Программисты много говорят про сложность решений. Мы можем часами размышлять о правильных шаблонах, красивых абстракциях и цепочках зависимостей. Однако, давайте поговорим открыто, всегда ли сложность обусловлена решаемой проблемой? Не оказываемся ли мы в плену наших стереотипов и убеждений?

День добрый. Меня зовут Никита Данилов, я ведущий .NET разработчик, при этом старательно интересуюсь как техническими нюансами .NET платформы, так и философскими аспектами ремесла программиста. Некоторое время назад я выступал на встрече SarDotNet с докладом «Имитация сложности» (Саратовское сообщество всероссийского DotNetRu), вольной расшифровкой которого хочу поделиться.
Вступление
Сегодня мы поговорим об имитации. Вынужден предупредить, всё что вы сейчас увидите и услышите – мысли на обдумывание, а не точные советы.
Сложное
Программисты могут часами размышлять о правильных шаблонах и красивых абстракциях. Как сделать еще гибче, еще круче, еще сложнее. Как усложнить. Обычно мы двигаемся от простого к сложному.
Простое → Сложное
На доклад меня подвигло именно то, что мы мало говорим о простом. По крайней мере в моём окружении мало разговоров об этом. Существуют статьи восхваляющие простые решения, но таковых довольно мало и чаще мы говорим о сложном. Давайте сегодня пройдемся от сложного к простому, через таинственную имитацию сложности. Предлагаю всем вместе подумать, почему мы так мало говорим про простые решения и много концентрируемся на сложных.
Простое ← Имитация Сложности ← Сложное
Малое и Большое, Простое и… Хаос
Если говорить про сложное и сложность, то вроде и много всего написано, а всё равно я ощущаю нехватку материалов. Размышляя про код, модули или архитектуру, мы интуитивно понимаем что такое маленькое и большое. Можем примерно отличить нечто простое (как кирпич) и интуитивно понимаем когда творится хаос (с лапшой). Так или иначе, все эти термины связаны с понятием сложности.

Вопрос: Попробуйте подумать, повспоминать и ответить на следующие вопросы:
- Какие существуют метрики сложности кода, архитектуры или программного обеспечения?
- Что такое «сложность» именно для вас?

Обозначений сложности много, она многогранна, перечислим лишь наиболее известные:
- Метрики размера программ:
- SLOC (Source Lines of Code) – анализ количества строк кода;
- Метрика Холстеда – анализ числа операторов и операндов программы;
- Метрики сложности потока управления:
- Метрика Маккейба – цикломатическая сложность (англ. Cyclomatic), или структурная (топологическая);
- Метрика Майерса – расширение метрики Маккейба с интервальным представлением значения метрики;
- Метрика Вудварда – Хенела и Хидлея, анализ точек пересечения передачи управления;
- Метрика Джилба – анализ насыщенности выражениями типа IF-THEN-ELSE;
- Метрики сложности потока данных:
- Метрика Чепина и её модификации – анализ характера использования переменных ввода-вывода;
- Метрика Спена – анализ обращений к данным внутри каждой программной секции;
- Метрики специфичные для объектно-ориентированного программирования:
- NOC (Number of Children) – анализ количества непосредственных потомков;
- DIT (Depth of Inheritance) – анализ глубины дерева наследования;
- WMC (Weighted Methods per Class) – анализ суммарной сложности всех методов класса;
- CBO (Coupling Between Classes) – анализ связности классов и методов;
- LCOM (Lack of Cohesion of Methods) – анализ сцепленности классов и методов;
- и многие-многие другие.
К сожалению, зачастую люди находят информацию лишь про SLOC, где обнаруживают критику, что метрика устарела с развитием языков, и на этом изучение теории сложности программного обеспечения завершается. Различные метрики сложности программного обеспечения мы постараемся разобрать в следующей статье (надеюсь). Сейчас же не будем отвлекаться, запомним лишь факт их существования.
Словари определяют, что само слово «сложный» является антонимом к слову «простой» и имеет несколько устоявшихся значений:
- состоящий из нескольких частей, элементов;
- многообразный по составу входящих частей, отношений, связей;
- затейливый, замысловатый по строению, форме;
- представляющий затруднения для понимания, решения, осуществления и т.п.
Если пристально вглядеться, в нашем мире и правда много сложного. Как нам думается. Навскидку, выписал слова, которые крутились в голове – ГОСТ, финансы, LESS, физика, Docker, ООП, Шаблоны проектирования, Опционы, АЭС и т.д. (см. КДПВ).
