
Точнее, как с него спуститься. Но обо всем по порядку. Эта статья немного выбьется из привычного формата статей от PVS-Studio. Мы часто пишем о проверке других проектов, но почти никогда не приоткрываем дверь нашей внутренней кухни. Пришло время это исправить и рассказать о том, как анализатор устроен изнутри. Точнее, о наиболее важной из его частей – синтаксическом дереве. Речь в статье пойдет о той части PVS-Studio, которая относится к языкам C и C++.
Сперва о главном
Синтаксическое дерево – это центральная часть любого компилятора. Так или иначе, код нужно представлять в удобном для программной обработки виде, и так уж вышло, что древовидная структура подходит для этого лучше всего. Не буду здесь углубляться в теорию — достаточно сказать, что дерево очень хорошо отражает иерархию выражений и блоков в коде, и при этом содержит только необходимые для работы данные.
При чем здесь компилятор, если речь идет о статическом анализаторе? Дело в том, что у этих двух инструментов очень много общего. На начальном этапе разбора кода они выполняют одну и ту же работу. Сначала код разбивается на поток лексем, который подается на вход парсеру. Затем в процессе синтаксического и семантического анализа лексемы организуются в дерево, которое отправляется дальше по конвейеру. Компиляторы на этом этапе могут производить промежуточные оптимизации перед генерацией бинарного кода, статические анализаторы начинают обход узлов и запуск различных проверок.
В анализаторе PVS-Studio с построенным деревом происходит несколько вещей:
- Для каждой декларации вычисляются типы. Декларацией может быть переменная, функция, класс, определение псевдонима типа через using или typedef, и так далее. Словом, любое объявление. Все это фиксируется в таблице для текущей области видимости;
- Обрабатываются выражения и вычисляются значения переменных. Сохраняется информация, которую анализатор использует для символьных вычислений и анализа потока данных;
- Выбираются перегрузки вызванных функций, к ним применяются заранее определенные аннотации, а если их нет, то по возможности они выводятся автоматически;
- Анализируется поток данных. Для этого анализатор хранит значение каждой переменной (если его можно вычислить во время компиляции). Кроме значений к переменным привязаны известные данные об их состоянии. Например, если в начале функции некий указатель проверили на nullptr и вышли из функции, если он оказался нулевым, то далее по коду такой указатель будет считаться валидным. Эти данные используются также в межпроцедурном анализе;
- Запускаются диагностические правила. В зависимости от логики их работы, они могут сделать дополнительный обход дерева. Для разных типов выражений запускаются свои наборы диагностик, которые иногда могут пересекаться.
Если вас интересуют подробности того, как работает анализ, рекомендую почитать статью "Технологии, используемые в анализаторе кода PVS-Studio для поиска ошибок и потенциальных уязвимостей". Некоторые моменты из списка рассмотрены там в деталях.
