
В Ceph можно распределять пулы с данными по разным типам серверов: «горячие» данные хранить и реплицировать на SSD, «холодные» — на HDD. Кроме того, пулы одного кластера можно разделять физически. В статье расскажем, как это сделать.
Статья подготовлена на основе лекции Александра Руденко, ведущего инженера группы разработки «Облака КРОК». Лекция доступна в рамках курса по Ceph в «Слёрме». Тема была добавлена уже после релиза видеокурса, в январе 2021. Также в январе в рамках развития курса появились новые практические задания:
- Установка при помощи cephadm.
- Установка при помощи Ansible.
- Использование Ceph: объектное хранилище.
- Пулы и классы хранения Ceph.
Зачем распределять пулы по разным устройствам и группам устройств
Размещение пулов на разных устройствах (HDD/SSD) нужно, чтобы использовать оборудование более эффективно. Например, когда в кластере есть и магнитные диски, и SSD, логично разместить индексный пул или пул с метаданными файловой системы на SSD, а пулы с данными — на HDD.
Физическое размещение пулов на разных серверах используют, когда нужно, чтобы у каждого пула был разный домен отказа, а также когда надо распределить данные по разным серверам одного типа. Например, кластер состоит из магнитных дисков, но часть из них это небольшие SAS-диски с 15000 RPS, а другая часть — большие и медленные диски с черепичной записью. На быстрых размещают «горячие» данные, на медленных — «холодные».
Второй сценарий менее распространённый, поэтому начнём с него.
Физическое размещение пулов на разных серверах
Для примера возьмём кластер с простой CRUSH-топологией: есть root — так называемый корневой элемент, внутри него есть 3 хоста и какое-то количество OSD. Стоек и дата-центров нет. Это простая дефолтная топология, которая появляется при создании кластера.
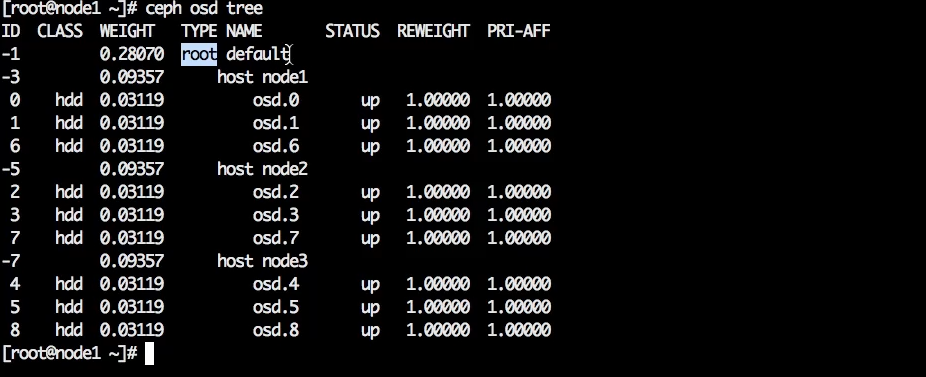
Есть пулы, часть которых RGV создал сам, часть созданы вручную.
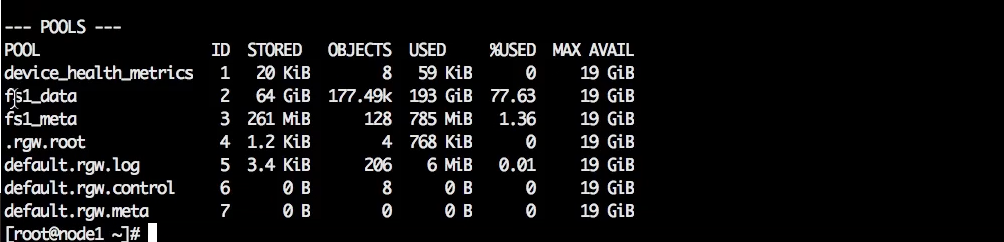
Что такое пул в Ceph
В Ceph при создании кластера и пулов нет возможности сказать: «создай мне кластер вот на этих серверах» или «используй диски с этих серверов, чтобы размещать данные этого пула». Потому что пул в Ceph — это высокоуровневый каталог с практически плоским пространством объектов. Есть группировка по стойкам, дата-центрам и OSD, но в целом это единое пространство или группа object stores.