Хотя зачастую мы сами явно не упрощаем. Именно в IT-индустрии многие могут знать не понаслышке про такие проекты, где собиралась огромная бригада аналитиков и менеджеров, приносились фреймворки и Blue-Green развертывание, event-driven микросервисы и реактивные микрофронтенды. И вот спустя полгода человек жонглирует 30 серверами пытаясь понять в каком месте оно не работает. А нужна была лишь система обработки заказов, с пиковой нагрузкой в 100 пользователей.
Имитация Сложности
Несмотря на то, что в этом мире существуют явно сложные задачи, тем не менее есть особая категория решений, которые строятся сложнее чем они могли бы быть построены (например, пишется больше кода чем необходимо для решения проблемы).
На мой взгляд, для описания подобной ситуации подходит слово «имитация» имеющее древние корни:
- imitari (праиндоевр.) — подражать, воспроизводить.
- imitatio (лат.) — подражание.
Когда мы имитируем сложность, у нас её еще нет, но мы решили попробовать ей подражать. Это промежуточная серая область, когда разрабатываемое решение уже нельзя считать простым, однако и сложность пока выглядит сомнительно либо неуместно. Позвольте объяснить точнее, рассмотрим на условном примере.
Простое ← Имитация Сложности ← Сложное
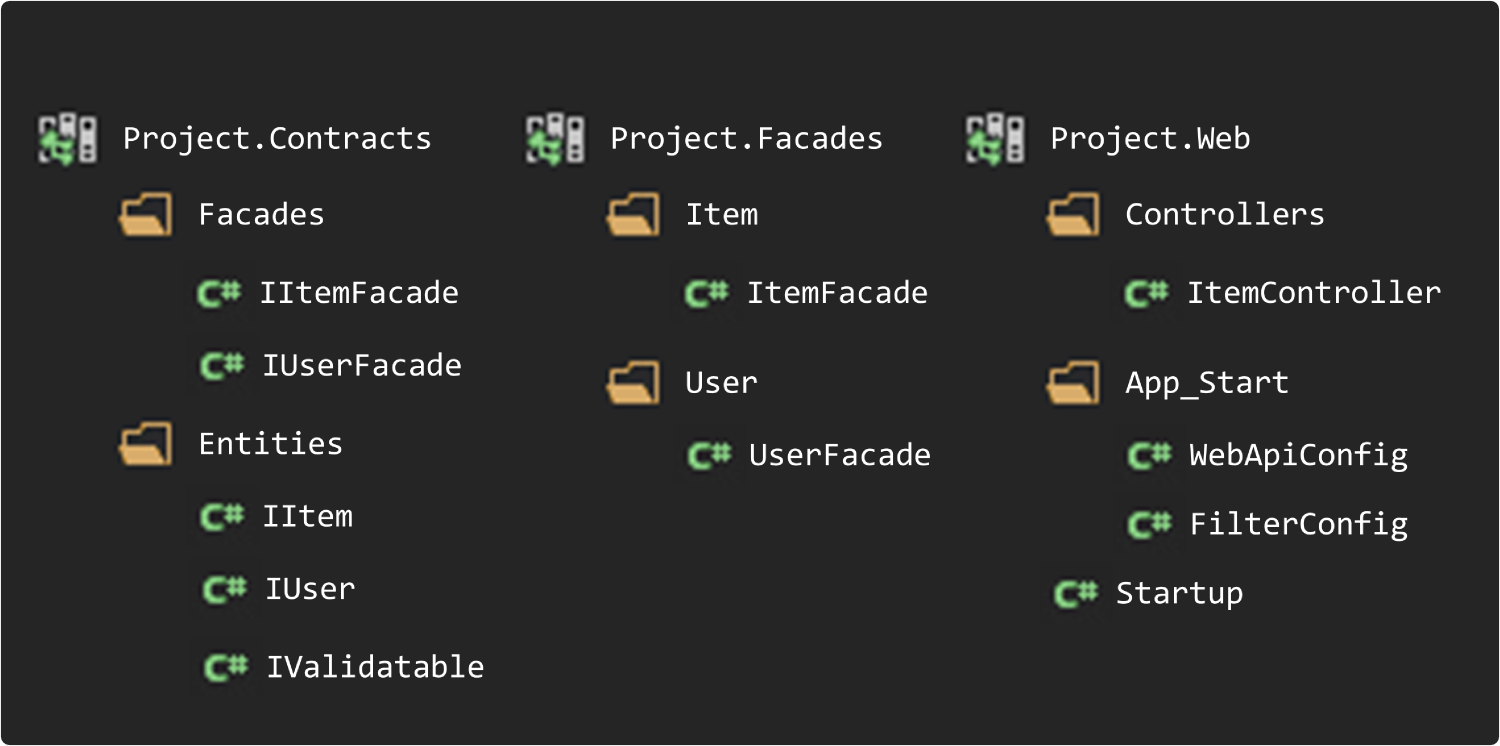
Вам передают приложение, разработанное кем то иным, допустим REST API. Вы открываете и видите N проектов: контракты, ядро, данные, веб, фасады и т.д. Богато выглядит, думаете вы, наверняка оно решает нечто важное.
