Мы в поте лица готовим очередную мажорную версию Tokio, асинхронной среды выполнения для Rust. 13 октября для слияния в ветку оформлен пул-реквест с полностью переписанным планировщиком задач. Результатом станет огромное улучшение производительности и уменьшение задержки. В некоторых тестах зафиксировано десятикратное ускорение! Как обычно, синтетические тесты не отражают фактическую выгоду в реальности. Поэтому мы также проверили, как изменения в планировщике повлияли на настоящие задачи, такие как Hyper и Tonic (спойлер: результат замечательный).
Готовясь к работе над новым планировщиком, я потратил время на поиск тематических ресурсов. Кроме фактических реализаций, особо ничего не нашлось. Я также обнаружил, что в исходниках существующих реализаций трудно ориентироваться. Чтобы исправить это, мы постарались написать шедулер Tokio как можно более чисто. Надеюсь, эта подробная статья о реализации планировщика поможет тем, кто находится в том же положении и безуспешно ищет информацию на эту тему.
Статья начинается с высокоуровневого обзора дизайна, в том числе политик захвата работы. Затем погрузимся в детали конкретных оптимизаций в новом планировщике Tokio.
Рассмотренные оптимизации:
Как видите, основная тема — «сокращение». В конце концов, самый быстрый код — это его отсутствие!
Поговорим также о тестировании нового планировщика. Очень сложно написать правильный, параллельный код без блокировок. Лучше работать медленно, но правильно, чем быстро, но с глюками, особенно если баги относятся к безопасности памяти. Лучший вариант, однако, должен работать быстро и без ошибок, поэтому мы написали loom, инструмент для тестирования параллелизма.
Прежде чем погрузиться в тему, хочу выразить благодарности:
Возьмите чашку кофе и устраивайтесь поудобнее. Это будет длинная статья.
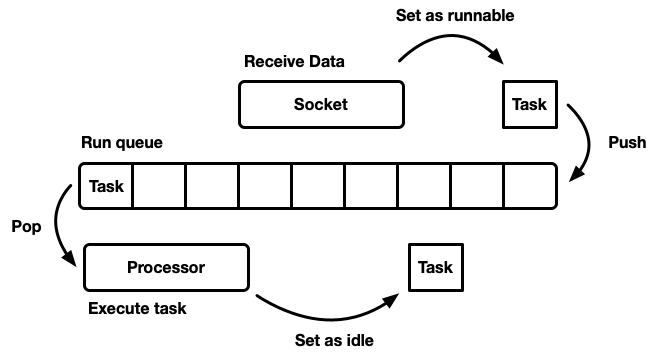
Задача шедулера заключается в планировании работы. Приложение разбивается на единицы работы, которые мы будем называть задачами (task). Задача считается выполняемой (runnable), когда может продвигаться в своём исполнении, а более не выполняемой или в режиме ожидания (idle), когда заблокирована на внешнем ресурсе. Задачи независимы в том смысле, что любое число выполняемых задач может выполняться одновременно. Планировщик отвечает за выполнение задач в запущенном состоянии, пока они не вернутся в режим ожидания. Выполнение задачи подразумевает назначение задаче процессорного времени — глобального ресурса.
В статье рассматриваются планировщики пользовательского пространства, то есть работающие поверх потоков операционной системы (которыми, в свою очередь, управляет шедулер уровня ядра). Планировщик Tokio выполняет «фьючерсы» Rust, которые можно рассматривать как «асинхронные зелёные потоки». Это шаблон смешанной потоковости M:N, в которой многие задачи пользовательского интерфейса мультиплексируются на несколько потоков операционной системы.
Есть много разных способов смоделировать шедулер, у каждого свои плюсы и минусы. На самом базовом уровне планировщик можно смоделировать как очередь выполнения и процессор, который её растаскивает. Процессор — это часть кода, которая выполняется в потоке. В псевдокоде он делает следующее:
Когда задача становится выполнимой, её вставляют в очередь выполнения.
Хотя можно спроектировать систему, в которой ресурсы, задачи и процессор существуют в одном потоке, Tokio предпочитает использовать несколько потоков. Мы живём в мире, где у компьютера много процессоров. Разработка однопоточного планировщика приведёт к недостаточной загрузке железа. Мы хотим использовать все CPU. Есть несколько способов сделать это:
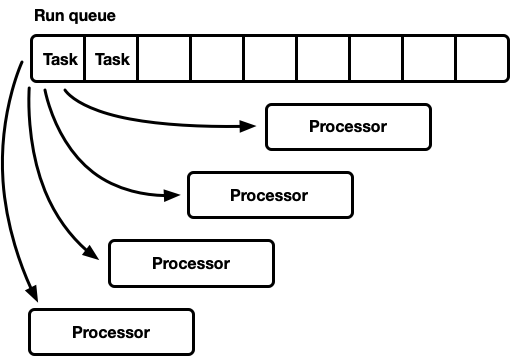
В этой модели одна глобальная очередь выполнения. Когда задачи становятся выполняемыми, они помещаются в хвост очереди. Есть несколько процессоров, каждый в отдельном потоке. Каждый процессор берёт задачу из головы очереди или блокирует поток, если нет доступных задач.
Очередь выполнения должна поддерживать множество производителей и потребителей. Обычно используется интрузивный список, в котором сама структура каждой задачи включает указатель на следующую задачу в очереди (вместо обёртывания задач в связанный список). Таким образом, можно избежать выделения памяти для операций push и pop. Можно использовать операцию push без блокировки, но для координации потребителей для операции pop требуется мьютекс (технически возможно реализовать многопользовательскую очередь без блокировки).
Однако на практике оверхед для правильной защиты от блокировок больше, чем просто использование мьютекса.
Такой подход часто используется для пула потоков общего назначения, поскольку у него ряд преимуществ:
Краткое замечание о справедливом (равнодоступном) планировании. Оно означает, что задачи выполняются честно: кто раньше пришёл — тот раньше вышел. Планировщики общего назначения стараются быть справедливыми, но есть исключения, такие как распараллеливание через fork-join, где важным фактором принимается скорость вычисления результата, а не справедливость для каждой отдельной подзадачи.
У такой модели есть обратная сторона. Все процессоры претендуют на задачи из головы очереди. Для потоков общего назначения это обычно не проблема. Время на выполнение задачи намного превышает время на её извлечение из очереди. Когда задачи выполняются в течение длительного периода времени, конкуренция в очереди уменьшается. Однако асинхронные задачи Rust, как ожидается, выполняются очень быстро. В этом случае значительно возрастают накладные расходы за борьбу в очереди.
Чтобы добиться максимальной производительности, мы должны максимально использовать аппаратные функции. Термин «симпатия к железу» (mechanical sympathy) в отношении программного обеспечения впервые использовал Мартин Томпсон (чей блог больше не обновляется, но по-прежнему весьма познавателен).
Подробное обсуждение реализации параллелизма в современном оборудовании выходит за рамки этой статьи. Если сильно обобщить, то железо увеличивает производительность не за счёт ускорения, а за счёт внедрения большего числа ядер CPU (даже у моего ноутбука их шесть!) Каждое ядро может выполнять большие объёмы вычислений за крошечные промежутки времени. Такие действия, как доступ к кэшу и памяти, занимают гораздо больше времени относительно времени выполнения в CPU. Поэтому для ускорения приложений нужно максимизировать количество инструкций CPU на каждый доступ к памяти. Хотя компилятор сильно помогает, нам всё равно придётся думать о таких вещах, как выравнивание и шаблоны доступа к памяти.
Параллельные потоки по отдельности работают очень похоже на один изолированный поток, пока несколько потоков не изменяют одновременно одну и ту же строку кеша (concurrent mutations) или не требуется последовательная согласованность. В этом случае активируется протокол когерентности кэша CPU. Он гарантирует актуальность кеша каждого CPU.
Вывод очевиден: насколько возможно, избегайте синхронизации между потоками, потому что она медленная.
