
То, как вы создаете и получаете доступ к своим данным, может повлиять на производительность вашего приложения. Посмотрим как.
Вступление
JavaScript — это язык очень высокого уровня. Таким образом, большинство разработчиков не задумываются о том, как данные хранятся в памяти. В этой статье мы рассмотрим, как данные хранятся в памяти, как они влияют на процессор и память и как способ, которым вы распространяете данные в JS и обращаетесь к ним, влияет на производительность.
Любовный треугольник
Когда компьютеру необходимо выполнить некоторые вычисления, процессору (ЦП) нужны данные для обработки. Таким образом, в соответствии с поставленной задачей он отправляет в память запрос на выборку данных через шину.
Это выглядит так:
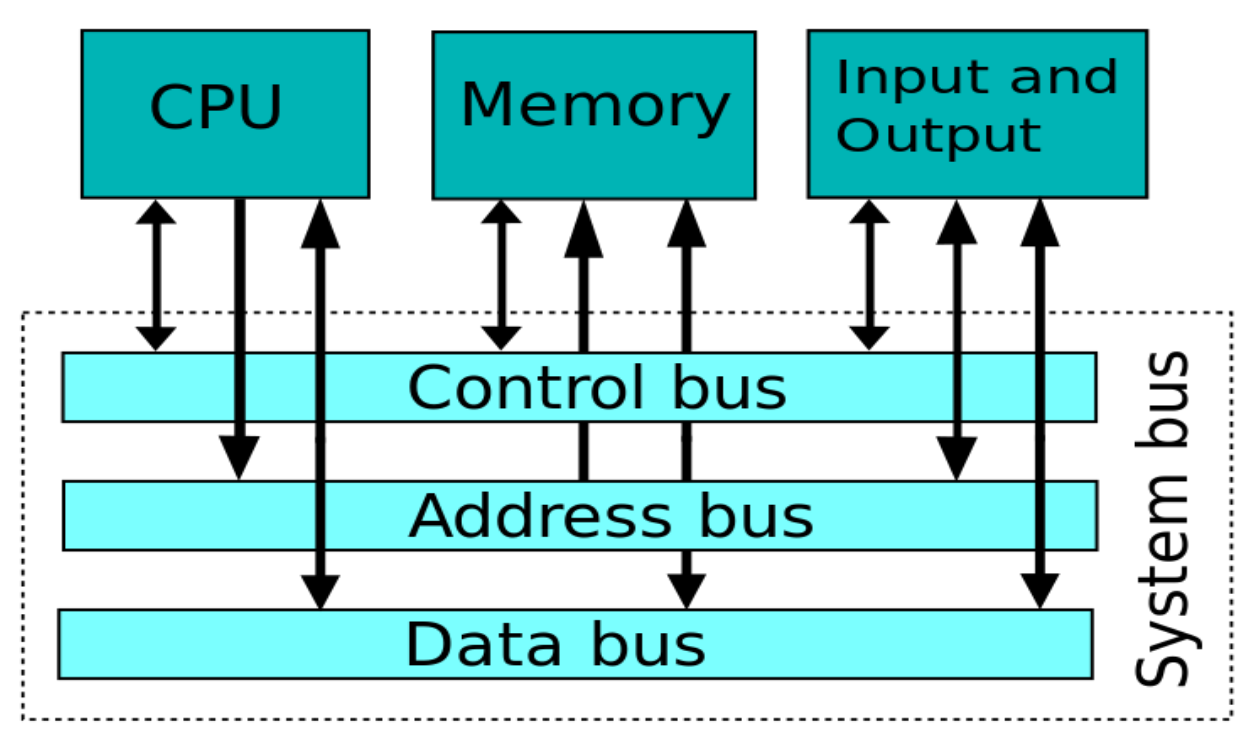
Так что это наш романтический треугольник — Процессор -> Шина -> Память
Поддерживать здоровые отношения в трио сложно
Процессор намного быстрее, чем память. Таким образом, этот процесс Процессор -> Шина -> Память -> Шина -> Процессор «тратит» время на вычисления. Пока просматривается память, процессор бездействует.
