
К старту курса о машинном и глубоком обучении делимся переводом статьи, автор которой показывает на практике, как модель машинного обучения может использоваться через Excel. Зачем это нужно? Компании больше и больше вкладывают в исследования и разработку моделей прогнозов; по мнению автора оригинала статьи, разработчика и основателя компании PyXLL доступ к ML-моделям через Excel открывает новые горизонты. Вы сможете показать модель пользователям Excel, у которых нет опыта программирования или широких знаний в области статистики. При желании можно создавать инструменты разработки и тренировки моделей полностью в Excel, например строить графы в TensorFlow. Весь исходный код из статьи доступен на GitHub.
Надстройка Excel PyXLL встраивает Python в Excel и позволяет расширять возможности Excel через Python. С помощью этой надстройки мы можем добавлять новые функции, макросы, меню и в целом перенести преимущества экосистемы Python и машинное обучение прямо в Excel. К концу статьи мы построим модель классификации животных.
Python для Machine Learning
Python хорошо подходит для машинного обучения, у него большой массив поддерживаемых пакетов, упрощающих программирование и сокращающих время разработки. ML и DL очень хорошо поддерживаются несколькими пакетами, поэтому Python — идеальный выбор. Посмотрим на распространённые пакеты для ML на Python.
Scikit-Learn
Пакет scikit-learn — это лаконичный и последовательный интерфейс к общим алгоритмам ML, упрощая введение ML в производственные системы. Библиотека сочетает высокую производительность, де-факто она отраслевой стандарт машинного обучения на Python. В статье мы будем работать именно с ней.
TensorFlow
TensorFlow от Google. Эта библиотека с открытым исходным кодом для расчёта графов потоков данных оптимизирована для целей ML. Она была разработана, чтобы удовлетворять высоким требованиям обучения нейронных сетей в среде Google и является преемницей DistBelief — основанной на нейронных сетях системы глубокого обучения, применяется в пограничных областях исследований Google.
Впрочем, TensorFlow не строго научна и достаточно обобщена, чтобы применяться в различных прикладных задачах. Ключевая особенность TensorFlow — многослойная система узлов, которая быстро тренирует сети искусственного интеллекта на больших наборах данных. В Google это даёт возможность распознавать голос и находить объекты на изображениях.
Keras
Keras — написанная на Python Open Source библиотека для нейронных сетей. Она способна работать поверх TensorFlow, Microsoft Cognitive Toolkit или Theano и имеет архитектуру, которая позволяет быстро проводить эксперименты с глубоким обучением и сосредоточена на модульности, расширяемости и удобстве пользователя. Из документации следует, что работать с Keras можно, когда вам нужна библиотека глубокого обучения, которая:
Обладая перечисленными выше преимуществами, позволяет просто и быстро прототипировать решения.
Поддерживает свёрточные и рекуррентные нейронные сети, а также их комбинирование.
Без проблем работает на CPU и GPU.
PyTorch
PyTorch — это научный вычислительный пакет на Python, он работает в двух направлениях:
Как замена NumPy с возможностью задействовать графические процессоры.
Как платформа исследования Deep Learning с максимумом гибкости и скорости.
Деревья решений
Деревья решений — техника машинного обучения для решения задач регрессии и классификации. Дерево делит набор данных на множество наборов по признакам так, что одно дерево владеет одним подмножеством данных. Конечные узлы дерева — листья — содержат прогнозы и используются в новых запросах к натренированной модели. Пример ниже поможет понять, как это работает. Предположим, мы имеем набор данных со множеством признаков животных: млекопитающих, птиц, рептилий, насекомых, моллюсков и амфибий. Интуитивно разделить этот набор можно так:
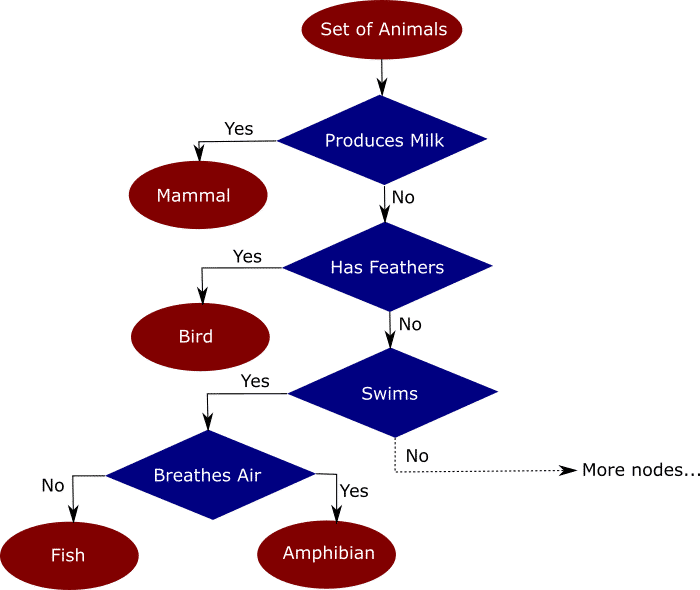
Распределение данных по деревьям на основе признака упрощает классификацию новых данных, точность которой зависит от того, насколько точно деревья отражают действительность. В незаконченное дерево на рисунке выше я заложил мои знания и интуитивные представления о животных. Модель выясняет, как распределить признаки по новым данным — это и называется машинным обучением.
