
В первой части мы с вами поговорили о научном оборудовании, которое используется для прочтения, казалось бы, утраченных навсегда текстов. А теперь мы поговорим о том, как обрабатывать эти данные. Мы рассмотрим интересные цветовые пространства, алгоритмы, фильтры и методы статистического анализа. Но перед этим еще раз вернемся к их извлечению. Нам, простым смертным, доступны два варианта — сканеры и фотоаппараты.
Есть еще USB-микроскопы но они скорее для исследования деталей, чем для оцифровки. К тому же, рекламные видеоролики с примерами изображения мне не сильно понравились — перешарп, как у дешевой китайщины.
Сканеры.
Сейчас подавляющее количество сканеров на контактном сенсоре (cis). Это позволяет питать сканер прямо по USB без применения дополнительного питания, получать разрешение до 600dpi, но при этом иметь проблемы с глубиной резкости. Если ваш документ приподнят над поверхностью стекла CIS сканера более чем на 3мм — ждите мыла. Более того, как рассказал мне Дмитрий Николаев он лично наблюдал откровенное маркетинговое намахалово в разных сканерах. Ты выбираешь в настройках продукта формат tiff, а по USB шине сканер гонит jpeg, и уже драйвер сканера делает обратное преобразование. Для глубоких исследовательских задач это может вызвать недоумение.

На что только не пойдешь, чтобы удовлетворить возросшие потребности покупателей!
.
О, молодец! Заметил!
Сейчас будет шутка
Где-то в компьютерном

Более профессиональные сканеры используют CCD сенсор, обернутый в объектив и зеркало. Благодаря этой оптической схеме исчезают проблемы с глубиной резкости документа. Переплеты книг могут оставаться четкими и до 1 см от сканирующей поверхности. Так же присутствует и еще одна важная физическая характеристика — это глубина цвета. Теоретически, изображение с цветовой глубиной в 48 бит для анализа лучше, чем в 16 бит. Как вы уже знаете, для формирования цветного изображения сканеру необходимо три цветовых фильтра перед сенсором, но существуют и специальные мультиспектральные сенсоры для спутникового оборудования, отсуствующие на потребительском рынке. Мне даже попадался проект опенсурсного сканера, где существовала возможность менять белый источник света сканера на любой из 12 полос оптического диапазона. Но к сожалению, проект куда-то исчез из сети.
Если вы, дорогой читатель, имеете опыт построения железок этого уровня, можем попробовать это обсудить. Взять какой нибудь сканер, и переделать ему подсветку. Из недостатков этой схемы — время работы на оцифровку и стекло между. При необходимости 12 сканов при 1200 dpi мы получаем минимум час чистой работы железки, поэтому в современных мультиспектральных системах используются 2D сенсоры.
Фотоаппараты
Если посмотреть даташиты на какие нибудь кремниевые сенсоры, то их спектральная отзывчивость от УФ до примерно 1000нм. Диапазон после 700нм считается ближним ИК, который нужно отсекать для привычной для нашего глаза картинки. Для этого перед каждым сенсором в любой потребительской технике находится ИК фильтр такого зеленого, на отлив фиолетового, цвета. Для задач мультиспектрального сканирования он только мешает. Поэтому любители ИК фотографии его тоже удаляют самостоятельно.
Промышленные камеры
Чуть более удобным техническим решением выступает использование USB3 промышленных камер без bayer-pattern т.е. использование монохромных сенсоров. (USB 3.0 monochrome industrial cameras) например, BFS-U3-200S6M-C. Очень удобно заниматься подготовкой лаборатории, корректировкой освещения и позиционированием документа, а особенно, проверки резкости (при разных длинах волн фокус разный!) наблюдая изображение на большом экране монитора.
Астрокамеры
Не следует забывать и про любителей вглядываться в вечность. Продавец астрокамер заверил меня, что между исследованием космоса и документов нет разницы и вместо промышленных камер лучше использовать камеры с активным охлаждением матрицы (их рабочий режим до минус 45 по цельсию) Например ASI183MM Pro.
С этой камерой можно использовать объективы от потребительских камер стандарта micro 4/3. Когда я делал обычную съемку на фотоаппарат Lumix DMC-GX80 (16mpx) дневника Васи Баранова я убедился, что мой Olympus 45mm f/1.8 на диафрагме 5.6 выдает достаточно резкие фотографии и вполне пригоден для использования. Даже шумов не так много, учитывая, что света было не так много как хотелось бы.
Из истории
Как-то Павел Полян укладывал меня спать у себя в московской квартире и предварительно разгребал для этого свои архивы. Одну комнату он расчистил, а другую — завалил. И в этом процессе и был обнаружен этот дневник, оставленный с какой-то выставки. Ну мы его и оцифровали.