В некоторых других системах хранения сначала создаётся пул, а потом в него добавляются ресурсы. Пользователь говорит: «добавь вот этот диск вот в этот пул, добавь вот этот сервер вот в этот пул» — то есть пул как бы собирается из какого-то количества ресурсов. Это более понятная концепция.
В Ceph всё иначе. Здесь пул — это просто каталог, который нельзя настроить так, чтобы он задействовал только часть ресурсов. Созданные пулы по умолчанию «размазываются» по всем дискам серверов. Внутри кластера могут быть медленные диски, SSD, серверы с 60-ю дисками — неважно, данные пула размажутся по всем серверам и OSD в зависимости от веса.
Разместить пул на выделенных серверах в Ceph нельзя. Предположим, нужно добавить в кластер 3 сервера и разместить на них особый пул, данные которого не будут попадать на соседние серверы. Доступным инструментарием Ceph сделать это невозможно. Да, можно отредактировать CRUSH, но это сложно и чревато разрушением кластера, поэтому делать так не рекомендуют. Рассмотрим более безопасный способ.
Как изолировать пул на группе хостов:
- создать новый корневой элемент;
- в этот корневой элемент добавить хосты, стойки и дата-центры (если нужно);
- с новых хостов вести OSD — у вас получится два отдельных root’а;
- в новом root’е создать политику размещения;
- новый пул создавать в этом root’е.
Посмотрим на примере: допустим, есть хост, и на этом хосте нужно разместить определённый пул. Для начала создадим объект хоста.
Синтаксис команды:
ceph osd crush add-bucket {имя} {тип}
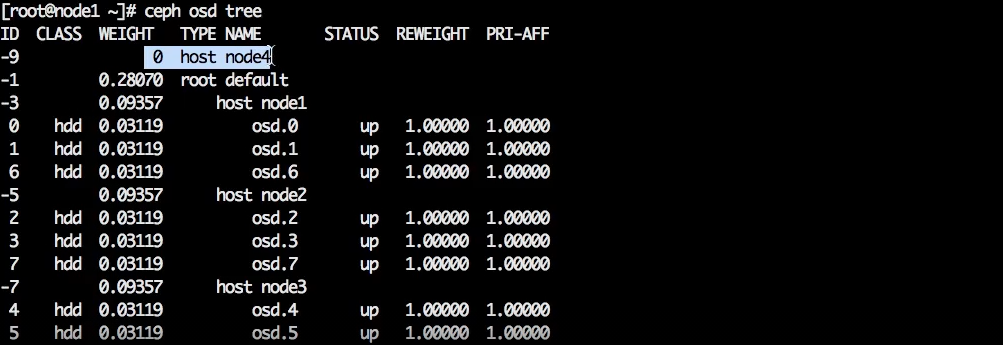
В нашем примере нужно создать объект с именем node 4 и типом host.
ceph osd crush add-bucket node 4 host
Объект создан, он появился вне дефолтного дерева.
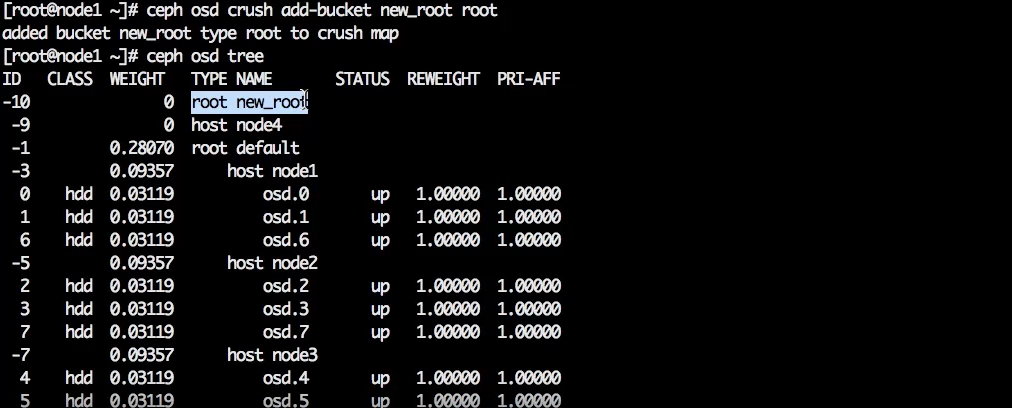
Теперь надо создать новый root. Синтаксис команды тот же, меняется только имя и тип объекта.
ceph osd crush add-bucket new_root root
Новый root появляется на том же уровне, что и host — вне дефолтного дерева.
