

В прошлом посте я начал разбираться в двухступенчатых Object Detection моделях и рассказал о самой базовой и, соответственно, первою из них – R-CNN. Сегодня мы рассмотрим другие модели этого семейства: Fast R-CNN и Faster R-CNN. Поехали!
Fast R-CNN
Поскольку R-CNN является медленной и не очень эффективной сетью, довольно быстро теми же авторами было предложено улучшение в виде Fast R-CNN сети.
Процесс обработки изображения изменился и выглядит следующим образом:
- Извлечение карты признаков изображения (не для каждой гипотезы по отдельности, а для всего изображения целиком);
- Поиск гипотез (аналогично R-CNN на основе Selective Search);
- Сопоставление каждой гипотезы с местом на карте признаков – т.е. использование единого набора выделенных признаков для каждой гипотезы (координаты гипотез можно однозначно сопоставить с местоположением на карте признаков);
- Классификация каждой гипотезы и исправление координат ограничивающей рамки (эту часть стало возможным запускать параллельно, поскольку больше нет зависимости от SVM-классификации).
RoI layer
В изначальной концепции R-CNN каждая предложенная гипотеза по отдельности обрабатывается с помощью CNN – такой подход стал своеобразным бутылочным горлышком. Для решения этой проблемы был разработан Region of Interest (RoI) слой. Этот слой позволяет единожды обрабатывать изображение целиком с помощью нейронной сети, получая на выходе карту признаков, которая далее используется для обработки каждой гипотезы.
Основной задачей RoI слоя является сопоставление координат гипотез (координаты ограничивающих рамок) с соответствующими координатами карты признаков. Делая «срез» карты признаков, RoI слой подает его на вход полносвязному слою для последующего определения класса и поправок к координатам (см. следующие разделы).
Появляется логичный вопрос – как подать на вход полносвязному слою гипотезы разного размера и соотношения сторон? Для этого и необходим RoI слой, который преобразовывает изображение с размерами
 в размеры
в размеры  . Для этого необходимо исходное изображение разделить на сетку размером (размер ячейки примерно
. Для этого необходимо исходное изображение разделить на сетку размером (размер ячейки примерно  ) и из каждой ячейки выбрать максимальное число.
) и из каждой ячейки выбрать максимальное число. Допустим, имеются карта признаков размером 5×5 и нужная гипотеза на этой карте имеет координаты (1,1,4,5) (первые две координаты – левый верхний угол, последние две – правый нижний). Последующий полносвязный слой ожидает размерность 4×1 (т.е. вытянутую 2×2 матрицу). Тогда поделим гипотезу на неодинаковые блоки разной размерности (этап Pooling) и возьмем в каждом из них максимальное число (этап Pooling и как результат этап Output).

Таким образом становится возможным обработать целиком изображение, а потом работать с каждой гипотезой на основе карты признаков.
Итог:
- Вход: координаты гипотезы и карта признаков изначального изображения;
- Выход: векторное представление гипотезы.
Полносвязный слой и его выходы
В предыдущей версии R-CNN использовались отдельные SVM-классификаторы, в данной же реализации они заменены одним SoftMax выходом размерности
 . Отмечается, что при этом потеря точности составляет менее 1 %.
. Отмечается, что при этом потеря точности составляет менее 1 %.Выход регрессоров обрабатывается с помощью NMS (Non-Maximum Suppression).
Итог:
- Вход: векторное представление гипотезы;
- Выход: вероятности принадлежности гипотезы к классам и поправки к координатам ограничивающей рамки.