Мы же посмотрим более подробно, что происходит с деревом внутри анализатора, и как оно вообще выглядит. С кратким введением покончено, время перейти к сути вопроса.

Как оно устроено
Исторически так сложилось, что PVS-Studio использует для представления кода бинарное дерево. Эта классическая структура данных знакома всем – у нас есть узел, который в общем случае ссылается на два дочерних. Узлы, у которых не предполагается наличие потомков, я буду называть терминалами, все другие – нетерминалами. Нетерминал может в некоторых случаях не иметь дочерних узлов, но его ключевое отличие от терминала в том, что потомки для него принципиально разрешены. Терминальные узлы (или листья) лишены способности ссылаться на что-то, кроме родителя.
Структура, которая используется в PVS-Studio, немного отличается от классического бинарного дерева – это нужно для удобства работы. Терминальные узлы обычно соответствуют ключевым словам, именам переменных, литералам и так далее. Нетерминалы – различные виды выражений, блоки кода, списки и тому подобные составные элементы дерева.
С точки зрения устройства компиляторов все здесь довольно стандартно, всем заинтересованным советую классику жанра – "Книгу дракона".
Мы же двигаемся дальше. Давайте посмотрим на простой пример кода и на то, как видит его анализатор. Дальше будет много картинок из нашей внутренней утилиты для визуализации дерева.
Собственно, пример:
int f(int a, int b)
{
return a + b;
}Эта простая функция после обработки парсером будет выглядеть так (желтым выделены нетерминальные узлы):
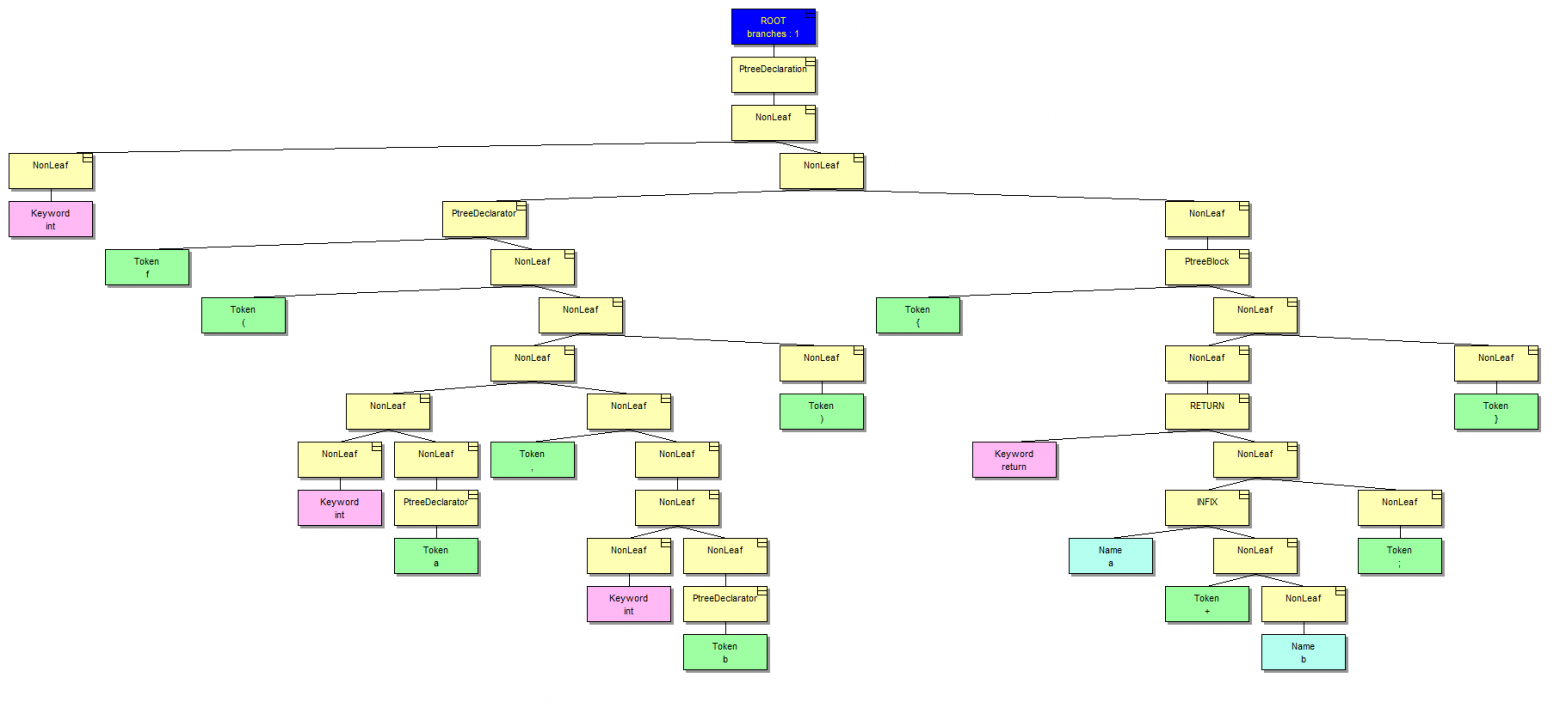
У такого представления есть свои плюсы и минусы, и последних, на мой взгляд, чуть больше. Но давайте рассмотрим дерево. Сразу оговорюсь, что оно несколько избыточно, например, потому что содержит пунктуацию и скобки. С точки зрения компиляции это лишний мусор, но анализатору такая информация бывает нужна для некоторых диагностических правил. Другими словами, анализатор работает не с абстрактным синтаксическим деревом (AST), а с деревом разбора (DT).
Дерево растет слева направо и сверху вниз. Левые дочерние узлы всегда содержат нечто осмысленное, например, деклараторы. Если посмотреть вправо, то мы увидим промежуточные нетерминалы, отмеченные словом NonLeaf. Они нужны только для того, чтобы дерево сохраняло свою структуру. Для нужд анализа никакой информационной нагрузки такие узлы не несут.
Пока нас будет интересовать левая часть дерева. Вот она же более крупным планом:
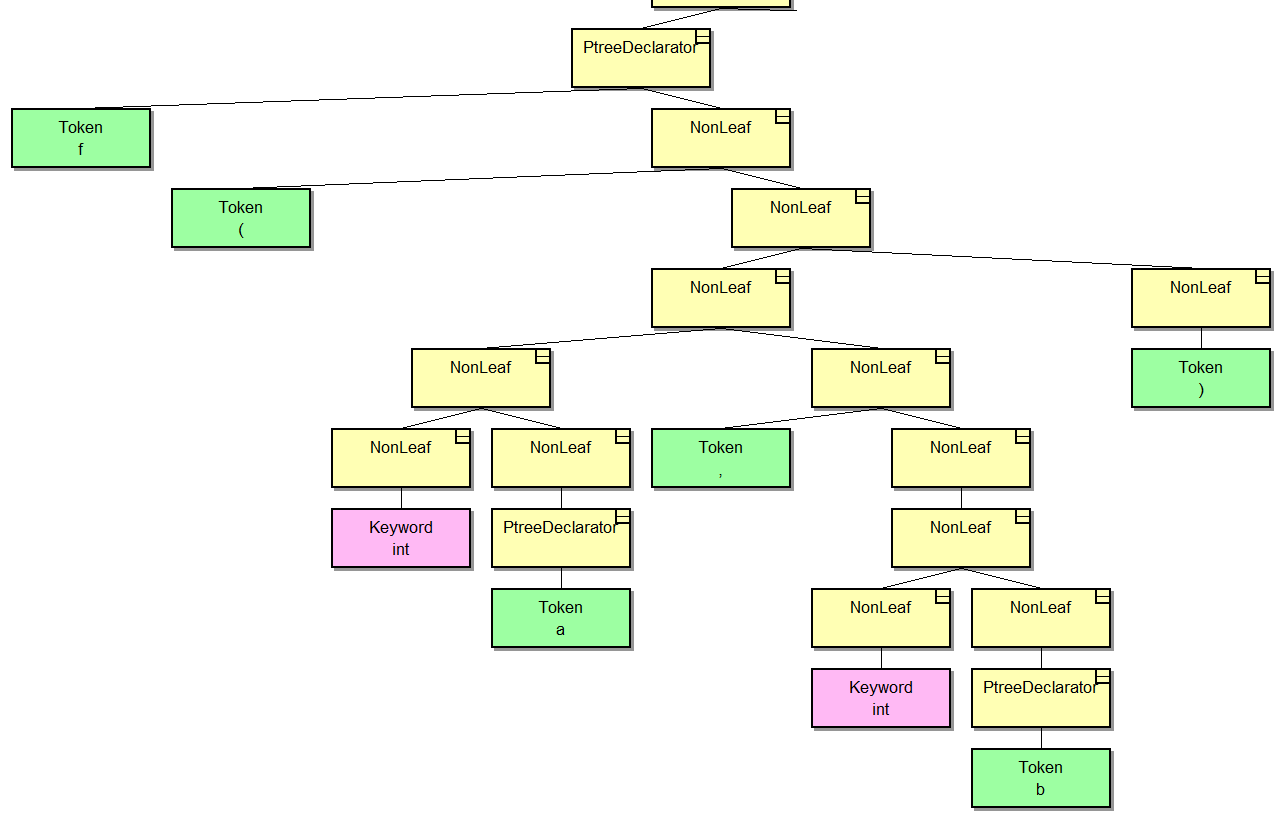
Этот объявление функции. Родительский узел PtreeDeclarator – это объект, через интерфейс которого можно получить доступ к узлам с именем функции и ее параметрами. Еще в нем хранится закодированная сигнатура для системы типов. Мне кажется, что эта картинка довольно наглядна, и по ней довольно просто сопоставить элементы дерева с кодом.
Выглядит просто, так ведь?