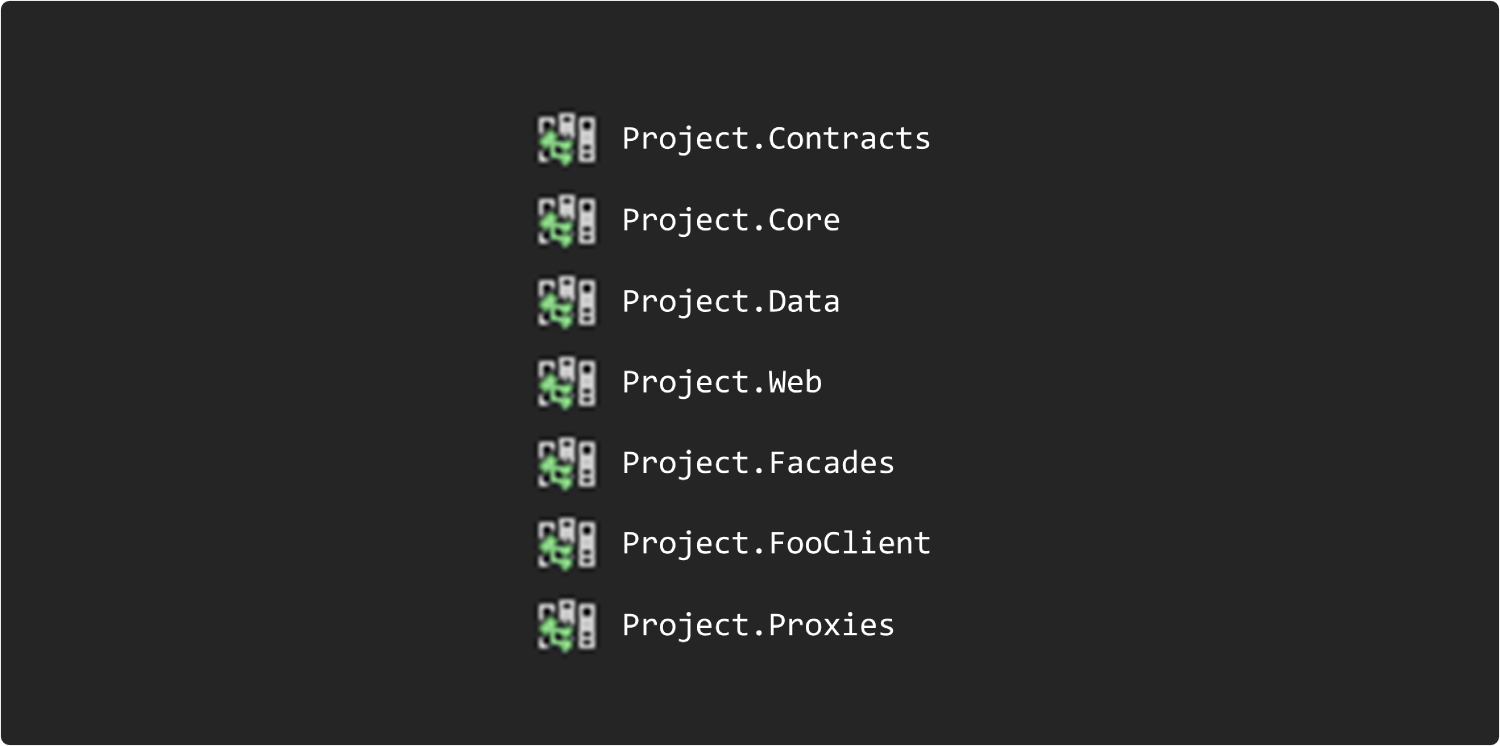
Открываете первый проект. Там 2 директории. 2 интерфейса на фасады. Некий интерфейс видимо указывающий на возможность валидации сущности. Хотя сущностей всего 2 и вроде и логично, что их можно валидировать.
Открываете фасады, думаете может там хитрость закопана. Там обнаружится всего два фасада, по одной реализации, без переключения с одной базы данных на другую или тому подобного. Закрадываются сомнения, а всё ли так богато на самом деле.
Постепенно вы добираетесь до проекта Web, думается там вся соль! Ан нет, там только один контроллер и стандартная конфигурация.