Созданы две сущности, которые никак друг с другом не связаны, но в нормальной иерархии host находится внутри root. Чтобы их связать, надо переместить хост node4 в новый root.
ceph osd crush move node4 root=new_root
Появилась иерархия:

Новый сервер добавлен и правильно размещен в иерархии, значит можно добавить OSD с этого сервера.
У нас есть готовый диск (называется “vdb”), из которого можно сделать OSD.

Сначала сотрём заголовки:
ceph-volume lvm zap /dev/vdb
Получим бутстрапный ключ. Он нужен, чтобы сгенерировать персональный ключ для создания OSD.
sudo -u ceph auth get client.bootstrap-osd > /var/lib/ceph/bootstrap-osd/ceph.keyring
Запустим создание OSD:
ceph-volume lvm create --data /dev/vdb
При создании OSD автоматически включается в CRUSH-иерархию: её хост добавляется в CRUSH-дерево. То есть можно было просто запустить создание OSD, и она бы создала запись в CRUSH для себя и своего хоста. Возможно, он был бы в дефолтном root’е, и нам бы пришлось его перемещать, но это не проблема.
OSD появилась в списке. Обратите внимание: ей присвоен следующий по счёту номер (в нашем случае — 9). То есть это не какое-то новое исчисление OSD, пространство идентификаторов OSD остаётся единым.
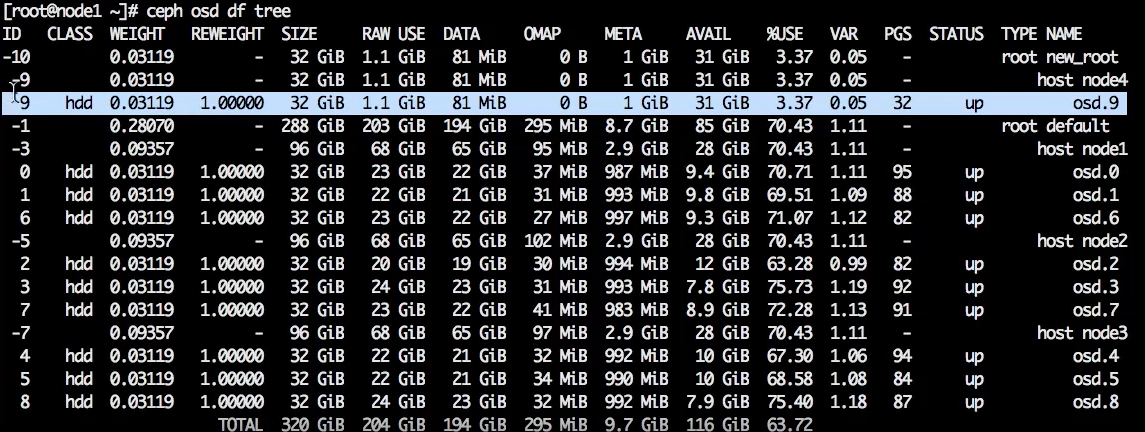
В нашем примере создан только один хост, так как для эксперимента больше не нужно. Но в принципе можно добавить сколько угодно хостов, OSD и получить отдельные, совершенно независимые деревья.
Для проверки выполним команду:
ceph osd df tree
Новая OSD зарегистрирована, и у нее ноль плейсмент групп (placement groups, PGS).

Новая OSD содержит ноль placement groups, потому что из первого дерева они ей не передаются. Разные root’ы — это физически разная топология. У них общие только мониторы и менеджеры.
Placement groups появляются вместе с пулами, в этом root’е мы ещё не создавали пулы, поэтому их нет.
CRUSH-топология создана. Теперь нужна политика репликации — распределения данных по этой топологии.
