Общая суть сортировок вставками такова:
- Перебираются элементы в неотсортированной части массива.
- Каждый элемент вставляется в отсортированную часть массива на то место, где он должен находиться.
Самое слабое место в этом подходе — вставка элемента в отсортированную часть массива. На самом деле это непросто и на какие только ухищрения не приходится идти, чтобы выполнить этот шаг.
Сортировка простыми вставками

Проходим по массиву слева направо и обрабатываем по очереди каждый элемент. Слева от очередного элемента наращиваем отсортированную часть массива, справа по мере процесса потихоньку испаряется неотсортированная. В отсортированной части массива ищется точка вставки для очередного элемента. Сам элемент отправляется в буфер, в результате чего в массиве появляется свободная ячейка — это позволяет сдвинуть элементы и освободить точку вставки.
def insertion(data): for i in range(len(data)): j = i - 1 key = data[i] while data[j] > key and j >= 0: data[j + 1] = data[j] j -= 1 data[j + 1] = key return data
На примере простых вставок показательно смотрится главное преимущество большинства (но не всех!) сортировок вставками, а именно — очень быстрая обработка почти упорядоченных массивов:

При таком раскладе даже самая примитивная реализация сортировки вставкам, скорее всего, обгонит супер-оптимизированный алгоритм какой-нибудь быстрой сортировки, в том числе и на больших массивах.
Этому способствует сама основная идея этого класса — переброска элементов из неотсортированной части массива в отсортированную. При близком расположении близких по величине данных место вставки обычно находится близко к краю отсортированной части, что позволяет вставлять с наименьшими накладными расходами.
Нет ничего лучше для обработки почти упорядоченных массивов чем сортировки вставками. Когда Вы где-то встречаете информацию, что лучшая временна́я сложность сортировки вставками равна
Сортировка простыми вставками с бинарным поиском

Так как место для вставки ищется в отсортированной части массива, то идея использовать бинарный поиск напрашивается сама собой. Другое дело, что поиск места вставки не является критичным для временно́й сложности алгоритма (главный пожиратель ресурсов — этап самой вставки элемента в найденную позицию), поэтому данная оптимизация здесь мало что даёт.
А в случае почти отсортированного массива бинарный поиск может работать даже медленнее, поскольку он начинает с середины отсортированного участка, который, скорее всего, будет находиться слишком далеко от точки вставки (а на обычный перебор от позиции элемента до точки вставки уйдёт меньше шагов, если данные в массиве в целом упорядочены).
def insertion_binary(data): for i in range(len(data)): key = data[i] lo, hi = 0, i - 1 while lo < hi: mid = lo + (hi - lo) // 2 if key < data[mid]: hi = mid else: lo = mid + 1 for j in range(i, lo + 1, -1): data[j] = data[j - 1] data[lo] = key return data
В защиту бинарного поиска отмечу, что он может сказать решающее слово в эффективности других сортировок вставками. Благодаря ему, в частности, на среднюю сложность по времени
Па́рная сортировка простыми вставками
Модификация простых вставок, разработанная в тайных лабораториях корпорации Oracle. Эта сортировка входит в пакет JDK, является составной частью Dual-Pivot Quicksort. Используется для сортировки малых массивов (до 47 элементов) и сортировки небольших участков крупных массивов.

В буфер отправляются не один, а сразу два рядом стоя́щих элемента. Сначала вставляется больший элемент из пары и сразу после него метод простой вставки применяется к меньшему элементу из пары.
Что это даёт? Экономию для обработки меньшего элемента из пары. Для него поиск точки вставки и сама вставка осуществляются только на той отсортированной части массива, в которую не входит отсортированная область, задействованная для обработки большего элемента из пары. Это становится возможным, поскольку больший и меньший элементы обрабатываются сразу друг за другом в одном проходе внешнего цикла.
На среднюю сложность по времени это не влияет (она так и остаётся равной
Алгоритмы я иллюстрирую на Python, но тут приведу первоисточник (видоизменённый в целях читабельности) на Java:
for (int k = left; ++left <= right; k = ++left) { //Очередную пару рядом стоя́щих элементов //заносим в пару буферных переменных int a1 = a[k], a2 = a[left]; if (a1 < a2) { a2 = a1; a1 = a[left]; } //Вставляем больший элемент из пары while (a1 < a[--k]) { a[k + 2] = a[k]; } a[++k + 1] = a1; //Вставляем меньший элемент из пары while (a2 < a[--k]) { a[k + 1] = a[k]; } a[k + 1] = a2; } //Граничный случай, если в массиве нечётное количество элементов //Для последнего элемента применяем сортировку простыми вставками int last = a[right]; while (last < a[--right]) { a[right + 1] = a[right]; } a[right + 1] = last;
Сортировка Шелла

В этом алгоритме очень остроумный подход в определении того, какую именно часть массива считать отсортированной. В простых вставках все просто: от текущего элемента всё что слева — уже отсортировано, всё что справа — ещё не отсортировано. В отличие от простых вставок сортировка Шелла не пытается слева от элемента сразу формировать строго отсортированную часть массива. Она создаёт слева от элемента почти отсортированную часть массива и делает это достаточно быстро.
Сортировка Шелла закидывает текущий элемент в буфер и сравнивает его с левой частью массива. Если находит бо́льшие элементы слева, то сдвигает их вправо, освобождая место для вставки. Но при этом берёт не всю левую часть, а только некоторую группу элементов из неё, где элементы разнесены друг от друга на некоторое расстояние. Такая система позволяет быстро вставлять элементы примерно в ту область массива, где они должны находиться.
С каждой итерацией основного цикла это расстояние постепенно уменьшается и когда оно становится равным единице, то сортировка Шелла в этот момент превращается в классическую сортировку простыми вставками, которой дали на обработку почти отсортированный массив. А почти отсортированный массив сортировка вставками в полностью отсортированный преобразует быстро.
def shell(data): inc = len(data) // 2 while inc: for i, el in enumerate(data): while i >= inc and data[i - inc] > el: data[i] = data[i - inc] i -= inc data[i] = el inc = 1 if inc == 2 else int(inc * 5.0 / 11) return data
Сортировка расчёской по похожему принципу улучшает пузырьковую сортировку, благодаря чему временна́я сложность алгоритма с
Про сортировку Шелла написано несколько хабрастатей, поэтому не будем перегружаться информацией и двигаемся дальше.
Сортировка деревом
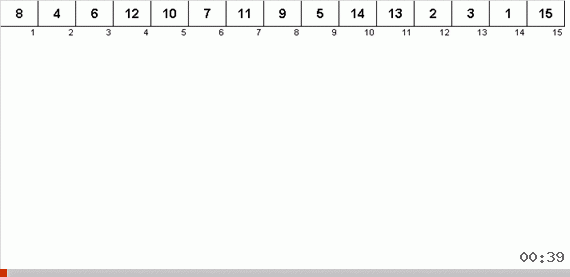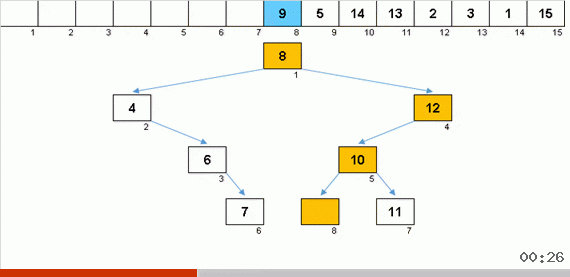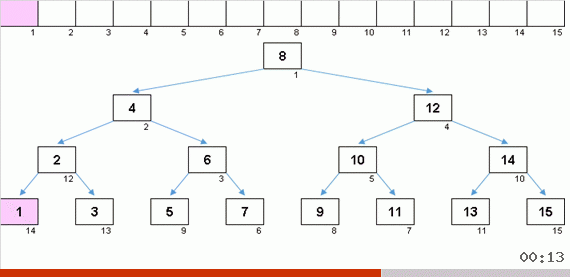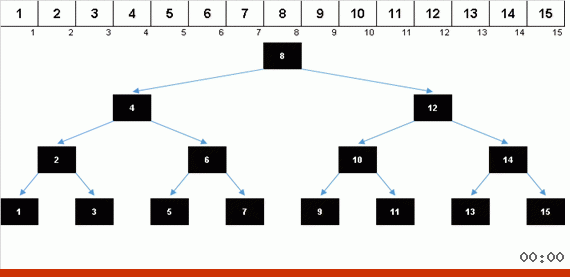
Сортировка деревом за счёт дополнительной памяти быстро решает вопрос с добавлением очередного элемента в отсортированную часть массива. Причём в роли отсортированной части массива выступает бинарное дерево. Дерево формируется буквально на лету при переборе элементов.
Элемент сравнивается сначала с корнем, а потом и с более вложенными узлами по принципу: если элемент меньше чем узел — то спускаемся по левой ветке, если не меньше — то по правой. Построенное по такому правилу дерево затем можно легко обойти так, чтобы двигаться от узлов с меньшими значениями к узлам с большими значениями (и таким образом получить все элементы в возрастающем порядке).
Основная загвоздка сортировок вставками (затраты на вставку элемента на своё место в отсортированной части массива) здесь решена, построение происходит вполне оперативно. Во всяком случае для освобождения точки вставки не нужно медленно передвигать караваны элементов как в предыдущих алгоритмах. Казалось бы, вот она, наилучшая из сортировок вставками. Но есть проблема.
Когда получается красивая симметричная ёлочка (так называемое идеально сбалансированное дерево) как в анимации тремя абзацами выше, то вставка происходит быстро, поскольку дерево в этом случае имеет минимально возможную вложенность уровней. Но сбалансированная (или хотя бы близкая к таковой) структура из рандомного массива получается редко. И дерево, скорее всего, будет неидеальное и несбалансированное — с перекосами, заваленным горизонтом и избыточным количеством уровней.
Рандомный массив со значениями от 1 до 10. Элементы в таком порядке генерируют несбалансированное двоичное дерево:

Дерево мало построить, его ещё нужно обойти. Чем больше несбалансированности — тем сильнее будет буксовать алгоритм по обходу дерева. Тут как скажут звёзды, рандомный массив может породить как уродливую корягу (что более вероятно) так и древовидный фрактал.
Значения элементов те же, но порядок другой. Генерируется сбалансированное двоичное дерево:


На прекрасной сакуре
Не хватает лепестка:
Бинарное дерево из десятки.
Проблему несбалансированных деревьев решает сортировка выворачиванием, которая использует особую разновидность бинарного дерева поиска — splay tree. Это замечательное древо-трансформер, которое после каждой операции перестраивается в сбалансированное состояние. Про это будет отдельная статья. К тому времени подготовлю и реализации на Python как для Tree Sort, так и для Splay sort.
Ну чтож, мы кратенько прошлись по самым популярным сортировкам вставками. Простые вставки, Шелл и двоичное дерево мы все знаем ещё со школы. А теперь рассмотрим других представителей этого класса, не столь широко известных.
Вики / Wiki —
Статьи серии:
- Excel-приложение AlgoLab.xlsm
- Сортировки обменами
- Сортировки вставками
- Сортировка библиотекаря
- Пасьянсная сортировка
- Сортировка «Ханойская башня»
- Сортировка выворачиванием
- Сортировка таблицей Юнга
- Сортировки выбором
- Сортировки слиянием
- Сортировки распределением
- Гибридные сортировки
Кто пользуется AlgoLab — рекомендую обновить файл. Я добавил в это приложение простые вставки с бинарным поиском и па́рные вставки. Также полностью переписал визуализацию для Шелла (в предыдущей версии там было не пойми что) и добавил подсветку родительской ветки при вставке элемента в бинарное дерево.

