Как стоит поступить (а как точно не надо), если в «многомиллионной» активно используемой таблице PostgreSQL нужно обновить большое количество записей — проинициализировать значение нового поля или скорректировать ошибки в существующих записях? А при этом сохранить свое время и не потерять деньги компании из-за простоя.

Подготовим тестовые данные:
Допустим, мы хотим просто увеличить значение v на 1 у всех записей с k в диапазоне 'q'..'z'.
Но, прежде чем начать эксперименты, сохраним исходный датасет, чтобы иметь «чистые» результаты каждый раз:
Самый простой вариант, который сразу приходит на ум — сделать все «за один UPDATE»:

[посмотреть на explain.tensor.ru]
Достаточно простая, казалось бы, операция на совсем «коротких» строках выполнялась дольше 2.5 секунд. А если выражение у вас будет посложнее, строка подлиннее, записей побольше, да еще и какие-нибудь триггеры вмешаются — время может увеличиться даже не до минут, а до часов. Положим, вы-то готовы подождать, а вся остальная ваша система, завязанная на эту базу, если в нее идет активная OLTP-нагрузка?
Проблема в том, что как только UPDATE добирается до конкретной записи, он ее блокирует до окончания выполнения. Если одновременно с той же записью захочет поработать параллельно запустившийся «точечный» UPDATE, он все равно «зацепится» на ожидании блокировки за обновляющий запрос, и провисит так до самого конца его работы.

© wumo.com/wumo
Хуже всего в такой ситуации приходится web-системам, где соединения к БД создаются по мере надобности — ведь такие «повисшие» коннекты накапливаются и будут проедать ресурсы как БД, так и клиента, если не делать от этого отдельный защитный механизм.
В общем, все не очень хорошо, если все делать за один запрос. Да и даже если мы разделим один большой UPDATE на несколько маленьких, но оставим все это работать в одной транзакции — проблема с блокировкой останется та же самая, потому что изменяемые записи блокируются до окончания всей транзакции.
Значит, нам надо разбить одну большую транзакцию на несколько. Для этого мы можем или использовать внешние средства, и написать какой-то порождающий отдельные транзакции скрипт, или использовать те возможности, которые нам может предоставить сама база.
Начиная с версии PostgreSQL 11, появилась возможность управлять транзакциями прямо внутри процедурного кода:
По этой же причине не будем рассматривать и вариант организации автономных транзакций через pg_background.
Для эмуляции автономных транзакций в PostgreSQL исторически используются разные методы, порождающие отдельные дополнительные соединения — через дополнительные процедурные языки или штатный модуль dblink. Преимущество последнего в том, что он по умолчанию входит в большинство дистрибутивов, и для его активации в базе требуется всего одна команда:
"… и много-много
Но прежде чем создавать dblink-обвязку, давайте сначала прикинем, как «обычный разработчик» разбивает большой датасет, который ему надо обновить, на маленькие.
Первая же идея — сделать «постраничный» перебор: «Давайте будем отбирать каждый раз следующую тысячу записей» с помощью увеличения OFFSET в каждом новом запросе:
Прежде чем тестировать производительность этого решения, восстановим датасет:
Как мы видели в плане выше, обновиться у нас должны будут примерно 384K записей. Поэтому давайте сразу посмотрим, как будут выполняться обновления ближе к концу — в районе 300-й итерации по 1000 записей:

[посмотреть на explain.tensor.ru]
Ой… Обновление находящейся ближе к концу выборки всего 1K записей будет стоить нам практически столько же времени, как весь исходный вариант целиком!
Это не наш выбор. Он еще может как-то использоваться, если получается мало итераций и небольшие значения OFFSET. Потому что LIMIT X OFFSET Y для базы эквивалентно "вычитай/отбери/сформируй сначала X+Y записей, а потом первые Y выкинь в мусор", что при больших значениях Y выглядит трагично.
