Коллеги, добрый день! Меня зовут Миша, я работаю программистом.
В настоящей статье я хочу рассказать о том, как наша команда решила применить подход CQRS & Event Sourcing в проекте, представляющем собой площадку для проведения онлайн-аукционов. А также о том, что из этого получилось, какие из нашего опыта можно сделать выводы и на какие грабли важно не наступить тем, кто отправится путем CQRS & ES.

Для начала немного истории и бизнесового бэкграунда. К нам пришел заказчик с платформой для проведения так называемых timed-аукционов, которая была уже в продакшене и по которой было собрано некоторое количество фидбэка. Заказчик хотел, чтоб мы сделали ему платформу для live-аукционов.
Теперь чуть-чуть терминологии. Аукцион — это когда продаются некие предметы — лоты (lots), а покупатели (bidders) делают ставки (bids). Обладателем лота становится покупатель, предложивший самую большую ставку. Timed-аукцион — это когда у каждого лота заранее определен момент его закрытия. Покупатели делают ставки, в какой-то момент лот закрывается. Похоже на ebay.
Timed-платформа была сделана классически, с применением CRUD. Лоты закрывало отдельное приложение, запускаясь по расписанию. Работало все это не слишком надежно: какие-то ставки терялись, какие-то делались как будто бы от лица не того покупателя, лоты не закрывались или закрывались по несколько раз.
Live-аукцион — это возможность участвовать в реальном офлайн-аукционе удаленно, через интернет. Есть помещение (в нашей внутренней терминологии — «комната»), в нем находится ведущий аукциона с молотком и аудитория, и тут же рядом с ноутбуком сидит так называемый клерк, который, нажимая кнопки в своем интерфейсе, транслирует в интернет ход аукциона, а подключившиеся к аукциону покупатели видят ставки, которые делаются офлайн, и могут делать свои ставки.
Обе платформы в принципе работают в реальном времени, но если в случае timed все покупатели находятся в равном положении, то в случае live крайне важно, чтоб онлайн-покупатели могли успешно соревноваться с находящимися «в комнате». То есть система должна быть очень быстрой и надежной. Печальный опыт timed-платформы недвусмысленно говорил нам, что классический CRUD нам не подходит.
Своего опыта работы с CQRS & ES у нас не было, так что мы посовещались с коллегами, у которых он был (компания у нас большая), презентовали им наши бизнес-реалии и совместно пришли к заключению, что CQRS & ES должен нам подойти.
Какая еще есть специфика работы онлайн-аукционов:
Не буду подробно останавливаться на рассмотрении подхода CQRS & ES, материалы об этом есть в интернете и в частности на Хабре (например, вот: Введение в CQRS + Event Sourcing). Однако кратко все же напомню основные моменты:

В целях экономии времени, а также в силу отсутствия специфического опыта мы решили, что нужно использовать какой-то фреймворк для CQRS & ES.
В целом наш технологический стек — это Microsoft, то есть .NET и C#. База данных — Microsoft SQL Server. Хостится все в Azure. На этом стеке была сделана timed-платформа, логично было и live-платформу делать на нем.
На тот момент, как сейчас помнится, Chinchilla была чуть ли не единственным вариантом, подходящим нам по технологическому стеку. Так что мы взяли ее.
Зачем вообще нужен фреймворк CQRS & ES? Он может «из коробки» решать такие задачи и поддерживать такие аспекты реализации как:
Таким образом, с учетом использования Chinchilla, к нашему стеку добавились:
Да, фронтенд сделан на Angular.
Как я уже говорил, одно из требований к системе — чтобы пользователи максимально быстро узнавали о результатах своих действий и действий других пользователей — это относится и к покупателям, и к клерку. Поэтому мы используем SignalR и веб-сокеты для оперативного обновления данных на фронтенде. Chinchilla поддерживает интеграцию с SignalR.
Одной из первых вещей, которую надо сделать при реализации подхода CQRS & ES — это определить, как доменная модель будет делиться на агрегаты.