Алгоритм быстро анализирует большой объём данных, чего вручную сделать невозможно. В работе деревьев решений множество аспектов, от математики до логики их построения. Мы не будем касаться этих деталей, но построим модель и я покажу, как работать с ней в Excel.
Тренировка модели
Натренируем модель классифицировать животных при помощи деревьев решений. Воспользуемся для этого набором данных UCI Zoo Data Set из 101 животного, в наборе 17 логических признаков и один признак, который мы будем прогнозировать.
Для загрузки данных воспользуемся pandas, а для построения дерева — scikit-learn. Загрузим данные во фрейм Pandas, разделим на признаки и целевой класс, то есть класс животного. Затем разделим данные на тренировочный и тестовый наборы. Scikit-Learn использует тренировочный набор для обучения деревьев, а тестовый резервируется для проверки точности модели.
from sklearn.tree import DecisionTreeClassifier from sklearn.model_selection import train_test_split import pandas as pd # Read the input csv file dataset = pd.read_csv("zoo.csv") # Drop the animal names since this is not a good feature to split the data on dataset = dataset.drop("animal_name", axis=1) # Split the data into features and target features = dataset.drop("class", axis=1) targets = dataset["class"] # Split the data into a training and a testing set train_features, test_features, train_targets, test_targets = \ train_test_split(features, targets, train_size=0.75)
Начинается самое интересное: при помощи классификатора дерева решений в scikit-learn обучим модель на тренировочных данных. Чтобы модель не переобучилась и могла работать, настроим несколько параметров. Максимальная глубина дерева будет равна 5. Поэкспериментируйте со значениями, чтобы увидеть влияние глубины на результаты.
# Train the model tree = DecisionTreeClassifier(criterion="entropy", max_depth=5) tree = tree.fit(train_features, train_targets)
Эти две строки строят и обучают модель. Чтобы проверить её точность, подадим на вход данные, которых она не видела.
# Predict the classes of new, unseen data prediction = tree.predict(test_features) # Check the accuracy score = tree.score(test_features, test_targets) print("The prediction accuracy is: {:0.2f}%".format(score * 100))
Воспользуемся моделью и выполним прогноз на новых данных:
# Try predicting based on some features features = { "hair": 0, "feathers": 1, "eggs": 1, "milk": 0, "airbone": 1, "aquatic": 0, "predator": 0, "toothed": 1, "backbone": 1, "breathes": 1, "venomous": 0, "fins": 0, "legs": 1, "tail": 1, "domestic": 0, "catsize": 0 } features = pd.DataFrame([features], columns=train_features.columns) prediction = tree.predict(features)[0] print("Best guess is {}".format(prediction])
Вызовем модель из Excel
Теперь загрузим модель в Excel, который хорошо подходит для интерактивных данных. Он работает почти везде, вы сможете показать модель незнакомым с разработкой людям, это даёт массу преимуществ в бизнесе, особенно когда модель применяется как часть пакетной системы или системы реального времени. Возможность вызывать модель интерактивно может оказаться по-настоящему полезной, когда нужно понять поведение системы.
К счастью, наша модель написана на Python и перенести её в Excel просто. В PyXLL есть всё необходимое, чтобы писать на Python в Excel. Нужно только добавить несколько декораторов @xl_func из модуля pyxll и настроить надстройку PyXLL для загрузки модуля с моделью. Если вы не знакомы с PyXLL, посмотрите введение в PyXLL в руководстве пользователя.
