
Вот уже несколько лет, как почти каждая статья о передовых подходах к кэшированию рекомендует пользоваться в продакшне следующими методиками:

Все известные мне средства для сборки проектов поддерживают добавление к именам файлов хэша их содержимого. Делается это с помощью простого конфигурационного правила (наподобие того, что показано ниже):
Столь широкая поддержка этой технологии привела к тому, что подобная практика стала чрезвычайно распространённой.
Эксперты в сфере производительности веб-проектов, кроме того, рекомендуют пользоваться методиками разделения кода. Эти методики позволяют разбивать JavaScript-код на отдельные бандлы. Такие бандлы могут быть загружены браузером параллельно, или даже лишь тогда, когда в них возникнет необходимость, по запросу браузера.
Одним из многих преимуществ разделения кода, в частности, имеющих отношение к передовым методикам кэширования, называют то, что изменения, внесённые в отдельный файл с исходным кодом, не приводят к инвалидации кэша всего бандла. Другими словами, если для npm-пакета, созданного разработчиком «X», вышло обновление безопасности, и при этом содержимое
Проблема тут заключается в том, что если всё это скомбинировать, то подобное редко приводит к повышению эффективности долговременного кэширования данных.
На практике изменения одного из файлов исходного кода почти всегда приводят к инвалидации более чем одного выходного файла системы сборки пакетов. И это происходит именно из-за того, что к именам файлов были добавлены хэши, отражающие версии содержимого этих файлов.
Представьте, что вы создали и развернули веб-сайт. Вы воспользовались разделением кода, в результате большая часть JavaScript-кода вашего сайта загружается по запросу.
На следующей диаграмме зависимостей можно видеть точку входа кодовой базы — корневой фрагмент
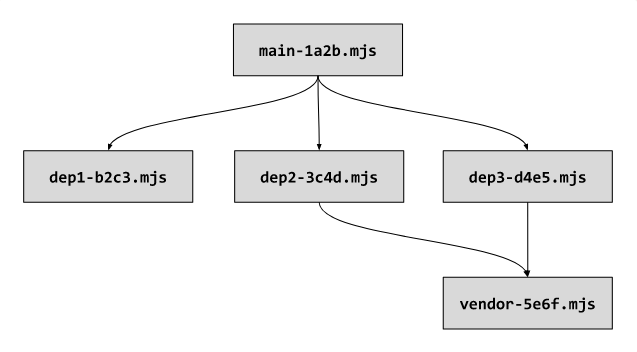
Типичное дерево зависимостей JavaScript-модуля
Так как фрагменты
Теперь подумаем о том, что произойдёт, если изменится содержимое фрагмента
Если это произойдёт, то хэш в имени соответствующего файла тоже изменится. А так как ссылка на имя этого файла имеется в командах импорта фрагментов
Однако так как эти команды импорта являются частью содержимого фрагментов
Но на этом всё не заканчивается. Так как фрагмент
И наконец, так как содержимое файла
Вот как теперь будет выглядеть диаграмма зависимостей.
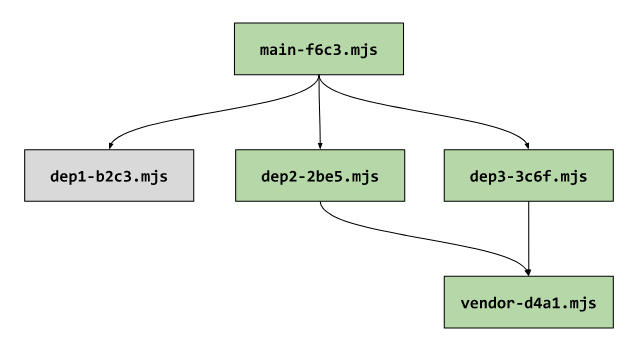
Модули в дереве зависимостей, на которые повлияло единственное изменение в коде одного из листовых узлов дерева
Из этого примера видно, как небольшое изменение кода, сделанное всего лишь в одном файле, привело к инвалидации кэша 80% фрагментов бандла.
Хотя и правда то, что не все изменения приводят к столь печальным последствиям (например, инвалидация кэша листового узла приводит к инвалидации кэша всех узлов вплоть до корневого, но инвалидация кэша корневого узла не вызывает каскадной инвалидации, доходящей до листовых улов), в идеальном мире нам не приходилось бы сталкиваться с любыми ненужными инвалидациями кэша.
Это приводит нас к следующему вопросу: «Можно ли получить преимущества, даваемые иммутабельными ресурсами и долговременным кэшированием, и при этом не страдать от каскадных инвалидаций кэша?».
