Примерно месяц назад общаясь с одним разработчиком приложения на Flutter встала проблема торможения обработки маленьких (в десятках тысяч) массивов данных на телефоне юзера.
Многие приложения предполагают обработку данных на телефоне и, далее, их синхронизацию с бэкендом. Например: списки дел, списки каких либо данных (анализов, заметок и т.п.).
Совсем не круто, когда список всего нескольких тысяч элементов, при удалении одного из них и далее записи в кеш или при поиске по кешу — начинает тормозить.
Решение есть! Hive — noSql база, написанная на чистом Dart, очень быстрая. Кроме этого плюсы Hive:
- Кросс-платформенность — так как на чистом Dart и нет нативных зависимостей — mobile, desktop, browser.
- Высокая производительность.
- Встроенное сильное шифрование.
В статье мы посмотрим как использовать Hive и сделаем простое ToDo приложение, которое в следующей статье дополним авторизацией и синхронизацией с облаком.

Начало
Вот такое приложение мы напишем в конце статьи, код выложен на github.
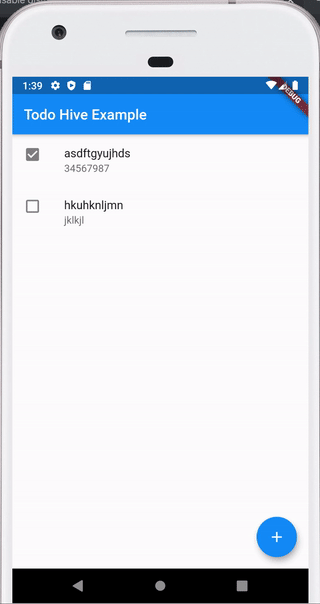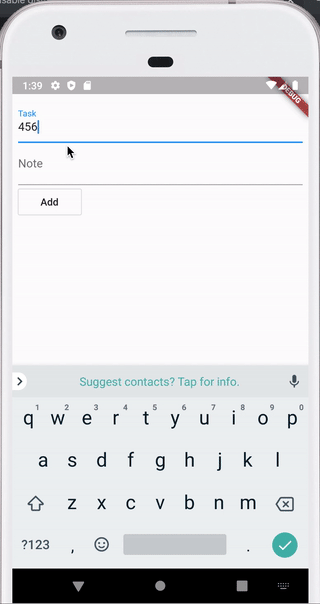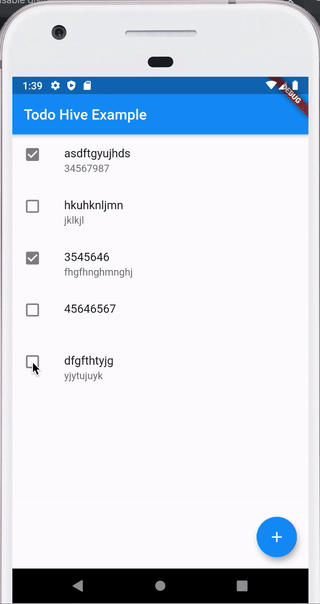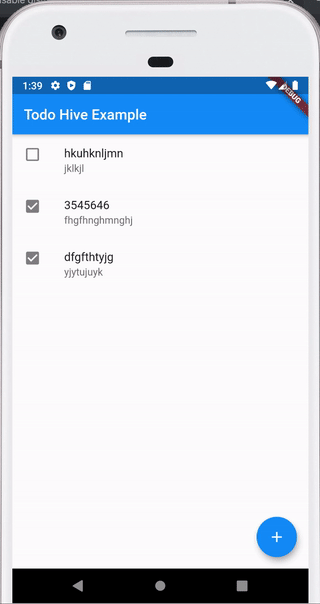
Один из плюсов Hive — очень хорошая документация https://docs.hivedb.dev/ — по идее там все есть. В статье я просто кратко опишу как с чем работать и сделаем пример.
Итак, для подключения hive в проект добавляем в pubspec.yaml
dependencies: hive: ^1.4.1+1 hive_flutter: ^0.3.0+2 dev_dependencies: hive_generator: ^0.7.0+2 build_runner: ^1.8.1
Далее инициализируем, обычно в начале приложения.
await Hive.initFlutter();
В случае, если мы пишем приложение под разные платформы, можно сделать инициализацию с условием. Пакет hive_flutter: ^0.3.0+2 — просто сервисная обертка упрощающая работу с Flutter.
Типы данных
Из коробки, Hive поддерживает типы данных List, Map, DateTime, BigInt и Uint8List.
Также, можно создавать свои типы и работать с ними используя адаптер TypeAdapters. Адаптеры можно делать самим https://docs.hivedb.dev/#/custom-objects/type_adapters или использовать встроенный генератор (мы его подключаем вот этой строкой hive_generator: ^0.7.0+2).
