Введение
Решил портировать одну старую давно забытую игрушку с DOS на современную платформу. Эта игра, в своё время, привлекала ураганным геймплеем, неплохой разрушаемостью, возможностью включить всё оружие одновременно и устроить настоящий бедлам. В 2021 году играть в такое всё ещё интересно, но делать это в родном разрешении 640х480, как-то не очень. Поэтому решил портировать игру и накатить хай-рез патч. Получилось!
Хочу сразу предупредить тех, кто подумает: "Сейчас кучу игр портирую, прочитав эту статью". Как говорится, не верь всему, что пишут на Хабре. Процесс реверса — это как процесс программирования, только, на мой взгляд, муторнее и дольше.
Портирование игр требует некоторых специфических знаний. Вы должны знать ассемблер, устройство .exe файла и какой-нибудь более высокоуровневый язык программирования, например C или C++ (или другой) хотя бы на среднем уровне и немного уметь работать с IDA. Этих вопросов я касаться не буду.
Если вы всё-таки решили портировать какую-то старую игрушку, или просто получить её исходники, советую выбирать самую-самую ностальгическую и интересную.
По умолчанию, в статье под операционной системой будет пониматься Windows.
План действия
У меня был какой-то план и я его придерживался:
Добыть дизассемблер
Открыть им экзешник
Разобрать, что делают все неизвестные функции, ну или как можно больше их
Параллельно дать всем переменным удобоваримые названия
Набраться терпения. Процесс разбора очень долгий
Создать ассемблерный файл с исходным кодом
Создать проект в %your_favorite_ide%, подключить ассемблерный файл и поправить его, чтобы он скомпилировался
Доработать ассемблерные инструкции на ваш вкус, чтобы запустить приложение, если исходники от Windows версии
Написать какой-то код на %your_favourite_language%, чтобы заменить ими ассемблерные DOS процедуры вывода на экран, прослушивания звука, инициализации окна и т.п.
В идеале все процедуры можно переписать и удалить ассемблерный файл
Наверное это самый быстрый путь, чтобы получить рабочий код, не переписывая его полностью. Пусть и на ассемблере.
Кстати, я пробовал по-другому. После разбора всех ассемблерных процедур, пытался переписать на языке высокого уровня, а также пытался написать саму игру с нуля, но быстро понял, что это займёт минимум несколько лет, которых я потратить не могу.
Также этот план подходит, чтобы получить исходники Windows приложения (начиная от версии Windows 95 и заканчивая Windows 10), хотя это может противоречить лицензии на использование этого приложения, следует иметь это в виду.
Немного подробнее по каждому пункту плана я напишу ниже.
1. Добыть дизассемблер
В наше время есть несколько мастодонтов дизассемблирования, это IDA и Ghidra и ещё какие-то. На мой взгляд, IDA пока выдаёт лучшее качество дизассемблированного кода, у неё лучше работает перевод ассемблерного кода в псевдокод, она лучше поддерживает старые библиотечные DOS функции.
Существует бесплатная версия IDA free, но она работает не совсем стабильно. У меня как-то пропала многочасовая работа по реверсу, версия free загубила свой файл проекта. Pro очень дорогая, но для разового проекта, как этот, я гонял IDA у друга, чего и вам советую.
2. Открыть экзешник
Во времена DOS существовало несколько форматов запускаемого файла. Точнее, формат запускаемых файлов постепенно развивался от самых ранних 16 битных, с расширением com, до более поздних .exe файлов с 32 битным расширителем.
Как правило, экзешники внутри упорядочены по своей структуре, с самого начала идёт заголовок(и), затем последовательность может быть разная: код, инициализированные данные, и неинициализированные данные, таблица импорта, которой может не быть (только если вы хотите открыть программу под Windows). Нам понадобятся код и данные. Таблицу импорта придётся всю вырезать и заменить её include-ми.
Если у вас экзешник от Windows версии (например плохо работающий на современных системах экзешник от Windows 95), то вам считайте повезло. Будет сравнительно легко получить запускаемый исходный код, а что самое главное, ещё и быстро. Если от DOS с использованием 32 битного расширителя, т.е. с dos4g, dos4gw расширителями, то вам полуповезло. Если от 16 битного DOS приложения, то лучше про IDA забыть и написать всё с нуля, может быть только посмотреть как распаковываются ресурсы в коде.
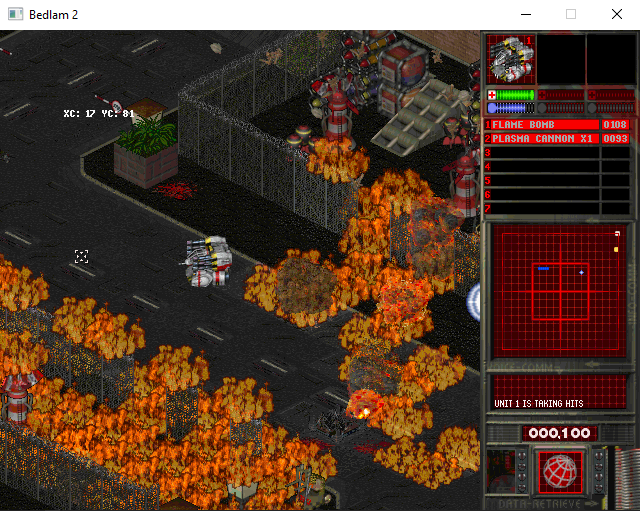
Я взял экзешник от DOS игры Bedlam 2: Absolute Bedlam. Эта игра необоснованно забыта, должна была выпускаться тем же издателем, который выпустил в своё время DOOM и Duke Nukem 3D и была очень качественной. Но, в итоге, что-то пошло не так и официального релиза не было. Игра была слита недоделанной с отсутствующими уровнями, кривым балансом, некоторыми багами и отладочной информацией для левел-дизайнеров. Также, не случился релиз версии для Windows 95, который уже был годом ранее для предыдущей, первой части Bedlam.
