
Не утихают споры о том, нужны ли юнит-тесты вообще, а если нужны — то как именно их писать. Сначала писать код или сначала писать тесты? Допустимо ли нарушать инкапсуляцию при тестировании или же можно трогать только публичное API? Сколько процентов кода должно быть покрыто тестами?
Тестирование во встраиваемых системах тоже порождает немало споров. Точки зрения разнятся от "покрытие должно быть 100% + нужны испытательные стенды" до "какие еще тесты, я программу написал — значит все работает".
Я не хочу начинать холивар и вооще стараюсь придерживаться некоего разумного баланса. Поэтому для начала предлагаю рассмотреть самые "низко висящие" плоды, которые позволяет сорвать юнит-тестирование применительно к embedded-разработке.
- Можно писать код для устройства, которого у вас еще нет. Это может быть датчик с алиэкспресса, который почтой идет две недели или какой-нибудь отечественный девайс со сроком поставки в полгода — это не столь важно.
- Можно менять код и не бояться, что ваши изменения сломают что-то, что работало раньше (если это что-то покрыто тестами, разумеется).
- Следствие предыдущего пункта: вы можете передавать разработку другому человеку и тоже не бояться, что он сломает что-то, что раньше работало.
- Если вы пишете какие-нибудь библиотеки (в минимуме — просто какой-то код, который используется не один раз), то с помощью тестов вы можете синтезировать ситуации, которые "руками" можно ловить очень долго.
- В тестовой конфигурации можно использовать всякие дополнительные инструменты для оценки качества/надежности кода — санитайзеры, опции компилятора для защиты от переполнения стека и тому подобные вещи, которые в "боевую" прошивку не влезают
Первый пункт сильно зависит от того, насколько документация на устройство соответствует действительности, но мой опыт показывает, что небольшие несоответствия все же не вызывают необходимости переписывать прям всё к чертям, а приводят к небольшим же изменениям в коде.
Второй и третий пункт предполагают, что ваши тесты действительно что-то проверяют (но если нет, то зачем их вообще писать?).
Разумеется, каждый решает сам для себя, нужны ему тесты или нет (если только у вас нет корпоративной политики, что они нужны); в этой статье я никого ни в чем не пытаюсь убедить, а просто рассказываю, как можно эти самые тесты писать и запускать, и как тестировать некоторые специфические вещи.
Далее пойдет речь о юнит-тестировании кода для встраиваемых систем — в основном, микроконтроллеров (МК). Предполагается что код на С и С++
- Как можно запускать тесты?
- Что тестировать?
- Историческая перспектива и локальная специфика
- Запуск тестов в симуляторе Keil'a
- Тесты интерфейсов связи
- Инициализация и деинициализация
- Тестирование assert'ов
- Что делать, если ассерт провалился
- Допустимо ли оставлять ассерты в "релизной" прошивке
- Допустимо ли вообще писать ассерты или все ошибки должны обрабатываться
- Какой ассерт использовать
- Ассерт времени выполнения:
- Ассерт времени компиляции:
- Нужно ли тестировать ассерты (и как)
- Ассерт времени компиляции
- Ассерт времени выполнения
- Ремарка про стек и кучу
- Тесты и ОСРВ
- Тесты на ПК
- Известные проблемы
- Личный опыт
- Подведем итоги
Как можно запускать тесты?
На мой взгляд, глобально можно выделить 3 способа:
- На обычном ПК (настольном или на тестовом сервере, не суть)
- На физическом МК — т.е. на специальной тестовой плате
- В симуляторе МК
Давайте разберем плюсы и минусы каждого подхода.
На обычном ПК
Плюсы:
- тесты выполняются максимально быстро
- у ПК много памяти, тестовый бинарник может быть существенно больше, чем релизная прошивка
- не нужна физическая плата; тестовое окружение можно сделать легко воспроизводимым
- можно использовать дополнительный инструментарий — valgrind, санитайзеры
- легко выводить результаты тестов — в stdout, в красивое окно, в текстовый файл — на ваш вкус
Спорный момент:
Другой компилятор и другая стандартная библиотека. Это плюс, потому что позволяет отловить платформозависимый код, получить больше предупреждений от нового компилятора. Но не факт, что вы к этому стремитесь. Минус, собственно, в этом же — придется писать платформонезависимый код, скорее всего, оборачиваясь в условную компиляцию; иногда придется подкостыливать код для работы под компилятором, который вам вообще и не нужен для собственно рабочей прошивки.
Минусы:
- почти наверняка другая архитектура процессора — т.е. какие-то вещи могут работать не так, как в релизной прошивке на целевом устройстве (например, какие-нибудь тонкие отличия между программной реализацией плавающей точки в МК и аппаратной у х86)
- нужно держать параллельный проект для другого компилятора/системы сборки. Трудоемкость этого зависит от системы сборки, которую вы выберете.
- трудно тестировать прерывания
- трудно тестировать работу с ОСРВ
На физическом МК
Плюсы:
- архитектура та же, что у целевого устройства
- тесты выполняются достаточно быстро
- легко тестировать прерывания и работу с ОСРВ
- можно тестировать работу с внешними устройствами
Спорный момент все тот же, только с другой стороны — компилятор, стандартная библиотека и рантайм такие же, как и в релизе.
Минусы:
- мало памяти — как для кода, так и оперативной
- нужна физическая тестовая плата, источник питания и т.д.
- нужен какой-то интерфейс для связи с ПК или с чем-то еще, чтобы выводить результаты тестирования
- короче, нужен тестовый стенд
В симуляторе
Плюсы:
- архитектура примерно та же, что и на целевом устройстве
- не нужна плата или тестовый стенд
- симулированной памяти может быть много
- если симулятор сможет, то можно тестировать прерывания и работу с ОСРВ
Спорный момент все тот же.
Минусы:
- нужен симулятор
- самый медленный вариант из трех
- симулятор не совсем идентичен физическому МК, это может породить тонкие проблемы
Следующий интересный вопрос — что покрывать тестами, а что нет?
Что тестировать?
С одной стороны, некоторые вещи тестить легко, а некоторые — тяжело. С другой, некоторые вещи как будто сильнее нуждаются в тестах, а другие — слабее.
Если разобраться, то легко тестить код, который слабо завязан на какие-то сложные концепции или аппаратную специфику. Например, общение с каким-нибудь датчиком легко абстрагируется от реального физического интерфейса — такому коду вполне достаточно умения принять пачку байт и отправить пачку байт.
А, скажем, код для управления BLDC-двигателем тестируется тяжело, потому что для этого нужна, фактически, виртуальная модель двигателя. Или, скажем, попиксельное рисование на каком-нибудь OLED-экране гораздо проще проверять визуально.
А вот насколько сильно вещи нуждаются в тестах, сильно зависит от задачи.
Что же выбрать? Тут я, опять-таки, не берусь давать универсальных советов, а вместо этого попытаюсь обосновать наш выбор с исторической точки зрения. Если вам это не очень интересно, то можете следующую главу смело пропустить.
Историческая перспектива и локальная специфика
Сперва специфика. Тут я не придумал, как можно эти факты упорядочить или сгруппировать, поэтому просто перечислю.