Как создать политику репликации
Дефолтная политика — это репликация по хостам, но можно задать репликацию по стойкам, дата-центрам и т. д.
Создадим политику для root’а через правило распределения данных:
ceph osd crush rule create-simple new_root_rule new_root host
new_root_rule — название политики,
new_root — нужный root,
host — то, как реплицировать данные, в нашем случае по хостам.
Если вместо host написать datacenter, то данные будут реплицироваться по дата-центрам: в каждом ДЦ будет храниться по одной копии.

Новое правило создано, теперь надо создать новый пул.
ceph osd pool create new_root_pool1 32 32 created new_root_rule
В команде надо указать созданное ранее правило (new_root_rule) и сколько нужно создавать PGS: первая цифра — количество PGS, вторая цифра — сколько из них доступно для аллокации (32 32). В Ceph часть placement groups пула могут быть закрыты для аллокации. Например, в пуле 128 PGS, а открыты для аллокации только 32. В нашем примере открыты 32 из 32 групп.

В текущем new_root только одна политика, которая говорит реплицировать данные по хостам. Однако можно создать несколько. Создавая новый пул, надо указывать политику. Таким образом новый пул связывается с конкретным root’ом, который использован в этой политике.
Теперь на OSD аллоцированы все 32 placement groups, которые были заданы.
Все они в статусе undersized и inactive.

Placement group неактивны, так как им недостаточно ресурсов. Новый пул создался с дефолтными правилами, а среди дефолтных глобальных параметров Ceph есть правило “osd_pool_default_size”, и его параметр равен 3. Таким образом пул создался с числом реплик 3.
Чтобы уменьшить число реплик, сначала надо изменить параметр min_size.
сeph osd pool set new_root_pool1 min_size 1
Затем уменьшить собственно размер:
сeph osd pool set new_root_pool1 size 1
В результате получится пул с replicated size 1.

Проверим командой ceph -s
Предупреждения о том, что placement groups находятся в статусе inactive и undersized, исчезли. Правда, появилось новое предупреждение: у пула выключена репликация. Но мы не будем на этом останавливаться.
В результате создана всего одна OSD и один хост, но это полностью рабочая конфигурация (рабочая в том смысле, что она может работать, а не в том, что она где-то применима; к счастью, никто не запускает Ceph для одного хоста).
Мы разграничили пулы, но при этом сохранили их в одном пространстве. Если что-то сломается в одном дереве, это никак не зааффектит другое дерево.
Важно: Старайтесь проводить манипуляции с пулами и распределением по классам устройств на этапе создания кластера, когда в нем еще мало данных. Потому что позже, когда кластер заполнен продакшн-данными, при смене классов устройств и перераспределении пулов между ними, у вас будет массивная ребалансировка.
Распределение пулов на разных устройствах
Раньше в Ceph не было понятия «класс устройства». В кластере могли быть SSD и магнитные диски, но нельзя было поместить один пул на SSD, другой на HDD. Относительно недавно ситуация изменилась. Теперь Ceph понимает, что есть HDD и есть SSD, и позволяет назначать на разные устройства разные пулы.
Тип устройства Ceph определяет автоматически, используя параметр rotational (вращающийся). Все, что rotational, он автоматически помечает как HDD, не rotational — как SSD.
В примере используется виртуальная среда, здесь все диски виртуальные, они все rotational, то есть HDD.
Но даже если диски не определяются как SSD автоматически, можно руками снять класс HDD и назначить класс SSD.
В рамках эксперимента пометим как SSD по одному из дисков на каждом сервере.
Для этого надо удалить с них класс HDD, это можно делать сразу для многих дисков:
сeph osd crush rm-device-class osd.0 osd.2 osd.4
Класс HDD удалился. Обратите внимание: класс удалился, но репликация не запустилась. Это произошло, потому что в руте по умолчанию используется дефолтное правило, которое не учитывает классы. Все пулы, созданные по дефолтному crush-правилу, будут размещаться по HDD и SSD равномерно. Это важно учитывать.