Для предотвращения простоя, в систему был добавлен кеш. Мы не будем вдаваться в подробности что такое кэш или какие есть типы кэша, но достаточно сказать, что кэш — это внутренняя память процессора.
Когда ЦП получает команду на исполнение, он сначала ищет данные в кэше, а если данных там нет, он отправляет запрос через шину.
Шина, в свою очередь, передает запрашиваемые данные плюс условную часть памяти и сохраняет их в кеше для быстрого обращения.
Таким образом, у ЦП будет меньше недовольства на то, насколько медленная память и, следовательно, у ЦП будет меньше времени простоя.
Ссоры являются частью любых отношений
Проблема, которая может возникнуть — особенно когда мы имеем дело с обработкой огромных объемов данных — это явление, называемое промах кэша (cache miss).
Промах кэша означает, что во время вычислений, ЦП обнаруживает, что не имеет необходимых данных в кэше, и ему нужно запрашивать эти данные по обычным каналам — вы помните про очееееень медленнную память.
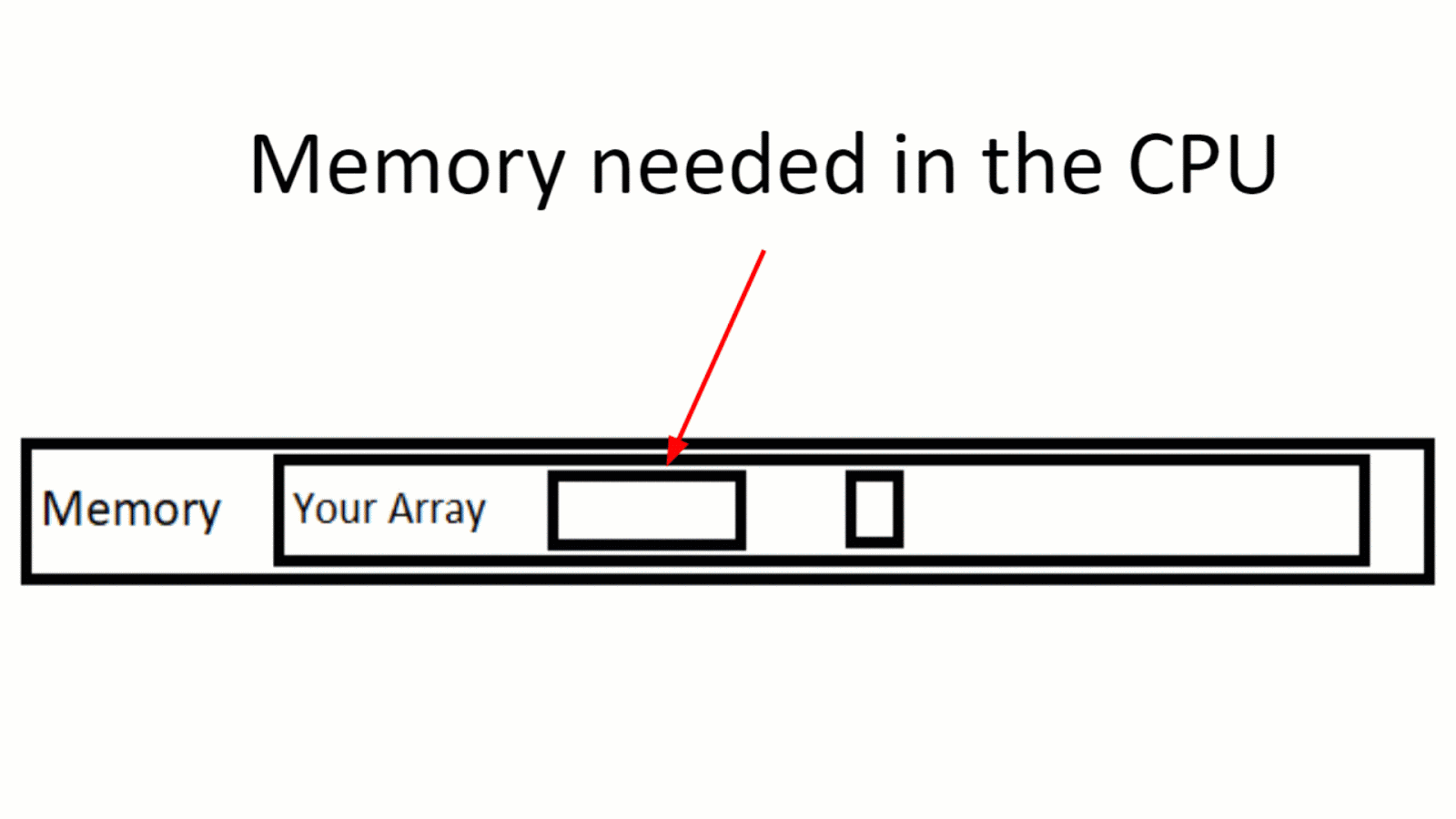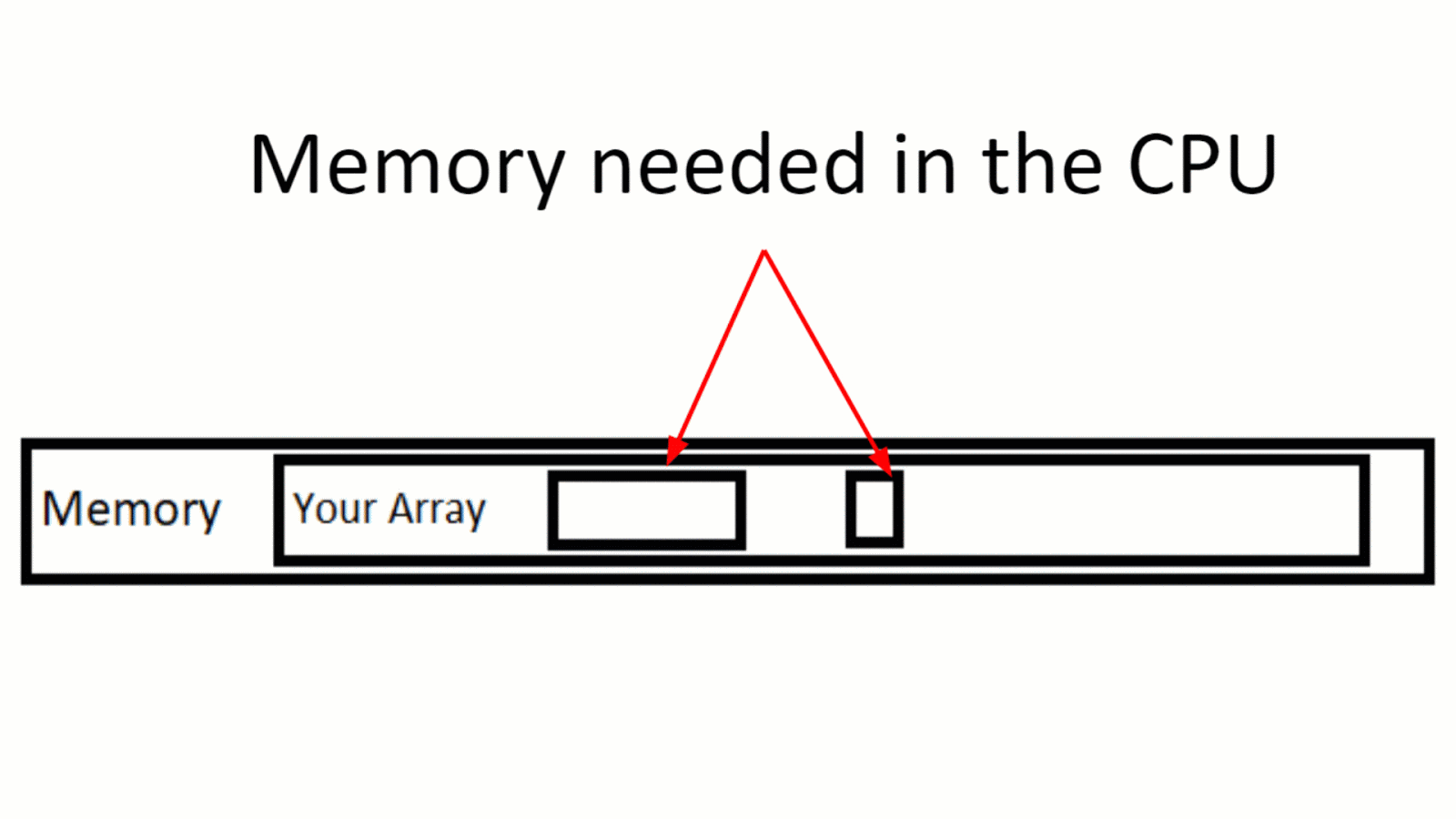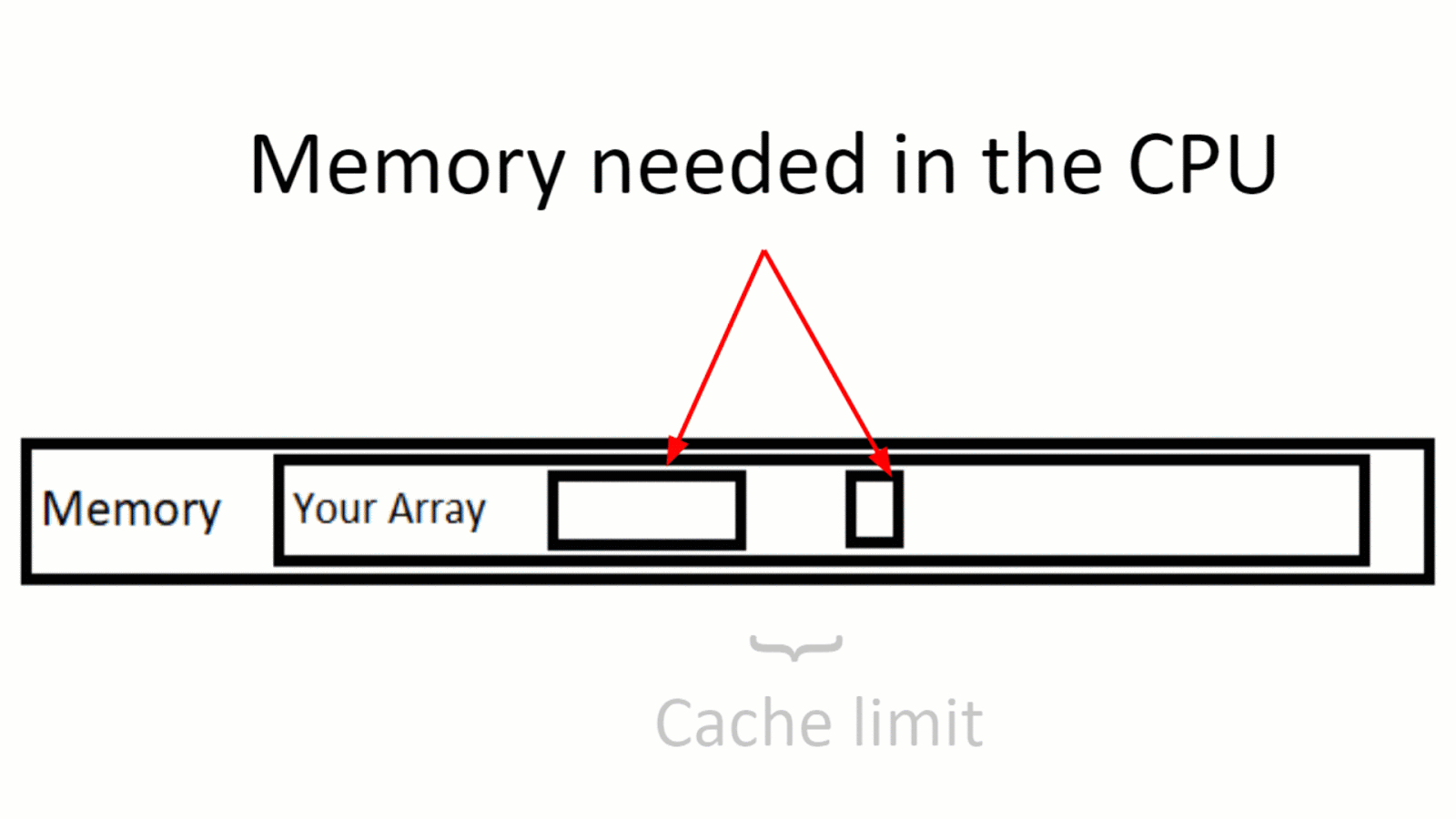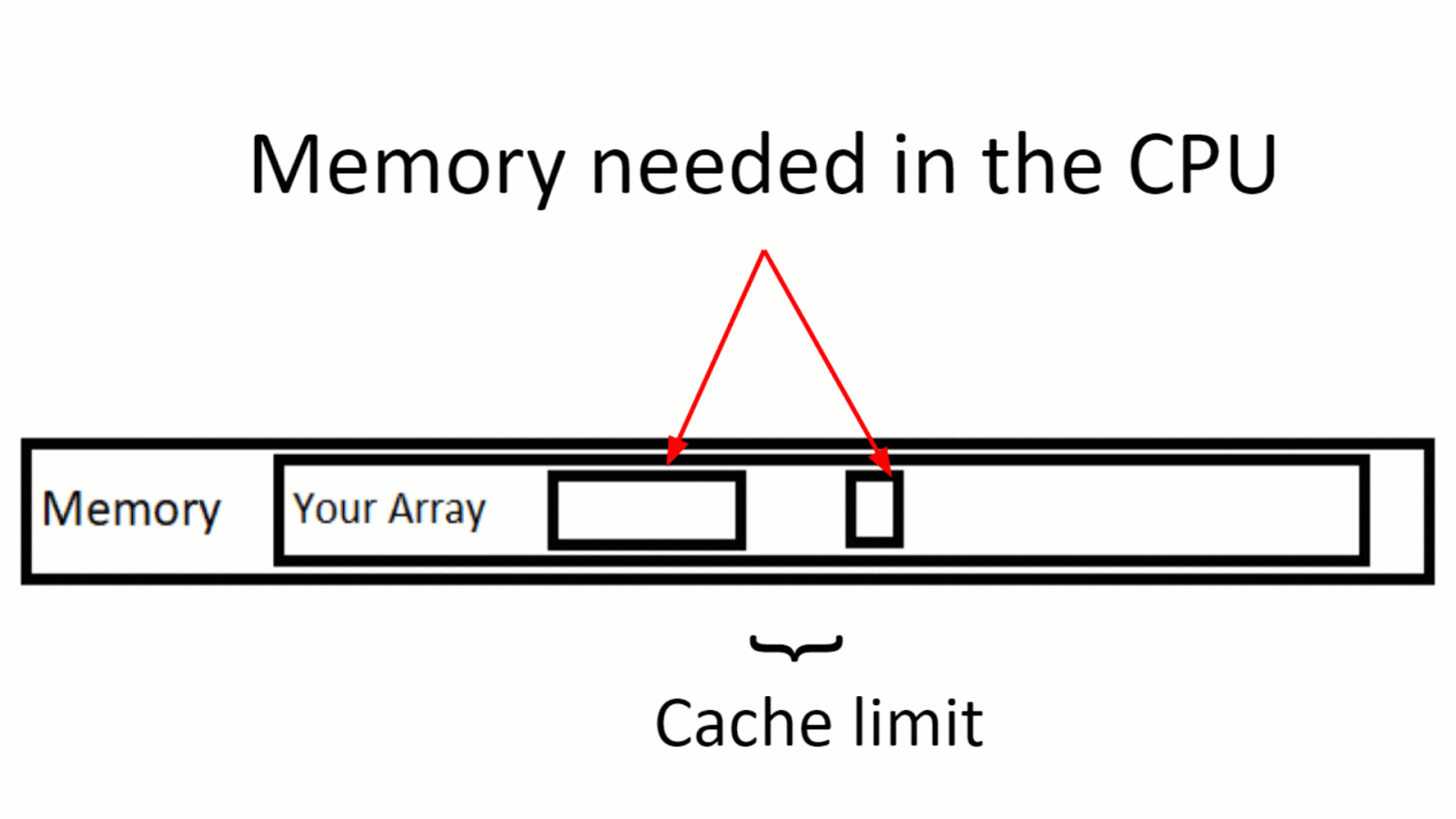
Иллюстрация промаха кеша. Данные из массива обрабатываются, но данные за пределами лимита кэша также запрашиваются для вычисления — и это создает «промах кэша».