Сперва вещи, над которыми программисты не властны:
- проектов (т.е. изделий) много, их разработка часто происходит одновременно. Длительность проектов от полугода до полутора лет; что-то более долгоиграющее попадается редко
- каждое изделие содержит одну, но чаще несколько плат с микроконтроллерами, эти платы связываются друг с другом какими-нибудь интерфейсами, поскольку должны взаимодействовать
- изделия сами по себе разные, но в них есть повторяющиеся или похожие "куски", как-то:
- общение по интерфейсам связи между платами
- управление DC и BLDC двигателями
- общение с разнообразными датчиками и прочими покупными изделиями
- работа с матричными клавиатурами и матрицами светодиодов
- некоторые изделия должны быть выполнены на отечественной элементной базе
А остальное — просто "исторически сложилось", иногда без всякой рациональной причины:
- почти всегда действует правило "одна прошивка — один разработчик". С одной стороны это снижает трудозатраты на слияния, но с другой стимулирует людей "окукливаться" в своем мирке, не обмениваться кодом и переизобретать велосипеды
- вся команда сидела под Windows, в качестве IDE использовался uVision Keil. Тут нет рациональных причин, только рационализации :)
- МК — только ARM Cortex; в основном — STM32, для "отечки" — Миландр. Во многом дело вкуса.
- изначально разработка велась на чистом С, но очень медленно перешла на С++
- никто из команды (включая меня) не учился на программиста
- никаких аджайлов, скрамов и прочих методов выпаса кошачьих не применялось
- начиналась вся эта история примерно в 2013 году — C++11 появился совсем недавно, Keil был версии 4.20 вроде бы и С++11 не поддерживал
К чему же все это привело? А вот к чему.
Разработчики разобщены и стремятся закуклиться, поэтому любые инновации нужно подавать постепенно; они не должны требовать установки 10 программ и полной смены рабочего процесса. Поэтому отпадает вариант "тестирование на ПК" — это потребовало бы ставить какую-то другую IDE, другой компилятор, вести в нем параллельный проект — слишком сложно.
Поэтому же отпадают все варианты, которые требуют ставить Linux (например, запуск тестов в QEMU).
Использование тестовой платы отпадает по умеренно-объективным причинам — нужна плата (и желательно не одна), просто слишком много возни по сравнению с чисто программными вариантами.
Таким образом историческая неизбежность приводит нас к запуску тестов в симуляторе Keil. А отсутствие хороших програмистстких практих подталкивает к велосипедостроению :)
Запуск тестов в симуляторе Keil'a
Выбор фреймворка
Я, честно говоря, уже плохо помню, чем я руководствовался, когда выбирал фреймворк, слишком много лет прошло. Кажется, я успел посмотреть на GoogleTest, но счел его слишком большим и сложным, фреймворки на чистом С были страшненькими и либо нуждались в ручной регистрации каждого теста, либо опирались на сторонние скрипты, с которыми связываться было не очень охота.
А у CppUTest был пример для IAR'a (а это почти как Keil).
В целом, это не очень важно. Главное, что CppUTest достаточно легко скомпилировался в Keil'e; для этого пришлось создать всего один файл, наполненный платформозависимыми функциями. Практически все оттуда я передрал из аналогичного файла для IAR, если честно.
Для полноты картины, привожу здесь этот файл целиком:
#include <stdio.h> #include <stdlib.h> #include <stdarg.h> #include <string.h> #include <math.h> #include <float.h> #include <ctype.h> #include <setjmp.h> #include "CppUTest/TestHarness.h" #include "CppUTest/PlatformSpecificFunctions.h" #include "CppUTest/TestRegistry.h" // скопировано из ИАРа static jmp_buf test_exit_jmp_buf[10]; static int jmp_buf_index = 0; int PlatformSpecificSetJmp(void (*function) (void* data), void* data) { if (0 == setjmp(test_exit_jmp_buf[jmp_buf_index])) { jmp_buf_index++; function(data); jmp_buf_index--; return 1; } return 0; } void PlatformSpecificLongJmp() { jmp_buf_index--; longjmp(test_exit_jmp_buf[jmp_buf_index], 1); } void PlatformSpecificRestoreJumpBuffer() { jmp_buf_index--; } void PlatformSpecificRunTestInASeperateProcess(UtestShell* shell, TestPlugin* plugin, TestResult* result) { printf("-p doesn't work on this platform as it is not implemented. Running inside the process\b"); shell->runOneTest(plugin, *result); } TestOutput::WorkingEnvironment PlatformSpecificGetWorkingEnvironment() { return TestOutput::vistualStudio; } ///////////// Time in millis static long TimeInMillisImplementation() { return 12345; } static long (*timeInMillisFp) () = TimeInMillisImplementation; long GetPlatformSpecificTimeInMillis() { return timeInMillisFp(); } void SetPlatformSpecificTimeInMillisMethod(long (*platformSpecific) ()) { timeInMillisFp = (platformSpecific == 0) ? TimeInMillisImplementation : platformSpecific; } ///////////// Time in String static const char* TimeStringImplementation() { return "Keil time needs work"; } static const char* (*timeStringFp) () = TimeStringImplementation; const char* GetPlatformSpecificTimeString() { return timeStringFp(); } void SetPlatformSpecificTimeStringMethod(const char* (*platformMethod) ()) { timeStringFp = (platformMethod == 0) ? TimeStringImplementation : platformMethod; } int PlatformSpecificAtoI(const char*str) { return atoi(str); } size_t PlatformSpecificStrLen(const char* str) { return strlen(str); } char* PlatformSpecificStrCat(char* s1, const char* s2) { return strcat(s1, s2); } char* PlatformSpecificStrCpy(char* s1, const char* s2) { return strcpy(s1, s2); } char* PlatformSpecificStrNCpy(char* s1, const char* s2, size_t size) { return strncpy(s1, s2, size); } int PlatformSpecificStrCmp(const char* s1, const char* s2) { return strcmp(s1, s2); } int PlatformSpecificStrNCmp(const char* s1, const char* s2, size_t size) { return strncmp(s1, s2, size); } char* PlatformSpecificStrStr(const char* s1, const char* s2) { return (char*) strstr(s1, s2); } int PlatformSpecificVSNprintf(char *str, size_t size, const char* format, va_list args) { char* buf = 0; int sizeGuess = size; int result = vsnprintf( str, size, format, args); str[size-1] = 0; while (result == -1) { if (buf != 0) free(buf); sizeGuess += 10; buf = (char*)malloc(sizeGuess); result = vsnprintf( buf, sizeGuess, format, args); } if (buf != 0) free(buf); return result; } PlatformSpecificFile PlatformSpecificFOpen(const char* filename, const char* flag) { return fopen(filename, flag); } void PlatformSpecificFPuts(const char* str, PlatformSpecificFile file) { fputs(str, (FILE*)file); } void PlatformSpecificFClose(PlatformSpecificFile file) { fclose((FILE*)file); } void PlatformSpecificFlush() { fflush(stdout); } int PlatformSpecificPutchar(int c) { return putchar(c); } void* PlatformSpecificMalloc(size_t size) { return malloc(size); } void* PlatformSpecificRealloc (void* memory, size_t size) { return realloc(memory, size); } void PlatformSpecificFree(void* memory) { free(memory); } void* PlatformSpecificMemCpy(void* s1, const void* s2, size_t size) { return memcpy(s1, s2, size); } void* PlatformSpecificMemset(void* mem, int c, size_t size) { return memset(mem, c, size); } double PlatformSpecificFabs(double d) { return fabs(d); } int PlatformSpecificIsNan(double d) { return isnan(d); } int PlatformSpecificVSNprintf(char *str, unsigned int size, const char* format, void* args) { while(1); return 0; //return vsnprintf( str, size, format, (va_list) args); } char PlatformSpecificToLower(char c) { return tolower(c); }
Помимо этого файла, во всем проекте пришлось разрешить исключения (ключом --exceptions) и выделить достаточно много памяти в стеке и в куче (килобайт по 15 примерно). Чтобы не засорять этим сборку, для тестов я создал отдельную конфигурацию — в Keil это называется "target".
