Про префиксное дерево (Trie) написано немало, в том числе и на Хабре. Вот пример, как оно может выглядеть:
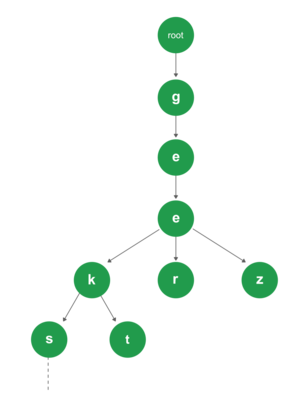
И даже реализаций в коде, в том числе на JavaScript, для него существует немало — от «каноничной» by John Resig и разных оптимизированных версий до серии модулей в NPM.
Зачем же нам понадобилось использовать его для сервиса по сбору и анализу планов PostgreSQL, да еще и «велосипедить» какую-то новую реализацию?..
Давайте посмотрим на небольшой кусок лога сервера PostgreSQL:
Определить и отсечь строку заголовка, которая начинается с даты, мы можем по формату, установленному переменной log_line_prefix:
Но дальше-то у нас идет запрос вместе с планом — и как понять, где кончается один и начинается другой?..
Казалось бы, план — это текстовое представление дерева, поэтому «корень»-то должен быть один? То есть первая снизу строка с минимальным отступом (пропуская,
Увы, нет. В нашем примере такой строкой окажется «хвост»
Но заметим, что план обязан начинаться с одного из узлов:
По сути, мы не знаем, какой именно из известных нам узлов находится в начале данной строки (и находится ли вообще), но хотим его найти. Как раз в этом нам и поможет префиксное дерево.
Но у нашего дерева, которое мы хотим построить, есть несколько особенностей:
Последнее требование обусловлено тем фактом, что анализ логов на наших коллекторах ведется без перерывов, в потоковом режиме. И чем меньше мы сможем «намусорить», тем больше ресурсов направим на полезную активность вместо уборки за собой.
В этом нам помогут две полезные функции:
Давайте посмотрим на примере, как можно построить карту, чтобы с помощью этих двух операций быстро находить нужные элементы из исходного набора:
Хм… да у них же есть одинаковый префикс «In»!
А раз он одинаковый, то проверяя его символы, мы никак не сможем получить новой информации — значит, проверять надо только символы, идущие дальше, вплоть до длины самого короткого элемента. Они помогут нам разбить все элементы на несколько групп:
В данном случае оказалось неважно, какой символ мы возьмем для разбиения (3-й или 5-й, например) — состав групп окажется все равно одинаковым, поэтому точно такую же комбинацию разбиения на группы повторно обрабатывать незачем:
Осталось только понять — а если бы на 3-м и 5-м символах группы оказались бы разными — какую из этих веток дерева стоит выбрать? Для этого введем метрику, которая даст нам ответ на этот вопрос — количество одинарных сравнений символа, чтобы найти каждый из ключей.
Тут мы пренебрегаем тем фактом, что часть узлов встречается в реальности в планах много чаще, чем другие, и считаем их равнозначными.
В итоге, для нашего примера оптимальная карта будет выглядеть так:
Теперь осталось только свести все воедино, добавить функцию поиска, немного оптимизаций — и можно использовать:
Как можно заметить, при поиске в таком Immutable Trieни одно животное не пострадало не создается никаких новых объектов в памяти, за которыми потом хотел бы прийти GC.
Из бонусов: теперь мы можем получать искомый префикс без необходимости делать
Ну а когда мы уже определились, где план начинается, ровно таким же способом (но уже с помощью Trie названий атрибутов) мы определяем строки, которые являются началом атрибута узла, а какие — продолжение multiline string и «склеиваем» их:
Ну а в таком виде его разбирать — уже намного проще.
И даже реализаций в коде, в том числе на JavaScript, для него существует немало — от «каноничной» by John Resig и разных оптимизированных версий до серии модулей в NPM.
Зачем же нам понадобилось использовать его для сервиса по сбору и анализу планов PostgreSQL, да еще и «велосипедить» какую-то новую реализацию?..