В нашем случае доменная модель состоит из нескольких основных сущностей, примерно таких:
У нас получилось два агрегата: Auction и Lot (с Bid’ами). В общем, логично, но мы не учли одного — того, что при таком делении состояние системы у нас размазалось по двум агрегатам, и в ряде случаев для сохранения консистентности мы должны вносить изменения в оба агрегата, а не в один. Например, аукцион можно поставить на паузу. Если аукцион на паузе, то нельзя делать ставки на лот. Можно было бы ставить на паузу сам лот, но аукциону на паузе тоже нельзя обрабатывать никаких команд, кроме как «снять с паузы».
В качестве альтернативного варианта можно было сделать только один агрегат, Auction, со всеми лотами и ставками внутри. Но такой объект будет довольно тяжелым, потому что лотов в аукционе может быть до нескольких тысяч и ставок на один лот может быть несколько десятков. За время жизни аукциона у такого агрегата будет очень много версий, и регидратация такого агрегата (последовательное применение к агрегату всех событий), если не делать снапшотов агрегатов, будет занимать довольно продолжительное время. Что для нашей ситуации неприемлемо. Если же использовать снапшоты (мы их используем), то сами снапшоты будут весить очень много.
С другой стороны, чтобы гарантировать применение изменений к двум агрегатам в рамках обработки одного действия пользователя, нужно или менять оба агрегата в рамках одной команды с использованием транзакции, либо выполнять в рамках одной транзакции две команды. И то, и другое, по большому счету, является нарушением архитектуры.
Подобные обстоятельства нужно учитывать, разбивая доменную модель на агрегаты.
Мы на данном этапе эволюции проекта живем с двумя агрегатами, Auction и Lot, и нарушаем архитектуру, меняя в рамках некоторых команд оба агрегата.
Если несколько покупателей одновременно делают ставку на один и тот же лот, то есть отправляют в систему команду «сделать ставку», успешно пройдет только одна из ставок. Лот — это агрегат, у него есть версия. При обработке команды создаются события, каждое из которых инкрементирует версию агрегата. Можно пойти двумя путями:
Мы используем второй вариант. Так у команд больше шансов выполниться. Потому что в той части приложения, которая отправляет команды (в нашем случае это фронтенд), текущая версия агрегата с некоторой вероятностью будет отставать от реальной версии на бэкенде. Особенно в условиях, когда команд отправляется много, и верcия агрегата меняется часто.
В нашей реализации, в большой степени обусловленной использованием Chinchilla, обработчик команд читает команды из очереди (Microsoft Azure Service Bus). Мы у себя явно разделяем ситуации, когда команда зафейлилась по техническим причинам (таймауты, ошибки подключения к очереди/базе) и когда по бизнесовым (попытка сделать на лот ставку той же величины, что уже была принята, и проч.). В первом случае попытка выполнить команду повторяется, пока не выйдет заданное в настройках очереди число повторений, после чего команда отправляется в Dead Letter Queue (отдельный топик для необработанных сообщений в Azure Service Bus). В случае бизнесового эксепшена команда отправляется в Dead Letter Queue сразу.
