять Spark, а до недавнего времени у него вообще не было docker-контейнера и нужно было собирать его самостоятельно. Кроме того, Spark JobServer использует PostgreSQL для хранения состояний. В итоге приходится проделывать большую и сложную работу, когда на самом деле нужны всего два метода с простым API.
Но можно подсмотреть в реализацию Spark JobServer и создать mock, который ведёт себя так же как, но не требует зависимостей оригинального Spark JobServer.
Это выглядит следующим образом (в примере упрощённый псевдокод):
Прямо в тестах создается и запускается http-сервер с таким же API как и у Spark JobServer. Он инициализируется с какими-то данными, а затем мы направляем приложение на этот сервер вместо настоящего. То, что возвращает метод, должно соответствовать тому, что мы положили в mock.
Но нужно как-то передать контейнеру, как ему подключаться к этому моку. С портом все более или менее понятно: мы можем его «зашить» или положить в config; вопрос в том, какой нужен host.
Наш
Каким же образом получить этот адрес? Если вы хорошо знаете устройство docker-сетей, то должны догадаться, что нужно использовать gateway той сети, где находится docker-контейнер.
Проблема в том, что у Testcontainers нет такого API. Однако, так как Testcontainers работает поверх обычного docker-java-клиента, можно спуститься на его уровень. То есть использовать «голый» docker-клиент:
Во-первых, нужно взять
На первый взгляд может показаться сложным, но когда сделаешь это один раз, все станет понятнее.
Но с этим решением есть проблема — оно работает не везде. Docker работает в разных окружениях: Windows, Mac, может быть удаленным. Но эта программа будет работать только на Linux. Для нас это не проблема, так как, мы все пишем на Linux и прогоняем тесты тоже на нём.
К счастью, в новых версиях Testcontainers эта проблема была решена. Теперь можно пробросить порт с хостовой машины таким образом, чтобы он был доступен в docker-сети. Делается это следующим образом:
Важно, чтобы этот метод был вызван до запуска контейнеров. После вызова хостовый порт будет доступен внутри docker-контейнеров. А в качестве хоста нужно будет использовать
Таким образом, наш код значительно упростится:
Как видно из примеров, описанных выше, за последнее время в Testcontainers появилось много улучшений, которые значительно упрощают жизнь пользователей библиотеки. Развивается как Java-библиотека, так и Scala-фасад. Среди основных направлений развития можно отметить следующие:
Сделать хорошие интеграционные тесты сложно. Docker помогает, но тянет за собой много особенностей, с ним нужно достаточно долго разбираться, чтобы в конце концов понять, что нужен network gateway.
Testcontainers — очень хорошая библиотека, которая решает многие проблемы. API еще не идеальный, но с каждым годом становится лучше.
Если вы не из Java-мира, то в любом случае сам подход очень хорош. Представление контейнеров в виде объектов — выигрышная стратегия на текущий момент. Взаимодействовать с ним очень удобно.
Для других языков и систем есть похожие библиотеки, и всегда есть docker-клиент, с помощью которого вы можете реализовать свой похожий проект.
Юрий Бадальянц на РИТ++ рассказал, как в 2ГИС тестируют связку из большого числа сервисов и целого зоопарка технологий. Под катом дополненная и актуализированная под тщательным присмотром спикера версия этого доклада: какие варианты пробовали, к чему пришли, какие проблемы теперь вам не придется решать. Будет про Docker, Testcontainers, а также про Scala.
О спикере: Юрий Бадальянц (@LMnet) начал свою карьеру в 2011 году как веб-разработчик, работал с PHP, JavaScript и Java. Сейчас пишет на Scala в 2ГИС.
Casino
2ГИС уже 20 лет предоставляет удобные карты городов и справочники предприятий, а недавно у нас появилась новая версия с безграничной картой России. Расскажу об опыте, полученном, пока я работал в команде Casino. Эта команда занимается тремя основными направлениями:
- Рекламой — каких рекламодателей показать, каких скрыть, каких поднять и каким понизить рейтинг.
- BigData связана с рекламой и ее персонализацией, а также с аналитикой и построением метрик.
- Crawler — это программа, которая занимается поиском организаций в интернете для их автоматического добавления в базу.
Эти три направления являются основными задачами, которые, в свою очередь, имеют большое количество подзадач. В настоящий момент это более 25 микросервисов, написанных на Scala. Это исключительно наш код, однако мы также используем сторонние системы, например, PostgreSQL, Cassandra и Kafka. Данные храним в Hadoop и обрабатываем их в Spark. Кроме того, используются методы машинного обучения, которые нам предоставляет команда Data Science.
В итоге мы имеем большое количество сервисов и микросервисов, большое количество зависимостей, и, естественно, все это нужно каким-то образом тестировать.
Конечно, мы пишем unit-тесты. Однако, даже если все тесты зелёные, это ещё не означает, что всё работает. На этапе интеграции компонентов или микросервисов что-то может пойти не так. Поэтому мы пишем интеграционные тесты.
Интеграционные тесты
Каждый микросервис, который разрабатывает команда Casino, решает свою бизнес-задачу и располагается в отдельном репозиторий в GitLab. В рамках этой статьи речь пойдет об интеграционном тестировании в рамках одного такого репозитория (микросервиса) с замоканными зависимостями, которое является ответственностью самих разработчиков. Тестированием взаимодействия микросервисов занимается команда QA, и этой темы я касаться не буду.