К сожалению, не весь софт можно дизассемблировать по этическим и лицензионным причинам. Сейчас Bedlam 2 относится к так называемому ПО abandonware, забытому программному обеспечению, которое не поддерживается разработчиками, которых сейчас уже, возможно, и нет в живых. Фирма разработчик Mirage Technologies и издатель GT Interactive уже не существуют, а игру невозможно купить. Лицензия на серию Bedlam, скорее всего ещё кому-то принадлежит, я даже догадываюсь кому, но не буду их сюда призывать.
Поскольку лицензионного соглашения игры Bedlam 2 я не нашел, а на заставке игры не запрещается игру дизассемблировать, то погнали. Экзешник собран 29.10.1997г., чуть менее 25 лет назад. Тогда очень редко кто заморачивался упаковкой и обфускацией кода для защиты от дизассемблинга. Но можно проверить.

DiE показывает, что это MSDOS LE экзешник, собранный компилятором Watcom C. Никаких упаковщиков применено не было.
Собственно, мне повезло, это оказалось 32 битное приложение с применением 32 битного расширителя dos4gw. Ещё один признак, указывающий на это, это наличие dos4gw.exe в папке с игрой.
Отлично, теперь нужно открыть BEDLAM.EXE в IDA, чтобы она определила и подсветила все известные ей библиотечные функции, а также, работал псевдокод. Запускаем IDA, жмём New, выбираем .exe файл, ставим такие настройки.

IDA должна выдать что-то типа того. Она сама определила main функцию, определила все известные ей библиотечные функции и выделила их синим цветом. Псевдокод работает (клавиша F5).

Если у вас не так и нет библиотечных функций. Вероятно, стоит попробовать открыть файл с другими настройками, например как MS-DOS executable или выбрать другой тип процессора, например 486й. Бывает так, что библиотечных функций вообще нет, поскольку DOS программа пишется на основе прерываний — своих встроенных функций. Благо IDA умеет их помечать.
Если не работает псевдокод. К сожалению, он работает только в 32 битных приложениях, но есть и лайфхак. Открыть файл как 16 битное приложение MS-DOS executable, а затем в сегментах (Shift-F7) выставить сегмент кода как 32 битный. Уж не знаю какое будет качество псевдокода, не проверял. Но это работает, если приложение точно написано с 32 битным расширителем, но по каким-то причинам помечается как 16 битное.
3. Разбор функций
В списке функций, в IDA, очень много непонятных процедур SUB_xxxxxx, где xxxxxx — просто смещение. Необходимо разобраться, что они делают и дать им удобоваримые названия. В будущем это очень поможет с правкой исходников.
Советую весь разбор вести в псевдокоде. Так проще. Если из него изменять имена глобальных переменных и имена функций, то они автоматически изменятся и в ассемблерном листинге. Псевдокод хоть и удобен, но это лишь инструмент, поэтому в ассемблерный листинг придётся частенько заглядывать.
Есть несколько техник, как определить, что делает процедура (ну или функция, кому как нравится). Можно найти все строковые переменные, посмотреть, откуда они вызываются и что с ними делается. Как правило они расположены в сегменте инициализированных данных, придется их просто поискать.
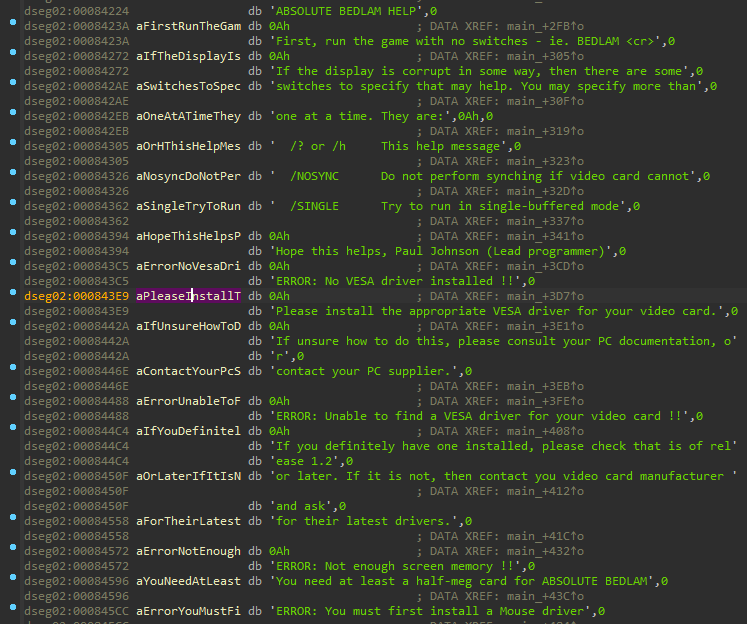
Например, на рисунке выше показаны описания ошибок инициализации видео и мыши. Стоит просто лишь выделить название строковой переменной (выделено фиолетовым цветом на рисунке, IDA их автоматически создаёт) и нажать X, IDA выведет все ссылки, где используется эта строковая переменная.