Ну и, конечно же, пришлось убрать ключ --c99, прописанный в опциях компилятора, потому что с ним Keil даже.срр-файлы пытался компилировать как сишные.
В последних версиях Keil'a этой проблемы нет, поскольку режим С99 включается галочкой, которая действует только на файлы с расширением.с.
Вывод результатов
Вывод CppUTest делает просто printf'ами в терминал, но ведь у МК нет терминала. Как же быть?
На отладочной плате можно было бы воспользоваться выводом в UART, а результаты на компе смотреть, скажем, в putty — но симулятор Keil'a далеко не для всех МК поддерживает симуляцию UART'a.
К счастью, у многих МК на ядре Cortex есть специальный отладочный интерфейс ITM. Если пользоваться полноразмерным разъемом JTAG (или если вы пользуетесь отладчиком STLink через разъем SWD, то у этого разъема должна быть подключена нога SWO) и ваш аппаратный отладчик этот самый ITM поддерживает, то в stdout можно в него и перенаправить.
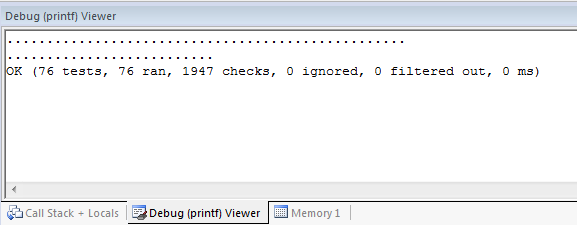
При этом, поскольку ITM является периферией уровня ядра, симулятор Keil'a поддерживает его всегда! Вывод при этом появляется в отладчике, в окне View->Serial windows->Debug (printf).
Чтобы сделать это перенаправление, потребуется переопределить несколько функций стандартной библиотеки. Это я делал методом проб и ошибок, на полноту и правоту не претендую, но вроде бы работает без нареканий. Перенаправлял я только stdout, поскольку в stdin и stderr нужды не испытывал.
#if __CC_ARM || ( (__ARMCC_VERSION) && (__ARMCC_VERSION >= 6010050) ) // armclang #if ( (__ARMCC_VERSION) && (__ARMCC_VERSION >= 6010050) ) asm(".global __use_no_semihosting_swi\n"); // armcc #elif __CC_ARM #pragma import(__use_no_semihosting_swi) namespace std { struct __FILE { int handle;} ; } #endif #include <stdio.h> #include <rt_sys.h> #include <rt_misc.h> std::FILE std::__stdout; std::FILE std::__stdin; std::FILE std::__stderr; extern "C" { int fputc(int c, FILE *f) { return ITM_SendChar(c); } int fgetc(FILE *f) { char ch = 0; return((int)ch); } int ferror(FILE *f) { /* Your implementation of ferror */ return EOF; } void _ttywrch(int ch) { ITM_SendChar(ch); } char *_sys_command_string(char *cmd, int len) { return NULL; } // вызывается после main void _sys_exit(int return_code) { while(1) { __BKPT(0xAA); } } } #endif
Сами тесты
Тут, на самом деле, никаких отличий от обычных тестов в CppUTest нету, но я все же приведу пример для наглядности
TEST(Loader, FirmwareCrcCheck_ErrorOnCheck) { makeLoaderReadyForBlockAddress(testLoader); sendSuccessfulWriteRandomDataBlock(testLoader, test_chunk_size); mockSender.isSent = false; // теперь флешер скажет, что срс не сходится mockFlasher.curMode = MockFlasher::Modes::ALL_FW_ERR; uint32_t crc = 0x11223344; uint32_t fwEnd = mockFlasher.getFreeFlashAddrMin() + Loader_Data_Block_Size; sendFwCrcCheck(testLoader, crc, fwEnd); checkIfError(); CHECK( mockFlasher.isAllFwChecked == true); // мы записывали только один блок CHECK( mockFlasher.fwStart == mockFlasher.getFreeFlashAddrMin() ); CHECK( mockFlasher.fwEnd == fwEnd); CHECK( mockFlasher.fwCrc == crc); }
Впечатления от CppUTest
Плюсы:
- быстро заработал в симуляторе
- не требуется ручная регистрация тестов
Минусы:
- требует С++, все тесты компилируются как код на С++ (но этот минус нивелируется переходом на С++)
- относительно много файлов в фреймворке
- требуется динамическая память и исключения. Справедливости ради скажу, что вместо исключений можно использовать
setjmp/longjmp, но уж лучше исключения! - поскольку исключения используются постоянно, отладка по шагам превращалась в очень увлекательное путешествие по библиотечному коду с внезапными прыжками туда-сюда
- поскольку тесты — это методы, названия тестов должны быть валидными идентификаторами. То есть
CamelCaseилиsnaking_case, ноNeitherOfThemIsVeryReadablewhen_test_name_is_long_enough, а названия тестов хочется делать подробными. - макросов для сравнения как-то уж слишком много:
CHECK— окей, все ясноCHECK_TEXT— хорошо, проверка с поясняющим текстомCHECK_FALSE— хмм, но почему бы не написатьCHECK( .. == false)?CHECK_EQUAL— э?STRCMP_EQUAL— стоп, серьезно? Но я ведь сам могу strcmp написать...STRNCMP_EQUAL— да ладноLONGS_EQUAL— CppUTest остановись, ты пьян!UNSIGNED_LONGS_EQUAL— аааа!!!
Нет, я все понимаю, у специализированных макросов обычно более понятный вывод, но это уже явно перебор! Да и Catch2 как-то справляется с однимREQUIRE.
- к тому же, мне весь этот более понятный вывод был до лампочки, поскольку я почти сразу начал практиковать TDD; в 90% случаев я заранее знал, какая именно проверка должна провалиться
- когда тест валился, в терминал выводилось сообщение типа такого:
src\Core\Loader\Bootloading\loader_test.cpp(815): error: Failure in TEST(Loader, SuccessfulWriteBlockWithoutErase) CHECK(mockFlasher.isBlockWritten != true) failed Errors (1 failures, 76 tests, 76 ran, 1942 checks, 0 ignored, 0 filtered out, 0 ms)
и потом провалившуюся проверку приходилось отыскивать по имени теста и номеру строки
- несколько раз тесты падали, потому что где-то в глубинах фреймворка не хватало стека или кучи, но понять это было очень сложно; неопытному мне из прошлого код казался очень запутанным
Разумеется, почти все эти минусы совершенно субъективные. У CppUTest большая и преданная аудитория, которую, вероятно, все устраивает. Но я решил на этом не останавливаться и двинулся дальше. А дальше мне на глаза попался munit.
Munit
Как я уже упоминал когда-то давно в своем посте про юнит-тесты на чистом С, munit — это самый маленький фреймворк для юнит-тестирования; настолько маленький, что его можно привести прямо в тексте статьи целиком:
#define mu_assert(message, test) do { if (!(test)) return message; } while (0) #define mu_run_test(test) do { char *message = test(); tests_run++; \ if (message) return message; } while (0) extern int tests_run;
Для меня в тот момент это было просто откровение! Никакого С++, никаких классов для тестов, произвольные строки в качестве названий и просто return 0, если все проверки пройдены! Никакой чехарды с исключениями!
