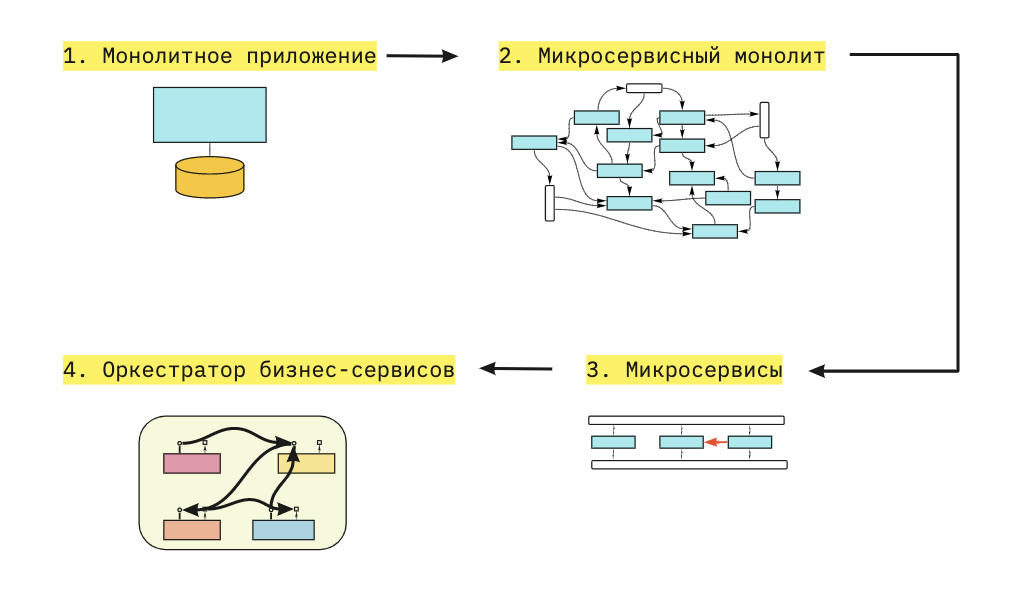
Если вы определите, на каком из этапов находитесь сейчас, это поможет вам понять плюсы и минусы текущего этапа, оценить стоит ли идти на следующий этап и, если стоит, увидеть шаги необходимые для перехода.
В каждом разделе вы найдете ссылки для более глубокого погружения в нюансы конкретного перехода.
Этап №1. Монолит
1.1 Характеристики
Обычно монолитную архитектуру можно описать так:
- Единая точка разработки и деплоя
- Единая база данных
- Единый цикл релиза для всех изменений
- В одной системе реализовано несколько бизнес-задач

Погружение в контекст:
1.2 Проблемы
- Система единая, при этом решает много разных бизнес-задач. Разные бизнес-задачи развивают разные подразделения компании и двигаются с разной скоростью. Отсюда возникает проблема с взаимозависимыми релизами разных подразделений, когда все ждут самого медленного.
- Сложно масштабировать бизнес-приложения, которые объединяет монолит. Это приводит к тому, что не учитываются особенности каждого приложения, и масштабирование делается неэффективно.
- При выборе технологического стека для новой бизнес-задачи приходится подстраиваться под среду разработки монолита, хотя этот выбор не всегда является наилучшим.
- Система уходит в релиз целиком, поэтому должна быть протестирована целиком. Это приводит к сложному регрессионному тестированию, затягиванию процесса тестирования и репотинга багов всем поставщикам изменений, замедлению скорости релизов, и, соответственно, увеличению времени time-to-market.
- Последнее ведет к тому, что бизнесу тяжело быстро собрать обратную связь от рынка.
1.3 Как перейти на следующий этап
В основе процесса выделения микросервисов лежит вынесение бизнес-задач из монолита в отдельные сервисы. При этом нужно руководствоваться принципом единственности ответственности, который перефразируется так: у микросервиса должна быть только одна причина для изменения. Этой причиной является изменение бизнес-логики той единственной задачи, за которую он отвечает.
В дополнение к SRP есть подход от любителей Domain-Driven Design: микросервис ограничивается одним или несколькими Bounded Context.