Когда я только пришел в команду, в конце 2016 года, существовала примерно следующая схема интеграционных тестов:
- Разработчик пушит свой код в GIT, после чего код микросервиса попадает в TeamCity. В TeamCity начинается сборка кода и прогон тестов.
- TeamCity забирает конфигурационный файл (config) из Chef (система управления конфигурациями, похожая на Ansible, только написанная на Ruby). Chef также служит для автоматизации развертывания. Когда у меня есть 100 машин, я не хочу заходить на каждую из них и по SSH устанавливать то, что мне нужно, а Chef позволяет это автоматизировать.
- TeamCity собирает jar-файл (так как мы пишем на Scala, артефакт, который мы публикуем, это jar), далее программа загружает его на CI окружение. Там разворачивается наше приложение, также есть какие-то зависимости. На схеме одна из зависимостей изображена в виде базы данных. Таких зависимостей может быть сколько угодно, и благодаря Chef, наше приложение знает о них и начинает с ними взаимодействовать.
- Далее TeamCity запускает SBT (это наша система сборки, где происходит компиляция и прогоняются тесты) и запускает собственно тесты. Они относительно похожи на unit-тесты, но работают в основном по такому принципу: пойти по http на определенный адрес, проверить какой-нибудь метод и посмотреть, что он вернул; или сделать какую-либо подготовку, а потом посмотреть, вернулось ли то, что необходимо.
Что можно сказать про такую схему? Главное, это работает. Когда всё настроено, тесты запустить легко, так как они похожи на unit-тесты. Но на этом плюсы заканчиваются.
И начинаются минусы. CI окружение всегда включено, а это лишняя трата ресурсов. Так как Chef — это статическая конфигурация, нужно всегда иметь какую-то машину, где будут настроены все зависимости, где приложения будут разворачиваться самостоятельно. Такая машина будет потреблять лишние ресурсы, так как тесты прогоняются время от времени, а машина все время должна быть готова. Кроме того, CI-окружение включено со всеми зависимостями.
Невозможно запустить тесты двух веток одновременно. Это вытекает из предыдущего пункта: так как у нас одно окружение, мы просто не можем запустить их параллельно.
Невозможно тестировать старт, стоп и рестарт. Объясню, для чего это нужно: все наши приложения подчиняются логике так называемого graceful shutdown, то есть когда мы получаем SIGTERM, мы не останавливаем процесс на середине, а перехватываем этот сигнал и понимаем, что нужно выключить программу. В этот момент включается определенная логика, например, обрабатываются те HTTP-запросы, которые «в полете», или если мы работаем с Kafka, то коммитим все offset’ы — иными словами, совершаем определенные действия, чтобы можно было спокойно завершить работу, а потом, когда все сделано, выключаемся.
Эта логика не всегда простая, и тестировать ее при такой схеме можно только вручную, потому что из тестов мы не управляем жизненным циклом приложений. Получается, что TeamCity через Chef каким-то образом что-то развернул, а тесты при этом находятся на другой стадии и не знают, как развернуто приложение.
Следующий минус заключается в том, что очень тяжело все это настроить локально. То есть, существует много зависимостей, у них есть свои конфиги, их нужно поднять на локальной машине. У самого приложения тоже есть свой конфигурационный файл, в котором множество значений. У самих тестов есть конфиг, который нужно согласовать с конфигом приложения, и там тоже может быть не одно конфигурационное значение. Вроде бы все это звучит не так страшно, типа «пойди и поправь конфиги в трех местах», но в действительности у новых сотрудников на это могут уходить часы.
GitLab CI + Docker
Со временем эта схема преобразовалась в другую: GitLab CI и Docker. Это произошло не потому, что предыдущая схема была не идеальной, а потому что компания немного изменила курс в плане административной организации.
Раньше каждая команда, а их у нас много, как хотела или как умела, так и разворачивала свою работу. Например, у нас был TeamCity, Chef, а другие команды могли использовать Jenkins или Ansible.
Сейчас же мы движемся в сторону локального облака и Kubernetes, и есть отдельная команда, которая всем этим управляет, как GitLab CI, так и Kubernetes. Другие команды просто используют это как сервис. Это намного удобнее, так как не нужно все это администрировать вручную.
Используя Kubernetes, мы развернули следующую схему:
- Вместо TeamCity теперь используется Gitlab CI.
- GitLab CI собирает docker-образ и деплоит его в Kubernetes. Конфигурация теперь хранится прямо в репозитории, а не отдельно в Chef, так что для деплоя не нужно работать со сторонним сервисом конфигурации.
- Зависимости подняты заранее, тоже в Kubernetes.
- Затем GitLab CI отдельным шагом запускает SBT и тесты.
Все достаточно похоже на предыдущую схему и принципиально от нее не отличается, то есть даже плюсы и минусы будут точно такие же, но появляется Docker.
С докером можно делать разные более прикольные штуки и одна из них — docker-compose.
Docker-compose
Это своеобразная «накладка» на Docker, которая позволяет запускать несколько docker-образов как единую сущность.
Хороший пример, когда docker-compose очень выручает, — это Kafka. Для запуска ей нужен ZooKeeper. Если поднимать Kafka и ZooKeeper без docker-compose, то нужно отдельно поднять ZooKeeper в докере, отдельно — Kafka, и держать эти два docker-контейнера согласованными. Это не очень удобно, а docker-compose позволяет в одном docker-compose.yml файле описать оба контейнера и простой командой
docker-compose run Kafka поднять Kafka и ZooKeeper.На docker-compose можно построить интеграционные тесты. Посмотрим, как это будет выглядеть.