И так, в зависимости от техники на выходе у вас будет либо RGB изображение, либо полутоновые изображения, снятые в различных длинах волн. Что делать дальше?
Софт
ImageJ
Утилита ImageJ является популярным инструментом в анализе изображений на западе. Свободные графические алгоритмы, часто пишутся под эту программу и она часто упоминается в разного рода исследованиях как платформа для быстрой отработки графических алгоритмов. Особенно интересен раздел плагинов.
ENVI
Если смотреть историю мультиспектрального анализа, то конечно же первым предметом исследования для ученых были фотографии со спутников. В них установлены те самые мультиспектральные датчики и задачи ставятся ровно такие же — произвести коррекцию и вытащить максимальное количества информации. В этом смысле нет разницы: вглядываемся ли мы в космос или в рукопись. Популярным исследовательским решением выступает программный комплекс ENVI. Я буду говорить о версии 5.3 (другой не нашел ;-) ).
(Если знаете другое ПО, просьба сообщить)
→ Ссылка
Photoshop
Забывать его тоже не будем, поскольку он удобен при ручных манипуляцих при отработке каких-нибудь гепотез.
Передо мной оцифрованный документ. С чего начинать?
Скорее всего у вас RGB документ. Начать нужно с анализа каналов и преобразования цветовых пространств.
Анализ каналов
ENVI / ImageJ / Photoshop plugin
RGB модель плохо подходит для максимизации отображаемых данных для нашей зрительной системы так же как и для сегментации изображений, определения краев и т.п. В 1989 году Xerox предложила цветовую модель YES. Она как раз основывается на физиологической модели нашего зрения. При съемке свитков Мертвого моря в 90-х после преобразования RGB в модель YES в канале E были обнаружены ранее непрочитанные исследователями символы. Y — компонент яркости, E — красный минус зеленый и S — синий минус желтый. Эта модель очень уж похожа на современный Lab. Поэтому на сегодня о YES давно забыли.
Для справки, существует цветовое пространство OHTA было экспериментально выведено при статистическом изучении некорреляционных компонентов цвета из большой выборки обычных фотографий. В 2012 году был предложен новый метод сегментации огня, основанный на OHTA. С помощью этого метода можно точно разделить пламя в различных погодных условиях и в различных условиях окружающей среды.
Все это означает, что выделение требуемого контраста определенных компонентов теоретически возможно.
Вы, конечно же, можете найти в imageJ почти все популярные цветовые модели и разложить на каналы самостоятельно, но есть замечательный аналитический онлайн-ресурс retroreveal.org.
Он отобразит в галерее каналы следующего набора цветовых моделей: Yuv, YQ1Q2, HSI, HSV, HSL, LCHLuv, LSHLuv, LSHLa, XYZ, Yxy, YUV, YIQ, Luv, Lab, AC1C2, I1I2I3.
Как-то раз...
К моему удивлению, он по каким-то причинам специально недоступен через выдачу в гугле. Его robots.txt содержит запрет на индексирование.
Как-то раз я просто забыл название ресурса и потратил кучу времени на его гуглеж по ключевым словам! И конечно же я ничего не нашел! Пришлось делать глаза котика и писать в твиттер британской библиотеки, чтобы мне напомнили некий ресурс, куда заливаешь скан и получаешь раскладку по каналам из разных цветовых моделей!
Как-то раз я просто забыл название ресурса и потратил кучу времени на его гуглеж по ключевым словам! И конечно же я ничего не нашел! Пришлось делать глаза котика и писать в твиттер британской библиотеки, чтобы мне напомнили некий ресурс, куда заливаешь скан и получаешь раскладку по каналам из разных цветовых моделей!
Если результат в анализе каналов показывает, что необходимая информация в изображении хоть как-то проявляется, то можно двигаться дальше.
Онлайн сервис retroreveal.org имеет ограничение на размер обрабатываемого файла. Аналогичное можно повторить локально через ColorTransform 2
www.russellcottrell.com/photo/colorTransformer2.htm
Фильтры
Levels and saturation
Привожу этот пример, как часть интуитивного мышления исследователя. Чуть ранее мы говорили о цветовом пространстве YES и нашем восприятии, а в пространстве RGB мы интуитивно правим изображение по уровням и насыщенности. Хорошим примером такого чутья выступает расшифровка медальона