Пример несколько гиперболизирован, однако ситуация многим может быть знакома.
Вопрос: На ваш взгляд, обоснована ли здесь такая организация кода, архитектуры, проектов?
Универсальный ответ — «зависит», ведь это зависит от контекста, от поставленной задачи и чего хотели достичь. Возможно это всё будет ещё расширяться, возможно нет, но если вдруг будет, приложение готово к расширению. Разумеется, я выступаю за продуманную организацию кода, а с другой стороны, вроде всё это упаковывается в 2 проекта и несколько файлов, на первое время.
Рассмотрим другой пример.
Вы создаете новое приложение, допустим, REST API. Решив начать всё с контроллера, вы описали контроллер, описали сущности контракта.

И ощущаете, вроде маловато. Надо еще ведь модульные тесты написать — создаете аксессор (и/или: репозиторий, UnitOfWork, DB-контекст, ...).

Потом идете на кухню попить чайку, открываете книгу про шаблоны проектирования, посещаете конференцию где вам рассказывают еще 3 истории успеха внедрения DDD и CQRS, т.е. вы где-то что-то зачем-то узнаете. Не успеваете оглянуться, вжух – кембрийский взрыв. В приложении появляются останки всех известных слов для выражения зависимостей:

Контракты, фасады, прокси, процессоры и т.д. и т.п. Я знаком с приложениями где больше слов, а делают они пока очень мало чего.
Справедливости ради, спустя 2 года эти приложения научились делать значительно больше и превратились в серьезные системы. Вот только некоторые зависимости так никогда и не были использованы, а некоторые раздробились на множество новых.
Вопрос: Насколько оно обосновано?
Опять-таки, возможно, всё здесь и как надо, возможно усложнили код предполагая будущие задачи. Всё зависит от контекста и наших целей. В теории правильно выстроенная архитектура и не должна позволять сделать неправильно. Однако, надеюсь я сумел донести саму идею существования определенной грани, когда реализуемая сложность еще не нужна, где начинается имитация сложности — будущей или вымышленной.
Мне доводилось самому делать такие приложения как показал на предыдущих слайдах – сразу всё по полочкам, с горой терминов. Потом вернулся через 3 года и выкинул много лишнего, что так и не пригодилось.
Серая область имитации сложности довольно велика и относительна. Но чтобы её лучше понять надо сначала осознать простое и сравнить сложное с простым.
Простое
Простое ← Имитация Сложности ← Сложное
Если существует сложность (и она измеряема), то с другой стороны должно быть нечто противопоставляемое, т.е. простое. Довольно давно сформулирован принцип KISS, про него немало всего написано и рассказано. Предлагаю рассмотреть какие преимущества нам дает простое решение.

1. Проще → Быстрее Разработка
Во-первых, простое решение быстрее реализовать. Уточню, реализовать изначально, тему дальнейшей поддержки/развития мы лишь отчасти затронем чуть ниже.
Безусловно, выбор решения во многом зависит от решаемой проблемы и поставленной задачи.
Сани, машина, ракета — всё из этого позволяет добраться из пункта А в пункт Б.

Сани не сгодятся для полета в космос, зато их сделать быстрее чем космический корабль.
Если мы понимаем, что нам надо лишь съехать с горки, то быть может и куска линолеума хватит, а в этом случае даже сани будут являться имитацией сложности. Мы захотели на более вычурных санках съехать, хотя линолеум прекрасно справился бы, а могли сэкономить деньги и время.
Другой пример это когда вам необходимо доплыть до пункта Б.

Летом, чтобы доплыть до островка неподалеку, зачастую хватает ваших собственных рук и ног, в крайнем случае подручных средств. Смастерить плот и весло сложнее, чем проплыть немного самостоятельно, зато с плотом легче преодолеть большую дистанцию. Структура плота явно проще парусной яхты. Иногда вы арендуете уже готовую яхту с командой и задача поддержки сложности при этом перекладывается на другого.
2. Проще → Надежнее Работа
Во-вторых, простое решение обеспечивает более надежную работу. Это заявление может выглядеть более спорным, а потому позвольте объяснить подробнее. Обратим наше внимание на названые ранее метрики сложности. Значение любой из них так или иначе прямо пропорционально числу «подвижных» частей нашего решения. Если мы входим в зону имитации сложности, мы начинаем добавлять код, вряд ли убавлять.
Вопрос: Какова вероятность ошибки или опечатки в строке кода? 1% или 0.1% или 0.01%?
