Меня зовут Алексей Казаков, я техлид команды Клиентских коммуникаций в ДомКлике. В этой статье я хочу поделиться с вами «рецептом», который позволил нам реализовать отложенные ретраи при использовании брокера сообщений RabbitMQ

Введение
В ДомКлик существенная часть взаимодействия между сервисами реализована асинхронно за счет брокера сообщений RabbitMQ. Типичная схема взаимодействия выглядит так.

- Сервис A на своём RabbitMQ-virtual_host (service_a_vh):
- создаёт RabbitMQ-exchange (service_a_inner_exch), в который другие сервисы будут публиковать сообщения-задачи для сервиса A,
- создаёт RabbitMQ-queue (service_a_input_q), из которой сообщения будут попадать в сервис A,
- связывает service_a_input_q с service_a_inner_exch.
- Сервис B, получив доступ к service_a_vh, публикует в service_a_inner_exch сообщения, которые должны быть обработаны сервисом А.
Обычно сервису B нужны результаты выполнения опубликованных задач. Для этого создаётся обратный RabbitMQ-exchange, в который сервис A публикует результаты, а другие сервисы посредством RabbitMQ-routing_key получают только нужные им данные. Но для нашего «рецепта» это будет не нужно.
Отличные руководства по RabbitMQ можно найти на их сайте.
Постановка проблемы
Наша команда занимается доставкой всевозможных СМС/пушей/писем до клиентов, и для этих целей мы используем сторонних провайдеров, которые не входят в зону нашей ответственности. В общем случае схема выглядит так. Сервис A синхронно взаимодействует по HTTP с внешним сервисом E. Иногда сервис E может испытывать проблемы и не отвечать/таймаутить/пятисотить. Если несколько HTTP-ретраев с возрастающей задержкой не помогают и сервис E по-прежнему отказывается корректно работать, то что делать с сообщением?
RabbitMQ позволяет сделать reject with requeue, что вернет задачу в очередь и она не потеряется. Проблема заключается в том, что эта же задача очень быстро (~100 раз в секунду) снова попадет в consumer, и так мы будем порождать лишнюю нагрузку на сервис E (реальный случай из практики).
Возможные решения
1) Хранить сообщение в памяти приложения, продолжая ретраить.
Недостатки:
- Если consumer однопоточный, то таким образом мы блокируем выполнение других задач из очереди, а сервис E может испытывать проблемы именно с конкретной задачей.
- Хранить задачу в памяти приложения, пока идут ретраи (а это могут быть десятки минут), не выглядит хорошей идеей.
2) С помощью механизма RabbitMQ-dead_letter_exchange сохранять задачи до лучших времен в отдельной очереди мертвых задач и считывать их оттуда отдельным consumer-ом.
Недостатки:
- Ручной запуск дополнительного consumer требует вмешательства программиста.
- Автоматический запуск и остановка — нетривиальная задача, которая требует лишнего кода.
3) Сохранять таски в базе, откуда снова доставлять их в consumer по истечении таймаута.
Недостатки:
- Нужно писать код, который будет этим заниматься.
Выбранное нами решение
Последний вариант привлекателен тем, что тот же самый consumer будет заниматься обработкой задач. Вот бы ещё избавиться от необходимости работать с базой, ведь «Лучший код — не написанный код».
К счастью, можно реализовать механизм отложенных ретраев исключительно средствами RabbitMQ.
Для начала нужно узнать, что в RabbitMQ есть очереди с таймаутами: при создании очереди можно указать аргумент x-message-ttl, определяющий, сколько миллисекунд сообщение просуществует в очереди, прежде чем будет помечено «мертвым».
Ниже приведу схему очередей, описание маршрута задачи и минимальный код на Python, который позволит вам воспроизвести схему.