Multi-task loss
В одновременном обучении сети для задач регрессии ограничивающих рамок и классификации применяется специальная лосс-функция:
![$L(P,u,t^{u},v)=L_{cls}(P,u)+\lambda[u≥1]L_{loc}(t^{u},v)$](https://habrastorage.org/getpro/habr/formulas/325/4ab/0a0/3254ab0a06549c1c2eaa734e6f4e94af.svg)
Здесь:
 необходим для настройки баланса между двумя функции (авторы использовали =1);
необходим для настройки баланса между двумя функции (авторы использовали =1); — правильный класс;
— правильный класс; представляет собой функции ошибки для классификации
представляет собой функции ошибки для классификации  ;
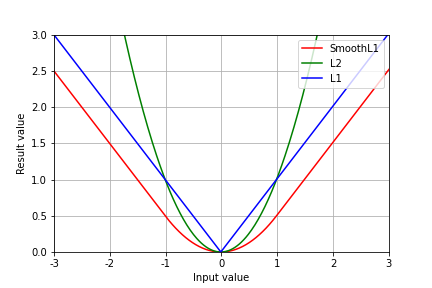
; является SmoothL1-функцией и измеряет разницу между
является SmoothL1-функцией и измеряет разницу между  и
и  значениями:
значениями:

Здесь, обозначает разность целевого значения и предсказания
обозначает разность целевого значения и предсказания  . Такая функция сочетает в себе преимущества L1 и L2 функции, поскольку является устойчивой при больших значениях и не сильно штрафует при малых значениях.
. Такая функция сочетает в себе преимущества L1 и L2 функции, поскольку является устойчивой при больших значениях и не сильно штрафует при малых значениях.
Обучение
Для лучшей сходимости авторы использовали следующий подход формирования батча:
- Выбирается количество гипотез в батче
 .
. - Выбирается случайно
 изображений.
изображений. - Для каждого из изображений берется
 гипотез (т.е. равномерно на каждое изображение).
гипотез (т.е. равномерно на каждое изображение).
При этом в R включаются как позитивные (25 % всего батча), так и негативные (75 % всего батча) гипотезы. Позитивными считаются гипотезы, которые перекрываются с правильным местоположением объекта более чем на 0.5 (IoU). Негативные же берутся по правилу Hard Negative Mining – наиболее ошибочные экземпляры (те, у кого IoU в диапазоне [0.1,0.5).
При этом авторы утверждают, что при параметрах
 и
и  сеть учится в разы быстрее, чем при
сеть учится в разы быстрее, чем при  и (т.е. по одной гипотезе из каждого изображения).
и (т.е. по одной гипотезе из каждого изображения).Faster R-CNN
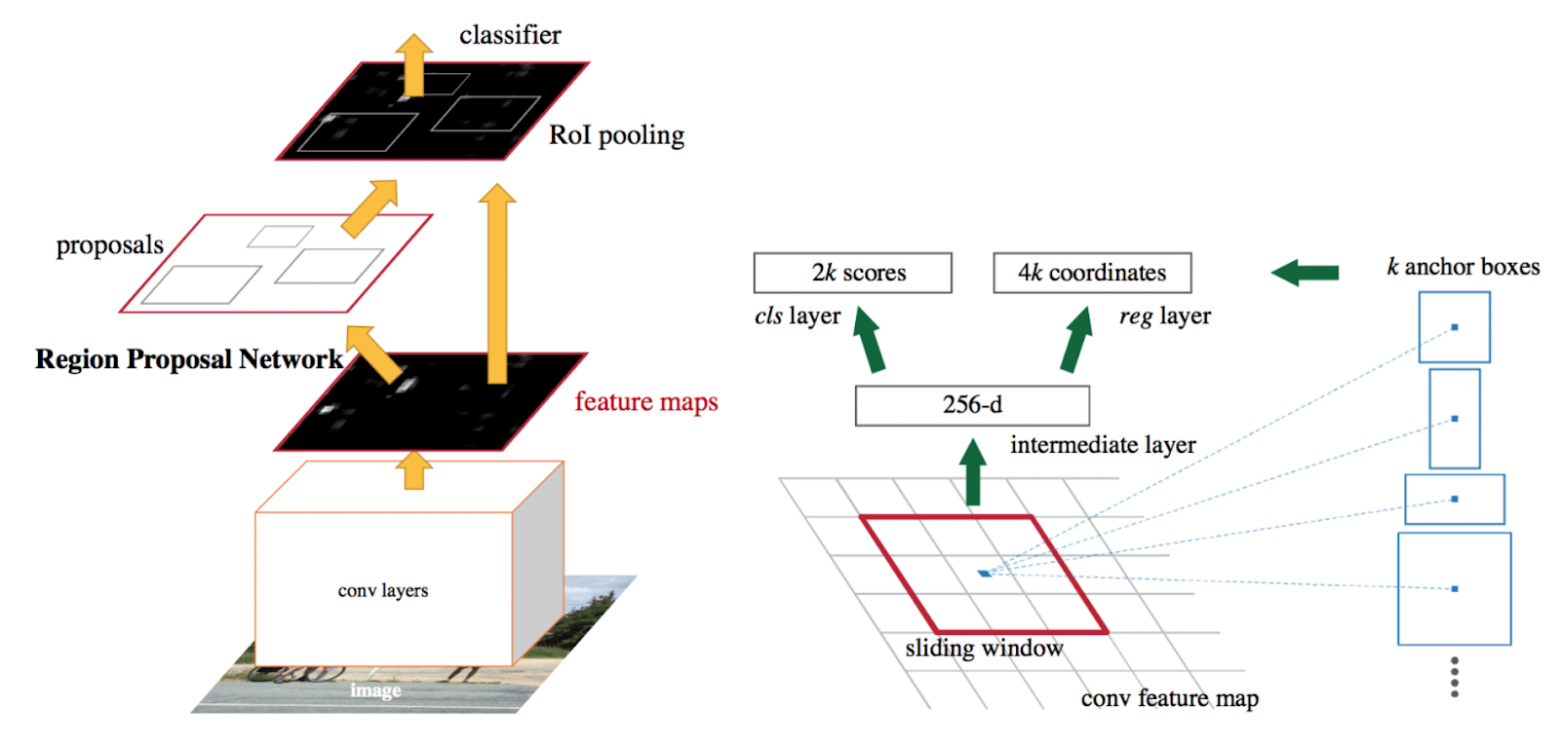
Дальнейшим логичным улучшением является способ устранения зависимости от Selective Search алгоритма. Для этого представим всю систему как композицию двух модулей – определение гипотез и их обработка. Первый модуль будет реализовываться с помощью Region Proposal Network (RPN), а второй аналогично Fast R-CNN (начиная с RoI слоя).