Как это прям точно было реализовано я не знаю, но обработка велась в photoshop Олегом Гусевым. Я же смог добиться разборчивости через предварительное поднятие банальной насыщенности.
Обратите внимание на скриншот с развертыванием бумаги. Как много остается мокрой бумажной пыли! А ведь такая кучка вполне может содержать пигмент на целую букву! При том, что идеальное решение этой задачи существует с помощью рентгеновской микротомографии! Я точно знаю, что рентгеновский томограф есть в институте кристаллографии им. А.В.Шубникова, но там такая очередь!

(Пожалуйста, не пытайтесь обрабатывать пример выше самостоятельно, сохранив файл на компьютер. Это скриншот с видео — труп. Я проверял результат с другого увеличенного кадра и подтверждаю, что это реально)
Среди поисковых отрядов есть желание сразу же увидеть фио бойца в найденных документах на глазок, под солнышком. Это приводит к очень печальным последствиям и очень злит. Документы просто уничтожаются. Цитата Алексея Мишина:
«Нашли недавно политрука 416 сп. Его документы распотрошили в чистом поле. Удостоверение с фотографией убили. Вся надежда на ДНК экспертизу. Сейчас ждём образцы от родственников.
Скорее всего нашли мл. Политрука Вандышева. »
А это состояние документов, найденных 3 октября 2020 года, с которыми приходится работать исследователям.

Как вы понимаете, их раскрывать очень рискованно.
Black&White
Подробно о применении этого фильтра я писал здесь.
Пример

Вот видео процесса и PDF-версия:
Если коротко, фильтр Black&White пересчитывает модель RGB в 7 цветных слоев, что позволяет регулировать интенсивность каждого довольно точно. Это как бы псевдо мультиспектральная съемка.
Highpass
В процессе обработки вы можете столкнуться с тем, что фильтры просвечивают и затемняют нужные зоны документа. В этом случае помогает фильтр highpass, его назначение именно в регулировании перепадов яркости. Опять же его практическое применение вы увидели в видео выше.
Алгоритмы
Decorrelation Stretch
ENVI / ImageJ
При отсутствии технологических возможностей, требования к анализу цифровых изображений выставляются часто предельные. Почему? Представьте, что у вас нет возможности слетать на марс с другим фотоаппаратом. Так в 2004 году марсоход Opportunity прислал фотографию после бурения породы.

На изображении три отверстия, созданные внутри «кратера выносливости» летом 2004 года. Ученые из NASA применили алгоритм Decorrelation Stretch
Поскольку цветовые вариации на марсе крайне слабы, с помощью этого алгоритма можно лучше различить структуру породы. Когда бур просверливает серый гематит, в результате получается ярко-красный порошок, а благодаря обработке можно различить процесс прохождения слоев. Первый слой красный, второй желтый, а самый глубокий — зеленый.