Для наглядности давайте возьмем пример попроще. Представьте себе, что у нас есть код, который вызывает нашу функцию f:
f(42, 23);Вызов функции в дереве будет выглядеть так:
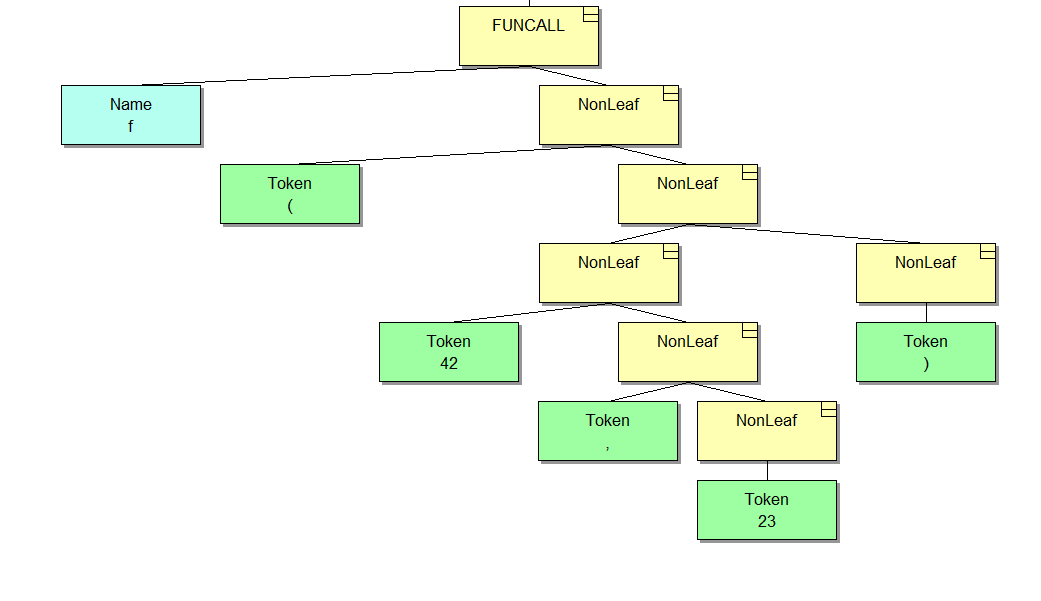
Структура очень похожа, только здесь мы видим вызов функции вместо ее объявления. Теперь допустим, что нам захотелось перебрать все аргументы и сделать что-то с каждым из них. Это реальная задача, которая часто встречается в коде анализатора. Понятное дело, что аргументами все не ограничивается, и перебирать приходится разные типы узлов, но сейчас мы рассмотрим этот конкретный пример.
Предположим, что у нас есть только указатель на родительский узел FUNCALL. У любого нетерминала мы можем получить левый и правый дочерний узел. Тип каждого из них известен. Структуру дерева мы знаем, так что можем сразу же достучаться до того узла, под которым лежит список аргументов – это NonLeaf, от которого на картинке растет терминал 42. Количество аргументов заранее нам неизвестно, и в списке есть запятые, которые нас в этом случае абсолютно не интересуют.
Как мы будем это делать? Читайте дальше.
Велосипедный завод
Казалось бы, проитерироваться по дереву довольно просто. Надо всего лишь написать функцию, которая будет это делать, и использовать ее везде. Возможно, передавать ей в качестве аргумента лямбду для обработки каждого элемента. Это действительно было бы так, если бы не пара нюансов.
Во-первых, обходить дерево каждый раз приходится немного по-разному. Различается как логика обработки каждого узла, так и логика работы со всем списком. Скажем, в одном случае мы хотим пройтись по аргументам списка и передать каждый из них на обработку в некую функцию. В другом, мы хотим выбрать и вернуть один аргумент, который соответствует каким-то требованиям. Или отфильтровать список и выбросить из него все неинтересные элементы.
Во-вторых, иногда нужно знать индекс текущего элемента. Например, мы хотим обработать только два первых аргумента и остановиться.
В-третьих, давайте отвлечемся от примера с функцией. Скажем, у нас есть код вроде такого:
int f(int a, int b)
{
int c = a + b;
c *= 2;
if (c < 42) return c;
return 42;
}Этот код глупый, я знаю, но давайте сейчас сконцентрируемся на том, как выглядит дерево. Мы уже видели объявление функции, здесь нам нужно ее тело:
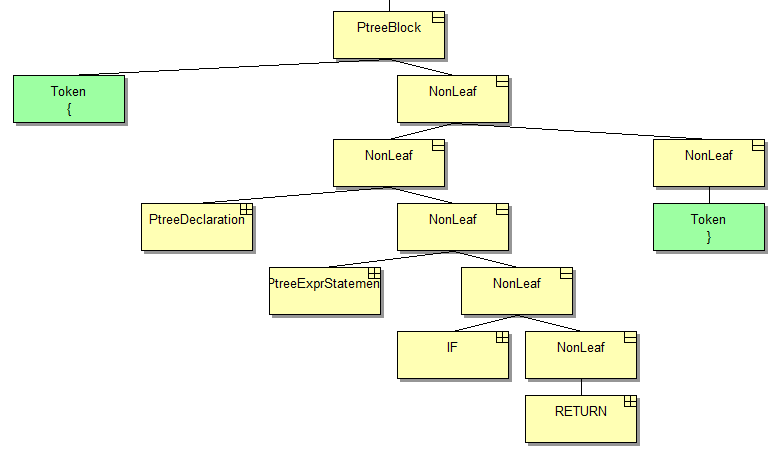
Этот случай похож на список аргументов, но вы можете заметить некоторую разницу. Взгляните еще раз на картинку из предыдущего раздела.
Заметили?
Правильно, в этом списке нет запятых, а значит его можно обрабатывать подряд и не заботиться о пропуске разделителей.
Итого, у нас есть как минимум два случая:
- Список с разделителями.
- Сплошной список.
Теперь посмотрим, как это все происходит в коде анализатора. Вот пример с обходом списка аргументов. Это упрощенный вариант одной из функций в трансляторе.
void ProcessArguments(Ptree* arglist)
{
if (!arglist) return;
Ptree* args = Second(arglist);
while (args)
{
Ptree* p = args->Car();
if (!Eq(p, ','))
{
ProcessArg(p);
}
args = args->Cdr();
}
}Если бы мне платили доллар каждый раз, когда я вижу подобный код, я бы уже разбогател.
Давайте посмотрим, что здесь происходит. Сразу оговорюсь, что это очень старый код, написанный задолго до появления даже C++11, не говоря о более современных стандартах. Можно сказать, что я специально искал осколок времён древних цивилизаций.