Построим дерево решений
Начнём с функции. Пользователь вызовет её, чтобы получить объект дерева, а затем этот объект для прогнозирования пройдёт через последовательность функций. Снова построим дерево, но пример будет сложнее: сохраним натренированную при помощи pickle и затем вместо того, чтобы каждый раз её создавать, загрузим её в Excel и настроим параметры, это будет интересно!
from pyxll import xl_func from sklearn.tree import DecisionTreeClassifier from sklearn.model_selection import train_test_split import pandas as pd import os @xl_func("float, int, int: object") def ml_get_zoo_tree(train_size=0.75, max_depth=5, random_state=245245): # Load the zoo data dataset = pd.read_csv(os.path.join(os.path.dirname(__file__), "zoo.csv")) # Drop the animal names since this is not a good feature to split the data on dataset = dataset.drop("animal_name", axis=1) # Split the data into a training and a testing set features = dataset.drop("class", axis=1) targets = dataset["class"] train_features, test_features, train_targets, test_targets = \ train_test_split(features, targets, train_size=train_size, random_state=random_state) # Train the model tree = DecisionTreeClassifier(criterion="entropy", max_depth=max_depth) tree = tree.fit(train_features, train_targets) # Add the feature names to the tree for use in predict function tree._feature_names = features.columns return tree
Код выше совпадает с кодом, который мы видели ранее, за исключением декоратора @xl_func, который сообщает дополнению PyXLL о том, какая функция Python должна стать пользовательской функцией Excel.
Строка float, int, int: object — это сигнатура функции. Она необязательна, но без этой сигнатуры пользователь сможет передавать в функцию свои типы, например, строки и это может привести к сбою. Возвращаемый тип object означает, что классификатор идёт через Excel как объект Python, функция возвращает дескриптор, который возможно передать другим функциям Python.
Код нужно добавить в список модулей конфигурационного файла pyxll.cfg, также необходима надстройка PyXLL, если вы не установили её.
Все аргументы функции имеют значение по умолчанию, поэтому необязательны, но при желании со входными данными можно экспериментировать.
Прогнозируем класс животного
Теперь всё, что нужно для работы с моделью — ещё одна функция для передачи входных данных и получения прогноза. Используем тот же код, что и раньше, но обернём его декоратором @xl_func.
_zoo_classifications = { 1: "mammal", 2: "bird", 3: "reptile", 4: "fish", 5: "amphibian", 6: "insect", 7: "mollusc" } @xl_func("object tree, dict features: var") def ml_zoo_predict(tree, features): # Convert the features dictionary into a DataFrame with a single row features = pd.DataFrame([features], columns=tree._feature_names) # Get the prediction from the model prediction = tree.predict(features)[0] return _zoo_classifications[prediction]
Модель возвращает целое число — спрогнозированный класс. Словарь _zoo_classifications содержит эти числа и понятные человеку названия классов.
Эта функция берёт объект дерева из ml_get_zoo_tree и список пар ключ-значение, переданных в неё как словарь. В словаре сопоставлены имена признаков, с которыми мы работали при конструировании дерева, и входные признаки. Их сопоставление таково, что при вызове tree.predict признаки упорядочены правильно.