Реализация этого алгоритма конкретно для imageJ доступна за денежку. Его автор Jon Harman. Он написал не очень дешевое мобильное приложение с этим же функционалом, чтобы не скучать во время вылазки в горы для любителей изучения древней наскальной живописи. Ссылки на его софт встречаются в публикациях, но что касается рукописей, как-то мне ничего дельного не встретилось.
Применение к рукописям членов зондеркоммандо программы Dstretch, чьи цифровые копии лежат у меня, по моему мнению, этот алгоритм неприменим из-за проблем с детализацией. Именно поэтому он лучше подходит для поиска крупных объектов. В базе матлаба тоже есть реализация этого алгоритма, но Dstrech умеет работать с конвертированием в массу цветовых пространств.
Результат обработки обычных фотографий наскальной живописи на его сайте достаточно любопытен.
Ссылка

Colour Deconvolution
ENVI / ImageJ / Photoshop plugin
Ссылка 1 | Ссылка 2
Цветовая деконволюция активно применяется в медицине для разделения подкрашенной прозрачной клеточной ткани. У алгоритма строгие требования к однородности цветовых пигментов и необходимости их наложения с наличием полупрозрачности (то есть верхний слой пигмента не должен полностью закрашивать подложку). Но такие ситуации тоже могут быть. Например, в примерах коммерческого плагина для photoshop есть онлайн редактор. К сожалению, реализации работающего на лету алгоритма я не встретил. Нужно тупо задавать три параметра и жать кнопку. Это очень неудобно.

Мое мнение по этому алгоритму: если контраст, который мы ищем основан на разнице в цвете (не близкого по спектру), обойтись получится куда более удобными подходами. Но если исходить из результата, очень близкие прозрачные цвета, наложенные друг на друга могут быть успешно разделены. Повторить это из известных мне трюков в фотошопе у меня не получилось.
Методы статистической обработки
Статистические методы анализа предполагают, что разделить информацию на слои для обнаружения новых закономерностей возможно, только не ясны параметры, по которым это следует сделать.
Здесь мы переключаемся на программный пакет ENVI, специализирующийся на обработке мультиспектральных спутниковых данных. В своем наборе он содержит больше количество алгоритмов, которые выступают стандартом первичного анализа данных, полученных после оцифровки, но для наших целей там всего несколько пунктов.
Метод главных компонент (PCA) и метод независимых компонент (ICA)
Выше мы с вами говорили, что результат оцифровки на монохромную камеру в разных длинах волн состоит из около 12 полутоновых изображений. Как с ними работать то?
Спектральные полосы изображения сильно коррелируют, так как занимают близкие области в пространстве. Для анализа такой массив данных не очень удобен. За последнее десятилетие было разработано большое количество методов сокращения размерности. Однако, в этой статье я не рассматриваю их применение через непосредственное обращение к коду. Я расскажу о методах, которые существуют в коммерческих продуктах.
Методы PCA и ICA используется для снижения размерности, то есть удаления избыточной информации. Из 12 каналов можно получить 3, но более детализированных. После обработки первый канал изображения содержит наибольшую дисперсию данных (наименьший разброс случайной величины относительно ее математического ожидания т.е среднего предполагаемого положения), второй — вторую по величине и так далее до того момента, когда данные уже сливаются в хаотический шум.
Удачным примером служат некоторые страницы палимпсеста Архимеда ( 287-212 ГГ. до Н.Э.)