Отчасти понадеемся на компилятор, он сможет обнаружить самые очевидные ошибки. Допустим мы уверены, что вероятность ошибки в строке кода крайне мала, пусть 0.01%. Перемножив вероятности ошибки на большом приложении с 10 000 строк кода, получаем 100%, что там есть ошибка. Что-то здесь не так...

Причем, исправление одной ошибки уменьшит вероятность следующей лишь незначительно, ведь эти события являются практически независимыми. Допустим мы пишем код идеально. Уменьшим вероятность еще на 2 знака, получим вероятность ошибки 1% на 10 000 строк кода. А потом вспоминаем, что у нас минимум 100 взаимосвязей или разных зависимостей между классами...

Продолжать можно бесконечно, хоть и к точности подсчета можно придраться, суть останется прежней: «Больше последовательных звеньев — ниже надежность». Сложность проверки превосходит количество строк кода в миллионы раз. Поэтому, чем меньше кода в вашем решении, тем выше вероятность надежной работы. Обычно.
3. Проще → Понятнее для Поддержки
В-третьих, простое решение понятнее для поддержки. Снова обратим наше внимание на метрики сложности, многие из которых означают – чем сложнее, тем больше у вас будет методов/классов/абстракций. Всевозможные шаблоны придуманы чтобы сокрыть сложность за некой абстракцией. Даже если они звучат лаконично, в реализации это может означать десятки классов, т.е. сложность зачастую привносит новые абстракции.
Абстракции это великолепный инструмент доступный человеческому разуму. Абстракции упрощают восприятие при моделировании, позволяют сокрыть сложность и абстрагироваться от деталей. Здесь мы спрятали за фасадом, здесь укрыли в репозиторий, и кажется сложности у нас совсем нет.
Если мы начинаем вводить абстракции заранее (а это почти всегда так), то что мы делаем? Имитируем будущую сложность. Проходит время и вы оказываетесь в роли знаменитой Даши. Где-то в глубине приложения что-то упало и вы начинаете копать.
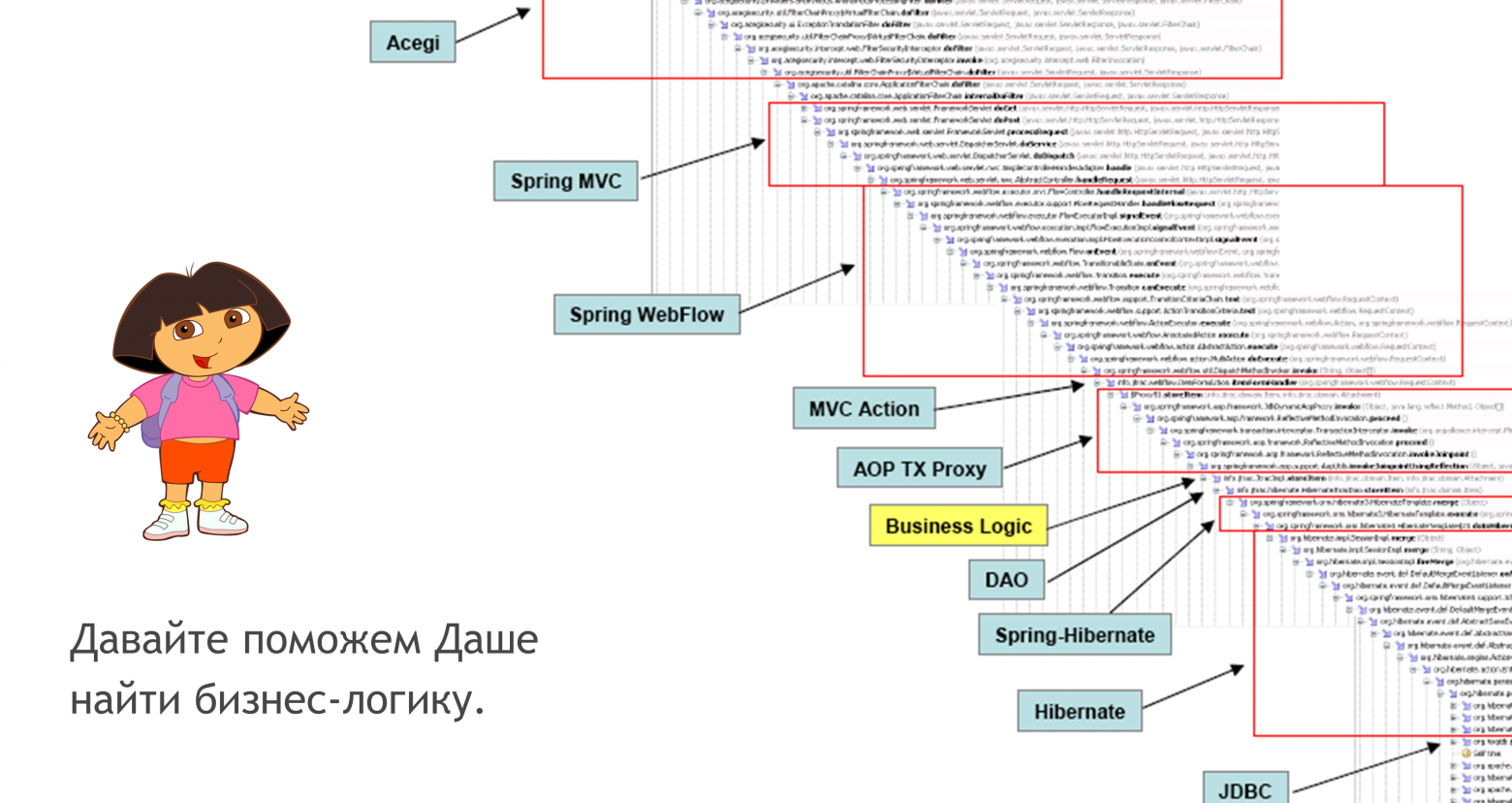
Начинаем смотреть на наши зависимости приправленные любимым контейнером для внедрения.