После удаления класса HDD назначим класс SSD:
сeph osd crush set-device-class SSD osd.0 osd.2 osd.4
Вот результат:
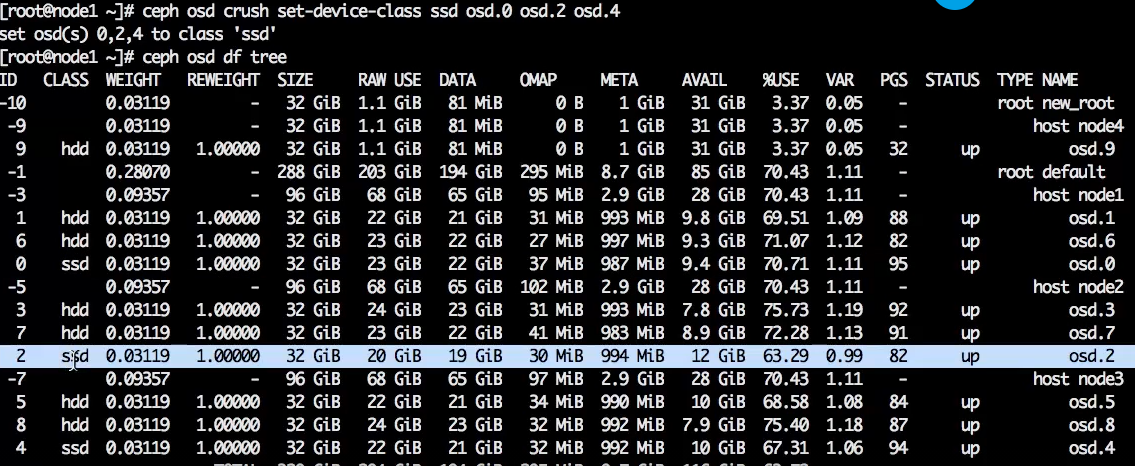
Назначенный класс останется даже после рестарта OSD.
Устройства с классом SSD созданы. Теперь переходим к правилам. Все правила можно посмотреть командой:
ceph osd crush rule ls

replicated_rule — дефолтное правило.
new_root_rule — правило для другого root, созданное нами.
Cоздадим новое специальное правило, в котором скажем использовать SSD. Команда та же, что и при создании обычного правила, только вместо create-simple поставим create-replicated.
ceph osd crush rule create-replicated replicated_SSD default host ssd
replicated_ssd — имя правила.
default — имя root’а.
host — тип репликации (репликация по хостам).
ssd — класс устройств (SSD или HDD).
Вот как выглядит созданное правило.

О применении правил поговорим чуть позже, сначала разберёмся с erasure-coding.
Создание erasure-code профиля
Для erasure coding все немного иначе. Создается не CRUSH-правило, а erasure code профиль. Синтаксис немного другой, но принцип тот же.
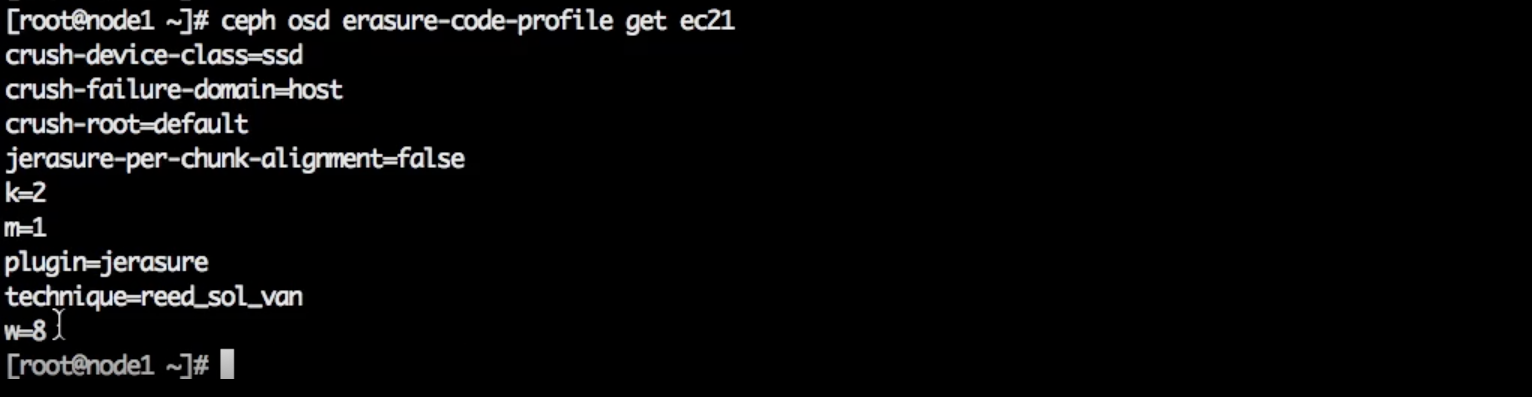
ceph osd erasure-code-profile set ec21 k=2 m=1 crush-failure-domain=host crush-device-class=SSD
ec21 — имя.
