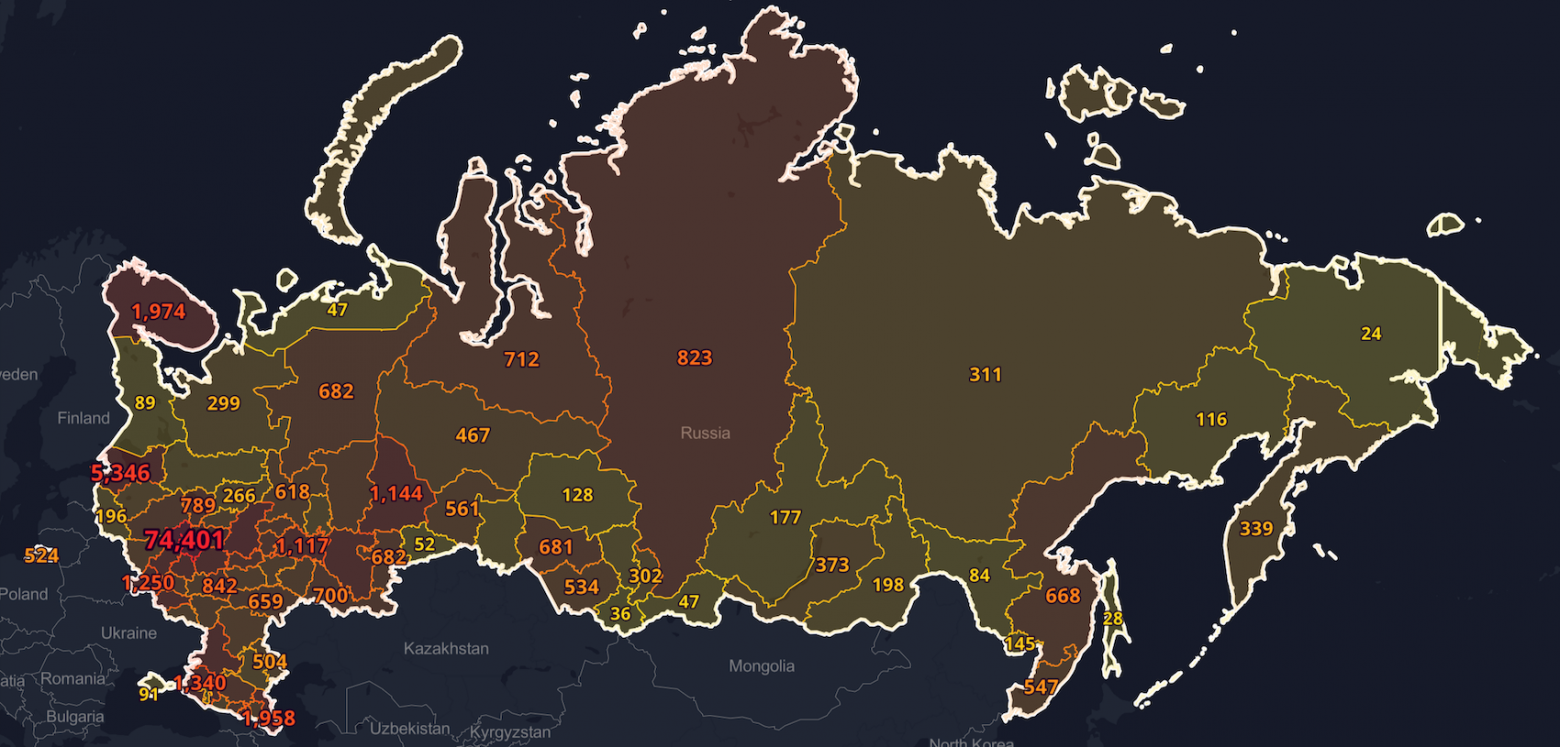
Наша команда занимается созданием информационного сервиса по отображению глобальных данных для многих стран, городов и территорий — Routitude. К концу февраля этого года стремительное распространение коронавируса по всему миру побудило нас внедрить дополнительный функционал для мониторинга ситуации в наше приложение. Помимо визуализации данных в веб-интерфейсе, основным компонентом реализации этой задачи стал микросервис, написанный на Python с использованием популярного веб-фреймворка Flask.
Сервис регулярно обновляет данные из различных источников и по запросу отдает необходимую информацию для визуализации в веб-интерфейсе. Основным источником данных являются страницы Википедии, посвященные распространению вируса в странах и территориях. Таблицы с показателями на этих страницах оперативно обновляются и отлично подходят в качестве источника данных для сервиса по мониторингу распространения инфекции.
В статье я расскажу про основные компоненты сервиса, от получения и обновления данных до создания API для клиентских запросов. Код проекта доступен в github репозитории.
