Данная статья написана для того, чтобы помочь выбрать для себя подходящее решение и понять отличия между такими SDS как Gluster, Ceph и Vstorage (Virtuozzo).
В тексте используются ссылки на статьи с более детальным раскрытием тех или иных проблем, поэтому описания будут максимально краткими с использованием ключевых моментов без лишней воды и вводной информации, которую вы сможете при желании самостоятельно добыть на просторах интернета.
На самом деле конечно затронутые темы требуют тоны текста, но в современном мире все больше и больше люди не любят много читать))), поэтому можно бегло прочесть и сделать выбор, а если что непонятно пройтись по ссылкам или погуглить непонятные слова))), а эта статья как прозрачная обертка для этих глубоких тем, показывающая начинку – главные ключевые моменты каждого решения.
Начнем с Gluster, который активно используется у производителей гиперконвергентных платформ с SDS на базе open source для виртуальных сред и его можно найти на сайте RedHat в разделе storage, где предлагается выбрать из двух вариантов SDS: Gluster или Ceph.
Gluster состоит из стека трансляторов – службы которые выполняют все работы по распределению файлов и т.д. Brick – служба которая обслуживает один диск, Volume – том(пул) – который объединяет эти brick’и. Далее идет служба распределения файлов по группам за счет функции DHT(distributed hash table). Службу Sharding включать в описание не будем так как в ниже выложенных ссылках будет описание проблем связанных с ней.
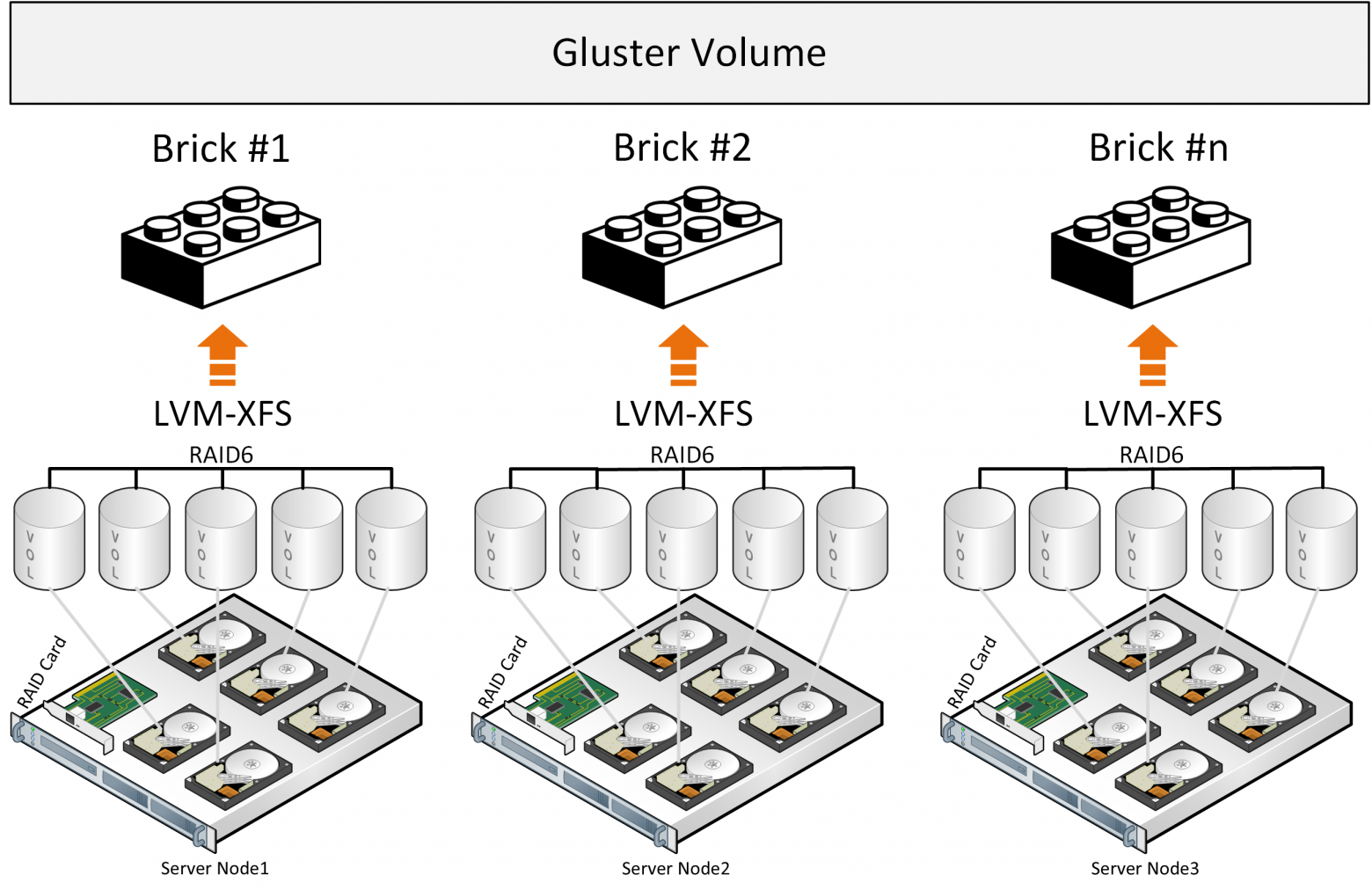
При записи файл целиком ложится в brick и его копия параллельно пишется на brick на втором сервере. Далее второй файл уже будет записываться в вторую группу из двух briсk(или более) на разных серверах.