Хорошо, но я JavaScript разработчик, почему меня это должно волновать?
Хороший вопрос. В большинстве случаев вы об этом не задумываетесь. Однако сегодня, когда все больше и больше данных проходит через сервера написанные на Node.js, у вас больше шансов встретить проблему промаха кэша при переборе больших наборов данных.
Я поверю в это, когда увижу это!!!
Справедливо. Давайте посмотрим на пример.
Вот класс под названием Boom.
class Boom {
constructor(id) {
this.id = id;
}
setPosition(x, y) {
this.x = x;
this.y = y;
}
}
Этот класс (Boom) имеет всего 3 свойства — id, x и y.
Теперь давайте создадим метод, который заполняет x и y.
Давайте зададим данные:
const ROWS = 1000;
const COLS = 1000;
const repeats = 100;
const arr = new Array(ROWS * COLS).fill(0).map((a, i) => new Boom(i));Теперь мы будем использовать эти данные в методе:
function localAccess() {
for (let i = 0; i < ROWS; i++) {
for (let j = 0; j < COLS; j++) {
arr[i * ROWS + j].x = 0;
}
}
}Что делает localAccess, так это линейно проходит по массиву и устанавливает x равным 0.
Если мы повторим эту функцию 100 раз (посмотрите на константу repeats), мы можем измерить, сколько времени потребуется для выполнения:
function repeat(cb, type) {
console.log(`%c Started data ${type}`, 'color: red');
const start = performance.now();
for (let i = 0; i < repeats; i++) {
cb();
}
const end = performance.now();
console.log('Finished data locality test run in ', ((end - start) / 1000).toFixed(4), ' seconds');
return end - start;
}
repeat(localAccess, 'Local');Вывод журнала:

Цена за промах кэша
Теперь, согласно тому, что мы узнали выше, мы можем рассмотреть проблему промаха кэша, если обработаем данные, которые находятся далеко во время итерации. Удаленные данные — это данные, которых нет в соседнем индексе. Вот функция для этого:
function farAccess() {
for (let i = 0; i < COLS; i++) {
for (let j = 0; j < ROWS; j++) {
arr[j * ROWS + i].x = 0;
}
}
}Здесь происходит то, что на каждой итерации мы обращаемся к индексу, который находится на расстоянии ROWS от последней итерации. Поэтому, если ROWS равен 1000 (как в нашем случае), мы получаем следующую итерацию: [0, 1000, 2000,…, 1, 1001, 2001,…].
Давайте добавим это в наш тест скорости:
repeat(localAccess, 'Local');
setTimeout(() => {
repeat(farAccess, 'Non Local');
}, 2000);И вот конечный результат:

Нелокальная итерация была почти в 4 раза медленнее. Эта разница будет расти с увеличением данных. Это происходит из-за того, что процессор простаивает из-за промаха кэша.
Так какую цену вы платите? Все зависит от размера ваших данных.
Хорошо, я клянусь, я никогда этого не сделаю!
Возможно, вы об этом не думаете, но… есть случаи, когда вы хотите получить доступ к массиву с некоторой логикой, которая не является линейной (например, 1,2,3,4,5) или не является условной (например, for(let i = 0; i <n; i + = 1000)).
Например, вы получаете данные из сервиса или БД, и вам нужно обрабатывать их, отсортировывать или отфильтровывать с помощью сложной логики. Это может привести к ситуации аналогичной той, что была показана в функции farAccess.