Другая модель — несколько однопоточных планировщиков. Каждый процессор получает собственную очередь выполнения, и задачи закрепляются на определённом процессоре. Это позволяет полностью избежать проблемы синхронизации. Поскольку модель задач Rust требует возможности ставить задачу в очередь из любого потока, по-прежнему должен быть потокобезопасный способ ввода задач в планировщик. Либо очередь выполнения каждого процессора поддерживает потокобезопасную операцию push (MPSC), либо в каждом процессоре две очереди выполнения: несинхронизированная и потокобезопасная.
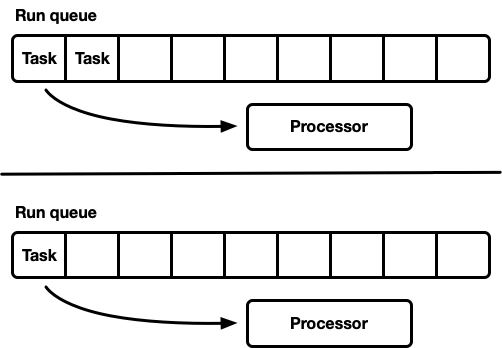
Такую стратегию использует Seastar. Поскольку мы почти полностью избегаем синхронизации, эта стратегия даёт очень хорошую скорость. Но она не решает все проблемы. Если рабочая нагрузка не полностью однородна, то некоторые процессоры находятся под нагрузкой, а другие простаивают, что приводит к не оптимальному расходованию ресурсов. Так происходит, потому что задачи закреплены на определённом процессоре. Когда в пакете запланирована группа задач на одном процессоре, он в одиночку отрабатывает пиковую нагрузку, даже если другие простаивают.
Большинство «реальных» рабочих нагрузок не однородны. Поэтому планировщики общего назначения обычно избегают этой модели.
Планировщик с политиками захвата работы (work-stealing scheduler) основан на модели распределённого планировщика (sharded scheduler) и решает проблему неполной загрузки аппаратных ресурсов. Каждый процессор поддерживает собственную очередь выполнения. Задачи, которые становятся выполняемыми, помещаются в очередь выполнения текущего процессора, и он над ней работает. Но когда процессор простаивает, он проверяет очереди родственного процессора и пытается оттуда что-нибудь выхватить. Процессор переходит в спящий режим только после того, как не сможет найти работу из одноранговых очередей выполнения.
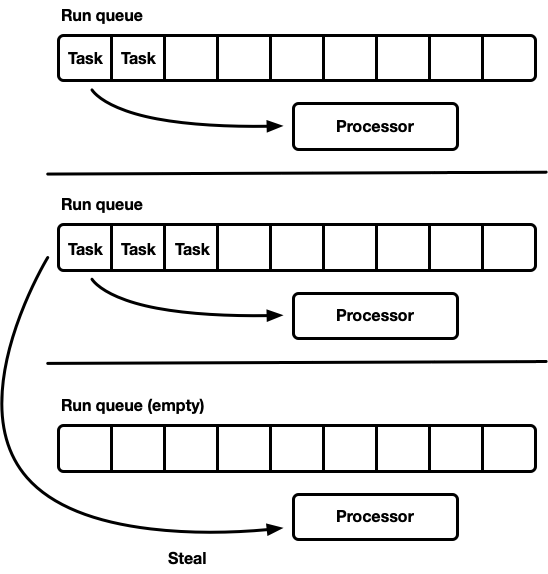
На уровне модели это подход «лучшее из обоих миров». Под нагрузкой процессоры работают независимо, избегая оверхеда синхронизации. В тех случаях, когда нагрузка между процессорами распределяется неравномерно, планировщик может её перераспределить. Вот почему такие планировщики используются в Go, Erlang, Java и других языках.
Недостатком является то, что этот подход намного сложнее. Алгоритм очереди должен поддерживать захват работы, а для бесперебойного выполнения требуется некоторая синхронизация между процессорами. Если её неправильно реализовать, то оверхед на реализацию захвата может быть больше, чем полученная выгода.
Рассмотрим такую ситуацию: процессор A в данный момент выполняет задачу, и у него пустая очередь выполнения. Процессор B простаивает; он пытается захватить какую-нибудь задачу, но терпит неудачу, поэтому переходит в спящий режим. Затем из задачи процессора А спаунится 20 заданий. В идеале, процессор B должен проснуться и захватить некоторые из них. Для этого требуется реализовать определённые эвристики в планировщике, где процессоры сигнализируют спящим одноранговым процессорам о появлении новых задач в своей очереди. Конечно, это требует дополнительной синхронизации, поэтому такие операции лучше свести к минимуму.
В итоге:
Первый рабочий планировщик для Tokio вышел в марте 2018 года. Это была первая попытка, основанная на некоторых предположениях, которые оказались неверными.
Во-первых, планировщик Tokio 0.1 предполагал, что процессорные потоки следует закрывать, если они простаивают определённое время. Планировщик изначально создавался как система «общего назначения» для пула потоков Rust. В то время среда выполнения Tokio ещё находилась на ранней стадии разработки. Тогда модель предполагала, что задачи I/O будут выполняться в одном потоке с селектором ввода-вывода (epoll, kqueue, iocp...). Больше вычислительных задач можно было бы направить в пул потоков. В этом контексте предполагается гибкая настройка числа активных потоков, так что имеет больше смысла отключать бездействующие потоки. Однако в планировщике с захватом работы модель перешла на выполнение всех асинхронных задач, а в этом случае есть смысл всегда поддерживать небольшое количество потоков в активном состоянии.
Во-вторых, там была реализована двусторонняя очередь crossbeam. Эта реализация основана на двусторонней очереди Чейза — Лева, а она не подходит для планирования независимых асинхронных задач по причинам, описанным ниже.
В-третьих, реализация оказалась слишком сложной. Отчасти это связано с тем, что это был мой первый планировщик задач. Кроме того, я был слишком нетерпелив, применяя атомики в ветках, где просто отлично справился бы мьютекс. Важный урок заключается в том, что очень часто именно мьютексы подходят лучше всего.
Наконец, в первоначальной реализации было много мелких недостатков. В первые годы детали реализации асинхронной модели Rust значительно эволюционировали, но библиотеки всё время сохраняли стабильность API. Это привело к накоплению некоторого технического долга.
Сейчас Tokio приближается к первому крупному релизу — и мы можем оплатить весь этот долг, а также извлечь уроки из опыта, полученного за годы разработки. Это захватывающее время!
Теперь пришло время подробнее разобрать, что изменилось в новом планировщике.
Во-первых, важно выделить то, что не является частью Tokio, но имеет решающее значение в части повышения эффективности: это новая система задач в
Структура
Очередь выполнения находится в центре планировщика. Таким образом, это самый важный компонент для исправления. В оригинальном планировщике Tokio использовалась двусторонняя очередь crossbeam: реализация с одним источником (producer) и многими потребителями. Задача помещаются с одного конца, а значения извлекаются с другого. Большую часть времени поток «выталкивает» значения с конца очереди, но иногда другие потоки перехватывают работу, производя такую же операцию. Двусторонняя очередь поддерживается массивом и набором индексов, отслеживающих голову и хвост. Когда очередь полна, внедрение в неё приведёт к росту места для хранения. Выделяется новый, более крупный массив, а значения перемещаются в новое хранилище.
Способность расти достигается за счёт сложности и накладных расходов. Операции push/pop должны учитывать этот рост. Кроме того, освобождение исходного массива сопряжено с дополнительными трудностями. В языке со сборкой мусора (GC) старый массив выйдет из области видимости, и в конечном итоге GC его очистит. Однако Rust поставляется без GC. Это означает, что мы сами несём ответственность за освобождение массива, но потоки могут пытаться одновременно получить доступ к памяти. Для решения этой проблемы crossbeam использует стратегию утилизации по эпохам (epoch based reclamation strategy). Хотя она не требует много ресурсов, но добавляет нетривиальные накладные расходы в основной поток выполнения (hot path). Каждая операция теперь должна выполнять атомарные операции RMW (read-modify-write) на входе и выходе из критических секций для сигнализации другим потокам, что память используется и её нельзя очищать.
Из-за оверхеда на рост очереди выполнения есть смысл задуматься: действительно ли настолько необходима поддержка этого роста? Этот вопрос в конечном итоге и подтолкнул меня переписать планировщик. Новая стратегия заключается в фиксированном размере очереди для каждого процесса. Когда очередь заполнена, вместо увеличения локальной очереди задача перемещается в глобальную очередь с несколькими потребителями и несколькими производителями. Процессоры будут периодически проверять эту глобальную очередь, но с гораздо меньшей частотой, чем локальную.
В рамках одного из первых экспериментов мы заменили crossbeam на mpmc. Это не привело к значительному улучшению из-за количества синхронизации для push и pop. Ключевой момент в захвате работы заключается в том, что под нагрузкой почти нет конкуренции в очередях, поскольку каждый процессор обращается только к своей собственной очереди.
На этом этапе я решил внимательнее изучить исходники Go — и обнаружил, что там используется фиксированный размер очереди с одним производителем и несколькими потребителями, при этом с минимальной синхронизацией, что очень впечатляет. Для адаптации алгоритма к планировщику Tokio я сделал несколько изменений. Примечательно, что реализация Go использует последовательные атомарные операции (насколько я понял). Версия для Tokio также уменьшает число некоторых операций копирования в более редких ветках кода.
Реализация очереди представляет собой циклический буфер, который хранит значения в массиве. Голова и хвост очереди отслеживаются атомарными операциями с целочисленными значениями.
Внедрение в очередь выполняется одним потоком:
Обратите внимание, что в этой функции
Когда очередь заполнена, вызывается
Если вы знакомы с деталями атомарных упорядочений памяти, то можете заметить потенциальную «проблему» с показанной выше функцией
Локальный
В этой функции один атомарный
Функция
Последняя недостающая часть — разбор глобальной очереди, куда поступают задачи, переполняющие локальные очереди, а также для передачи задач планировщику из непроцессорных потоков. Если процессор под нагрузкой, то есть в локальной очереди есть задачи, то процессор попытается вытянуть задачи из глобальной очереди примерно после каждых 60-ти задач локальной очереди. Он также проверяет глобальную очередь, когда находится в состоянии «поиска», описанном ниже.
Приложения на Tokio обычно состоят из множества небольших независимых задач. Они взаимодействуют друг с другом с помощью сообщений. Такой шаблон похож на другие языки, такие как Go и Erlang. Учитывая, насколько распространён шаблон, планировщику есть смысл его оптимизировать.
Предположим, даны задачи А и B. Задача А сейчас выполняется и отправляет сообщение задаче B по каналу передачи. Канал является ресурсом, на котором в настоящее время заблокирована задача B, поэтому действие отправки сообщения приведёт к переходу задачи B в исполняемое состояние — и она поместится в очередь выполнения текущего процессора. Затем процессор выведет из очереди выполнения следующую задачу, выполнит её и будет повторять этот цикл, пока не достигнет задачи B.
Проблема в том, что между отправкой сообщения и выполнением задачи B может возникнуть значительная задержка. Кроме того, «горячие» данные, такие как сообщение, хранятся в кеше CPU, но к моменту выполнения задачи высока вероятность, что соответствующие кеши будут очищены.
Чтобы решить эту проблему, новый планировщик Tokio реализует оптимизацию (как в планировщиках Go и Kotlin). Когда задача переходит в исполняемое состояние, она не помещается в конец очереди, а сохраняется в специальном слоте «следующая задача». Процессор всегда проверяет этот слот перед проверкой очереди. Если при вставке в слот там уже есть старая задача, она удаляется из слота и перемещается в конец очереди. Таким образом, задача передачи сообщения выполнится практически без задержек.
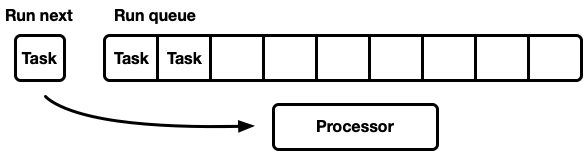
В планировщике с захватом работы, если очередь выполнения процессора пуста, процессор пытается захватить задачи из одноранговых CPU. Для начала выбирается случайный одноранговый CPU, если у него задачи не найдены, производится поиск следующего и так далее, пока не будут найдены задачи.
На практике несколько процессоров зачастую заканчивают обработку очереди выполнения примерно в одно и то же время. Это происходит, когда поступает пакет работ (например, когда
Чтобы обойти эту проблему, новый планировщик ограничивает число параллельных процессоров, выполняющих операции захвата. Мы называем состояние процессора, в котором он пытается захватить чужие задачи, «поиском работы», или «поиском» для краткости (об этом позже). Такая оптимизация выполняется с помощью атомарного значения
После перехода в состояние поиска процессор пытается захватить работу у одноранговых CPU и проверяет глобальную очередь.
Другая важная часть планировщика — уведомление одноранговых CPU о новых задачах. Если «брат» спит, он просыпается и захватывает задания. Уведомления играют ещё одну важную роль. Напомним, что алгоритм очереди использует слабое атомарное упорядочивание (
Оригинальный планировщик Tokio использовал наивный подход к уведомлениям. Всякий раз, когда новая задача помещалась в очередь выполнения, процессор получал уведомление. Всякий раз, когда CPU был уведомлён и увидел задачу после пробуждения, то уведомлял ещё один CPU. Эта логика очень быстро привела к тому, что все процессоры просыпались и искали работу (вызывая конфликт). Зачастую большинство процессоров не находили работу и снова засыпали.
Новый планировщик значительно улучшил эту схему по образцу планировщика Go. Уведомления рассылаются как и раньше, но только в том случае, если нет CPU в состоянии поиска (см. предыдущий раздел). Когда процессор получает уведомление, он немедленно переходит в состояние поиска. Когда процессор в состоянии поиска находит новые задачи, то сначала уходит из состояния поиска, а затем уведомляет другой процессор.
Такая логика ограничивает скорость, с которой просыпаются процессоры. Если запланирован сразу целый пакет задач (например, когда
Новый планировщик Tokio требует только одного выделения памяти на каждую порождённую задачу, в то время как старый требовал двух. Ранее структура задачи выглядела примерно так:
Структура
Теперь структура
Для задачи необходимы и
Последняя оптимизация, которую мы обсудим в этой статье, заключается в уменьшении количества атомарных ссылок. Есть много ссылок на структуру задачи, в том числе из планировщика и от каждого waker. Общая стратегия управления этой памятью — атомарный подсчёт ссылок. Эта стратегия требует атомарной операции при каждом клонировании ссылки и при каждом удалении ссылки. Когда последняя ссылка выходит за пределы области, память освобождается.
В старом планировщике Tokio и планировщик, и все waker'ы содержали ссылку на дескриптор задачи, примерно:
Когда пробуждается задача, ссылка клонируется (происходит атомарное приращение). Затем ссылка помещается в очередь выполнения. Когда процессор получает задачу и завершает её выполнение, то отбрасывает ссылку, что приводит к атомарному уменьшению. Эти атомарные операции (приращение и уменьшение) складываются.
Данную проблему ранее выявили разработчики системы задач
Такая конструкция API заставляет использовать при вызове
Это позволяет избежать накладных расходов на дополнительный подсчёт ссылок только в том случае, если можно взять на себя ответственность за пробуждение. По моему опыту, вместо этого почти всегда желательно просыпаться с
Новый планировщик решает проблему «пробуждения через
Сложность такой оптимизации заключается в том, что планировщик не будет удалять задачи из своего списка до тех пор, пока не получит гарантии, что задача снова будет помещена в очередь выполнения. Детали реализации этой схемы выходят за рамки этой статьи, но настоятельно рекомендую вам посмотреть исходники.
Очень сложно писать правильный, параллельный код без блокировок. Лучше работать медленно, но правильно, чем быстро, но с глюками, особенно если баги относятся к безопасности памяти. Лучший вариант, однако, должен работать быстро и без ошибок. В новом планировщике сделаны некоторые довольно агрессивные оптимизации и он избегает большинства типов
Существует несколько способов тестирования параллельного кода. Один из них — чтобы пользователи вместо вас выполняли тестирование и отладку (привлекательный вариант, это точно). Другой — написать модульные тесты, которые запускаются в цикле и могут выловить ошибку. Может, даже использовать TSAN. Конечно, если он найдёт ошибку, её невозможно легко воспроизвести без повторного запуска цикла тестов. Кроме того, сколько времени занимает этот цикл? Десять секунд? Десять минут? Десять дней? Раньше так приходилось тестировать параллельный код в Rust.
