Свежий взгляд на традиционные концепции. Сегодня будет такой «декарт» которого в школе не проходили.

Суть алгоритма в том, что на основании массива строится так называемое декартово дерево. А из построенного декартового дерева очень легко получить все элементы в порядке возрастания или убывания.
Декартово дерево является гибридной структурой, объединяющей в себе свойства кучи и бинарного дерева поиска. Для этого дерева есть синонимы, которые будут использоваться в статье:
дерамида (дерево + пирамида),
трип (treap — tree + heap)
и даже дуча (дерево + куча).
Давайте возьмём для примера вот этот массив:

и последовательно взглянем, как для него выглядит двоичное дерево поиска, куча и дерамида.
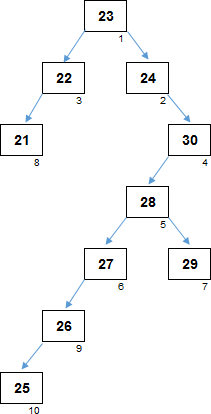
Внешний вид дерева сильно зависит от того, как изначально расположены элементы массива. На рандомных данных, дерево с высокой долей вероятности получится несбалансирвоанным, с гораздо большим количеством уровней, по сравнению с оптимальным. В нашем примере образовалось 7 уровней. Если бы элементы массива располагались, например, в таком порядке:
25, 28, 29, 23, 30, 27, 24, 22, 21, 26
дерево поиска бы получилось сбалансированным, с минимально возможным количеством уровней (= 4). Сортировка с помощью сбалансированного дерева имела бы сложность по времени:O(n log n) . Но в случае несбалансированного дерева может деградировать и до O(n2) .
В предыдущей хабрастатье рассмотрена сортировка бинарным деревом поиска, а также её интересная модификация, позволяющая гарантировано сортировать с временно́й сложностьюO(n log n) .
Чем более несбалансированным будет дерево поиска, тем более затратным будет его обход.
С другой стороны, хранение данных в дереве поиска весьма удобно с организационной точки зрения, позволяет с этими данными делать очень многие операции, сортировать в том числе.
Родитель в двоичном дереве поиска необязательно больше чем потомок. Но при этом левый потомок всегда меньше родителя, правый потомок всегда больше родителя (или равен ему).
Максимальный элемент массива при построении дерева поиска попадает где-то в правое поддерево. Чтобы этот максимум извлечь, дерево поиска надо полностью обойти.
В обычной куче очень просто организованы взаимосвязи «родитель — потомок», они привязаны к самим индексам элементов.

На рисунке на самом деле пока ещё не куча, поскольку такое дерево, изначально построенное на рандомном массиве ещё не является сортирующим. Нужно обойти каждый элемент и сделать для него просейку. В результате элементы в массиве перестроятся так, что каждый родитель будет больше своего потомка:

Максимальный элемент находится в корне дерева. Его расположение известно, его искать не нужно. С другой стороны, при если извлечь максимум из кучи (и вместо него в корень дерева приходится ставить какой-то другой элемент массива), куча перестаёт быть сортирующим деревом, её нужно опять просеивать.
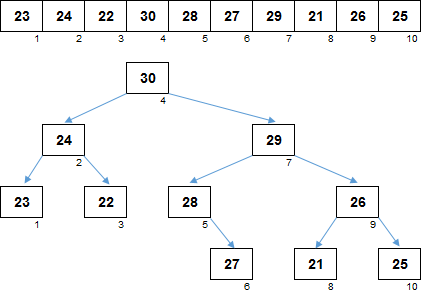
И, наконец, декартово дерево. Взаимосвязи установлены таким образом, что с одной стороны, оно является кучей, если смотреть на значения элементов. Все родители больше своих потомков:
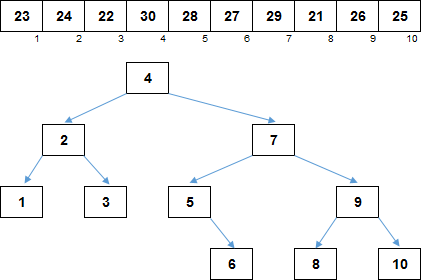
С другой стороны, структура является бинарным деревом поиска, если смотреть на индексы элементов. На изображении в дереве для наглядности убрали в узлах значения элементов, оставили только индексы. Каждый левый потомок меньше родителя, каждый правый потомок — больше родителя:
С одной стороны, мы имеем быстрый доступ к максимальному элементу. Так как это куча, то максимум находится в корне.
С другой стороны, из структуры легко можно удалить максимум и работать с оставшимися данными дальше. Так как это бинарное дерево поиска, удаление корня не связано с большими затратами. Во взаимосвязях «родители-потомки» происходят относительно небольшие изменения, в корень декартова дерева попадает новый максимум и можно работать дальше.
Каждый элемент характеризуется двумя числами — значением элемента и индексом элемента в массиве. Индекс можно считать за координату X, значение — за Y, а сам элемент интепретировать как точку на координатной плоскости. Если родителей и потомков соединить стрелками, то получается примерно такая картина:

Фигура на графике полностью изоморфна декартову дереву чуть выше.
Итоговый алгоритм:

Декартово дерево с минимальными затратами обрабатывает отсортированные и почти отсортированные (причём неважно, по возрастанию или убыванию) участки массива. Вот, например, так выглядит процесс для реверсно упорядоченного массива:

Самая затратная часть алгоритма — это операция Merge, которую для каждого из n элементов приходится делать дважды — сначала при построении дерамиды и затем при её разборке. На рандомных данных однократная операция Merge обходится вO(log n) , но для элементов, находящихся в упорядоченных областях массива стоимость операции O(1).
Таким образом, средняя и худшая временна́я сложность сортировки —O(n log n) , лучшая — O(n).
По дополнительной памяти дела обстоят похуже — O(n). Если бы декартово дерево было просто разновидностью кучи, то затраты были бы O(1). Но cartesian tree — это также и дерево бинарного поиска, из-за чего для всех n элементов приходится отдельно хранить взаимосвязи «родители-потомки».
Кроме того, реализация именно в таком виде означает, что это внешняя сортировка — отсортированные элементы собираются в отдельном массив. А это ещё O(n) по дополнительной памяти.
 Cartesian
Cartesian
 Декартово дерево: Часть 1, Часть 2, Часть 3
Декартово дерево: Часть 1, Часть 2, Часть 3
В приложение AlgoLab добавлена сегодняшняя сортировка декартовым деревом, кто пользуется — обновите excel-файл с макросами. Рекомендую брать массивы с небольшим разбросом в значениях элементов — иначе декартова плоскость не будет помещаться на экране.
Суть алгоритма в том, что на основании массива строится так называемое декартово дерево. А из построенного декартового дерева очень легко получить все элементы в порядке возрастания или убывания.
В рамках этой статьи я решил воздержаться от подробной теории и не стану разъяснять, что такое декартово дерево, как его построить и какие с ним возможны операции. Это уже прекрасно сделано и до меня — на Хабре есть превосходный материал, где все эти моменты удачно и подробно освещены — в конце этой лекции есть раздел «Ссылки», где можно перейти к этим хабрастатьям. В дальнейшем я буду освещать некоторые моменты, характерные для этой структуры, но при этом подразумевается, что вы понимаете её специфику или, в случае заинтересованности, готовы её изучить по указанным ниже ссылкам.
Компания EDISON всегда рада приобщиться к прекрасному.
Один из наших классических проектов — диагностика хранилища документов Vivaldi, благодаря чему оптимизирован одновременный доступ к тысячам документам и произведениям в сетевой библиотеке.
Мы очень любим сеять разумное, доброе, вечное! ;-)


Декартово дерево является гибридной структурой, объединяющей в себе свойства кучи и бинарного дерева поиска. Для этого дерева есть синонимы, которые будут использоваться в статье:
дерамида (дерево + пирамида),
трип (treap — tree + heap)
и даже дуча (дерево + куча).
Давайте возьмём для примера вот этот массив:
и последовательно взглянем, как для него выглядит двоичное дерево поиска, куча и дерамида.
Бинарное дерево поиска
Внешний вид дерева сильно зависит от того, как изначально расположены элементы массива. На рандомных данных, дерево с высокой долей вероятности получится несбалансирвоанным, с гораздо большим количеством уровней, по сравнению с оптимальным. В нашем примере образовалось 7 уровней. Если бы элементы массива располагались, например, в таком порядке:
25, 28, 29, 23, 30, 27, 24, 22, 21, 26
дерево поиска бы получилось сбалансированным, с минимально возможным количеством уровней (= 4). Сортировка с помощью сбалансированного дерева имела бы сложность по времени:
В предыдущей хабрастатье рассмотрена сортировка бинарным деревом поиска, а также её интересная модификация, позволяющая гарантировано сортировать с временно́й сложностью
Чем более несбалансированным будет дерево поиска, тем более затратным будет его обход.
С другой стороны, хранение данных в дереве поиска весьма удобно с организационной точки зрения, позволяет с этими данными делать очень многие операции, сортировать в том числе.
Родитель в двоичном дереве поиска необязательно больше чем потомок. Но при этом левый потомок всегда меньше родителя, правый потомок всегда больше родителя (или равен ему).
Максимальный элемент массива при построении дерева поиска попадает где-то в правое поддерево. Чтобы этот максимум извлечь, дерево поиска надо полностью обойти.
Бинарная куча
В обычной куче очень просто организованы взаимосвязи «родитель — потомок», они привязаны к самим индексам элементов.
На рисунке на самом деле пока ещё не куча, поскольку такое дерево, изначально построенное на рандомном массиве ещё не является сортирующим. Нужно обойти каждый элемент и сделать для него просейку. В результате элементы в массиве перестроятся так, что каждый родитель будет больше своего потомка:
Максимальный элемент находится в корне дерева. Его расположение известно, его искать не нужно. С другой стороны, при если извлечь максимум из кучи (и вместо него в корень дерева приходится ставить какой-то другой элемент массива), куча перестаёт быть сортирующим деревом, её нужно опять просеивать.
Декартово дерево
И, наконец, декартово дерево. Взаимосвязи установлены таким образом, что с одной стороны, оно является кучей, если смотреть на значения элементов. Все родители больше своих потомков:
С другой стороны, структура является бинарным деревом поиска, если смотреть на индексы элементов. На изображении в дереве для наглядности убрали в узлах значения элементов, оставили только индексы. Каждый левый потомок меньше родителя, каждый правый потомок — больше родителя:
С одной стороны, мы имеем быстрый доступ к максимальному элементу. Так как это куча, то максимум находится в корне.
С другой стороны, из структуры легко можно удалить максимум и работать с оставшимися данными дальше. Так как это бинарное дерево поиска, удаление корня не связано с большими затратами. Во взаимосвязях «родители-потомки» происходят относительно небольшие изменения, в корень декартова дерева попадает новый максимум и можно работать дальше.
Каждый элемент характеризуется двумя числами — значением элемента и индексом элемента в массиве. Индекс можно считать за координату X, значение — за Y, а сам элемент интепретировать как точку на координатной плоскости. Если родителей и потомков соединить стрелками, то получается примерно такая картина:
Фигура на графике полностью изоморфна декартову дереву чуть выше.
Сортировка декартовым деревом :: Cartesian tree sort
Итоговый алгоритм:
- I. На основании неотсортированного массива строим декартово дерево:
- I.1. Перебираем элементы массива слева-направо.
- I.1. Если это первый элемент массива, то он просто является самым первым узлом декартова дерева.
- I.2. Если это не первый элемент массива, считаем что это декартово дерево, состоящее из одного элемента. Производим операцию Merge этого дерева с тем деревом, которое построено из предыдущих элементов.
- II. Текущий максимальный элемент удаляем из дерева, после чего восстанавливаем декартово дерево.
- II.1. Текущий максимальный элемент — корень дерева.
- II.2. Удаляем из дерева корень, сам максимальный элемент переносим в дополнительный массив.
- II.3. После удаления корня структура распалось на два декартова дерева.
- II.4. Для этих двух деревьев производим операцию Merge. Новым текущим максимумом становится один из корней объединяемых деревьев.
- II.5. Для нового максимума снова повторяем действия II.1-II.4.
Сложность
Декартово дерево с минимальными затратами обрабатывает отсортированные и почти отсортированные (причём неважно, по возрастанию или убыванию) участки массива. Вот, например, так выглядит процесс для реверсно упорядоченного массива:
Самая затратная часть алгоритма — это операция Merge, которую для каждого из n элементов приходится делать дважды — сначала при построении дерамиды и затем при её разборке. На рандомных данных однократная операция Merge обходится в
Таким образом, средняя и худшая временна́я сложность сортировки —
По дополнительной памяти дела обстоят похуже — O(n). Если бы декартово дерево было просто разновидностью кучи, то затраты были бы O(1). Но cartesian tree — это также и дерево бинарного поиска, из-за чего для всех n элементов приходится отдельно хранить взаимосвязи «родители-потомки».
Кроме того, реализация именно в таком виде означает, что это внешняя сортировка — отсортированные элементы собираются в отдельном массив. А это ещё O(n) по дополнительной памяти.
Ссылки
Статьи серии:
- Excel-приложение AlgoLab.xlsm
- Сортировки обменами
- Сортировки вставками
- Сортировки выбором
- Сортировки слиянием
- Сортировки распределением
- Гибридные сортировки
В приложение AlgoLab добавлена сегодняшняя сортировка декартовым деревом, кто пользуется — обновите excel-файл с макросами. Рекомендую брать массивы с небольшим разбросом в значениях элементов — иначе декартова плоскость не будет помещаться на экране.