Если файлы примерно одного размера и том будет состоять только из одной группы, то все нормально, но вот при других условиях возникнут из описаний следующие проблемы:
Из официального описания архитектуры также невольно приходит понимание, что gluster работает как файловое хранилище поверх классического аппаратного RAID. Были попытки разработки нарезать(Sharding) файлы на блоки, но все это дополнение, которое накладывает потери производительности к уже существующему архитектурному подходу, плюс использование таких свободно распространяемых компонентов с ограничением в производительности как Fuse. Нет сервисов метаданных, что ограничивает по возможностям производительности и отказоустойчивости хранилище при распределении файлов на блоки. Более хорошие показатели производительности можно наблюдать при конфигурации “Distributed Replicated” и количество нод должно быть не менее 6 для организации надежной реплики 3 с оптимальным распределением нагрузки.
Эти выводы также связаны с описанием опыта использования Gluster и при сравнении с Ceph, а также есть описание опыта к приходу понимания этой более производительной и более надежной конфигурации “Replicated Distributed”.
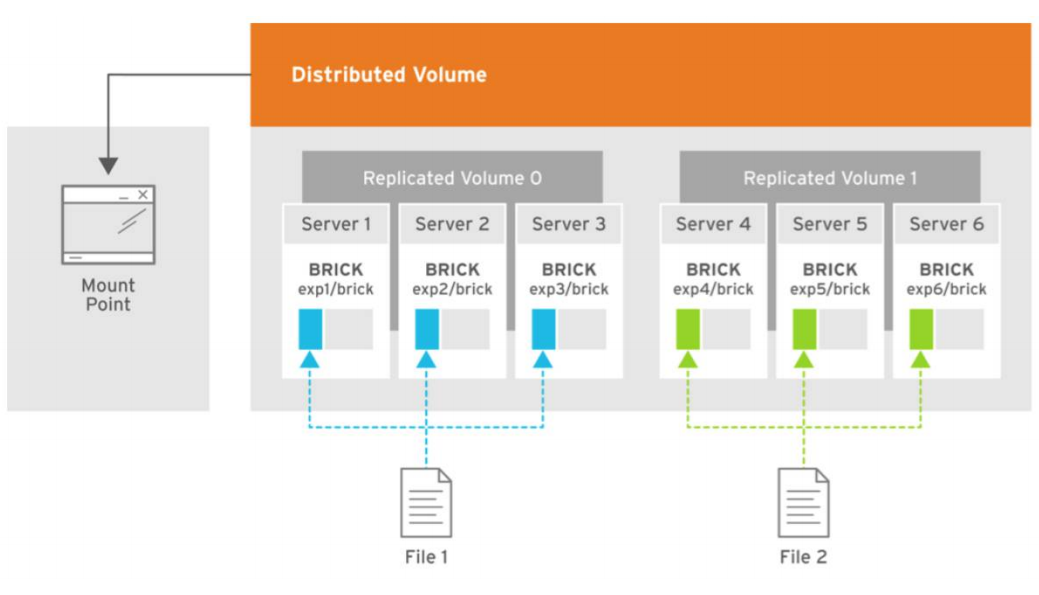
В картинке показано распределение нагрузки при записи двух файлов, где копии первого файла раскладываются по трем первым серверам, которые объединены в volume 0 группу и три копии второго файла ложатся на вторую группу volume1 из трех серверов. Каждый сервер имеет один диск.
Общий вывод такой, что использовать можно Gluster, но с пониманием того, что в производительности и отказоустойчивости будут ограничения, которые создают трудности при определенных условиях гиперконвергентного решения, где ресурсы нужны еще и для вычислительных нагрузок виртуальных сред.