К сожалению, отсутствие С++ означало сложности с автоматической регистрацией — борьбе с этим посвящена другой пост, в которой, фактически, был рожден маленький велосипедный тестовый фреймворк на С.
Этим фреймворком мы даже успели попользоваться какое-то время, но после относительно масштабного проекта, так же написанного на С, но в ООП стиле, мы, вдоволь нахлебавшись виртуального наследования вручную, сказали ХВАТИТ ЭТО ТЕРПЕТЬ и решили переходить на С++.
Ну а раз вся разработка переходит на С++, то можно и тестовый фреймворк обновить и избавиться от этой мути с BOOST_PP_COUNTER.
UmbaCppTest
И так был рожден новый велосипедный фреймворк для юнит-тестирования! Ееее! Кратко пробегусь по ключевым фишкам:
- автоматическая регистрация тестов (легко, когда есть конструкторы)
- названия тестов — произвольные строки
- не требуются исключения
- не требуется динамическое выделение памяти
- минимум макросов для проверок — фактически, только
UMBA_CHECK( cond, text ), но text — опциональный - фреймворк из двух файлов (один.срр и один .h)
- "киллер-фича": если проверка провалилась, то отладка останавливается на проблемной строке! Это тоже легко, симулятор корректно выполняет ассемблерную инструкцию
BKPT; очень удобно! - киллер-фича опциональная, можно как обычно — просто вывести в терминал сообщение, что тест провалился и выполнять тесты дальше
- поскольку фреймворк самодельный, его можно было легко и быстро дорабатывать по ходу дела, допиливать фичи, которые нужны только нам
Пример теста:
UMBA_TEST("Check timer with no overflow - one-shot timer shall be handled") { using namespace time_service; for( uint32_t i=0; i<1000; i++ ) { time_service::setCurTime_mcs( Microsec{ i*1000 } ); time_service::setCurTime_ms( i ); testLwipTask.work( i ); if( mockCallbacks.flag == true ) break; } UMBA_CHECK( mockCallbacks.flag == true ); return 0; }
А запуск всех тестов выглядит как-то так:
int main() { #ifdef USE_TESTS umba::runAllTests(); __BKPT(0xAA); while(1) {} #endif
При этом пользователь должен создать конфигурационный файл для фреймворка, который обязан называться umba_cpp_test_config.h и определить в нем несколько вещей:
#pragma once #include <stdint.h> // включить логирование #define UMBA_TEST_LOGGING_ENABLED 1 // выключить подвисание на упавшем тесте #define UMBA_TEST_HANG_ON_FAILED_TEST_ENABLED 1 #define UMBA_TEST_DISABLE_IRQ() __disable_irq() namespace umba { // максимальное количество тестов в одной группе const uint32_t tests_in_group_max = 200; // максимальное количество групп тестов const uint32_t groups_max = 100; }
Конечно, фреймворк очень простой, поэтому минусов у него тоже полно:
- нет автоматической генерации моков, фаззинга и прочих классных фишек
- проверочные макросы нельзя просто использовать во вспомогательных функциях, а не прямо внутри самого теста
- немножечко опирается на порядок инициализации глобальных переменных. В целом, это исправить легко, но никак руки не доходят — а работать вроде и так работает -_-'
Тесты интерфейсов связи
Как уже было сказано вначале, одним из самых удобных и полезных для юнит-тестирования вещей являются модули связи — всякие парсеры протоколов, модули общения с датчиками и тому подобное.
Как же их тестировать?
Возможны варианты. Для начала, что вообще нужно от интерфейса связи коду, который им пользуется? Например, от UART'a в самом минимуме нужно не так уж много:
- принять байт
- отправить байт
Принятый байт можно "скармливать" пользовательскому коду как параметр у функции, а для отправки пользоваться одним коллбэком.
Но отправлять один байт не всегда удобно, хочется отправлять массив. Окей, не проблема, для этого тоже хватит одного коллбэка.
Потом оказывается, что иногда нужно можно отправлять массив блокирующе (т.е. колбэк может не возвращать управление, пока не отправит массив целиком), а иногда нельзя.
Иногда массив локальный — и тогда в неблокирующем варианте его приходится куда-то копировать — а иногда он слишком большой, чтобы его куда-то копировать, но зато статический.
Потом вдруг выясняется, что конкретный датчик может при первом включении работать на любом из 10 разных бодрейтов...
Короче, передавать 10 разных коллбэков по одному как-то глупо. Само собой напрашивается решение — сделать класс "обертка над UART'ом", а в нем методы. И тогда для каждого UART'a мы просто создаем экземпляр такой обертки.
Допустим. Но как же их тогда тестировать? Нам нужно, чтобы в тестовой сборке методы делали одно, а в релизной — другое.
По факту, нам нужен полиморфизм. И вот тут начинаются вопросы.
- С одной стороны, для этого не нужен полиморфизм времени выполнения, т.е. можно обойтись ifdef'ами
- С другой, это как-то не красиво; у класса фактически поменяется вся реализация от одного ifdef'a. Некрасиво.
- С третьей, есть относительно идиоматичное решение — CRTP, которое дает полиморфизм на этапе компиляции с помощью шаблонов.
- А с четвертой есть "обычный" полиморфизм из С++ — через виртуальное наследование.
Отметая вариант с ifdef'ами по эстетическим соображениям, давайте посмотрим на CRTP.
Для тех, кто не в курсе, выглядит это как-то так:
template <typename T> class Amount { public: int getValue() const { return static_cast<T const&>(*this).getValue(); } }; class Constant42 : public Amount<Constant42> { public: int getValue() const { return 42; } };
Соответственно, класс Amount тут является статическим интерфейсом, а класс Constant42 его реализует.
К сожалению, у такого подхода есть 2 большие проблемы:
- Amount — это не класс, это шаблон класса. Соответственно, мы не можем передать указатель на него в клиентский код. Мы вынуждены делать клиентский код шаблонным! И вот это реально проблема, потому что Keil не очень хорошо позволяет отлаживать шаблоны и прочий код в заголовочных файлах — на него иногда невозможно поставить точку останова, невозможно прошагать в отладке. И насколько мне известно, у многих IDE такая проблема есть, в той или иной степени.
- Нельзя забывать, что мои коллеги в тот момент, когда эти вопросы в первый раз поднимались, только-только начали переползать на С++. Обычные шаблоны выглядят страшно, а ЭТО вызывало легкую панику.
Соответственно, остается вариант с обычным полиморфизмом времени выполнения.
Но как же так, возможно вскричали сейчас матерые разработчики? Ведь виртуальные вызовы это очень дорого, это таблица виртуальных методов, это дополнительный оверхед при вызове!
И да, действительно, это несколько дороже, чем хотелось бы. Тем не менее:
- таблица виртуальных методов — если этих методов не слишком много — весит пару сотен байт.
- виртуальный вызов дороже на несколько десятков команд. Поскольку у МК обычно нет кэш-памяти, виртуальный вызов не ведет к кэш-промаху, соответственно время вызова увеличивается незначительно.
Но самое главное, что код выглядит просто и понятно — он не требует выворачивать себе мозг каждый раз. И шаблоны не распространяются на всю кодовую базу, как чума.
У такого подхода, как ни странно, есть менее очевидный минус. В Keil'e есть простая оптимизация, которая очень существенно сокращает размер бинарника — выбрасывание неиспользуемых функций.
И вот она-то от наличия таблицы виртуальных методов ломается — ведь на метод есть указатель! Значит, он используется. С этим можно бороться, но как показала практика — особого смысла в этом нет.
