Содержание
- Основные различия
- Reproducibility crisis
- Система контроля версий
- Data Version Control
- Полезные ссылки
Введение
Несмотря на всю пользу DVC, об этом инструменте знает катастрофически мало разработчиков. Поэтому, думаю, не лишним будет для начала вас познакомить. DVC – это open-source система контроля версий данных, которая отлично подходит для машинного обучения. И основное отличие DVC от Git’a в том, что он: во-первых, имеет более широкий и удобный инструментарий для ML-проектов; во-вторых, создан для контроля версий данных, а не кода. И по большей части здесь их основные различия заканчиваются. А далее я постараюсь описать, чем же так хорош DVC, и почему Git'а не достаточно для ML.
Reproducibility crisis
В машинном обучении есть такой термин «Reproducibility crisis» (от англ. – «кризис воспроизводимости»), который означает, что некоторые модели, обученные однажды, не смогут обучиться заново с такой же точностью, что и в первый раз.
Чем же это плохо? Если заказчик попросил написать условный классификатор пчёл, и вы смогли добиться точности в 98.5%, то зачем вообще её воспроизводить и переучивать?
Представим, что неожиданно ученные открыли еще один вид пчёл. А вашему заказчику ну очень нужно и его распознавать. И если ваша модель изначально воспроизводима, достаточно просто добавить в датасет информацию о новом виде пчел. Представим другую ситуацию – однажды вы осознаете, что классификатор можно улучшить парой другой строчек кода, но если как изначального датасета не осталось, ни у вас, ни у заказчика, улучшить его навряд ли получится.
Разумеется, классификатор пчёл – весьма условный пример. Основная проблема Кризиса в том, что больших компаниях и в исследовательских лабораториях работа одних разработчиков/исследователей в условиях невоспроизводимости результата сильно зависит от их коллег. А это всегда чревато падением КПД, временными задержками и убытками.
Система контроля версий
Git привнес огромный вклад в воспроизводимость моделей. Теперь, после написания/изменения какой-либо модели, можно сохранять её состояние как локально, так и на различных серверах, например GitHub. А это уже позволило отслеживать какие именно модели лучше справляются в каких условиях и с какими гиперпараметрами. Но как бы хороша не была построена модель, если она не обучена, назвать её полезной сложно. С одной стороны – да, можно сохранять заранее обученные модели с помощью какого-нибудь joblib. Но с другой стороны, такой подход и создаёт кризис воспроизводимости. Решение проблемы – Git-LFS
Git-LFS предназначен для хранения [относительно] больших файлов в Git серверах, и является расширением Git. Основная идея – замена больших аудио/видео файлов, датасетов и т. п. текстовыми указателями. И для некоторых проектов использование этого расширения может быть достаточно. Особенно, если следующие минусы вас не смущают:
- Git-LFS имеет лимиты – 1 Гб на GitHub в (бесплатном тарифе), в Gitlab и в Atlassian могут быть свои. Причем это лимиты не на размеры файлов, а на всё LFS хранилище и на его пропускную способность.
- Данные хранятся вместе со всем остальным в репозитории, а значит они влияют на скорость его загрузки.
- Git-LFS ограничивает выбор места хранения данных. Это всегда должен быть LFS сервер.
- Полноценно устранить проблему Кризиса у Git-LFS не получается.