Итак, во-первых, на вход эта функция принимает список аргументов в круглых скобках. Что-то вроде этого:
(42, 23)
Функция Second здесь вызывается для того, чтобы достать содержимое скобок. Все, что она делает, это перемещение один раз вправо и потом один раз влево по бинарному дереву. Далее цикл последовательно достает элементы: 42, затем запятую, затем 23, а на следующем шаге указатель args становится нулевым, потому что мы доходим до конца ветки. Цикл, само собой, пропускает неинтересные запятые.
Подобные функции с немного измененной логикой можно встретить во многих местах, особенно в старом коде.
Другой пример. Как узнать, есть ли в некоем блоке кода вызов определенной функции? Примерно так:
bool IsFunctionCalled(const Ptree* body, std::string_view name)
{
if (!arglist) return;
const Ptree* statements = body;
while (statements)
{
const Ptree* cur = statements->Car();
if (IsA(cur, ntExprStatement) && IsA(cur->Car(), ntFuncallExpr))
{
const Ptree* funcName = First(cur->Car());
if (Eq(funcName, name))
return true;
}
statements = statements->Cdr();
}
return false;
}Примечание. Внимательный читатель может заметить. Какой же он старый? Там std::string_view торчит. Всё просто, даже самый старый код постепенно подвергается рефакторингу и постепенно ничего подобного не останется.
Было бы неплохо использовать здесь что-то более изящное, правда? Ну, например, стандартный алгоритм find_if. Да что там алгоритм, даже обычный range-based for намного улучшил бы читаемость и облегчил поддержку такого кода.
Давайте попробуем этого добиться.
Кладем дерево в коробку
Наша цель – добиться того, чтобы дерево вело себя подобно контейнеру из STL. Причем, нас не должна заботить внутренняя структура списков, мы хотим единообразно итерироваться по узлам, например, вот так:
void DoSomethingWithTree(const Ptree* tree)
{
....
for (auto cur : someTreeContainer)
{
....
}
}Как видите, здесь у нас появилась некая сущность по имени someTreeContainer, о которой мы пока ничего не знаем. У такого контейнера должны быть как минимум методы begin и end, возвращающие итераторы. Кстати об итераторах, они тоже должны вести себя подобно стандартным. С них и начнем.
В простейшем случае итератор выглядит так:
template <typename Node_t,
std::enable_if_t<std::is_base_of_v<Node_t, Ptree>, int>>
class PtreeIterator
{
public:
using value_type = Node_t;
using dereference_type = value_type;
using reference = std::add_lvalue_reference_t<value_type>;
using pointer = std::add_pointer_t<value_type>;
using difference_type =
decltype(std::declval<pointer>() - std::declval<pointer>());
using iterator_category = std::forward_iterator_tag;
public:
PtreeIterator(Node_t* node) noexcept : m_node{ node } {}
....
PtreeIterator& operator++() noexcept
{
m_node = Rest(m_node);
return *this;
}
dereference_type operator*() const noexcept
{
return static_cast<dereference_type>(First(m_node));
}
private:
Node_t* m_node = nullptr;
};Чтобы не загромождать код, я убрал некоторые подробности. Ключевые моменты здесь – разыменование и инкремент. Шаблон нужен для того, чтобы итератор мог работать как с константными, так и с неконстантными данными.
Теперь напишем контейнер, в который мы будем помещать узел дерева. Вот простейший вариант:
template <typename Node_t>
class PtreeContainer
{
public:
using Iterator = PtreeIterator<Node_t>;
using value_type = typename Iterator::dereference_type;
using size_type = size_t;
using difference_type =
typename Iterator::difference_type;
public:
PtreeContainer(Node_t* nodes) :
m_nodes{ nodes }
{
if (IsLeaf(m_nodes))
{
m_nodes = nullptr;
}
}
....
Iterator begin() const noexcept
{
return m_nodes;
}
Iterator end() const noexcept
{
return nullptr;
}
bool empty() const noexcept
{
return begin() == end();
}
private:
Node_t* m_nodes = nullptr;
};Мы закончили, можно расходиться, спасибо за внимание.
Хотя нет, постойте. Все не может быть настолько просто, верно? Вернемся к нашим двум вариантам списков – с разделителями и без. Здесь мы при инкременте берем просто правый узел дерева, так что проблему это не решает. Нам все еще нужно пропускать запятые, если мы хотим работать только с данными.
Не проблема, мы просто добавим в итератор дополнительный шаблонный параметр. Скажем, вот так:
enum class PtreeIteratorTag : uint8_t
{
Statement,
List
};
template <typename Node_t, PtreeIteratorTag tag,
std::enable_if_t<std::is_base_of_v<Node_t, Ptree>, int> = 0>
class PtreeIterator { .... };Как нам это поможет? Элементарно. Будем проверять этот параметр в инкременте и вести себя соответственно. Благо, в C++17 мы можем решить это на этапе компиляции с помощью конструкции if constexpr:
PtreeIterator& operator++() noexcept
{
if constexpr (tag == PtreeIteratorTag::Statement)
{
m_node = Rest(m_node);
}
else
{
m_node = RestRest(m_node);
}
return *this;
}Так лучше, теперь мы можем выбирать итератор под свои нужды. Как поступить с контейнерами? Можно, к примеру, так:
template <typename Node_t, PtreeIteratorTag tag>
class PtreeContainer
{
public:
using Iterator = PtreeIterator<Node_t, tag>;
....
};Теперь-то мы точно закончили? На самом деле, не совсем.
Но это еще не все
Давайте посмотрим на такой вот код:
void ProcessEnum(Ptree* argList, Ptree* enumPtree)
{
const ptrdiff_t argListLen = Length(argList);
if (argListLen < 0) return;
for (ptrdiff_t i = 0; i < argListLen; ++i)
{
std::string name;
Ptree* elem;
const EGetEnumElement r = GetEnumElementInfo(enumPtree, i, elem, name);
....
}
}Мне очень многое не нравится в этом коде, начиная от цикла со счетчиком, и заканчивая тем, что функция GetEnumElementInfo выглядит очень подозрительно. Сейчас она для нас остается черным ящиком, но мы можем предположить, что она достает элемент enum по индексу и возвращает его имя и узел в дереве через выходные параметры. Возвращаемое значение тоже немного странное. Давайте вообще от нее избавимся – идеальная работа для нашего итератора по списку:
void ProcessEnum(const Ptree* argList)
{
for (auto elem : PtreeContainer<const Ptree, PtreeIteratorTag::List>(argList))
{
auto name = PtreeToString(elem);
....