«Склеенные» логи
Давайте посмотрим на небольшой кусок лога сервера PostgreSQL:
2020-09-11 14:49:53.281 MSK [80927:619/4255507] [explain.tensor.ru] 10.76.182.154(59933) pgAdmin III - ???????????????????? ???????????????? LOG: duration: 0.016 ms plan: Query Text: explain analyze SELECT * FROM pg_class WHERE relname = 'мама мыла раму'; Index Scan using pg_class_relname_nsp_index on pg_class (cost=0.29..2.54 rows=1 width=265) (actual time=0.014..0.014 rows=0 loops=1) Index Cond: (relname = 'мама мыла раму'::name) Buffers: shared hit=2
Определить и отсечь строку заголовка, которая начинается с даты, мы можем по формату, установленному переменной log_line_prefix:
SHOW log_line_prefix; -- "%m [%p:%v] [%d] %r %a "
Потребуется совсем немного магии регулярных выражений
const reTS = "\\d{4}(?:-\\d{2}){2} \\d{2}(?::\\d{2}){2}" , reTSMS = reTS + "\\.\\d{3}" , reTZ = "(?:[A-Za-z]{3,5}|GMT[+\\-]\\d{1,2})"; var re = { // : log_line_prefix '%a' : "(?:[\\x20-\\x7F]{0,63})" , '%u' : "(?:[\\x20-\\x7F]{0,63})" , '%d' : "[\\x20-\\x7F]{0,63}?" , '%r' : "(?:(?:\\d{1,3}(?:\\.\\d{1,3}){3}|[\\-\\.\\_a-z0-9])\\(\\d{1,5}\\)|\\[local\\]|)" , '%h' : "(?:(?:\\d{1,3}(?:\\.\\d{1,3}){3}|[\\-\\.\\_a-z0-9])|\\[local\\]|)" , '%p' : "\\d{1,5}" , '%t' : reTS + ' ' + reTZ , '%m' : reTSMS + ' ' + reTZ , '%i' : "(?:SET|SELECT|DO|INSERT|UPDATE|DELETE|COPY|COMMIT|startup|idle|idle in transaction|streaming [0-9a-f]{1,8}\/[0-9a-f]{1,8}|)(?: waiting)?" , '%e' : "[0-9a-z]{5}" , '%c' : "[0-9a-f]{1,8}\\.[0-9a-f]{1,8}" , '%l' : "\\d+" , '%s' : "\\d{4}(?:-\\d{2}){2} \\d{2}(?::\\d{2}){2} [A-Z]{3}" , '%v' : "(?:\\d{1,9}\\/\\d{1,9}|)" , '%x' : "\\d+" , '%q' : "" , '%%' : "%" // : log_min_messages , '%!' : "(?:DEBUG[1-5]|INFO|NOTICE|WARNING|ERROR|LOG|FATAL|PANIC)" // : log_error_verbosity , '%@' : "(?:DETAIL|HINT|QUERY|CONTEXT|LOCATION|STATEMENT)" }; re['%#'] = "(?:" + re['%!'] + "|" + re['%@'] + ")"; // преобразуем log_line_prefix в RegExp для разбора строки let lre = self.settings['log_line_prefix'].replace(/([\[\]\(\)\{\}\|\?\$\\])/g, "\\\$1") + '%#: '; self.tokens = lre.match(new RegExp('(' + Object.keys(re).join('|') + ')', 'g')); let matcher = self.tokens.reduce((str, token) => str.replace(token, '(' + re[token] + ')'), lre); self.matcher = new RegExp('^' + matcher, '');
Но дальше-то у нас идет запрос вместе с планом — и как понять, где кончается один и начинается другой?..
Казалось бы, план — это текстовое представление дерева, поэтому «корень»-то должен быть один? То есть первая снизу строка с минимальным отступом (пропуская,
Trigger ...) — искомый корень и начало плана?Увы, нет. В нашем примере такой строкой окажется «хвост»
раму'::name) от распавшейся на части multiline string. Как быть?Use Trie, Luke!