- Опять пушим все в GitLab.
- GitLab CI запускает docker-compose.
- В docker-compose поднимается приложение, поднимаются все зависимости и SBT, а SBT гоняет тесты к этому приложению — все происходит внутри docker-compose.
Благодаря такой схеме, не нужно держать отдельное окружение и зависимости, потому что все проходит непосредственно в GitLab CI runner, где просто должны быть docker и docker-compose. Во время старта он подкачает нужные образы и запустит их.
Кроме того, можно тестировать разные ветки одновременно, потому что все происходит на runner.
Теперь окружение стало проще настроить локально, но все еще нужно согласовывать несколько мест. Речь идет о том, что теперь, когда мы делаем локальную настройку, нам не нужно все ставить на локальную машину, все прописано в docker-compose.yml файле. Таким образом, конфигурировать приходится в двух разных местах — это docker-compose.yml и конфиг наших тестов.
Что касается минусов, все еще невозможно тестировать старт, стоп и рестарт, потому что из SBT, из тестов, мы не управляем жизненным циклом приложения. Им управляет docker-compose, он запускает SBT и внутри SBT запускаются тесты. Таким образом, полноценного управления жизненным циклом приложения нет. Также есть сложности с запуском, про которые мне бы хотелось рассказать подробнее.
docker-compose 2
Во времена docker-compose 2 docker-compose.yml файл выглядел так:
version: '2.1' services: web: build: . depends_on: db: condition: service_healthy redis: condition: service_started redis: image: redis db: image: db healthcheck: test: "some test here"
Здесь прописаны сервисы (services), то есть то, что мы будем поднимать в рамках этого docker-compose. В данном случае я просто взял пример из документации docker-compose. Тут есть три сервиса: web, redis и db (база данных).
Web — это наше приложение, а redis и db — какие-то зависимости.
В web-блоке есть пункт, который называется
depends_on. Это говорит о том, что web-приложение зависит от каких-то других контейнеров, и ниже описано, от каких: от базы данных и redis.Также, есть пункт
condition. У redis это service_started, а значит, пока redis не запустится, контейнер не будет пытаться стартовать web-приложение.Что касается базы данных, у нее условие —
service_healthy, а ниже описан healthcheck. То есть, нам нужно не только запустить docker-контейнер, но еще и выполнить определенный healthcheck. Это может быть любая кастомная логика.Например, мы используем PostgreSQL, в котором используется расширение PostGIS, а ему нужно некоторое время для инициализации. Когда мы запускаем docker-контейнер, мы не можем сразу работать с postgis-расширением — нужно дождаться инициализации расширения. Поэтому, мы просто шлем запросы
SELECT PostGIS_Version();. Пока расширение не будет инициализировано, запрос будет выдавать ошибку, а когда расширение инициализируется, начнет возвращать версию. Это очень удобно и логично — сначала поднимем все зависимости, а затем приложение.docker-compose 3
Когда вышел docker-compose 3, мы начали его использовать.
Но в документации к нему появился пункт об изменении логики depends_on. Разработчики docker решили, что достаточно описания графа зависимостей. Это значит, что при старте команды
docker-compose run web, и само приложение, и db, от которой оно зависит, запустятся одновременно.Следующий пункт документации говорит о том, что в depends_on больше нет condition.
Таким образом, если вы все же хотите получить ту функциональность, которой пользовались во второй версии, вам придется взять все в свои руки.
На странице Controlling startup order предлагается несколько вариантов решений. Первый вариант — это использовать wait-for-it.sh.
Теперь docker-compose.yml выглядит немного по-другому:
version: '3' services: web: build: . depends_on: [ db, redis ] redis: image: redis command: [ "./wait-for-it.sh", ... ] db: image: redis command: [ "./wait-for-db.sh", ... ]
depends_on — это просто массив, нет никаких условий.В наших зависимостях мы переопределяем команду, то есть в docker-compose можно прикрепить команду, с помощью которой docker-контейнер стартует.
Там мы должны написать wait-for-it.sh, и еще что-то. Вместо трех точек в примере выше мы должны написать, чего нужно подождать, а также оригинальную команду, которая запускает docker-контейнер.
Чтобы это сделать, необходимо найти docker-файл, скопировать оттуда команду для redis и вставить ее, то же самое и для базы данных. Огромный минус заключается в том, что ломается абстракция — я не хочу знать, какой командой запускается docker-контейнер. Эти команды могут быть нетривиальными, довольно сложными, а я не хочу заморачиваться, я хочу просто ввести команду
docker run и все.Такое решение лично мне не очень нравится, но у нас была парочка сервисов, которые так работают.
Скрипт поверх docker-compose
Тогда я решил, что пришло время «велосипедостроения», и у меня появился docker-compose-run.sh:
version: '3' services: postgres: ... my_service: depends_on: [ postgres ] ... sbt: depends_on: [ my_service ] ...
Приведу полуреалистичный пример: есть postgres в docker-compose.yml, есть приложение my_service, которое зависит от postgres, и SBT, в котором прогоняются тесты и который зависит от моего сервиса.