}
}Неплохо. Только этот код не компилируется. Почему? Потому что индекс, который мы убрали, использовался в теле цикла ниже вызова GetEnumElementInfo. Я не буду здесь говорить, как именно его использовали, потому что это сейчас не важно. Достаточно сказать, что индекс нужен.
Что ж, давайте добавим переменную и испортим наш красивый код:
void ProcessEnum(const Ptree* argList)
{
size_t i = 0;
for (auto elem : PtreeContainer<const Ptree, PtreeIteratorTag::List>(argList))
{
auto name = PtreeToString(elem);
....
UseIndexSomehow(i++);
}
}Все еще рабочий вариант, но на подобное лично я реагирую примерно так:

Что ж, попробуем решить эту проблему. Нам нужно нечто, способное считать элементы автоматически. Добавим итератор со счетчиком. Я снова пропустил лишние подробности для краткости:
template <typename Node_t, PtreeIteratorTag tag,
std::enable_if_t<std::is_base_of_v<Node_t, Ptree>, int>>
class PtreeCountingIterator
{
public:
using size_type = size_t;
using value_type = Node_t;
using dereference_type = std::pair<value_type, size_type>;
using reference = std::add_lvalue_reference_t<value_type>;
using pointer = std::add_pointer_t<value_type>;
using difference_type =
decltype(std::declval<pointer>() - std::declval<pointer>());
using iterator_category = std::forward_iterator_tag;
public:
PtreeCountingIterator(Node_t* node) noexcept : m_node{ node } {}
....
PtreeCountingIterator& operator++() noexcept
{
if constexpr (tag == PtreeIteratorTag::Statement)
{
m_node = Rest(m_node);
}
else
{
m_node = RestRest(m_node);
}
++m_counter;
return *this;
}
dereference_type operator*() const noexcept
{
return { static_cast<value_type>(First(m_node)), counter() };
}
private:
Node_t* m_node = nullptr;
size_type m_counter = 0;
};Теперь мы можем написать вот такой код, верно?
void ProcessEnum(const Ptree* argList)
{
for (auto [elem, i] :
PtreeCountedContainer<const Ptree, PtreeIteratorTag::List>(argList))
{
auto name = PtreeToString(elem);
....
UseIndexSomehow(i);
}
}В целом, действительно можем, но есть одна проблема. Если вы посмотрите на этот код, вы можете заметить, что мы ввели еще одну сущность – нечто по имени PtreeCountedContainer. Похоже, ситуация усложняется. Очень не хочется жонглировать разными типами контейнеров, а с учетом того, что внутри они одинаковые, рука сама тянется за бритвой Оккама.
Придется использовать итератор как шаблонный параметр для контейнера, но об этом чуть дальше.
Зоопарк типов
Отвлечемся от счетчиков и сортов итераторов на минуту. В погоне за универсальным обходом узлов мы забыли про самое главное – собственно дерево.
Взглянем на такой код:
int a, b, c = 0, d;Что мы видим в дереве:
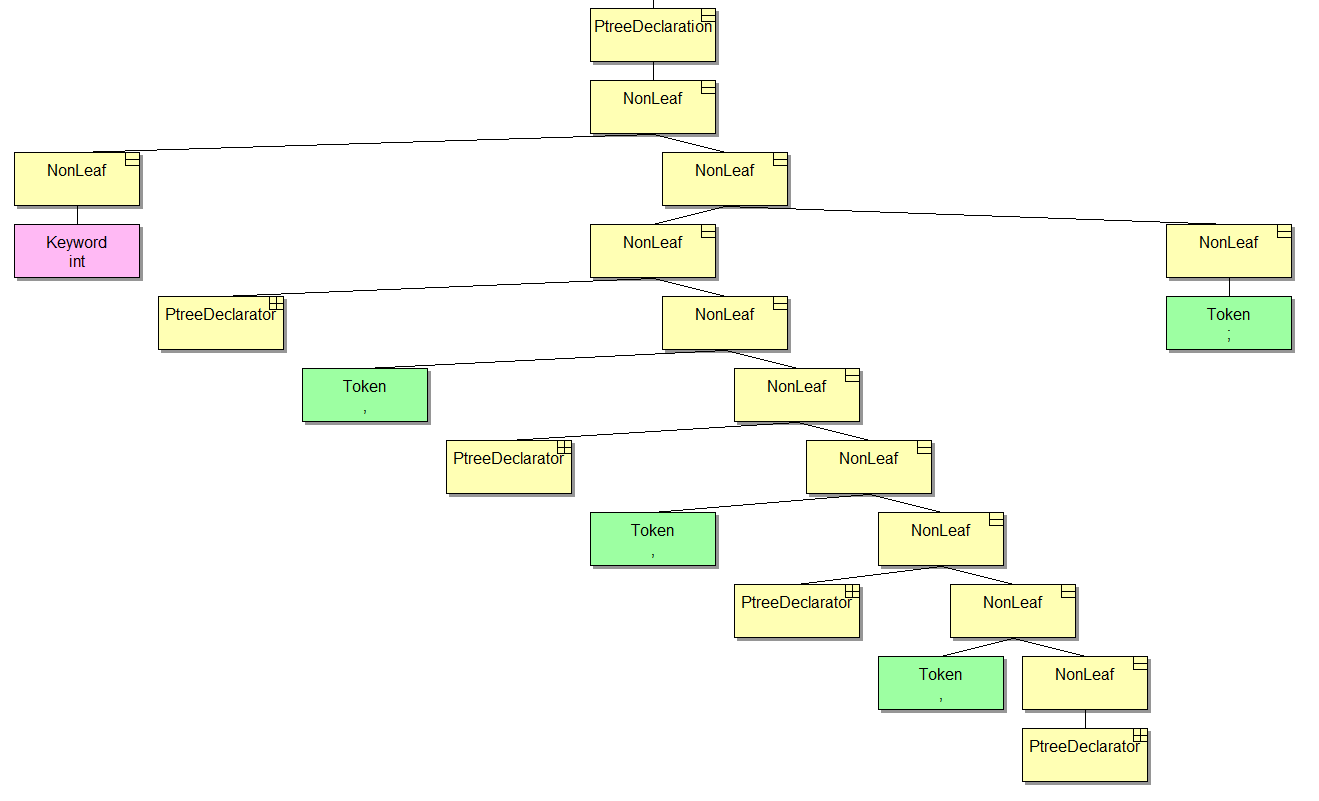
Давайте теперь проитерируемся по списку деклараторов, но сперва я расскажу про дерево кое-что еще. Все время до этого мы имели дело с указателем на класс Ptree. Это базовый класс, от которого унаследованы все прочие типы узлов. Через их интерфейсы мы можем получить дополнительную информацию. В частности, самый верхний узел на картинке может вернуть нам список деклараторов без использования утилитных функций типа First и Second. Также, нам не понадобятся низкоуровневые методы Car и Cdr (привет фанатам языка Lisp). Это очень хорошо, так как в диагностиках мы можем абстрагироваться от реализации дерева. Я думаю, все согласны, что текущие абстракции – это очень плохо.