host — по какому уровню реплицировать дерево.
SSD — класс устройств.
Нужно задать уровень CRUSH-дерева для репликации данных и класс устройства. В результате получается:
- правило, по которому в CRUSH будут размещаться данные,
- профиль erasure-coding, который потом можно использовать для создания erasure-coding пула.
При создании replicated пулов указывают crush rule, которое описывает топологию репликации и устройство. При создании erasure-coding пула указывают профиль, который в принципе является тем же самым, только в нём ещё заданы “k” и “m”.
Посмотреть созданное правило:
ceph osd erasure-code-profile get ec21
Создать пул:
ceph osd pool create ec1 16 erasure ec21
Таким образом создан новый erasure-code профиль с размещением на SSD и новый пул, который будет использовать этот профиль.
Применение правил для replicated пулов
Переназначим CRUSH-правило для конкретного пула.
Среди пулов (просмотреть список можно с помощью ceph df) есть пул с метаданными файловой системы и rgw.meta, который нужно разместить на SSD.
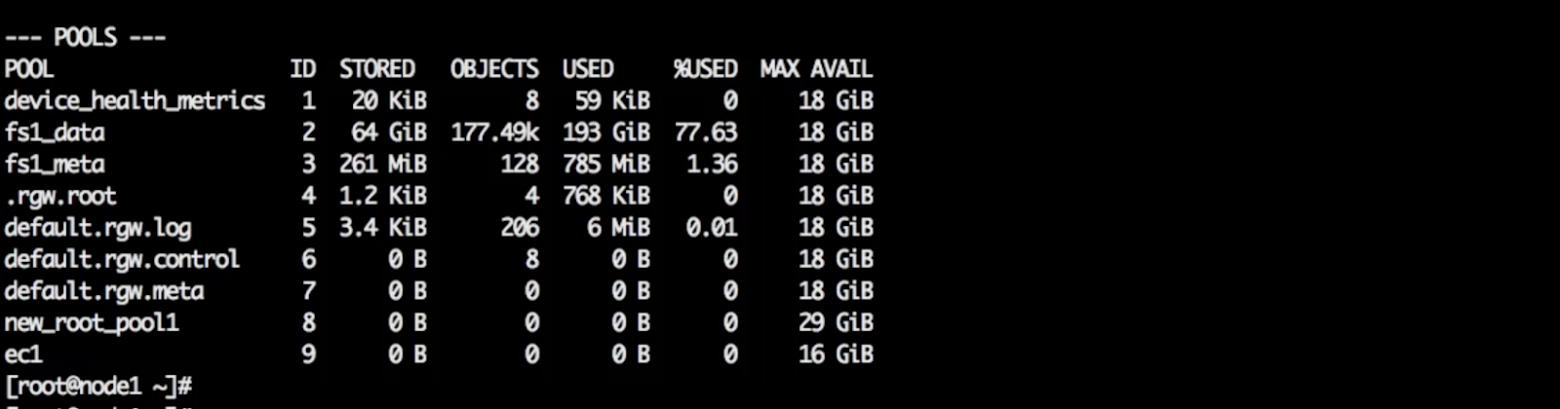
Команда для размещения пулов на SSD:
ceph osd pool set fs1_meta crush_rule replicated_SSD
fs1_meta — название пула.
replicated_SSD — название правила.
После выполнения команды запускается rebalance: те два пула, которым был назначен новый профиль, полностью переезжают на SSD.