Также, следующий способ узнать, что делает процедура, это найти известные вам библиотечные функции, например printf, sprintf, fopen, fread, и т.п. Посмотреть, откуда они вызываются и там уже догадаться, что выводится на экран или открывается и считывается, в зависимости от библиотечной функции.
Например строчка кода, приведённая ниже, расположенная в очень большой процедуре на несколько сотен строк, наталкивает на мысли, что эта процедура — комната покупки оружия, поскольку только там есть надпись "CASH:". Поэтому можно переименовать SUB, где вызывается этот sprintf, в shop_room, а остальные переменные как показано ниже.
sprintf(v159, "CASH: %i %s: %i", v87, aAmt, v88); // После переименовывания sprintf(cash_ammount_buffer_str, "CASH: %i %s: %i", cash_value_1, aAmt, amount_1);
В псевдокоде можно указать какие аргументы есть у функции, сколько их и какой их тип. Надо лишь выделить название функции и нажать Y. Формально это никак не скажется в дальнейшем на ассемблерном листинге, но поможет структурировать псевдокод.
Чтобы определить, сколько вообще у функции аргументов, на ассемблере, надо обратиться к соглашению о вызовах. Как правило, определить с каким соглашением была скомпилирована программа труда не составит, надо просто посмотреть на вызов процедур. Например, в моем случае, это очень похоже на fastcall, хотя Watcom его в то время не поддерживал. Наверняка использовалась ваткомовская директива #pragma aux для использования всех доступных регистров, в последовательности EAX, EDX, EBX, ECX, ESI, EDI, EBP. А если их не хватает, то переменные загружаются в стек справа налево. Например, вызов процедуры вывода картинки из файла numbers.bin на экран выглядит следующим образом. Точкой с запятой выделены комментарии.
mov ecx, 0 ; y_pos mov esi, ds:numbers_bin_ptr ; bin_ptr mov ebx, 0 ; x_pos mov eax, 1 ; image_number mov edx, 1 ; transparent call draw_IMG_on_screen ; Call Procedure
Зачастую IDA неверно определяет количество аргументов. Чтобы узнать какие переменные точно можно удалить из аргументов функции, можно зайти в процедуру в ассемблерном листинге и глянуть, что расположено в начале и в конце процедуры.
proc_name proc near push ebx push ecx push esi push edi push ebp mov ebp, eax mov edi, edx ; Какой-то код здесь pop ebp pop edi pop esi pop ecx pop ebx proc_name endp
В данном примере, регистры EBX, ECX, ESI, EDI, EBP никак не используются для передачи параметров в процедуру, потому как запоминаются в начале и затем восстанавливают своё состояние из стека в конце. Поэтому из аргументов их можно удалить (в псевдокоде клавиша Y, выделив функцию, и просто стереть ненужные аргументы). А EAX и EDX содержат входные параметры.
Не все функции имеют одинаковое соглашение о вызовах. Например, библиотечные функции могут иметь свои соглашения, отличные от всего пользовательского кода. Например, функция printf использует cdecl и принимает свои параметры через стек.
push ecx ; sample_str push offset aCouldNotFindSa ; "COULD NOT FIND SAMPLE:%s\n" call printf_
Иногда вам будут встречаться процедуры nullsub_X, которые состоят всего лишь из одного retn. Это следствие оптимизации программы, означающее выход из какой-либо процедуры, которая прыгнет с помощью jmp на адрес nullsub_X. Если же это будет что-то вроде call nullsub_X, то на это можно просто не обращать внимание.
Иногда IDA неверно определяет границы функции из-за её оптимизации, точнее неверно определяется конец функции. Из-за этого ломается весь псевдокод, поэтому придётся вручную задавать границы в листинге. Верный признак того, что IDA неправильно определила границы функции это пустой вывод в псевдокоде. Как правило, это ничего не значит для дальнейшей сборки и на этапе первого запуска и отладки это выявляется.
У каждого реверсёра есть свои любимые техники, но зачастую просто используются и комбинируются все по ходу разбора программы.
4. Работа с переменными
Чтобы упростить работу по разбору функций, желательно переименовать все переменные в ней.
Если вы видите byte_xxxxxx, word_xxxxxx, dword_xxxxxx и т.п. — это названия переменных, в области памяти программы. Они могут как иметь инициализированное значение, так и нет. Примеры объявления некоторых переменных приведены ниже.
dword_xxxxxx dd 0 ; переменная инициализирована word_xxxxxx dw ? ; переменная не инициализирована, ; обычно распологается в другой секции byte_xxxxxx db 'Some string', 0 ; инициализированная строковая переменная ; в C стиле, занимает 12 байт с нулём dword_xxxxxx dd 0 ; массив из n элементов (но не обязательно), db 0 ; указатель на массив db 0 ; определился как dword, а количество элементов db 0 ; придётся определять самим db 0 db 0 ; далее, примерно, миллион строк c db 0
Естественно, всем переменным надо дать удобоваримые названия. И не просто x, y, а, например, player_pos_x, player_pos_y и т.п. Если в чём-то есть сомнение, можно к названию переменной добавлять что-то вроде _maybe. К названиям функций это тоже относится.
