Наши клиенты часто спрашивают, какие технологии машинного обучения лучше подходят для решения их задач.
Наиболее убедительный аргумент в пользу тех или иных решений — обыкновенные цифры. Конкретные метрики, которые отражают качество работы таких систем. Их бывает непросто подсчитать, но с КРОК сотрудничают специалисты, которые разбираются в вопросе. Это разработчики сервиса роботизации службы поддержки из нашего продуктового портфеля.
Недавно команда AutoFAQ решила сравнить свою технологию с решениями от известных компаний на конкретной практической задаче.

Одна из основных задач в разработке диалоговой системы (чат-бота) — научиться определять, чего хочет пользователь.
Поставь будильник на полседьмого.
Заведи будильник на шесть тридцать.
Включи будильник в шесть часов тридцать минут.
Команды звучат по-разному, но за ними кроется одно и то же намерение, и его нужно распознать. Определение намерений пользователя по различным репликам называется распознаванием интентов (intent recognition).
Эту задачу невозможно решить без качественного датасета. Чем больше будет набор данных, тем большей точности можно добиться, и тем лучше чат-бот будет понимать собеседника. Однако такой датасет — роскошь, которая есть далеко не у всех компаний.
Сбор, очистка и разметка большого датасета — непростое дело, которое отнимает много сил, времени и ресурсов. Да и результат, несмотря на все усилия, бывает далек от идеального.
Кроме того, данные собирают и размечают через специальные сервисы — Яндекс.Толока или Amazon Mechanical Turk, но это недешевое удовольствие. Для работы с этими площадками важно понимать, как правильно поставить задачу перед исполнителями. И все равно реальные диалоги отличаются от того, что было размечено на краудсорсинге.
Поэтому так важно выбрать из всех движков для машинного обучения наиболее точный, быстрый и при этом требующий минимальный набор данных. Решения на базе такого движка быстрее и проще выкатить на прод.
Муки выбора
На рынке доступны многочисленные SaaS решения: Google Dialogflow, IBM Watson Assistant, Microsoft LUIS, Cognigy, AutoFAQ.ai. Чтобы работать с ними, даже не нужно навыков программирования. Настройка модели происходит через веб-интерфейс, а данные загружаются через Excel таблицы.
Доступны и библиотеки, ориентированные на разработчиков, например, RASA, DeepPavlov. Они позволяют развернуть инфраструктуру на своих серверах, самостоятельно описать конфигурацию классификатора и тонко настроить модель.
Широкий выбор, но не очевидно, какие из этих решений лучше справляются с распознаванием интентов.
Актуальные исследования
Конечно, мы не первые задались вопросом, что лучше. На эту тему существует ряд исследований. Для начала рассмотрим сравнение, приуроченное к конференции IWSDS 2019.
Авторы этой работы собрали и выложили в открытый доступ англоязычный датасет HWU64 (Heriot-Watt University) на базе диалогов с домашним роботом-помощником. Он наполнен командами типа «завести будильник» и «увеличить громкость». Всего 64 интента и 25 716 примеров.
При помощи этого набора данных исследователи сравнили качество работы Watson, Dialogflow, LUIS и RASA. За основную метрику взяли F1-меру — гармоническое среднее между точностью и полнотой. Это наиболее универсальный показатель, по которому обычно сравнивают качество работы моделей. Вот их результаты:
Название | F1-мера |
RASA | 0.863 |
Dialogflow | 0.864 |
LUIS | 0.855 |
Watson | 0.882 |
Лучше всех с распознаванием интентов в этом исследовании справился IBM Watson. Однако это данные, полученные на крупном качественном датасете, то есть, в почти что идеальных условиях.
В исследовании на один интент в среднем приходится 400 примеров. Реальность немного отличается. Для сравнения, порой наши клиенты с трудом набирают по 10 примеров на интент. Поэтому для наших целей правильнее оценивать качество работы движков на датасете поменьше.