Следовательно, в этот раз процесс работы с изображением изменился и теперь происходит таким образом:
- Извлечение карты признаков изображения c помощью нейронной сети;
- Генерация на основе полученной карты признаков гипотез – определение приблизительных координат и наличие объекта любого класса;
- Сопоставление координат гипотез с помощью RoI с картой признаков, полученной на первом шаге;
- Классификация гипотез (уже на определение конкретного класса) и дополнительное уточнение координат (на самом деле, может и не применяться).
Основное улучшение произошло именно в месте генерации гипотез – теперь для этого есть отдельная небольшая нейронная сеть, которую назвали Region Proposal Network.
Region Proposal Network
Конечной задачей данного модуля является полноценная замена Selective Search алгоритма. Для более быстрой работы необходимы общие веса с сетью, извлекающей необходимые признаки. Поэтому входом RPN является карта признаков, полученная после этой сети. Авторы оригинальной статьи используют для извлечения признаков сеть VGG16, выходом которой считают последний сверточный слой – conv5_3. Такая сеть имеет следующие характеристики рецептивного поля:
- Эффективное сжатие (effective strides,
 ): 16
): 16 - Размер рецептивного поля (receptive field size,
 ): 196
): 196
Это значит, что карта признаков будет в 16 раз меньше изначального размера изображения (количество каналов равно 512), а на каждое значение в ее ячейках оказывают влияние пиксели изначального изображения, лежащие в прямоугольнике размером 196×196. Таким образом выходит, что если использовать стандартный вход VGG16 224×224, то на формирование значения центральной ячейки карты признаков (14,14) будет влиять почти все изображение целиком! На основе полученной карты признаков RPN для каждой ячейки выдает
 гипотез (в изначальной реализации
гипотез (в изначальной реализации  ) разного размера и соотношения сторон. Так, для стандартного размера это 14×14×9=1764 гипотезы!
) разного размера и соотношения сторон. Так, для стандартного размера это 14×14×9=1764 гипотезы!На основе изображения ниже рассмотрим алгоритм работы RPN модуля подробнее (картинка кликабельная):

- Получим карту признаков
 с предыдущего шага.