На самом деле, такой способ вообще нельзя применять! Мало того, что мы опираемся при отборе на обновляемые значения, так еще и рискуем пропустить часть записей, а другую часть обновить дважды, если блоки с одинаковыми ключами попадут на границу страниц:
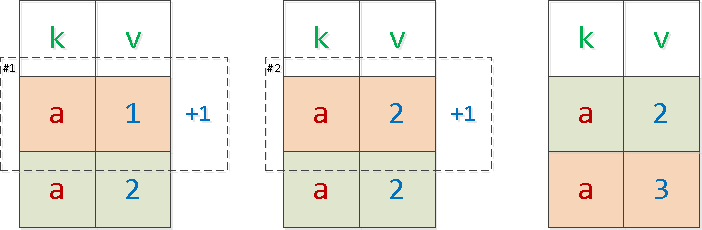
В этом примере «зеленую» запись мы обновили дважды, а «красную» — ни разу. Просто потому, что при одинаковых значениях ключей сортировки порядок самих записей внутри такого блока не фиксирован.
Давайте чуть модифицируем задачу — добавим новое поле, в которое и будем записывать наше значение v + 1:
Обратите внимание, что такая конструкция работает практически мгновенно, без переписывания всей таблицы. А вот если добавить DEFAULT-значение, то — только начиная с 11-й версии.
Уже наученные горьким опытом, давайте сразу создадим индекс, в котором будут оставаться только неинициализированные записи:
CONCURRENTLY-индекс не блокирует работу с таблицей на чтение-запись, пока неспешно накатывается даже на огромный датасет.
Теперь идея звучит как «Давайте отбирать из этого индекса каждый раз только первую тысячу записей»:
[посмотреть на explain.tensor.ru]
Уже много лучше — длительность каждой отдельной транзакции теперь у нас короче примерно в 6 раз.
Но давайте опять посмотрим, во что превратится план к 200-й итерации:
Время опять ухудшилось (правда, всего на 25%), и значение buffers выросло — но почему?
Дело в том, что MVCC в PostgreSQL оставляет в индексе «мертвые души» — версии уже обновленных записей, теперь под индекс уже не подходящих. То есть отбирая всего 1000 первых записей на 200-й итерации, мы все равно сканируем, хоть потом и отбрасываем, предыдущие 199K уже измененных версий кортежей.
Если итераций у нас требуется не несколько сотен, а несколько сотен тысяч, то деградация будет все заметнее с каждым следующим выполнением запроса.
Собственно, а чего мы так привязались к этому значению «1000 записей»? Ведь у нас нет причин выбирать ровно по 1000 или какому-то другому конкретному числу. Мы всего-то хотели просто весь датасет «нарезать» на какие-то, необязательно равные, непересекающиеся сегменты — так давайте используем по прямому назначению имеющийся у нас индекс.
Для нашей задачи индексированная пара (k, v) отлично подходит. Построим запрос, чтобы он мог отталкиваться от последней обработанной пары:
На первой итерации нам достаточно выставить параметры запроса в «нулевое» значение ('', 0), а для каждой следующей итерации брать результат предыдущего запроса.
[посмотреть на explain.tensor.ru]
Время транзакции/блокировок — меньше миллисекунды, деградации от количества итераций — нет, полное предварительное сканирование всех данных в таблице — не требуется. Отлично!
Дополнительное преимущество такого способа заключается в возможности прервать выполнение этого скрипта в любой момент, а потом возобновить с нужной точки.
Отдельно упомяну ситуацию со сложным вычислением присваиваемого значения — когда надо что-то посчитать по связаным таблицам.
Время, затрачиваемое на вычисления, точно так же увеличивает длительность транзакции. Поэтому наиболее оптимальным вариантом будет вынести процесс вычисления этих значений за рамки UPDATE.
Например, мы хотим заполнить наше новое поле x количеством записей, которые имеют то же значение (k,v). Создадим «временную» таблицу, генерация которой не накладывает дополнительных блокировок:
Теперь мы можем по описанной выше модели итерировать уже по этой таблице, обновляя целевую:
Как видим, никаких сложных вычислений уже не требуется.