Важно: дефолтное правило позволяет остальным пулам аллоцироваться и на SSD, и на HDD. Поэтому на SSD будут placement groups в том числе тех пулов, которые должны быть на магнитных дисках. Их нужно переместить на соответствующие устройства, применив правило для HDD. Опять же, если делать это на этапе, когда в кластере много данных, то случится большой rebalance.
Переместим на HDD несколько пулов:
ceph osd pool set device_health_metrics crush_rule replicated_hdd ceph osd pool set .rgw.root crush_rule replicated_SSD ceph osd pool set default.rgw.log crush_rule replicated_hdd
Как удалять правила
Для пример удалим дефолтное правило “replicated_rule”.
ceph osd crush rule rm replicated_rule
В нашем случае команда не сработала, так как правило используется — “is in use”.
Посмотреть, какой пул использует это правило:
ceph osd pool ls detail
В открывшемся списке надо найти параметр “crush_rule”.
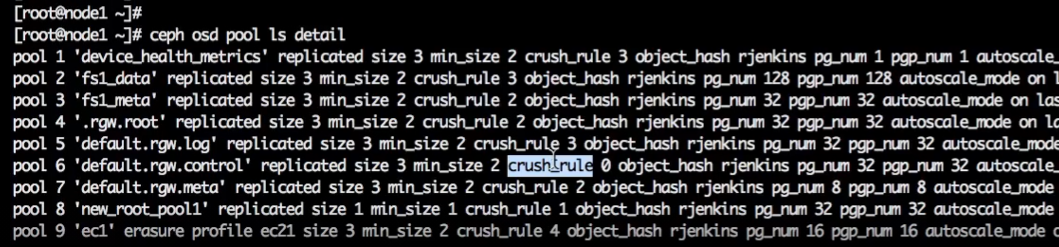
Нас интересует crush_rule 0 (т. к. дефолтное правило получает индекс 0). Находим, какой пул использует это правило, перемещаем его на другое правило:
ceph osd pool set default.rgw.control crush_rule replicated_hdd
Теперь можно удалить:
ceph osd crush rule rm replicated_rule
Готово!
Как проверить, что placement groups находятся на правильном классе устройств
У каждого пула есть идентификатор (колонка ID). Все placement groups конкретного пула начинаются с идентификатора этого пула. Например, ec1 мы создали на SSD.
ceph df
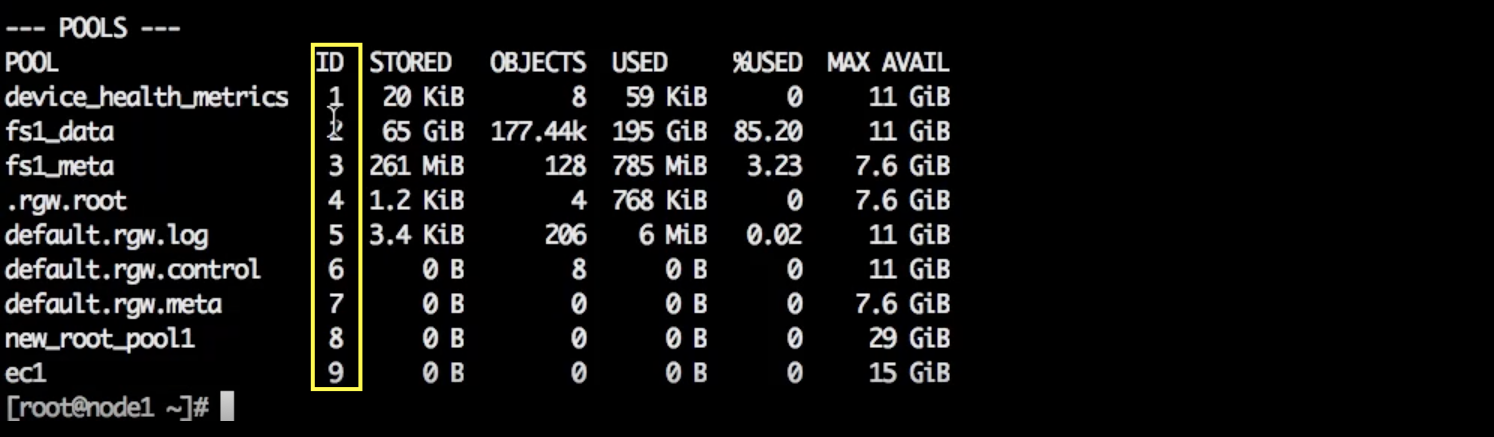
Посмотрим, на каких устройствах размещаются его placement groups. Ищем по идентификатору пула — 9.