Так выглядит обход всех деклараторов:
void ProcessDecl(const PtreeDeclarator* decl) { .... }
void ProcessDeclarators(const PtreeDeclaration* declaration)
{
for (auto decl : declaration->GetDeclarators())
{
ProcessDecl(static_cast<const PtreeDeclarator*>(decl));
}
}Метод GetDeclarators возвращает итерируемый контейнер. Его тип в данном случае – PtreeContainer<const Ptree, PtreeIteratorTag::List>.
С этим кодом все было бы хорошо, если бы не каст. Дело в том, что функция ProcessDecl хочет указатель на класс, производный от Ptree, но наши итераторы ничего про него не знают. Хотелось бы избавиться от необходимости преобразовывать типы вручную.
Кажется, пришло время снова поменять итератор и добавить ему способность к касту.
template <typename Node_t, typename Deref_t, PtreeIteratorTag tag,
std::enable_if_t<std::is_base_of_v<Node_t, Ptree>, int>>
class PtreeIterator
{
public:
using value_type = Deref_t;
using dereference_type = value_type;
using reference = std::add_lvalue_reference_t<value_type>;
using pointer = std::add_pointer_t<value_type>;
using difference_type =
decltype(std::declval<pointer>() - std::declval<pointer>());
using iterator_category = std::forward_iterator_tag;
....
}Чтобы каждый раз не писать все эти шаблонные аргументы вручную, добавим несколько псевдонимов на все случаи жизни:
template <typename Node_t, typename Deref_t = std::add_pointer_t<Node_t>>
using PtreeStatementIterator =
PtreeIterator<Node_t, Deref_t, PtreeIteratorTag::Statement>;
template <typename Node_t, typename Deref_t = std::add_pointer_t<Node_t>>
using PtreeListIterator =
PtreeIterator<Node_t, Deref_t, PtreeIteratorTag::List>;
template <typename Node_t, typename Deref_t = std::add_pointer_t<Node_t>>
using PtreeStatementCountingIterator =
PtreeCountingIterator<Node_t, Deref_t, PtreeIteratorTag::Statement>;
template <typename Node_t, typename Deref_t = std::add_pointer_t<Node_t>>
using PtreeListCountingIterator =
PtreeCountingIterator<Node_t, Deref_t, PtreeIteratorTag::List>;Так лучше. Теперь, если нам не нужен каст, мы можем указать только первый шаблонный аргумент, а также можем не забивать голову значением параметра tag.
Но что делать с контейнерами? Напомню, что мы хотим иметь всего один универсальный класс, который подходил бы для любого итератора. Теперь же разных комбинаций становится неприлично много, а нам нужна простота. Что-то вроде такого:
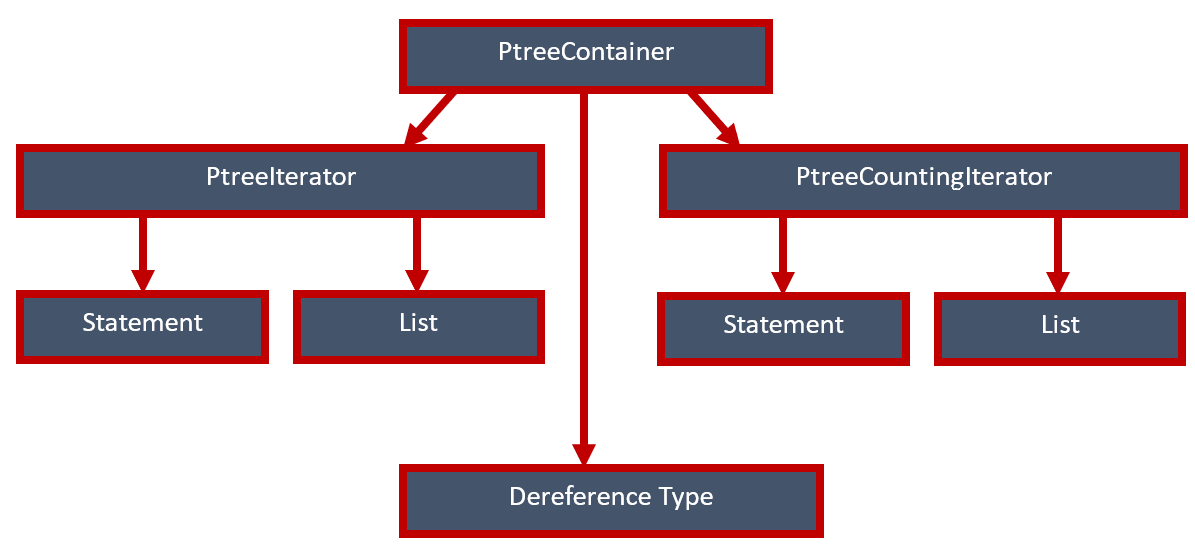
То есть, мы хотим, чтобы единственный класс контейнера мог поддерживать все типы наших итераторов и уметь сообщать им, какой тип вернуть при разыменовании. Тогда в коде мы просто создадим нужный нам контейнер и начнем с ним работать, не задумываясь о том, какие итераторы нам нужны.
Разберем этот вопрос в следующем разделе.
Шаблонная магия
Итак, вот что нам нужно:
- Один контейнер, который умеет универсально работать с любым итератором.
- Итератор, который, в зависимости от списка узлов, может работать как с каждым элементом, так и через один.
- Такой же итератор, но со счетчиком.
- Оба итератора должны уметь при разыменовании делать каст, если дополнительно указан тип.
