В глобальной сети можно встретить огромное число разнообразных наборов данных для обучения ваших моделей. Однако часто бывает так, что задача очень специфична и требует подготовки своего собственного уникального датасета. О том, как можно быстро и качественно разметить свои данные для задач CV вы узнаете из этой статьи.
Алгоритмы машинного обучения всё глубже проникают во многие сферы жизни и то, что еще вчера казалось фантастикой, сегодня уже воспринимается как обыденность: автомобили без водителей, чат-боты продающие товары и оказывающие консультации, автоматизированные производственные линии, работающие фактически без вмешательства человека – всё это лишь малая часть областей, где уже сейчас активно применяется искусственный интеллект. Вычислительные мощности растут, вместе с ними усложняются алгоритмы, совершенствуются подходы, благодаря чему все больше задач можно доверить бездушной машине.
Однако, прежде чем поручать задачу ИИ, зачастую требуется уделить особое внимание очень важному этапу – обучению модели. Чем внимательнее мы отнесемся к данному этапу, чем больше и разнообразнее данные мы предоставим, и чем они будут «чище», тем более точным и устойчивым будет наш алгоритм. К сожалению, сбор и разметка датасета это, пожалуй, самый долгий и дорогой этап подготовки будущей модели. И даже затратив много времени и средств на сбор данных, вы всё равно рискуете получить разметку не надлежащего качества. В этой статье мы рассмотрим, как можно ускорить процесс разметки и снизить стоимость затрат при подготовке датасета для компьютерного зрения.
Не так давно перед нами стояла задача создать модель, которая была бы способна выделять на изображении купюры и проверять находятся ли эти купюры в боксах, предназначенных для соответствующих номиналов.

В качестве модели для поиска объектов на изображении с камеры была выбрана популярная и достаточно быстра модель – Yolov5. Из коробки она способна сегментировать 80 классов. К сожалению российские купюры, и тем более их различные номиналы, не входят число предобученных классов, а значит для обучения нам предстояла долгая и кропотливая работа по разметке. Поскольку времени на проект было не так много, а для разметки требовалось обработать более 10 тыс. изображений мы серьезно задумались, как же можно ускорить процесс аннотации данных.
На сегодняшний день существует достаточное число универсальных инструментов для разметки, но многие из них платные. Кроме того, некоторые инструменты сложно установить или запустить на рабочем месте с жесткой политикой безопасности, такой, как например в банковских структурах или ряде государственных организаций.
После изучения популярных инструментов в конечном счете в своём выборе мы остановились на утилите «VGG Image Annotator». Это простой в освоении инструмент, который работает на стеке HTML+JS, что позволяет запустить его практически на любом рабочем месте. Не смотря на свою простоту и лояльность к ресурсам, данный инструмент представляет полноценный функционал по сегментированию объектов.
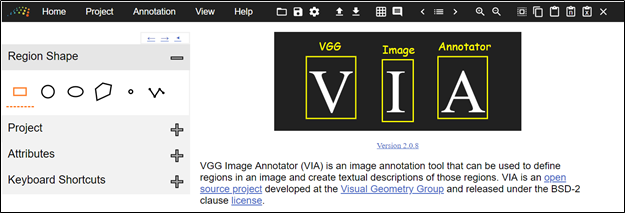
Во вкладке «Region Shape» настраивается форма разметки (например, прямоугольник или полигон), во вкладке «Project» перечисляются файлы, а вкладка «Attributes» служит для описания возможных классов и значений для метки по умолчанию. Сохранение разметки производится через сохранение всего проекта, или через экспорт аннотаций. Мы использовали в качестве выходного формата «JSON», но также есть возможность сохранить в «CSV» и «COCO»
Итак, у нас есть инструмент для разметки и есть необученная модель. Что дальше? Идея проста – мы возьмем некоторый посильный объем изображений, вручную разметим их, обучим на этих данных модель, а затем «попросим» нашу модель сгенерировать разметку для другой части неразмеченных изображений.

Естественно, модель не всегда будет качественно размечать данные, особенно сначала, когда обучающая выборка мала. Поэтому данные нужно обязательно валидировать вручную. В данном случае валидация выполняет 2 задачи: с одной стороны, мы обогащаем датасет качественной разметкой, а с другой стороны получаем примерное представление на сколько хорошо обучилась модель и пригодна ли она для финальной маркировки данных. Как только мы считаем качество приемлемым мы можем запустить модель на оставшихся изображениях, провести валидацию и сохранить конечный датасет. Основная экономия времени и ресурсов получается за счет того, что мы не размечаем все данные, а фактически только проверяем и исправляем автоматическую разметку. Кроме того, обычно последний этап не требует от специалиста высокой квалификации.