Примерно так же рассуждали аналитики из немецкой компании Cognigy. В ноябре 2020 года они провели еще одно сравнение. Только на этот раз из датасета HWU64 выделили два набора данных так, что в первом на каждый интент приходилось по 10 примеров, а во втором по 30 примеров. Как и оригинальный датасет, эти наборы лежат в открытом доступе.
Для тестов исследователи взяли все те же Google Dialogflow, Luis, Watson и собственную разработку — Cognigy NLU.
Новый метод дал результаты, которые лучше отражают показатели этих систем в реальных бизнес-задачах.
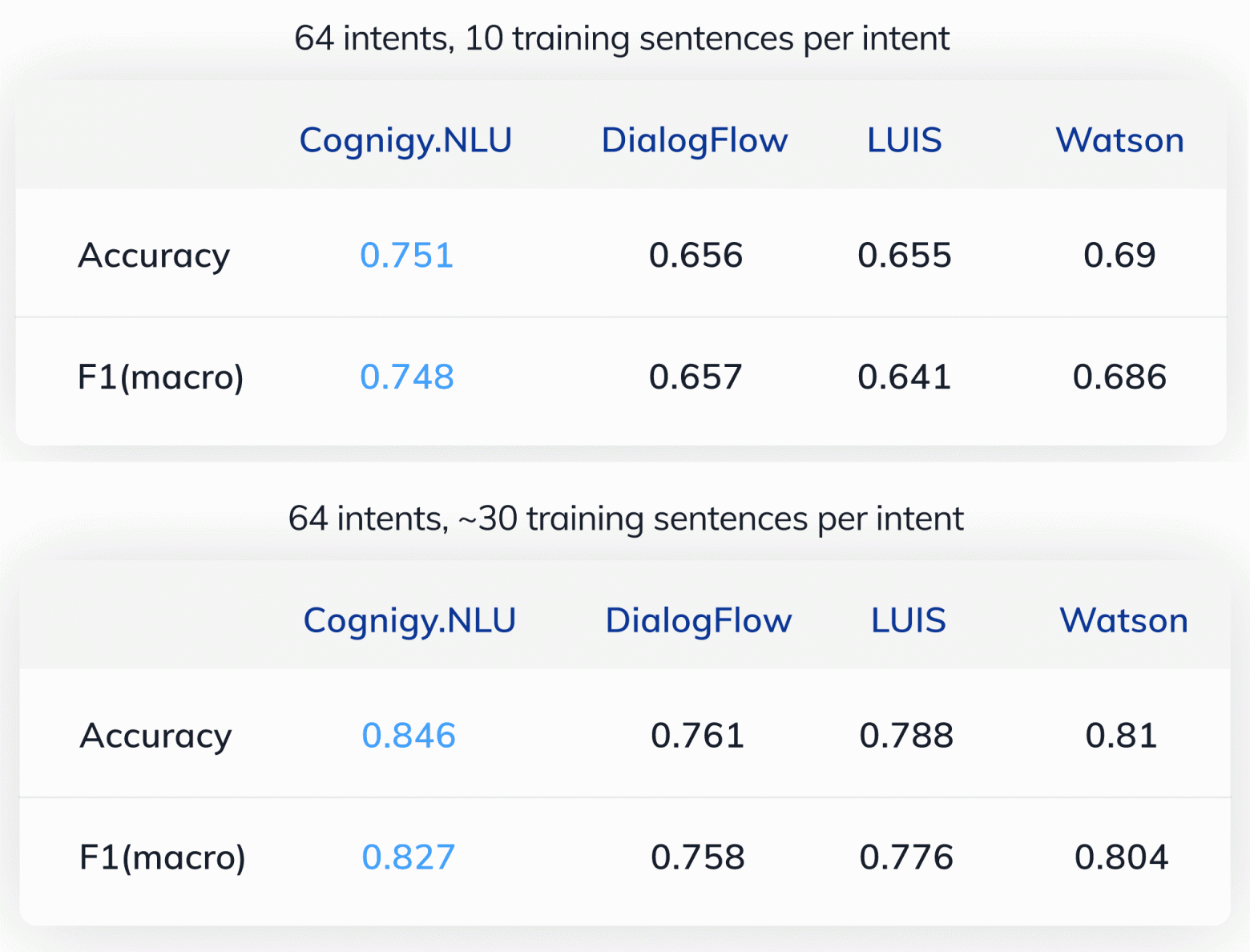
Оценка качества SaaS систем на примере датасета HWU64 по 10 и 30 примеров на интент
Качество работы Dialogflow, Luis и Watson после обучения на небольшом датасете, ожидаемо снизилось.