Первым делом нам нужно как-то привязать тип контейнера к типу итератора через шаблонные параметры. Вот что у нас вышло:
template <template <typename, typename> typename FwdIt,
typename Node_t,
typename Deref_t = std::add_pointer_t<Node_t>>
class PtreeContainer
{
public:
using Iterator = FwdIt<Node_t, Deref_t>;
using value_type = typename Iterator::dereference_type;
using size_type = size_t;
using difference_type = typename Iterator::difference_type;
public:
PtreeContainer(Node_t* nodes) :
m_nodes{ nodes }
{
if (IsLeaf(m_nodes))
{
m_nodes = nullptr;
}
}
....
Iterator begin() const noexcept
{
return m_nodes;
}
Iterator end() const noexcept
{
return nullptr;
}
bool empty() const noexcept
{
return begin() == end();
}
....
private:
Node_t* m_nodes = nullptr;
};Также, в контейнер можно добавить еще методов. Например, вот так мы можем узнать количество элементов:
difference_type count() const noexcept
{
return std::distance(begin(), end());
}Или вот оператор индексирования:
value_type operator[](size_type index) const noexcept
{
size_type i = 0;
for (auto it = begin(); it != end(); ++it)
{
if (i++ == index)
{
return *it;
}
}
return value_type{};
}Понятно, что обращаться с подобными методами нужно осторожно из-за их линейной сложности, но иногда они бывают полезны.
Для простоты использования добавим псевдонимов:
template <typename Node_t, typename Deref_t = std::add_pointer_t<Node_t>>
using PtreeStatementList =
PtreeContainer<PtreeStatementIterator, Node_t, Deref_t>;
template <typename Node_t, typename Deref_t = std::add_pointer_t<Node_t>>
using PtreeItemList =
PtreeContainer<PtreeListIterator, Node_t, Deref_t>;
template <typename Node_t, typename Deref_t = std::add_pointer_t<Node_t>>
using PtreeCountedStatementList =
PtreeContainer<PtreeStatementCountingIterator, Node_t, Deref_t>;
template <typename Node_t, typename Deref_t = std::add_pointer_t<Node_t>>
using PtreeCountedItemList =
PtreeContainer<PtreeListCountingIterator, Node_t, Deref_t>;Теперь мы можем создавать контейнеры легко. Скажем, в уже упомянутом классе PtreeDeclaration мы хотим получить от метода GetDeclarators контейнер, итератор которого пропускает разделители, при этом счетчика в нем нет, и при разыменовании он возвращает значение типа PtreeDeclarator. Вот объявление такого контейнера:
using DeclList =
Iterators::PtreeItemList<Ptree, PtreeDeclarator*>;
using ConstDeclList =
Iterators::PtreeItemList<const Ptree, const PtreeDeclarator*>;
Теперь мы можем писать такой код и не думать о типе списка и кастах:
void ProcessDecl(const PtreeDeclarator* decl) { .... }
void ProcessDeclarators(const PtreeDeclaration* declaration)
{
for (auto decl : declaration->GetDeclarators())
{
ProcessDecl(decl);
}
}Ну и напоследок, так как выведение типов для псевдонимов появится только в C++20, чтобы удобнее создавать контейнеры в коде, мы добавили такие функции:
template <typename Node_t>
PtreeStatementList<Node_t> MakeStatementList(Node_t* node)
{
return { node };
}
template <typename Node_t>
PtreeItemList<Node_t> MakeItemList(Node_t* node)
{
return { node };
}
template <typename Node_t>
PtreeCountedStatementList<Node_t> MakeCountedStatementList(Node_t* node)
{
return { node };
}
template <typename Node_t>
PtreeCountedItemList<Node_t> MakeCountedItemList(Node_t* node)
{
return { node };
}Вспомним функцию, которая работала с enum. Теперь мы можем написать ее так:
void ProcessEnum(const Ptree* argList)
{
for (auto [elem, i] : MakeCountedItemList(argList))
{
auto name = PtreeToString(elem);
....
UseIndexSomehow(i);
}
}Сравните с изначальным вариантом, мне кажется, стало лучше:
void ProcessEnum(Ptree* argList, Ptree* enumPtree)
{
const ptrdiff_t argListLen = Length(argList);
if (argListLen < 0) return;
for (ptrdiff_t i = 0; i < argListLen; ++i)
{
std::string name;
Ptree* elem;
const EGetEnumElement r = GetEnumElementInfo(enumPtree, i, elem, name);
....
UseIndexSomehow(i);
}
}That's all, folks
На этом у меня все, спасибо за внимание. Надеюсь, вы узнали что-то интересное или даже полезное.
По содержанию статьи может показаться, что я ругаю код нашего анализатора и хочу сказать, что там все плохо. Это не так. Как любой проект с историей, наш анализатор полон геологических отложений, которые остались от прошлых эпох. Считайте, что мы сейчас провели раскопки, достали из-под земли артефакты древней цивилизации и провели реставрацию, чтобы они хорошо смотрелись на полке.
Постскриптум
Здесь будет много кода. Я сомневался, включать сюда реализацию итераторов или нет, и в итоге решил включить, чтобы не оставлять ничего за кадром. Если вам не интересно читать код, здесь я с вами попрощаюсь. Остальным желаю приятно провести время с шаблонами.