Я запускаю программу не через
docker run, а через скрипт docker-compose-run.sh.Во-первых, он сначала запускает самую глубокую зависимость, в моем случае это postgres. Скрипт запускает зависимость в режиме «демона», то есть не блокирует терминал:
docker-compose up -d postgres
Потом я жду выполнения условия функцией wait_until. Это практически то же самое, что и wait-for-it.sh, только, так скажем, в императивном стиле. Пока PostGIS инициализируется, терминал блокируется, то есть программа тоже ждет, а если не дожидается, то выбрасывается ошибка и работа тестов прекращается.
wait_until 10 2 docker-compose exec -T postgres psql
Когда PostGIS инициализирован, приступаем к следующему шагу и делаем то же самое с сервисом. Для него тест немного проще: должен быть привязан 80 порт.
docker-compose up -d my_service wait_until 10 2 docker-compose exec -T \ my_service sh -c "netstat -ntlp | grep 80 || exit 1"
Последний шаг — через команду run запустить SBT, в котором прогоняются тесты.
docker-compose run sbt down $?
Таким образом, все поднято в правильном порядке, но вручную.
В конце вызывается функция
down, которая принимает результат выполнения предыдущей команды. Если он «0», значит, тесты пройдены, и мы просто выключаем docker-compose; иначе, мы сначала «выплевываем» логи, чтобы разобраться, что пошло не так, и только потом выключаем docker-compose.function down { echo "Exiting with code $1" if [[ $1 -eq 0 ]]; then docker-compose down exit $1 else docker-compose logs -t postgres my_service docker-compose down exit $1 fi }
Такая схема работает, но плохо масштабируется. В каждом сервисе придётся описывать свой docker-compose-run.sh со своей логикой. Плюс, конфигурация запуска расползается между docker-compose-run.sh и docker-compose.yml. Ну и в целом, выглядит так, что мы не используем docker-compose, а боремся с его недостатками.
Запуск docker из кода
Когда предыдущая схема была создана, я подумал: если у меня и так все в докере, то почему бы не запускать его из кода. Я начал искать решение и нашел несколько вариантов.
Первый вариант — просто использовать docker-клиент. В JVM-мире есть два основных docker-клиента: docker-java и spotify docker-client.
Docker-клиент позволяет запускать docker-команды прямо из кода, используя API. То есть, вместо конкатенирования строк для построения команд типа
`docker run ...`, можно просто сформировать такую команду в коде и запустить. Это намного удобнее.Такой способ хорошо работает, и, наверняка, им можно все сделать, однако, это очень низкий уровень. Мне пришлось бы создать свой аналог docker-compose, а это очень большая задача.
Следующий вариант — это библиотека docker-it-scala, которая оборачивает оба этих клиента и позволяет выбрать, какой бэкенд использовать. Она может запустить нужные вам контейнеры.
Но минус этой библиотеки в том, что у нее не очень гибкий API и нет контроля за жизненным циклом.
Этот вариант мне тоже не понравился, я продолжил поиски и нашел Testcontainers. Об этом я бы хотел рассказать немного подробнее.
Testcontainers
Это своеобразная java-библиотека для запуска и тестирования docker-контейнеров. Там есть Scala-фасад, testcontainers-scala. Из коробки присутствует ряд популярных сервисов, например, PostgreSQL, MySQL, Nginx, Kafka, Selenium. Можно запускать любые другие контейнеры. У библиотеки довольно простой и гибкий API, на котором я остановлюсь подробнее.
Predefined containers
Итак, как работать с Predefined containers, которые есть в библиотеке: на самом деле все довольно просто, так как контейнеры представляются в виде объектов:
val pgContainer: PostgreSQLContainer = PostgreSQLContainer("postgres:9.6") pgContainer.start() val pgUrl: String = pgContainer.jdbcUrl val pgPort: Int = pgContainer.mappedPort(5432) pgContainer.stop()
В данном случае мы создаем
PostgreSQLContainer, можем его запустить и начать с ним работать. Далее достаем jbdcUrl, с помощью которого можно подсоединиться к PostgreSQL. После этого достаем mappedPort.Это значит, что PostgreSQL «торчит» изнутри докера портом 5432, а Testcontainers видит этот порт и автоматически назначает на какой-то случайный порт. То есть из тестов мы видим, допустим, 32422. Назначение происходит автоматически.
Custom container
Следующий вид, так называемый, кастомный контейнер тоже довольно прост:
class GenericContainer( imageName: String, exposedPorts: Seq[Int] = Seq(), env: Map[String, String] = Map(), command: Seq[String] = Seq(), classpathResourceMapping: Seq[(String, String, BindMode)] = Seq(), waitStrategy: Option[WaitStrategy] = None ) ...
Есть
GenericContainer, от которого нужно отнаследоваться и переопределить ряд полей. Обязательно нужно задать только imageName — это имя контейнера, который мы хотим создать.Можно задать
exposedPorts: те порты, которыми будет «торчать» контейнер. В env можно задать переменные окружения, также можно задать command для запуска.classpathResourceMapping позволяет прокинуть внутрь docker-контейнера ресурсы из classpath. Это очень удобно, например, если конфиг приложения лежит прямо в тестовых ресурсах. Вы просто делаете мэппинг внутрь, и приложение внутри docker получает доступ к этому конфигу.waitStrategy — очень удобная вещь, которой не хватало в docker-compose 3, фактически это HealthCheck. Есть несколько предопределенных waitStrategy, например, можно подождать, когда произойдет привязка порта, или определенный http метод отдаст 200. Но можно написать любой свой HealthCheck.Так как вы пишете HealthCheck просто в своем коде, можете использовать, во-первых, нормальный язык, а не bash, а, во-вторых, любые библиотеки, которые доступны из вашего кода: хотите сделать кастомный HealthCheck в Cassandra — берете драйвер и пишете любой HealthCheck.