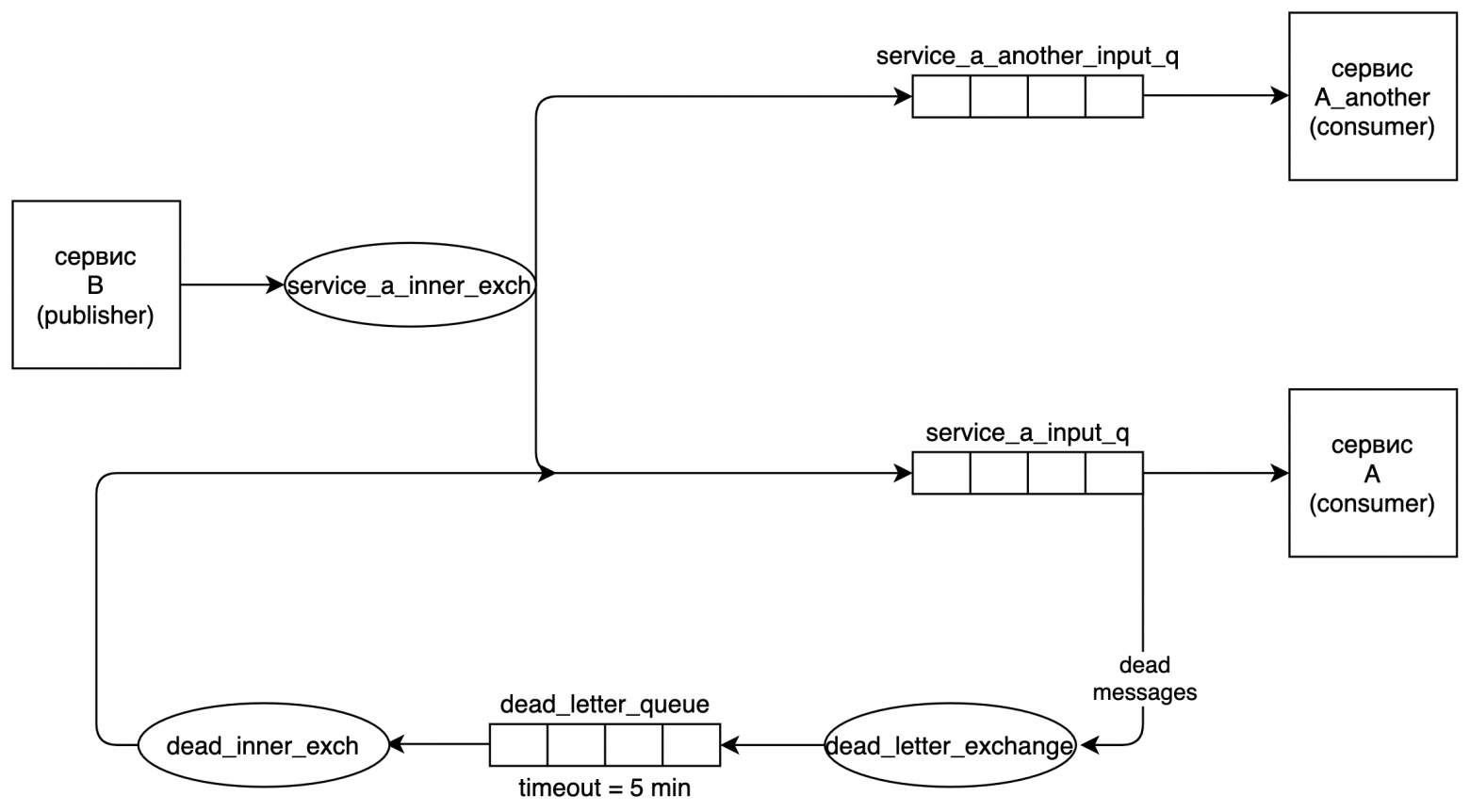
Все элементы схемы уже описаны ранее за исключением пути от dead_letter_queue в service_a_inner_exch. Такая «петля» получается за счет того, что для dead_letter_queue в качестве dead letter exchange мы указываем service_a_inner_exch. В этом и заключается основная идея. Мы зацикливаем путь сообщения, отправляя его после таймаута из dead_letter_queue снова в исходный exchange.