На этом рисунке палимпсест содержит смесь из двух наложенных текстов и, вероятно, разные слои из плесени и прочих пятен. На основе мультиспектральной съемки из итоговых 14 слоев удалось извлечь чистые страницы первичного текста Архимеда.
На изображении ниже к рукописи Лейба Лангфуса применен ICA. Особенность этого документа — практически полное отсутствие цветового пигмента чернил и отдавался он на перевод таким, какой был со сканера. После обработки появляется более значимый контраст. Даже этого достаточно, чтобы просто увеличить скорость перевода.
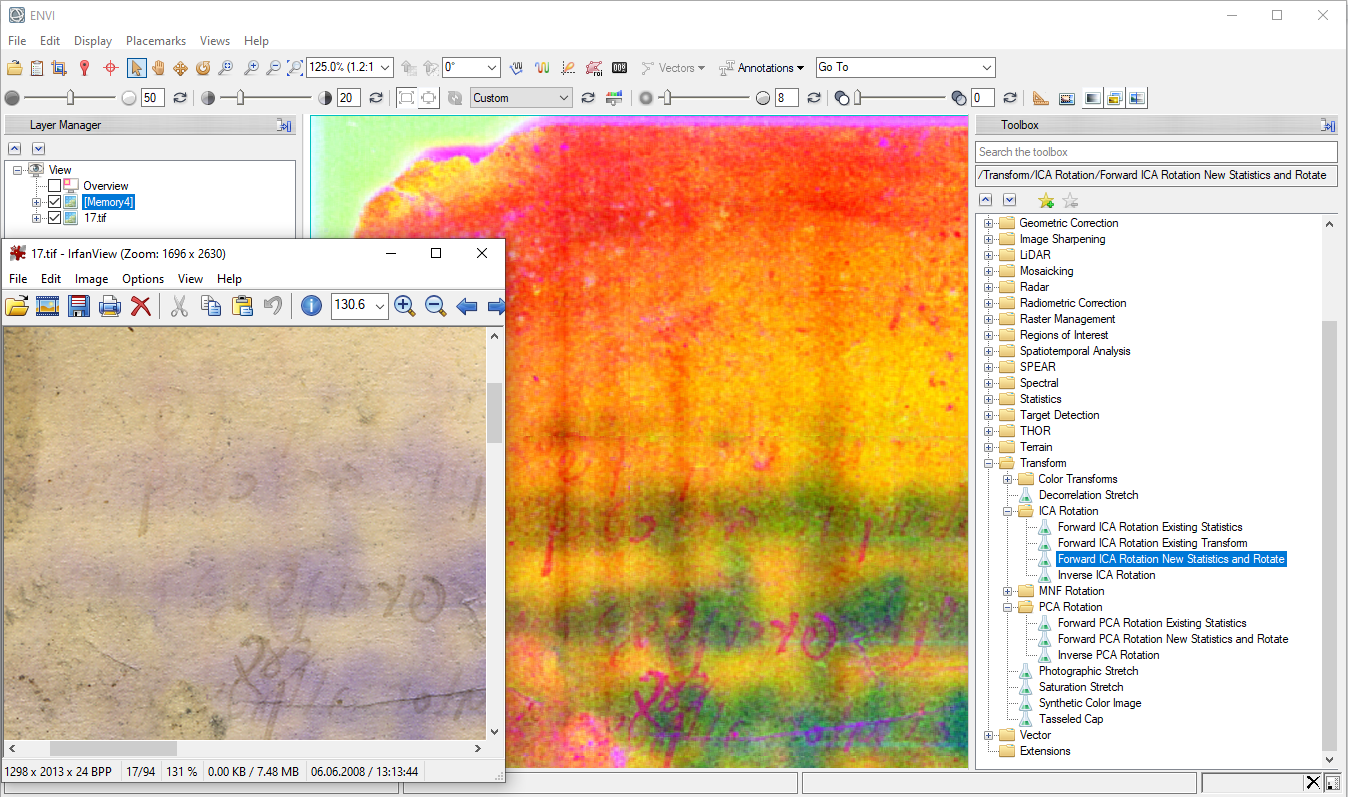
А здесь применение ICA для образца из главы про цветовую деконволюцию. Мы получаем результат, но теряем оригинальные цвета.

Следует отметить, что программный продукт matlab содержит в себе около 12 способов уменьшения размерности, помимо PCI и ICA.
Если вы читали в моей предыдущей статье о палимпсесте Галена, то некоторые из его страниц прочитались с помощью CVA (Метод анализа канонических переменных)
А это часть из тестируемых образцов, где метод CVA показан первым.