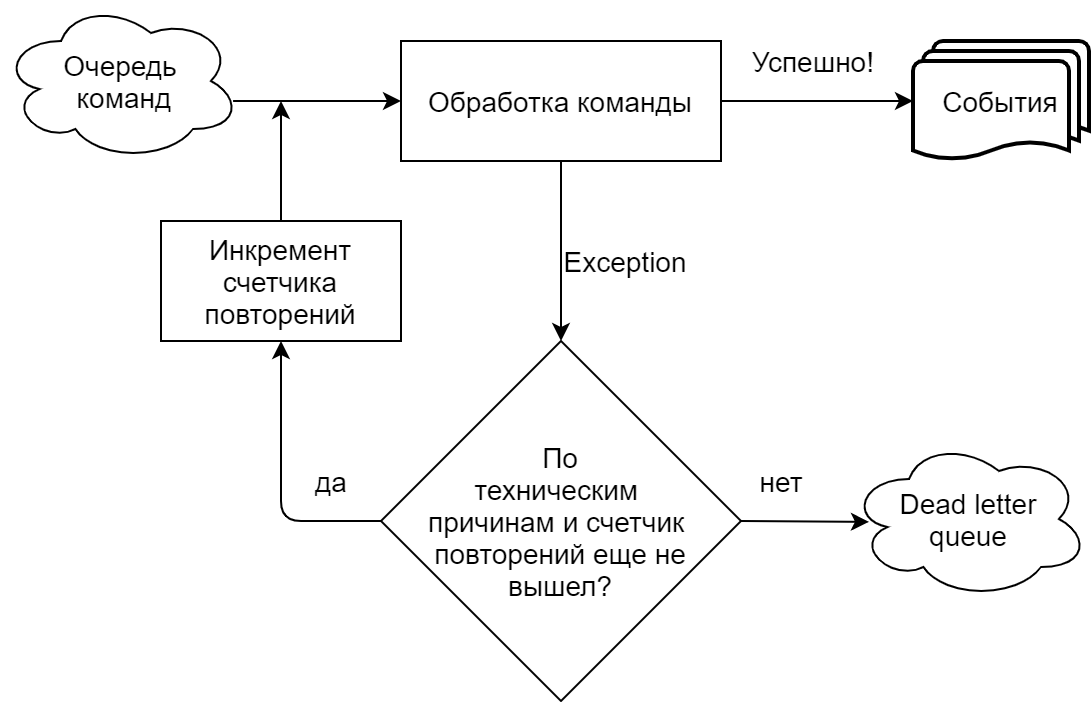
События, создаваемые в результате выполнения команды, в зависимости от реализации, тоже могут отправляться в очередь и браться из очереди обработчиками событий. И при обработке событий тоже случаются ошибки.
Однако, в отличие от ситуации с невыполненной командой, здесь все хуже — может получиться так, что команда выполнилась и события в write-базу записались, но обработка их обработчиками зафейлилась. И если один из этих обработчиков обновляет read-базу, то read-база не обновится. То есть окажется в неконсистентном состоянии. Благодаря наличию механизма повторных попыток обработки события read-база почти всегда, в конечном итоге, обновляется, однако вероятность того, что после всех попыток она останется поломанной, все-таки остается.

Мы у себя столкнулись с этой проблемой. Причина, впрочем, была в большой степени в том, что в обработке событий у нас присутствовала некоторая бизнес-логика, которая при интенсивном потоке ставок имеет хорошие шансы фейлиться из раза в раз. К сожалению, осознали мы это слишком поздно, переделать бизнес-реализацию быстро и просто не получилось.
В итоге, в качестве временной меры мы отказались от использования Azure Service Bus для передачи событий из write-части приложения в read-часть. Вместо нее используется так называемая In-Memory Bus, что позволяет обрабатывать команду и события в одной транзакции и в случае неудачи откатить все целиком.

Такое решение не способствует масштабируемости, но зато мы исключаем ситуации, когда у нас ломается read-база, от чего в свою очередь ломаются фронтенды и продолжение аукциона без пересоздания read-базы через проигрывание заново всех событий становится невозможным.
Такое в принципе уместно, но только в случае, когда невыполнение этой второй команды не ломает состояние системы.
В общем случае в результате выполнения одной команды получается несколько событий. Бывает, что на каждое из событий нам нужно сделать какое-то изменение в read-базе. Бывает также, что последовательность событий тоже важна, и в неправильной последовательности обработка событий не отработает как надо. Все это означает, что мы не можем читать из очереди и обрабатывать события одной команды независимо, например, разными экземплярами кода, который читает сообщения из очереди. Плюс к этому нам нужна гарантия того, что события из очереди будут прочитаны в той же последовательности, в которой они были туда отправлены. Либо нам нужно быть готовыми к тому, что не все события команды будут успешно обработаны с первой попытки.

Если в качестве реакции на одно событие системе нужно выполнить несколько разных действий, обычно делаются несколько обработчиков этого события. Они могут отрабатывать параллельно или последовательно. В случае последовательного запуска при неуспешном выполнении одного из обработчиков вся последовательность запускается заново (в Chinchilla это так). При такой реализации важно, чтобы обработчики были идемпотентными, чтобы второй запуск один раз успешно отработавшего обработчика не свалился. В противном случае при падении второго обработчика из цепочки она, цепочка, уже точно не отработает целиком, потому что во вторую (и последующие) попытку упадет первый обработчик.
