Пять лет назад на Хабре была опубликована статья «Печать и воспроизведение звука на бумаге» — о системе создания и проигрывания спектрограмм. Затем, полтора года назад Meklon опубликовал квест, в котором такая чёрно-белая логарифмическая спектрограмма стала одним из этапов. По авторскому замыслу, её надо было распечатать на принтере, отсканировать смартфоном с приложением-проигрывателем, и воспользоваться таким образом «надиктованным» паролем.

У меня в тот момент не было в досягаемости ни принтера, ни смартфона, так что меня заинтересовали два аспекта задачи:
(Для тех, кто видит спектрограммы впервые, стоит пояснить, что это график, где по горизонтальной оси идёт время воспроизведения, по вертикальной (она логарифмическая) — частота звука, а степень черноты точки обозначает мощность данной частоты в данный момент времени.)
Готовых скриптов для воспроизведения спектрограмм я не нашёл, хотя для обратного преобразования — звука в спектрограмму — легко* находятся примеры, благодаря тому, что функциональность
Результатом вы можете полюбоваться на tyomitch.github.io/#meklon.png
Внизу видны повторяющиеся горизонтальные полосы — форманты, по положению которых распознаются гласные. Вверху — вертикальные «всплески», соответствующие шумным согласным: более широкие — щелевым (фрикативным), более узкие — смычным. Сонорным же согласным ([р] и [л]) соответствуют «облака» в средних частотах.

Для того, чтобы можно было поиграть со спектрограммой, я приделал примитивную рисовалку, почти целиком скопированную из туториала по рисованию на canvas. Кнопка «Copy» позволяет перевести изображение в красный канал (он игнорируется синтезатором) и попытаться «обвести» звуки.
Википедия пишет: «Считается, что для характеристики звуков речи достаточно выделения четырёх формант». Обведём форманты F2-F4 (F1 почему-то игнорируется синтезатором), и убедимся, что гласные вполне распознаются:
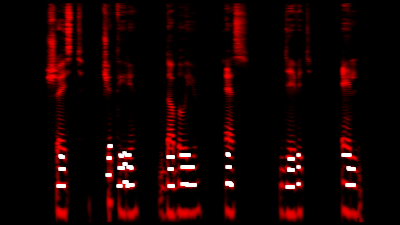
Затем обведём шумные согласные: аффриката [ч] — это [т], плавно переходящее в [ш]; а звонкое [д] от глухого [т] отличается наличием среднечастотных формант. Теперь уже можно различить цифры «шесть» и «де'ить»:

Добавляем тёмно-серым сонорные согласные: заодно заметим, что [р] немного «приподнимает» гласные форманты, а [л] — наоборот, опускает.

Остались недорисованными только губные согласные [б] и [в], но и без них пароль более-менее ясен.
А можно ли нарисовать звук с чистого листа, не обводя спектрограмму аудиозаписи? Скажу честно, у меня не получилось. Может быть, хотите попробовать сами?
У меня в тот момент не было в досягаемости ни принтера, ни смартфона, так что меня заинтересовали два аспекта задачи:
- Как проще всего расшифровать спектрограмму без дополнительных устройств и без дополнительного софта — желательно, прямо в браузере?
- Можно ли её расшифровать вообще без софта — «на глаз»?
(Для тех, кто видит спектрограммы впервые, стоит пояснить, что это график, где по горизонтальной оси идёт время воспроизведения, по вертикальной (она логарифмическая) — частота звука, а степень черноты точки обозначает мощность данной частоты в данный момент времени.)
Готовых скриптов для воспроизведения спектрограмм я не нашёл, хотя для обратного преобразования — звука в спектрограмму — легко* находятся примеры, благодаря тому, что функциональность
AnalyserNode.getByteFrequencyData() встроена в Web Audio API. А вот для преобразования массива частот в массив PCM для воспроизведения — не обойтись без реализации в скрипте обратного преобразования Фурье (DFT).*В первом примере в качестве аудиозаписи для спектрального анализа предлагается фрагмент трека "По поводу реализации DFT сразу ясно, что такая «числодробилка» на чистом JavaScript будет работать медленно и печально; к счастью, я обнаружил готовый порт библиотеки FFTW («Fastest Fourier Transform in the West») на asm.js — это форма представления низкоуровневого кода, обычно написанного на Си, которую современные браузеры обещают выполнять со скоростью почти как у скомпилированного в машинный код. Обвязку для FFTW, превращающую чёрно-белое изображение в WAV-файл, я взял из ARSS и собственноручно переписал на JavaScript. ARSS принимает изображения, инвертированные по сравнению с PhonoPaper, и я не стал это менять." от Aphex Twin: в качестве секретного послания музыкант встроил в этот трек селфи, проявляющееся на логарифмической спектрограмме. К сожалению, в этом примере спектрограмма отображается линейно, так что лицо получается растянутым вверху и сжатым внизу.
Результатом вы можете полюбоваться на tyomitch.github.io/#meklon.png
Внизу видны повторяющиеся горизонтальные полосы — форманты, по положению которых распознаются гласные. Вверху — вертикальные «всплески», соответствующие шумным согласным: более широкие — щелевым (фрикативным), более узкие — смычным. Сонорным же согласным ([р] и [л]) соответствуют «облака» в средних частотах.
Для того, чтобы можно было поиграть со спектрограммой, я приделал примитивную рисовалку, почти целиком скопированную из туториала по рисованию на canvas. Кнопка «Copy» позволяет перевести изображение в красный канал (он игнорируется синтезатором) и попытаться «обвести» звуки.
Википедия пишет: «Считается, что для характеристики звуков речи достаточно выделения четырёх формант». Обведём форманты F2-F4 (F1 почему-то игнорируется синтезатором), и убедимся, что гласные вполне распознаются:
Затем обведём шумные согласные: аффриката [ч] — это [т], плавно переходящее в [ш]; а звонкое [д] от глухого [т] отличается наличием среднечастотных формант. Теперь уже можно различить цифры «шесть» и «де'ить»:
Добавляем тёмно-серым сонорные согласные: заодно заметим, что [р] немного «приподнимает» гласные форманты, а [л] — наоборот, опускает.
Остались недорисованными только губные согласные [б] и [в], но и без них пароль более-менее ясен.
А можно ли нарисовать звук с чистого листа, не обводя спектрограмму аудиозаписи? Скажу честно, у меня не получилось. Может быть, хотите попробовать сами?


{kind=link}
{kind=link}
{kind=link}
{kind=link}