Постепенно у вас образуется набор из микросервисов, где каждый отвечает лишь за свою бизнес-задачу:
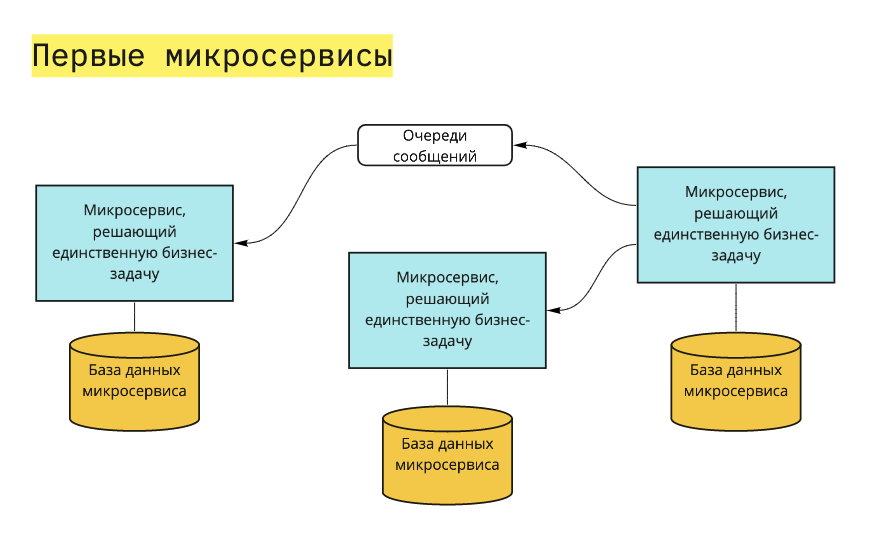
Погружение в контекст:
При создании микросервисной архитектуры полезно периодически проверять себя по чеклисту The Microservice Architecture Assessment, чтобы не упустить какую-то важную деталь.
Этап №2. Микросервисный монолит
2.1 Характеристики
Все части монолита стали независимыми микросервисами и эти микросервисы должны общаться между собой. Если раньше, находясь внутри одного процесса, сервисы вызывали методы друг друга напрямую, то теперь нужно интегироваться.
Из четырех способов интеграции в микросервисной архитектуре обычно не используют обмен файлами и стараются не использовать shared database, зато активно работают с RPC и очередью сообщений.
Получается, что все части монолита распались на микросервисы, а их обратно соединили паутиной синхронных и асинхронных интеграций:

По факту, получился тот же монолит, но с большим количеством новых проблем.
2.2 Проблемы
- Прямые связи между микросервисами усложняют анализ проблем. Например, запрос может пройти через 5 микросервисов, прежде, чем вернуться с ответом. Что если на третьем микросервисе запрос завис? Что если там была ошибка? Что если на втором шаге должно было создаться сообщение в очередь, но оно не появилось? Возникает сложность с разбором проблем.
- Предыдущий пункт усложняется, если у микросервиса много экземпляров. Тогда возникает ситуация, что запрос пришел на экземпляр, который завис.
- Архитектуру сложно понять и, чем больше сервисов вы добавляете, тем запутанней всё становится. В целом, добавление новых сервисов нелинейно повышает сложность архитектуры.
- Неизвестно, кто потребители вашего API, что добавляет сложности в проектировании API и его изменении.
Если на пути рефакторинга монолита вы остановитесь на этом этапе, то, вполне резонно, сделаете вывод, что с монолитом было лучше и дешевле.
2.3 Как перейти на следующий этап
Основные идеи: локализовать точки интеграции и контролировать все потоки данных. Чтобы этого добиться, надо использовать:
- API Gateway для локализации синхронных взаимодействий и мониторинг/логирование трафика между микросервисами. В идеале, надо иметь визуализацию трассировки любого запроса.
- Service Discovery для отслеживания работоспособности экземпляров микросервиса и перенаправление трафика на «живые» экземпляры.
- Запретить прямые вызовы между микросервисами.
Чтобы избежать типовых проблем и упростить разработку, рекомендую взять на вооружение подходы по повышению отказоустойчивости:
Этап №3. Микросервисы
3.1 Характеристики
Микросервисы ничего не знают о существовании друг друга: работают со своей базой данных, API и сообщениями в очереди. Каждый микросервис решает только одну бизнес-задачу и старается делать это максимально эффективно, за счет выбора технологий, стратегии масштабирования.
Становится заметна главная черта хорошей архитектуры: сложность системы растет линейно с увеличением количества микросервисов.