Мы посчитали неприемлемым такое положение вещей. Когда мы выпускаем код, то хотим чувствовать уверенность (насколько это возможно), особенно в случае параллельного кода без блокировок. Пользователям Tokio нужна надёжность.
Поэтому мы разработали Loom: инструмент пермутационного тестирования параллельного кода. Тесты пишутся как обычно, но
В качестве примера, вот тест loom для нового планировщика:
Выглядит достаточно нормально, но фрагмент кода в блоке
Проницательный читатель может усомниться, что loom проверяет «все возможные пермутации», и будет прав. Наивные пермутации приведут к комбинаторному взрыву. Любой нетривиальный тест никогда не завершится. Эту проблему изучали в течение многих лет, и разработан ряд алгоритмов для предотвращения комбинаторного взрыва. Основной алгоритм Loom основан на динамической редукции с частичным упорядочением (dynamic partial-order reduction). Этот алгоритм устраняет пермутации, приводящие к одинаковому результату. Но пространство состояний всё равно может вырасти до такого размера, что не будет обработано за разумное время (несколько минут). Loom позволяет дополнительно его ограничивать с помощью динамической редукции с частичным упорядочением.
В целом, благодаря обширному тестированию с помощью Loom я теперь гораздо более уверен в корректности планировщика.
Итак, мы рассмотрели, что такое планировщики и как новый планировщик Tokio добился огромного прироста производительности… но какого именно прироста? Учитывая, что новый планировщик только разработан, в реальном мире его ещё не проверили по полной программе. Вот то, что мы знаем.
Во-первых, новый планировщик намного быстрее в микро-бенчмарках:
В этот бенчмарк входит следующее:
Разница в бенчмарках очень впечатляет. Но как это отразится в «реальном мире»? Трудно сказать точно, но я попытался запустить бенчмарки Hyper.
Вот простейший сервер Hyper, производительность которого замеряется с помощью
Мы видим рост на 34% запросов в секунду просто после смены планировщика! Впервые увидев это, я очень обрадовался, поскольку ожидал увеличения максимум на 5-10%. Но потом мне стало грустно, ведь этот результат также показывал, что старый планировщик Tokio не так хорош. Затем я вспомнил, что Hyper и так лидирует в рейтингах TechEmpower. Интересно посмотреть, как новый планировщик повлияет на рейтинги.
Tonic, клиент и сервер gRPC, с новым планировщиком ускорился примерно на 10%, что довольно впечатляет, учитывая, что Tonic ещё не полностью оптимизирован.
Я действительно очень рад, наконец, завершить этот проект после нескольких месяцев работы. Это серьёзное улучшение асинхронного ввода-вывода Rust. Я очень доволен сделанными улучшениями. В коде Tokio ещё много возможностей для оптимизации, так что мы ещё не закончили с повышением производительности.
Надеюсь, что материал в статье будет полезен для коллег, которые попытаются написать свой планировщик задач.
Готовясь к работе над новым планировщиком, я потратил время на поиск тематических ресурсов. Кроме фактических реализаций, особо ничего не нашлось. Я также обнаружил, что в исходниках существующих реализаций трудно ориентироваться. Чтобы исправить это, мы постарались написать шедулер Tokio как можно более чисто. Надеюсь, эта подробная статья о реализации планировщика поможет тем, кто находится в том же положении и безуспешно ищет информацию на эту тему.
Статья начинается с высокоуровневого обзора дизайна, в том числе политик захвата работы. Затем погрузимся в детали конкретных оптимизаций в новом планировщике Tokio.
Рассмотренные оптимизации:
- Новая система задач std::future
- Выбор лучшего алгоритма очереди
- Оптимизация шаблонов передачи сообщений
- Захват дросселирования
- Сокращение синхронизации между потоками
- Сокращение выделений памяти
- Сокращение атомарного подсчёта ссылок
Как видите, основная тема — «сокращение». В конце концов, самый быстрый код — это его отсутствие!
Поговорим также о тестировании нового планировщика. Очень сложно написать правильный, параллельный код без блокировок. Лучше работать медленно, но правильно, чем быстро, но с глюками, особенно если баги относятся к безопасности памяти. Лучший вариант, однако, должен работать быстро и без ошибок, поэтому мы написали loom, инструмент для тестирования параллелизма.
Прежде чем погрузиться в тему, хочу выразить благодарности:
- @withoutboats и другим, кто работал над функцией
async / awaitв Rust. Вы проделали отличную работу. Это убойная фича.
- @cramertj и другим, кто разработал
std::task. Это огромное улучшение по сравнению с тем, что было раньше. И отличный код.
- Компании Buoyant, создателю Linkerd и, что ещё важнее, моему работодателю. Спасибо, что позволили мне потратить столько времени на эту работу. Если кого-то интересует service mesh — посмотрите на Linkerd. Скоро в него включат все преимущества, обсуждаемые в этой статье.
- Go за такую хорошую реализацию планировщика.
Возьмите чашку кофе и устраивайтесь поудобнее. Это будет длинная статья.
Как работают планировщики?
Задача шедулера заключается в планировании работы. Приложение разбивается на единицы работы, которые мы будем называть задачами (task). Задача считается выполняемой (runnable), когда может продвигаться в своём исполнении, а более не выполняемой или в режиме ожидания (idle), когда заблокирована на внешнем ресурсе. Задачи независимы в том смысле, что любое число выполняемых задач может выполняться одновременно. Планировщик отвечает за выполнение задач в запущенном состоянии, пока они не вернутся в режим ожидания. Выполнение задачи подразумевает назначение задаче процессорного времени — глобального ресурса.
В статье рассматриваются планировщики пользовательского пространства, то есть работающие поверх потоков операционной системы (которыми, в свою очередь, управляет шедулер уровня ядра). Планировщик Tokio выполняет «фьючерсы» Rust, которые можно рассматривать как «асинхронные зелёные потоки». Это шаблон смешанной потоковости M:N, в которой многие задачи пользовательского интерфейса мультиплексируются на несколько потоков операционной системы.
Есть много разных способов смоделировать шедулер, у каждого свои плюсы и минусы. На самом базовом уровне планировщик можно смоделировать как очередь выполнения и процессор, который её растаскивает. Процессор — это часть кода, которая выполняется в потоке. В псевдокоде он делает следующее:
while let Some(task) = self.queue.pop() { task.run(); }
Когда задача становится выполнимой, её вставляют в очередь выполнения.
Хотя можно спроектировать систему, в которой ресурсы, задачи и процессор существуют в одном потоке, Tokio предпочитает использовать несколько потоков. Мы живём в мире, где у компьютера много процессоров. Разработка однопоточного планировщика приведёт к недостаточной загрузке железа. Мы хотим использовать все CPU. Есть несколько способов сделать это:
- Одна глобальная очередь выполнения, много процессоров.
- Много процессоров, каждый со своей собственной очередью выполнения.
Одна очередь, много процессоров
В этой модели одна глобальная очередь выполнения. Когда задачи становятся выполняемыми, они помещаются в хвост очереди. Есть несколько процессоров, каждый в отдельном потоке. Каждый процессор берёт задачу из головы очереди или блокирует поток, если нет доступных задач.
Очередь выполнения должна поддерживать множество производителей и потребителей. Обычно используется интрузивный список, в котором сама структура каждой задачи включает указатель на следующую задачу в очереди (вместо обёртывания задач в связанный список). Таким образом, можно избежать выделения памяти для операций push и pop. Можно использовать операцию push без блокировки, но для координации потребителей для операции pop требуется мьютекс (технически возможно реализовать многопользовательскую очередь без блокировки).
Однако на практике оверхед для правильной защиты от блокировок больше, чем просто использование мьютекса.
Такой подход часто используется для пула потоков общего назначения, поскольку у него ряд преимуществ:
- Задачи справедливо запланированы.
- Относительно простая реализация. Более-менее стандартная очередь сопрягается с процессорным циклом, описанным выше.