с предыдущего шага. - Применим сверточный слой 3×3 (отступ равен единице – итоговая матрица не меняется в размерах). По всей видимости, этот шаг применяется авторами для дополнительного наращивания рецептивного поля (
 ,
,  ).
).
- Ячейке (
 ) карты признаков соответствует вектор размерности
) карты признаков соответствует вектор размерности  (в нашем случае 512).
(в нашем случае 512).
- К каждому такому вектору применимы два сверточных слоя с ядром 1×1 и количеством выходных каналов
 (ядро такого размера просто отображает размерность в ):
(ядро такого размера просто отображает размерность в ):
- Первой слой (cls) имеет параметр
 – необходим для определения вероятности наличия или отсутствия какого-либо объекта внутри гипотезы (классификация с 2 классами).
– необходим для определения вероятности наличия или отсутствия какого-либо объекта внутри гипотезы (классификация с 2 классами). - Второй слой (reg) имеет параметр
 – необходим для определения координат гипотез.
– необходим для определения координат гипотез.
Отметим, что полученные вектора можно переформировать в матрицы и
и  . Таким образом получаем матрицы, где
. Таким образом получаем матрицы, где  строке соответствуют значения для конкретной гипотезы.
строке соответствуют значения для конкретной гипотезы. - Первой слой (cls) имеет параметр
Возникает вполне логичный вопрос, как из вектора, который поступает в reg слой можно определить абсолютные координаты гипотез? Ответ прост – никак. Для правильного определения координат необходимо использовать так называемые якоря (anchors) и поправки к их координатам.
Якорем называют четырехугольник разного соотношения сторон (1:1, 2:1, 1:2) и размеров (128×128, 256×256, 512×512). Центром якоря считается центр ячейки (
) карты признаков. Так, например, возьмем ячейку (7,7), центром которой являются значения (7.5,7.5), что соответствует координатам (120,120) исходного изображения (16×7.5). Сопоставим с этими координатами прямоугольники трех соотношений сторон и трех размеров (всего получается 3×3=9). В будущем слой reg по отношению к этим координатам будет выдавать соответствующие правки, тем самым корректируя местоположение и форму ограничивающей рамки. Итог:
- Вход: карта признаков изначального изображения;
- Выход: гипотезы, содержащие какой-либо объект.
Loss функция
Для обучения RPN используется следующее обозначение классов:
- Позитивными являются все якоря, имеющие пересечение (IoU) более 0.7 или имеющие наибольшее пересечение среди всех якорей (применяется в случае, если нет пересечения более 0.7).
- Негативными являются все якоря, имеющие пересечение менее 0.3.
- Все остальные якоря не участвуют в обучении (по сути, они являются нейтральными).
Таким образом класс
 якоря присуждается по следующему правилу:
якоря присуждается по следующему правилу:
С такими обозначениями минимизируется следующая функция:

Здесь:
- – номер якоря;
 – вероятность нахождения объекта в якоре;
– вероятность нахождения объекта в якоре;- – правильный номер класса (обозначен выше);
 – 4 предсказанные поправки к координатам;
– 4 предсказанные поправки к координатам; – ожидаемая (ground truth) поправки к координатам;
– ожидаемая (ground truth) поправки к координатам; – бинарный log-loss;
– бинарный log-loss; – SmoothL1 лосс. Активируется только в случае
– SmoothL1 лосс. Активируется только в случае  , т.е. если гипотеза содержит хоть какой-нибудь объект;
, т.е. если гипотеза содержит хоть какой-нибудь объект; и
и  – выходы классификационной и регрессионной модели соответственно;
– выходы классификационной и регрессионной модели соответственно;- – коэффициент для настройки баланса между классификацией и регрессией.
Обе части комбинированного лосса нормализуются на
 и
и  соответственно. Авторы использовали равный размеру мини-батча (256), а равный количеству якорей.
соответственно. Авторы использовали равный размеру мини-батча (256), а равный количеству якорей.Для регрессии поправок к ограничивающим рамкам значения инициализируются и подсчитываются следующим образом:

Здесь
,  ,
,  и
и  обозначают центр, ширину и высоту ограничивающей рамки. Переменные ,
обозначают центр, ширину и высоту ограничивающей рамки. Переменные ,  и
и  обозначают предсказание, ground truth и значение якорей (для , и аналогично).