Проблема, касающаяся хэшей содержимого файлов, находящихся в именах файлов, с технической точки зрения, заключается не в том, что хэши находятся в именах. Она заключается в том, что эти хэши появляются и внутри других файлов. В результате кэш этих файлов инвалидируется при изменении хэшей в именах файлов, от которых они зависят.
Решение этой проблемы заключается в том, чтобы, говоря языком вышеприведённого примера, сделать возможным импорт фрагмента
Как оказалось, существует несколько способов достижения этой цели:
Рассмотрим эти механизмы.
Карты импорта — это простейшее решение проблемы каскадной инвалидации кэшей. Кроме того, этот механизм легче всего реализовать. Но он, к сожалению, поддерживается лишь в Chrome (эту возможность, к тому же, нужно явным образом включать).
Несмотря на это я хочу начать именно с рассказа о картах импорта, так как уверен в том, что это решение станет в будущем наиболее распространённым. Кроме того, описание работы с картами импорта поможет объяснить и особенности других подходов к решению нашей проблемы.
Использование карт импорта для предотвращения каскадной инвалидации кэша состоит из трёх шагов.
Нужно настроить бандлер так, чтобы он, при сборке проекта, не включал бы хэши содержимого файлов в их имена.
Если собрать проект, модули которого показаны на диаграмме из предыдущего примера, не включая в имена файлов хэши их содержимого, то файлы в выходной директории проекта будут выглядеть так:
Команды импорта в соответствующих модулях тоже не будут включать в себя хэши:
Нужно воспользоваться инструментом, наподобие rev-hash, и сгенерировать с его помощью копию каждого файла, к имени которого добавлен хэш, указывающий на версию его содержимого.
После того, как эта часть работы выполнена, содержимое выходной директории должно будет выглядеть примерно так, как показано ниже (обратите внимание на то, что там теперь присутствует по два варианта каждого файла):
Нужно создать JSON-объект, хранящий сведения о соответствии каждого файла, в имени которого нет хэша, каждому файлу, в имени которого хэш есть. Этот объект нужно добавить в HTML-шаблоны.
Этот JSON-объект и является картой импорта. Вот как он может выглядеть:
После этого всякий раз, когда браузер увидит команду импорта файла, находящегося по адресу, соответствующему одному из ключей карты импорта, браузер импортирует тот файл, который соответствует значению ключа.
Если воспользоваться этой картой импорта как примером, то можно выяснить, что команда импорта, ссылающаяся на файл
Это означает, что исходный код модулей может совершенно спокойно ссылаться на имена файлов модулей, не содержащих хэшей, а браузер всегда будет загружать файлы, имена которых содержат сведения о версиях их содержимого. А, так как хэшей нет в исходном коде модулей (они присутствуют лишь в карте импорта), то изменения этих хэшей не приведут к инвалидации модулей, отличных от тех, содержимое которых действительно изменилось.
Возможно, вы сейчас задаётесь вопросом о том, почему я создал копию каждого файла вместо того, чтобы просто файлы переименовать. Это нужно для поддержки браузеров, которые не могут работать с картами импорта. В предыдущем примере подобные браузеры увидят лишь файл
Если вы хотите увидеть карты импорта в действии, то вот — набор примеров, демонстрирующих все способы решения проблемы каскадной инвалидации кэша, показанные в этом материале. Кроме того, взгляните на конфигурацию сборки проекта, на тот случай, если вам интересно узнать о том, как я генерировал карту импорта и хэши версий для каждого файла.
Продолжение следует…
Уважаемые читатели! Знакома ли вам проблема каскадной инвалидации кэша?


- Добавление в имена файлов информации о версии содержащихся в них данных (обычно — в виде хэша данных, находящихся в файлах).
- Установка HTTP-заголовков
Cache-Control: max-ageиExpires, управляющих временем кэширования материалов (что позволяет исключить повторную валидацию соответствующих материалов для посетителей, возвращающихся на ресурс).
Все известные мне средства для сборки проектов поддерживают добавление к именам файлов хэша их содержимого. Делается это с помощью простого конфигурационного правила (наподобие того, что показано ниже):
filename: '[name]-[contenthash].js'
Столь широкая поддержка этой технологии привела к тому, что подобная практика стала чрезвычайно распространённой.
Эксперты в сфере производительности веб-проектов, кроме того, рекомендуют пользоваться методиками разделения кода. Эти методики позволяют разбивать JavaScript-код на отдельные бандлы. Такие бандлы могут быть загружены браузером параллельно, или даже лишь тогда, когда в них возникнет необходимость, по запросу браузера.