Running tests
А теперь немного о том, как запускать тесты:
class PostgresqlSpec extends FlatSpec with ForAllTestContainer { override val container = PostgreSQLContainer() "PostgreSQL container" should "be started" in { Class.forName(container.driverClassName) val connection = DriverManager .getConnection(container.jdbcUrl, container.username, container.password) // test some stuff } }
Я буду рассказывать на примере ScalaTest — де-факто стандарта для тестирования в Scala-мире.
Например, мы хотим написать тесты для Postgres. Создаем тест
PostgresqlSpec и наследуем его от ForAllTestContainer. Это трейт, который предоставляется библиотекой. Он будет запускать нужные контейнеры перед всеми тестами и останавливать их после всех тестов. Или можно использовать ForeachTestContainer, тогда контейнеры запускаться перед каждым тестом и останавливаться после каждого из них.Затем нужно переопределить контейнер. Это можно сделать, переопределив свойство
container. В моём случае я использую PostgreSQLContainer.Потом пишем тесты. В примере я создаю connection, беру jdbcUrl, username, password, пишу определенные тесты, посылаю запросы.
Обычно, для интеграционных тестов нужно несколько контейнеров. Я могу создать их с помощью
MultipleContainers:val pgContainer = PostgreSQLContainer() val myContainer = MyContainer() override val container = MultipleContainers(pgContainer, myContainer)
То есть, я создаю контейнеры, добавляю их в
MultipleContainers, и использую его в качестве container.Схема запуска тестов с Testcontainers выглядит следующим образом:
- Пушим код в GitLa.
- GitLab CI runner запускает SBT.
- SBT запускает тесты. Внутри тестов запускаются наше приложение и зависимости.
Плюсы этой схемы:
- Не нужно держать отдельное окружение и зависимости, все происходит на runner.
- Можно тестировать разные ветки одновременно.
- Можно тестировать старт, стоп и рестарт, потому что мы можем управлять жизненным циклом приложения (всё запускается прямо в коде теста).
- Есть гибкие HealthCheck’и, которых очень не хватало.
- Нет никаких *.sh-файлов в репозитории, можно конфигурировать тесты в приложении как угодно гибко.
- Благодаря classpathResourсe Mapping можно использовать один и тот же конфиг как с тестами, так и с приложением.
- Можно конфигурировать тесты из кода.
- Все это запускается одинаково легко как на CI, так и локально, потому что это просто тесты, которые выглядят и запускаются как unit-тесты, только все поднимается в docker-контейнере.
Выходит все подозрительно гладко и хорошо, но это только на первый взгляд, на самом деле мы столкнулись с рядом проблем.
Dependent containers
Первая проблема, с которой мы столкнулись, это зависимые контейнеры. Допустим, есть какой-то тест:
class MySpec extends FlatSpec with ForAllTestContainer { val pgCont = PostgreSQLContainer() val appCont = AppContainer(pgCont.jdbcUrl, pgCont.username, pgCont.password) override val container = MultipleContainers(appCont, pgCont) // tests here }
Он запускает postgres и AppContainer. В AppContainer из postgres передаются jdbcUrl, имя пользователя и пароль для подключения. Далее создается MultipleContainers и описывается сам тест.
Запускаю программу и вижу ошибку:
Exception encountered when invoking run on a nested suite - Mapped port can only be obtained after the container is started
Речь идет о том, что назначенный порт не может быть взят, пока контейнер не запущен. Почему это происходит?
Дело в том, что
ForAllTestContainer или ForEachTestContainer запускают контейнеры непосредственно перед тестами, а не в момент, когда я создаю инстансы контейнеров. Получается, в тот момент, когда я создаю AppContainer, у меня еще не включен PostgreSQLContainer, а значит, я не могу взять у него назначенный порт, а он нужен для формирования jdbcUrl.Проблема в том, что сущность контейнера мутабельна: у нее есть несколько состояний. Например, она может быть выключена и включена.
Как решить данную проблему? Первый способ я бы назвал «ленивым».
class MyTest extends FreeSpec with BeforeAndAfterAll { lazy val pgCont = PostgreSQLContainer() lazy val appCont = AppContainer(pgCont.jdbcUrl, pgCont.username, pgCont.password) override def beforeAll(): Unit = { super.beforeAll() pgCont.start() appCont.start() } override def afterAll(): Unit = { super.afterAll() appCont.stop() pgCont.stop() } // tests here }
Основная идея — создавать контейнеры, используя lazy val. Тогда они не будут инициализироваться сразу в конструкторе теста, а будут ожидать первого обращения. Инициализацию сделаем в методах
beforeAll и afterAll, которые предоставляет трейт BeforeAndAfterAll из ScalaTest. В beforeAll контейнеры стартуют, а в afterAll — выключаются. Так как контейнеры объявлены ленивыми, то в момент вызова метода start в beforeAll они будут и создаваться, и инициализироваться, и стартовать.Однако, все равно возникает ошибка, что я не могу присоединиться к localhost:32787:
org.postgresql.util.PSQLException: Connection to localhost:32787 refused. Check that the hostname and port are correct and that the postmaster is accepting TCP/IP connections.