Краткое замечание о справедливом (равнодоступном) планировании. Оно означает, что задачи выполняются честно: кто раньше пришёл — тот раньше вышел. Планировщики общего назначения стараются быть справедливыми, но есть исключения, такие как распараллеливание через fork-join, где важным фактором принимается скорость вычисления результата, а не справедливость для каждой отдельной подзадачи.
У такой модели есть обратная сторона. Все процессоры претендуют на задачи из головы очереди. Для потоков общего назначения это обычно не проблема. Время на выполнение задачи намного превышает время на её извлечение из очереди. Когда задачи выполняются в течение длительного периода времени, конкуренция в очереди уменьшается. Однако асинхронные задачи Rust, как ожидается, выполняются очень быстро. В этом случае значительно возрастают накладные расходы за борьбу в очереди.
Параллелизм и механическая симпатия
Чтобы добиться максимальной производительности, мы должны максимально использовать аппаратные функции. Термин «симпатия к железу» (mechanical sympathy) в отношении программного обеспечения впервые использовал Мартин Томпсон (чей блог больше не обновляется, но по-прежнему весьма познавателен).
Подробное обсуждение реализации параллелизма в современном оборудовании выходит за рамки этой статьи. Если сильно обобщить, то железо увеличивает производительность не за счёт ускорения, а за счёт внедрения большего числа ядер CPU (даже у моего ноутбука их шесть!) Каждое ядро может выполнять большие объёмы вычислений за крошечные промежутки времени. Такие действия, как доступ к кэшу и памяти, занимают гораздо больше времени относительно времени выполнения в CPU. Поэтому для ускорения приложений нужно максимизировать количество инструкций CPU на каждый доступ к памяти. Хотя компилятор сильно помогает, нам всё равно придётся думать о таких вещах, как выравнивание и шаблоны доступа к памяти.
Параллельные потоки по отдельности работают очень похоже на один изолированный поток, пока несколько потоков не изменяют одновременно одну и ту же строку кеша (concurrent mutations) или не требуется последовательная согласованность. В этом случае активируется протокол когерентности кэша CPU. Он гарантирует актуальность кеша каждого CPU.
Вывод очевиден: насколько возможно, избегайте синхронизации между потоками, потому что она медленная.
Много процессоров, каждый с собственной очередью выполнения
Другая модель — несколько однопоточных планировщиков. Каждый процессор получает собственную очередь выполнения, и задачи закрепляются на определённом процессоре. Это позволяет полностью избежать проблемы синхронизации. Поскольку модель задач Rust требует возможности ставить задачу в очередь из любого потока, по-прежнему должен быть потокобезопасный способ ввода задач в планировщик. Либо очередь выполнения каждого процессора поддерживает потокобезопасную операцию push (MPSC), либо в каждом процессоре две очереди выполнения: несинхронизированная и потокобезопасная.
Такую стратегию использует Seastar. Поскольку мы почти полностью избегаем синхронизации, эта стратегия даёт очень хорошую скорость. Но она не решает все проблемы. Если рабочая нагрузка не полностью однородна, то некоторые процессоры находятся под нагрузкой, а другие простаивают, что приводит к не оптимальному расходованию ресурсов. Так происходит, потому что задачи закреплены на определённом процессоре. Когда в пакете запланирована группа задач на одном процессоре, он в одиночку отрабатывает пиковую нагрузку, даже если другие простаивают.
Большинство «реальных» рабочих нагрузок не однородны. Поэтому планировщики общего назначения обычно избегают этой модели.
Планировщик с захватом работы
Планировщик с политиками захвата работы (work-stealing scheduler) основан на модели распределённого планировщика (sharded scheduler) и решает проблему неполной загрузки аппаратных ресурсов. Каждый процессор поддерживает собственную очередь выполнения. Задачи, которые становятся выполняемыми, помещаются в очередь выполнения текущего процессора, и он над ней работает. Но когда процессор простаивает, он проверяет очереди родственного процессора и пытается оттуда что-нибудь выхватить. Процессор переходит в спящий режим только после того, как не сможет найти работу из одноранговых очередей выполнения.
На уровне модели это подход «лучшее из обоих миров». Под нагрузкой процессоры работают независимо, избегая оверхеда синхронизации. В тех случаях, когда нагрузка между процессорами распределяется неравномерно, планировщик может её перераспределить. Вот почему такие планировщики используются в Go, Erlang, Java и других языках.
Недостатком является то, что этот подход намного сложнее. Алгоритм очереди должен поддерживать захват работы, а для бесперебойного выполнения требуется некоторая синхронизация между процессорами. Если её неправильно реализовать, то оверхед на реализацию захвата может быть больше, чем полученная выгода.
Рассмотрим такую ситуацию: процессор A в данный момент выполняет задачу, и у него пустая очередь выполнения. Процессор B простаивает; он пытается захватить какую-нибудь задачу, но терпит неудачу, поэтому переходит в спящий режим. Затем из задачи процессора А спаунится 20 заданий. В идеале, процессор B должен проснуться и захватить некоторые из них. Для этого требуется реализовать определённые эвристики в планировщике, где процессоры сигнализируют спящим одноранговым процессорам о появлении новых задач в своей очереди. Конечно, это требует дополнительной синхронизации, поэтому такие операции лучше свести к минимуму.
В итоге:
- Чем меньше синхронизации — тем лучше.
- Захват работы является оптимальным алгоритмом для планировщиков общего назначения.
- Каждый процессор работает независимо от других, но для захвата работы требуется некоторая синхронизация.
Планировщик Tokio 0.1
Первый рабочий планировщик для Tokio вышел в марте 2018 года. Это была первая попытка, основанная на некоторых предположениях, которые оказались неверными.
Во-первых, планировщик Tokio 0.1 предполагал, что процессорные потоки следует закрывать, если они простаивают определённое время. Планировщик изначально создавался как система «общего назначения» для пула потоков Rust. В то время среда выполнения Tokio ещё находилась на ранней стадии разработки. Тогда модель предполагала, что задачи I/O будут выполняться в одном потоке с селектором ввода-вывода (epoll, kqueue, iocp...). Больше вычислительных задач можно было бы направить в пул потоков. В этом контексте предполагается гибкая настройка числа активных потоков, так что имеет больше смысла отключать бездействующие потоки. Однако в планировщике с захватом работы модель перешла на выполнение всех асинхронных задач, а в этом случае есть смысл всегда поддерживать небольшое количество потоков в активном состоянии.
Во-вторых, там была реализована двусторонняя очередь crossbeam. Эта реализация основана на двусторонней очереди Чейза — Лева, а она не подходит для планирования независимых асинхронных задач по причинам, описанным ниже.
В-третьих, реализация оказалась слишком сложной. Отчасти это связано с тем, что это был мой первый планировщик задач. Кроме того, я был слишком нетерпелив, применяя атомики в ветках, где просто отлично справился бы мьютекс. Важный урок заключается в том, что очень часто именно мьютексы подходят лучше всего.
Наконец, в первоначальной реализации было много мелких недостатков. В первые годы детали реализации асинхронной модели Rust значительно эволюционировали, но библиотеки всё время сохраняли стабильность API. Это привело к накоплению некоторого технического долга.
Сейчас Tokio приближается к первому крупному релизу — и мы можем оплатить весь этот долг, а также извлечь уроки из опыта, полученного за годы разработки. Это захватывающее время!
Планировщик Tokio нового поколения
Теперь пришло время подробнее разобрать, что изменилось в новом планировщике.