Проект может быть полезным тем, кто интересуется созданием микросервисов на Python с помощью Flask фреймворка и хочет опробовать навыки на базе реальной задачи. Также, в статье описаны простые способы получения данных из Википедии, которые могут быть применены для обогащения информацией того или иного приложения. В целом, проект готов к использованию для создания собственного сервиса по мониторингу распространения инфекции COVID-19.
Конфигурация и структура Flask сервиса
Для реализации проекта нам понадобится Python и любая база данных, которая поддерживается популярной библиотекой для описания ORM моделей в Python SQLAlchemy. В Routitude мы используем PostgreSQL.
Первым делом необходимо клонировать репозиторий с проектом и установить необходимые зависимости:
pip install requirements.txt
Для успешного взаимодействия с базой данных нужно установить переменную окружения с URI до нее:
export COVID19API_DB_URI=<ваш БД URI, пример: postgresql://localhost/covid19api>
На этом вся необходимая конфигурация заканчивается. Теперь давайте познакомимся со структурой проекта:
/api Логика формирования ответов API covid.py Формирование ответов API c данными по COVID-19 из БД /datasources Источники данных /test Тесты сбора данных из источников test_covid.py Тесты сбора и обработки данных по COVID-19 из Википедии covid_wiki.py Сбор данных по распространению COVID-19 со страниц Википедии utils.py Вспомогатильный набор функций для обработки данных /mirgations Миграции БД на базе SQLAlchemy ... Автогенерируемый код Flask-Migrate (Alembic) /test Тесты проекта test_app.py Тесты приложения (API) app.py Входная точка приложения и реализация методов HTTP запросов appvars.py Инициализация основных компонент сервиса config.py Конфигурация приложения manage.py Реализация CLI методов для работы с сервисом models.py ORM модель и логика обновления данных в БД requirements.txt Список необходимых зависимостей
Итого, наш сервис состоит из четырех основных компонент:
- сбор данных из Википедии для стран и территорий, а также административных делений США и России;
- создание ORM модели со статистикой по COVID-19;
- разработка логики обновления данных в БД;
- реализация API для обработки запросов и формирования ответов, содержащих требуемые показатели.
Рассмотрим их подробнее в следующих разделах. Перед каждым блоком кода будет приведена ссылка на соответствующий файл в github репозитории, в котором можно глубже погрузится в проект и изучить все вспомогательные методы, неупомянутые в статье.
Сбор данных по коронавирусу из Википедии
Данные по распространению коронавируса регулярно обновляются на соответствующих страницах в Википедии и хорошо структурированы в виде таблиц. Ознакомиться с содержимым интересующих нас страниц можно по ссылкам:
- Пандемия коронавируса по странам и территориям
- Пандемия коронавируса в России
- Хронология пандемии коронавируса в США
Нас интересуют данные из таблиц со следующими показателями:
- Количество подтвержденных случаев заражения
- Количество смертей
- Количество восстановившихся пациентов
Одним из самых простых способов получения таблиц с html страницы является метод read_html из популярного пакета для анализа данных Pandas. Данный метод возвращает список всех найденных таблиц на странице. Обычно нас интересует конкретная таблица. Мы можем понять ее порядок, однако, он может легко измениться при редактировании страницы. При этом, часть содержимого текста в таблице будет меняться значительно реже, чем ее порядок. Таким образом, мы можем идентифицировать нужную таблицу по вхождению в нее определенного текста. Ниже приведен метод для получения Pandas DataFrame, содержащего данные из таблицы, найденной на заданной html странице по вхождению указанной строки.
import pandas as pd def get_wiki_table_df(page_url, match_string): response = requests.get(page_url) tables = pd.read_html(response.content) df = None for table in tables: df = table if match_string in str(df): break return df
Будем использовать описанный метод для получения необходимых данных с каждой из интересующих нас страниц. Следующий блок кода содержит метод возвращающий таблицу со статистикой распространения вируса по странам и территориям. По аналогии, модуль содержит методы для получения подобных данных по распространению инфекции COVID-19 в отдельных административных субъектах России и США.
def get_report_countries(): url = ( 'https://en.wikipedia.org/wiki/' '2019%E2%80%9320_coronavirus_pandemic_by_country_and_territory' ) df = utils.get_wiki_table_df(url, 'Locations[b]') df = pd.DataFrame( df.values[:, 1:5], columns=['country', 'confirmed', 'deaths', 'recovered'] ) df = df[~df['country'].isna()] df['country'] = df['country'].apply(lambda x: utils.clean_territory_name(x)) df.drop(df[df['country'].str.len() > 40].index, inplace=True) df = utils.wiki_table_df_numeric_column_clean(df, [ 'confirmed', 'deaths', 'recovered' ]) df['state'] = None check_report(df) return df
Для того чтобы оперативно реагировать на изменения в структуре html страниц и, в целом, для более комфортной дальнейшей разработки, покроем тестами методы получения данных.