Например, обработчик события в read-базе добавляет ставку на лот величиной 5 рублей. Первая попытка сделать это будет успешной, а вторую не даст выполнить constraint в базе.

Сейчас наш проект находится в стадии, когда, как нам кажется, мы наступили уже на бОльшую часть существующих граблей, актуальных для нашей бизнес-специфики. В целом мы считаем свой опыт довольно успешным, CQRS & ES хорошо подходит для нашей предметной области. Дальнейшее развитие проекта видится в отказе от Chinchilla в пользу другого фреймворка, дающего больше гибкости. Впрочем, возможен и вариант отказа от использования фреймворка вообще. Также вероятно будут какие-то изменения в направлении поиска баланса между надежностью с одной стороны и быстротой и масштабируемостью решения с другой.
Что касается бизнес-составляющей, то и здесь некоторые вопросы по-прежнему остаются открытыми — например, деление доменной модели на агрегаты.
Хочется надеяться, что наш опыт окажется для кого-то полезным, поможет сэкономить время и избежать граблей. Спасибо за внимание.
В настоящей статье я хочу рассказать о том, как наша команда решила применить подход CQRS & Event Sourcing в проекте, представляющем собой площадку для проведения онлайн-аукционов. А также о том, что из этого получилось, какие из нашего опыта можно сделать выводы и на какие грабли важно не наступить тем, кто отправится путем CQRS & ES.
Прелюдия
Для начала немного истории и бизнесового бэкграунда. К нам пришел заказчик с платформой для проведения так называемых timed-аукционов, которая была уже в продакшене и по которой было собрано некоторое количество фидбэка. Заказчик хотел, чтоб мы сделали ему платформу для live-аукционов.
Теперь чуть-чуть терминологии. Аукцион — это когда продаются некие предметы — лоты (lots), а покупатели (bidders) делают ставки (bids). Обладателем лота становится покупатель, предложивший самую большую ставку. Timed-аукцион — это когда у каждого лота заранее определен момент его закрытия. Покупатели делают ставки, в какой-то момент лот закрывается. Похоже на ebay.
Timed-платформа была сделана классически, с применением CRUD. Лоты закрывало отдельное приложение, запускаясь по расписанию. Работало все это не слишком надежно: какие-то ставки терялись, какие-то делались как будто бы от лица не того покупателя, лоты не закрывались или закрывались по несколько раз.
Live-аукцион — это возможность участвовать в реальном офлайн-аукционе удаленно, через интернет. Есть помещение (в нашей внутренней терминологии — «комната»), в нем находится ведущий аукциона с молотком и аудитория, и тут же рядом с ноутбуком сидит так называемый клерк, который, нажимая кнопки в своем интерфейсе, транслирует в интернет ход аукциона, а подключившиеся к аукциону покупатели видят ставки, которые делаются офлайн, и могут делать свои ставки.
Обе платформы в принципе работают в реальном времени, но если в случае timed все покупатели находятся в равном положении, то в случае live крайне важно, чтоб онлайн-покупатели могли успешно соревноваться с находящимися «в комнате». То есть система должна быть очень быстрой и надежной. Печальный опыт timed-платформы недвусмысленно говорил нам, что классический CRUD нам не подходит.
Своего опыта работы с CQRS & ES у нас не было, так что мы посовещались с коллегами, у которых он был (компания у нас большая), презентовали им наши бизнес-реалии и совместно пришли к заключению, что CQRS & ES должен нам подойти.
Какая еще есть специфика работы онлайн-аукционов:
- Много пользователей одновременно пытаются воздействовать на один и тот же объект в системе — текущий лот. Покупатели делают свои ставки, клерк вводит в систему ставки «из комнаты», закрывает лот, открывает следующий. В каждый момент времени в системе можно сделать ставку только одной величины — например, 5 рублей. И только один пользователь сможет сделать эту ставку.
- Нужно хранить всю историю действий над объектами системы, чтобы в случае необходимости можно было посмотреть, кто какую ставку сделал.