Есть некоторые также показатели производительности Gluster, которых можно добиться при определенных условиях ограничиваясь в отказоустойчивости.
Теперь рассмотрим Сeph из описаний архитектуры, которые мне удалось найти. Также есть сравнение между Glusterfs и Ceph, где можно сразу понять что Ceph желательно разворачивать на отдельных серверах, так как его сервисам необходимы все ресурсы железа при нагрузках.
Архитектура Сeph более сложнее чем Gluster и есть такие сервисы как службы метаданных, но весь стек компонентов довольно непрост и не очень гибок для использования его в решении с виртуализацией. Данные укладываются по блокам, что выглядит более производительным, но есть в иерархии всех служб(компонентов), потери и latency при определенных нагрузках и аварийных условиях в пример следующая статья.
Из описания архитектуры сердцем выступает CRUSH, благодаря которому выбирается место для размещения данных. Далее идет PG — это наиболее сложная абстракция (логическая группа) для понимания. PG нужны для того, чтобы CRUSH был более эффективным. Основное предназначение PG — группировка объектов для снижения ресурс-потребления, повышения производительности и масштабируемости. Адресация объектов на прямую, по отдельности, без объединения их в PG была бы очень затратной. OSD – это сервис для каждого отдельного диска.


Кластер может иметь один или много пулов данных разного назначения и с разными настройками. Пулы делятся на плейсмент-группы. В плейсмент-группах хранятся объекты, к которым обращаются клиенты. На этом логический уровень заканчивается, и начинается физический, потому как за каждой плейсмент-группой закреплен один главный диск и несколько дисков-реплик (сколько именно зависит от фактора репликации пула). Другими словами, на логическом уровне объект хранится в конкретной плейсмент-группе, а на физическом — на дисках, которые за ней закреплены. При этом диски физически могут находиться на разных узлах или даже в разных датацентрах.
В этой схеме плейсмент-группы выглядят как необходимый уровень для гибкости всего решения, но в тоже время и как лишнее звено в этой цепочки, что невольно наводит мысли о потери производительности. Например при записи данных системе необходимо разбивать их на эти группы и потом на физическом уровне на главный диск и на диски для реплик. То есть Хеш функция работает при поиске и вставке объекта, но есть побочный эффект – это очень большие затраты и ограничения на перестройку хэша (при добавлении, удалении диска). Ещё одна проблема хэша – это чётко прибитое расположение данных, которые нельзя менять. То есть если как-то диск испытывает повышенную нагрузку, то система не имеет возможности не писать на него (выбрав другой диск), хеш функция обязывает располагать данные по правилу, независимо от того насколько диску плохо, поэтому Ceph ест много памяти при перестроении PG в случае self-healing или увеличения хранилища. Вывод, что Ceph работает хорошо(хоть и медленно), но только когда нет масштабирования, аварийных ситуаций и обновления.
Есть конечно варианты повышения производительности за счет кеширования и кеш-тиринга, но при этом необходимо хорошее железо и все равно будут потери. Но в целом Ceph выглядит заманчивее чем Gluster для продуктива. Также при использовании этих продуктов необходимо учитывать немаловажный фактор – это высокий уровень компетенций, опыта и профессионализма с большим акцентом на linux, так как очень важно все правильно развернуть, настроить и поддерживать, что накладывает еще больше ответственности и нагрузки на администратора.
Еще более интереснее выглядит архитектура у Virtuozzo storage(Vstorage), которую можно использовать совместно с гипервизором на тех же узлах, на том же железе, но очень важно правильно все сконфигурировать, чтобы добиться хорошей производительности. То есть развернув такой продукт с коробки на какой попало конфигурации без учета рекомендаций в соответствии с архитектурой будет очень легко, но не производительно.
Что же может сосуществовать для хранения рядом с сервисами гипервизора kvm-qemu, а это всего лишь несколько служб, где найдена компактная оптимальная иерархия компонентов: сервис клиента монтируемый через FUSE(модифицированный, не open source), служба метаданных MDS (Metadata service), служба блоков данных Chunk service, которая на физическом уровне равна одному диску и на этом все. По скорости конечно оптимально использовать отказоустойчивую схему в две реплики, но если задействовать кеширование и журналы на диски SSD, то помехоустойчивое кодирование (erase coding или raid6) можно прилично разогнать на гибридной схеме или даже лучше на all flash. С EC(erase coding) некоторый минус: при изменении одного блока данных необходимо пересчитать суммы четности. Для обхода потерь на эту операцию Сeph пишет в EC отложено и проблемы с производительностью могут произойти при определенном запросе, когда например понадобятся считать все блоки, а в случае с Virtuozzo Storage запись измененных блоков осуществляется используя подход “log-structured file system”, что минимизирует затраты на вычисления четности. Чтобы прикинуть приблизительно варианты с ускорением работы при EC и без, есть калькулятор. – цифры можно получить приблизительные зависит от коэффициента точности производителя оборудования, но результат вычислений хорошо помогает запланировать конфигурацию.