Watson все еще опережает конкурентов, но на первом месте оказалась система Cognigy, которая хорошо справляется и с 10, и с 30 примерами на интент.
Казалось бы, вот то, что мы искали, но IBM не осталась в долгу. Вскоре компания заявила, что улучшила свою модель распознавания интентов, и данные Cognigy больше не актуальны. В июне 2021 года IBM опубликовала статью с доказательствами.
В этом исследовании сравнивали SaaS системы и отдельные модели: BERT, RASA с DIETClassifier на четырех датасетах:
HWU64, уже знакомый нам по предыдущим работам;
CLINC150 — датасет с 150 интентами и 22 500 примерами из разных областей: путешествий, работы и т. п.;
BANKING777, состоящий из 77 интентов и 13 083 примеров из области банковского дела;
HINT3 — датасет из 3 наборов данных — SOFMAttress, Curekart и Powerplay11. Причем каждый из наборов представлен в двух вариантах: полный набор и подвыборка с меньшим количеством примеров.
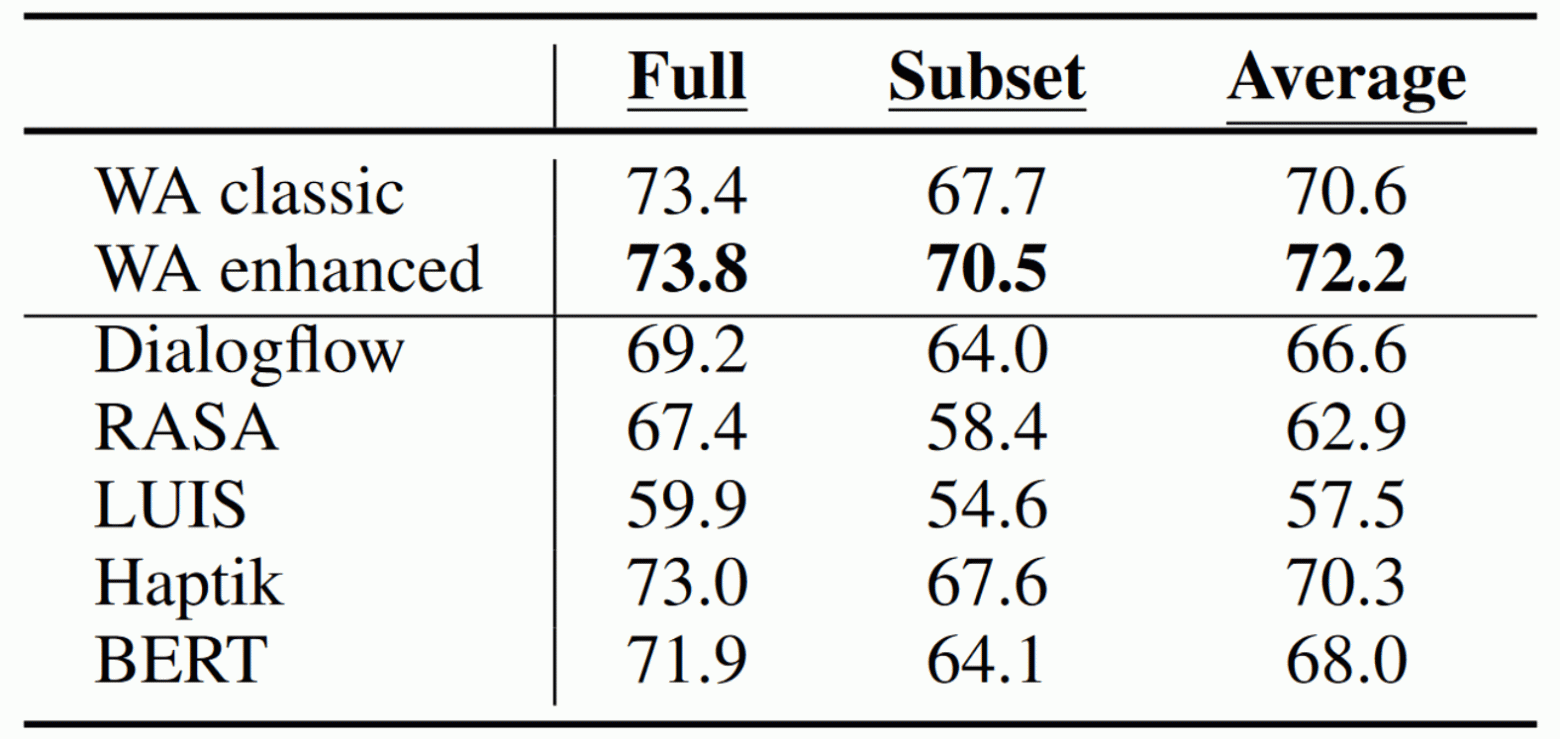
Исследование IBM Watson и других SaaS систем на датасете HINT3. Показана средняя точность по трем наборам из этого датасета
Выяснилось, что Watson опережает другие SaaS решения по качеству распознавания. Эта система обучается быстрее других и укладывается в 2 минуты там, где BERT-large требует 270 минут обучения на GPU Tesla K80.