Если бы мы пользовались слабыми МК с небольшим количеством памяти и низкой тактовой частотой, то разговор скорее всего был бы совсем иной. Но даже весьма бюджетные модели STM вполне справляются. Да, средний размер бинарника вырос — ну… и ладно? До тех пор, пока в условия технического задания мы вписываемся — кому какая разница?
Отмечу, что мы обычно даже в релизе не включаем оптимизацию кода — потому что так отлаживать проще, а прошивка все равно влезает! Т.е. примерно двухкратный запас по размеру кода почти всегда имеется.
Соответственно, ответ на вопрос раздела простой (но на всякий случай я его проговорю) — для каждого интерфейса связи делаем интерфейс (каламбур не намеренный) — т.е. класс с чисто-виртуальными методами.
Во всем пользовательском коде используем только этот интерфейс.
В релизной прошивке в пользовательский код передаются объекты нормального класса, а в тестовом — моки (mock). Скажем, в мок для UART'a можно передать массив, который пользовательский класс потом "примет" через метод для чтения входящих байт.
Инициализация и деинициализация
Как известно, юнит-тесты не должны зависеть от порядка, в котором их запускают. Поэтому каждый тест должен работать с "чистым" состоянием тестируемого объекта.
Собственно, для этого почти во всех тестовых фреймворках используются функции setup и teardown; которые инициализируют и деинициализируют объект соответственно.
Как можно инициализировать объект?
- В конструкторе
- В методе init
Казалось бы, предпочтительнее инициализация в конструкторе — ее невозможно забыть, т.е. невозможно создать объект в невалидном состоянии.
К сожалению, в embedded иногда приходится создавать глобальные объекты — в основном, чтобы взаимодействовать с прерываниями. А выполнять какой-то сложный код в конструкторе глобального объекта чревато static initialization order fiasco, т.е. можно нарваться на зависимость от какого-то другого глобального объекта из другой единицы трансляции.
Но на самом деле не так важно, как объект инициализировать; в функциии setup мы просто создадим объект (и может быть вызываем для него метод init). А вот как его деинициализировать?
- В деструкторе
- В методе deInit
И вот тут возникает неприятность. В embedded очень многие объекты имеют бесконечное время жизни — потому что main никогда не завершается. Прошивка должна работать, пока на устройстве есть питание; а когда питания нет — уже завершаться поздно.
Поэтому большинству объектов не нужны ни деструкторы, ни методы для деинициализации. А раз они не нужны — писать их специально для тестов как-то не очень хочется.
При этом вполне вероятно, что объект не владеет ресурсами, которые реально нужно деинициализировать, было бы вполне достаточно просто сконструировать объект заново.
Как сконструировать объект заново?
- просто вызвать init еще раз
- создать новый объект, а старый удалить
Подход с методом init обладает неприятным моментом — таким образом не получится заново заполнить константные или ссылочные поля. А чтобы создавать и удалять объекты, нужна динамическая память — традиции ембедеров не велят мне использовать ее… Впрочем, в тестовой сборке это вполне допустимо, а иногда даже обязательно — например, CppUTest без кучи работать не хочет.
Тем не менее, если вам тоже неприятно использовать динамическую память, есть другой способ переконструировать объект — placement new! Это относительно малоизвестная фича С++, которая, по-факту, позволяет вызывать конструктор явным образом для заранее выделенного куска памяти.
У placement new есть свои подводные камни (скажем, не совсем понятно, как таким образом конструировать массивы), но для наших целей это не существенно — вполне достаточно создать статический объект файле с тестами, а перед каждым тестом (или после каждого теста) переконструировать его in place.
Это удобно делать с помощью небольшой вспомогательной функции (которую, кажется, невозможно в общем виде написать без С++11):
template< typename T, typename ... Args > void inplace_new( T & object, Args && ... args ) { auto t = &object; new (t)T{ std::forward<Args>(args)... }; } A a(1,2,3); inplace_new( a, 3,4,5 );
У такого варианта тоже есть один неприятный момент — компилятор armcc (он же Arm Compiler 5), который все еще является компилятором по-умолчанию при создании проекта в Keil'e, поддерживает С++11 очень странно.
Из языковых конструкций поддерживается почти все, но вот стандартная библиотека осталась от С++03. Поэтому std::forward в нем использовать не получится — только если свой писать.
Соответственно, в Keil'e придется или использовать placement new напрямую, или перелезать на "шестую версию компилятора", которая на самом деле clang, или обходиться без forward'a. Ну или написать свой forward.
Если у объекта все-таки есть необходимость в какой-то деинициализации, то при таком подходе нужно не забывать явно вызывать деструктор!
Тестирование assert'ов
На случай, если кто-то не в курсе: ассерты — это проверки условий, которые должны быть истинными; проваленный ассерт как правило означает ошибку в логике программы.
Как правило, ассерт программу экстренно завершает с помощью вызова std::terminate, exit(1) или чего-то вроде того.
Зачем нужны ассерты? В основном для проверок предусловий (т.е. корректности входных параметров у функций) — и постусловий (корректности результатов).
Для встраиваемых систем возникают обычные вопросы:
- что делать, если ассерт провалился?
- допустимо ли оставлять ассерты в "релизной" прошивке?
- допустимо ли их вообще писать или все ошибки должны обрабатываться?
- какой ассерт использовать?
- нужно ли их тестировать и, если да, то как?
Что делать, если ассерт провалился
Самое простое, что можно сделать — это пустой бесконечный цикл:
while(1) {}
Насколько я знаю, примерно так и поступают почти всегда, потому что сходу непонятно, что еще можно сделать — даже вызов std::terminate в конце концов упрется в пустой цикл, который сгенерировал компилятор.
Пустой цикл не очень хорош по двум причинам:
- не сразу понятно, что ассерт сработал, даже под отладкой
- прерывания могут прерывать этот пустой цикл и продолжать что-то делать
Обе эти проблемы решаются тривиально — прерывания в этом пустом цикле можно запретить, а отладку остановить с помощью уже известной нам инструкции BKPT.
#define UMBA_ASSERT( statement ) do { if(! (statement) ) { __disable_irq(); while(1){ __BKPT(0xAC); if(0) break;} } } while(0)
Допустимо ли оставлять ассерты в "релизной" прошивке
Тут каждый решает сам, в зависимости от сроков и серьезности проекта. Я часто оставляю, потому что:
- лучше пусть сработает ассерт, чем прошивка продолжи выполнение с бредовыми данными
- от зависания намертво помогает watchdog
- далеко не всегда есть способ просигнализировать об ошибке хоть как-то
Допустимо ли вообще писать ассерты или все ошибки должны обрабатываться
Ответ практически повторяет предыдущий пункт, но к этому можно добавить следующую мысль.
Если используются велосипедные библиотеки (или просто какой-то общий код), то в них ассерты становятся нужны для гарантии правильного использования.
Какой ассерт использовать
Ассерт времени выполнения:
Чисто теоретически, есть заголовочный файл assert.h, но как-то я особо не видел, чтобы им в embedded пользовались.
Вероятно, потому что реализация поведения при срабатывании ассерта будет зависимой от компилятора.