Как видно из листинга кода выше, не всегда понятно, массив это, или указатель, или переменная или двойной указатель. С размерностью массивов тоже не всё сперва ясно. Иногда в коде встречается что-то типа:
clear_buffer(1184u, (_BYTE *)&dword_4E7ED6 + 2);
И тогда понятно, что dword_4E7ED6 + 2 — это начало массива на 1184 байта. Внутри clear_buffer, кстати, обычный memset(*, 0, );, это я переименовал, для понимания.
Но иногда встречается и такое:
clear_buffer(&loc_577FE + 2, game_screen_ptr);
IDA неверно определила константу 0x57800 как указатель loc_577FE + 2. К сожалению, все такие места придётся найти и поправить, иначе пересобранная программа будет крашиться в этом месте, или где-то рядом.
Как правило, довольно легко определить, константа это или переменная. Просто 2 раза кликнув на нее, можно попасть в сегмент данных (есть вероятность, что это константа, тогда такие места надо пометить до дальнейшей отладки программы) или в сегмент кода, тогда это точно константа и, выделив её, правой кнопкой мыши в ассемблерном листинге, надо это указать (или клавиша Q).
Ещё один пример в псевдокоде:
v6 -= int3;
int3 здесь — точно константа, просто IDA определила константу 0x10000 как адрес прерывания int 3, которое расположено по этому адресу.
Кстати, псевдокод пестрит переменными v0, v1, v2..., которых нет в ассемблерном листинге. Так IDA помечает регистры и локальные переменные. Их тоже лучше переименовывать для упрощения работы.
И да никогда не следует давать глобальным и локальным переменным одинаковые имена. Потому как с компиляцией будут проблемы.
5. Наберитесь терпения
Серьезно. Процесс разбора функций и переменных очень долгий. Возможно понадобится полгода-год, чтобы разобраться. При этом, полностью всё переименовать невозможно, но хватит и процентов семидесяти.
6. Создание ассемблерного файла
Сначала надо определиться, где будете кодить. Я выбрал Visual Studio, с поддержкой MASM ассемблера. Каких-то определенных сложностей для Linux пользователей тоже нет. Есть и MASM компиляторы для Linux, например JWasm.
Прежде чем создать ASM файл необходимо выполнить несколько шагов. Последовательность не обязательна.
IDA поддерживает синтаксис TASM и некий Generic for Intel (IDA — Options — General — Analysis). С каждым из них не всё так гладко, как хотелось бы, поэтому оставляем по умолчанию Generic for Intel.
IDA — Options — Assembler Directives. Убрать галочку ASSUME.
Развернуть все библиотечные функции. По умолчанию, IDA сворачивает их в одну строку. И если они свёрнуты, то так и попадут в ASM файл свёрнутыми. View — Unhide all.
Необходимо что-то сделать со структурами. Сложность в том, что современный MASM не поддерживает идовское объявление структур. Надо либо удалить их все из списка структур, либо использовать специальный ключ MASM компилятора "/Zm" для совместимости. Если решите оставить структуры, если, конечно, они у вас есть, нужно их развернуть, потому как они по умолчанию тоже сворачиваются в одну строку. View — Unhide all в структурах.
Убедиться, что вы не давали одинаковые имена локальным и глобальным переменным. К сожалению, какого-то совета, как это сделать нет. При компиляции вылезет.
Убедиться, что нет какого-то специфичного не MASM синтаксиса, который можно поправить прямо в IDA. Например, у меня было такое в секции данных:
a89Abc: text "UTF-16LE", '89:;<=>?@ABC' aEfghijklmno: text "UTF-16LE", 'EFGHIJKLMNO' aPqrstuvwxyz: text "UTF-16LE", 'PQRSTUVWXYZ[' aAbcdefgh: text "UTF-16LE", ']^_`abcdefgh'
MASM не поддерживает такую запись unicode текста, поэтому по каждой такой записи правой кнопкой мыши — Undefine.
Ещё одна проблема создания ассемблерного листинга — это данные, принятые за код. И код за данные. У меня была такая памятная строка в секции кода, выглядящая изначально как набор непонятных инструкций. Если есть сомнения, нужно смотреть дамп памяти, там есть представление в ASCII символах.
aWatcomCC32RunT db 'WATCOM C/C++32 Run-Time system. (c) Copyright by WATCOM' db 'International Corp. 1988-1995. All rights reserved.'
Кажется, всё. Можно генерировать ASM файл. Делается это довольно просто, File — Produce File — Create ASM file. Может получиться что-то типа filename.exe.asm. Тогда удалите из названия .exe. Сохраните также куда-нибудь копию сгенерированного файла и не трогайте её в дальнейшем, хоть в гит отдельным бранчем, потом пригодится для вспоминания, что было изначально в каком-либо месте.
7. Создание проекта и компиляция файла
Теперь необходимо поправить все ошибки в файле и просто его скомпилировать. Ничего страшного, если исходный файл от DOS программы, запускать мы его не планируем, пока что. Если файл от Windows, тогда можно будет и запустить.
Создайте пустой проект в Visual Studio, подключите туда ASM файл. Вы можете использовать любой другой редактор, подключив MASM компилятор из SDK masm32, но он плохо работает с большими файлами на несколько сот тысяч строк. Лучше взять компилятор ml.exe от студии. На линуксе можно использовать JWasm c флагами компиляции "-elf -c -zcw" (формат 32 битный, без сборки, с именами функций без ведущей литеры '_' ).
В VS нужно включить MASM в зависимостях сборки (Правой кнопкой по проекту — зависимости сборки). См. рисунок.
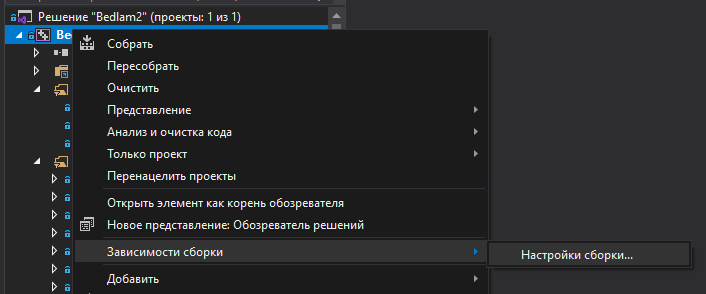
После этого всё должно компилироваться. Или по крайне мере пытаться компилироваться. После 100 ошибок MASM компилятор выдаст, что на этом его полномочия всё и прекратит работу.
Первое, что надо сделать, это поправить весь синтаксис, не характерный для MASM. Ассемблерный файл должен напоминать следующую структуру
.586 ; Модель ЦПУ. Можно выбирать .486 .686 ... .model flat,C ; Модель памяти и соглашение о вызове option casemap:none ; Нечувствительность к регистру .code ; Секция кода ; Сюда надо вставить весь код .data ; Секция данных ; Cюда всю дату .data? ; Секция неинициализированных данных ; Сюда всю неинициализированную дату end ; Окончание программы
При этом надо удалить все объявления секций, которые у нас были созданы идой. В MASM секции объявляются директивами .CODE, .DATA и .DATA?. При этом, последовательность секций значения не имеет. Т.е. вместо
.586 .model flat cseg01 segment para public 'CODE' use32 ; КОД public start ; ЕЩЁ КОД cseg01 ends dseg02 segment para stack 'STACK' use32 ; ДАТА dseg02 ends end start
Должно получиться
.586 .model flat,C ; Не забудьте соглашение C option casemap:none .code ; КОД ; ЕЩЁ КОД .data ; ДАТА (вся инициализированная дата) .data? ; ДАТА (вся неинициализированная дата, которая раньше была в dseg) end
Также нужно удалить строчки public start и end start, которые означали начало и конец программы. Вместо этого в MASM используется метки start:, end start. Их ставить не обязательно, если вы не будете запускать программу. Точнее, эти метки start указывают точку входа в программе.
Теперь быстренько пробежимся над ошибками, которые выдает компилятор. Их все придётся устранить одну за другой.
instruction prefix not allowed
Двойной клик по ошибке перенаправляет на инструкцию repne movsb. В такой записи MASM не видит смысла, поэтому просто автозаменой поменяйте все такие инструкции на rep movsb. Повторите автозамену также для repne movsw, repne movsd. Не трогайте repne stos(-b, -w, -d).
invalid combination with segment alignment : %num_bytes%
Как правило, надпись align %num_bytes%, на которую перенаправляет сообщение об ошибке, означает %num_bytes% нулевых байт для выравнивания, т.е. на этом месте располагается %num_bytes% строк db 0 или db ?, в зависимости от того, в какой секции вы находитесь. Чтобы устранить эту ошибку, необходимо подставить это число строк, вместо align. Либо просто удалить строчку с align, если она расположена в конце сегмента кода.
undefined symbol : loc_xxxxxx
Очень много неопределенных меток loc_xxxxxx и def_xxxxxx, которые MASM не может найти, хотя они присутствуют в файле. Причина, почему такое происходит, это локальные метки для MASM и область их поиска ограничена процедурой proc, end proc. Такие ошибки чаще всего возникают, если:
IDA неверно определила границы процедуры. Решение: просто передвинуть конец процедуры end proc на верное окончание процедуры. Начало процедуры лучше не двигать, если вы 100% не уверены в правильности вашего решения.
Компилятор соптимизировал часть дизассемблированной программы и процедуры вызывают одни и те же участки кода в других процедурах. Как правило, оптимизации подвергается окончание процедур с вереницей одинаковых pop-ов. Есть два решения этой проблемы. Либо сделать метку глобальной, просто добавив второе двоеточие, вроде loc_xxxxxx::, либо раскопировать весь оптимизированный код по местам, где он должен стоять. Быстрее и безошибочнее на этом этапе, мне кажется, метод с двумя двоеточиями.
Компилятор дизассемблируемой программы поместил метки оператора switch (характерно для программ на языках C, C++) за пределами процедуры. Если вы видите очень много меток def_xxxxxx или loc_xxxxxx, а в комментария от IDA написано что-то вроде ;jumptable XXXXXX case X, то это тот случай. Как правило, метки располагаются рядом с процедурой целым списком, вроде:
jpt_24016 dd offset loc_2407B dd offset loc_2401E ; jump table for switch statement dd offset loc_2404D dd offset loc_2407B dd offset loc_2404D dd offset loc_2404D dd offset loc_2401E dd offset loc_2401E dd offset loc_2407B dd offset loc_2404D dd offset loc_2401E proc1 proc ; Код из proc1, который вызывает метки выше retn proc1 endp
Нужно переделать так, чтобы эти метки располагались в процедуре:
proc1 proc ; Код из proc1 не трогать retn jpt_24016 dd offset loc_2407B dd offset loc_2401E ; jump table for switch statement dd offset loc_2404D dd offset loc_2407B dd offset loc_2404D dd offset loc_2404D dd offset loc_2401E dd offset loc_2401E dd offset loc_2407B dd offset loc_2404D dd offset loc_2401E proc1 endp
Опять же константы, принятые за метки, про которые я ранее писал. Например, метка loc_186A0, в данном случае, — это константа 100000. На константу намекает круглое значение и то, что по адресу 0x186A0 находится какой-то участок кода, а не дата.
mov dword ptr [eax], offset loc_186A0
На метку же намекают все типы прыжков. Что-то вроде jmp loc_16860 всегда будет меткой.
undefined symbol : %segment_name%
К сожалению, мы стёрли все имена сегментов, при написании директив .code, .data и тп. Имя можно добавить после директивы, например .data %segment_name%. Но дело в том, что занесение адреса начала сегмента в регистр, а потом работа с ним — это очень специфическая DOS фигулина, которую придётся править, если вы хотите запустить программу на современной системе. У меня это было начало колбэк функции, которая вызывалась раз в 10 миллисекунд и которую я потом переписал на C++. Соответственно, эту процедуру из файла я вообще удалил.
interrypt_callback proc near ; DATA XREF: setup_interrypts+89↓o cli pushf push eax mov al, 20h ; ' ' out 20h, al push es push ds mov ax, seg dseg02 ; здесь заносится адрес сегмента ...
undefined symbol : %some_name%
Тоже что и локальная метка loc_xxxxxx. Просто поставьте двойное двоеточие вместо одинарного: some_name::.
missing operator in expression
Нажимая на ошибку, попадаем на строчку
mov ebx, large es:5Ch
Нужно стереть все large. MASM их не понимает. Смысл остаётся тот же.
use of register assumed to ERROR
Нажимая на ошибку, попадаем в место вроде:
mov dword ptr gs:[edx], 1000h
Регистр GS никак не определён или компилятор думает об этом, поэтому надо незадолго до процедуры, а лучше где-нибудь вначале сегмента с кодом написать:
ASSUME GS:NOTHING
initializer magnitude too large for specified size
dbl_83D6E dq 1.797693134862316e308
Кажется это MAX_DOUBLE, использующееся, для вспомогательной функции форматирования (s)printf. Измените на:
dbl_83D6E dq 1.7976931348623157e308
На этом всё. Ошибки закончились, файл компилируется. Линкер ругается на отсутствие функции main, потому как не может найти точку входа в программу, мы ведь не добавляли start:, end start метки.
8. Разные доработки в asm (компиляция Windows программы)
Если у вас файл игры изначально был от Windows 95 и выше, чтобы запустить вновь скомпилированную игру, вам, во-первых, надо добавить метки start: вместо бывшего идовского public start и метку end start в конце программы. Во-вторых, надо удалить из asm-файла всю таблицу импорта библиотечных и других импортируемых .dll функций и импортировать их согласно синтаксису MASM, прописав соответствующие include и includelib.
Расскажу вкратце на примере одной функции. Для остальных всё будет аналогично. Например, где-то в коде вызывается библиотечная функция создания окна.
call cs:CreateWindowExA ; Или call CreateWindowExA
Нужно найти процедуру proc CreateWindowExA, которая перенаправляет на библиотечное импортированное название функции, и удалить её. Нужно также удалить все оффсеты и переменные, содержащие CreateWindowExA в сегменте данных. Нужно удалить любые похожие имена вроде __imp_CreateWindowExA. Нужно вообще всё удалить, с именем CreateWindowExA, чтобы кроме вызова функции больше ничего не было.
CreateWindowExA — это библиотечная функция, которая содержится в User32.dll, стандартном компоненте Windows. Это можно прочитать в документации Microsoft. Для вызова этой функции из MASM потребуется библиотека user32.lib и инклюд user32.inc. В студии имеются .lib файлы для стандартных библиотек, но отсутствуют ассемблерные инклюды.
Нужно скачать и установить masm32 SDK. В папке masm32\include и masm32\lib содержится всё, что нам нужно. Нужно подключить user32.lib и user32.inc в проект и указать пути до библиотек и инклюдов в свойствах проекта. Это делается следующим образом.
В самом начале ассемблерного исходника, перед секцией кода, дописать:
include user32.inc includelib user32.lib
Если всё сделано правильно, то линкер не будет ругаться на отсутствие функции. Всё скомпилируется, если вы, конечно же, повторите шаги для всех импортируемых функций.
Иногда функции импортируются из кастомных .dll файлов, которые лежат рядом с запускаемым файлом программы. В masm32 необходимых библиотек и инклюдов не окажется, поэтому нужно их создать самому.
Сперва надо сделать .def файл, затем из него .lib. Покажу на примере sqlite3.dll файла. В командной строке поочерёдно наберите:
dumpbin /exports sqlite3.dll > exports.txt echo LIBRARY SQLITE3 > sqlite3.def echo EXPORTS >> sqlite3.def for /f "skip=19 tokens=4" %A in (exports.txt) do echo %A >> sqlite3.def lib /def:sqlite3.def /out:sqlite3.lib /machine:x86
Все имена файлов (exports.txt , sqlite3.dll , sqlite3.def и т.д.) должны быть полными путями. Инструменты dumpbin, lib вы можно найти в пакете masm32\bin.
Кастомный инклюд сделать очень просто. Все имена функций из exports.txt надо переписать в виде, как показано ниже. Это и будет наш инклюд.
extrn SomeFuncName:proc extrn AnotherFuncName:proc ; ... ; ??? ; profit!
Более подробно, можно посмотреть как реализованы вызовы библиотечных функций в репозитории первой части игры Bedlam, Windows версии.
9. Замена DOS процедур на аналоги
Самое время написать что-нибудь на C++. Необходимо заменить все библиотечные DOS функции и прерывания на кросс-платформенные аналоги. С библиотечными функциями понятно, что это такое, этот термин не менялся с того времени. Прерывания же представляют собой встроенные DOS функции, которые выполняются, прерывая собой пользовательскую программу.
Существует великое множество прерываний. Например, считывание/запись файла, выделение памяти, вывод на экран, вывод звука и т.п.
Вызываются прерывания довольно просто. Ассемблерный пример:
int %int_number% ; вызов прерывания int_number
Прерывания могут принимать параметры из регистров, например тип функции прерывания, указатель на буфер, размер и т.п.
Наш ассемблерный файл содержит прерывания и некоторые специфические команды вроде in, out, sti, cli, которые могут выполняться в современной ОС, кажется, только на уровне ядра. При запуске скомпилированной пользовательской программы трассировка дойдет до первой такой команды и вывалится в ошибку. Поэтому самый верный путь — это ручная трассировка и замена этих функций на аналоги.
Замене подвергнутся процедуры вывода графики на экран, вывода звука, инициализация мыши и клавиатуры, прерывания по таймеру. Их придётся реализовать высокоуровневом языке, например C++. Хотя подойдет любой язык, способный вызывать функции из сторонних библиотечных файлов. Структура программы будет следующая: необходимая инициализация на C++, затем запуск main функции из ассемблерного файла, который будет дергать нужные функции ввода-вывода, написанные на С++.
Чтобы запустить ассемблерную процедуру из C++ программы, необходимо сделать следующее. Создать С++ заголовочный файл с объявлением функции. В примере, у нас есть ассемблерный main_ proc, который имеет соглашение о вызове __cdecl. Значит в export_from_asm.h надо написать:
extern "C" int main_(int, char **);
Здесь спецификатор __cdecl опущен, поскольку это платформозависимая запись, а в настройках проекта все функции, по умолчанию компилируются как __cdecl. Литера "C" указывает компилятору использовать имена функций в C стиле.
Кстати, помимо main_, в ассемблерном листинге присутствует start proc, из которого вызывается main_, но он не нужен и будет автоматически создан заново компилятором.
Затем создать любой .cpp файл и написать:
#inclide "export_from_asm.h" int main(int argc, char *argv[]) { // Вся необходимая инициализация здесь // Вызов main из ассемблерного файла return main_(argc, argv); }
Для вызова C++ функции из ассемблерного листинга необходимо указать компилятору, что имя функции в C-стиле, указать соглашение о вызове. Соглашение платформозависимо, написано в windows стиле. Например, есть некая функция сложения:
#include "export_to_asm.h" int __cdecl some_func(int a, int b) { return a + b; }
В заголовочном export_to_asm.h:
extern "C" int __cdecl some_func(int a, int b);
В ассемблерном файле, где-нибудь незадолго до секции .code надо написать объявление:
extrn some_func:proc
Вызвать функцию на ассемблере можно так (характерно лишь для соглашения __cdecl и 32 битного кода):
pusha ; Сохранение регистров, если надо push b ; b и a - переменные в памяти, размерностью 4 байта push a ; можно использовать регистры call some_func mov result, eax ; Результат вычисления возвращается в регистре eax ; заносится в память переменной result add esp, 8 ; Согласно cdecl, выравнивание стека после запушивания ; аргументов занимается пользовательская программа popa ; Восстановление значений регистров, если надо
Какого-то универсального совета, как переписать вывод графики, звука, опрос мыши, клавиатуры, реализовать таймеры и т.п. не существует.
С графикой в DOS всё довольно сложно. Дело в том, что ранний и поздний DOS существенно отличаются в плане вывода графики. Необходимо будет найти что-то типа указателя на экранный буфер, который линкуется в память видеокарты. Кстати, таких буферов может быть несколько. Пока один наполняется, второй отображается на экране. Также буферы могут быть разбиты на страницы, размерностью кратной степени двойки байт.
В игре Bedlam 2, используется экранный буфер, размерностью 640*480 байт, которое равно разрешению экрана. Каждый байт этого буфера — это пиксель с индексом цвета 256-цветовой палитры. Палитра представляет собой отдельный массив байтовых элементов Red, Green, Blue. Каждое число в палитре поделено на 4, как я понял, для создания градиентных переходов, использующих простой сдвиг палитры. Сами палитры хранятся в файлах с расширением .pal.
Во время игры используется другой буфер, больше экранного, на который рисуются все спрайты, затем этот буфер копируется с обрезкой в экранный буфер. Это сделано для того, чтобы можно было корректно рисовать спрайты на границах экрана.
С выводом звука много проще. Bedlam 2 использует .raw звуковые файлы, представляющие PCM поток c характеристиками 8 бит, 11025 Гц, 1 канал. Минимально, требуется заменить и реализовать на C++ только две asm-функции: raw_index = load_raw(raw_path); и play_sound(raw_index, x_pos, y_pos, flag);. Ассемблерная инициализация звука и звуковые прерывания были вырезаны из ассемблерного файла без разбора, что они делают.
Мышь и клава — это кажется самое простое, что пришлось переписать. В процессе разбора asm-исходников были найдены переменные: координаты мыши, координаты левого/правого клика, состояние кнопок мыши, а также массив bool-ов, содержащий нажатия кнопок клавиатуры, где индекс массива равен ordinary keyboard scancode (на вики нет описания, если вкратце, одна кнопка представляет один определенный байт — ordinary scancode). Потребовалось просто записывать в эти переменные свои значения каждый цикл игры.
Другие интересности
Исходный код игры писался во времена, когда 486й процессор считался очень хорошим. Разработчики боролись за каждый такт. Соптимизированно всё и вся. Из-за быстродействия, использовался язык C, хотя C++ в то время уже было лет 10-15.
В коде игры не использовалось ни одного float и double значений, либо иного значения с плавающей запятой.
Всё переменные, которые можно подсчитать до начала игры — подсчитаны. Почти ни одной команды умножения (mul, imul и тп.) во время игрового процесса. Вместо них, зачастую, массив с предварительно умноженными значениями.
Там, где умножение необходимо, используются степени двойки и сдвиги. Там, где этого недостаточно, умножение соптимизированно в адскую последовательность сдвигов и сложений.
Деление? Забудьте. Хотя, через полгода копания в коде, я нашел пару инструкций idiv.
Взятие синуса — довольно затратная процедура в то время. Поэтому синус берётся из таблицы Брадиса файла sintable.bin по индексу-значению.
Используются разные целочисленные хаки. Например, вычисление гипотенузы, аналог теоремы Пифагора, без извлечения квадратного корня. Аналогично формуле SQRT(dx*dx + dy*dy).
int get_distance(int delta_x, int delta_y) { int x1 = abs(delta_x); int y1 = abs(delta_y); if (x1 <= y1) { x1 >>= 1; } else { y1 >>= 1; } return x1 + y1; }
Для повышении точности этого хака, иногда входные параметры сдвигаются на 8 бит влево. А выходной — вправо.
Кстати, по поводу сдвигов. Используются везде. Координаты объекта, например игрока, сдвинутые на 8 бит вправо будут давать координаты плитки тайла, на котором находится игрок.
Номер, извлечённый из missionX.tot буфера по координатам плитки тайла, будет равняться номеру картинки тайла по координатам x, y из графического файла-пака missionX.bin.
Используются два рандомных генератора, инициализированных сидами 123456 и 234567. Генераторы, как я понял, стандартные для Cи ГПСЧ. Из за довольно частого и не последовательного обращения к ним быстро набирают энтропию.
Некоторые рандомные значения тоже заранее вычисляются и заносятся в массив. Например, шум картинки юнита, когда он получает повреждения.
Управление памятью — отдельная история. Нелегко сделать игру, когда у тебя ограничение в восемь мегабайт на графику и логику и два с половиной на звук, который можно отключить, чтобы сэкономить.
Изначально игра, при инициализации, выделяет все восемь метров и проверяет код ошибки, выделилась ли память. Затем, когда во время игры необходим новый динамический массив, вместо malloc вызывается собственная функция, я назвал её find_next_free_mem, которая возвращает адрес свободной памяти из выделенного массива на восемь метров. Что-то вроде фабрики. Со звуком так же.
Кстати, фабрики созданы и для врагов, снарядов, взрывов, обломков, останков, бонусов, возможно чего-то ещё. Максимальное количество объектов в каждом случае константное.
Всё игровое поле, т.е. поверхность и постройки на нём — набор ромбовидных тайлов. Как я писал, номера картинок тайлов уровня, проще говоря карта, находится в буфере missionX.tot. Хотите добавить огня на карту, просто запишите номер картинки огня в этот буфер. Конечно же, это происходит в оперативной памяти. Хотите разрушить постройку, занесите картинку разрушенной постройки туда же. Игра так и работает.
Послесловие
Видео портированной второй части, переработанной мной под различные разрешения. Конкретно, в этом случае, 1080p.
Git Bedlam 1 (довольно мало ей занимался, поэтому просто сырые компилирующиеся сорцы). Можно посмотреть, как сделан импорт библиотечных функций.
Git Bedlam 2: Absolute Bedlam, виновник статьи.
Git Bedlam Tools (инструмент для просмотра BIN файлов, прослушивания RAW, MRW файлов игры).
Ссылка на реверс тут (файлы IDA).
К сожалению, эти игры сейчас официально не купить вообще нигде, поэтому ссылки для ознакомления с Windows версиями вы найдёте здесь: 2 часть (для запуска понадобится пакет "Microsoft Visual C++ 2015 Redistributable x86").
Рекомендую также ознакомиться с 1 частью игры (для игры в 1080p запускать BEDLAMwinMod.EXE, мой патч оригинального .exe файла. Если боитесь вирусов, см. реверс выше. В файле желательно выставить режим совместимости с WinXP, т.к. он старенький, ему около 25 лет, и он крашится так же, как оригинал, иногда).
К сожалению, рабочей Linux версий нет. Рабочая Linux версия второй части есть. Вы можете её найти на Github, ссылка чуть выше. Для игры потребуются оригинальные файлы от DOS версии.
Спасибо за чтение!
PS. Хочу поменять стек на C++. Джун нужен кому? Просьба в личку.