Новая система задач
Во-первых, важно выделить то, что не является частью Tokio, но имеет решающее значение в части повышения эффективности: это новая система задач в
std, изначально разработанная Тейлором Крамером. Эта система предоставляет хуки, которые должен реализовать планировщик для выполнения асинхронных задач Rust, и система действительно великолепно спроектирована и реализована. Она намного легче и гибче, чем предыдущая итерация.Структура
Waker из ресурсов сигнализирует о том, что есть выполнимая задача, которую следует поместить в очередь планировщика. В новой системе задач это структура в два указателя, тогда как раньше она была намного больше. Уменьшение размера важно для минимизации накладных расходов на копирование значения Waker в разных местах, и она занимает меньше места в структурах, что позволяет втиснуть в строку кэша больше важных данных. В дизайне vtable сделан ряд оптимизаций, которые мы рассмотрим позже.Выбор лучшего алгоритма очереди
Очередь выполнения находится в центре планировщика. Таким образом, это самый важный компонент для исправления. В оригинальном планировщике Tokio использовалась двусторонняя очередь crossbeam: реализация с одним источником (producer) и многими потребителями. Задача помещаются с одного конца, а значения извлекаются с другого. Большую часть времени поток «выталкивает» значения с конца очереди, но иногда другие потоки перехватывают работу, производя такую же операцию. Двусторонняя очередь поддерживается массивом и набором индексов, отслеживающих голову и хвост. Когда очередь полна, внедрение в неё приведёт к росту места для хранения. Выделяется новый, более крупный массив, а значения перемещаются в новое хранилище.
Способность расти достигается за счёт сложности и накладных расходов. Операции push/pop должны учитывать этот рост. Кроме того, освобождение исходного массива сопряжено с дополнительными трудностями. В языке со сборкой мусора (GC) старый массив выйдет из области видимости, и в конечном итоге GC его очистит. Однако Rust поставляется без GC. Это означает, что мы сами несём ответственность за освобождение массива, но потоки могут пытаться одновременно получить доступ к памяти. Для решения этой проблемы crossbeam использует стратегию утилизации по эпохам (epoch based reclamation strategy). Хотя она не требует много ресурсов, но добавляет нетривиальные накладные расходы в основной поток выполнения (hot path). Каждая операция теперь должна выполнять атомарные операции RMW (read-modify-write) на входе и выходе из критических секций для сигнализации другим потокам, что память используется и её нельзя очищать.
Из-за оверхеда на рост очереди выполнения есть смысл задуматься: действительно ли настолько необходима поддержка этого роста? Этот вопрос в конечном итоге и подтолкнул меня переписать планировщик. Новая стратегия заключается в фиксированном размере очереди для каждого процесса. Когда очередь заполнена, вместо увеличения локальной очереди задача перемещается в глобальную очередь с несколькими потребителями и несколькими производителями. Процессоры будут периодически проверять эту глобальную очередь, но с гораздо меньшей частотой, чем локальную.
В рамках одного из первых экспериментов мы заменили crossbeam на mpmc. Это не привело к значительному улучшению из-за количества синхронизации для push и pop. Ключевой момент в захвате работы заключается в том, что под нагрузкой почти нет конкуренции в очередях, поскольку каждый процессор обращается только к своей собственной очереди.
На этом этапе я решил внимательнее изучить исходники Go — и обнаружил, что там используется фиксированный размер очереди с одним производителем и несколькими потребителями, при этом с минимальной синхронизацией, что очень впечатляет. Для адаптации алгоритма к планировщику Tokio я сделал несколько изменений. Примечательно, что реализация Go использует последовательные атомарные операции (насколько я понял). Версия для Tokio также уменьшает число некоторых операций копирования в более редких ветках кода.
Реализация очереди представляет собой циклический буфер, который хранит значения в массиве. Голова и хвост очереди отслеживаются атомарными операциями с целочисленными значениями.
struct Queue { /// Concurrently updated by many threads. head: AtomicU32, /// Only updated by producer thread but read by many threads. tail: AtomicU32, /// Masks the head / tail position value to obtain the index in the buffer. mask: usize, /// Stores the tasks. buffer: Box<[MaybeUninit<Task>]>, }
Внедрение в очередь выполняется одним потоком:
loop { let head = self.head.load(Acquire); // safety: this is the **only** thread that updates this cell. let tail = self.tail.unsync_load(); if tail.wrapping_sub(head) < self.buffer.len() as u32 { // Map the position to a slot index. let idx = tail as usize & self.mask; // Don't drop the previous value in `buffer[idx]` because // it is uninitialized memory. self.buffer[idx].as_mut_ptr().write(task); // Make the task available self.tail.store(tail.wrapping_add(1), Release); return; } // The local buffer is full. Push a batch of work to the global // queue. match self.push_overflow(task, head, tail, global) { Ok(_) => return, // Lost the race, try again Err(v) => task = v, } }
Обратите внимание, что в этой функции
push единственными атомарными операциями являются загрузка с упорядочением Acquire и сохранение с упорядочением Release. Здесь нет операций RMW (compare_and_swap, fetch_and...) или последовательного порядка, как раньше. Это важно, потому что на чипах x86 все загрузки/сохранения уже являются «атомарными». Таким образом, на уровне CPU эта функция не будет синхронизироваться. Атомарные операции помешают определённым оптимизациям в компиляторе, но это всё. Скорее всего, первую операцию load можно было безопасно выполнить с упорядочением Relaxed, но замена не несёт какого-то заметного оверхеда.Когда очередь заполнена, вызывается
push_overflow. Эта функция перемещает половину задач из локальной в глобальную очередь. Глобальная очередь — это интрузивный список, защищённый мьютексом. При перемещении в глобальную очередь задачи сначала связываются вместе, затем создаётся мьютекс, и все задачи вставляются путём обновления указателя на хвост глобальной очереди. Это сохраняет небольшой размер критической секции.Если вы знакомы с деталями атомарных упорядочений памяти, то можете заметить потенциальную «проблему» с показанной выше функцией
push. Атомарная операция load с упорядочением Acquire довольно слабая. Она может возвращать устаревшие значения, т. е. параллельная операция захвата может уже увеличить значение self.head, но в кеше потока push останется старое значение, поэтому он не заметит операцию захвата. Это не проблема корректности алгоритма. В основном (быстром) пути push мы заботимся только о том, заполнена локальная очередь или нет. Поскольку пушить в очередь может только текущий поток, устаревшая операция load просто приведёт к тому, что очередь будет выглядеть более наполненной, чем на самом деле. Она может неправильно определить, что очередь заполнена, и вызвать push_overflow, но эта функция включает более сильную атомарную операцию. Если push_overflow определяет, что очередь на самом деле не заполнена, то возвращает w/Err, и операция push запускается снова. Это ещё одна причина, по которой push_overflow перемещает половину очереди выполнения в глобальную очередь. После этого перемещения гораздо реже происходят такие ложные срабатывания.Локальный
pop (от процессора, которому принадлежит очередь) тоже реализован просто:loop { let head = self.head.load(Acquire); // safety: this is the **only** thread that updates this cell. let tail = self.tail.unsync_load(); if head == tail { // queue is empty return None; } // Map the head position to a slot index. let idx = head as usize & self.mask; let task = self.buffer[idx].as_ptr().read(); // Attempt to claim the task read above. let actual = self .head .compare_and_swap(head, head.wrapping_add(1), Release); if actual == head { return Some(task.assume_init()); } }
В этой функции один атомарный
load и один compare_and_swap с Release. Основные накладные расходы идут от compare_and_swap.Функция
steal похожа на pop, но от self.tail должна передаваться атомарная нагрузка. Кроме того, подобно push_overflow, операция steal пытается претендовать на половину очереди вместо одной задачи. Это хорошо отражается на производительности, что мы рассмотрим позже.Последняя недостающая часть — разбор глобальной очереди, куда поступают задачи, переполняющие локальные очереди, а также для передачи задач планировщику из непроцессорных потоков. Если процессор под нагрузкой, то есть в локальной очереди есть задачи, то процессор попытается вытянуть задачи из глобальной очереди примерно после каждых 60-ти задач локальной очереди. Он также проверяет глобальную очередь, когда находится в состоянии «поиска», описанном ниже.
Оптимизация шаблонов передачи сообщений
Приложения на Tokio обычно состоят из множества небольших независимых задач. Они взаимодействуют друг с другом с помощью сообщений. Такой шаблон похож на другие языки, такие как Go и Erlang. Учитывая, насколько распространён шаблон, планировщику есть смысл его оптимизировать.
Предположим, даны задачи А и B. Задача А сейчас выполняется и отправляет сообщение задаче B по каналу передачи. Канал является ресурсом, на котором в настоящее время заблокирована задача B, поэтому действие отправки сообщения приведёт к переходу задачи B в исполняемое состояние — и она поместится в очередь выполнения текущего процессора. Затем процессор выведет из очереди выполнения следующую задачу, выполнит её и будет повторять этот цикл, пока не достигнет задачи B.