Простая схема компонентов хранения это не значит, что эти компоненты не поглощают ресурсы железа, но если подсчитать все расходы заранее, то можно рассчитывать на совместную работу рядом с гипервизором.
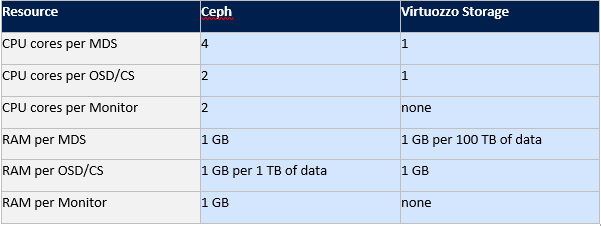
Есть схема сравнения потребления ресурсов железа службами Сeph и Virtuozzo storage.
Если ранее сравнивать Gluster и Ceph можно было по старым статьям, используя самые важные строки из них, то с Virtuozzo сложнее. Статей по этому продукту не так много и информацию можно черпать только с документации на английском или на русском если рассматривать Vstorage в качестве хранилища используемого в некоторых гиперконвергентных решениях в таких компаниях как Акронис.
Попробую помочь с описанием этой архитектуры поэтому текста будет чуть больше, но чтобы самому разобраться в документации необходимо много времени, а имеющуюся документацию можно использовать только как справочник с помощью пересмотра оглавления или поиск по ключевому слову.
Рассмотрим процесс записи в гибридной конфигурации железа с выше описанными компонентами: запись начинает идти на тот узел с которого ее инициировал клиент(служба точки монтирования FUSE), но компонент мастер службы метаданных(MDS) конечно направит клиента на прямую к нужному чанк сервису(службе хранения блоков CS), то есть MDS не участвует в процессе записи, а просто направляет на необходимый чанк сервис. В общем можно привести аналогию записи с разливом воды по бочкам. Каждая бочка, это блок данных в 256МБ.
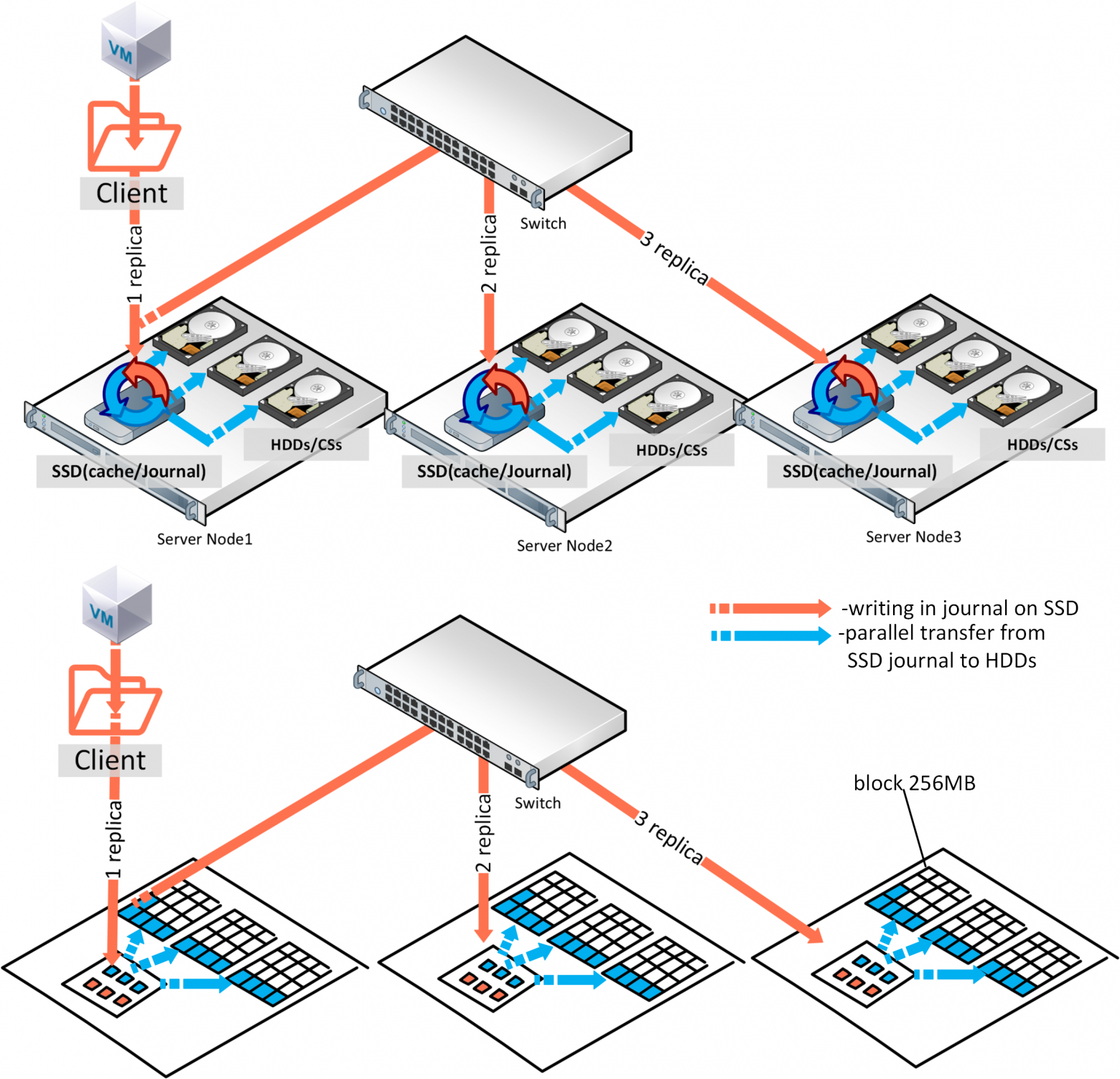
То есть один диск, это какое-то количество таких бочек, то есть объем диска разделить на 256МБ. Каждая копия разливается на один узел, вторая почти параллельно уже на другой узел и т.д… Если у нас три реплики и есть SSD диски, для кеша (под чтение и журналы записи), то подтверждение записи будет происходить после записи журнала в SSD, а параллельный сброс с SSD, будет продолжаться на HDD, как бы в фоновом режиме. В случае трех реплик коммит записи будет после подтверждения от SSD третьего узла. Может показаться, что сумму скорости записи трех SSD можно поделить на три и мы получим скорость записи одной реплики, но запись копий идет параллельно и скорость Latency сети обычно выше, чем у SSD, и по сути производительность записи будет зависеть от сети. В связи с этим, чтобы увидеть реальные IOPS необходимо правильно нагрузить весь Vstorage по методике, то есть тестировать реальную нагрузку, а не память и кэш, где необходимо учесть правильный размер блока данных, количество потоков и т.д.