Приведу пример. Допустим вам необходимо разметить 5000 фотографий. Разделим их условно на 4 пачки: 100, 200, 300 и оставшиеся 4400 изображений. Первую пачку необходимо разметить вручную, вторая и третья пачка нужны для повышения качества модели. Последняя, четвертая пачка, размечается автоматически, нам остаётся лишь проверить разметку и подправить в тех случаях, если она не корректна. Схематически данный процесс можно представить в виде схемы:
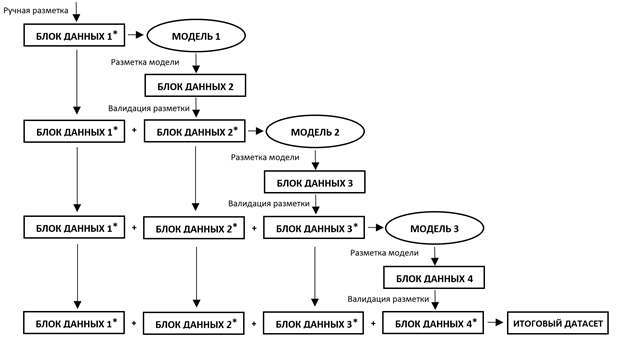
На первый взгляд данный процесс может показаться слегка запутанным, но эта сложность развеится, если создать пайплайн на языке Python. Давайте этим и займемся.
Как мы понимаем, первым шагом является ручная разметка первой пачки. Для этого мы воспользовались утилитой VIA. Для начала нам нужно сохранить весь проект разметки в формате «JSON». Для этого переходим в Project->Save (обязательно оставляем все галочки) и жмем «ОК».
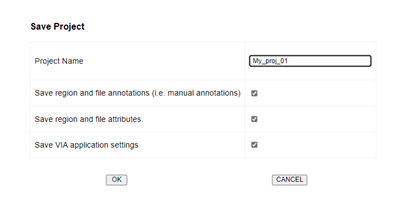
Добавляем в имя файла постфикс «_val», чтобы понимать, что данный датасет был провалидирован. Например, в нашем случае получился файл «01pack_val.json». Отлично, разметка есть. Давайте теперь на основе нее подготовим датасет для Yolov5:
from cook_data import *
source_dir = '/path/to/images'
prep_dirs(source_dir, 'my_dataset')
# fill train data
train_img_path = os.path.join(source_dir, ds_name, 'images', 'train')
train_lab_path = os.path.join(source_dir, ds_name, 'labels', 'train')
for path in [d for d in sorted(os.listdir(source_dir)) if d.endswith('_val.json')]:
path_json = os.path.join(source_dir, path)
info = viaLabels(path_json)
path_images = os.path.join(source_dir, os.path.dirname(path), info[0])
out = via2yola(path_json, path_images, info[1])
for txt in out:
if create_empty or len(out[txt]) > 0:
img_file = os.path.join(path_images, txt[:-4] + '.jpg')
if os.path.exists(img_file):
shutil.copy(img_file, os.path.join(train_img_path, txt[:-4] + '.jpg'))
with open(os.path.join(train_lab_path, txt), 'w') as f:
f.write('\n'.join(out[txt]))
#fill val data
val_img_path = os.path.join(source_dir, ds_name, 'images', 'val')
val_lab_path = os.path.join(source_dir, ds_name, 'labels', 'val')
if input('print "1" if need create val with {}% of train_set: '.format(val_prc)) == '1':
train_set = os.listdir(train_img_path)
random.shuffle(train_set)
val_cnt = len(train_set) // val_prc
val_set = train_set[:val_cnt]
for vs in val_set:
shutil.move(os.path.join(train_img_path, vs), os.path.join(val_img_path, vs))
shutil.move(os.path.join(train_lab_path, vs[:-4] + '.txt'), os.path.join(val_lab_path, vs[:-4] + '.txt'))
ds_path = os.path.join(source_dir, ds_name)
with open(ds_path + '.yaml', 'w') as f:
f.write('train: {}\n'.format(ds_path + os.sep))
f.write('val: {}\n\n'.format(ds_path + os.sep))
f.write('nc: {}\n\n'.format(len(info[1].keys())))
f.write('names: {}\n'.format(list(info[1].keys())))После выполнения данного скрипта мы получим правильно разложенные картинки и аннотации к ним, а также описание набора данных в понятном для Yolov5 виде. Сам процесс обучения весьма прост и подробно описан в репозитории к модели: https://github.com/ultralytics/yolov5