Вот иллюстрация, которая (надеюсь) прояснит ситуацию:

Исходные данные в памяти vs отсортированные данные в памяти. Числа обозначают индексы объектов в исходном массиве.
Глядя на изображение выше, мы видим данные в том виде, в каком они хранятся в памяти (верхняя серая полоса). Ниже мы видим массив, который был создан, когда данные поступили с сервера. Наконец, мы видим отсортированный массив, который содержит ссылки на объекты, хранящиеся в различных позициях в памяти.
Таким образом, итерация по отсортированному массиву может привести к множественным промахам в кэше, как показано в примере выше.
Обратите внимание, что этот пример для небольшого массива. Промахи в кеше актуальны для гораздо больших данных.В мире, где вам нужны плавные анимации на фронтенде и где вы можете загружать каждую миллисекунду процессорного времени на бекенде — это может стать критическим.
О нет! Все потеряно!!!
Нет, не совсем.
Существуют различные решения этой проблемы, но теперь, когда вы знаете причину такого падения производительности, вы, вероятно, можете придумать решение самостоятельно. Вам просто нужно хранить данные, которые обрабатываются как можно ближе в памяти.
Такая техника называется шаблоном проектирования Data Locality.Давайте продолжим наш пример. Предположим, что в нашем приложении наиболее распространенным процессом является обработка данных с помощью логики, показанной в функции farAccess. Мы хотели бы оптимизировать данные, чтобы они работали быстро в наиболее распространенном цикле for.
Мы организуем такие данные:
const diffArr = new Array(ROWS * COLS).fill(0);
for (let col = 0; col < COLS; col++) {
for (let row = 0; row < ROWS; row++) {
diffArr[row * ROWS + col] = arr[col * COLS + row];
}
}Так что теперь, в diffArr, объекты, которые находятся в индексах [0,1,2,…] в исходном массиве, теперь установлены следующим образом [0,1000,2000,…, 1, 1001, 2001,…, 2, 1002, 2002, ...]. Цифры обозначают индекс объекта. Это имитирует сортировку массива, что является одним из способов реализации шаблона проектирования Data Locality.
Чтобы легко это проверить, мы немного изменим нашу функцию farAccess, чтобы получить кастомный массив:
function farAccess(array) {
let data = arr;
if (array) {
data = array;
}
for (let i = 0; i < COLS; i++) {
for (let j = 0; j < ROWS; j++) {
data[j * ROWS + i].x = 0;
}
}
}А теперь добавьте сценарий к нашему тесту:
repeat(localAccess, 'Local');
setTimeout(() => {
repeat(farAccess, 'Non Local')
setTimeout(() => {
repeat(() => farAccess(diffArr), 'Non Local Sorted')
}, 2000);
}, 2000);Мы запускаем это, и мы получаем:

И вуаля! — мы оптимизировали наши данные, чтобы они соответствовали более распространенному подходу к ним.
Полный пример приведен тут.
Вывод
В этой статье мы продемонстрировали шаблон проектирования Data Locality. По сути, мы показали, что доступ к структуре данных способом, для которого она не оптимизирована, может снизить производительность. Затем мы оптимизировали данные в соответствии с нашим способом их обработки — и увидели, как они улучшили производительность.
Шаблон проектирования Data Locality распространен в сфере разработки игр, где часто приходилось сталкиваться с множеством сущностей, которые повторяются много раз. В приведенных выше результатах мы видим, что локальность данных по-прежнему имеет значение даже в языках высокого уровня, таких как JavaScript, а не только в играх.
Сегодня, учитывая объем данных, передаваемых между серверами или загружаемых в браузеры, разработчики приложений должны учитывать шаблоны проектирования, которые раньше были повседневными для разработчиков игр — и на стороне сервера и на стороне клиента.

Узнайте подробности, как получить востребованную профессию с нуля или Level Up по навыкам и зарплате, пройдя платные онлайн-курсы SkillFactory:
- Курс по Machine Learning (12 недель)
- Курс «Профессия Data Scientist» (24 месяца)
- Курс «Профессия Data Analyst» (18 месяцев)
- Курс «Python для веб-разработки» (9 месяцев)