Проблема в том, что между отправкой сообщения и выполнением задачи B может возникнуть значительная задержка. Кроме того, «горячие» данные, такие как сообщение, хранятся в кеше CPU, но к моменту выполнения задачи высока вероятность, что соответствующие кеши будут очищены.
Чтобы решить эту проблему, новый планировщик Tokio реализует оптимизацию (как в планировщиках Go и Kotlin). Когда задача переходит в исполняемое состояние, она не помещается в конец очереди, а сохраняется в специальном слоте «следующая задача». Процессор всегда проверяет этот слот перед проверкой очереди. Если при вставке в слот там уже есть старая задача, она удаляется из слота и перемещается в конец очереди. Таким образом, задача передачи сообщения выполнится практически без задержек.
Захват дросселирования
В планировщике с захватом работы, если очередь выполнения процессора пуста, процессор пытается захватить задачи из одноранговых CPU. Для начала выбирается случайный одноранговый CPU, если у него задачи не найдены, производится поиск следующего и так далее, пока не будут найдены задачи.
На практике несколько процессоров зачастую заканчивают обработку очереди выполнения примерно в одно и то же время. Это происходит, когда поступает пакет работ (например, когда
epoll опрашивается на готовность сокета). Процессоры пробуждаются, получают задачи, запускают их и завершают. Это приводит к тому, что все процессоры пытаются одновременно захватить чужие задачи, то есть многие потоки пытаются получить доступ к одним и тем же очередям. Возникает конфликт. Случайный выбор начальной точки помогает уменьшить конкуренцию, но ситуация всё равно не очень хорошая.Чтобы обойти эту проблему, новый планировщик ограничивает число параллельных процессоров, выполняющих операции захвата. Мы называем состояние процессора, в котором он пытается захватить чужие задачи, «поиском работы», или «поиском» для краткости (об этом позже). Такая оптимизация выполняется с помощью атомарного значения
int, которое процессор увеличивает перед началом поиска и уменьшает при выходе из состояния поиска. Максимально в состоянии поиска может находиться половина от общего числа процессоров. То есть установлен примерный предел, и это нормально. Нам не нужен жёсткий лимит на количество CPU в поиске, просто дросселирование. Жертвуем точностью ради эффективности алгоритма.После перехода в состояние поиска процессор пытается захватить работу у одноранговых CPU и проверяет глобальную очередь.
Уменьшение синхронизации между потоками
Другая важная часть планировщика — уведомление одноранговых CPU о новых задачах. Если «брат» спит, он просыпается и захватывает задания. Уведомления играют ещё одну важную роль. Напомним, что алгоритм очереди использует слабое атомарное упорядочивание (
Acquire / Release). Из-за атомарного выделения памяти нет гарантии, что одноранговый процессор когда-либо увидит задачи в очереди без дополнительной синхронизации. Поэтому уведомления отвечают за неё тоже. По этой причине уведомления становятся дорогими. Цель в том, чтобы минимизировать их количество, чтобы не использовать ресурсы CPU, т. е. у процессора есть задачи, и «брат» не может их украсть. Чрезмерное количество уведомлений приводит к проблеме громового стада.Оригинальный планировщик Tokio использовал наивный подход к уведомлениям. Всякий раз, когда новая задача помещалась в очередь выполнения, процессор получал уведомление. Всякий раз, когда CPU был уведомлён и увидел задачу после пробуждения, то уведомлял ещё один CPU. Эта логика очень быстро привела к тому, что все процессоры просыпались и искали работу (вызывая конфликт). Зачастую большинство процессоров не находили работу и снова засыпали.
Новый планировщик значительно улучшил эту схему по образцу планировщика Go. Уведомления рассылаются как и раньше, но только в том случае, если нет CPU в состоянии поиска (см. предыдущий раздел). Когда процессор получает уведомление, он немедленно переходит в состояние поиска. Когда процессор в состоянии поиска находит новые задачи, то сначала уходит из состояния поиска, а затем уведомляет другой процессор.
Такая логика ограничивает скорость, с которой просыпаются процессоры. Если запланирован сразу целый пакет задач (например, когда
epoll опрашивается на готовность сокета), то первая задача приведёт к уведомлению процессора. Он теперь находится в состоянии поиска. Остальные запланированные задачи в пакете не будут уведомлять процессор, поскольку есть по крайней мере один CPU в состоянии поиска. Этот уведомленный процессор захватит половину задач в пакете и, в свою очередь, уведомит другой процессор. Проснётся третий процессор, найдёт задачи одного из первых двух процессоров и захватит половину из них. Это приводит к плавному наращиванию количества рабочих CPU, а также быстрой балансировке нагрузки.Сокращение выделений памяти
Новый планировщик Tokio требует только одного выделения памяти на каждую порождённую задачу, в то время как старый требовал двух. Ранее структура задачи выглядела примерно так:
struct Task { /// All state needed to manage the task state: TaskState, /// The logic to run is represented as a future trait object. future: Box<dyn Future<Output = ()>>, }
Структура
Task также будет выделена в Box. Я очень давно хотел исправить этот косяк (впервые попытался в 2014 году). Со времён старого планировщика Tokio изменились две вещи. Во-первых, стабилизировался std::alloc. Во-вторых, будущая система задач переключилась на явную стратегию vtable. Именно этих двух вещей не хватало, наконец, избавиться от неэффективного двойного выделения памяти на каждую задачу.Теперь структура
Task представлена в таком виде:struct Task<T> { header: Header, future: T, trailer: Trailer, }
Для задачи необходимы и
Header, и Trailer, но они разделены между «горячими» данными (голова) и «холодными» (хвост), т. е. примерно между данными, к которым часто обращаются, и теми, которые редко используются. «Горячие» данные помещаются во главе структуры и хранятся как можно меньше. Когда процессор разыменовывает указатель задачи, он сразу загружает строку кеша (от 64 до 128 байт). Мы хотим, чтобы эти данные были как можно более актуальными.Сокращение атомарного подсчёта ссылок
Последняя оптимизация, которую мы обсудим в этой статье, заключается в уменьшении количества атомарных ссылок. Есть много ссылок на структуру задачи, в том числе из планировщика и от каждого waker. Общая стратегия управления этой памятью — атомарный подсчёт ссылок. Эта стратегия требует атомарной операции при каждом клонировании ссылки и при каждом удалении ссылки. Когда последняя ссылка выходит за пределы области, память освобождается.
В старом планировщике Tokio и планировщик, и все waker'ы содержали ссылку на дескриптор задачи, примерно:
struct Waker { task: Arc<Task>, } impl Waker { fn wake(&self) { let task = self.task.clone(); task.scheduler.schedule(task); } }
Когда пробуждается задача, ссылка клонируется (происходит атомарное приращение). Затем ссылка помещается в очередь выполнения. Когда процессор получает задачу и завершает её выполнение, то отбрасывает ссылку, что приводит к атомарному уменьшению. Эти атомарные операции (приращение и уменьшение) складываются.
Данную проблему ранее выявили разработчики системы задач
std::future. Они заметили, что при вызове Waker::wake исходная ссылка на waker зачастую больше не нужна. Это позволяет повторно использовать счётчик атомарных ссылок при перемещении задачи в очередь выполнения. Система задач std::future теперь включает два вызова API для «пробуждения»:wake, который принимаетself
wake_by_ref, который принимает&self
Такая конструкция API заставляет использовать при вызове
wake, избегая атомного приращения. Реализация становится такой:impl Waker { fn wake(self) { task.scheduler.schedule(self.task); } fn wake_by_ref(&self) { let task = self.task.clone(); task.scheduler.schedule(task); } }
Это позволяет избежать накладных расходов на дополнительный подсчёт ссылок только в том случае, если можно взять на себя ответственность за пробуждение. По моему опыту, вместо этого почти всегда желательно просыпаться с
&self. Пробуждение self предотвращает повторное использование waker (полезно в случаях, когда ресурс отправляет много значений, т. е. каналы, сокеты,...). Также в случае self сложнее реализовать потокобезопасное пробуждение (подробности оставим для другой статьи).Новый планировщик решает проблему «пробуждения через
self», избегая атомарного приращения в wake_by_ref, что делает его столь же эффективным, как и wake(self). Для этого планировщик поддерживает список всех задач, которые в настоящее время активны (ещё не завершены). Список представляет счётчик ссылок, необходимый для отправки задачи в очередь выполнения.Сложность такой оптимизации заключается в том, что планировщик не будет удалять задачи из своего списка до тех пор, пока не получит гарантии, что задача снова будет помещена в очередь выполнения. Детали реализации этой схемы выходят за рамки этой статьи, но настоятельно рекомендую вам посмотреть исходники.