Для нашего приложения нам понадобится класс для хранения тудушек
class Todo { bool complete; String id; String note; String task; }
Модифицируем его для генератора и присваиваем id — typeId: 0
import 'package:hive/hive.dart'; part 'todo.g.dart'; @HiveType(typeId: 0) class Todo { @HiveField(0) bool complete; @HiveField(1) String id; @HiveField(2) String note; @HiveField(3) String task; }
Если в будущем нам понадобится расширить класс, то важно не нарушать порядок, а добавлять новые свойства далее по номерам. Уникальные номера свойств используются для их идентификации в бинарном формате Hive.
Теперь запускаем команду
flutter packages pub run build_runner build --delete-conflicting-outputs
(эта команда нужна очень часто, рекомендую добавить статью в закладки или сделать шорткат в терминале)
и получаем сгенерированный класс для нашего типа данных todo.g.dart
Теперь мы можем использовать этот тип для записи и получения объектов этого типа в\из Hive.
HiveObject — класс для упрощения менеджмента объектов Мы можем добавить удобные методы в наш тип данных Todo просто наследовав его от встроенного класса HiveObject
class Todo extends HiveObject {
Это добавляет 2 метода save() и delete(), которые иногда удобно использовать.
Хранение данных — Box
В hive данные хранятся в боксах (box). Это очень удобно, так как мы можем сделать разные боксы для настроек юзера, тудушек и т.д.
Box идентифицируется строкой. Чтобы его использовать, надо сначала его асинхронно открыть (это очень быстрая операция). В нашем варианте
var todoBox = await Hive.openBox<Todo>('box_for_todo');
и потом мы можем синхронно read / write данные из этого бокса.
Идентификация данных в боксе возможна либо по ключу, либо по порядковому номеру:
Например, откроем бокс со строковыми данными и запишем данные по ключу и с автоинкрементом
var stringBox = await Hive.openBox<String>('name_of_the_box');
По ключу
stringBox.put('key1', 'value1'); print(stringBox.get('key1')); // value1 stringBox.put('key2', 'value2'); print(stringBox.get('key2')); // value2
Автоинкеремент при записи + доступ по индексу
Для записи множества объектов удобно использовать бокс аналогично List. У всех объектов в боксе есть индекс типа autoinrement.
Для работы с этим предназначены методы: getAt(), putAt() and deleteAt()
Для записи просто используем add() без индекса.
stringBox.add('value1'); stringBox.add('value2'); stringBox.add('value3'); print(stringBox.getAt(1)); //value2
Почему возможно работать синхронно? Разработчики пишут, что это одна сильных сторон Hive. При запросе на запись все Listeners уведомляются сразу, а запись происходит в фоне. Если произошел сбой записи (что очень маловероятно и по идее, можно это не обрабатывать), то Listeners уведомляются снова. Также можно использовать await для работы.
Когда бокс уже открыт, то в любом месте приложения мы его вызываем
var stringBox = await Hive.box<String>('name_of_the_box');
из чего сразу становится понятно, что при создании бокса пакет делает singleton.
Поэтому, если мы не знаем, открыт уже бокс или нет, а проверять лень, то можно в сомнительных местах использовать
var stringBox = await Hive.openBox<String>('name_of_the_box');
- в случае если бокс уже открыт, этот вызов просто вернет инстанс уже открытого бокса.
Если посмотреть исходный код пакета, то можно увидеть несколько вспомогательных методов:
/// Returns a previously opened box. Box<E> box<E>(String name); /// Returns a previously opened lazy box. LazyBox<E> lazyBox<E>(String name); /// Checks if a specific box is currently open. bool isBoxOpen(String name); /// Closes all open boxes. Future<void> close();
Devhack Вообще, так как Flutter — полный open source, то можно лезть в любые методы и пакеты, что зачастую быстрее и понятнее, чем читать документацию.
LazyBox — для больших массивов данных
Когда мы создаем обычный бокс, то все его содержимое хранится в памяти. Это дает высокое быстродействие. В таких боксах удобно хранить настройки пользователя, какие-то небольшие данные.
Если данных много, то лучше создавать боксы lazily
var lazyBox = await Hive.openLazyBox('myLazyBox'); var value = await lazyBox.get('lazyVal');
При его открытии Hive считывает ключи и хранит их в памяти. Когда мы запрашиваем данные, то Hive знает положение данных на диске и быстро считывает их.
Шифрование боксов
Hive поддерживает AES-256 шифрование данных в боксе.
Для создания 256-битного ключа мы можем использовать встроенную функцию
var key = Hive.generateSecureKey();
которая создает ключ используя Fortuna random number generator.
После создания ключа создаем бокс
var encryptedBox = await Hive.openBox('vaultBox', encryptionKey: key); encryptedBox.put('secret', 'Hive is cool'); print(encryptedBox.get('secret'));
Особенности:
- Шифруются только значения, ключи хранятся как plaintext.
- При закрытии приложения ключ можно хранить с помощью пакета flutter_secure_storage или использовать свои методы.
- Нет встроенной проверки корректности ключа, поэтому, в случае неправильного ключа мы должны сами программировать поведение приложения.
Сжатие боксов
Как обычно, если мы удаляем или меняем данные, то они пишутся по нарастающей в конец бокса.
Мы можем делать сжатие, например при закрытии бокса при выходе из приложения
var box = Hive.box('myBox'); await box.compact(); await box.close();
Приложение todo_hive_example
Ок, это вроде бы все, напишем приложение, которое потом расширим для работы с бэкендом.
Модель данных у нас уже есть, интерфейс сделаем простой.
Экраны:
- Главный экран — список дел + весь функционал
- Экран добавления дела
Действия:
- Кнопка + добавляет дело
- Нажатие на галочку — переключение выполнено \ не выполнено
- Смахивание в любую сторону — удаление
Создание приложения Действие 1 — добавить
Создаем новое приложение, удаляем комменты, всю структуру оставляем (нам понадобится кнопочка +.
Модель данных кладем в отдельную папку, запускаем команду для создания генератора.
Создаем список общих дел.
Для построения списка дел используем встроенное расширение (да, в Dart пару месяцев назад добавили расширения (extensions)), которое лежит тут /hive_flutter-0.3.0+2/lib/src/box_extensions.dart
/// Flutter extensions for boxes. extension BoxX<T> on Box<T> { /// Returns a [ValueListenable] which notifies its listeners when an entry /// in the box changes. /// /// If [keys] filter is provided, only changes to entries with the /// specified keys notify the listeners. ValueListenable<Box<T>> listenable({List<dynamic> keys}) => _BoxListenable(this, keys?.toSet()); }
Мы кстати сами можем легко создавать подобные расширения, чем займемся в усложненном варианте приложения в следующей статье.
Итак, создаем список дел, который сам будет обновляться при изменении бокса
body: ValueListenableBuilder( valueListenable: Hive.box<Todo>(HiveBoxes.todo).listenable(), builder: (context, Box<Todo> box, _) { if (box.values.isEmpty) return Center( child: Text("Todo list is empty"), ); return ListView.builder( itemCount: box.values.length, itemBuilder: (context, index) { Todo res = box.getAt(index); return ListTile( title: Text(res.task), subtitle: Text(res.note), ); }, ); }, ),
Пока список пустой. Теперь при нажатии кнопочки + сделаем добавление дела.
Для этого создаем экран с формой, на который перекидываем при нажатии кнопочки +.
На этом экране при нажатии кнопки Add вызываем код, который добавляет запись в бокс и перекидывает обратно на главный экран.
void _onFormSubmit() { Box<Todo> contactsBox = Hive.box<Todo>(HiveBoxes.todo); contactsBox.add(Todo(task: task, note: note)); Navigator.of(context).pop(); }
Все, первая часть готова, это приложение уже умеет добавлять Todo. При перезапуске приложения все данные сохраняются в Hive.
Коммит на github приложения на этой стадии.
Создание приложения Действие 2 — переключение выполнено \ не выполнено
Тут все совсем просто. Мы используем метод сохранения, который получили наследовав наш class Todo extends HiveObject
Заполняем два свойства и всё готово
leading: res.complete ? Icon(Icons.check_box) : Icon(Icons.check_box_outline_blank), onTap: () { res.complete = !res.complete; res.save(); });
Коммит на github приложения на этой стадии.
Создание приложения Действие 3 — смахивание влево — удаление
Тут тоже все просто. Оборачиваем виджет в котором хранится дело в dismissable и опять используем сервисный метод удаления.
background: Container(color: Colors.red), key: Key(res.id), onDismissed: (direction) { res.delete(); },
Вот и все, мы получили полностью рабочее приложение, которое хранит данные в локальной базе.
Код приложения на github — https://github.com/awaik/todo_hive_example
To be continued:
- В следующей статье прикрутим авторизацию с паттерном BLoC. Через почту, гугл, Apple Id.
- Потом добавим синхронизацию с бэкендом Firebase через GraphQl по пути рассмотрев проблему устойчивого обновления короткоживущих токенов. Рассмотрим также устойчивую синхронизацию в обе стороны бэкенда и фронтэнда в неустойчивой среде мобильного приложения (прошу прощения за тавтологию).