Путь задачи:
- сервис B публикует сообщение в service_a_inner_exch,
- сообщение попадает в очередь service_a_input_q,
- сервис A не может обработать сообщение и делает reject,
- сообщение попадает в dead_letter_exchange,
- а оттуда сразу в dead_letter_queue,
- в этой очереди сообщение проведет 5 минут и потом будет помечено «мертвым»,
- «мертвое» сообщение попадает в dead letter exchange очереди dead_letter_queue, а это service_a_inner_exch.
Количество «кругов», которые проходит одна задача, можно ограничить с помощью анализа заголовков, которые изменяются при прохождении dead letter exchange. Это будет показано в примере кода ниже.
Код написан на Python 3.6.2 с использованием библиотеки pika==0.10.0.
import pika import settings def init_rmq(): connection = pika.BlockingConnection(pika.ConnectionParameters( host=settings.RMQ_HOST, port=settings.RMQ_PORT, virtual_host=settings.RMQ_VHOST, credentials=pika.PlainCredentials(settings.RMQ_USERNAME, settings.RMQ_PASSWORD), )) channel = connection.channel() channel.exchange_declare(exchange=settings.RMQ_INPUT_EXCHANGE, exchange_type='fanout') return channel, connection if __name__ == '__main__': channel, connection = init_rmq() channel.basic_publish(exchange=settings.RMQ_INPUT_EXCHANGE, routing_key='', body='message from rmq') connection.close()
import logging import pika import settings logger = logging.getLogger(__name__) def init_rmq(): connection = pika.BlockingConnection(pika.ConnectionParameters( host=settings.RMQ_HOST, port=settings.RMQ_PORT, virtual_host=settings.RMQ_VHOST, credentials=pika.PlainCredentials(settings.RMQ_USERNAME, settings.RMQ_PASSWORD), )) channel = connection.channel() # создаем service_a_inner_exch channel.exchange_declare(exchange=settings.RMQ_INPUT_EXCHANGE, exchange_type='fanout') # создаем dead_letter_exchange channel.exchange_declare(exchange=settings.RMQ_DEAD_EXCHANGE, exchange_type='fanout') # создаем service_a_input_q channel.queue_declare( queue=settings.RMQ_INPUT_QUEUE, durable=True, arguments={ # благодаря этому аргументу сообщения из service_a_input_q # при nack-е будут попадать в dead_letter_exchange 'x-dead-letter-exchange': settings.RMQ_DEAD_EXCHANGE, } ) # создаем очередь для "мертвых" сообщений channel.queue_declare( queue=settings.RMQ_DEAD_QUEUE, durable=True, arguments={ # благодаря этому аргументу сообщения из service_a_input_q # при nack-е будут попадать в dead_letter_exchange 'x-message-ttl': settings.RMQ_DEAD_TTL, # также не забываем, что у очереди "мертвых" сообщений # должен быть свой dead letter exchange 'x-dead-letter-exchange': settings.RMQ_INPUT_EXCHANGE, } ) # связываем очередь "мертвых" сообщений с dead_letter_exchange channel.queue_bind( exchange=settings.RMQ_DEAD_EXCHANGE, queue=settings.RMQ_DEAD_QUEUE, ) # связываем основную очередь с входным exchange channel.queue_bind(settings.RMQ_INPUT_QUEUE, settings.RMQ_INPUT_EXCHANGE) return channel def callback(ch, method, properties, body): logger.info('Processing message `%s`', body) if can_retry(properties): logger.warning('Retrying message') # requeue=False отправит сообщение не в исходную очередь, а в dead letter exchange ch.basic_reject(delivery_tag=method.delivery_tag, requeue=False) return logger.error('Can`t retry, drop message') ch.basic_ack(delivery_tag=method.delivery_tag) def can_retry(properties): """ Заголовок x-death проставляется при прохождении сообщения через dead letter exchange. С его помощью можно понять, какой "круг" совершает сообщение. """ deaths = (properties.headers or {}).get('x-death') if not deaths: return True if deaths[0]['count'] >= settings.RETRY_COUNT: return False return True if __name__ == '__main__': channel = init_rmq() logger.info('Consuming.') channel.basic_consume( queue=settings.RMQ_INPUT_QUEUE, consumer_callback=callback, ) channel.start_consuming()