Одним из многих преимуществ разделения кода, в частности, имеющих отношение к передовым методикам кэширования, называют то, что изменения, внесённые в отдельный файл с исходным кодом, не приводят к инвалидации кэша всего бандла. Другими словами, если для npm-пакета, созданного разработчиком «X», вышло обновление безопасности, и при этом содержимое
node_modules разбито на фрагменты по разработчикам, то изменить придётся только фрагмент, содержащий пакеты, созданные «X».Проблема тут заключается в том, что если всё это скомбинировать, то подобное редко приводит к повышению эффективности долговременного кэширования данных.
На практике изменения одного из файлов исходного кода почти всегда приводят к инвалидации более чем одного выходного файла системы сборки пакетов. И это происходит именно из-за того, что к именам файлов были добавлены хэши, отражающие версии содержимого этих файлов.
Проблема, касающаяся версионирования имён файлов
Представьте, что вы создали и развернули веб-сайт. Вы воспользовались разделением кода, в результате большая часть JavaScript-кода вашего сайта загружается по запросу.
На следующей диаграмме зависимостей можно видеть точку входа кодовой базы — корневой фрагмент
main, а также — три фрагмента-зависимости, загружаемых асинхронно — dep1, dep2 и dep3. Есть здесь и фрагмент vendor, содержащий все зависимости сайта из node_modules. Все имена файлов, в соответствии с рекомендациями по кэшированию, включают в себя хэши содержимого этих файлов.Типичное дерево зависимостей JavaScript-модуля
Так как фрагменты
dep2 и dep3 импортируют модули из фрагмента vendor, то в верхней части их кода, сгенерированного сборщиком проекта, мы, скорее всего, обнаружим команды импорта, выглядящие примерно так:import {...} from '/vendor-5e6f.mjs';
Теперь подумаем о том, что произойдёт, если изменится содержимое фрагмента
vendor.Если это произойдёт, то хэш в имени соответствующего файла тоже изменится. А так как ссылка на имя этого файла имеется в командах импорта фрагментов
dep2 и dep3, тогда нужно будет, чтобы изменились и эти команды импорта:-import {...} from '/vendor-5e6f.mjs'; +import {...} from '/vendor-d4a1.mjs';
Однако так как эти команды импорта являются частью содержимого фрагментов
dep2 и dep3, то их изменение означает, что изменится и хэш содержимого файлов dep2 и dep3. А значит — и имена этих файлов тоже изменятся.Но на этом всё не заканчивается. Так как фрагмент
main импортирует фрагменты dep2 и dep3, а имена их файлов изменились, команды импорта в main тоже поменяются:-import {...} from '/dep2-3c4d.mjs'; +import {...} from '/dep2-2be5.mjs'; -import {...} from '/dep3-d4e5.mjs'; +import {...} from '/dep3-3c6f.mjs';
И наконец, так как содержимое файла
main изменилось, имя этого файла тоже должно будет измениться.Вот как теперь будет выглядеть диаграмма зависимостей.
Модули в дереве зависимостей, на которые повлияло единственное изменение в коде одного из листовых узлов дерева
Из этого примера видно, как небольшое изменение кода, сделанное всего лишь в одном файле, привело к инвалидации кэша 80% фрагментов бандла.
Хотя и правда то, что не все изменения приводят к столь печальным последствиям (например, инвалидация кэша листового узла приводит к инвалидации кэша всех узлов вплоть до корневого, но инвалидация кэша корневого узла не вызывает каскадной инвалидации, доходящей до листовых улов), в идеальном мире нам не приходилось бы сталкиваться с любыми ненужными инвалидациями кэша.
Это приводит нас к следующему вопросу: «Можно ли получить преимущества, даваемые иммутабельными ресурсами и долговременным кэшированием, и при этом не страдать от каскадных инвалидаций кэша?».
Подходы к решению проблемы
Проблема, касающаяся хэшей содержимого файлов, находящихся в именах файлов, с технической точки зрения, заключается не в том, что хэши находятся в именах. Она заключается в том, что эти хэши появляются и внутри других файлов. В результате кэш этих файлов инвалидируется при изменении хэшей в именах файлов, от которых они зависят.
Решение этой проблемы заключается в том, чтобы, говоря языком вышеприведённого примера, сделать возможным импорт фрагмента
vendor фрагментами dep2 и dep3 без указания информации о версии файла фрагмента vendor. При этом нужно гарантировать, чтобы загруженная версия vendor была бы правильной, принимая во внимание текущие версии dep2 и dep3.Как оказалось, существует несколько способов достижения этой цели:
- Карты импорта.