Выше упомянутый журнал записи на SSD, работает так, что как только в него попадают данные, то сразу считываются службой и пишутся на HDD. Служб метаданных (MDS) несколько на кластер и их количество определяется кворумом, который работает по алгоритму Paxos. С точки зрения клиента точка монтирования FUSE, это папка кластерного хранилища, которая одновременно видна всем нодам кластера, каждая нода имеет смонтированного клиента по такому принципу поэтому каждому узлу доступно это хранилище.
Для производительности любого из выше описанного подхода очень важно, на этапе планирования и развертывания, правильно настроить сеть, где будет балансировка за счет агрегации и правильно подобранная пропускная способность сетевого канала. В агрегации важно правильно подобрать режим хеширования и размеры фреймов. Есть также очень сильное отличие от выше описанных SDS, это fuse с технологией fast path в Virtuozzo Storage. Который по мимо модернизированного fuse в отличие от остальных open source решений, значительно прибавляет IOPS-ов и позволяет не ограничиваться горизонтальным или вертикальным масштабированием. В общем по сравнению с выше описанными архитектурами эта выглядит более мощнее, но за такое удовольствие конечно же необходимо покупать лицензии в отличии от Сeph и Gluster.
Подводя итоги можно подчеркнуть топом из трех: первое место по производительности и надежности архитектуры занимает Virtuozzo Storage, второе Ceph и третье Gluster.
Критерии, по которому выбран Virtuozzo Storage: это оптимальный набор компонентов архитектуры, модернизированный под этот подход Fuse с fast path, гибкий набор конфигурации железа, меньшее потребление ресурсов и возможность совместного использования с compute(вычислениями/виртуализации), то есть полностью подходит для гиперконвергентного решения, в составе которого он и идет. Второе место Ceph, потому что это более производительная архитектура перед Gluster, за счет оперирования блоками, а также более гибкими сценариями и возможностью работы в более масштабных кластерах.