Что-то там делается, вызывается менеджер с разными параметрами.
class Controller { Controller(IManager, ILogger, ISettings) { … } Load() { … var data = _manager.Load(...); … } }
Идем дальше. Менеджер вроде тоже вполне прозрачный, зависимости какие-то, но параметры перекомпоновывает, поэтому надо разобраться как именно. Разобрались, идём дальше.
class Manager { Manager(IFacade, ILogger, IChecker, IWrapper) { … } Load() { … var data = _facade.Load(...); … } }
Открываем фасад, там еще порция зависимостей. Перегруппировка параметров и вызов дальше аксессора.
class Facade { Facade(IAccessor, ILogger, IPermission, IPhone) { … } Load() { … var data = _accessor.Load(...); … } }
Открываем аксессор, нет зависимостей – ура! Подождите ка...
class Accessor { Accessor() { } Load(...) { NLog.Instance.Write(…); var context = new DbContext("connectionString"); var data = context.Entities.ToList(); } }
Видимо человек, кто писал аксессор на этом уровне, уже просто устал разбираться. Взял любимый логгер, указал хардкодом строку подключения для начала разработки, да так и оставил. Теоретически, архитектура не должна позволять делать такое. Только кто запретит человеку выстрелить себе в ногу? Возможно на код-ревью потом отловим. Возможно и не отловим, изменится строка подключения и всё рухнет.
Этот пример о том, что вот я стал уставать от обилия абстракций. Здесь десяток абстракций запомни, здесь десяток, и вроде недолго разбираться, но время тратится. Грустно, хочется задачу решать, а не заучивать плоды чьей то фантазии.
Так почему не делать всё Просто?
Итого, простота ведет к Скорости (уменьшению затрачиваемого времени), к Надежности, к Поддерживаемости. Казалось бы,
«Обалдеть, дайте две!» ©
Замечательно, давайте делать всё максимально просто, чего я вообще тут про имитацию распинаюсь. Почему мы не делаем всё Просто? Разумеется, указанные параметры здесь встают в позу знаменитой тройки: лебедь, рак и щука.