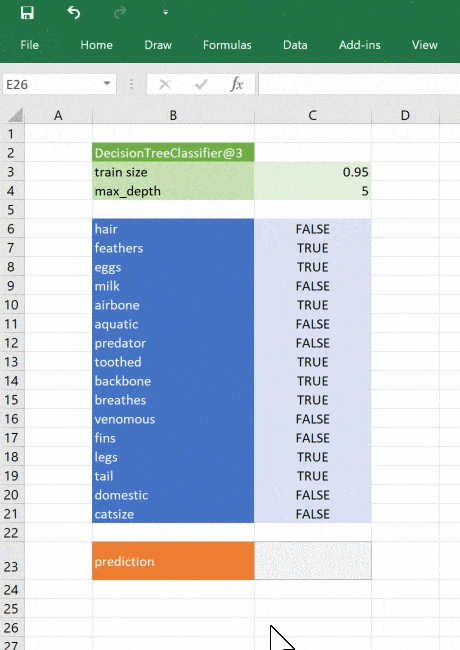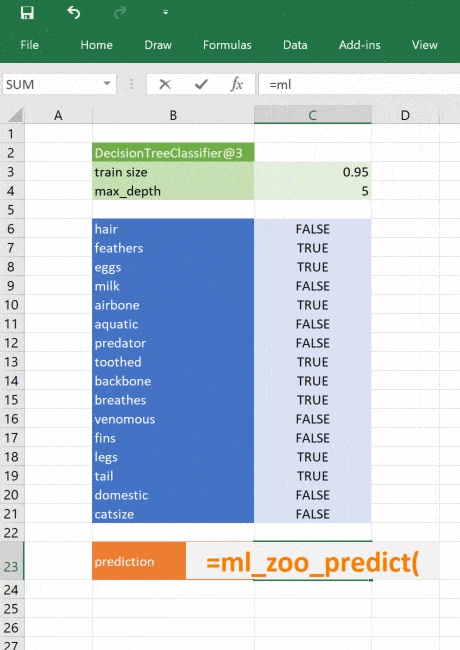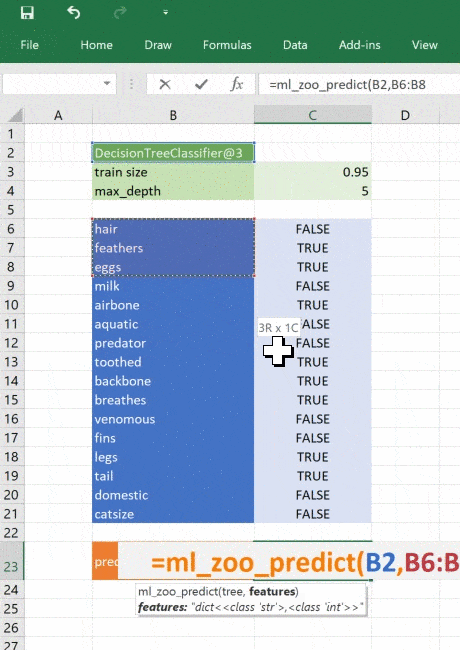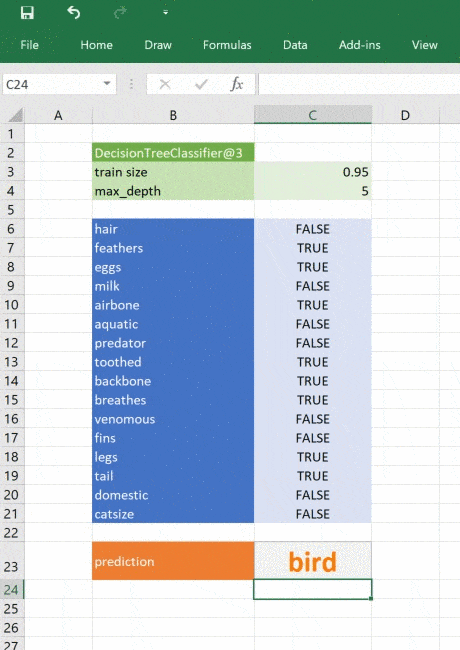
Это простой пример, натренированный на минимуме данных, но принцип применим к любой сложной модели. При помощи Python вы можете исследовать, разрабатывать и строить модель, чтобы получить ценные инсайты и быстрые прогнозы на реальных данных.
Небольшое дополнение
Чёрно-белые листы с цифрами нравятся всем, но иногда мне нравится добавлять небольшие детали ради привлекательности таблицы. PyXLL позволяет получить доступ к объектной модели Excel с помощью функции xl_app. Объектная модель Excel точно совпадает с той, что применяется в VBA. Функция ниже создаёт на листе объект изображения и загружает его.