Казалось бы, мы использовали jdbcUrl, почему появляется localhost? Давайте посмотрим, как работает jdbcUrl:
@Override public String getJdbcUrl() { return "jdbc:postgresql://" + getContainerIpAddress() + ":" + getMappedPort(POSTGRESQL_PORT) + "/" + databaseName; }
Это просто конкатенация строк. С константами всё понятно, они сломаться не могут.
getMappedPort тоже должен работать, потому что мы его уже починили. databaseName — это «захардкоженная» константа. А вот с getContainerIpAddress интереснее. По названию можно предположить, что он должен вернуть IP-адрес контейнера. Но если позапускать этот код, то выяснится, что он всегда возвращает localhost. Как оказалось, этот метод не предназначен для межконтейнерного взаимодействия: getContainerIpAddress обеспечивает взаимодействие из тестов внутрь контейнера.Рекомендация разработчиков Testcontainers: создать кастомный network для взаимодействия между контейнерами. Примерно так и работает docker-compose: он создает network и самостоятельно все решает.
Значит, нужно создать network.
class MyTest extends FreeSpec with BeforeAndAfterAll { val network: Network = Network.newNetwork() val dbName = "some_db" val pgContainerAlias = "postgres" val jdbcUrl = s"jdbc:postgresql://$pgContainerAlias:5432/$dbName" lazy val pgCont = { val c = PostgreSQLContainer("postgres:9.6") c.container.withNetwork(network) c.container.withNetworkAliases(pgContainerAlias) c.container.withDatabaseName(dbName) c } lazy val appCont = { val c = AppContainer(jdbcUrl, pgCont.username, pgCont.password) c.container.withNetwork(network) c } override def beforeAll(): Unit = { super.beforeAll() pgCont.start() appCont.start() } override def afterAll(): Unit = { super.afterAll() appCont.stop() pgCont.stop() network.close() } // tests here }
Теперь нам приходится вручную формировать свой jdbcUrl. Также мы должны включить наши контейнеры в network, и задать alias для PostgreSQLContainer, чтобы внутри сети он был доступен по какому-то доменному имени. В конце нужно не забыть «убить» network.
Наконец, такая программа будет работать.
В последних версиях testcontainers-scala ленивая инциализация контейнеров поддерживается из коробки:
class MyTest extends FreeSpec with ForAllTestContainer with BeforeAndAfterAll { val network: Network = Network.newNetwork() val dbName = "some_db" val pgContainerAlias = "postgres" val jdbcUrl = s"jdbc:postgresql://$pgContainerAlias:5432/$dbName" lazy val pgCont = { val c = PostgreSQLContainer("postgres:9.6") c.container.withNetwork(network) c.container.withNetworkAliases(pgContainerAlias) c.container.withDatabaseName(dbName) c } lazy val appCont = { val c = AppContainer(jdbcUrl, pgCont.username, pgCont.password) c.container.withNetwork(network) c } override val container = MultipleContainers(pgCont, appCont) override def afterAll(): Unit = { super.afterAll() network.close() } // tests here }
Можно снова использовать
ForAllTestContainer и MultipleContainers. В beforeAll больше не нужно вручную прописывать порядок запуска. Теперь MultipleContainers может работать с lazy val и запускать их в правильном порядке, и не делает strict инициализации сразу по созданию. При этом, манипуляции с кастомной сетью и jdbcUrl также нужно делать вручную.Mocks
Однако, все еще есть проблемы. Например моки. Иногда бывает не очень удобно создавать какую-то зависимость в docker-контейнере. Мы используем Spark JobServer, который создает Spark job’ы и контролирует их жизненный цикл в Spark. Мы используем два его метода: «создать» и «дать статус».
Чтобы запустить Spark JobServer внутри docker. Нужно поднять Spark, а до недавнего времени у него вообще не было docker-контейнера и нужно было собирать его самостоятельно. Кроме того, Spark JobServer использует PostgreSQL для хранения состояний. В итоге приходится проделывать большую и сложную работу, когда на самом деле нужны всего два метода с простым API.
Но можно подсмотреть в реализацию Spark JobServer и создать mock, который ведёт себя так же как, но не требует зависимостей оригинального Spark JobServer.
Это выглядит следующим образом (в примере упрощённый псевдокод):
val hostIp = ??? AppContainer(sparkJobServerMockHost = hostIp) val sparkJobServerMock = new SparkJobServerMock() sparkJobServerMock.init(someData) val apiResult = appApi.callMethod() assert(apiResult == someData)
Прямо в тестах создается и запускается http-сервер с таким же API как и у Spark JobServer. Он инициализируется с какими-то данными, а затем мы направляем приложение на этот сервер вместо настоящего. То, что возвращает метод, должно соответствовать тому, что мы положили в mock.
Но нужно как-то передать контейнеру, как ему подключаться к этому моку. С портом все более или менее понятно: мы можем его «зашить» или положить в config; вопрос в том, какой нужен host.
Наш
SparkJobServerMock запускается прямо из теста, то есть работает на host-машине, а приложение работает в docker-контейнере, который, в свою очередь, работает в одной из наших кастомных docker-сетей.Каким же образом получить этот адрес? Если вы хорошо знаете устройство docker-сетей, то должны догадаться, что нужно использовать gateway той сети, где находится docker-контейнер.