Только не забудьте потом удалить вспомогательную таблицу.
Подготовим тестовые данные:
CREATE TABLE tbl(k text, v integer); INSERT INTO tbl SELECT chr(ascii('a'::text) + (random() * 26)::integer) k , (random() * 100)::integer v FROM generate_series(1, 1000000) i; -- вот он, наш миллион записей! CREATE INDEX ON tbl(k, v);
Допустим, мы хотим просто увеличить значение v на 1 у всех записей с k в диапазоне 'q'..'z'.
Но, прежде чем начать эксперименты, сохраним исходный датасет, чтобы иметь «чистые» результаты каждый раз:
CREATE TABLE _tbl AS TABLE tbl;
UPDATE: один за всех, и все за одного
Самый простой вариант, который сразу приходит на ум — сделать все «за один UPDATE»:
UPDATE tbl SET v = v + 1 WHERE k BETWEEN 'q' AND 'z';
[посмотреть на explain.tensor.ru]
Достаточно простая, казалось бы, операция на совсем «коротких» строках выполнялась дольше 2.5 секунд. А если выражение у вас будет посложнее, строка подлиннее, записей побольше, да еще и какие-нибудь триггеры вмешаются — время может увеличиться даже не до минут, а до часов. Положим, вы-то готовы подождать, а вся остальная ваша система, завязанная на эту базу, если в нее идет активная OLTP-нагрузка?
Проблема в том, что как только UPDATE добирается до конкретной записи, он ее блокирует до окончания выполнения. Если одновременно с той же записью захочет поработать параллельно запустившийся «точечный» UPDATE, он все равно «зацепится» на ожидании блокировки за обновляющий запрос, и провисит так до самого конца его работы.
© wumo.com/wumo
Хуже всего в такой ситуации приходится web-системам, где соединения к БД создаются по мере надобности — ведь такие «повисшие» коннекты накапливаются и будут проедать ресурсы как БД, так и клиента, если не делать от этого отдельный защитный механизм.
Дробим транзакции
В общем, все не очень хорошо, если все делать за один запрос. Да и даже если мы разделим один большой UPDATE на несколько маленьких, но оставим все это работать в одной транзакции — проблема с блокировкой останется та же самая, потому что изменяемые записи блокируются до окончания всей транзакции.
Значит, нам надо разбить одну большую транзакцию на несколько. Для этого мы можем или использовать внешние средства, и написать какой-то порождающий отдельные транзакции скрипт, или использовать те возможности, которые нам может предоставить сама база.
CALL и управление транзакциями
Начиная с версии PostgreSQL 11, появилась возможность управлять транзакциями прямо внутри процедурного кода:
В процедурах, вызываемых командой CALL, а также в анонимных блоках кода (в команде DO) можно завершать транзакции, выполняя COMMIT и ROLLBACK. После завершения транзакции этими командами новая будет начата автоматически.Но эта версия стоит «на бою» далеко не у всех, да и работа с CALL имеет свои ограничения. Поэтому попробуем решить нашу задачу без внешних средств, и так чтобы она работала на всех актуальных версиях, да еще и с минимальными изменениями на самом сервере — чтобы не надо было ничего компилировать и перезапускать.
По этой же причине не будем рассматривать и вариант организации автономных транзакций через pg_background.
Управление соединениями «внутри» базы
Для эмуляции автономных транзакций в PostgreSQL исторически используются разные методы, порождающие отдельные дополнительные соединения — через дополнительные процедурные языки или штатный модуль dblink. Преимущество последнего в том, что он по умолчанию входит в большинство дистрибутивов, и для его активации в базе требуется всего одна команда:
CREATE EXTENSION dblink;
"… и много-много ргадостей детишкам принесла"
Но прежде чем создавать dblink-обвязку, давайте сначала прикинем, как «обычный разработчик» разбивает большой датасет, который ему надо обновить, на маленькие.