datasources/test/test_covid.py
from unittest import TestCase from datasources import covid_wiki class TestCovid(TestCase): def test_get_wiki_report(self): report = covid_wiki.get_report_countries() self.assertTrue('Russia' in list(report['country'])) self.assertTrue(report.shape[0] > 0)
Для запуска тестов можно воспользоваться следующей командой:
nosetests datasources
Создание SQLAlchemy ORM модели в Flask приложении
После того как мы научились собирать данные из источника, самое время подумать о том, как их хранить и обновлять. Популярным решением этой проблемы является создание связи между Python объектами, описывающими данные, и таблицами в базе данных, которые их хранят. Формально это называется объектно-реляционное отображение (Object-Relational Mapping, ORM). Классическим инструментом в Python для создания ORM модели является библиотека SQLAlchemy. Помимо нее, нам понадобится инструмент для создания миграций базы данных, который берет на себя всю работу по созданию, редактированию и версионированию таблиц в базе данных на основе SQLAchemy объектов. С такими задачами отлично справляется пакет Alembic. Но мы пойдем выше и будем использовать обертку над ним, специально созданную для Flask приложений, Flask-Migrate. Конфигурация данного инструмента сводится к инициализации нескольких объектов в appvars.py и manage.py.
Для того чтобы создать ORM модель необходимо унаследовать класс от объекта Model из пакета SQLAlchemy. Далее требуется описать каждое поле в таблице в виде атрибутов класса с помощью объектов SQLAchemy для разных типов полей. Помимо этого, можно задать индексы на указанные поля как показано в примере ниже. В этом примере создается ORM модель для таблицы с данными о распространение коронавируса в различных странах и территориях.
class CovidWiki(db.Model): __tablename__ = 'covid_wiki' territory_id = Column( db.VARCHAR(length=256), nullable=False, primary_key=True ) update_time = Column(db.TIMESTAMP(), nullable=False) country = Column(db.VARCHAR(length=128), nullable=False) state = Column(db.VARCHAR(length=128), nullable=True) confirmed = Column(db.INTEGER(), nullable=True) deaths = Column(db.INTEGER(), nullable=True) recovered = Column(db.INTEGER(), nullable=True) Index('ix_covid_wiki_country', CovidWiki.country) Index('ix_covid_wiki_state', CovidWiki.state)
Если вы не работаете с готовым проектом из репозитория, а начали проект с нуля, прежде всего необходимо инициализировать хранилище миграций на базе Alembic:
python manage.py db init
Эта команда создаст папку migrations со всем необходимым для дальнейшей работы содержимым. Для того чтобы создать миграции для базы данных на основе описанной ORM модели нужно выполнить следующую команду:
python manage.py db migrate -m covid_wiki
При использовании готового проекта из репозитория, исполнять приведенные выше команды не нужно, так как они уже были выполнены и, следовательно, код для создания в базе данных объектов, соответствующих описанной модели, был сгенерирован. Этот код находится в папке migrations/versions. Она, в свою очередь, хранит набор скриптов python, соответствующих версиям состояний базы данных. Каждый файл состоит из 2 методов — upgrate и downgrade. Первый метод трансформирует содержимое базы данных к текущей версии ORM модели, а второй реализует набор действий с базой данных для того, чтобы привести ее к состоянию предыдущей версии.
Предыдущая команда генерирует код для создания миграции для текущего состояния, но не приводит его в действие. Для того чтобы применить изменения и исполнить код текущей миграции необходимо выполнить команду:
python manage.py db upgrade
Теперь все необходимые таблицы и индексы в базе данных созданы и мы готовы пополнять ее данными по распространению коронавируса.
Логика обновления данных по COVID-19 в БД
Для обновления данных в БД создадим метод в классе ORM модели, который будет принимать pandas DataFrame с данными по коронавирусу, сравнивать записи в нем с записями в базе данных и, если они изменились или не нашлись, записывать показатели в таблицу. Помимо основной статистики, будем фиксировать время последнего обновления данных по каждой записи в таблице. Для всех операций, связанных с получением данных из БД и записи в нее, используются вспомогательные методы SQLAlchemy.
def update_data_by_dataframe(self, df): report = df.to_dict(orient='records') report_last = self.get_wiki_last_report() for value in report: territory_id = self.get_id(value['country'], value['state']) value['territory_id'] = territory_id changed = ( (len(report_last) == 0) or (territory_id not in report_last) or (utils.get_covid_values_sum(value) != utils.get_covid_values_sum(report_last[territory_id])) ) if not changed: continue logging.info(f"Updating data for territory: {territory_id}") data = dict(value) for name in utils.STAT_NAMES: value = data[name] if np.isnan(value): data[name] = None continue data[name] = int(value) data['update_time'] = datetime.datetime.now() report = CovidWiki(**data) db.session.merge(report) db.session.commit()
Далее объединим получение данных по странам и административным субъектам России и США в один метод для обновления показателей из всех отчетов. Для этого будем последовательно вызывать вышеописанный метод и передавать в него результат получения данных из Википедии для каждого из отчетов.