Data Version Control
DVC вам не новый Git. Он представляет из себя утилиту по управлению кодом и большими файлами данных, которая должна работать в связке с системой управления исходного кода (например, Git). Работа с DVC + Git выглядит примерно так:
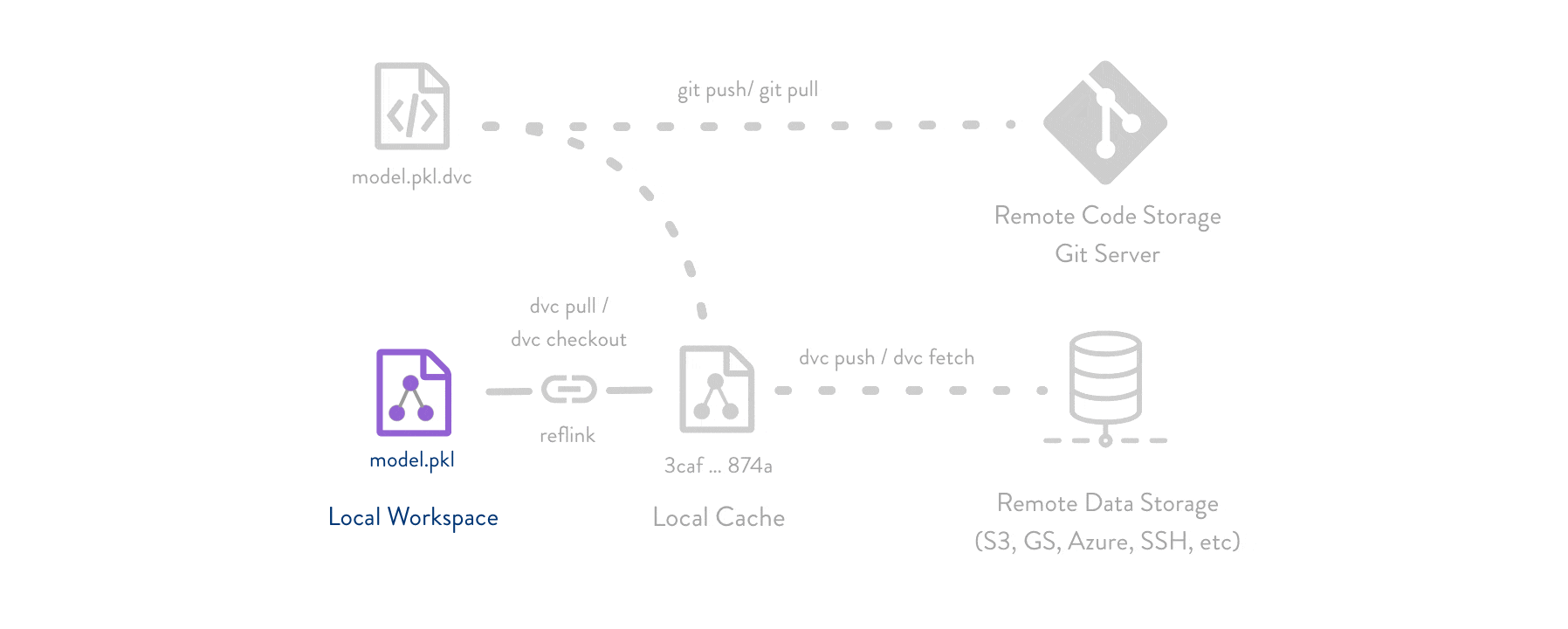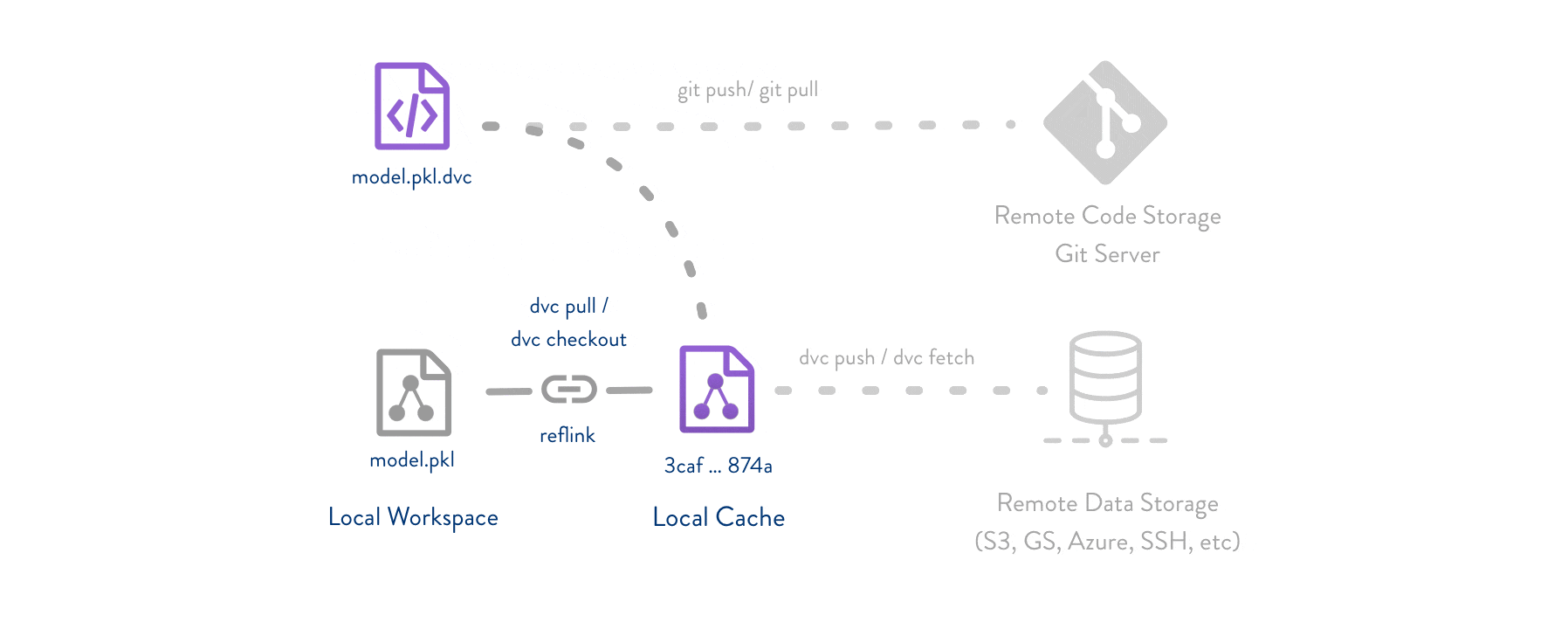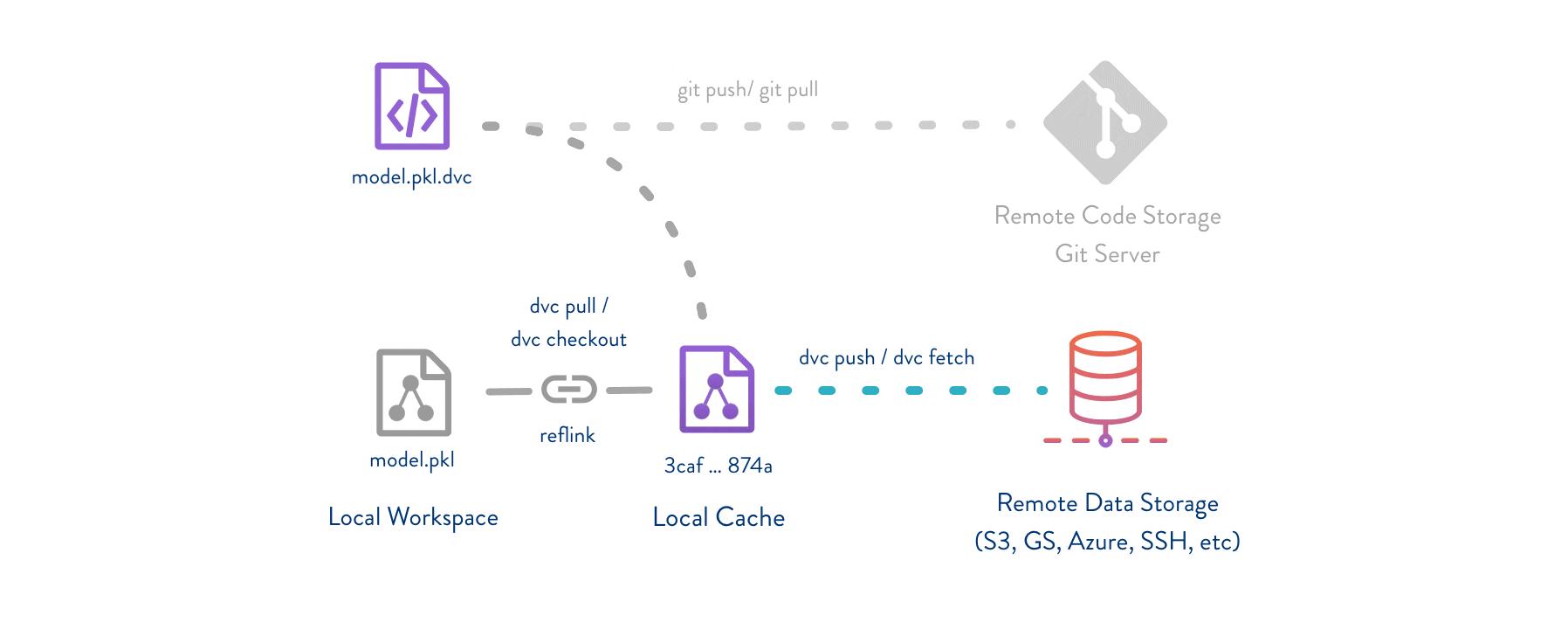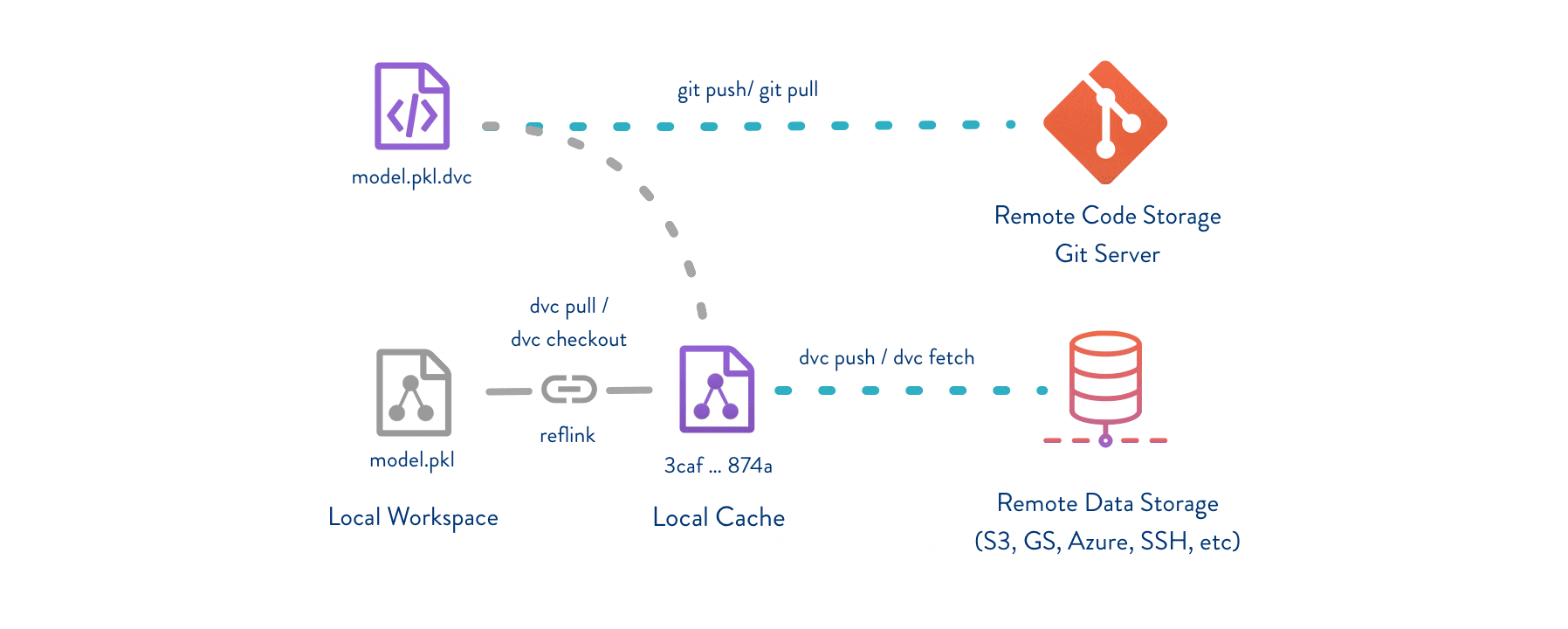

На Github’е хранятся весь ваш код и какие-нибудь метафайлы об имеющихся данных и зависимостях между ними. А в специально выбранном месте (локально или на любом сервере) хранятся данные для обучения, тестирования и т. п.
Также DVC хранит зависимости между скриптами и датасетами. Если у вас изначально был один датасет, и вы решили его как-нибудь обработать, вы можете написать скрипт-обработчик и указать зависимость «скрипт-обработчик и датасет0 формируют датасет1». DVC сам сформирует «датасет1» и начнет его отслеживать. Но самое интересное – цепочки зависимостей: «скрипт0 и датасет0 формируют датасет1», «скрипт1 и датасет1 формируют датасет2» и «скрипт2 и датасет2 формируют файл оценки точности». Файл метрик в этом примере формирует цепочка из 6 файлов. И если хотя бы один из них был изменен в течении работы, достаточно одной команды DVC и все будет заново просчитано по древу зависимостей. Причем, как и утилита Make, DVC отслеживает был ли изменен тот или иной файл.
Вот какие преимущества вам даёт DVC:
- Абстракция кода от данных;
- Хранение данных в любом хранилище;
- Создание пайплайнов по обработке датасетов и их визуализация в консоли;
- Сохранение и отслеживание всех метрик;
- Переключение между версиями файлов;
- Воспроизведение моделей по созданным пайплайнам.