В планах есть желание написать сравнение между vSAN, Space Direct Storage, Vstorage и Nutanix Storage, тестирование Vstorage на оборудовании HPE, Huawei, а также сценарии интеграции Vstorage с внешними аппаратными СХД, поэтому если статья вам понравилась, то неплохо было бы получить от вас отзывы, которые могли бы усилить мотивацию на новые статьи с учетом ваших замечаний и пожеланий.
В тексте используются ссылки на статьи с более детальным раскрытием тех или иных проблем, поэтому описания будут максимально краткими с использованием ключевых моментов без лишней воды и вводной информации, которую вы сможете при желании самостоятельно добыть на просторах интернета.
На самом деле конечно затронутые темы требуют тоны текста, но в современном мире все больше и больше люди не любят много читать))), поэтому можно бегло прочесть и сделать выбор, а если что непонятно пройтись по ссылкам или погуглить непонятные слова))), а эта статья как прозрачная обертка для этих глубоких тем, показывающая начинку – главные ключевые моменты каждого решения.
Gluster
Начнем с Gluster, который активно используется у производителей гиперконвергентных платформ с SDS на базе open source для виртуальных сред и его можно найти на сайте RedHat в разделе storage, где предлагается выбрать из двух вариантов SDS: Gluster или Ceph.
Gluster состоит из стека трансляторов – службы которые выполняют все работы по распределению файлов и т.д. Brick – служба которая обслуживает один диск, Volume – том(пул) – который объединяет эти brick’и. Далее идет служба распределения файлов по группам за счет функции DHT(distributed hash table). Службу Sharding включать в описание не будем так как в ниже выложенных ссылках будет описание проблем связанных с ней.
При записи файл целиком ложится в brick и его копия параллельно пишется на brick на втором сервере. Далее второй файл уже будет записываться в вторую группу из двух briсk(или более) на разных серверах.
Если файлы примерно одного размера и том будет состоять только из одной группы, то все нормально, но вот при других условиях возникнут из описаний следующие проблемы:
- место в группах утилизируется неравномерно, это зависит от размеров файлов и если в группе недостаточно места для записи файла — вы получите ошибку, файл не будет записан и не будет перераспределен в другую группу;
- при записи одного файла IO идет только на одну группу, остальные простаивают;
- нельзя получить IO всего тома при записи одного файла;
- и общая концепция выглядит менее производительнее за счет отсутствия распределения данных по блокам, где проще осуществить балансировку и решить проблему равномерного распределения, а не как сейчас файл ложится в брик целиком.
Из официального описания архитектуры также невольно приходит понимание, что gluster работает как файловое хранилище поверх классического аппаратного RAID. Были попытки разработки нарезать(Sharding) файлы на блоки, но все это дополнение, которое накладывает потери производительности к уже существующему архитектурному подходу, плюс использование таких свободно распространяемых компонентов с ограничением в производительности как Fuse. Нет сервисов метаданных, что ограничивает по возможностям производительности и отказоустойчивости хранилище при распределении файлов на блоки. Более хорошие показатели производительности можно наблюдать при конфигурации “Distributed Replicated” и количество нод должно быть не менее 6 для организации надежной реплики 3 с оптимальным распределением нагрузки.
Эти выводы также связаны с описанием опыта использования Gluster и при сравнении с Ceph, а также есть описание опыта к приходу понимания этой более производительной и более надежной конфигурации “Replicated Distributed”.
В картинке показано распределение нагрузки при записи двух файлов, где копии первого файла раскладываются по трем первым серверам, которые объединены в volume 0 группу и три копии второго файла ложатся на вторую группу volume1 из трех серверов. Каждый сервер имеет один диск.
Общий вывод такой, что использовать можно Gluster, но с пониманием того, что в производительности и отказоустойчивости будут ограничения, которые создают трудности при определенных условиях гиперконвергентного решения, где ресурсы нужны еще и для вычислительных нагрузок виртуальных сред.
Есть некоторые также показатели производительности Gluster, которых можно добиться при определенных условиях ограничиваясь в отказоустойчивости.
Ceph
Теперь рассмотрим Сeph из описаний архитектуры, которые мне удалось найти. Также есть сравнение между Glusterfs и Ceph, где можно сразу понять что Ceph желательно разворачивать на отдельных серверах, так как его сервисам необходимы все ресурсы железа при нагрузках.
Архитектура Сeph более сложнее чем Gluster и есть такие сервисы как службы метаданных, но весь стек компонентов довольно непрост и не очень гибок для использования его в решении с виртуализацией. Данные укладываются по блокам, что выглядит более производительным, но есть в иерархии всех служб(компонентов), потери и latency при определенных нагрузках и аварийных условиях в пример следующая статья.
Из описания архитектуры сердцем выступает CRUSH, благодаря которому выбирается место для размещения данных. Далее идет PG — это наиболее сложная абстракция (логическая группа) для понимания. PG нужны для того, чтобы CRUSH был более эффективным. Основное предназначение PG — группировка объектов для снижения ресурс-потребления, повышения производительности и масштабируемости. Адресация объектов на прямую, по отдельности, без объединения их в PG была бы очень затратной. OSD – это сервис для каждого отдельного диска.
Кластер может иметь один или много пулов данных разного назначения и с разными настройками. Пулы делятся на плейсмент-группы. В плейсмент-группах хранятся объекты, к которым обращаются клиенты. На этом логический уровень заканчивается, и начинается физический, потому как за каждой плейсмент-группой закреплен один главный диск и несколько дисков-реплик (сколько именно зависит от фактора репликации пула). Другими словами, на логическом уровне объект хранится в конкретной плейсмент-группе, а на физическом — на дисках, которые за ней закреплены. При этом диски физически могут находиться на разных узлах или даже в разных датацентрах.
В этой схеме плейсмент-группы выглядят как необходимый уровень для гибкости всего решения, но в тоже время и как лишнее звено в этой цепочки, что невольно наводит мысли о потери производительности. Например при записи данных системе необходимо разбивать их на эти группы и потом на физическом уровне на главный диск и на диски для реплик. То есть Хеш функция работает при поиске и вставке объекта, но есть побочный эффект – это очень большие затраты и ограничения на перестройку хэша (при добавлении, удалении диска). Ещё одна проблема хэша – это чётко прибитое расположение данных, которые нельзя менять. То есть если как-то диск испытывает повышенную нагрузку, то система не имеет возможности не писать на него (выбрав другой диск), хеш функция обязывает располагать данные по правилу, независимо от того насколько диску плохо, поэтому Ceph ест много памяти при перестроении PG в случае self-healing или увеличения хранилища. Вывод, что Ceph работает хорошо(хоть и медленно), но только когда нет масштабирования, аварийных ситуаций и обновления.
Есть конечно варианты повышения производительности за счет кеширования и кеш-тиринга, но при этом необходимо хорошее железо и все равно будут потери. Но в целом Ceph выглядит заманчивее чем Gluster для продуктива. Также при использовании этих продуктов необходимо учитывать немаловажный фактор – это высокий уровень компетенций, опыта и профессионализма с большим акцентом на linux, так как очень важно все правильно развернуть, настроить и поддерживать, что накладывает еще больше ответственности и нагрузки на администратора.
Vstorage
Еще более интереснее выглядит архитектура у Virtuozzo storage(Vstorage), которую можно использовать совместно с гипервизором на тех же узлах, на том же железе, но очень важно правильно все сконфигурировать, чтобы добиться хорошей производительности. То есть развернув такой продукт с коробки на какой попало конфигурации без учета рекомендаций в соответствии с архитектурой будет очень легко, но не производительно.
Что же может сосуществовать для хранения рядом с сервисами гипервизора kvm-qemu, а это всего лишь несколько служб, где найдена компактная оптимальная иерархия компонентов: сервис клиента монтируемый через FUSE(модифицированный, не open source), служба метаданных MDS (Metadata service), служба блоков данных Chunk service, которая на физическом уровне равна одному диску и на этом все. По скорости конечно оптимально использовать отказоустойчивую схему в две реплики, но если задействовать кеширование и журналы на диски SSD, то помехоустойчивое кодирование (erase coding или raid6) можно прилично разогнать на гибридной схеме или даже лучше на all flash. С EC(erase coding) некоторый минус: при изменении одного блока данных необходимо пересчитать суммы четности. Для обхода потерь на эту операцию Сeph пишет в EC отложено и проблемы с производительностью могут произойти при определенном запросе, когда например понадобятся считать все блоки, а в случае с Virtuozzo Storage запись измененных блоков осуществляется используя подход “log-structured file system”, что минимизирует затраты на вычисления четности. Чтобы прикинуть приблизительно варианты с ускорением работы при EC и без, есть калькулятор. – цифры можно получить приблизительные зависит от коэффициента точности производителя оборудования, но результат вычислений хорошо помогает запланировать конфигурацию.
Простая схема компонентов хранения это не значит, что эти компоненты не поглощают ресурсы железа, но если подсчитать все расходы заранее, то можно рассчитывать на совместную работу рядом с гипервизором.
Есть схема сравнения потребления ресурсов железа службами Сeph и Virtuozzo storage.
Если ранее сравнивать Gluster и Ceph можно было по старым статьям, используя самые важные строки из них, то с Virtuozzo сложнее. Статей по этому продукту не так много и информацию можно черпать только с документации на английском или на русском если рассматривать Vstorage в качестве хранилища используемого в некоторых гиперконвергентных решениях в таких компаниях как Акронис.
Попробую помочь с описанием этой архитектуры поэтому текста будет чуть больше, но чтобы самому разобраться в документации необходимо много времени, а имеющуюся документацию можно использовать только как справочник с помощью пересмотра оглавления или поиск по ключевому слову.
Рассмотрим процесс записи в гибридной конфигурации железа с выше описанными компонентами: запись начинает идти на тот узел с которого ее инициировал клиент(служба точки монтирования FUSE), но компонент мастер службы метаданных(MDS) конечно направит клиента на прямую к нужному чанк сервису(службе хранения блоков CS), то есть MDS не участвует в процессе записи, а просто направляет на необходимый чанк сервис. В общем можно привести аналогию записи с разливом воды по бочкам. Каждая бочка, это блок данных в 256МБ.
То есть один диск, это какое-то количество таких бочек, то есть объем диска разделить на 256МБ. Каждая копия разливается на один узел, вторая почти параллельно уже на другой узел и т.д… Если у нас три реплики и есть SSD диски, для кеша (под чтение и журналы записи), то подтверждение записи будет происходить после записи журнала в SSD, а параллельный сброс с SSD, будет продолжаться на HDD, как бы в фоновом режиме. В случае трех реплик коммит записи будет после подтверждения от SSD третьего узла. Может показаться, что сумму скорости записи трех SSD можно поделить на три и мы получим скорость записи одной реплики, но запись копий идет параллельно и скорость Latency сети обычно выше, чем у SSD, и по сути производительность записи будет зависеть от сети. В связи с этим, чтобы увидеть реальные IOPS необходимо правильно нагрузить весь Vstorage по методике, то есть тестировать реальную нагрузку, а не память и кэш, где необходимо учесть правильный размер блока данных, количество потоков и т.д.
Выше упомянутый журнал записи на SSD, работает так, что как только в него попадают данные, то сразу считываются службой и пишутся на HDD. Служб метаданных (MDS) несколько на кластер и их количество определяется кворумом, который работает по алгоритму Paxos. С точки зрения клиента точка монтирования FUSE, это папка кластерного хранилища, которая одновременно видна всем нодам кластера, каждая нода имеет смонтированного клиента по такому принципу поэтому каждому узлу доступно это хранилище.
Для производительности любого из выше описанного подхода очень важно, на этапе планирования и развертывания, правильно настроить сеть, где будет балансировка за счет агрегации и правильно подобранная пропускная способность сетевого канала. В агрегации важно правильно подобрать режим хеширования и размеры фреймов. Есть также очень сильное отличие от выше описанных SDS, это fuse с технологией fast path в Virtuozzo Storage. Который по мимо модернизированного fuse в отличие от остальных open source решений, значительно прибавляет IOPS-ов и позволяет не ограничиваться горизонтальным или вертикальным масштабированием. В общем по сравнению с выше описанными архитектурами эта выглядит более мощнее, но за такое удовольствие конечно же необходимо покупать лицензии в отличии от Сeph и Gluster.
Подводя итоги можно подчеркнуть топом из трех: первое место по производительности и надежности архитектуры занимает Virtuozzo Storage, второе Ceph и третье Gluster.
Критерии, по которому выбран Virtuozzo Storage: это оптимальный набор компонентов архитектуры, модернизированный под этот подход Fuse с fast path, гибкий набор конфигурации железа, меньшее потребление ресурсов и возможность совместного использования с compute(вычислениями/виртуализации), то есть полностью подходит для гиперконвергентного решения, в составе которого он и идет. Второе место Ceph, потому что это более производительная архитектура перед Gluster, за счет оперирования блоками, а также более гибкими сценариями и возможностью работы в более масштабных кластерах.
В планах есть желание написать сравнение между vSAN, Space Direct Storage, Vstorage и Nutanix Storage, тестирование Vstorage на оборудовании HPE, Huawei, а также сценарии интеграции Vstorage с внешними аппаратными СХД, поэтому если статья вам понравилась, то неплохо было бы получить от вас отзывы, которые могли бы усилить мотивацию на новые статьи с учетом ваших замечаний и пожеланий.