- Время отклика системы должно быть очень маленьким — ход онлайн-версии аукциона не должен отставать от офлайн, пользователям должно быть понятно, к чему привели их попытки сделать ставку — успешны они или нет.
- Пользователи должны оперативно узнавать обо всех изменениях в ходе аукциона, а не только о результатах своих действий.
- Решение должно быть масштабируемым — несколько аукционов могут проходить одновременно.
Краткий обзор подхода CQRS & ES
Не буду подробно останавливаться на рассмотрении подхода CQRS & ES, материалы об этом есть в интернете и в частности на Хабре (например, вот: Введение в CQRS + Event Sourcing). Однако кратко все же напомню основные моменты:
- Самое главное в event sourcing: система хранит не данные, а историю их изменения, то есть события. Текущее состояние системы получается последовательным применением событий.
- Доменная модель делится на сущности, называемые агрегатами. Агрегат имеет версию. События применяются к агрегатам. Применение события к агрегату инкрементирует его версию.
- События хранятся в write-базе. В одной и той же таблице хранятся события всех агрегатов системы в том порядке, в котором они произошли.
- Изменения в системе инициируются командами. Команда применяется к одному агрегату. Команда применяется к последней, то есть текущей, версии агрегата. Агрегат для этого выстраивается последовательным применением всех «своих» событий. Этот процесс называется регидратацией.
- Для того, чтобы не регидрировать каждый раз с самого начала, какие-то версии агрегата (обычно каждая N-я версия) можно хранить в системе в готовом виде. Такие «снимки» агрегата называются снапшотами. Тогда для получения агрегата последней версии при регидратации к самому свежему снапшоту агрегата применяются события, случившиеся после его создания.
- Команда обрабатывается бизнес-логикой системы, в результате чего получается, в общем случае, несколько событий, которые сохраняются в write-базу.
- Кроме write-базы, в системе может еще быть read-база, которая хранит данные в форме, в которой их удобно получать клиентам системы. Сущности read-базы не обязаны соответствовать один к одному агрегатам системы. Read-база обновляется обработчиками событий.
- Таким образом, у нас получается разделение команд и запросов к системе — Command Query Responsibility Segregation (CQRS): команды, изменяющие состояние системы, обрабатываются write-частью; запросы, не изменяющие состояние, обращаются к read-части.
Реализация. Тонкости и сложности.
Выбор фреймворка
В целях экономии времени, а также в силу отсутствия специфического опыта мы решили, что нужно использовать какой-то фреймворк для CQRS & ES.
В целом наш технологический стек — это Microsoft, то есть .NET и C#. База данных — Microsoft SQL Server. Хостится все в Azure. На этом стеке была сделана timed-платформа, логично было и live-платформу делать на нем.
На тот момент, как сейчас помнится, Chinchilla была чуть ли не единственным вариантом, подходящим нам по технологическому стеку. Так что мы взяли ее.
Зачем вообще нужен фреймворк CQRS & ES? Он может «из коробки» решать такие задачи и поддерживать такие аспекты реализации как:
- Сущности агрегата, команды, события, версионирование агрегатов, регидратация, механизм снапшотов.
- Интерфейсы для работы с разными СУБД. Сохранение/загрузка событий и снапшотов агрегатов в/из write-базы (event store).
- Интерфейсы для работы с очередями — отправка в соответствующие очереди команд и событий, чтение команд и событий из очереди.
- Интерфейс для работы с веб-сокетами.
Таким образом, с учетом использования Chinchilla, к нашему стеку добавились:
- Azure Service Bus в качестве шины команд и событий, Chinchilla поддерживает его «из коробки»;
- Write- и read-базы — Microsoft SQL Server, то есть обе они — SQL-базы. Не скажу, что это является результатом осознанного выбора, скорее по историческим причинам.
Да, фронтенд сделан на Angular.
Как я уже говорил, одно из требований к системе — чтобы пользователи максимально быстро узнавали о результатах своих действий и действий других пользователей — это относится и к покупателям, и к клерку. Поэтому мы используем SignalR и веб-сокеты для оперативного обновления данных на фронтенде. Chinchilla поддерживает интеграцию с SignalR.