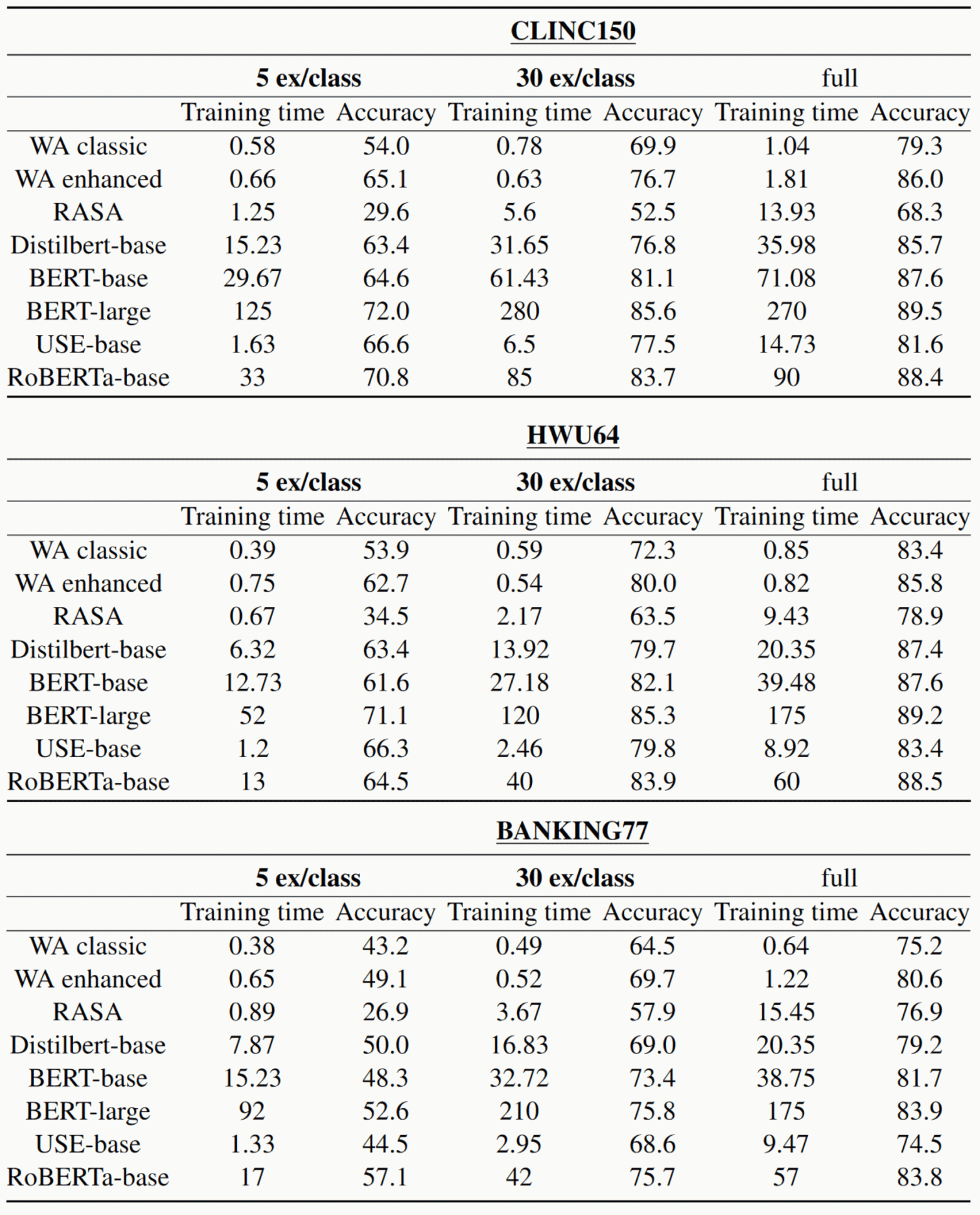
Оценка качества IBM Watson (WA) по сравнению с другими моделями. Время обучения приведено в минутах. 5 ex/class, 30 ex/class, full — число примеров на интент
Увы, и это исследование не дает полной картины. В IBM замеряли показатели Watson образца 2021 года, и сравнивали их с данными о производительности других систем, собранными еще в 2020 году.
Кроме того, в статье отсутствует сравнение по времени ответа и не указано время обучения для конкурирующих SaaS решений.
Наше исследование
Чтобы исправить эти недочеты, в сентябре 2021 года мы провели собственный эксперимент и заново рассчитали производительность для актуальных версий: IBM Watson, Google Dialogflow, Micorosft LUIS, Cognigy и AutoFAQ.ai.
Мы не стали изобретать собственную методологию. Вместо этого, использовали подход Cognigy из второй статьи.
Эта методика построена на открытых данных и не требует больших ресурсов для экспериментов. К тому же, она дает результаты для валидации и сравнения с нашими замерами.
Результаты исследования
Система | F1-макро (HWU64-10) | Точность (HWU64-10) | F1-макро (HWU64-30) | Точность (HWU64-30) | Время ответа на 1 запрос (сек.) |
AutoFAQ.ai | 0.786 | 0.802 | 0.858 | 0.851 | 0.270+-0.035 |