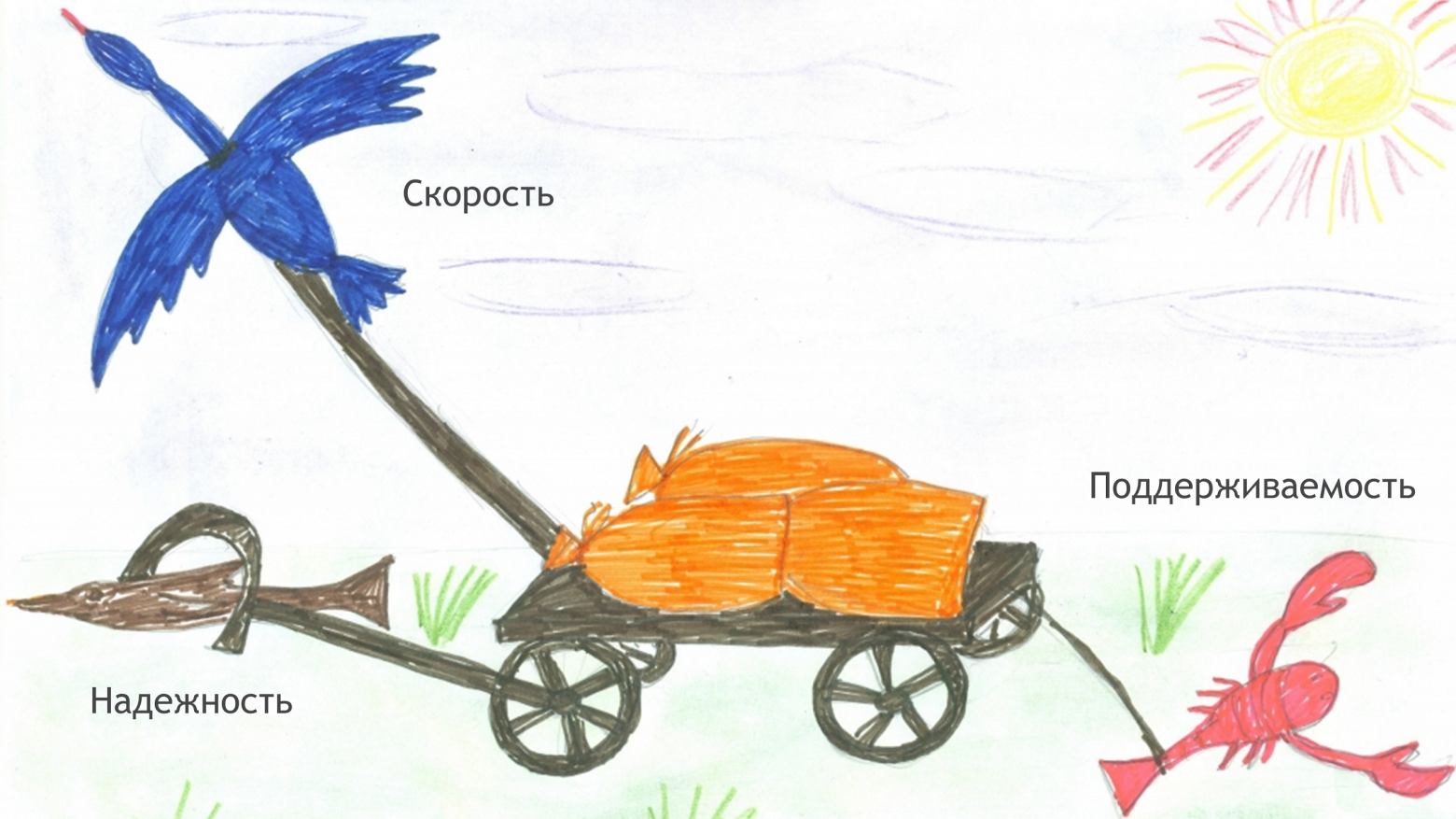
(источник, автор: Анна Тимакова, Город: Москва, возраст: 7 лет)
К сожалению, реально полноценно совместить лишь 2 аспекта, а 3-й обязательно будет страдать. Примерно как CAP теорема, или Тройственная ограниченность проекта, только про другое (очень уж людям нравится треугольники). Нам придется делать выбор, а выбор обусловлен целью и задачами, как мы помним. Решаемая задача каждый раз особая, где для одной допустимо простое решение, для другой придется усложнять. В одном случае топорное решение обеспечит страдания при поддержке, а в другом наоборот позволит быстрее переписать при необходимости.
Нередко встречаю аргументацию, мол бывает «сложное» решение реализовать даже «проще», зато с «простым» вы потом получите «сложные» проблемы. Однако, здесь легко можно попасть в лингвистическую и семантическую ловушку. Решение которое видится нам «простым», на самом деле может оказаться невероятно сложным с т.з. отдельных метрик. Лишь отчасти можно утверждать, что такое «сложное» решение «проще» подстраивать, т.е. обходиться компоновкой существующих деталей.
Кто виноват? Что делать?
Попробуем подумать, зачем мы имитируем?
- Крутизна, хотим чтобы выглядело круто, посложнее, солиднее, богаче, изучить новый подход.
- Изучение, пробуем сделать посложнее дабы изучить новый подсмотренный подход.
- Демонстрация, показать что мы это умеем.
- Вдохновение, попробовать нечто новое и крышесносящее, подслушанное на конференции.
- Опасения, желаем чтобы приняли диплом.
- Предусмотрительность, стараемся добиться слабой связанности модулей для последующих изменений.
- Гибкость, волшебное слово «гибкость», чтобы было гибко, конфигурируемо, мы же сейчас всё сделаем так, что потом поменяем два контракта и всё будет работать как раньше.
- Поддерживаемость, стараемся избежать технического долга.
- и т.д. и т.п.
Причины могут быть разные, я не берусь сейчас разделять на «хорошие» или «плохие», но важно честно и рационально их оценивать.