Смелый (небезопасный) параллелизм с Loom
Очень сложно писать правильный, параллельный код без блокировок. Лучше работать медленно, но правильно, чем быстро, но с глюками, особенно если баги относятся к безопасности памяти. Лучший вариант, однако, должен работать быстро и без ошибок. В новом планировщике сделаны некоторые довольно агрессивные оптимизации и он избегает большинства типов
std ради специализации. В общем, в нём довольно много небезопасного кода unsafe.Существует несколько способов тестирования параллельного кода. Один из них — чтобы пользователи вместо вас выполняли тестирование и отладку (привлекательный вариант, это точно). Другой — написать модульные тесты, которые запускаются в цикле и могут выловить ошибку. Может, даже использовать TSAN. Конечно, если он найдёт ошибку, её невозможно легко воспроизвести без повторного запуска цикла тестов. Кроме того, сколько времени занимает этот цикл? Десять секунд? Десять минут? Десять дней? Раньше так приходилось тестировать параллельный код в Rust.
Мы посчитали неприемлемым такое положение вещей. Когда мы выпускаем код, то хотим чувствовать уверенность (насколько это возможно), особенно в случае параллельного кода без блокировок. Пользователям Tokio нужна надёжность.
Поэтому мы разработали Loom: инструмент пермутационного тестирования параллельного кода. Тесты пишутся как обычно, но
loom будет многократно их запускать, переставляя все возможные варианты выполнения и поведения, с которыми тест может столкнуться в потоковой среде. Он также проверяет правильный доступ к памяти, освобождение памяти и т. д.В качестве примера, вот тест loom для нового планировщика:
#[test] fn multi_spawn() { loom::model(|| { let pool = ThreadPool::new(); let c1 = Arc::new(AtomicUsize::new(0)); let (tx, rx) = oneshot::channel(); let tx1 = Arc::new(Mutex::new(Some(tx))); // Spawn a task let c2 = c1.clone(); let tx2 = tx1.clone(); pool.spawn(async move { spawn(async move { if 1 == c1.fetch_add(1, Relaxed) { tx1.lock().unwrap().take().unwrap().send(()); } }); }); // Spawn a second task pool.spawn(async move { spawn(async move { if 1 == c2.fetch_add(1, Relaxed) { tx2.lock().unwrap().take().unwrap().send(()); } }); }); rx.recv(); }); }
Выглядит достаточно нормально, но фрагмент кода в блоке
loom::model запускается много тысяч раз (возможно, миллионы), каждый раз с небольшим изменением поведения. При каждом запуске меняется точный порядок потоков. Кроме того, для каждой атомарной операции loom пробует все различные варианты поведения, разрешённые в модели памяти C++11. Вспомните, что атомарная нагрузка с Acquire была довольно слабой и могла возвращать устаревшие значения. Тест loom будет пробовать все возможные значения, которое могут быть загружены.loom стал бесценным инструментом в разработке нового планировщика. Он поймал более десяти багов, которые прошли все модульные тесты, ручную проверку и нагрузочное тестирование.Проницательный читатель может усомниться, что loom проверяет «все возможные пермутации», и будет прав. Наивные пермутации приведут к комбинаторному взрыву. Любой нетривиальный тест никогда не завершится. Эту проблему изучали в течение многих лет, и разработан ряд алгоритмов для предотвращения комбинаторного взрыва. Основной алгоритм Loom основан на динамической редукции с частичным упорядочением (dynamic partial-order reduction). Этот алгоритм устраняет пермутации, приводящие к одинаковому результату. Но пространство состояний всё равно может вырасти до такого размера, что не будет обработано за разумное время (несколько минут). Loom позволяет дополнительно его ограничивать с помощью динамической редукции с частичным упорядочением.
В целом, благодаря обширному тестированию с помощью Loom я теперь гораздо более уверен в корректности планировщика.
Результаты
Итак, мы рассмотрели, что такое планировщики и как новый планировщик Tokio добился огромного прироста производительности… но какого именно прироста? Учитывая, что новый планировщик только разработан, в реальном мире его ещё не проверили по полной программе. Вот то, что мы знаем.
Во-первых, новый планировщик намного быстрее в микро-бенчмарках:
Старый планировщик
test chained_spawn ... bench: 2,019,796 ns/iter (+/- 302,168) test ping_pong ... bench: 1,279,948 ns/iter (+/- 154,365) test spawn_many ... bench: 10,283,608 ns/iter (+/- 1,284,275) test yield_many ... bench: 21,450,748 ns/iter (+/- 1,201,337)
Новый планировщик
test chained_spawn ... bench: 168,854 ns/iter (+/- 8,339) test ping_pong ... bench: 562,659 ns/iter (+/- 34,410) test spawn_many ... bench: 7,320,737 ns/iter (+/- 264,620) test yield_many ... bench: 14,638,563 ns/iter (+/- 1,573,678)
В этот бенчмарк входит следующее:
chained_spawnрекурсивно спаунит новые задачи, т. е. порождает задачу, которая порождает другую задачу, которая тоже порождает задачу и т. д.
ping_pongвыделяет каналoneshotи порождает задачу, которая отправляет сообщение на этом канале. Исходная задача ожидает получения сообщения. Это самый близкий к «реальному миру» тест.
spawn_manyпроверяет внедрение задач в планировщик, т. е. порождает задачи из-за пределов его контекста.
yield_manyпроверяет самостоятельное пробуждение задачи.
Разница в бенчмарках очень впечатляет. Но как это отразится в «реальном мире»? Трудно сказать точно, но я попытался запустить бенчмарки Hyper.
Вот простейший сервер Hyper, производительность которого замеряется с помощью
wrk -t1 -c50 -d10:Старый планировщик
Running 10s test @ http://127.0.0.1:3000
1 threads and 50 connections
Thread Stats Avg Stdev Max +/- Stdev
Latency 371.53us 99.05us 1.97ms 60.53%
Req/Sec 114.61k 8.45k 133.85k 67.00%
1139307 requests in 10.00s, 95.61MB read
Requests/sec: 113923.19
Transfer/sec: 9.56MBНовый планировщик
Running 10s test @ http://127.0.0.1:3000
1 threads and 50 connections
Thread Stats Avg Stdev Max +/- Stdev
Latency 275.05us 69.81us 1.09ms 73.57%
Req/Sec 153.17k 10.68k 171.51k 71.00%
1522671 requests in 10.00s, 127.79MB read
Requests/sec: 152258.70
Transfer/sec: 12.78MBМы видим рост на 34% запросов в секунду просто после смены планировщика! Впервые увидев это, я очень обрадовался, поскольку ожидал увеличения максимум на 5-10%. Но потом мне стало грустно, ведь этот результат также показывал, что старый планировщик Tokio не так хорош. Затем я вспомнил, что Hyper и так лидирует в рейтингах TechEmpower. Интересно посмотреть, как новый планировщик повлияет на рейтинги.
Tonic, клиент и сервер gRPC, с новым планировщиком ускорился примерно на 10%, что довольно впечатляет, учитывая, что Tonic ещё не полностью оптимизирован.
Заключение
Я действительно очень рад, наконец, завершить этот проект после нескольких месяцев работы. Это серьёзное улучшение асинхронного ввода-вывода Rust. Я очень доволен сделанными улучшениями. В коде Tokio ещё много возможностей для оптимизации, так что мы ещё не закончили с повышением производительности.
Надеюсь, что материал в статье будет полезен для коллег, которые попытаются написать свой планировщик задач.