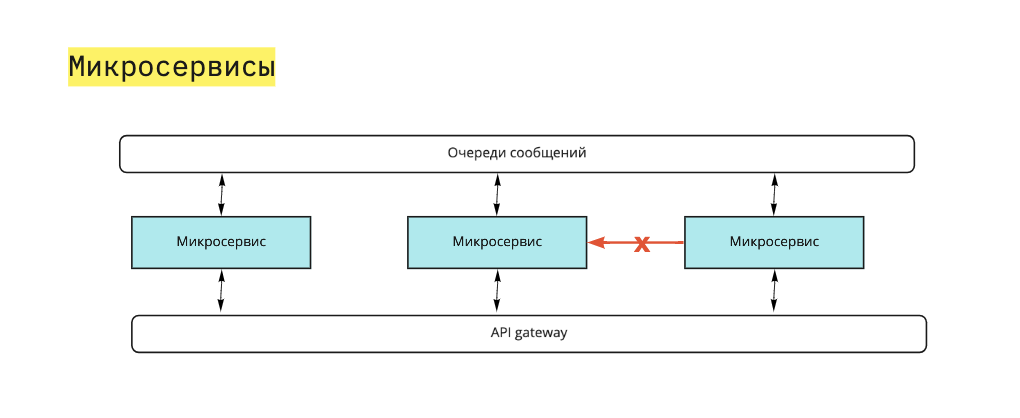
Погружение в контекст:
3.2 Проблемы
На этом этапе сложные технические задачи решены, поэтому начинаются проблемы на уровне бизнес-задач:
- Среди сотен микросервисов и разных API бизнес не может понять, какие инструменты есть у него в руках. Пазл складывается в стройные картинки только у энтерпрайз архитекторов, а их, как известно, очень мало на Земле.
- Бизнес хочет увидеть лес за деревьями, чтобы понимать, какие есть детали и как из них можно собирать новые продукты, не прибегая к разработке.
- Сборку новых продуктов из существующих кубиков, хочется совместить с продуктовой разработкой, чтобы Владелец продукта сам ориентировался, какие ему доступны ресурсы.
3.3 Как перейти на следующий этап
Многие компании не идут дальше, потому что на текущем этапе бизнес-задачи могут решаться уже достаточно быстро и эффективно. Тем, кто решают двигаться дальше:
- Изучите концепцию Citizen Integrator. Для наглядного примера заведите себе пару процессов в Zapier.
- Опишите микросервисы в виде блоков, решающих бизнес-задачу, и сделайте из них конструктор. Это можно сделать: 1) на готовых инструментах, 2) обернуть BPM-движки типа Camunda, 3) написать всё самим с нуля. Все три подхода жизнеспособны. Выбор подхода зависит от стратегии вашей компании и наличии у вас ИТ-архитекторов и хороших программистов.


Погружение в контекст:
Этап №4. Оркестратор бизнес-сервисов
4.1 Характеристики
Оркестратор бизнес-сервисов обычно является визуальной платформой, где соединяются сервисы, выставляются триггеры и условия ветвления, контролируются все потоки данных: реализована трассировка запросов, логирование событий, автомасштабирование по условиям. Сам оркестратор ничего не знает о специфике бизнес-процессов, которые на нем крутятся.
На этом этапе можете решить задачу создания продукта в визуальном редакторе. Если нужных «квадратиков» не хватает, то программисты создают микросервис, учитывая правила описания сервиса для оркестратора, публикуют API и «кубик» появляется в визуальном редакторе, готовый соединяться с другими участниками бизнес-задачи.

4.2 Проблемы
- Создание, внедрение и развитие оркестратора бизнес-процессов является дорогим удовольствием.
- Если ослабить архитектурный контроль, оркестратор может превратиться в узкое место систем, созданных на нем.
- Чем больше систем создается на оркестраторе, тем больше бизнес зависит от этого решения. В целом, это начинает напоминать проблемы монолита.
4.3 Как перейти на следующий этап
На данный момент я не вижу сформировавшегося пятого этапа. Если вы видели жизнь после оркестратора бизнес-сервисов, буду рад увидеть описание вашего опыта в комментариях.
Заключение
Эти четыре этапа показывают, как мне кажется, естественный ход вещей:
- Вначале приложение небольшое и решает одну бизнес-задачу. Со временем в него добавляют много всего и оно превращается в неповоротливый монолит.
- При первой попытке разделить монолит многие команды не готовы к возрастающей сложности. Монолит делится на много микросервисов, но из-за большого количество взаимосвязей получается тот же монолит, только с новыми проблемами: простейшие задачи типа трейсинга запроса или мониторинга инфраструктуры становятся вызовом для команды разработки.
- Когда сложности решаются, получается стройная и масштабируемая архитектура. Добавление новых микросервисов линейно повышает сложность.
- На последнем этапе приходит бизнес и резонно говорит, что раз есть готовые решения бизнес-задач, то давайте делать новые продукты без разработки. Будем соединять готовые независимые блоки в новые бизнес-процессы через оркестратор.