Код
Обычный итератор
template <typename Node_t, typename Deref_t, PtreeIteratorTag tag,
std::enable_if_t<std::is_base_of_v<Node_t, Ptree>, int> = 0>
class PtreeIterator
{
public:
using value_type = Deref_t;
using dereference_type = value_type;
using reference = std::add_lvalue_reference_t<value_type>;
using pointer = std::add_pointer_t<value_type>;
using difference_type =
decltype(std::declval<pointer>() - std::declval<pointer>());
using iterator_category = std::forward_iterator_tag;
public:
PtreeIterator(Node_t* node) noexcept : m_node{ node } {}
PtreeIterator() = delete;
PtreeIterator(const PtreeIterator&) = default;
PtreeIterator& operator=(const PtreeIterator&) = default;
PtreeIterator(PtreeIterator&&) = default;
PtreeIterator& operator=(PtreeIterator&&) = default;
bool operator==(const PtreeIterator & other) const noexcept
{
return m_node == other.m_node;
}
bool operator!=(const PtreeIterator & other) const noexcept
{
return !(*this == other);
}
PtreeIterator& operator++() noexcept
{
if constexpr (tag == PtreeIteratorTag::Statement)
{
m_node = Rest(m_node);
}
else
{
m_node = RestRest(m_node);
}
return *this;
}
PtreeIterator operator++(int) noexcept
{
auto tmp = *this;
++(*this);
return tmp;
}
dereference_type operator*() const noexcept
{
return static_cast<dereference_type>(First(m_node));
}
pointer operator->() const noexcept
{
return &(**this);
}
Node_t* get() const noexcept
{
return m_node;
}
private:
Node_t* m_node = nullptr;
};
template <typename Node_t, typename Deref_t = std::add_pointer_t<Node_t>>
using PtreeStatementIterator =
PtreeIterator<Node_t, Deref_t, PtreeIteratorTag::Statement>;
template <typename Node_t, typename Deref_t = std::add_pointer_t<Node_t>>
using PtreeListIterator =
PtreeIterator<Node_t, Deref_t, PtreeIteratorTag::List>;Итератор со счетчиком
template <typename Node_t, typename Deref_t, PtreeIteratorTag tag,
std::enable_if_t<std::is_base_of_v<Node_t, Ptree>, int> = 0>
class PtreeCountingIterator
{
public:
using size_type = size_t;
using value_type = Deref_t;
using dereference_type = std::pair<value_type, size_type>;
using reference = std::add_lvalue_reference_t<value_type>;
using pointer = std::add_pointer_t<value_type>;
using difference_type =
decltype(std::declval<pointer>() - std::declval<pointer>());
using iterator_category = std::forward_iterator_tag;
public:
PtreeCountingIterator(Node_t* node) noexcept : m_node{ node } {}
PtreeCountingIterator() = delete;
PtreeCountingIterator(const PtreeCountingIterator&) = default;
PtreeCountingIterator& operator=(const PtreeCountingIterator&) = default;
PtreeCountingIterator(PtreeCountingIterator&&) = default;
PtreeCountingIterator& operator=(PtreeCountingIterator&&) = default;
bool operator==(const PtreeCountingIterator& other) const noexcept
{
return m_node == other.m_node;
}
bool operator!=(const PtreeCountingIterator& other) const noexcept
{
return !(*this == other);
}
PtreeCountingIterator& operator++() noexcept
{
if constexpr (tag == PtreeIteratorTag::Statement)
{
m_node = Rest(m_node);
}
else
{
m_node = RestRest(m_node);
}
++m_counter;
return *this;
}
PtreeCountingIterator operator++(int) noexcept
{
auto tmp = *this;
++(*this);
return tmp;
}
dereference_type operator*() const noexcept
{
return { static_cast<value_type>(First(m_node)), counter() };
}
value_type operator->() const noexcept
{
return (**this).first;
}
size_type counter() const noexcept
{
return m_counter;
}
Node_t* get() const noexcept
{
return m_node;
}
private:
Node_t* m_node = nullptr;
size_type m_counter = 0;
};
template <typename Node_t, typename Deref_t = std::add_pointer_t<Node_t>>
using PtreeStatementCountingIterator =
PtreeCountingIterator<Node_t, Deref_t, PtreeIteratorTag::Statement>;
template <typename Node_t, typename Deref_t = std::add_pointer_t<Node_t>>
using PtreeListCountingIterator =
PtreeCountingIterator<Node_t, Deref_t, PtreeIteratorTag::List>;Обобщенный контейнер
template <template <typename, typename> typename FwdIt,
typename Node_t, typename Deref_t = std::add_pointer_t<Node_t>>
class PtreeContainer
{
public:
using Iterator = FwdIt<Node_t, Deref_t>;
using value_type = typename Iterator::dereference_type;
using size_type = size_t;
using difference_type = typename Iterator::difference_type;
public:
PtreeContainer(Node_t* nodes) :
m_nodes{ nodes }
{
if (IsLeaf(m_nodes))
{
m_nodes = nullptr;
}
}
PtreeContainer() = default;
PtreeContainer(const PtreeContainer&) = default;
PtreeContainer& operator=(const PtreeContainer&) = default;
PtreeContainer(PtreeContainer&&) = default;
PtreeContainer& operator=(PtreeContainer&&) = default;
bool operator==(std::nullptr_t) const noexcept
{
return empty();
}
bool operator!=(std::nullptr_t) const noexcept
{
return !(*this == nullptr);
}
bool operator==(Node_t* node) const noexcept
{
return get() == node;
}
bool operator!=(Node_t* node) const noexcept
{
return !(*this == node);
}
bool operator==(PtreeContainer other) const noexcept
{
return get() == other.get();
}
bool operator!=(PtreeContainer other) const noexcept
{
return !(*this == other);
}
value_type operator[](size_type index) const noexcept
{
size_type i = 0;
for (auto it = begin(); it != end(); ++it)
{
if (i++ == index)
{
return *it;
}
}
return value_type{};
}
Iterator begin() const noexcept
{
return m_nodes;
}
Iterator end() const noexcept
{
return nullptr;
}
bool empty() const noexcept
{
return begin() == end();
}
value_type front() const noexcept
{
return (*this)[0];
}
value_type back() const noexcept
{
value_type last{};
for (auto cur : *this)
{
last = cur;
}
return last;
}
Node_t* get() const noexcept
{
return m_nodes;
}
difference_type count() const noexcept
{
return std::distance(begin(), end());
}
bool has_at_least(size_type n) const noexcept
{
size_type counter = 0;
for (auto it = begin(); it != end(); ++it)
{
if (++counter == n)
{
return true;
}
}
return false;
}
private:
Node_t* m_nodes = nullptr;
};
template <typename Node_t, typename Deref_t = std::add_pointer_t<Node_t>>
using PtreeStatementList =
PtreeContainer<PtreeStatementIterator, Node_t, Deref_t>;
template <typename Node_t, typename Deref_t = std::add_pointer_t<Node_t>>
using PtreeItemList =
PtreeContainer<PtreeListIterator, Node_t, Deref_t>;
template <typename Node_t, typename Deref_t = std::add_pointer_t<Node_t>>
using PtreeCountedStatementList =
PtreeContainer<PtreeStatementCountingIterator, Node_t, Deref_t>;
template <typename Node_t, typename Deref_t = std::add_pointer_t<Node_t>>
using PtreeCountedItemList =
PtreeContainer<PtreeListCountingIterator, Node_t, Deref_t>;
Если хотите поделиться этой статьей с англоязычной аудиторией, то прошу использовать ссылку на перевод: Yuri Minaev. How to climb a tree.