Проблема в том, что у Testcontainers нет такого API. Однако, так как Testcontainers работает поверх обычного docker-java-клиента, можно спуститься на его уровень. То есть использовать «голый» docker-клиент:
val client: com.github.dockerjava.api.DockerClient = DockerClientFactory .instance .client val networkInfo: com.github.dockerjava.api.model.Network = client .inspectNetworkCmd() .withNetworkId(network.getId) .exec() val hostIp: String = networkInfo .getIpam .getConfig .get(0) .getGateway
Во-первых, нужно взять
DockerClient. У Testcontainers есть DockerClientFactory для этого. Потом cформировать команду inspectNetworkCmd. И в конце, из info, получаем gateway.На первый взгляд может показаться сложным, но когда сделаешь это один раз, все станет понятнее.
Но с этим решением есть проблема — оно работает не везде. Docker работает в разных окружениях: Windows, Mac, может быть удаленным. Но эта программа будет работать только на Linux. Для нас это не проблема, так как, мы все пишем на Linux и прогоняем тесты тоже на нём.
К счастью, в новых версиях Testcontainers эта проблема была решена. Теперь можно пробросить порт с хостовой машины таким образом, чтобы он был доступен в docker-сети. Делается это следующим образом:
Testcontainers.exposeHostPorts(sparkJobServerMockPort)
Важно, чтобы этот метод был вызван до запуска контейнеров. После вызова хостовый порт будет доступен внутри docker-контейнеров. А в качестве хоста нужно будет использовать
`host.testcontainers.internal`.Таким образом, наш код значительно упростится:
val sparkJobServerMockHost = "host.testcontainers.internal" val sparkJobServerMockPort = 33333 Testcontainers.exposeHostPorts(sparkJobServerPort) AppContainer(sparkJobServerMockHost, sparkJobServerMockPort)
Развитие Testcontainers
Как видно из примеров, описанных выше, за последнее время в Testcontainers появилось много улучшений, которые значительно упрощают жизнь пользователей библиотеки. Развивается как Java-библиотека, так и Scala-фасад. Среди основных направлений развития можно отметить следующие:
- Движение в сторону отказа от жесткой интеграции с тестовыми фреймворками. Изначально, testcontainers-java работал только с JUnit, а testcontainers-scala только со ScalaTest, но сейчас testcontainers-java может работать и с другими тестовыми фреймворками. В Scala-фасаде тоже планируются подобные изменения.
- Модуляризация Scala фасада. Сейчас библиотека публикуется как единый модуль. Это является источником проблемы, описанной в первом пункте. Кроме того, для использования predefined контейнеров всё равно приходится подключать дополнительные модули из Java-библиотеки. Так что логичнее вынести этот код в модули, что упростит использование и развитие библиотеки.
- Более безопасный API. Некоторые проблемы библиотеки можно решить на уровне API, чтобы пользователи просто не могли допустить ошибки в своём коде. Например, вместо мутабельных контейнеров можно использовать иммутабельные. Тогда проблема с тем, что мы пытаемся обратиться к незапущенному контейнеру, отпадёт сама собой.
Итоги
Сделать хорошие интеграционные тесты сложно. Docker помогает, но тянет за собой много особенностей, с ним нужно достаточно долго разбираться, чтобы в конце концов понять, что нужен network gateway.
Testcontainers — очень хорошая библиотека, которая решает многие проблемы. API еще не идеальный, но с каждым годом становится лучше.
Если вы не из Java-мира, то в любом случае сам подход очень хорош. Представление контейнеров в виде объектов — выигрышная стратегия на текущий момент. Взаимодействовать с ним очень удобно.
Для других языков и систем есть похожие библиотеки, и всегда есть docker-клиент, с помощью которого вы можете реализовать свой похожий проект.
Вопросы и ответы после доклада
— Все это работает исключительно в тестовом окружении, и вы не используете все эти наработки, например, для деплоя сервисов и т. д.?
Нет, деплой и тесты отдельно.
— Но ведь из-за контейнеров довольно заметно различается окружение?
Так как у нас Kubernetes, у нас все в контейнерах. И речь идет не об end-to-end тестах, а об интеграционных тестах, то есть в них, когда все поднято, это работает вместе.
Это не самый высокий слой тестов, а немного ниже, но при этом это и не unit-тесты, когда мы даем просто маленький кусочек кода с тестированием метода или класса.
— Почему тестовое окружение нельзя было разворачивать в отдельном Kubernetes и против него тестировать?
Во-первых, это сложнее, а во-вторых, как я показывал, иногда это не очень удобно, то есть с моках все будет гораздо сложнее, а возможность поднять Spark в Kubernetes появилась буквально недавно; мы делали все это до ее появления, и нам бы пришлось снова изобретать велосипед.
Далее, такой подход позволяет все описать в коде, то есть я просто пишу unit-тест, я могу там, скажем, поставить break point и посмотреть, в каком состоянии у меня все находится, потому что это важно.
Представим, я поменял код, запустил тесты, а на CI выходит ошибка, тогда я должен иметь возможность посмотреть.
Кроме того, есть очень много негативных отзывов про minicube — он не работает на Mac, например. Не хотелось бы со всем этим связываться, но у нас есть другие команды, которые этим пользуются, и вроде как, все нормально.
— Как задать конкретную версию контейнера? По какой версии они у вас работают: всегда master? Допустим, у меня есть какой-то сервис, у него, скажем версия 2.1, а моя ветка 2.2, и как быть?
Нужно просто задать ImageName, я задавал Postgres 9.6.
Я задаю версию 9.6, по умолчанию там будет 10. То есть пишем [имя контейнера], ставим двоеточие и его тег.
