Абсолютной надежности приложения или сервиса нельзя достичь. Пользователи этого не заметят из-за сбоев посредников — сотовых сетей или провайдеров, но при этом останутся без новых функций, потому что все разработчики будут заняты поддержанием стабильности. Но можно достичь того уровня надежности, которого будет достаточно, чтобы были довольны клиенты, бизнес и инженеры с разработчиками. В этом помогает концепция Site Reliability Engineering, которую ввел Google в 2003 году. Основная ее задача — предотвратить «футбол» с багами между разработкой и эксплуатацией.

Концепция SRE содержит много «странных вещей». В SRE разработчики не только пишут код, но и следят за тем, как он работает в продакшне. Доступность и надежность приложений и сайтов начинается с измерения доступности в виде четких показателей и установки показателей надежности. Еще в SRE есть «право на ошибку» или Error Budget. Когда это «право» исчерпано, команда занимается повышением надежности. Если нет — работает над новыми функциями.
Обо всем этом расскажет Матвей Кукуй. SLI, SLO и Error Budget, источники инцидентов и их особенности, инструкция по наведению порядка в мониторинге — об этом под катом через кейсы из реальной жизни.
Матвей Кукуй (Matvey-Kuk) CEO и сооснователь компании Amixr.IO. Работал в Kaspersky, CTO в HuskyJam и в Cisco. Перед Amixr.IO перешел в стартап Constructor IO. Стартап — это команда из 7 человек, которая строит конкурента поисковику Algolia со штатом в 150. В Constructor IO Матвей отвечал за инфраструктуру и реакцию на инциденты, поэтому попробовал из инструментария все, что только можно.
Amixr — это инструмент, который помогает управлять инцидентами. Он принимает данные об инцидентах от систем мониторинга клиентов, но при этом находится вне их контуров. Когда Amixr видит инцидент, он отправляет инженерам сообщения в Slack, Telegram или по SMS. Как Amixr будет это делать, зависит от клиента: можно настроить свои правила, можно довериться искусственному интеллекту. Причем ИИ пытается соблюдать баланс: и чтобы инженеры не выгорели, и чтобы продакшн не лежал долго.
Клиент отправляет инциденты в Amixr через API.
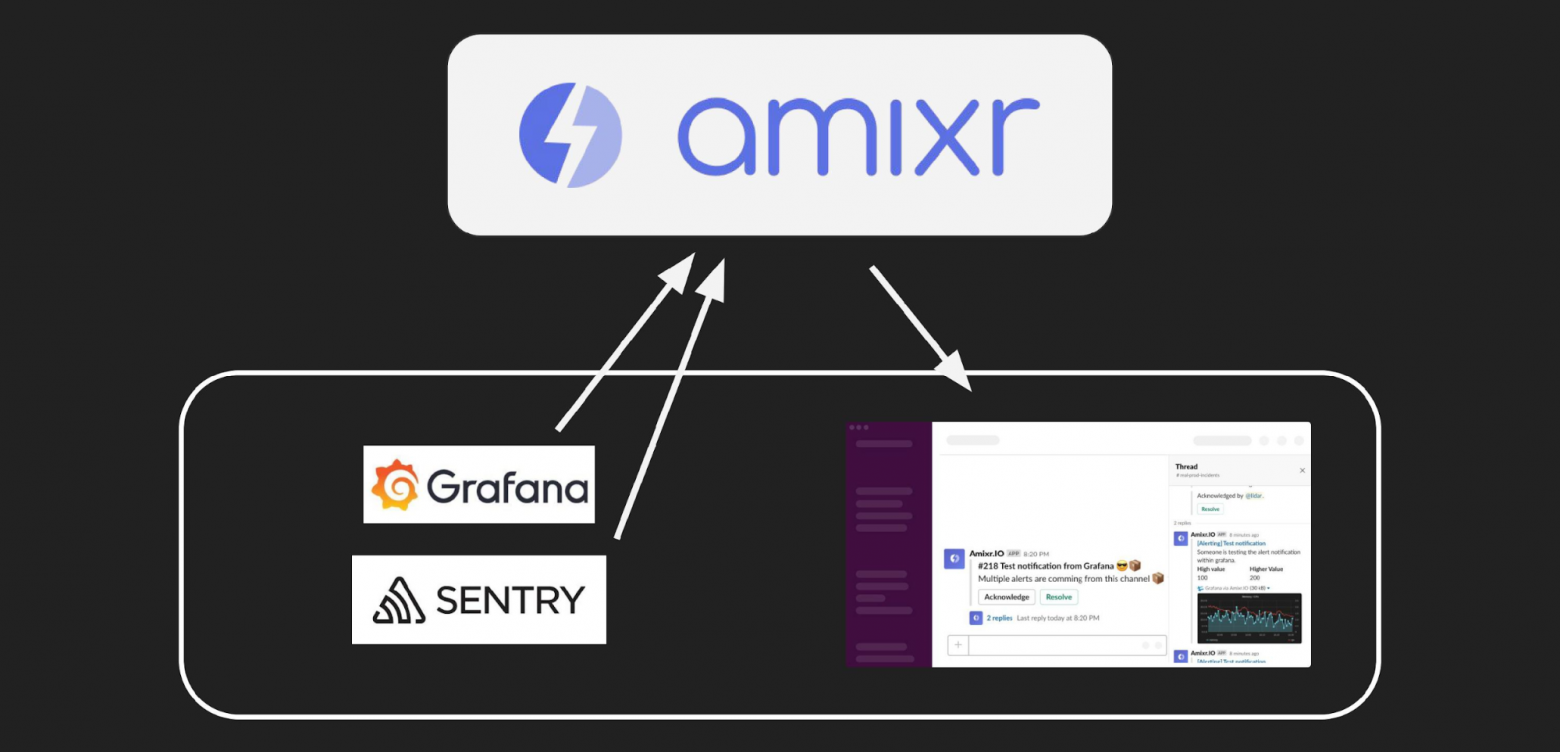
Со стороны Amixr это выглядит как множество клиентов, которое подсоединило к нам свои Grafana, Alertmanager, Sentry.
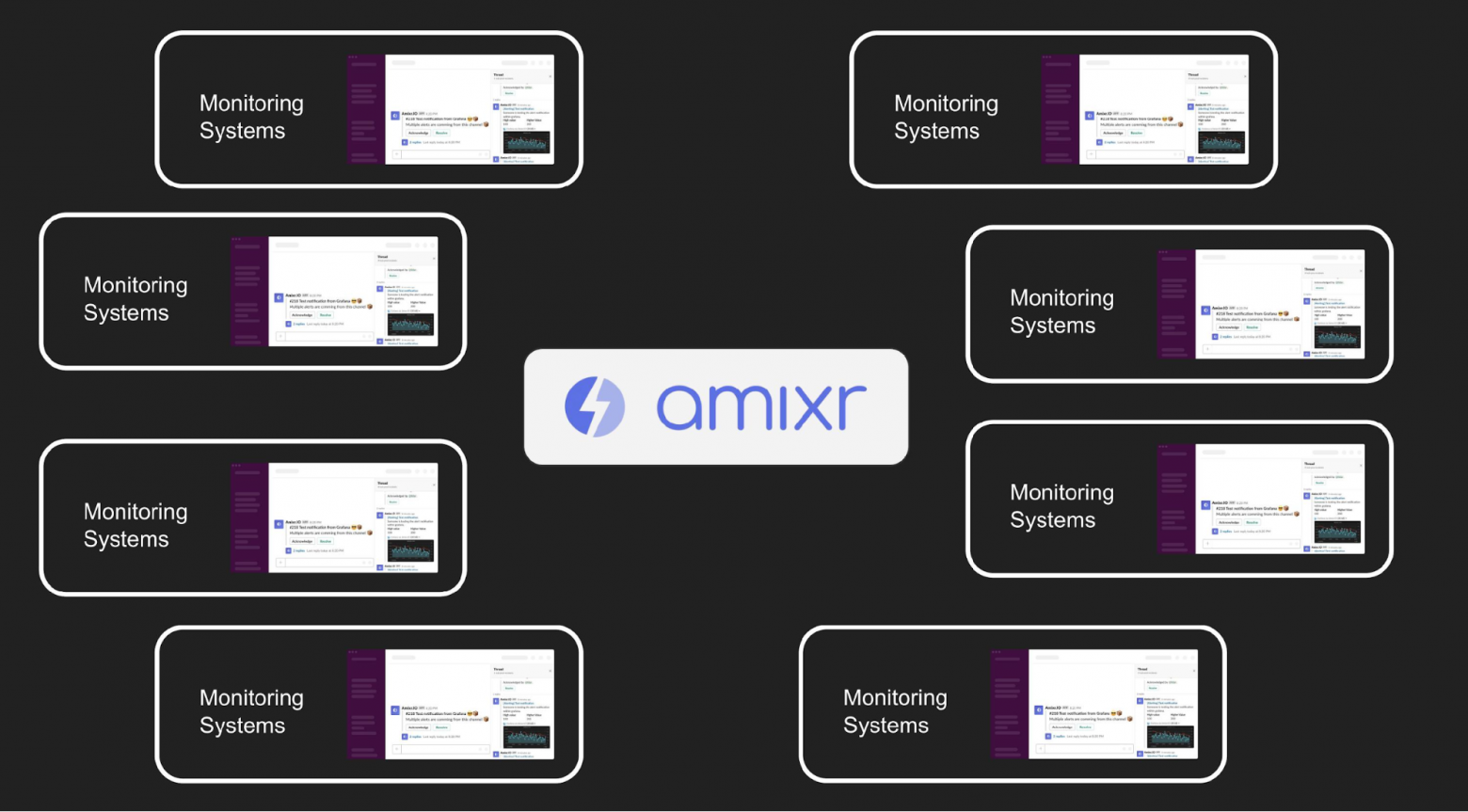
На инциденты смотрим снаружи команд, а не изнутри — регулярно интервьюируем команды, чтобы понять, что у них и как. В своем рассказе я опираюсь именно на эту информацию.
«Гарантированное» время разрешения инцидентов. Ничего гарантированного не бывает, но менеджмент обычно хочет, чтобы время на решение было жестко ограничено.
Инженеры не хотят заниматься инцидентами все время. В некоторых компаниях дежурят специально обученные люди, но большинство передают ответственность на SRE или DevOps-инженеров.
Число инцидентов не должно увеличиваться с ростом системы и, в идеале, не должно зависеть от внешних условий.
Для себя мы различаем 4 разных типа источников инцидентов. Самые яркие представители из них: Grafana, Alertmanager, Crashlytics и самописные инструменты.