Поэтому — опять велосипеды. Но это ведь С++, тут все привыкли, что у каждой библиотеки свои тайпдефы над стандартными типами, свой ассерт и т.д :)
Ассерт времени компиляции:
Тут все просто. Если у вас есть возможность использовать С++11 и выше, то есть стандартный static_assert. Если нет, то используется конструкция аля:
#define UMBA_STATIC_ASSERT_MSG(condition, msg) typedef char umba_static_assertion_##msg[(condition)?1:-1] #define UMBA_STATIC_ASSERT3(X, L) UMBA_STATIC_ASSERT_MSG(X, at_line_##L) #define UMBA_STATIC_ASSERT2(X, L) UMBA_STATIC_ASSERT3(X, L) #define UMBA_STATIC_ASSERT(X) UMBA_STATIC_ASSERT2(X, __LINE__)
Нужно ли тестировать ассерты (и как)
На мой взгляд, если пишется библиотека, то нужно, потому что ассерт вполне может срабатывать и будет срабатывать достаточно часто — пока пользователь библиотеки пытается допереть, какие параметры библиотека принимает на входе.
В пользовательском коде же ассерт срабатывать как бы и не должен и в любом случае является затычкой для проблемы, вместо ее нормальной обработки.
Соответственно, если мы пишем библиотеку, то желательно удостовериться в корректности проверок для аргументов.
Окей, решили что ассерты тестить нужно. Как?
Ассерт времени компиляции
Вроде бы такая классная штука, проверка на этапе компиляции! Но как его тестировать, если он компиляцию останавливает?
Медитации на stackoverflow (и вот это видео Roland Bock) показали мне три пути:
- Тесты с помощью системы сборки, скажем, в CMake можно ожидать, что файл не должен компилироваться
Имхо способ не очень удобный. Каждый тест нужно будет пихать в отдельный файл или заворачивать в ifdef; ну и к системе сборки привязываться не очень хочется. Не говоря уже о том, что Кейл так не сумеет.
- Вариант, который предлагает Roland Bock — с опорой на то, что decltype это unevaluated context.
Имхо, выглядит это не очень красиво, приходится делать вспомогательный тип на каждый ассерт, перемазываться макросами. А еще этот способ не очень работает на clang'e (по крайней мере, на момент видеозаписи).
К тому же, у Кейла (точнее, у компилятора armcc) не очень все хорошо с decltype.
- Заменять static_assert на обычный.
Roland этот способ отбросил сходу без особых пояснений, но я лично не вижу в нем ничего плохого (если вы видите — то расскажите, пожалуйста). Просто не используем static_assert напрямую, а прячем его за макросом. И в тестовой сборке этот макрос может делать обычный, рантаймовый assert, таким образом сводя этот вопрос к следующему.
Не нужно никаких особых ухищрений или поддержки со стороны системы сборки, не нужно создавать кучу вспомогательных типов. Разве что можно случайно не constant expression в ассерте написать, но это быстро вскроется в релизной сборке.
Если вы знаете какой-то еще способ, то, пожалуйста, расскажите.
Ассерт времени выполнения
Если оставить реализацию с бесконечным циклом, то тоже никак! Выполнение просто уйдет в этот бесконечный цикл и все.
К счастью, исправить это достаточно легко — для тестовой конфигурации изменить макрос ассерта так, чтобы он не уводил выполнение в бесконечный цикл, а, например, бросал исключение.
Это ведь тестовая сборка, почему бы и нет? Весь окружающий код при этом не меняется.
И с помощью небольшого дополнительного макроса в нашем тестовом фреймворке, это исключение можно поймать и проверить:
#if defined USE_TESTS #define UMBA_ASSERT( statement ) \ do \ { \ if(! (statement) ) \ { \ printf("\nUmba Assertion failed in " __FILE__ ":%d\n", __LINE__ ); \ throw ::umba::AssertionFailedException(); \ } \ } while(0) #include <exception> namespace umba { class AssertionFailedException : public std::exception { }; } #endif
Для теста нам потребуется еще один макрос, доводя таким образом суммарное количество проверяющих макросов до 4, но это все еще меньше, чем в CppUTest :)
Ремарка про стек и кучу
Ремарка вроде бы тривиальная, но на всякий случай ее лучше произнести. Тестовая конфигурация сама по себе имеет право потреблять больше стека, чем релизная, а использование исключений автоматически означает использование динамической памяти (а я не любитель динамической памяти в релизе).
При этом в тестовой конфигурации вообще можно себе разрешить существенно большее потребление памяти, в том числе памяти кода.
В Кейле размеры ОЗУ и ПЗУ задаются в настройках конфигурации проекта (Project->Options->Target), поэтому их легко сделать разными для разных конфигураций. А вот размеры стека и кучи как правило задаются в ассемблерном стартап-файле, как-то так:
Stack_Size EQU 0x00000400 ... Heap_Size EQU 0x00000000
Можно, конечно, держать по два стартапа — один для релиза, а другой для тестов, но это как-то глупо. Удобнее эти строки в стартапе закомментировать, а константы передавать через опцию к ассемблеру (аналогично опции -D для компилятора) — на вкладке Project->Options->Assembler в поле Define.
Тесты и ОСРВ
Еще один интересный вопрос — как тестировать код, написанный под ОСРВ?
Краткий ликбез: ОСРВ — операционные системы реального времени. В случае микроконтроллеров они как правило поставляются в исходных кодах и дают вам возможность создавать потоки выполнения на основе функций. В результате прошивка начинает выглядеть примерно как многопоточное приложение под десктоп.
Основной затык тут следующий — в embedded потоки, как правило, никогда не завершаются. Они создаются на основе функций вида:
void task(void * arg ) { // инициализация while(1) { // работа // какой-нибудь системный вызов } }
Опять бесконечный цикл мешает тестированию!
Обойти это препятствие можно очевидным образом — сделать цикл небесконечным в тестовой конфигурации:
#ifdef USE_TESTS uint32_t umba::decrementTaskCycleCounter(); #define OS_IS_RUNNING (::umba::decrementTaskCycleCounter()) #else #define OS_IS_RUNNING 1 #endif void task(void * arg ) { // инициализация while(OS_IS_RUNNING) { // работа // какой-нибудь системный вызов } }
А во фреймворке заведем функции:
typedef void (*TaskCycleCallback)(void); static uint32_t taskCycleCounter = 0; static TaskCycleCallback taskCycleCallback; void setTaskCycleCounter(uint32_t cnt) { taskCycleCounter = cnt; } uint32_t decrementTaskCycleCounter(void) { if (taskCycleCallback != nullptr) { taskCycleCallback(); } uint8_t a = taskCycleCounter; taskCycleCounter--; return a; } void setTaskCycleCallback( TaskCycleCallback cb ) { taskCycleCallback = cb; }
Теперь мы сможем выставить количество оборотов "бесконечного" цикла в тесте — и при желании, назначить коллбек, который будет дергаться при каждом обороте.
Соответственно, в тесте поток можно просто вызывать, как обычную функцию.
Ну, а если функция-поток делает какие-то блокирующие системные вызовы (например, повисает на семафоре), то этот семафор нужно освободить заранее.
Еще пара моментов:
- перед входом в цикл потока может быть этап инициализации; в тестах нужно каждый раз делать де-инициализацию
- запуск тестов приходится тоже выносить в отдельный поток и запускать весь этот ужас под ОСРВ, иначе примитивы синхронизации работать не будут
У меня не очень большой опыт использования ОСРВ, поэтому что еще тут сказать, я не знаю. Спрашивайте :)
Тесты на ПК
Время шло, вселенные вставали и рушились, разработчики вылуплялись из куколок, и Кейл как IDE перестал нас удовлетворять.
Начались поиски другого решения, которые пока что привели к гибриду: код пишется в Eclipse-CDT с привязанным arm-none-eabi-gcc, но отлаживается и прошивается в Кейле. Тесты по-прежнему можно выполнять в симуляторе Кейла.
Такой подход обладает своими плюсами и минусами, расписывание которых еще больше раздует и так неприлично большой пространный пост.
Остановимся на главном — Eclipse, в отличие от Кейла, умеет не только кросс-компилятор вызывать.
Это дает возможность скомпилировать тестовую сборку не только под симулятор, но и под десктоп. Зачем, спросите вы?
Ну, тесты под десктопом будут выполняться существенно быстрее. А еще в Линуксе можно использовать Google Sanitizer'ы! Это замечательный набор инструментов, который позволяет отлавливать типичные ошибки в плюсовом коде:
- выходы за границы массивов
- переполнения знаковых целых
- и прочие виды неопределенного поведения разных сортов
К тому же, тесты не в симуляторе должны выполняться гораздо быстрее. Теоретически.
Чтобы собрать тесты под Линукс, нужно создать тестовую конфигурацию (на этот раз в Eclipse), которая будет отличаться от обычной только компилятором и каким-нибудь специальным дефайном.
- эта конфигурация должна быть для обычного gcc (не cross)
- из нее нужно убрать все файлы, которые приколочены к архитектуре — например, ассемблерные стартапы
- весь платформозависимый код, разумеется, нужно будет поифдефать
- если мы таки хотим санитайзеры, то нужно прописать соответствующие ключи к компилятору
-fsanitize=address -fsanitize=leak -fsanitize=undefined
и к линкеру:
-fsanitize=address -fsanitize=leak -fsanitize=undefined
По желанию, можно добавить и других ключей — скажем, -fdiagnostics-color=always для цветного вывода и -ftrapv -fstack-protector-all -fstack-check для дополнительных проверок переполнения стека.
Запуск тестов тоже придется немножко доработать — по факту, просто разрешить main'у завершаться с кодом возврата
int main(void) { #ifdef USE_TESTS #ifdef USE_DOCKER // выключаем буферизацию stdout; без этого сообщения санитайзеров // могут смешиваться с выводом тестов setvbuf(stdout, NULL, _IONBF, 0); #endif auto res = umba::runAllTests(); (void)res; #ifdef USE_DOCKER return res; #else __BKPT(0xAB); while(1); #endif #endif
Велика так же вероятность, что обычный gcc будет выдавать много предупреждений на микроконтроллерные библиотеки — например, на заголовочные файлы CMSIS'a, которые любят кастовать адреса к uint32_t, а не к uintptr_t — даже если вы в тестируемом коде регистры не трогаете.
Это можно исправить, например, если подключать эти библиотеки не через -I (как это обычно делает эклипс), а через -isystem. К сожалению, для этого придется прописывать пути уже как опции компилятора, а не в диалоге для Include Paths.
Вообще же, в репозитории есть пример, который собирается в Keil'e и в Eclipse, так что за совсем подробными подробностями — прошу туда.
Далее, нам потребуется ПК с Линуксом. Можно, конечно, всем разработчикам поставить по виртуалке. Но если мы хотим делать красиво, то нужен отдельный сервер для автоматического запуска тестов! Ну, как у больших мальчиков, после каждого коммита.
У нас сервер был, но — опять же, по историческим причинам — на нем стоит Windows Server 2012; со связкой Jenkins-Redmine-Gitblit.
Но тем не менее. Что нам понадобится, чтобы запускать тесты таким образом?
- Docker
- Сборка Eclipce CDT, которая согласится в нем заработать
- VirtualBox
- Немножко воображения и костылей, чтобы все это запускалось из-под Windows
- Еще подкрутить наш фреймворк (и код), чтобы докер не подавился
Начнем с последнего. Из всех тестов и тестового фреймворка придется убрать явные обращения к регистрам и ассемблерные вставки. Какое счастье, что как раз обращения к регистрам-то мы и не тестировали :)
К сожалению, в коде также нельзя будет использовать прерывания (не очень-то и хотелось) и ОСРВ. Точнее, можно, но надо изобретать еще какой-то дополнительный уровень абстракции, до которого пока что руки не дошли.
Если писать тесты "правильно", передавать платформозависимые вещи снаружи и оборачивать их в обертки, а не хардкодить, то особых проблем переезд на другую платформу вызывать не должен.
Фреймворк придется немного подправить, чтобы убрать явные зависимости от инструкции BKPT и запрета прерываний, вынесем это все в конфигурационный файл:
#pragma once #include <stdint.h> // включить логирование #define UMBA_TEST_LOGGING_ENABLED 1 #ifndef USE_DOCKER // наименее процессорно-зависимый инклуд #include <cmsis_compiler.h> #define UMBA_TEST_HANG_ON_FAILED_TEST_ENABLED 1 #define UMBA_TEST_DISABLE_IRQ() __disable_irq() #define UMBA_TEST_STOP_DEBUGGER() __BKPT(0xAA) #else #define UMBA_TEST_HANG_ON_FAILED_TEST_ENABLED 0 #define UMBA_TEST_DISABLE_IRQ() #define UMBA_TEST_STOP_DEBUGGER() #endif namespace umba { // максимальное количество тестов в одной группе const uint32_t tests_in_group_max = 200; // максимальное количество групп тестов const uint32_t groups_max = 100; // тип коллбэка для одного оборота цикла в потоке ОСРВ typedef void (*TaskCycleCallback)(void); const char COLOR_RESET[] = "\x1b[0m"; const char RED_FG[] = "\x1b[31m"; const char GREEN_FG[] = "\x1b[32m"; const char RED_BG[] = "\x1b[41m"; }
Отмечу, что далее будет просто приблизительное описание того, как оно у нас сделано. Скорее всего, оно сделано неправильно, но, к сожалению, devops'ов у нас нет.
Поэтому тут я лучше все под спойлеры спрячу :)
FROM eclipse:latest # Copy project into the container at /app/project COPY . /app/project # Build project # Replace ~~PROJECT~~ with your Eclipse project name and ~~Docker~~ with docker-friendly configuration RUN ./eclipse/eclipse -nosplash -application org.eclipse.cdt.managedbuilder.core.headlessbuild -import ./project/ -build ~~PROJECT~~/~~Docker~~ # Run tests CMD ["/app/project/~~Docker~~/~~PROJECT~~"]
export DOCKER_CERT_PATH="C:\Users\Jenkins\.docker\machine\machines\default" IS_ERROR=0 # удаляем кэш докера taskkill -F -FI "IMAGENAME eq Vbox*" && rm -rf /c/Users/Jenkins/.docker/ # подтягиваем изменения из репозитория с образом эклипса и скриптом настройки докера git -C /c/docker/ pull # настраиваем докер printf 'DIR=\"$( cd \"$(dirname \"$0\")\" ; pwd -P )\"\n \"/c/Program Files/Git/bin/bash.exe\" -x /c/docker/Server/start.sh 2> $DIR/__out.txt' > $WORKSPACE/_jenkins.sh && /d/PSTools/psexec -accepteula -h -u Jenkins -p verysecretpassword "C:\Program Files\Git\bin\bash.exe" $WORKSPACE/_jenkins.sh && # запускаем сборку проекта и тесты. Ошибки временно игнорируем, чтобы почистить кэш cd /c/Program\ Files/Docker\ Toolbox/ && ./docker load < /c/docker/eclipse.tar.gz && ./docker build -t=project $WORKSPACE/ && ./docker run --rm --privileged project || IS_ERROR=1 # удаляем кэш докера taskkill -F -FI "IMAGENAME eq Vbox*" && rm -rf /c/Users/Jenkins/.docker/ || echo exit $IS_ERROR
К сожалению, кэш докера по невыясненным причинам приходится каждый раз очищать. Поэтому быстрее чем в симуляторе не получилось. Ну, как сказать? Сами тесты выполняются моментально :) А вот разворачивается вся эта штука минут 15. Да.
Тем не менее, теперь благодаря связке локального гит-сервера с дженкинсом, после каждого пуша можно получить уведомление на почту, о том, что все хорошо:

Ну или не очень хорошо, если все же санитайзер что-то обнаружил:
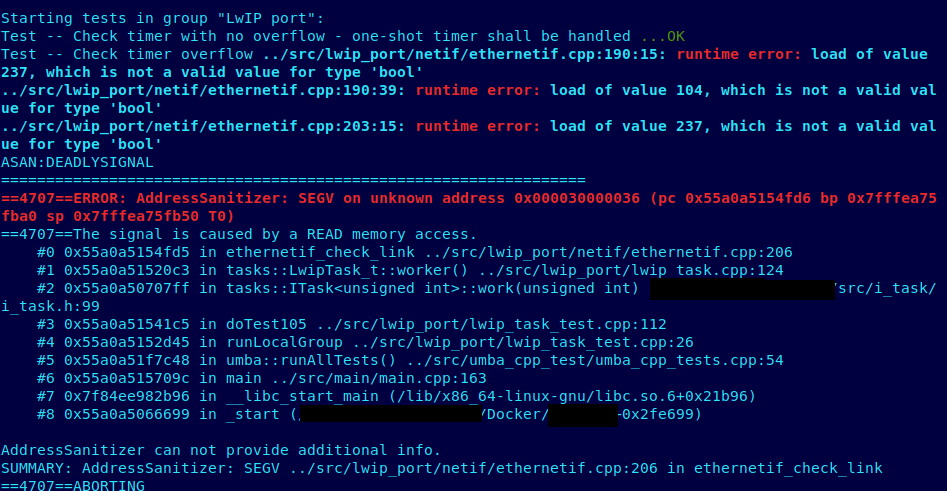
А если он ничего не нашел, то еще и глубокое спокойствие — ведь теперь мы знаем, что в нашей прошивке нет неопределенного поведения!
Ну, наверное, нет. Скорее всего ._.
Разумеется, к этому можно далее прикручивать любые вещи — автоматическую сборку hex-файла прошивки с добавлением в архив (чтобы для прошивания платы программиста не дергали), дополнительную проверку с помощью PVS-Studio, что угодно, бесконечность не предел.
(ремарка: я помню, что представители PVS-Studio рекомендуют встраивать проверку в обычный процесс сборки, а не выполнять ее только по праздникам; над этим мы тоже работаем :)
Известные проблемы
Основная проблема использования юнит-тестов вообще, с которой лично я столкнулся, это когда где-то надо немножко сменить API (потому что оно было придумано N лет назад, и накопились проблемы) — но все покрыто тестами… И прям руки опускаются при мысли, что надо 100+ тестов тоже править.
Но в какой-то момент все же пересиливаешь себя, меняешь API и видишь, что упало-то всего тестов 10.
Остальное — скорее проблемы "фреймворка", поэтому я их лучше под спойлер спрячу.
BKPT не всегда останавливает выполнение "красиво"; зачастую оно останавливается где-то в дизассемблере, а не на строчке в срр-файле. Это сильно зависит от настроек компилятора, поэтому как-то в общем виде это решить не получается. К счастью, обычно достаточно немножко поскроллить вверх-вниз дизасемблер, чтобы Keil смог показать нужный срр-файл.
Т.к. названия функций-тестов генерируются с помощью директивы
__LINE__, это название не очень-то человекочитаемое. Поэтому по call-stack'у не очень понятно, что за тест такой —doTest56.
И очень, на мой взгляд, удобное окно в Eclipse — outline — которое показывает список всех функций в файле, становится менее удобным.

Отчасти, эти проблемы друг друга дополняют :) Не знаешь, что такое doTest56 — находишь его в outline и переходишь к нему.
Ну и Collapse All (по хоткею Ctrl+Shift+/) тоже сильно облегчает жизнь, хотя после него придется пару раз кликнуть на плюсик. Судя по всему, использовать строковые литералы в качестве названий тестов — не всегда хорошо.

Поскольку ошибки в тестах — это просто ненулевые возвращаемые значения, нельзя использовать макрос
UMBA_CHECKвнутри вспомогательных функций, а не прямо внутри самого теста. Пока что эта проблема подкостылена с помощью дополнительных макросов —UMBA_CHECK_FиUMBA_CHECK_CALL.
А если вспомогательная функция — лямбда, то из нее нельзя возвращать 0 или nullptr, иначе слишком суровый вывод типов вынудит вас указывать тип возвращаемого значения явно как
const char *. Для небольшого облегчения заведен макросUMBA_TEST_OK.
При ловле ассертов ломается красивый вертикальный столбик из ОК'ов :(
Личный опыт
Один из "бета-чтецов" (которым отдельное большое спасибо) порекомендовал мне добавить акцента на полезности тестов, потому что после столь продолжительного описания всяческих проблем у читающих может возникнуть мысль — а может ну его?
Поэтому я приведу несколько позитивных примеров, в которых, на мой взгляд, тесты очень сильно облегчили жизнь лично мне. Не знаю, честно говоря, насколько это показательно — но пусть будет.
Большой проект для военных, только отечественная элементная база. У большинства приборов срок поставки полгода, у некоторых — год. А код надо писать уже сейчас, потом время будет только на отладку. Как это делать без юнит-тестов — я даже не знаю. Просто вслепую писать и надеятся, что сходу заработает?
Загрузчик. Да, каждый embedded-разработчик должен написать свой загрузчик, это как обряд взросления :) В моем случае загрузчик должен поддерживать несколько разных микроконтроллеров и интерфейсов связи; но при этом основная логика прошивания остается неизменной. Поскольку эта логика покрыта тестами, багов в ней не находилось уже очень-очень давно, проблемы появляются в основном при необходимости поддержки нового микроконтроллера или когда пользователь неправильно конфигурацию выполняет.
Еще один проект для военных, опять "отечка", необходимость общения по протоколу заказчика. Вся "высокоуровневая" логика протокола протестирована, поэтому проблемы с коммуникацией были только из-за Ethernet на Миландре -_-'
Подведем итоги
Внезапно даже в embedded можно использовать юнит-тесты и для этого совершенно необязательно наличие дорогущего оборудования, ложа с гвоздями или чего-то подобного.
При этом, разные стратегии тестирования не обязательно противоречат, а вполне могут дополнять друг друга. Так, тестирование в симуляторе, встроенному в IDE, гораздо лучше подходит для TDD, а тестирование на билд-сервере позволяет проводить более полные и/или сложные проверки.
Разумеется, такое тестирование ни в коем случае не является всеобъемлющим! Это подход именно к юнит-тестированию отдельным программных модулей, а не всего устройства в целом — они не замена дорогущему оборудованию для изделия в целом, ложу с гвоздями для плат или приемочным испытаниям у заказчика.
Тем не менее, по своему опыту скажу, что юнит-тесты вынуждают вас писать более модульный код и действительно вселяют уверенность в том, что код работает. Баги в ужасе мигрируют из покрытого тестами кода в отдаленные закоулки :)
Продублирую ссылку на репозиторий
P.S. Отдельно прошу прощения у Polaris99, которому я обещал эту статью несколько месяцев назад -_- Надеюсь, длина статьи хотя бы отчасти компенсирует долгое ожидание.