from pyxll import xl_app def show_image_in_excel(classification, figname="prediction_image"): """Plot a figure in Excel""" # Show the figure in Excel as a Picture object on the same sheet # the function is being called from. xl = xl_app() sheet = xl.ActiveSheet # if a picture with the same figname already exists then get the position # and size from the old picture and delete it. for old_picture in sheet.Pictures(): if old_picture.Name == figname: height = old_picture.Height width = old_picture.Width top = old_picture.Top left = old_picture.Left old_picture.Delete() break else: # otherwise create a new image top_left = sheet.Cells(1, 1) top = top_left.Top left = top_left.Left width, height = 100, 100 # insert the picture filename = os.path.join(os.path.dirname(__file__), "images", _zoo_classifications[classification] + ".jpg") picture = sheet.Shapes.AddPicture(Filename=filename, LinkToFile=0, # msoFalse SaveWithDocument=-1, # msoTrue Left=left, Top=top, Width=width, Height=height) # set the name of the new picture so we can find it next time picture.Name = figname
Вызов ml_zoo_predict обновляет изображение в Excel при каждом изменении прогноза. Функция обновляет Excel, поэтому вызывать её нужно после вычислений, именно этим занимается async_call из pyxll, а ниже вы видите новую версию ml_zoo_predict:
from pyxll import xl_func, async_call @xl_func("object tree, dict features: var") def ml_zoo_predict(tree, features): # Convert the features dictionary into a DataFrame with a single row features = pd.DataFrame([features], columns=tree._feature_names) # Get the prediction from the model prediction = tree.predict(features)[0] # Update the image in Excel async_call(show_image_in_excel, prediction) return _zoo_classifications[prediction]
Изображение обновляется при изменении прогноза:
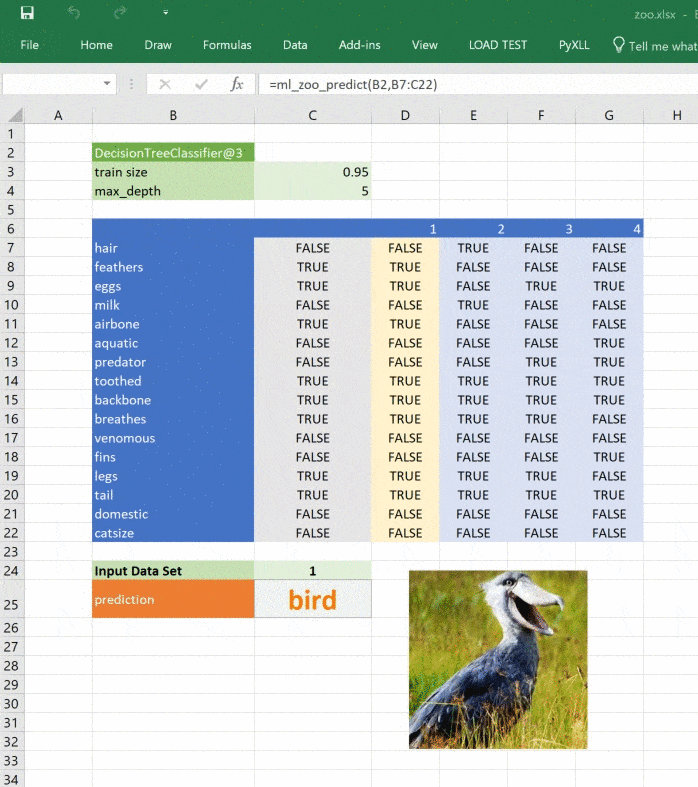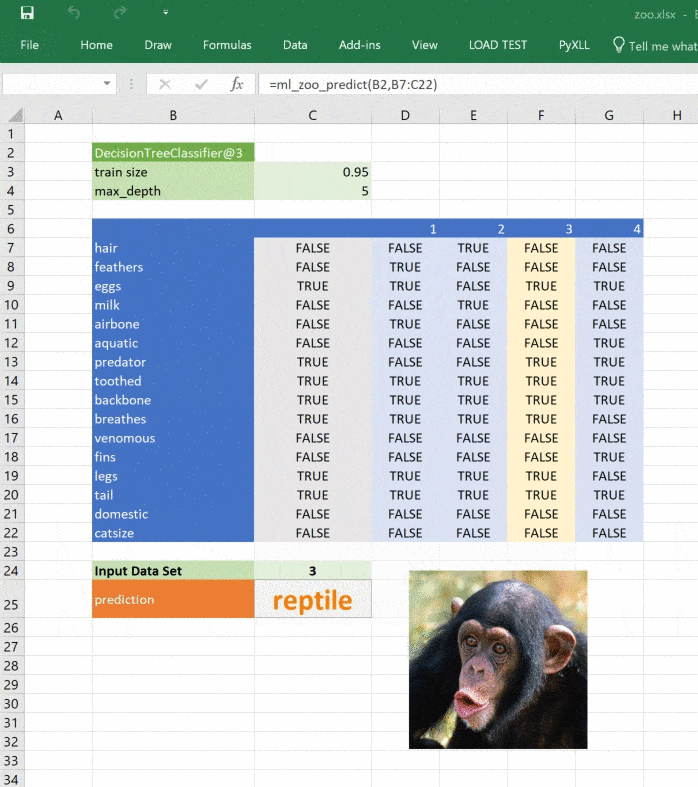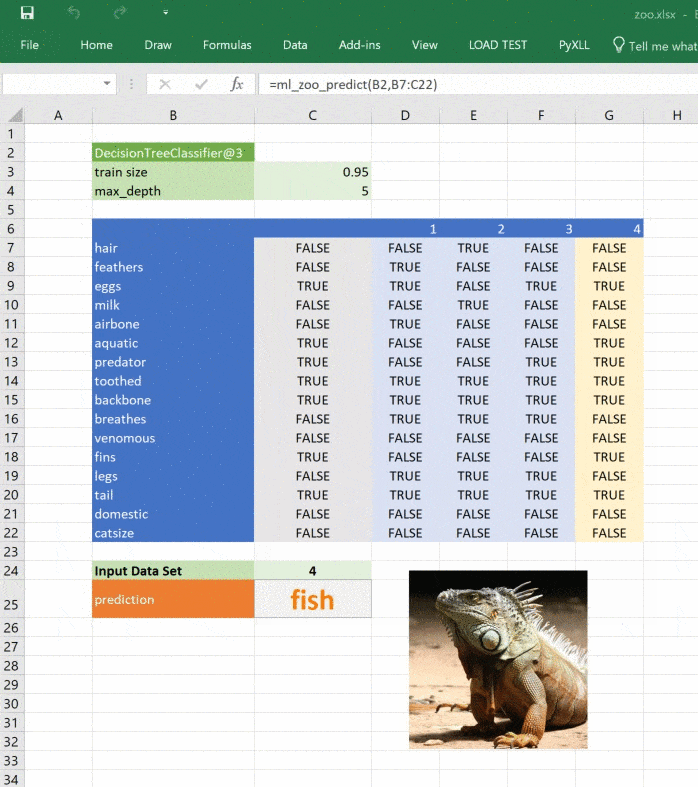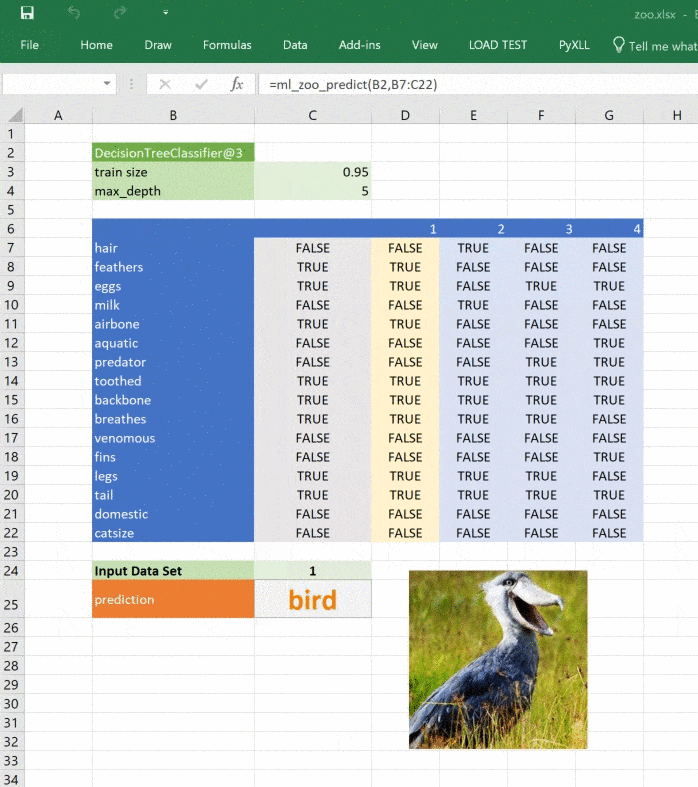
Ссылки
Этот материал — яркое напоминание о том, что Excel может справляться с задачами машинного обучения, а область ML сложна, но её сложность преодолима и если вы хотите изменить карьеру или вывести ваши навыки на новый уровень, то можете обратить внимание на наши курсы по Machine Learning, аналитике данных или присмотреться к флагманскому курсу Data Science. Также вы можете узнать, как начать или продолжить развитие в других направлениях:

Data Science и Machine Learning
Python, веб-разработка
Мобильная разработка
Java и C#
От основ — в глубину
А также:

