Здравствуйте, сегодня хотел бы рассказать про мой опыт анализа акций сбербанка. Порой они показывают немного разную динамику — мне стало интересно проанализировать движение их котировок.
В данном примере мы будем скачивать котировки с сайта Финама. Ссылка для скачивания обычного Сбербанка.
Для операций со столбцами буду использовать pandas, для визуализации matplotlib.
Импортируем:
Чтобы таблицы не сокращались, необходимо убрать ограничения:
(указываем разделитель, где находятся название столбцов, какой столбец будет индексом, включаем парсинг дат).
Также укажем сортировку:
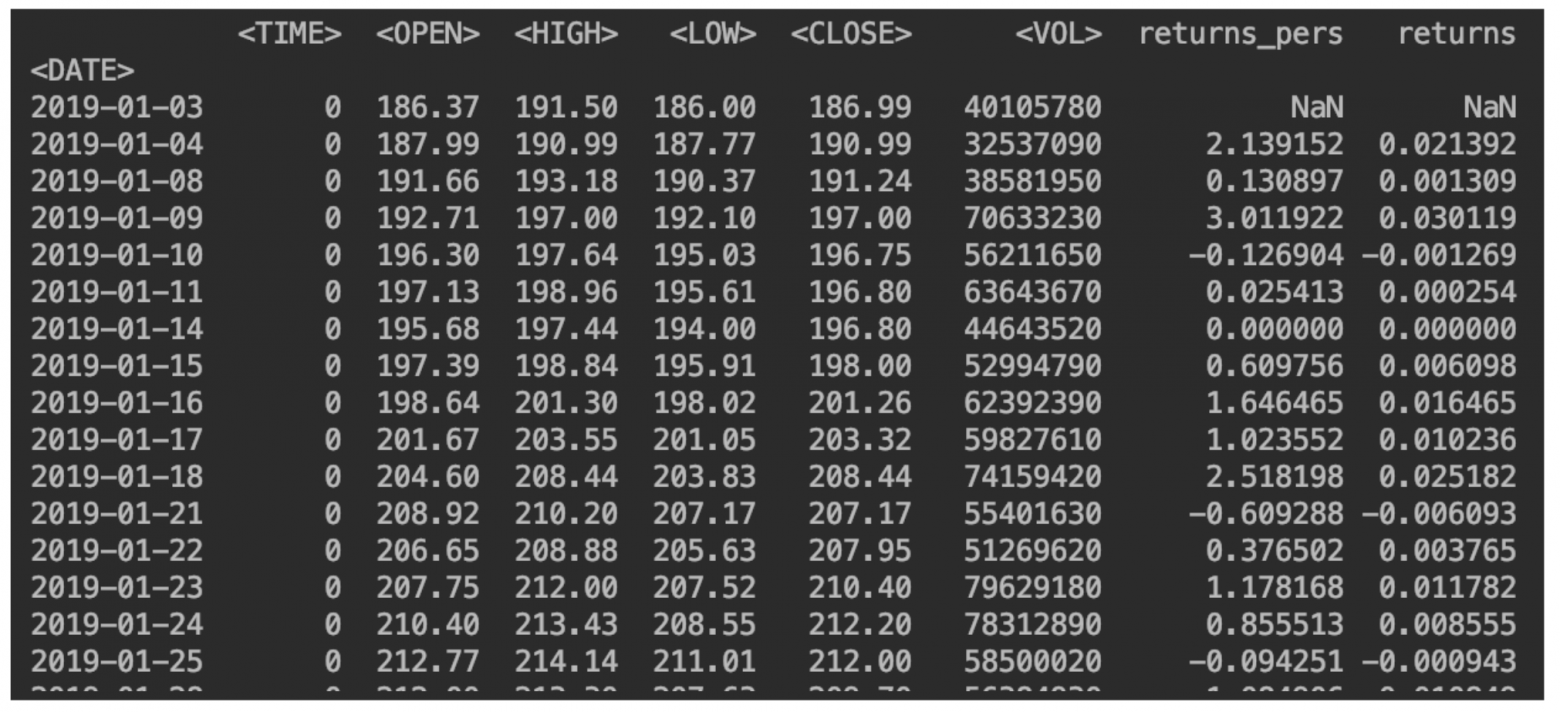
Отобразим наши данные:

Добавляем столбец с изменением цены
Так можно выводить именно процент:
Делаем это точно таким же образом

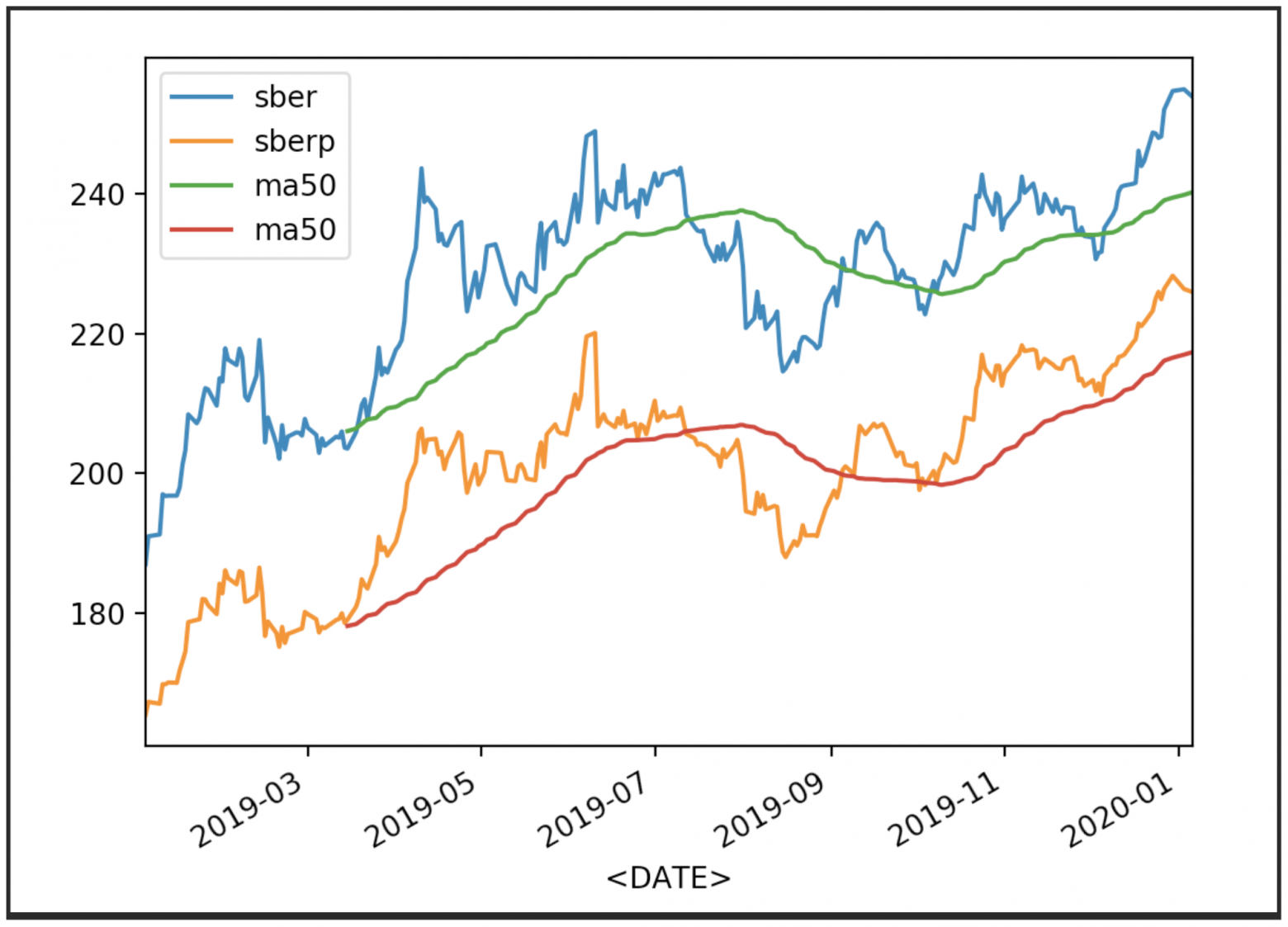
Теперь отобразим котировки с их средними (MA 50):
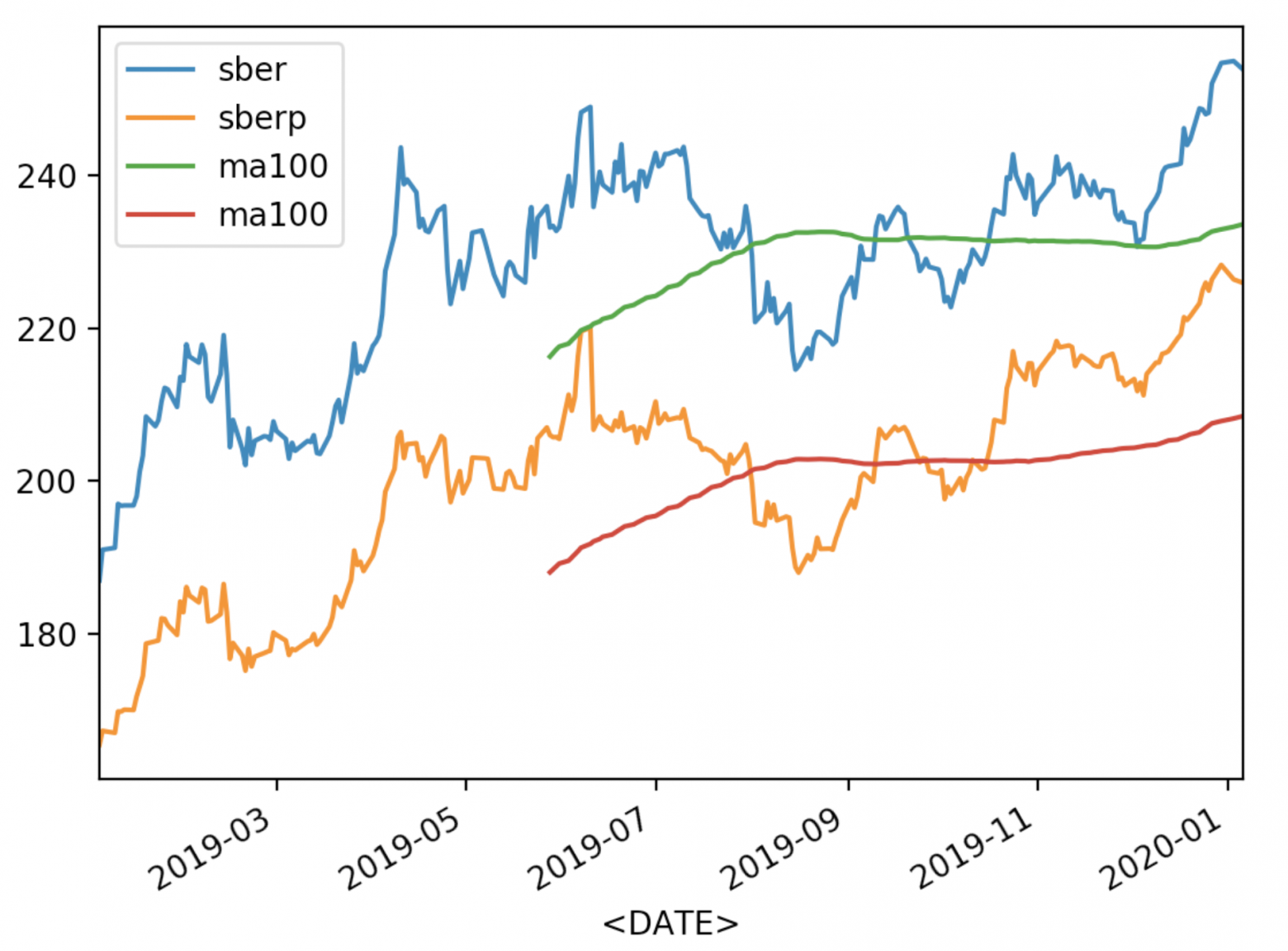
Можно отобразить и другие средние
Теперь выведем оборот по акциям:
Добавим также название оси У
и размер холста

Теперь подробнее посмотрим на корреляцию. в этом нам поможет матричный график
Создадим новую таблицу с колонками по обеим акциям и зададим им названия

Теперь импортируем нужный график
И выведем его:
Следует уточнить, что нам нужно добавить прозрачность (alpha=0,2), чтобы видеть наложение точек
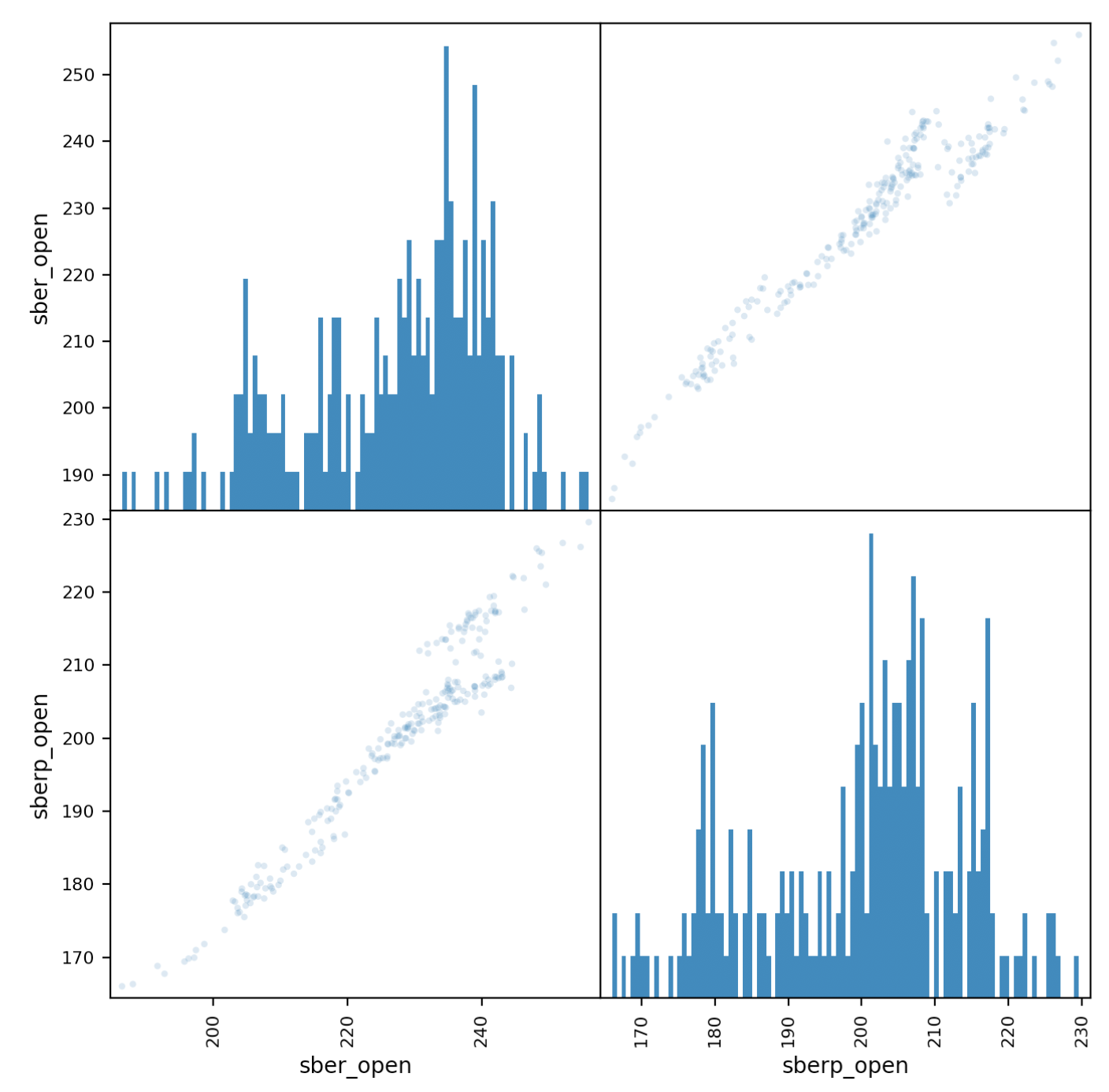
Если точки “идут” по диагонали, наблюдается корреляция.

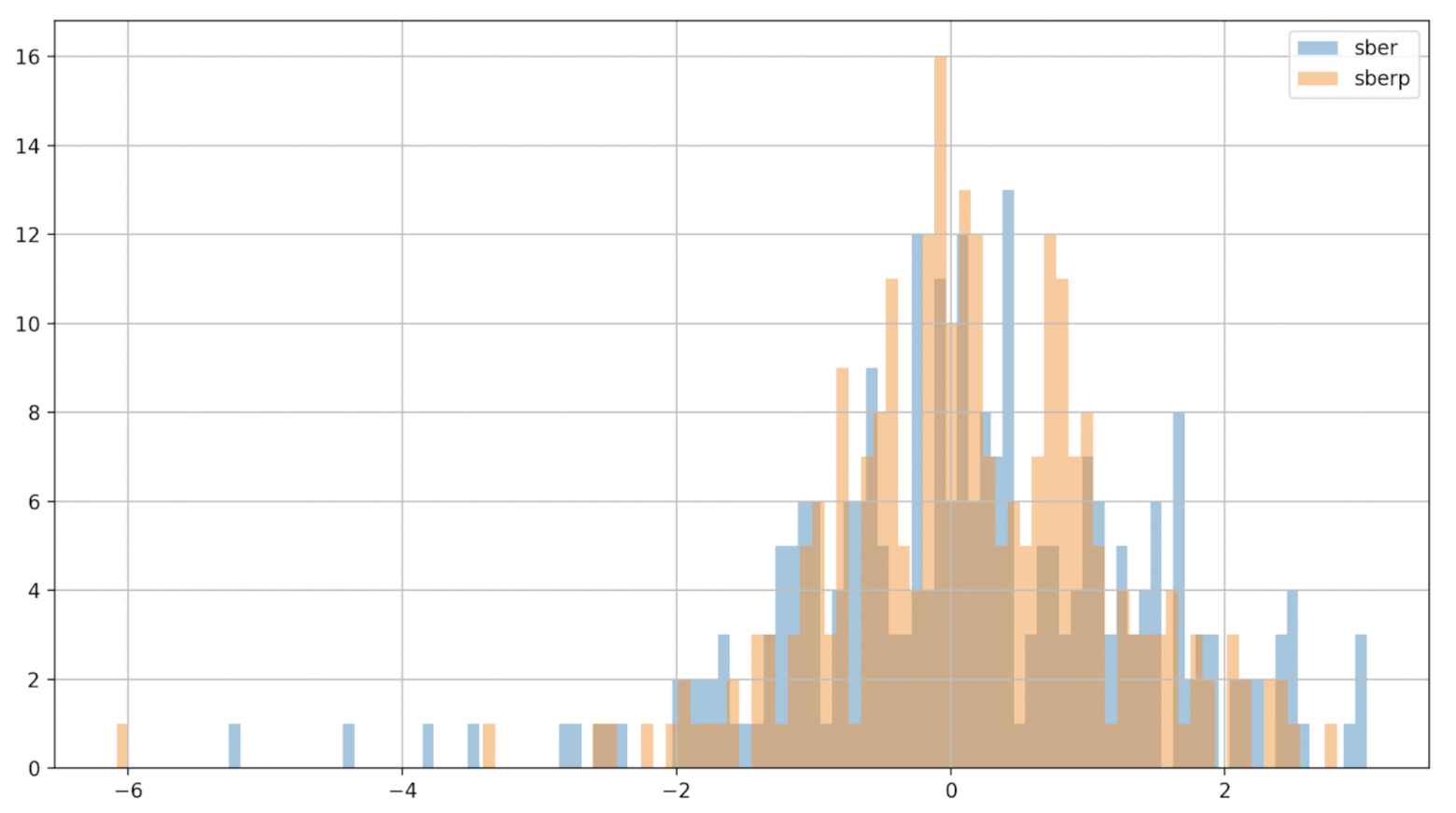
Для лучшего понимания Отобразим волатильность на другом графике — гистограмме
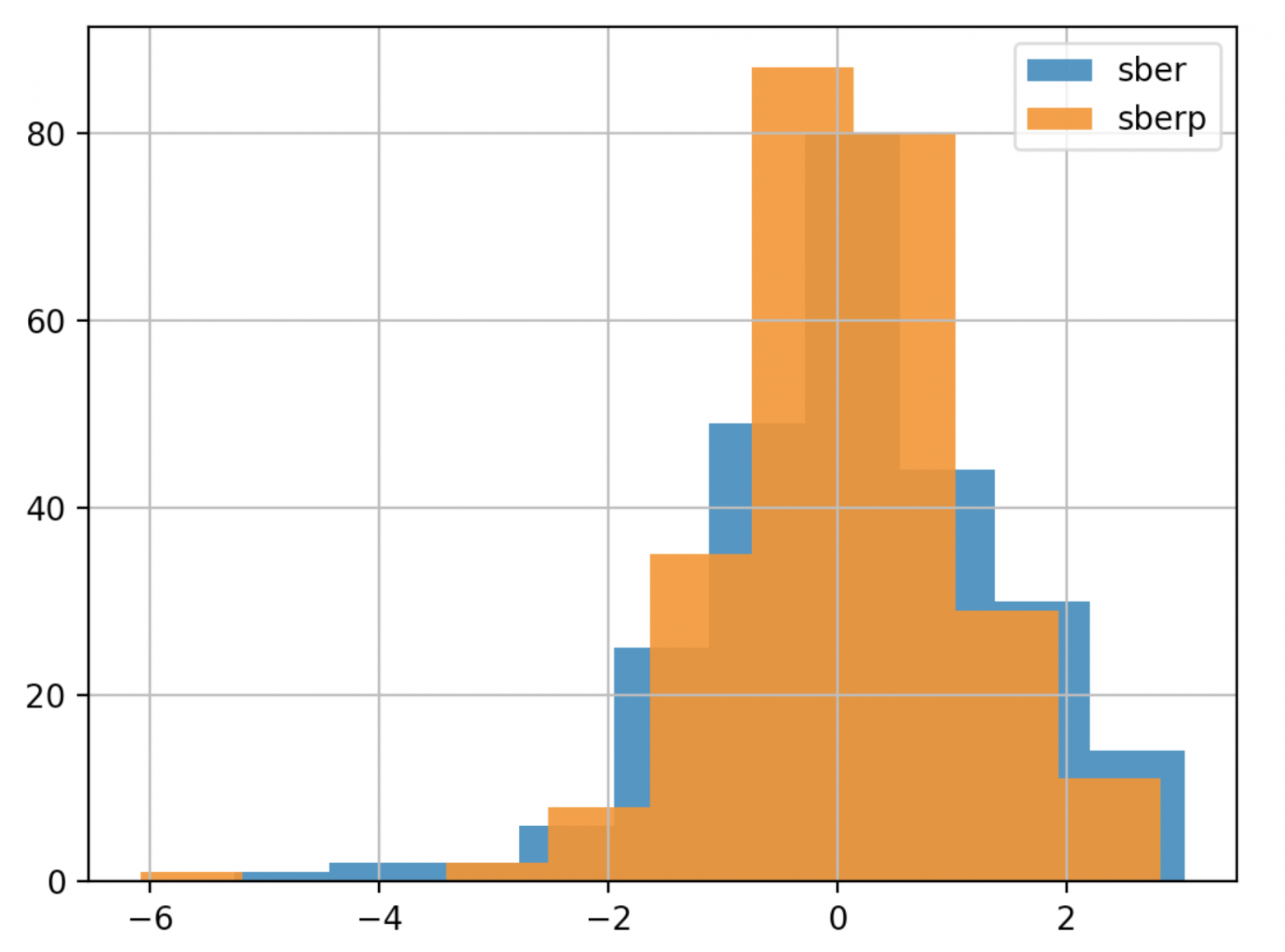
Чтобы сделать вывод быстрее, можно упростить график (сделаем график менее подробным и менее прозрачным):
Теперь выведем изменение стоимости акций в процентах.
Для этого введем столбец с накопленным доходом.
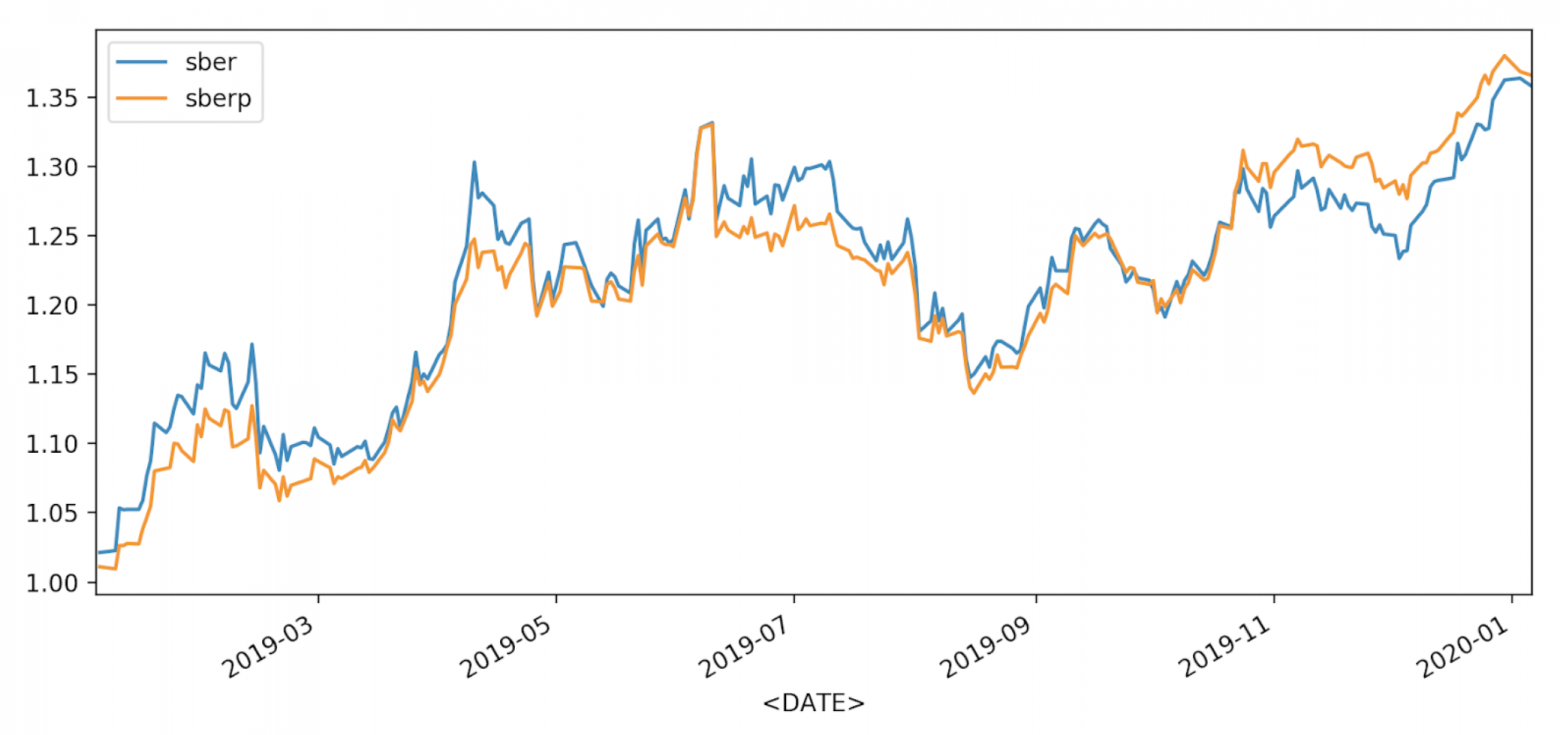
На графиках мы можем увидеть временные промежутки, когда одна из акций недооценена или переоценена относительно другой. В текущих обстоятельствах (при прочих равных, прошу заметить) нам это поможет выбрать акцию для усреднения при падении капитализации Сбербанка.
В данном примере мы будем скачивать котировки с сайта Финама. Ссылка для скачивания обычного Сбербанка.
Для операций со столбцами буду использовать pandas, для визуализации matplotlib.
Импортируем:
import pandas as pd import matplotlib.pyplot as plt
Чтобы таблицы не сокращались, необходимо убрать ограничения:
pd.set_option('display.max_columns', None) pd.set_option('display.expand_frame_repr', False) pd.set_option('max_colwidth', 80) pd.set_option('max_rows', 6000)
Читаем данные по акции
df = pd.read_csv("SBER_190101_200105.csv",sep=';', header=0, index_col='<DATE>', parse_dates=True)
(указываем разделитель, где находятся название столбцов, какой столбец будет индексом, включаем парсинг дат).
Также укажем сортировку:
df = df.sort_values(by='<DATE>')
Отобразим наши данные:
print(df)
Добавляем столбец с изменением цены
df['returns']=(df['<CLOSE>']/df['<CLOSE>'].shift(1))-1
Так можно выводить именно процент:
df['returns_pers']=((df['<CLOSE>']/df['<CLOSE>'].shift(1))-1)*100
Добавляем вторую акцию
Делаем это точно таким же образом
df2 = pd.read_csv("SBERP_190101_200105.csv",sep=';', header=0, index_col='<DATE>', parse_dates=True) df = df.sort_values(by='<DATE>') df2['returns_pers']=((df2['<CLOSE>']/df2['<CLOSE>'].shift(1))-1)*100 df2['returns']=(df2['<CLOSE>']/df2['<CLOSE>'].shift(1))-1 print(df2)
Визуализируем котировки наших акций
df['<CLOSE>'].plot(label='sber') df2['<CLOSE>'].plot(label='sberp') plt.legend() plt.show()
Теперь отобразим котировки с их средними (MA 50):
df['<CLOSE>'].plot(label='sber') df2['<CLOSE>'].plot(label='sberp') df['ma50'] = df['<OPEN>'].rolling(50).mean().plot(label='ma50') df2['ma50'] = df2['<OPEN>'].rolling(50).mean().plot(label='ma50') plt.legend() plt.show()
Можно отобразить и другие средние
df['<CLOSE>'].plot(label='sber') df2['<CLOSE>'].plot(label='sberp') df['ma100'] = df['<OPEN>'].rolling(100).mean().plot(label='ma100') df2['ma100'] = df2['<OPEN>'].rolling(100).mean().plot(label='ma100') plt.legend() plt.show()
Теперь выведем оборот по акциям:
Добавим также название оси У
и размер холста
df['total_trade'] = df['<OPEN>']*df['<VOL>'] df2['total_trade'] = df2['<OPEN>']*df2['<VOL>'] df['total_trade'].plot(label='sber',figsize=(16,8)) df2['total_trade'].plot(label='sberp',figsize=(16,8)) plt.legend() plt.ylabel('Total Traded') plt.show()
Анализ корреляций
Теперь подробнее посмотрим на корреляцию. в этом нам поможет матричный график
Создадим новую таблицу с колонками по обеим акциям и зададим им названия
all_sber = pd.concat([df['<OPEN>'],df2['<OPEN>']],axis=1) all_sber.columns = ['sber_open','sberp_open'] print(all_sber)
Теперь импортируем нужный график
from pandas.plotting import scatter_matrix
И выведем его:
scatter_matrix(all_sber,figsize=(8,8),alpha=0.2,hist_kwds={'bins':100}); plt.show()
Следует уточнить, что нам нужно добавить прозрачность (alpha=0,2), чтобы видеть наложение точек
Если точки “идут” по диагонали, наблюдается корреляция.
Оценка волатильности бумаг
df['returns_pers'].plot(label='sber') df2['returns_pers'].plot(label='sberp') plt.legend() plt.show()
Для лучшего понимания Отобразим волатильность на другом графике — гистограмме
df['returns_pers'].hist(bins=100,label='sber',alpha=0.5) df2['returns_pers'].hist(bins=100,label='sberp',alpha=0.5) plt.legend() plt.show()
Чтобы сделать вывод быстрее, можно упростить график (сделаем график менее подробным и менее прозрачным):
df['returns_pers'].hist(bins=10,label='sber',alpha=0.9) df2['returns_pers'].hist(bins=10,label='sberp',alpha=0.9) plt.legend() plt.show()
Анализ накопленного дохода
Теперь выведем изменение стоимости акций в процентах.
Для этого введем столбец с накопленным доходом.
df['Cumulative Return'] = (1+ df['returns']).cumprod() df2['Cumulative Return'] = (1+ df2['returns']).cumprod() print(df) print(df2) df['Cumulative Return'].plot(label='sber') df2['Cumulative Return'].plot(label='sberp') plt.legend() plt.show()
На графиках мы можем увидеть временные промежутки, когда одна из акций недооценена или переоценена относительно другой. В текущих обстоятельствах (при прочих равных, прошу заметить) нам это поможет выбрать акцию для усреднения при падении капитализации Сбербанка.