Выбор агрегатов
Одной из первых вещей, которую надо сделать при реализации подхода CQRS & ES — это определить, как доменная модель будет делиться на агрегаты.
В нашем случае доменная модель состоит из нескольких основных сущностей, примерно таких:
public class Auction { public AuctionState State { get; private set; } public Guid? CurrentLotId { get; private set; } public List<Guid> Lots { get; } } public class Lot { public Guid? AuctionId { get; private set; } public LotState State { get; private set; } public decimal NextBid { get; private set; } public Stack<Bid> Bids { get; } } public class Bid { public decimal Amount { get; set; } public Guid? BidderId { get; set; } }
У нас получилось два агрегата: Auction и Lot (с Bid’ами). В общем, логично, но мы не учли одного — того, что при таком делении состояние системы у нас размазалось по двум агрегатам, и в ряде случаев для сохранения консистентности мы должны вносить изменения в оба агрегата, а не в один. Например, аукцион можно поставить на паузу. Если аукцион на паузе, то нельзя делать ставки на лот. Можно было бы ставить на паузу сам лот, но аукциону на паузе тоже нельзя обрабатывать никаких команд, кроме как «снять с паузы».
В качестве альтернативного варианта можно было сделать только один агрегат, Auction, со всеми лотами и ставками внутри. Но такой объект будет довольно тяжелым, потому что лотов в аукционе может быть до нескольких тысяч и ставок на один лот может быть несколько десятков. За время жизни аукциона у такого агрегата будет очень много версий, и регидратация такого агрегата (последовательное применение к агрегату всех событий), если не делать снапшотов агрегатов, будет занимать довольно продолжительное время. Что для нашей ситуации неприемлемо. Если же использовать снапшоты (мы их используем), то сами снапшоты будут весить очень много.
С другой стороны, чтобы гарантировать применение изменений к двум агрегатам в рамках обработки одного действия пользователя, нужно или менять оба агрегата в рамках одной команды с использованием транзакции, либо выполнять в рамках одной транзакции две команды. И то, и другое, по большому счету, является нарушением архитектуры.
Подобные обстоятельства нужно учитывать, разбивая доменную модель на агрегаты.
Мы на данном этапе эволюции проекта живем с двумя агрегатами, Auction и Lot, и нарушаем архитектуру, меняя в рамках некоторых команд оба агрегата.
Применение команды к определенной версии агрегата
Если несколько покупателей одновременно делают ставку на один и тот же лот, то есть отправляют в систему команду «сделать ставку», успешно пройдет только одна из ставок. Лот — это агрегат, у него есть версия. При обработке команды создаются события, каждое из которых инкрементирует версию агрегата. Можно пойти двумя путями:
- Отправлять команду, указывая в ней, к какой версии агрегата мы хотим ее применить. Тогда обработчик команды сразу же может сравнить версию в команде с текущей версией агрегата и не продолжать в случае несовпадения.
- Не указывать в команде версию агрегата. Тогда агрегат регидрируется с какой-то версией, выполняется соответствующая бизнес-логика, создаются события. И уже только при их сохранении может выскочить эксепшен о том, что такая версия агрегата уже существует. Потому что кто-то другой успел раньше.
Мы используем второй вариант. Так у команд больше шансов выполниться. Потому что в той части приложения, которая отправляет команды (в нашем случае это фронтенд), текущая версия агрегата с некоторой вероятностью будет отставать от реальной версии на бэкенде. Особенно в условиях, когда команд отправляется много, и верcия агрегата меняется часто.
Ошибки при выполнении команды с использованием очереди
В нашей реализации, в большой степени обусловленной использованием Chinchilla, обработчик команд читает команды из очереди (Microsoft Azure Service Bus). Мы у себя явно разделяем ситуации, когда команда зафейлилась по техническим причинам (таймауты, ошибки подключения к очереди/базе) и когда по бизнесовым (попытка сделать на лот ставку той же величины, что уже была принята, и проч.). В первом случае попытка выполнить команду повторяется, пока не выйдет заданное в настройках очереди число повторений, после чего команда отправляется в Dead Letter Queue (отдельный топик для необработанных сообщений в Azure Service Bus). В случае бизнесового эксепшена команда отправляется в Dead Letter Queue сразу.
