Писать игровой AI очень интересно и увлекательно - не раз убеждался в этом на личном опыте. Недавно, случайно наткнувшись на код своего старого проекта шахматной программы, решил его немного доработать и выложить на GitHub. А заодно рассказать о том, как он создавался и какие уроки преподал мне в процессе работы.
Начало
Это случилось в 2009 году: я решил написать простую шахматную программу, чтобы попрактиковаться в разработке игрового AI. Сам я не шахматист и даже не сказать что любитель шахмат. Но задача для тренировки вполне подходящая и интересная. Кроме того, играя в шахматы на доске или в программе, мне всегда было любопытно, почему тот или иной ход сильнее другого. Хотелось возможности наглядно видеть всё дерево развития шахматной позиций. Такой фичи в других программах я не встречал - так почему бы не написать самому? Ну а раз уж это тренировка - то придумывать и писать нужно с нуля, а не изучать другие алгоритмы и писать их собственную реализацию. В общем, думаю, дня за три можно управиться и сделать какой-то рабочий вариант.
Первая версия
Обычно шахматные движки используют поиск в глубину с алгоритмом "ветвей и границ" для сужения поиска. Но это не очень-то наглядно, поэтому решено: мы пойдём своим путём - пусть это будет поиск в ширину на фиксированную глубину. Тогда в памяти будет полное дерево поиска, которое можно как-то визуализировать. А также выяснить: а) на какую глубину можно просчитать шахматную игру в рамках имеющихся ресурсов CPU и памяти, б) насколько хорошо или плохо будет играть такой алгоритм?
Надо сказать, что на тот момент у меня был 2-ядерный процессор с 2 или 4 Гб памяти (точно уже не помню), 32-битная винда и 32-битный компилятор Turbo Delphi Explorer. Так что если временем работы ещё можно было как-то пожертвовать, то доступная процессу память была ограничена 2Gb. Про PE flag, расширяющий user memory до 3Gb я тогда не знал. Впрочем, поскольку память кушают и система, и Delphi и другие программы - для шахмат, чтобы не уходить в своп, доступно менее гигабайта.
В результате получилась первая версия игры, состоящая из таких модулей:
UI - основное окно, отрисовка доски с фигурами.
Игровая логика - составление списка возможных ходов, выполнение хода, детекция завершения игры.
AI:оценка - оценочная функция позиции.
AI:перебор - поиск в ширину через очередь.
UI:браузер - окно визуализации дерева поиска, в котором можно наглядно изучать как всё работает.
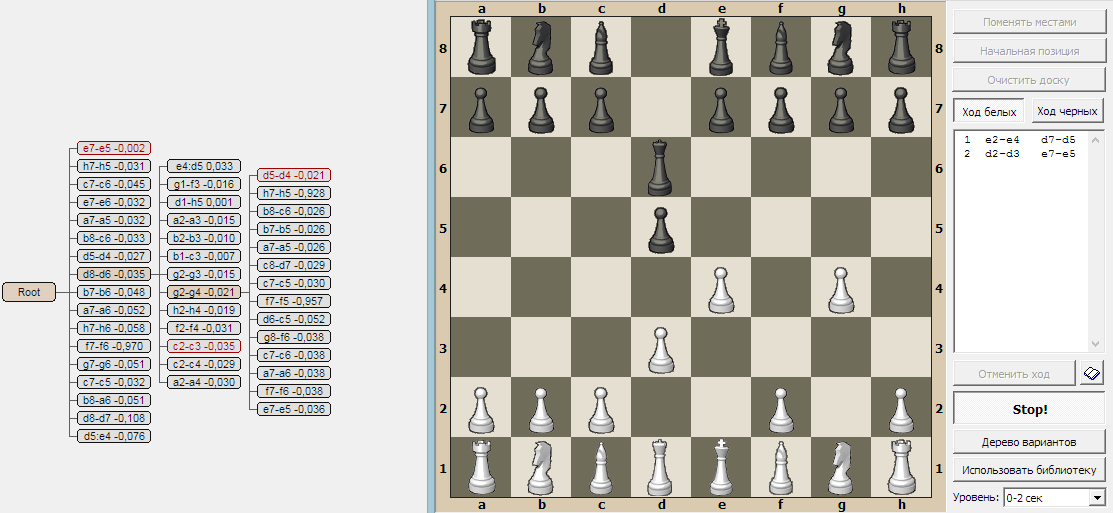
Выяснилось что:
Поиск на глубину 3 полухода работает быстро - меньше секунды, и расходует немного памяти - 5-15 Мб. А вот поиск на глубину 4 полухода работает уже довольно долго и расходует большую часть доступной памяти. В отдельных ситуациях памяти и вовсе не хватает.
