В предыдущей статье мы обсудили основы устройства рекомендательных систем и кейсы использования. Узнали, что основной принцип заключается в рекомендации товаров, понравившихся людям с похожим вкусом, и применении алгоритма коллаборативной фильтрации.
В данной статье, будут рассмотрены лайфхаки рекомендательных систем на основе реальных бизнес кейсов. Будет показано, какие метрики лучше использовать, и какую степень близости выбрать для предсказания.

В машинном обучении используется различные метрики для оценки работы алгоритмов. Но в бизнесе, основная метрика одна – сколько денег принесет внедрение решения. Исходя из этого, в наших кейсах, которые реализует команда Data4, мы стараемся увеличить общую выручку на пользователя.
Для максимизации выручки, полезно знать, какие товары пользователь купил. Но к сожалению, если построить матрицу товарных предпочтений только на данных о покупках, наша матрица получится разреженной, и качество пострадает.
Давайте использовать в матрице товарных предпочтений не только покупки, но и промежуточные действия: клик на карточку, добавление в корзину, оформление заказа.
Каждому действию присвоим весовой коэффициент, и наша матрица получится более «плотной».
Но не все товары одинаково конверсионные. После открытия карточки человек может не продолжить покупку из-за «внутренних» свойств товара. Пример: элементы роскоши часто просматривают, но мало покупают.
Давайте построим распределения по товарам для каждого этапа воронки, и уберем из рекомендаций по 5-10% самых низкоконверсионных товаров на каждом этапе. Главное, не «выплеснуть с водой ребенка». Оставшиеся товары будут обладать «внутренними» свойствами, не препятствующими совершению покупки. Пример внутреннего свойства – размеры одежды в наличии. Если товар хороший, но только одного размера, конверсия будет низкая.
С товарами разобрались, теперь давайте посмотрим на то, как измерять «похожесть» пользователя.
Существует много метрик схожести, начиная с косинусной близости, наименьших квадратов, и заканчивая экзотическими вариантами.
Исходя из опыта Data4 построения рекомендательных систем для интернет магазинов, работа идет с разряженными матрицами. Для таких матриц наилучшим является использовать коэффициент близости – Жаккара. Это дает прирост метрик больше, чем смена алгоритмов.
Прежде чем использовать нейросети, попробуйте SVD и факторизационные машины. Это работает.
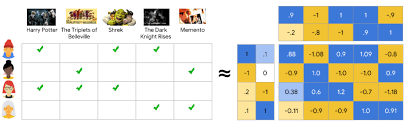
Рис.1 Принцип работы факторизационных машин
Распознавать похожие товары по изображению весело, но качество с использованием SVD на основе поведения — лучше.
Новым пользователям рекомендовать популярные товары (так преодолевается проблема холодного старта), а постоянным — из длинного хвоста распределения популярности товаров. Рекомендации хорошо работают, когда рекомендуют низкочастотные товары подходящие пользователю. Нет смысла рекомендовать фильм Титаник, если пользователь хотел его посмотреть, он его уже посмотрел. А вот малоизвестный фильм или товар может приятно удивить пользователя.

Вносите разнообразие в рекомендации, никто не хочет открыв страницу, увидеть 10 одинаковых шуб, или только фильмы одного режиссера. Разнообразие контента повышает вероятность покупки.