Но заметим, что план обязан начинаться с одного из узлов:
Seq Scan, Index Scan, Sort, Aggregate, ... — ни много, ни мало, а 133 разных варианта, исключая CTE, InitPlan и SubPlan, которые не могут быть корневыми.По сути, мы не знаем, какой именно из известных нам узлов находится в начале данной строки (и находится ли вообще), но хотим его найти. Как раз в этом нам и поможет префиксное дерево.
Immutable Trie
Но у нашего дерева, которое мы хотим построить, есть несколько особенностей:
- компактность
Возможных элементов у нас десятки/сотни вполне ограниченной длины, поэтому не может возникнуть ситуации большого количества очень длинных почти совпадающих ключей, отличающихся только в последнем символе. Самый длинный из наших ключей, наверное —'Parallel Index Only Scan Backward'. - иммутабельность
То есть элементы добавляются только при инициализации. В дальнейшем процессе его существования они уже не добавляются и не удаляются. - пропускная способность
Мы хотим тратить минимум операций на проверку совпадения каждого элемента. Иначе можно было бы просто последовательно сравнивать каждый элемент с началом строки, пока не найдется нужный. - отсутствие сайд-эффектов
Операции поиска не должны создавать новых объектов в памяти, которые потом пришлось бы «зачищать» Garbage Collector'у.
Последнее требование обусловлено тем фактом, что анализ логов на наших коллекторах ведется без перерывов, в потоковом режиме. И чем меньше мы сможем «намусорить», тем больше ресурсов направим на полезную активность вместо уборки за собой.
В этом нам помогут две полезные функции:
String.prototype.charCodeAt(index)позволяет узнать код символа на определенной позиции в строкеString.prototype.startsWith(searchString[, position])проверяет, совпадает ли начало строки [с определенной позиции] с искомой
Строим карту
Давайте посмотрим на примере, как можно построить карту, чтобы с помощью этих двух операций быстро находить нужные элементы из исходного набора:
Insert
Index Scan
Index Scan Backward
Index Only Scan
Index Only Scan BackwardХм… да у них же есть одинаковый префикс «In»!
// определение минимальной длины ключа и Longest Common Prefix let len, lcp; for (let key of keys) { // первый элемент if (lcp === undefined) { len = key.length; lcp = key.slice(off); continue; } len = Math.min(len, key.length); // пропускаем, если уже "обнулили" LCP или он совпадает для этого элемента if (lcp == '' || key.startsWith(lcp, off)) { continue; } // усечение LCP при несовпадении префикса for (let i = 0; i < lcp.length; i++) { if (lcp.charCodeAt(i) != key.charCodeAt(off + i)) { lcp = lcp.slice(0, i); break; } } }
А раз он одинаковый, то проверяя его символы, мы никак не сможем получить новой информации — значит, проверять надо только символы, идущие дальше, вплоть до длины самого короткого элемента. Они помогут нам разбить все элементы на несколько групп:
Insert
Index Scan
Index Scan Backward
Index Only Scan
Index Only Scan BackwardВ данном случае оказалось неважно, какой символ мы возьмем для разбиения (3-й или 5-й, например) — состав групп окажется все равно одинаковым, поэтому точно такую же комбинацию разбиения на группы повторно обрабатывать незачем:
// перебираем варианты выбора номера тестируемого символа let grp = new Set(); res.pos = {}; for (let i = off + lcp.length; i < len; i++) { // группируем ключи по соответствующим значениям [i]-символа let chr = keys.reduce((rv, key) => { if (key.length < i) { return rv; } let ch = key.charCodeAt(i); rv[ch] = rv[ch] || []; rv[ch].push(key); return rv; }, {}); // не обрабатываем повторно уже встречавшуюся комбинацию распределений ключей по группам let cmb = Object.values(chr) .map(seg => seg.join('\t')) .sort() .join('\n'); if (grp.has(cmb)) { continue; } else { grp.add(cmb); } res.pos[i] = chr; }
Метрика оптимума
Осталось только понять — а если бы на 3-м и 5-м символах группы оказались бы разными — какую из этих веток дерева стоит выбрать? Для этого введем метрику, которая даст нам ответ на этот вопрос — количество одинарных сравнений символа, чтобы найти каждый из ключей.