После обучения в нашем распоряжении оказывается модель, которая уже имеет некоторое представление о классах, которые необходимо детектировать. Давайте предскажем ею разметку для второго блока данных, а после преобразуем выход модели в проект, который сможем импортировать обратно в VIA. В последствии, мы сможем проволидировать автоматическую разметку и оценить насколько хороша наша модель. Но всё по порядку – сгенерируем разметку:
model = torch.hub.load('/path/to/yolov5_dir',
'custom',
path='/path/to/yolov5_dir/best_model.pt',
source='local')
labels = {model.names[i]: '' for i in range(len(model.names))}
batchsize = 16
for _, dirs, _ in os.walk(source_dir):
for d in sorted(dirs):
if d[0] == '.':
continue
try:
yoloAnnotations = []
tmp_path = os.path.join(source_dir, d)
for _, _, files in os.walk(tmp_path):
imgs = [i for i in files if i[-3:] in ('jpg', 'png', 'bmp')]
break
for n in tqdm(range(len(imgs) // batchsize + 1), desc=d):
imgs_batch = imgs[n * batchsize: (n + 1) * batchsize]
imgs_ = []
for img in imgs_batch:
imgs_.append(Image.open(os.path.join(tmp_path, img)))
if len(imgs_) > 0:
result = model(imgs_, size=640)
yoloAnnotations.extend(result.pandas().xyxy)
fromYolaToVia(tmp_path, imgs, yoloAnnotations, labels, project_name='fromYolaToVia')
except:
print('error', os.path.join(source_dir, d), )
breakЕсли сейчас мы зайдем в каталог c данными, мы увидим, что для каждой папки с изображениями создался свой «JSON» - проект с авторазметкой.
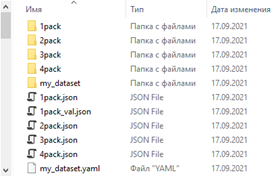
Откроем проект в VIA. Для этого запустим утилиту, далее Project – Load и укажем соответствующий файл, в нашем случае это 2pack.json. Настройки загружены, однако утилита сообщит, что файлы не найдены. Чтобы этой ошибки не было идем Project – Setting и в графе Default Path указываем полный путь к папке с пачкой данных:
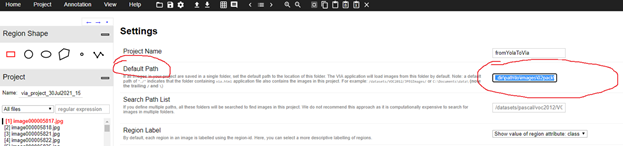
Очень важная особенность – путь необходимо завершить слешем, иначе VIA так и не увидит файлы. Должно получиться что-то вроде «source_dir\path\to\images\02pack\». Нажимаем «Save». Теперь наша утилита видит файлы и разметку, которую сгенерировала модель, а мы получаем возможность заняться проверкой размеченных данных. По завершению валидации сохраняем «02pack_val.json».
Теперь мы можем вернуться в начало статьи и повторить запуск подготовки датасета для модели. На этот раз в обучающую выборку добавятся данные из второй пачки. Соответсвенно на этих данных мы обучим новую модель и разметим ею третью пачку.
Эту процедуру мы продолжаем до тех пор, пока качество автоматической разметки не выйдет на уровень, необходимый нам. Другими словами, мы итерационно обучаем модель размечать за нас данные, и когда модель окажется готова – отдаём ей оставшийся массив данных. Финальная разметка, полученая подобным способом, почти не нуждается в правках и ее проверка не требует высокой квалификации специалиста или больших временных затрат.
В целом, подобный подход к разметке позволяет многократно сократить время получения итогового датасета и существенно повысить качество самой разметки, особенно в случаях, когда на изображении одновременно присутствует большое число сегментируемых объектов, а также в тех случаях, когда необходимо разметить огромное число фотографий. Все необходимые файлы для построения описанного пайлайна доступны в репозитории https://github.com/drova326/marking_utils. На этом у меня все. Размечайте с умом =)