Какой способ и когда лучше работает — исследователи сказать не могут.
Индивидуальные подходы
В зависимости от характера повреждения текста процесс возможной обработки является уже творческой задачей. К сожалению, примеров работ с подобными трюками пока мне известно крайне мало.
Компенсация протекших чернил
В случае с рукописью Марселя Наджари мне пришел в голову способ компенсирования протекших чернил.
Я уже отсылал к своей статье. Суть довольно проста — если у вас есть два скана одной страницы, вы можете использовать обратную сторону зеркально чтобы уменьшить ее влияние на восприятие информации на лицевой стороне. Так или иначе этот способ позволил значительно увеличить читаемость первой страницы Марселя, а на дальнейших — значительно облегчить труд переводчика.
Оптико-электроная текстология
Из российских проектов мне известны работы по прочтению рукописи Чехова и Достоевского. Не смотря на то, что те статьи озаглавлены как «ОСНОВЫ ОПТИКО-ЭЛЕКТРОННОЙ ТЕКСТОЛОГИИ» — это кропотливый труд. Суть рассматриваемой работы заключалась в большом мастерстве автора соединять видимые элементы рукописного текста, который зрительно можно разобрать. Оказывается, можно вполне себе восстановить целые предложения.
Ниже страницы письма Ф. М. Достоевского к А. Е. Врангелю от 14 июля 1856 г. с зачеркнутым текстом.

А это результат

Не смотря на то, что были попытки проводить мультиспектральный анализ, из-за идентичного состава чернил разницы в контрасте не возникло. На этом исследователи остановились. Еще фрагмент:

Мастерству натренированного глаза можно только удивляться! По словам исследователей, данная работа продвигалась невероятно медленно. ЕЩЕ БЫ! Я когда это первый раз увидел, думал что за магия, где формулы? На мой взгляд, методы статистической обработки позволили бы сделать эту работу быстрее.
Итог
На этом, я думаю можно подводить итоги и завершать экскурс в эту интересную тему.
- Если вы можете получить серию чб фотографий, то есть произвести съемку в разных спектрах, используйте envi и прочие алгоритмы статического анализа для уменьшения размерности.
- Если у вас есть RGB файл, то из всего перечисленного выше стоит рассматривать retroreveal как первичный анализ, ColorTransform 2 — для обработки локально без ограничений по объему файла, Dstretch для imageJ — альтернативный вариант ( а может и более лучший) и методы статистической обработки.
Я надеюсь, что вы сможете поделиться данной статьей с людьми, в чьих интересах лежит схожая область или же они не подозревают о существовании таких подходов. Мемуары вашего ветерана или же другой испорченный документ может быть восстановлен с помощью современных технологий.
Обращусь к коммерческим компаниям, занимающимся как и фотокамерами так и другим исследовательским оборудованием. Для вас это может быть хорошим пиар ходом. Эту статью наверняка прочитают сотрудники государственных архивов и музеев и не долог тот час, когда вы можете быть нужны друг другу. Как много еще неизученных документов, письма Пушкина, Салтыкова-Щедрина, Достоевского, Чехова и других писателей, которые без вас еще долго будут пылиться на полках из-за отсутствия нужного оборудования. По данным из совместной работы вы можете подготовить замечательные и полезные рекламные статьи.
Источники
http://unknown-dostoevsky.ru/files/redaktor_pdf/1438251988.pdf
https://lechaim.ru/academy/shabat-chitaetsya-chetko/
https://arxiv.org/ftp/arxiv/papers/1612/1612.06457.pdf
https://www.scientific.net/AMR.485.7
https://www.manuscript-cultures.uni-hamburg.de/MC/articles/mc7_Easton_Kelbe_Carlson.pdf
https://www.sciencedirect.com/science/article/pii/S2090123219300037
https://chsopensource.org/multispectral-imaging-system/
https://lechaim.ru/academy/shabat-chitaetsya-chetko/
https://arxiv.org/ftp/arxiv/papers/1612/1612.06457.pdf
https://www.scientific.net/AMR.485.7
https://www.manuscript-cultures.uni-hamburg.de/MC/articles/mc7_Easton_Kelbe_Carlson.pdf
https://www.sciencedirect.com/science/article/pii/S2090123219300037
https://chsopensource.org/multispectral-imaging-system/