Ошибки при обработке событий с использованием очереди
События, создаваемые в результате выполнения команды, в зависимости от реализации, тоже могут отправляться в очередь и браться из очереди обработчиками событий. И при обработке событий тоже случаются ошибки.
Однако, в отличие от ситуации с невыполненной командой, здесь все хуже — может получиться так, что команда выполнилась и события в write-базу записались, но обработка их обработчиками зафейлилась. И если один из этих обработчиков обновляет read-базу, то read-база не обновится. То есть окажется в неконсистентном состоянии. Благодаря наличию механизма повторных попыток обработки события read-база почти всегда, в конечном итоге, обновляется, однако вероятность того, что после всех попыток она останется поломанной, все-таки остается.
Мы у себя столкнулись с этой проблемой. Причина, впрочем, была в большой степени в том, что в обработке событий у нас присутствовала некоторая бизнес-логика, которая при интенсивном потоке ставок имеет хорошие шансы фейлиться из раза в раз. К сожалению, осознали мы это слишком поздно, переделать бизнес-реализацию быстро и просто не получилось.
В итоге, в качестве временной меры мы отказались от использования Azure Service Bus для передачи событий из write-части приложения в read-часть. Вместо нее используется так называемая In-Memory Bus, что позволяет обрабатывать команду и события в одной транзакции и в случае неудачи откатить все целиком.
Такое решение не способствует масштабируемости, но зато мы исключаем ситуации, когда у нас ломается read-база, от чего в свою очередь ломаются фронтенды и продолжение аукциона без пересоздания read-базы через проигрывание заново всех событий становится невозможным.
Отправка команды в качестве реакции на событие
Такое в принципе уместно, но только в случае, когда невыполнение этой второй команды не ломает состояние системы.
Обработка множества событий одной команды
В общем случае в результате выполнения одной команды получается несколько событий. Бывает, что на каждое из событий нам нужно сделать какое-то изменение в read-базе. Бывает также, что последовательность событий тоже важна, и в неправильной последовательности обработка событий не отработает как надо. Все это означает, что мы не можем читать из очереди и обрабатывать события одной команды независимо, например, разными экземплярами кода, который читает сообщения из очереди. Плюс к этому нам нужна гарантия того, что события из очереди будут прочитаны в той же последовательности, в которой они были туда отправлены. Либо нам нужно быть готовыми к тому, что не все события команды будут успешно обработаны с первой попытки.
Обработка одного события несколькими обработчиками
Если в качестве реакции на одно событие системе нужно выполнить несколько разных действий, обычно делаются несколько обработчиков этого события. Они могут отрабатывать параллельно или последовательно. В случае последовательного запуска при неуспешном выполнении одного из обработчиков вся последовательность запускается заново (в Chinchilla это так). При такой реализации важно, чтобы обработчики были идемпотентными, чтобы второй запуск один раз успешно отработавшего обработчика не свалился. В противном случае при падении второго обработчика из цепочки она, цепочка, уже точно не отработает целиком, потому что во вторую (и последующие) попытку упадет первый обработчик.
Например, обработчик события в read-базе добавляет ставку на лот величиной 5 рублей. Первая попытка сделать это будет успешной, а вторую не даст выполнить constraint в базе.
Выводы/Заключение
Сейчас наш проект находится в стадии, когда, как нам кажется, мы наступили уже на бОльшую часть существующих граблей, актуальных для нашей бизнес-специфики. В целом мы считаем свой опыт довольно успешным, CQRS & ES хорошо подходит для нашей предметной области. Дальнейшее развитие проекта видится в отказе от Chinchilla в пользу другого фреймворка, дающего больше гибкости. Впрочем, возможен и вариант отказа от использования фреймворка вообще. Также вероятно будут какие-то изменения в направлении поиска баланса между надежностью с одной стороны и быстротой и масштабируемостью решения с другой.
Что касается бизнес-составляющей, то и здесь некоторые вопросы по-прежнему остаются открытыми — например, деление доменной модели на агрегаты.
Хочется надеяться, что наш опыт окажется для кого-то полезным, поможет сэкономить время и избежать граблей. Спасибо за внимание.