При глубине поиска в 3 полухода уровень сложности - "младшая школа": компьютер вроде как-то играет, не позволяет "зевнуть" фигуру, не упускает возможность поставить "вилку". Но в то же время допускает грубые ошибки и легко попадается в ловушки. В общем, очень слабый соперник.
При любой глубине поиска, компьютер совершенно не умеет играть в эндшпиле и не понимает что делать, если у противника остался один король.
Таким образом, вырисовались направления дальнейшей работы: углубить поиск, научить позиционной игре а также научить играть в эндшпиле. И многие проблемы можно решить за счёт оценочной функции.
Оценочная функция
Функция оценки позиции - важнейший компонент любого шахматного движка. Где-то она предельно простая и быстрая - учитывает лишь количество фигур и их стоимость, а где-то - сложная и учитывает множество факторов. Поскольку в моём случае количество оцениваемых позиций ограничено объемом памяти, имеет смысл использовать сложную оценочную функцию и заложить в неё как можно больше факторов.
В итоге пришел к примерно такому алгоритму:
Для каждого игрока:
Подсчитать стоимость фигур: конь - 3, ладья - 5 и т.д. Начальная стоимость пешки - 1, но она растёт по мере её продвижения.
Бонус за сделанную рокировку, штраф за потерю возможности рокировки, штраф в миттельшпиле за невыведенные фигуры (коней и ладьи в углах). Штраф за сдвоенные пешки и бонус за захваченные открытые линии.
Определение какие поля находятся под боем и кем. Это медленная операция - основная часть времени выполнения оценочной функции тратится именно здесь. Зато польза от неё колоссальная! Незащищённая фигура под боем на ходу противника - минус фигура. Защищённая - минус разность стоимости фигур. Это позволяет получить эффект углубления поиска на 1-2 уровня.
Если остался один король: штраф за расстояние от центра доски и штраф за расстояние до короля противника. Такая формула в эндшпиле заставляет AI стремиться прижать короля противника к краю доски, т.е. получить позицию, из которой можно найти возможность поставить мат.
Итоговая оценка = (white_rate - black_rate) * (1 + 10 / (white_rate + black_rate)). Эта формула делает разницу более значимой в эндшпиле, заставляя отстающего игрока избегать размена фигур, а ведущего - наоборот, стремиться к размену.
Углубление поиска
Прежде всего, несмотря на доработку оценочной функции, углубление поиска необходимо для ходов со взятием а также шахов. Для этого добавлен новый атрибут узла - вес, который используется вместо глубины. Если дочерний узел порождается обычным ходом - его вес уменьшается на 1, если ходом со взятием - на 0.4, если ходом с шахом - не уменьшается вовсе. Узлы с положительным весом возвращаются в очередь поиска и получают продолжение.
Кроме того, нужно развивать наиболее перспективные направления - ветки с наибольшей оценкой.
В итоге алгоритм получился такой:
На первой стадии строится дерево с базовой глубиной 3 (при этом ветки со взятиями и шахами могут достигать заметно большей глубины).
Оценка дерева алгоритмом минимакс.
Если выполнены критерии принятия решения - выбирается ветка с наилучшей оценкой и алгоритм завершается.
Обрезка дерева: последовательно удаляются ветки с наихудшей оценкой пока не будет свободно достаточно памяти для продолжения поиска.
Переход к следующей стадии: добавляем вес всем листьям дерева и продолжаем поиск. После завершения переходим к п 2.
Критерии принятия решения:
Осталась единственная ветка - выбора нет.
Одна из веток имеет оценку существенно более высокую чем у остальных - выбираем её.
Истекло время на ход - выбираем ветку с наилучшей оценкой.
Кэширование
В процессе работы больше всего времени тратится на оценочную функцию. Но бывает, что в ходе поиска одни и те же позиции встречаются несколько раз: в одно и то же состояние можно прийти различными путями. Возникает мысль: почему бы не кэшировать результат оценочной функции?
Всё просто: нужно вычислить хэш от позиции и если в кэше уже есть оценка с таким хэшем - использовать её вместо вычисления. А если нет - вычислить и сохранить в кэше оценок. Основная проблема - нужна достаточно качественная и быстрая хэш-функция. После множества экспериментов получилось написать приемлемую функцию, вычисляющую 64-битный хэш. Общее количество возможных шахматных позиций значительно больше 264, но количество позиций, оцениваемых в ходе партии значительно меньше 232, поэтому более-менее качественная хэш-функция должна свести вероятность хэш-коллизий к минимуму.