обозначают предсказание, ground truth и значение якорей (для , и аналогично). Обучение на полном списке якорей будет иметь смещение в сторону отрицательного класса (гипотез с таким классом в разы больше). В связи с этим мини-батч формируется в соотношении 1:1 позитивных якорей к негативным. В случае, если не удается найти соответствующее количество позитивных якорей, мини-батч дозаполняется с помощью негативных классов.
Общее обучение сети
Основной задачей является совместное использование весов между двумя модулями –это повысит скорость работы. Поскольку невозможно (или довольно-таки сложно) обучить сразу два независимых модуля, авторы статьи используют итеративный подход:
- Тренировка RPN сети. Сверточные слои инициализируются весами, ранее полученными при тренировке на ImageNet. Дообучаем на задаче определения регионов с каким-либо классом (уточнение класса занимается часть Fast R-CNN).
- Тренировка Fast R-CNN сети. Так же, как и в п.1 инициализируем Fast R-CNN весами, ранее полученными при обучении на ImageNet. Дообучаем, используя гипотезы об объектах с помощью RPN сети, обученной в п.1. В этот раз задачей обучения является уточнение координат и определение конкретного класса объекта.
- Используя веса из п.2 обучаем только RPN часть (слои, идущие до RPN сети, принадлежащие feature extractor, замораживаются и никак не изменяются).
- Используя веса из п.3 (то есть, уже более точно настроенный RPN), обучаем слои для Fast R-CNN (остальные веса – идущие ранее или относящиеся к RPN — заморожены).
С помощью такого итеративного обучения получается, что вся сеть построена на одних и тех же весах. Можно и дальше обучать сеть по такому принципу, но авторы отмечают, что сильных изменений в метриках нет.
Процесс предсказания
Во время использования нейронных сетей для предсказаний прохождение изображения выглядит так:
- Изображение поступает на вход нейронной сети, генерируя карту признаков.
- Каждая ячейка карты признаков обрабатывается с помощью RPN, выдавая в результате поправки к положению якорей и вероятность наличия объекта любого класса.
- Соответствующие предсказанные рамки далее на основе карты признаков и RoI слоя поступают в дальнейшую обработку Fast R-CNN части.
- На выходе получаем уже конкретный класс объектов и их точное положение на изображении.
Итоговые различия
Приведем краткое резюме моделей между собой (базовые идеи наследуется от более младшей к более старшей):
R-CNN:
- Использование Selective Search как генератор гипотез.
- Использование SVM + Ridge для классификации и регрессии гипотез (причем их параллельная работа не возможна).
- Запуск нейронной сети для обработки каждой гипотезы по отдельности.
- Низкая скорость работы.
Fast R-CNN:
- Нейронная сеть запускается только один раз на изображение – все гипотезы проверяются на основе единой карты признаков.
- «Умная» обработка гипотез разного размера за счет RoI слоя.
- Замена SVN на SoftMax слой.
- Возможность параллельной работы классификации и регрессии.
Faster R-CNN:
- Генерация гипотез с помощью специального отдельно дифференцируемого модуля.
- Изменения в процессе обработки изображения, связанные с появлением RPN модуля.
- Самая быстрая из этих трех моделей.
- Является одной из самых точных и по сей день.
Заключение
В заключение можно сказать, что развитие R-CNN двигалось от разрозненных алгоритмов, решающих одну задачу в сторону единого end-to-end решения. Такое объединение позволяет сделать почти любой подход более точным и наиболее производительным, Object Detection не стал исключением.
Список литературы
- R. Girshick, J. Donahue, T. Darrell, and J. Malik. «Rich feature hierarchies for accurate object detection and semantic segmentation.» In CVPR, 2014. arXiv:1311.2524
- R. Girshick, J. Donahue, T. Darrell, and J. Malik. «Region-based convolutional networks for accurate object detection and segmentation.» TPAMI, 2015
- R. Girshick, «Fast R-CNN,» in IEEE International Conference on Computer Vision (ICCV), 2015.
- S. Ren, K. He, R. Girshick, and J. Sun, «Faster R-CNN: Towards real-time object detection with region proposal networks,» in Neural Information Processing Systems (NIPS), 2015.