Самая популярная платформа у нас. От клиентов, которые подключили Grafana, в апреле 2019 мы приняли 30 тысяч инцидентов, а в августе уже 120 тысяч.
У Grafana есть особенность. Она не всем очевидна, хотя весьма примитивна: Grafana умеет отправлять не только алерты (что не новость), но и «ОК».

Если копнем свои данные, часто видим это.

Один инцидент — это огромное количество цепочек из «ОК» и алертов.
— Что-то сломалось?
— Нет, все нормально.
— Что-то сломалось?
— Нет, все нормально.
Цепочки могут копиться днями и неделями. Это не нормально, когда источник так себя ведет. Обычно причины в изменениях внешней среды: растет нагрузка, деплой и метрики подбираются к максимумам.

Ситуация не критична, но отвлекает, что стоит компании денег. С этим нужно бороться.
Мой любимый сервис, потому что разговорчивый. Он умеет генерировать много трафика, чем доставил неудобства нашим инженерам.
В документации Alertmanager на первой странице стоит параграф о группировке.

Группировка в Alertmanager работает так.
Визуализирую этот процесс во времени. Стык между зеленой и красной частью — момент инцидента. Через 45 с после события мы получаем первый алерт, а через 2 минуты еще один. 4 часа — это repeat-интервал, то есть время, через которое Alertmanager передаст все алерты заново.

Как все видят инженеры.

Это скриншот графика потока инцидентов в час. Когда они уже узнали об инциденте, каждые 3 минуты или чаще, они получают алерты: в Slack, Telegram, кто-то звонит себе на телефон из Twilio. Инженер решает проблему, а каждые 2 минуты получает звонок.
Когда мы заметили такие графики (ниже) у fabric и Sentry, нам было непонятно, почему сначала прыжок, потом разрыв и у всех один паттерн.

Горизонтальная ось это дата: один столбец — один день. По вертикальной оси — количество алертов. Верхнее значение — 100 алертов день.
Мы расспрашивали пользователей и команды, чтобы узнать, что происходит. Вот, что мы выяснили.

Команды «отключают» режим оперативного реагирования на инциденты и занимаются только частыми исключениями. У таких команд нет градации багов по серьезности и критичности, поэтому они исправляют только то, что им кажется важным. Свежими исключениями они не занимаются — оценить серьезность новых багов не могут.
Для меня это самые интригующие источники. Самописные системы, которых много в любой компании, ведут себя не как все предыдущие.
Спамят сообщениями как Alertmanager. Это предсказуемо: они обычно stateless, написаны на Cron. Чаще это машина, которая отправляет сообщения в Kafka, а потом ждет, когда оно придет в БД.
Меняют мнение, как Grafana, потому что крутятся около максимумов.
Но у самописных решений есть бонус — как правило, у них нет веб-интерфейса. Обычно, когда команда уже написала собственный мониторинг, она не думает, как его мониторить. Поэтому самописные системы тихо падают. Падения мы видим постоянно. Если какие-то очень шумные источники алертов замолчали, скорее всего, они самописные.
Он состоит из нескольких пунктов, которые мы собираем в собственную практику:
Теперь подробнее.
Задача простая, но требует полного погружения.
Примечание. Дальше я буду говорить в терминах из книги Site Reliability Engineering. Основной из них это SLI (Service Level Indicator) — индикатора уровня доступности. Это показатели, который бизнес использует, чтобы понять, насколько его продукт доступен для пользователей.
Это первый шаг — понять по метрика, что у нас с доступностью. Например, мы выводим в дашборд Grafana (или другого мониторинга) графики. Продакт-менеджер открывает их, видит: «Скорость ответа в 9 секунд — очень плохо!» и ставит задачу в Jira.
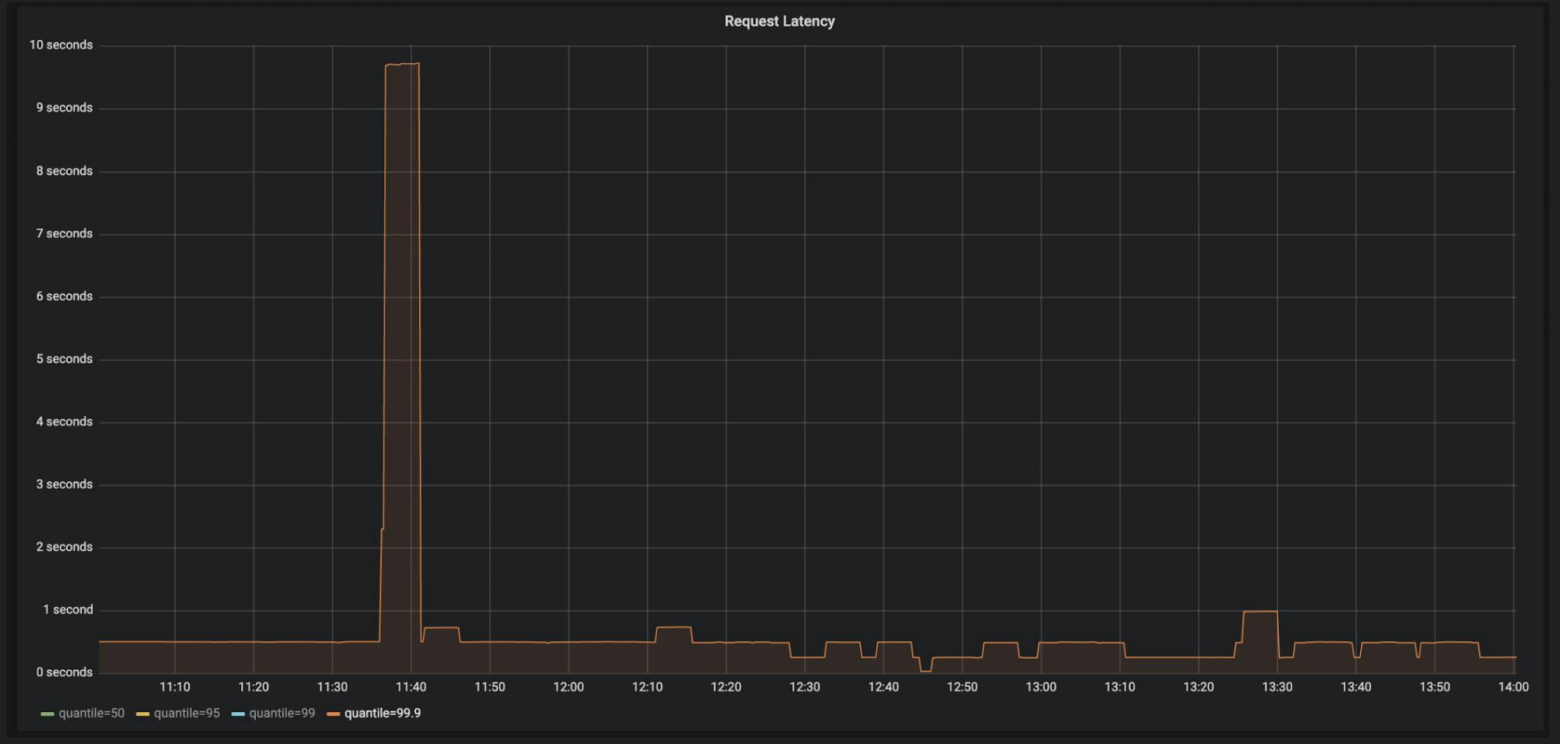
Разработчик открывает задачу и видит тот же график уже иначе.

Это частая ситуация, когда в команде разные участники видят одно и то же событие на разных графиках.
Продакт-менеджер собрал митинг всей команды, чтобы определиться с едиными графиками. Все смотрят на дашборд и проводят отсечку. Дальше решают, что задержка должна быть в 95 перцентиле и меньше 300 миллисекунд — это среднее значение по рынку. Но что делать с этими выступами — превышениями SLO (Service Level Objective)?

Service Level Objective — это бинарное представление графика в видекрасно-зеленый полосы, когда метрика либо удовлетворяет нашим требованиям, либо не удовлетворяет.
Исходя из этой идеи, определяем уровень SLO, которого будем придерживаться. SLO определяет процент времени, когда мы позволяем себе быть недоступны. Этот процент называется Error Budget. Например, когда значение SLO установлено в 99%, мы можем падать в 1% случаев. Один процент — это Error Budget.
Когда SLO подбирается к нашим границам, всю команду заваливает алертами. Все берут кирки и «латают дыры» руками.

Работа неинтересная и скучная — не для этого команда нанималась и учила Kubernetes, чтобы вручную перемещать ноды и файлики по FTTP. Это никчемная и неинтересная работа, но без нее не обойтись. Эту работу в SRE называют Toil & Toil — «тяжелый труд».
Toil Budget. Кроме метрик и SLO мы определяем еще один протокол — сколько сил и времени можем тратить на Toil & Toil. Собираемся всей командой и решаем, например, что на ручной труд уделяем 10 часов — это наш Toil Budget. Если меньше — нам сложно что-то починить, а больше не нужно. Пишем правило.
Расшифрую: если ручного труда больше, чем заложено в бюджете, то останавливаем разработку и деплои. Правило работает, только если все продакт-менеджеры, проджект-менеджеры и тимлиды примут этот договор.
У правила есть бонус.
Расшифрую: если ручного труда меньше, чем заложено в бюджете, то не автоматизируйте инфраструктуру — у вас все нормально.
Мы определили метрики и снизили общее количество инцидентов на команду. Теперь все само балансируется: когда инцидентов слишком много, toil budget превышается и деплои останавливаются. у нас появился баланс — 5 инцидентов в день, например. Каждый из них отнимает по 10-30 минут, что допустимо.
Теперь нам нужно правильно разбалансировать алерты внутри команды. Это редкое понятие, потому что разбалансировку применяют только в больших enterprise-проектах или в стартапах, в которых работают люди из enterprise разработки.
Объясню, как это работает.
Когда инженер получает алерт об инциденте, он тратит на решение в среднем 30 минут. Сначала он пытается понять критичный алерт или нет, потом исправляет, а в процессе переживает — это же продакшн.
5 инцидентов в день по 30 минут (0,5 часа) это 600 минут. Если инциденты отправляются в общий Slack-канал, где сидит 15 инженеров, то суммарно получается 37, 5 часов в неделю:
Клиентов эта цифра шокирует. Но если убрать последний множитель, то получается намного меньше:
Какой из этого вывод?
С расписанием, в любой момент времени у вас есть дежурный для оперативного реагирования на инциденты.

Расписание лучше реализовать через ПО. Если вручную, то это ад: в начале рабочего дня сотрудник смотрит в Excel, проверяет свое дежурство, включает идентификацию в Slack-канале. Не надо так.
По доменным зонам: каждому сотруднику свое уведомление, например, специалистам по БД поступают алерты из только базы.

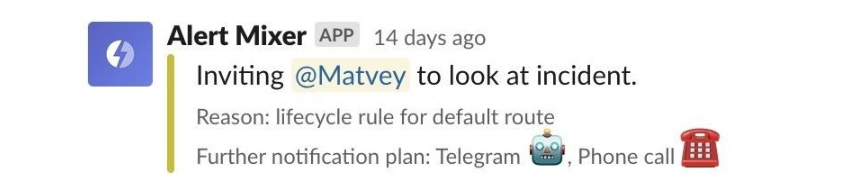
Уведомление у нас выглядит так. Система зовет определенного человека в Slack: «Матвей, реши проблему, иначе я тебе позвоню».
Это редкий пункт, который помогает разгрузить или не напрягать бедный мозг инженера, когда он начнет разбираться с инцидентом.

Это «волшебная таблетка», но мы замечаем их только в 5% инцидентов.
Runbook — это ссылка в инциденте. Инженер получает оповещение, нажимает на ссылку и попадает в документацию. В ней рассказывается, как исправлять подобный инцидент и как это делали в прошлом.

Runbook помогает инженеру быстро понять контекст и ускоряет принятие решения.
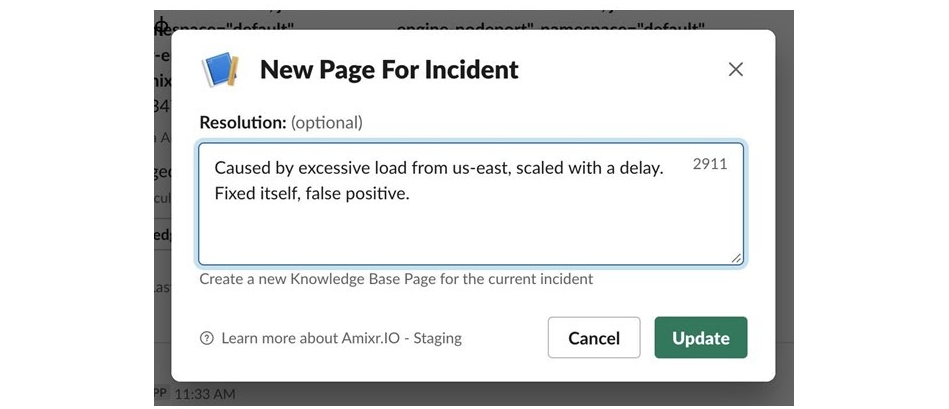
Мы записываем еще и post mortem после исправления инцидента. Это помогает устранять проблему, когда она возникнет снова.
Следующая эффективная рабочая практика — подключать к on call разработчика ( не DevOps и не SRE). Днем на него можно передать пару часов дежурства. Важно, чтобы он был первым, кто узнает об инциденте и набрал команду для решения проблемы.
Я проводил такой эксперимент в команде из 15 инженеров и результат меня удивил. Например, инженер много лет пишет программу и она работает на серверах в небольшой команде. Но, когда во вторник начнется смена и он будет ответственным за продакшн, весь понедельник инженер изучает свою программу, чтобы понять как она работает…
Это хорошо помогает распространять знания в команде и увеличивает bus factor.
За дежурства нужно платить. Даже если инженер дежурит во время работы. График и периодичность дежурств выводится из SLO.
Представьте, что в команде прочли книгу о SRE и все доклады по инцидентам. Собираем всех в переговорке и договариваемся о SLI и SLO. Все «просветлились», разошлись, но никто ничего не начал делать. Почему?

Причина в дрейфах, когда договоренности и установленный процесс ломается из-за изменений внешних условий или ожиданий.
Первый типичный дрейф. Возникает, когда появляется новый код и меняются условия. Например, Grafana подбирается к максимальным значениям, а мониторинги шумят, либо молчат.
Этот дрейф мы встречаем у всех. Он проявляется через 1-2 недели после тотальной настройки мониторинга и может изматывать команду месяцами.
У нас есть детектор этого дрейфа. Если какой-то источник подозрительно долго молчит или много шлет, мы пишем команде, чтобы они обратили внимание на источник.

Самый опасный дрейф. Причины, скорее всего, в психологии: некоторые инженеры начинают брать на себя все больше инцидентов, даже если не дежурят. Другие инженеры это видят и перестают реагировать на свои уведомления — зачем, есть же «самый ответственный», который не пропускает ни одного уведомления. Это приводит к дисбалансу — несколько человек в команде заняты инцидентами, а все остальные своими делами.
Для этого дрейфа у нас также есть детектор. Что интересно, по показаниям детектора мы поняли, что в каждой команде есть «герой», который берет всю ответственность на себя, встает ночью не в свою смену и выгорает.

Это когда информация о том, как исправлять инциденты, исчезает в команде. Например, сотрудник после долгого отпуска вливается в работу с инцидентами, но встречается с чем-то новым и не может решить проблему. В результате уже вся команда помогает сотруднику, вместо решения своих задач.

Кроме отпуска, есть и другие причины:
Это регулярная проблема наших клиентов, а решение в контроле. Здесь нужно не помогать всем коллективом, а контролировать работу сотрудника. Пусть научится исправлять инциденты, иначе коллектив будет регулярно отвлекаться на помощь одному человеку.
Чтобы со всем этим разобраться, мы применяем методику, которая называется Production Meeting. Не я ее придумал — это часть Site Reliability Engineering. Методика применяется для быстрорастущих система, когда появляется большая нагрузка и большой поток инцидентов.
На стандартных стендапах решается над чем и когда будет работать команда. На Production Meeting сначала изучаются метрики: вся команда открывает дашборд и часто видит что-то новое.
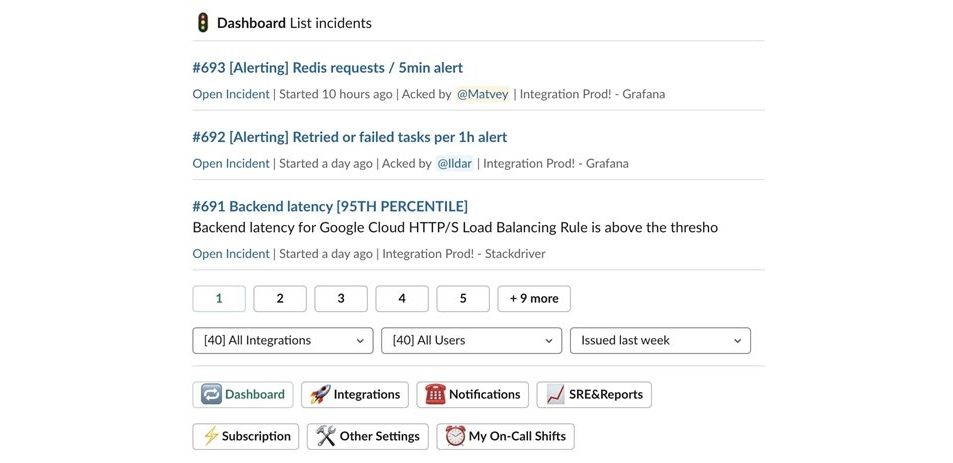
Изучается каждый инцидент в дашборде системы управлениями инцидентами, чтобы понять, что произошло. Это помогает предотвратить проблемы в будущем: некоторые категории инцидентов всплывают постоянно, например, метрики или отключения.
На Production Meeting также изучаются инциденты, которые не поднимали команду, а просто копились. Потом пишется план действий (action items). Это очень похоже на стендап, который посвящен исключительно инцидент-менеджменту.
Мы провели собеседования с сотней команд по всему миру: в России, США и Европе. Это были большие компании, маленькие, даже фриланс-группы, но среди них не было двух одинаковых команд.
Что интересного мы заметили?
Все работают с инцидентами по-разному. Есть команды, которым инциденты постоянно выносят мозг и разработка ничего не разрабатывает. Есть команды, которые считают, что их продакшн важен, а это не так, поэтому у них нет инцидентов. Обычно это мобильные разработчики, которые пользуются serverless архитектурой или получают сообщения от пользователей — это и есть их инциденты.
Инцидент-менеджмент не дрейфует в командах меньше 3 человек. Это логично — два человека постоянно крутятся, у них все прекрасно и быстро работает.
В командах от 10 до 30 человек нет контроля. В них есть место для ухода в тень, что большинство и делает — перестает реагировать на инциденты. В командах такого размера менеджмент обычно сфокусирован на чем-то другом, нет выделенных людей, которые отвечают за инциденты.
Чем больше enterprise-проект — тем больше контроль. Как правило, в них есть люди, которые отвечают за свое направление: отдельно за инциденты, отдельно за post mortem и runbooks.
В некоторых компаниях за инциденты отвечает штатный дежурный. Это отдельная должность с одной задачей — разбирать инциденты. В таких компаниях не имеют значения инструменты и практики, потому что дежурный сидит за компьютером, разбирает поток писем, а в 6 вечера его сменяют. Им нужны другие инструменты и другие подходы, у них все работает.
Концепция SRE содержит много «странных вещей». В SRE разработчики не только пишут код, но и следят за тем, как он работает в продакшне. Доступность и надежность приложений и сайтов начинается с измерения доступности в виде четких показателей и установки показателей надежности. Еще в SRE есть «право на ошибку» или Error Budget. Когда это «право» исчерпано, команда занимается повышением надежности. Если нет — работает над новыми функциями.
Обо всем этом расскажет Матвей Кукуй. SLI, SLO и Error Budget, источники инцидентов и их особенности, инструкция по наведению порядка в мониторинге — об этом под катом через кейсы из реальной жизни.
Матвей Кукуй (Matvey-Kuk) CEO и сооснователь компании Amixr.IO. Работал в Kaspersky, CTO в HuskyJam и в Cisco. Перед Amixr.IO перешел в стартап Constructor IO. Стартап — это команда из 7 человек, которая строит конкурента поисковику Algolia со штатом в 150. В Constructor IO Матвей отвечал за инфраструктуру и реакцию на инциденты, поэтому попробовал из инструментария все, что только можно.
Amixr Inc.
Amixr — это инструмент, который помогает управлять инцидентами. Он принимает данные об инцидентах от систем мониторинга клиентов, но при этом находится вне их контуров. Когда Amixr видит инцидент, он отправляет инженерам сообщения в Slack, Telegram или по SMS. Как Amixr будет это делать, зависит от клиента: можно настроить свои правила, можно довериться искусственному интеллекту. Причем ИИ пытается соблюдать баланс: и чтобы инженеры не выгорели, и чтобы продакшн не лежал долго.
Клиент отправляет инциденты в Amixr через API.
Со стороны Amixr это выглядит как множество клиентов, которое подсоединило к нам свои Grafana, Alertmanager, Sentry.
На инциденты смотрим снаружи команд, а не изнутри — регулярно интервьюируем команды, чтобы понять, что у них и как. В своем рассказе я опираюсь именно на эту информацию.
Что хотят клиенты
«Гарантированное» время разрешения инцидентов. Ничего гарантированного не бывает, но менеджмент обычно хочет, чтобы время на решение было жестко ограничено.
Инженеры не хотят заниматься инцидентами все время. В некоторых компаниях дежурят специально обученные люди, но большинство передают ответственность на SRE или DevOps-инженеров.
Число инцидентов не должно увеличиваться с ростом системы и, в идеале, не должно зависеть от внешних условий.
Источники инцидентов
Для себя мы различаем 4 разных типа источников инцидентов. Самые яркие представители из них: Grafana, Alertmanager, Crashlytics и самописные инструменты.
Grafana
Самая популярная платформа у нас. От клиентов, которые подключили Grafana, в апреле 2019 мы приняли 30 тысяч инцидентов, а в августе уже 120 тысяч.
У Grafana есть особенность. Она не всем очевидна, хотя весьма примитивна: Grafana умеет отправлять не только алерты (что не новость), но и «ОК».
Если копнем свои данные, часто видим это.
Один инцидент — это огромное количество цепочек из «ОК» и алертов.
— Что-то сломалось?
— Нет, все нормально.
— Что-то сломалось?
— Нет, все нормально.
Цепочки могут копиться днями и неделями. Это не нормально, когда источник так себя ведет. Обычно причины в изменениях внешней среды: растет нагрузка, деплой и метрики подбираются к максимумам.
Ситуация не критична, но отвлекает, что стоит компании денег. С этим нужно бороться.
Grafana генерирует много шума.По статистике нашей платформы, 20% инцидентов (метрик в Grafana) на одно значимое срабатывание генерируют 5 алертов и больше.
Alertmanager
Мой любимый сервис, потому что разговорчивый. Он умеет генерировать много трафика, чем доставил неудобства нашим инженерам.
В документации Alertmanager на первой странице стоит параграф о группировке.
Группировка в Alertmanager работает так.
group_by: ['instance', 'job']— можно сгруппировать алерты по лейблам.group_wait: 45s. Это время между появлением первого инцидента и моментом, когда AlertManager группирует, держит в себе все эти инциденты и передает во внешний источник.group_interval: 2m # Usually ~5 mins or more— интервалы передачи нового инцидента. В больших инфраструктурах обычно это каждые 2 минуты.
Визуализирую этот процесс во времени. Стык между зеленой и красной частью — момент инцидента. Через 45 с после события мы получаем первый алерт, а через 2 минуты еще один. 4 часа — это repeat-интервал, то есть время, через которое Alertmanager передаст все алерты заново.
Как все видят инженеры.
Это скриншот графика потока инцидентов в час. Когда они уже узнали об инциденте, каждые 3 минуты или чаще, они получают алерты: в Slack, Telegram, кто-то звонит себе на телефон из Twilio. Инженер решает проблему, а каждые 2 минуты получает звонок.
Alertmanager генерирует много оповещений.
Crashlytics/fabric
Когда мы заметили такие графики (ниже) у fabric и Sentry, нам было непонятно, почему сначала прыжок, потом разрыв и у всех один паттерн.
Горизонтальная ось это дата: один столбец — один день. По вертикальной оси — количество алертов. Верхнее значение — 100 алертов день.
Мы расспрашивали пользователей и команды, чтобы узнать, что происходит. Вот, что мы выяснили.
- Деплой новой версии — это генератор исключений (exception).
- После деплоя новой версии команда знает о своих багах и отключает нас, чтобы их заваливало уведомлениями — они не могут фокусироваться.
- Но без алертов страшно и нас подключают обратно.
Команды «отключают» режим оперативного реагирования на инциденты и занимаются только частыми исключениями. У таких команд нет градации багов по серьезности и критичности, поэтому они исправляют только то, что им кажется важным. Свежими исключениями они не занимаются — оценить серьезность новых багов не могут.
Самописные
Для меня это самые интригующие источники. Самописные системы, которых много в любой компании, ведут себя не как все предыдущие.
Спамят сообщениями как Alertmanager. Это предсказуемо: они обычно stateless, написаны на Cron. Чаще это машина, которая отправляет сообщения в Kafka, а потом ждет, когда оно придет в БД.
Меняют мнение, как Grafana, потому что крутятся около максимумов.
Но у самописных решений есть бонус — как правило, у них нет веб-интерфейса. Обычно, когда команда уже написала собственный мониторинг, она не думает, как его мониторить. Поэтому самописные системы тихо падают. Падения мы видим постоянно. Если какие-то очень шумные источники алертов замолчали, скорее всего, они самописные.
План действий
Он состоит из нескольких пунктов, которые мы собираем в собственную практику:
- снижаем количество инцидентов;
- распределяем инциденты по специалистам;
- повышаем эффективность;
- поддерживаем.
Теперь подробнее.
Снижаем общее количество инцидентов на команду
Задача простая, но требует полного погружения.
Примечание. Дальше я буду говорить в терминах из книги Site Reliability Engineering. Основной из них это SLI (Service Level Indicator) — индикатора уровня доступности. Это показатели, который бизнес использует, чтобы понять, насколько его продукт доступен для пользователей.
Определяем метрики
Это первый шаг — понять по метрика, что у нас с доступностью. Например, мы выводим в дашборд Grafana (или другого мониторинга) графики. Продакт-менеджер открывает их, видит: «Скорость ответа в 9 секунд — очень плохо!» и ставит задачу в Jira.
Разработчик открывает задачу и видит тот же график уже иначе.
Это частая ситуация, когда в команде разные участники видят одно и то же событие на разных графиках.
SLO
Продакт-менеджер собрал митинг всей команды, чтобы определиться с едиными графиками. Все смотрят на дашборд и проводят отсечку. Дальше решают, что задержка должна быть в 95 перцентиле и меньше 300 миллисекунд — это среднее значение по рынку. Но что делать с этими выступами — превышениями SLO (Service Level Objective)?
Service Level Objective — это бинарное представление графика в видекрасно-зеленый полосы, когда метрика либо удовлетворяет нашим требованиям, либо не удовлетворяет.
Ничто не может работать на 100% надежно.Если мы хотим 100% надежности, то придется запретить разработчикам вносить любые изменения и новые функции.
Исходя из этой идеи, определяем уровень SLO, которого будем придерживаться. SLO определяет процент времени, когда мы позволяем себе быть недоступны. Этот процент называется Error Budget. Например, когда значение SLO установлено в 99%, мы можем падать в 1% случаев. Один процент — это Error Budget.
Работаем руками
Когда SLO подбирается к нашим границам, всю команду заваливает алертами. Все берут кирки и «латают дыры» руками.
Работа неинтересная и скучная — не для этого команда нанималась и учила Kubernetes, чтобы вручную перемещать ноды и файлики по FTTP. Это никчемная и неинтересная работа, но без нее не обойтись. Эту работу в SRE называют Toil & Toil — «тяжелый труд».
Toil Budget. Кроме метрик и SLO мы определяем еще один протокол — сколько сил и времени можем тратить на Toil & Toil. Собираемся всей командой и решаем, например, что на ручной труд уделяем 10 часов — это наш Toil Budget. Если меньше — нам сложно что-то починить, а больше не нужно. Пишем правило.
if toil_used > toil_budget: automate(toil)
Расшифрую: если ручного труда больше, чем заложено в бюджете, то останавливаем разработку и деплои. Правило работает, только если все продакт-менеджеры, проджект-менеджеры и тимлиды примут этот договор.
У правила есть бонус.
if toil_used > toil_budget: automate(toil) else: do smth else!
Расшифрую: если ручного труда меньше, чем заложено в бюджете, то не автоматизируйте инфраструктуру — у вас все нормально.
Балансируем инциденты внутри команды
Мы определили метрики и снизили общее количество инцидентов на команду. Теперь все само балансируется: когда инцидентов слишком много, toil budget превышается и деплои останавливаются. у нас появился баланс — 5 инцидентов в день, например. Каждый из них отнимает по 10-30 минут, что допустимо.
Теперь нам нужно правильно разбалансировать алерты внутри команды. Это редкое понятие, потому что разбалансировку применяют только в больших enterprise-проектах или в стартапах, в которых работают люди из enterprise разработки.
Объясню, как это работает.
Когда инженер получает алерт об инциденте, он тратит на решение в среднем 30 минут. Сначала он пытается понять критичный алерт или нет, потом исправляет, а в процессе переживает — это же продакшн.
5 инцидентов в день по 30 минут (0,5 часа) это 600 минут. Если инциденты отправляются в общий Slack-канал, где сидит 15 инженеров, то суммарно получается 37, 5 часов в неделю:
0,5 * 5 * 15 = 37,5.Клиентов эта цифра шокирует. Но если убрать последний множитель, то получается намного меньше:
0,5 * 5 = 2,5 часаКакой из этого вывод?
В один момент времени за инцидент должен быть ответственен только один человек.Правило реализуется с помощью нескольких инструментов: расписание и маршрутизация.
Расписание
С расписанием, в любой момент времени у вас есть дежурный для оперативного реагирования на инциденты.
Расписание лучше реализовать через ПО. Если вручную, то это ад: в начале рабочего дня сотрудник смотрит в Excel, проверяет свое дежурство, включает идентификацию в Slack-канале. Не надо так.
Маршрутизация
По доменным зонам: каждому сотруднику свое уведомление, например, специалистам по БД поступают алерты из только базы.
Уведомление у нас выглядит так. Система зовет определенного человека в Slack: «Матвей, реши проблему, иначе я тебе позвоню».
Повышаем эффективность решения
Это редкий пункт, который помогает разгрузить или не напрягать бедный мозг инженера, когда он начнет разбираться с инцидентом.
Runbooks
Это «волшебная таблетка», но мы замечаем их только в 5% инцидентов.
Runbook — это ссылка в инциденте. Инженер получает оповещение, нажимает на ссылку и попадает в документацию. В ней рассказывается, как исправлять подобный инцидент и как это делали в прошлом.
Runbook помогает инженеру быстро понять контекст и ускоряет принятие решения.
Мы записываем еще и post mortem после исправления инцидента. Это помогает устранять проблему, когда она возникнет снова.
Дежурство с software-инженерами
Следующая эффективная рабочая практика — подключать к on call разработчика ( не DevOps и не SRE). Днем на него можно передать пару часов дежурства. Важно, чтобы он был первым, кто узнает об инциденте и набрал команду для решения проблемы.
Я проводил такой эксперимент в команде из 15 инженеров и результат меня удивил. Например, инженер много лет пишет программу и она работает на серверах в небольшой команде. Но, когда во вторник начнется смена и он будет ответственным за продакшн, весь понедельник инженер изучает свою программу, чтобы понять как она работает…
Это хорошо помогает распространять знания в команде и увеличивает bus factor.
За дежурства нужно платить. Даже если инженер дежурит во время работы. График и периодичность дежурств выводится из SLO.
Поддерживаем
Представьте, что в команде прочли книгу о SRE и все доклады по инцидентам. Собираем всех в переговорке и договариваемся о SLI и SLO. Все «просветлились», разошлись, но никто ничего не начал делать. Почему?
Причина в дрейфах, когда договоренности и установленный процесс ломается из-за изменений внешних условий или ожиданий.
Дрейф пороговых значений
Первый типичный дрейф. Возникает, когда появляется новый код и меняются условия. Например, Grafana подбирается к максимальным значениям, а мониторинги шумят, либо молчат.
Этот дрейф мы встречаем у всех. Он проявляется через 1-2 недели после тотальной настройки мониторинга и может изматывать команду месяцами.
У нас есть детектор этого дрейфа. Если какой-то источник подозрительно долго молчит или много шлет, мы пишем команде, чтобы они обратили внимание на источник.
Дрейф расписаний и нагрузки на инженеров
Самый опасный дрейф. Причины, скорее всего, в психологии: некоторые инженеры начинают брать на себя все больше инцидентов, даже если не дежурят. Другие инженеры это видят и перестают реагировать на свои уведомления — зачем, есть же «самый ответственный», который не пропускает ни одного уведомления. Это приводит к дисбалансу — несколько человек в команде заняты инцидентами, а все остальные своими делами.
Для этого дрейфа у нас также есть детектор. Что интересно, по показаниям детектора мы поняли, что в каждой команде есть «герой», который берет всю ответственность на себя, встает ночью не в свою смену и выгорает.
Дрейф знаний об исправлении инцидентов
Это когда информация о том, как исправлять инциденты, исчезает в команде. Например, сотрудник после долгого отпуска вливается в работу с инцидентами, но встречается с чем-то новым и не может решить проблему. В результате уже вся команда помогает сотруднику, вместо решения своих задач.
Кроме отпуска, есть и другие причины:
- игнорирование;
- новая доменная зона;
- новое ПО.
Это регулярная проблема наших клиентов, а решение в контроле. Здесь нужно не помогать всем коллективом, а контролировать работу сотрудника. Пусть научится исправлять инциденты, иначе коллектив будет регулярно отвлекаться на помощь одному человеку.
Production meeting
Чтобы со всем этим разобраться, мы применяем методику, которая называется Production Meeting. Не я ее придумал — это часть Site Reliability Engineering. Методика применяется для быстрорастущих система, когда появляется большая нагрузка и большой поток инцидентов.
На стандартных стендапах решается над чем и когда будет работать команда. На Production Meeting сначала изучаются метрики: вся команда открывает дашборд и часто видит что-то новое.
Изучается каждый инцидент в дашборде системы управлениями инцидентами, чтобы понять, что произошло. Это помогает предотвратить проблемы в будущем: некоторые категории инцидентов всплывают постоянно, например, метрики или отключения.
На Production Meeting также изучаются инциденты, которые не поднимали команду, а просто копились. Потом пишется план действий (action items). Это очень похоже на стендап, который посвящен исключительно инцидент-менеджменту.
Все команды разные
Мы провели собеседования с сотней команд по всему миру: в России, США и Европе. Это были большие компании, маленькие, даже фриланс-группы, но среди них не было двух одинаковых команд.
Что интересного мы заметили?
Все работают с инцидентами по-разному. Есть команды, которым инциденты постоянно выносят мозг и разработка ничего не разрабатывает. Есть команды, которые считают, что их продакшн важен, а это не так, поэтому у них нет инцидентов. Обычно это мобильные разработчики, которые пользуются serverless архитектурой или получают сообщения от пользователей — это и есть их инциденты.
Инцидент-менеджмент не дрейфует в командах меньше 3 человек. Это логично — два человека постоянно крутятся, у них все прекрасно и быстро работает.
В командах от 10 до 30 человек нет контроля. В них есть место для ухода в тень, что большинство и делает — перестает реагировать на инциденты. В командах такого размера менеджмент обычно сфокусирован на чем-то другом, нет выделенных людей, которые отвечают за инциденты.
Чем больше enterprise-проект — тем больше контроль. Как правило, в них есть люди, которые отвечают за свое направление: отдельно за инциденты, отдельно за post mortem и runbooks.
В некоторых компаниях за инциденты отвечает штатный дежурный. Это отдельная должность с одной задачей — разбирать инциденты. В таких компаниях не имеют значения инструменты и практики, потому что дежурный сидит за компьютером, разбирает поток писем, а в 6 вечера его сменяют. Им нужны другие инструменты и другие подходы, у них все работает.
Мы уделяем большое внимание теме SRE на DevOpsConf. Если у вас есть полезный опыт, которым вы готовы делиться, присылайте заявку на доклад. Несмотря на то, что конференция в сентябре, мы уже работаем над программой и не оставим заявку без внимания. А если ваша тема ближе к разработке высоконагруженных систем, то есть еще несколько дней, чтобы подать доклад на Saint HighLoad++.
Подписывайтесь на рассылку или telegram-канал, чтобы быть в курсе дедлайнов и обновлений конференции.