- Сервис-воркеры.
- Собственные скрипты для загрузки ресурсов.
Рассмотрим эти механизмы.
Подход №1: карты импорта
Карты импорта — это простейшее решение проблемы каскадной инвалидации кэшей. Кроме того, этот механизм легче всего реализовать. Но он, к сожалению, поддерживается лишь в Chrome (эту возможность, к тому же, нужно явным образом включать).
Несмотря на это я хочу начать именно с рассказа о картах импорта, так как уверен в том, что это решение станет в будущем наиболее распространённым. Кроме того, описание работы с картами импорта поможет объяснить и особенности других подходов к решению нашей проблемы.
Использование карт импорта для предотвращения каскадной инвалидации кэша состоит из трёх шагов.
▍Шаг 1
Нужно настроить бандлер так, чтобы он, при сборке проекта, не включал бы хэши содержимого файлов в их имена.
Если собрать проект, модули которого показаны на диаграмме из предыдущего примера, не включая в имена файлов хэши их содержимого, то файлы в выходной директории проекта будут выглядеть так:
dep1.mjs dep2.mjs dep3.mjs main.mjs vendor.mjs
Команды импорта в соответствующих модулях тоже не будут включать в себя хэши:
import {...} from '/vendor.mjs';
▍Шаг 2
Нужно воспользоваться инструментом, наподобие rev-hash, и сгенерировать с его помощью копию каждого файла, к имени которого добавлен хэш, указывающий на версию его содержимого.
После того, как эта часть работы выполнена, содержимое выходной директории должно будет выглядеть примерно так, как показано ниже (обратите внимание на то, что там теперь присутствует по два варианта каждого файла):
dep1-b2c3.mjs", dep1.mjs dep2-3c4d.mjs", dep2.mjs dep3-d4e5.mjs", dep3.mjs main-1a2b.mjs", main.mjs vendor-5e6f.mjs", vendor.mjs
▍Шаг 3
Нужно создать JSON-объект, хранящий сведения о соответствии каждого файла, в имени которого нет хэша, каждому файлу, в имени которого хэш есть. Этот объект нужно добавить в HTML-шаблоны.
Этот JSON-объект и является картой импорта. Вот как он может выглядеть:
<script type="importmap"> { "imports": { "/main.mjs": "/main-1a2b.mjs", "/dep1.mjs": "/dep1-b2c3.mjs", "/dep2.mjs": "/dep2-3c4d.mjs", "/dep3.mjs": "/dep3-d4e5.mjs", "/vendor.mjs": "/vendor-5e6f.mjs", } } </script>
После этого всякий раз, когда браузер увидит команду импорта файла, находящегося по адресу, соответствующему одному из ключей карты импорта, браузер импортирует тот файл, который соответствует значению ключа.
Если воспользоваться этой картой импорта как примером, то можно выяснить, что команда импорта, ссылающаяся на файл
/vendor.mjs, на самом деле выполнит запрос и загрузку файла /vendor-5e6f.mjs:// Команда ссылается на `/vendor.mjs`, но загружает`/vendor-5e6f.mjs`. import {...} from '/vendor.mjs';
Это означает, что исходный код модулей может совершенно спокойно ссылаться на имена файлов модулей, не содержащих хэшей, а браузер всегда будет загружать файлы, имена которых содержат сведения о версиях их содержимого. А, так как хэшей нет в исходном коде модулей (они присутствуют лишь в карте импорта), то изменения этих хэшей не приведут к инвалидации модулей, отличных от тех, содержимое которых действительно изменилось.
Возможно, вы сейчас задаётесь вопросом о том, почему я создал копию каждого файла вместо того, чтобы просто файлы переименовать. Это нужно для поддержки браузеров, которые не могут работать с картами импорта. В предыдущем примере подобные браузеры увидят лишь файл
/vendor.mjs и просто загрузят этот файл, поступив так, как обычно поступают, встречая подобные конструкции. В результате и оказывается, что на сервере должны существовать оба файла.Если вы хотите увидеть карты импорта в действии, то вот — набор примеров, демонстрирующих все способы решения проблемы каскадной инвалидации кэша, показанные в этом материале. Кроме того, взгляните на конфигурацию сборки проекта, на тот случай, если вам интересно узнать о том, как я генерировал карту импорта и хэши версий для каждого файла.
Продолжение следует…
Уважаемые читатели! Знакома ли вам проблема каскадной инвалидации кэша?