def update_data(self): logging.info('Updating countries data') self.update_data_by_dataframe(covid_wiki.get_report_countries()) logging.info('Updating Russian states data') self.update_data_by_dataframe(covid_wiki.get_report_ru()) logging.info('Updating USA states data') self.update_data_by_dataframe(covid_wiki.get_report_us())
Расширение для Flask приложений Flask-Script позволяет нам быстро и удобно создать простой консольный интерфейс для запуска различных скриптов из командной строки. Используя это пакет для того, чтобы превратить метод в исполняемый скрипт, достаточно добавить декоратор manager.command перед его объявлением. Воспользуемся этим инструментом для создания скрипта обновления данных в БД.
@manager.command def update_covid_data(): CovidWiki().update_data()
Теперь, для получения и обновления данных в ДБ, достаточно выполнить следующую команду:
python manage.py update_covid_data
Выполнение этой команды имеет смысл запускать с использованием какого-либо инструмента для автоматического исполнения заданий по расписанию, например cron.
Реализация API с данными по COVID-19 с помощью Flask
Основной целью сервиса является обработка клиентских запросов и формирование ответов с требуемой информацией по распространению коронавируса. Пришло время реализовать этот функционал в нашем Flask приложении. Как мы уже выяснили, SQLAlchemy предоставляет набор удобных инструментов для получения записей из базы данных. Воспользуемся ими и создадим набор методов, возвращающих следующие статистические показатели распространения инфекции COVID-19:
- базовые показатели по странам и территориям;
- показатели административных субъектов по заданной стране;
- агрегированные показатели по всему миру.
def get_covid_countries_report(): data = db.session.query(CovidWiki).filter(CovidWiki.state.is_(None)).all() return [v.to_dict() for v in data] def get_covid_states_report_by_country(country): data = db.session.query(CovidWiki).filter(and_( CovidWiki.state.isnot(None), func.lower(CovidWiki.country) == country.lower(), )).all() return [v.to_dict() for v in data] def get_covid_total_stats(): def to_dict(v): return {'confirmed': v[0], 'deaths': v[1], 'recovered': v[2]} curr = db.session.query( func.sum(CovidWiki.confirmed), func.sum(CovidWiki.deaths), func.sum(CovidWiki.recovered), func.max(CovidWiki.update_time) ).filter(CovidWiki.state.is_(None)).one() return { 'data': to_dict(curr), 'last_update_time': utils.datetime2string(curr[3], time=True) }
Завершим разработку приложения описанием конкретных ресурсов сервиса для каждого из методов API. Сделать это можно с помощью специальных декораторов, задающих адрес метода, по которому будет доступен соответсвующий ресурс.
@app.route('/covid/countries') def get_covid_countries_report(): report = covid_api.get_covid_countries_report() check_data(report) return jsonify(report) @app.route('/covid/states/<string:country>') def get_covid_states_report_by_country(country): report = covid_api.get_covid_states_report_by_country(country) check_data(report) return jsonify(report) @app.route('/covid/total') def get_covid_total_stats(): report = covid_api.get_covid_total_stats() check_data(report) return jsonify(report)
Остается запустить приложение и протестировать его работоспособность на базе сервера Flask для разработки.
python app.py
Теперь сервис доступен на указанном в выводе порту, и вы можете проверить корректность его работы, запрашивая ресурсы по заданным адресам в браузере или другими инструментами, например curl.
curl http://localhost:5000/covid/total
В проекте предусмотрено тестирование приложения. Тесты находятся в директории test, а запустить их можно следующей командой из корня проекта:
nosetests
Для промышленной эксплуатации запускайте сервис на базе промышленного веб-сервера. Популярными вариантами таких серверов для Python приложений являются gunicorn и uWSGI.
Подводя итоги
Описанный в статье сервис решает задачу сбора и обновления данных по распространению коронавируса в различных странах и территориях, а также административных субъектах России и США. Он позволяет обрабатывать клиентские запросы посредством API для предоставления информации, содержащей базовые показатели по распространению вируса. Данные из Википедии отлично подходят для отражения текущей ситуации, так как они оперативно обновляются и соответствуют официальным источникам по всем формальным признакам.
В Routitude мы используем этот сервис для отображения текущих показателей по распространению инфекции COVID-19 на карте и дашбордах. Все исходные материалы доступны в github репозитории. Приветствуются любые доработки, багфиксы, новые фичи и данные. Я буду рад любым замечаниям по статье и предложениям по улучшению проекта.