Тут мы пренебрегаем тем фактом, что часть узлов встречается в реальности в планах много чаще, чем другие, и считаем их равнозначными.
То есть, если мы взяли в строке 3-й символ и обнаружили там's', то потом нам надо сравнить с помощьюstartsWith, в худшем случае, еще 6 символов, чтобы убедиться, что там именноInsert.
Итого: 1 (.charCodeAt(2)) + 6 (.startsWith('Insert')) = 7 сравнений.
А вот если там обнаружился'd', то надо взять еще 7-й, чтобы узнать, будет там'O'или'S'. И после этого нам все равно придется перебором проверить список — был ли это'Index Scan Backward'(+19 сравнений) или только'Index Scan'(+10 сравнений).
Причем, если в строке будет'Index Scan Backward', то мы используем всего 19 сравнений, а вот если'Index Scan'— тогда 19 + 10 = 29.
Итого: 1 (.charCodeAt(2)) + 1 (.charCodeAt(6)) + 19 + 29 (.startsWith(...)) = 50 сравнений только по этой подветке.
В итоге, для нашего примера оптимальная карта будет выглядеть так:
{ '$pos' : 2 // проверяем 3-й символ , '$chr' : Map { 100 => { // 'd' '$pos' : 6 // проверяем 7-й символ , '$chr' : Map { 79 => [ 'Index Only Scan Backward', 'Index Only Scan' ] // 'O' , 83 => [ 'Index Scan Backward', 'Index Scan' ] // 'S' } } , 115 => 'Insert' // 's' } }
Вжух!
Теперь осталось только свести все воедино, добавить функцию поиска, немного оптимизаций — и можно использовать:
// заполнение карты поиска const fill = (obj, off, hash) => { off = off || 0; hash = hash || {}; let keys = obj.src; // проверка наличия такого списка ключей среди уже обработанных let H = keys.join('\n'); hash[off] = hash[off] || {}; if (hash[off][H]) { obj.res = hash[off][H]; return; } obj.res = {}; hash[off][H] = obj.res; let res = obj.res; // ситуация единственного ключа - возможна только при стартовом вызове if (keys.length == 1) { res.lst = [...keys]; res.cmp = res.lst[0].length; return; } // определение минимальной длины ключа и Longest Common Prefix let len, lcp; for (let key of keys) { // первый элемент if (lcp == undefined) { len = key.length; lcp = key.slice(off); continue; } len = Math.min(len, key.length); // пропускаем, если уже "обнулили" LCP или он совпадает для этого элемента if (lcp == '' || key.startsWith(lcp, off)) { continue; } // усечение LCP при несовпадении префикса for (let i = 0; i < lcp.length; i++) { if (lcp.charCodeAt(i) != key.charCodeAt(off + i)) { lcp = lcp.slice(0, i); break; } } } // если один из ключей является общим префиксом if (off + lcp.length == len) { let cmp = 0; // для двух ключей оптимальный вариант поиска - список if (keys.length == 2) { res.lst = [...keys]; } // выносим "за скобки" слишком короткие ключи else { res.src = keys.filter(key => key.length > off + lcp.length); res.lst = keys.filter(key => key.length <= off + lcp.length); } // поиск по списку проходит, начиная с самого длинного ключа, и стоит дорого res.lst.sort((x, y) => y.length - x.length); // s.length DESC cmp += res.lst.reduce((rv, key, idx, keys) => rv + (keys.length - idx + 1) * key.length, 0); // если есть продолжение - копаем дальше if (res.src && res.src.length) { fill(res, off + lcp.length + 1, hash); cmp += res.res.cmp; } res.cmp = cmp + 1; return; } // перебираем варианты выбора номера тестируемого символа let grp = new Set(); res.pos = {}; for (let i = off + lcp.length; i < len; i++) { // группируем ключи по соответствующим значениям [i]-символа let chr = keys.reduce((rv, key) => { if (key.length < i) { return rv; } let ch = key.charCodeAt(i); rv[ch] = rv[ch] || []; rv[ch].push(key); return rv; }, {}); // не обрабатываем повторно уже встречавшуюся комбинацию распределений ключей по группам let cmb = Object.values(chr) .map(seg => seg.join('\t')) .sort() .join('\n'); if (grp.has(cmb)) { continue; } else { grp.add(cmb); } let fl = true; let cmp = 0; for (let [ch, keys] of Object.entries(chr)) { // упаковываем группы из единственного ключа if (keys.length == 1) { let key = keys[0]; chr[ch] = key; cmp += key.length; } // для групп из нескольких ключей запускаем рекурсию else { fl = false; chr[ch] = {src : keys}; fill(chr[ch], i + 1, hash); cmp += chr[ch].res.cmp; } } res.pos[i] = { chr , cmp }; // запоминаем позицию "лучшего" символа if (res.cmp === undefined || cmp + 1 < res.cmp) { res.cmp = cmp + 1; res.bst = i; } // если за каждым символом остался конкретный ключ, то другие варианты нам не нужны if (fl) { res.bst = i; for (let j = off; j < i; j++) { delete res.pos[j]; } break; } } }; // сжатие карты поиска в минимальный формат const comp = obj => { // удаляем служебные ключи delete obj.src; delete obj.cmp; if (obj.res) { let res = obj.res; if (res.pos !== undefined) { // сохраняем только оптимальный вариант проверяемого символа obj.$pos = res.bst; let $chr = res.pos[res.bst].chr; Object.entries($chr).forEach(([key, val]) => { // упаковываем содержимое ключа comp(val); // если внутри символа только список - "поднимаем" его на уровень выше let keys = Object.keys(val); if (keys.length == 1 && keys[0] == '$lst') { $chr[key] = val.$lst; } }); // преобразуем объект с ключами-строками в Map с ключами-числами obj.$chr = new Map(Object.entries($chr).map(([key, val]) => [Number(key), val])); } // при наличии списка "поднимаем" вложенные результаты на уровень выше if (res.lst !== undefined) { obj.$lst = res.lst; delete res.lst; if (res.res !== undefined) { comp(res); Object.assign(obj, res); } } delete obj.res; } }; // поиск по карте - циклы вместо рекурсии и замыканий const find = (str, off, map) => { let curr = map; do { // по символу в позиции let $pos = curr.$pos; if ($pos !== undefined) { let next = curr.$chr.get(str.charCodeAt(off + $pos)); if (typeof next === 'string') { // значение ключа if (str.startsWith(next, off)) { return next; } } else if (next instanceof Array) { // список ключей на проверку for (let key of next) { if (str.startsWith(key, off)) { return key; } } } else if (next !== undefined) { // вложенный map, если есть curr = next; continue; } } // ищем по дополнительному списку, если он есть if (curr.$lst) { for (let key of curr.$lst) { if (str.startsWith(key, off)) { return key; } } } return; } while (true); }; function ImmutableTrie(keys) { this.map = {src : keys.sort((x, y) => x < y ? -1 : +1)}; fill(this.map); comp(this.map); } const p = ImmutableTrie.prototype; p.get = function(line, off) { return find(line, off || 0, this.map); }; p.has = function(line, off) { return this.get(line, off) !== undefined; }; module.exports = ImmutableTrie;
Как можно заметить, при поиске в таком Immutable Trie
Из бонусов: теперь мы можем получать искомый префикс без необходимости делать
.slice на исходной строке, даже если мы знаем, что в самом начале у нее, традиционно для плана, что-то постороннее:const nodeIT = new ImmutableTrie(...); nodeIT.get(' -> Parallel Seq Scan on abc', 6); // 'Parallel Seq Scan'
Ну а когда мы уже определились, где план начинается, ровно таким же способом (но уже с помощью Trie названий атрибутов) мы определяем строки, которые являются началом атрибута узла, а какие — продолжение multiline string и «склеиваем» их:
Index Scan using pg_class_relname_nsp_index on pg_class (cost=0.29..2.54 rows=1 width=265) (actual time=0.014..0.014 rows=0 loops=1) Index Cond: (relname = 'мама\nмыла\nраму'::name) Buffers: shared hit=2
Ну а в таком виде его разбирать — уже намного проще.