ceph pg dump | grep ^9
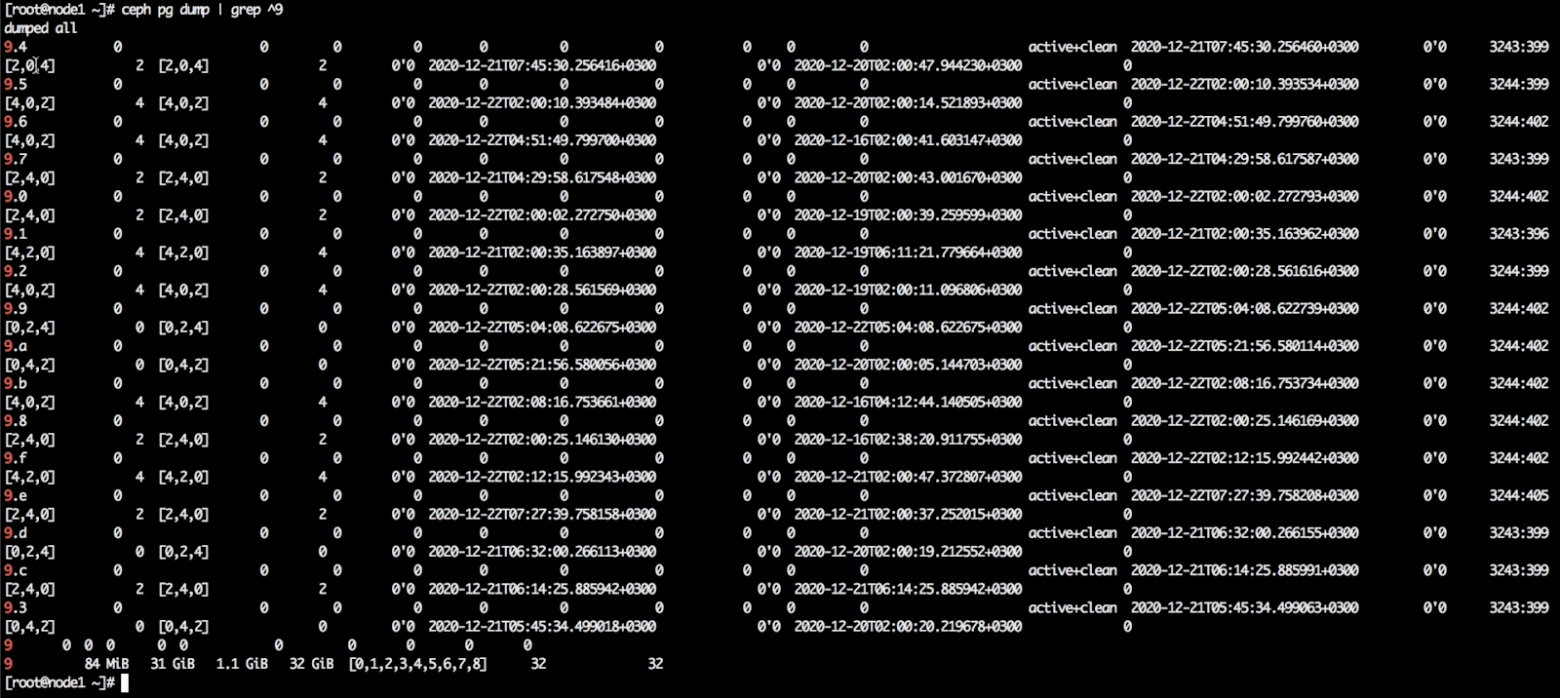
На скрине все placement groups пула ec1. Они находятся именно на тех трёх OSD, которые мы раньше специально пометили как SSD — 0, 2 и 4. То есть все данные находятся на правильном классе устройств.
Предыдущие материалы цикла статей по Ceph:
Флаги для управления состояниями OSD
Флаги для управления восстановлением и перемещением данных
Что такое Scrub и как им управлять