Выберите метрику, которую понимаете, как она работает. Пусть простая RMSE, но надежный результат, чем nDCG@K(эта метрика подходит), и случайный результат.
Люди могут обидеться на рекомендации, так, не следует рекомендовать женщинам большие размеры одежды, если вы не знаете их размер.
Только проведение A/B теста на пользователях, подскажет вам, как работает решение. Метрики качества – промежуточный результат, A/B тест – подтверждение, которое может вас разочаровать, но чаще радует.
Используя описанные приемы, наша команда Data4, осуществила несколько кейсов внедрения рекомендательных систем.
В статье мы поговорили, что для улучшения качества рекомендательной системы можно 1) учитывать промежуточные действия пользователей 2) Исключить низкоконверсионные товары 3) Использовать коэффициент Жаккара для разреженных матриц 4) Использовать SVD и факторизационные машины, если вы не Google 5) Осторожно подходить к поиску близости по изображению, если бюджет ограничен 6) Рекомендовать неочевидные товары старым пользователям из хвоста распределения популярности 7) Рекомендовать разнообразные товары 8) Использовать правильные метрики качества 9) Не обижать людей рекомендациями 10) Использовать A/B тест для проверки результата.
В данной статье, будут рассмотрены лайфхаки рекомендательных систем на основе реальных бизнес кейсов. Будет показано, какие метрики лучше использовать, и какую степень близости выбрать для предсказания.
В машинном обучении используется различные метрики для оценки работы алгоритмов. Но в бизнесе, основная метрика одна – сколько денег принесет внедрение решения. Исходя из этого, в наших кейсах, которые реализует команда Data4, мы стараемся увеличить общую выручку на пользователя.
Для максимизации выручки, полезно знать, какие товары пользователь купил. Но к сожалению, если построить матрицу товарных предпочтений только на данных о покупках, наша матрица получится разреженной, и качество пострадает.
Лайфхак №1
Давайте использовать в матрице товарных предпочтений не только покупки, но и промежуточные действия: клик на карточку, добавление в корзину, оформление заказа.
Каждому действию присвоим весовой коэффициент, и наша матрица получится более «плотной».
Но не все товары одинаково конверсионные. После открытия карточки человек может не продолжить покупку из-за «внутренних» свойств товара. Пример: элементы роскоши часто просматривают, но мало покупают.
Лайфхак №2
Давайте построим распределения по товарам для каждого этапа воронки, и уберем из рекомендаций по 5-10% самых низкоконверсионных товаров на каждом этапе. Главное, не «выплеснуть с водой ребенка». Оставшиеся товары будут обладать «внутренними» свойствами, не препятствующими совершению покупки. Пример внутреннего свойства – размеры одежды в наличии. Если товар хороший, но только одного размера, конверсия будет низкая.
С товарами разобрались, теперь давайте посмотрим на то, как измерять «похожесть» пользователя.
Существует много метрик схожести, начиная с косинусной близости, наименьших квадратов, и заканчивая экзотическими вариантами.
Лайфхак №3
Исходя из опыта Data4 построения рекомендательных систем для интернет магазинов, работа идет с разряженными матрицами. Для таких матриц наилучшим является использовать коэффициент близости – Жаккара. Это дает прирост метрик больше, чем смена алгоритмов.
Лайфхак №4
Прежде чем использовать нейросети, попробуйте SVD и факторизационные машины. Это работает.
Рис.1 Принцип работы факторизационных машин
Лайфхак №5
Распознавать похожие товары по изображению весело, но качество с использованием SVD на основе поведения — лучше.
Лайфхак №6
Новым пользователям рекомендовать популярные товары (так преодолевается проблема холодного старта), а постоянным — из длинного хвоста распределения популярности товаров. Рекомендации хорошо работают, когда рекомендуют низкочастотные товары подходящие пользователю. Нет смысла рекомендовать фильм Титаник, если пользователь хотел его посмотреть, он его уже посмотрел. А вот малоизвестный фильм или товар может приятно удивить пользователя.
Лайфхак №7
Вносите разнообразие в рекомендации, никто не хочет открыв страницу, увидеть 10 одинаковых шуб, или только фильмы одного режиссера. Разнообразие контента повышает вероятность покупки.
Лайфхак №8
Выберите метрику, которую понимаете, как она работает. Пусть простая RMSE, но надежный результат, чем nDCG@K(эта метрика подходит), и случайный результат.
Лайфхак №9
Люди могут обидеться на рекомендации, так, не следует рекомендовать женщинам большие размеры одежды, если вы не знаете их размер.
Лайфхак №10
Только проведение A/B теста на пользователях, подскажет вам, как работает решение. Метрики качества – промежуточный результат, A/B тест – подтверждение, которое может вас разочаровать, но чаще радует.
Используя описанные приемы, наша команда Data4, осуществила несколько кейсов внедрения рекомендательных систем.
В статье мы поговорили, что для улучшения качества рекомендательной системы можно 1) учитывать промежуточные действия пользователей 2) Исключить низкоконверсионные товары 3) Использовать коэффициент Жаккара для разреженных матриц 4) Использовать SVD и факторизационные машины, если вы не Google 5) Осторожно подходить к поиску близости по изображению, если бюджет ограничен 6) Рекомендовать неочевидные товары старым пользователям из хвоста распределения популярности 7) Рекомендовать разнообразные товары 8) Использовать правильные метрики качества 9) Не обижать людей рекомендациями 10) Использовать A/B тест для проверки результата.