import logging.config RMQ_HOST = '' RMQ_PORT = 5672 RMQ_VHOST = '' RMQ_USERNAME = '' RMQ_PASSWORD = '' RMQ_INPUT_EXCHANGE = '' RMQ_INPUT_QUEUE = '' RMQ_DEAD_EXCHANGE = '' RMQ_DEAD_QUEUE = '' RMQ_DEAD_TTL = 60 * 1000 # 1 секунда RETRY_COUNT = 2 dict_config = { 'version': 1, 'disable_existing_loggers': False, 'formatters': { 'detailed': { 'class': 'logging.Formatter', 'format': '%(asctime)s %(levelname)s %(name)s: %(message)s' } }, 'handlers': { 'console': { 'class': 'logging.StreamHandler', 'level': 'INFO', 'formatter': 'detailed', }, }, 'root': { 'level': 'INFO', 'handlers': ['console'] }, } logging.config.dictConfig(dict_config)
Если в settings.py вы укажете необходимые данные для подключения к RabbitMQ, то последовательный запуск consumer.py и publisher.py выдаст следующий лог:
... 2020-05-02 12:16:32,260 INFO __main__: Consuming. 2020-05-02 12:16:35,233 INFO __main__: Processing message `b'message from rmq'` 2020-05-02 12:16:35,233 WARNING __main__: Retrying message 2020-05-02 12:17:35,241 INFO __main__: Processing message `b'message from rmq'` 2020-05-02 12:17:35,241 WARNING __main__: Retrying message 2020-05-02 12:18:35,249 INFO __main__: Processing message `b'message from rmq'` 2020-05-02 12:18:35,250 ERROR __main__: Can`t retry, drop message ...
Т.е. код создаст схему, показанную на рисунке, отправит одно сообщение в систему, попытается трижды его обработать и отбросит после двух ретраев.
Возможные улучшения. Разные таймауты
В качестве расширения функциональности предложенной схемы можно рассмотреть создание нескольких dead letter queue с разными таймаутами. После прохождения через через dead letter exchange:
- routing key сохраняется, поэтому можно использовать topics-exchange для направления сообщений в разные dead letter queue в зависимости от исходного значения routing key,
- заголовки дополняются, поэтому можно использовать headers-exchange для направления сообщений в разные dead letter queue в зависимости от исходных заголовков сообщения.
Возможные улучшения. Несколько consumer-ов
Если у вас с service_a_inner_exch связано несколько очередей, предназначенных для разных consumer-ов, то предложенная схема должна быть доработана. Например, у вас есть еще один сервис A_another, читающий из очереди service_a_another_input_q, связанной с service_a_inner_exch. Тогда текущая «петля» отправит сообщение повторно в обе очереди, и оба сервиса получат его повторно. Чтобы этого избежать, можно завести отдельный exchange dead_inner_exch, как показано на рисунке ниже.
Заключение
Описанное решение позволяет реализовать произвольное количество отложенных ретраев с равными промежутками между попытками. Для этого требуется минимальный дополнительный код, а вся логика по задержке и повторной доставке выполняется кластером RabbitMQ.
Эта схема успешно эксплуатируется примерно 7 месяцев, неоднократно спасала при проблемах с сервисом E и ни разу не потребовала ручного вмешательства в свою работу. Условия эксплуатации: RabbitMQ 3.6.12, 4 RPS в среднем, с пиками до 40 RPS.
Надеюсь, эта статья поможет какому-нибудь программисту крепче спать по ночам.
