49. За и против сквозного обучения
Продолжим рассматривать систему распознавания речи:

Большинство элементов этого конвейера созданы без применения машинного обучения (разработаны людьми или hand-designed):
- MFCC — это набор звуковых признаков, извлекаемых математическими манипуляциями с частотами, не требующими обучающихся алгоритмов. При этом обеспечивается удобная свертка входящего сигнала с потерей не значимой информации.
- Фонемы — изобретение лингвистов. При помощи них создается упрощенная модель звуков живой речи. Как и всякая модель сложного явления, фонемы не совершенны, качество работы системы, частью которой они являются, ограничено их несовершенным отражением реальности.
С одной стороны не обучаемые алгоритмы (hand-engineered components) ограничивают потенциальную производительность речевой системы. С другой их использование имеет определенные преимущества:
- Функции MFCC устойчивы к некоторым свойствам речи, не влияющим на смысл сказанного, например к тональности голоса. Их применение упрощает задачу для обучаемого алгоритма.
- Фонемы, если они правильно отражают звуки реальной речи, помогают обучающемуся алгоритму уловить основные звуковые элементы, повышая качество его работы
Теперь рассмотрим сквозную систему:

Эта система не может воспользоваться результатами алгоритмов, не требующих обучения (hand-engineered), работающих безотносительно к имеющимся данным. Как следствие, если обучающая выборка небольшая, система со сквозным обучением может работать хуже, чем конвейер с элементами не требующими обучения (hand-engineered pipeline).
Тем не менее, если в наличие имеется большая обучающая выборка, систему сквозного обучения не ограничивают недостатки MFCC или фонемных моделей. Если обучающийся алгоритм представляет собой большую нейронную сеть и в наличие имеется достаточное количество данных для обучения, то у такой системы появляется потенциал для того, чтобы превзойти систему с использованием не обучающихся алгоритмов, и, возможно, даже приблизиться к оптимальному уровню ошибок.
Системы сквозного обучения, как правило, хорошо себя показывают, когда в наличии имеется много размеченных данных для «обоих концов» — для входа и для выхода. В примере с распознаванием речи, для ее обучения понадобится большая выборка пар (записанная речь, ее расшифровка). В том случае, когда данные такого типа недоступны в достаточном количестве, нужно относится к сквозному обучению с большой осторожностью.
Если вы работаете над проблемой машинного обучения, имея в наличие очень ограниченную обучающую выборку, работа вашего алгоритма большей частью должна опираться на человеческое понимание решаемой задачи. Т. е. система в основном будет состоять из компонент, содержащих не обучаемые алгоритмы (hand engineering).
Если вы откажетесь от использования сквозного обучения, вам придется решить, из каких компонент должен состоять ваш конвейер и как из них сконструировать работающую систему. В следующих главах мы дадим несколько советов по проектированию таких конвейеров.
50. Выбираем компоненты конвейера: доступность данных
Из чего нужно исходить при выборе элементов не сквозной конвейерной системы? Выбор компонент и их взаимосвязь сильно влияет на качество работы всей системы. Важным фактором также является возможность легко собирать данные для обучения каждого из компонентов.
Для примера рассмотрим архитектуру не сквозного алгоритма автономного вождения:
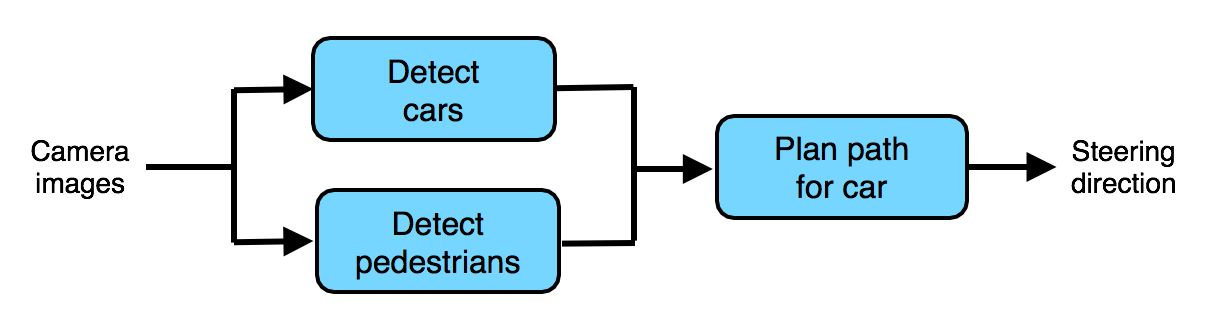
Для обнаружения автомобилей и пешеходов можно использовать машинное обучение. Тем более, что существует множество маркированных выборок для компьютерного зрения, содержащих в избытке изображения с автомобилями и пешеходами. Также можно использовать краудсорсинг (например, Amazon Mechanical Turk) для разметки дополнительных данных. Таким образом, относительно легко добыть данные для обучения детектора автомобилей и детектора пешеходов.
Рассмотрим, в чем отличие сквозного подхода:

Для обучения такой системы, необходим большой объем специфических данных, отражающих связь между изображением с камеры и поворотом рулевого колеса (пара: Изображение, Направление рулевого колеса). Для сбора такой выборки, требуется много времени и средств. Нужны специально оборудованные автомобили и время водителей. Потребуется большой парк таких автомобилей и огромное количество часов их вождения для того, чтобы обучающая выборка охватывала широкий спектр возможных сценариев развития реальных ситуаций на дорогах. Отсутствие таких выборок и высокая стоимость их создания затрудняет обучение сквозной системы. Намного легче получить большие размеченные выборки с изображениями автомобилей или пешеходов.
В общем, если доступны большие выборки для обучения «промежуточных модулей» конвейера (таких как автомобильный детектор или детектор пешеходов), то можно рассмотреть возможность использования конвейера, состоящего из нескольких компонент. Такой не сквозной подход будет предпочтительнее, так как позволяет использовать все имеющиеся данные.
Я считаю, что до тех пор, пока не появится больше данных для обучения сквозных систем, не сквозной (конвейерный) подход значительно более перспективен для разработки систем автономного вождения: его архитектура лучше соответствует имеющимся данным.