Мне знакомы ситуации, когда люди привносили сложность т.к. им было стыдно показать простое решение. Они выходили на кухню, там все рассказывали про сложные шаблоны и рождалась мысль: «Как же я свои 2 класса покажу, это же всё не по книгам».
Часто можно услышать и другую универсальную причину — сделаем гибче, еще гибче, на будущее. Мы многое можем спрятать под общими словами, не желая признать собственное непонимание решаемой задачи.
Не призываю совсем избегать сложности, ведь она бывает оправдана, да и зачастую она оправдана. Всё-таки мы проблемы Бизнеса решаем, а не лямбдами балуемся.
Не призываю создавать только примитивные решения, ведь действительно с ними потом можно получить множество проблем при необходимости внести изменение. Если строить лишь телеги, то в космос не полететь. Хотя если строить лишь космические корабли, то и саночек не останется.
Многое в этом мире автоматизировано и успешно функционирует с использованием относительно простых решений. Признаю проблематичность подтверждения пруфами данного утверждения, оно основано скорее на личном общении. Можно вспомнить доклад Дилана Битти «Ctrl-Alt-Del: учимся любить легаси-код», где Excel упоминается как самая популярная в истории платформа для разработки коммерческих продуктов, а рядом бродит призрак Visual Basic. Знаю небольшие магазины, где долгие годы люди успешно работают с примитивнейшим полу-консольным интерфейсом кассовых аппаратов.
Призываю быть честными по отношению к себе, к коллегам и решаемой задаче. Давайте стараться всегда начинать с упрощения самой постановки проблемы ещё до начала проектирования решения. Возможно, достаточно больших красных букв на странице, вместо механизма отката распределенных транзакций.
«Всё следует упрощать до тех пор, пока это возможно, но не более того» © Альберт Эйнштейн
Упростив постановку проблемы и предлагаемое решение, вы получите пространство для маневра.
Если вы осознаете необходимость восхитительно гибкого механизма — прекрасно, вы эксперт, дерзайте.
Если вы хотите именно здесь опробовать новый подход и он не принесёт страданий — замечательно, пробуйте.
Если же причин усложнять нет, а вас смущают лишь субъективные нерабочие факторы, разве это повод обеспечить трудности будущему себе?
Простое <—> Имитация Сложности <—> Сложное
Давайте чаще задумываться о простом, помня о преимуществах как сложных, так и простых решений. На мой взгляд, именно благодаря этому мы сможем свободно варьировать сложность в зависимости от реальных потребностей. Потом вам и другие скажут спасибо, и вы сами себе.
В ближайшем будущем я планирую подготовить статью с описанием метрик сложности и разбором их влияния на программное обеспечение (информационную систему). По-хорошему, стоило такую статью опубликовать первой, но заготовки под неё не было, зато вот имелся текст выступления с докладом о наболевшем.
Благодарю за внимание, до новых встреч.
Ссылки
Rich Hickey, Simple Made Easy.
Vlad Balin, Software: Managing the Complexity.
Дилан Битти, Ctrl-Alt-Del: учимся любить легаси-код.
Основы теории надежности, Расчет показателей надежности невосстанавливаемых нерезервированных систем.
DotNetRu
DotNetRu — группа независимых сообществ .NET разработчиков со всей России. Мы объединяем людей вокруг .NET платформы, чтобы способствовать обмену опытом и знания. Проводим регулярные встречи, чтобы делиться новостями и лучшими практиками в разработке программных продуктов.
Мы стараемся объединить всех .NET разработчиков России, стать тем метасообществом, где можно посмотреть видео всех докладов, почитать новости, поделиться своими знаниями или мнением на ту или иную тему. В 2018 году нас было 4 города, а через два года уже 13! Это настоящее объединение русскоговорящих .NET сообществ.
DotNetRu ставит перед собой следующие цели:
- собираться вместе, знакомиться, обсуждать новости, делиться проблемами и искать решения;
- приглашать самых лучших докладчиков, настоящих профессионалов и уникальных авторов;
- находить и подготавливать новых спикеров для крупнейших российских конференций;
- создать и поддерживать качественную коллекцию видео-лекций.
Мы в телеграмме: новостной канал DotNetRu и обсуждение насущных вопросов DotNetRuChat.
Если вы хотите организовать .NET сообщество в вашем городе, свяжитесь с нами. У нас богатый опыт организации встреч, тренировки докладчиков, общения со спонсорами и мы всегда рады новым инициативам. Пишите по любым вопросам и предложениям. Мы сами перенаправим ваше послание нужному адресату. Присоединяйтесь, вместе — мы сила!