Наивный LIMIT… OFFSET
Первая же идея — сделать «постраничный» перебор: «Давайте будем отбирать каждый раз следующую тысячу записей» с помощью увеличения OFFSET в каждом новом запросе:
UPDATE tbl T SET v = T.v + 1 FROM ( SELECT k , v FROM tbl WHERE k BETWEEN 'q' AND 'z' ORDER BY -- обеспечиваем как бы одинаковый порядок отбора k, v -- у нас же есть индекс! LIMIT $1 OFFSET $2 * $1 ) S WHERE (T.k, T.v) = (S.k, S.v);
Прежде чем тестировать производительность этого решения, восстановим датасет:
TRUNCATE TABLE tbl; INSERT INTO tbl TABLE _tbl;
Как мы видели в плане выше, обновиться у нас должны будут примерно 384K записей. Поэтому давайте сразу посмотрим, как будут выполняться обновления ближе к концу — в районе 300-й итерации по 1000 записей:
[посмотреть на explain.tensor.ru]
Ой… Обновление находящейся ближе к концу выборки всего 1K записей будет стоить нам практически столько же времени, как весь исходный вариант целиком!
Это не наш выбор. Он еще может как-то использоваться, если получается мало итераций и небольшие значения OFFSET. Потому что LIMIT X OFFSET Y для базы эквивалентно "вычитай/отбери/сформируй сначала X+Y записей, а потом первые Y выкинь в мусор", что при больших значениях Y выглядит трагично.
На самом деле, такой способ вообще нельзя применять! Мало того, что мы опираемся при отборе на обновляемые значения, так еще и рискуем пропустить часть записей, а другую часть обновить дважды, если блоки с одинаковыми ключами попадут на границу страниц:
В этом примере «зеленую» запись мы обновили дважды, а «красную» — ни разу. Просто потому, что при одинаковых значениях ключей сортировки порядок самих записей внутри такого блока не фиксирован.
Печальный ORDER BY… LIMIT
Давайте чуть модифицируем задачу — добавим новое поле, в которое и будем записывать наше значение v + 1:
ALTER TABLE tbl ADD COLUMN x integer;
Обратите внимание, что такая конструкция работает практически мгновенно, без переписывания всей таблицы. А вот если добавить DEFAULT-значение, то — только начиная с 11-й версии.
Уже наученные горьким опытом, давайте сразу создадим индекс, в котором будут оставаться только неинициализированные записи:
CREATE INDEX CONCURRENTLY ON tbl(k, v) WHERE x IS NULL;
CONCURRENTLY-индекс не блокирует работу с таблицей на чтение-запись, пока неспешно накатывается даже на огромный датасет.
Теперь идея звучит как «Давайте отбирать из этого индекса каждый раз только первую тысячу записей»:
UPDATE tbl T SET x = T.v + 1 FROM ( SELECT k, v FROM tbl WHERE k BETWEEN 'q' AND 'z' AND x IS NULL ORDER BY k, v LIMIT 1000 -- и никаких OFFSET! ) S WHERE (T.k, T.v) = (S.k, S.v) AND T.x IS NULL;
[посмотреть на explain.tensor.ru]
Уже много лучше — длительность каждой отдельной транзакции теперь у нас короче примерно в 6 раз.
Но давайте опять посмотрим, во что превратится план к 200-й итерации:
Update on tbl t (actual time=530.591..530.591 rows=0 loops=1) Buffers: shared hit=789337 read=1 dirtied=1
Время опять ухудшилось (правда, всего на 25%), и значение buffers выросло — но почему?
Дело в том, что MVCC в PostgreSQL оставляет в индексе «мертвые души» — версии уже обновленных записей, теперь под индекс уже не подходящих. То есть отбирая всего 1000 первых записей на 200-й итерации, мы все равно сканируем, хоть потом и отбрасываем, предыдущие 199K уже измененных версий кортежей.