Процент "попаданий" в кэш в ходе игры получился в районе 30-45%, но в эндшпиле достигает 80-90%, что даёт ускорение почти в 5-10 раз, а следовательно позволяет увеличить глубину поиска. Неплохой выигрыш!
Что получилось?
Я добавил библиотеку дебютов, и в таком состоянии программа играла уже довольно неплохо - примерно на уровне 2-го разряда, а может и чуть сильнее. Результат, в принципе, достойный - можно остановиться. Хотя были вполне очевидны недостатки и направления развития:
AI работает в один поток - ресурс CPU задействован не полностью.
А что если предоставить больше памяти?
AI думает только во время своего хода. Почему бы не использовать время соперника для просчёта наиболее вероятных продолжений?
Главная слабость: детерминированность. Каждый ход рассматривается как отдельная задача, каждая позиция приводит к детерминированному решению. Достаточно выиграть один раз, чтобы запомнить последовательность ходов, которая всегда приведёт к победе. А играть с таким соперником неинтересно.
Однако, к этому времени код проекта уже достаточно "замусорился" и требовал рефакторинга. Поскольку на него и так уже было потрачено много времени, я решил его забросить.
Дальнейшее развитие
Недавно наткнувшись на этот заброшенный проект, решил всё-таки привести его код в порядок и доработать. Доработки сделал такие:
Многопоточность: сейчас у меня уже 8-поточный, а не 2-поточный CPU, поэтому многопоточный вариант даёт серьёзную прибавку в скорости.
64-битный режим: кроме возможности использовать больше памяти, было любопытно, будет ли алгоритм работать быстрее на архитектуре x64. Как ни странно, оказалось что нет! Хотя отдельные функции на x64 работают быстрее, в целом версия x86 оказалась на 5-10% быстрее. Возможно 64-битный компилятор Delphi не очень хорош, не знаю.
Больше памяти: даже в 32-битном режиме за счёт PE-флага расширения адресного пространства доступной памяти стало больше. Однако практика показала, что больше 1 Гб памяти все-равно не нужно - разве что для хранения "обрезанных" ветвей дерева. К усилению игры увеличение памяти не приводит.
Непрерывность поиска: теперь дерево поиска не создаётся с нуля каждый ход, а создаётся лишь в начале партии. Когда делается ход - неактуальные ветви дерева обрезаются а поиск продолжается с того состояния, которое было. В том числе и во время хода соперника - идёт проработка перспективных продолжений, поэтому когда соперник сделает ход, поиск продолжится не с нуля. Быть может и вовсе получится сразу же сделать ход. Момент времени, когда игрок сделает ход - это фактор случайности, который делает игру недетерминированной. Теперь уже нельзя запомнить выигрышную последовательность ходов.
Оценка дерева. Ввёл новый атрибут узла - качество оценки. Качество равно сумме качества всех прямых потомков, умноженное на коэффициент затухания. Т.е. качество оценки показывает проработанность ветки.
Углубление поиска. Качество оценки вместе с самой оценкой учитывается при выборе веток для углубления поиска. Чем выше оценка и чем ниже её качество - тем выше приоритет такой ветки для её развития. Потому что мало смысла до посинения развивать и так хорошо проработанную ветку с максимальной оценкой, которая уже вряд ли существенно изменится, когда она сравнивается со слабо проработанными ветками, чья оценка может значительно измениться.
База оценок и самообучение. В процессе игры какие-то позиции детально прорабатываются и получают оценку с высоким качеством. Почему бы не сохранять такие оценки для использования в других партиях? Это ещё одна фича, которая делает игру недетерминированной.
В результате этих доработок AI стал сильнее, и вполне уверенно обыгрывает старую версию игры. Я провел несколько партий против AI на chess.com и выяснил, что уровень моей программы примерно соответствует рейтингу 1800-1900. Прогресс есть, и это хорошо!
Программирование игрового AI - занятие чертовски затягивающее: всегда хочется добиться большего. И хотя у меня по прежнему есть масса идей для дальнейшего развития, наступает момент, когда надо остановиться. Думаю, он наступил. Однако если кто-либо желает - может взять мой код, побаловаться, поэкспериментировать, что-нибудь реализовать. Благо, сейчас Delphi доступен каждому благодаря бесплатной Community Edition, не говоря уже про бесплатный Free Pascal и Lazarus. Код проекта (а также скомпилированный exe-шник) можно взять тут (для компиляции понадобится также кое что из https://github.com/Cooler2/ApusGameEngine). Спасибо всем, кто дочитал.