В конфиге у нас есть Image tag — это конфигурационное значение, — и мы каждую ветку маркируем определенным тегом, тогда каждая ветка независимо прогоняется со своим тегом. Когда все работает хорошо, у мастера есть latest и есть теги.
— Значит, в конфигурационном файле ветки я должен написать имя моего лейбла докера?
Да, из CI это подтягивается очень легко, в GitLab CI это, кажется, называется Branch Name.
— Вы сказали, что у вас один сервис тестируется, то есть он интеграционный, но против инфраструктуры? Или у вас есть какие-то тесты, где у вас описано несколько сервисов? Неужели у ваших 20-ти сервисов нет интерзависимости, которую требуется тестировать?
Во-первых, эти тесты находятся в репозитории самого приложения, и они относятся исключительно к тестам самого приложения. Если это приложение зависит от наших, то оно использует либо эти контейнеры, либо моки, в зависимости, какая перед ним стоит задача, как удобнее.
Какого-то большого интеграционного теста у нас нет, мы делаем это вручную, но этим занимаются full-time тестировщики, а интеграционные тесты, по крайней мере в нашей команде, пишут разработчики.
Эти тесты прогоняются с каждым commit’ом, а большая интеграция нужна не так часто, обычно, когда выходит одна новая большая фича, и там нужны Android, iOS и т. д. Это происходит не часто, и это чуть более высокий уровень тестирования, а то, что я представил, — чуть более низкий.
Есть некоторая проблема с терминологией, то есть, в разных источниках это называют по-разному: где-то интеграционные тесты, где-то функциональные. Возможно, из-за этого возникло некоторое недопонимание.
Нет, деплой и тесты отдельно.
— Но ведь из-за контейнеров довольно заметно различается окружение?
Так как у нас Kubernetes, у нас все в контейнерах. И речь идет не об end-to-end тестах, а об интеграционных тестах, то есть в них, когда все поднято, это работает вместе.
Это не самый высокий слой тестов, а немного ниже, но при этом это и не unit-тесты, когда мы даем просто маленький кусочек кода с тестированием метода или класса.
— Почему тестовое окружение нельзя было разворачивать в отдельном Kubernetes и против него тестировать?
Во-первых, это сложнее, а во-вторых, как я показывал, иногда это не очень удобно, то есть с моках все будет гораздо сложнее, а возможность поднять Spark в Kubernetes появилась буквально недавно; мы делали все это до ее появления, и нам бы пришлось снова изобретать велосипед.
Далее, такой подход позволяет все описать в коде, то есть я просто пишу unit-тест, я могу там, скажем, поставить break point и посмотреть, в каком состоянии у меня все находится, потому что это важно.
Представим, я поменял код, запустил тесты, а на CI выходит ошибка, тогда я должен иметь возможность посмотреть.
Кроме того, есть очень много негативных отзывов про minicube — он не работает на Mac, например. Не хотелось бы со всем этим связываться, но у нас есть другие команды, которые этим пользуются, и вроде как, все нормально.
— Как задать конкретную версию контейнера? По какой версии они у вас работают: всегда master? Допустим, у меня есть какой-то сервис, у него, скажем версия 2.1, а моя ветка 2.2, и как быть?
Нужно просто задать ImageName, я задавал Postgres 9.6.
val pgContainer: PostgreSQLContainer = PostgreSQLContainer("postgres:9.6")
Я задаю версию 9.6, по умолчанию там будет 10. То есть пишем [имя контейнера], ставим двоеточие и его тег.
В конфиге у нас есть Image tag — это конфигурационное значение, — и мы каждую ветку маркируем определенным тегом, тогда каждая ветка независимо прогоняется со своим тегом. Когда все работает хорошо, у мастера есть latest и есть теги.
— Значит, в конфигурационном файле ветки я должен написать имя моего лейбла докера?
Да, из CI это подтягивается очень легко, в GitLab CI это, кажется, называется Branch Name.
— Вы сказали, что у вас один сервис тестируется, то есть он интеграционный, но против инфраструктуры? Или у вас есть какие-то тесты, где у вас описано несколько сервисов? Неужели у ваших 20-ти сервисов нет интерзависимости, которую требуется тестировать?
Во-первых, эти тесты находятся в репозитории самого приложения, и они относятся исключительно к тестам самого приложения. Если это приложение зависит от наших, то оно использует либо эти контейнеры, либо моки, в зависимости, какая перед ним стоит задача, как удобнее.
Какого-то большого интеграционного теста у нас нет, мы делаем это вручную, но этим занимаются full-time тестировщики, а интеграционные тесты, по крайней мере в нашей команде, пишут разработчики.
Эти тесты прогоняются с каждым commit’ом, а большая интеграция нужна не так часто, обычно, когда выходит одна новая большая фича, и там нужны Android, iOS и т. д. Это происходит не часто, и это чуть более высокий уровень тестирования, а то, что я представил, — чуть более низкий.
Есть некоторая проблема с терминологией, то есть, в разных источниках это называют по-разному: где-то интеграционные тесты, где-то функциональные. Возможно, из-за этого возникло некоторое недопонимание.
Хотите больше подробностей о собственно микросервисах и не только на Scala – в программе нашей ScalaConf есть ответы на разные вопросы. Больше интересуетесь архитектурой и взаимосвязями разных её частей – приходите на HighLoad++ 7-8 ноября.
Все такое вкусное, и непонятно, что выбрать, тогда подпишитесь на рассылку, в которой мы рассказываем о докладах и собираем полезные материалы по теме.