Если итераций у нас требуется не несколько сотен, а несколько сотен тысяч, то деградация будет все заметнее с каждым следующим выполнением запроса.
UPDATE по сегментам
Собственно, а чего мы так привязались к этому значению «1000 записей»? Ведь у нас нет причин выбирать ровно по 1000 или какому-то другому конкретному числу. Мы всего-то хотели просто весь датасет «нарезать» на какие-то, необязательно равные, непересекающиеся сегменты — так давайте используем по прямому назначению имеющийся у нас индекс.
Для нашей задачи индексированная пара (k, v) отлично подходит. Построим запрос, чтобы он мог отталкиваться от последней обработанной пары:
WITH kv AS ( SELECT k, v FROM tbl WHERE (k, v) > ($1, $2) AND k BETWEEN 'q' AND 'z' AND x IS NULL ORDER BY k, v LIMIT 1 ) , upd AS ( UPDATE tbl T SET x = T.v + 1 WHERE (T.k, T.v) = (TABLE kv) AND T.x IS NULL RETURNING k, v ) TABLE upd LIMIT 1;
На первой итерации нам достаточно выставить параметры запроса в «нулевое» значение ('', 0), а для каждой следующей итерации брать результат предыдущего запроса.
[посмотреть на explain.tensor.ru]
Время транзакции/блокировок — меньше миллисекунды, деградации от количества итераций — нет, полное предварительное сканирование всех данных в таблице — не требуется. Отлично!
Собираем финальный вариант с dblink
DO $$ DECLARE k text = ''; v integer = 0; BEGIN PERFORM dblink_connect('dbname=' || current_database() || ' port=' || current_setting('port')); -- формируем PREPARED STATEMENT, чтобы каждая итерация шла побыстрее PERFORM dblink($q$ PREPARE _q(text, integer) AS WITH kv AS ( SELECT k, v FROM tbl WHERE (k, v) > ($1, $2) AND k BETWEEN 'q' AND 'z' AND x IS NULL ORDER BY k, v LIMIT 1 ) , upd AS ( UPDATE tbl T SET x = T.v + 1 WHERE (T.k, T.v) = (TABLE kv) AND T.x IS NULL RETURNING k, v ) TABLE upd LIMIT 1; $q$); -- итерируем, пока есть что LOOP SELECT * INTO k, v FROM dblink($p$EXECUTE _q('$p$ || k || $p$',$p$ || v || $p$)$p$) T(k text, v integer); RAISE NOTICE '(k,v) = (''%'',%)', k, v; -- выходим из цикла, если ничего больше нет EXIT WHEN (k, v) IS NULL; END LOOP; PERFORM dblink_disconnect(); END; $$ LANGUAGE plpgsql;
Дополнительное преимущество такого способа заключается в возможности прервать выполнение этого скрипта в любой момент, а потом возобновить с нужной точки.
Сложные вычисления в UPDATE
Отдельно упомяну ситуацию со сложным вычислением присваиваемого значения — когда надо что-то посчитать по связаным таблицам.
Время, затрачиваемое на вычисления, точно так же увеличивает длительность транзакции. Поэтому наиболее оптимальным вариантом будет вынести процесс вычисления этих значений за рамки UPDATE.
Например, мы хотим заполнить наше новое поле x количеством записей, которые имеют то же значение (k,v). Создадим «временную» таблицу, генерация которой не накладывает дополнительных блокировок:
CREATE TABLE tmp AS SELECT k, v, count(*) x FROM tbl GROUP BY 1, 2; CREATE INDEX ON tmp(k, v);
Теперь мы можем по описанной выше модели итерировать уже по этой таблице, обновляя целевую:
UPDATE tbl T SET x = S.x FROM tmp S WHERE (T.k, T.v) = (S.k, S.v) AND (S.k, S.v) = ($1, $2);
Как видим, никаких сложных вычислений уже не требуется.
Только не забудьте потом удалить вспомогательную таблицу.