Cognigy | 0.771 | 0.776 | 0.829 | 0.842 | 0.590+-0.241 |
Dialogflow | 0.649 | 0.640 | 0.754 | 0.756 | 0.273+-0.033 |
LUIS | 0.657 | 0.673 | 0.771 | 0.782 | 0.314+-0.053 |
Watson | 0.761 | 0.776 | 0.848 | 0.855 | 0.180+-0.036 |
Результаты экспериментов на двух наборах данных HWU64. В первом по 10 обучающих примеров на каждый из 64 интентов, во втором по 30. Все данные и код можно скачать с GitHub и повторить замеры самостоятельно
По результатам нашего исследования, качество Watson действительно заметно выросло по сравнению с 2020 годом. Специалисты IBM не ошиблись, их решение опережает Cognigy образца 2020 года и сохраняет превосходство над версией 2021 года. У остальных систем заметного прироста качества не наблюдается.
И все же, Watson не абсолютный лидер. В категории F1-макро на датасетах HWU64-10 и HWU64-30 первое место заняла наша разработка — AutoFAQ.ai. А по точности с датасетом HWU64-30 Watson опередил AutoFAQ.ai всего на 0.004.
AutoFAQ.ai, ее ядро, пайплайн со старта разработки затачивались под обучение на минимальных наборах данных. Мы ожидали высокой точности, но первое место стало приятным сюрпризом.
Время обучения рассмотренных систем примерно на одном уровне — для HWU64-10 порядка 10 секунд, для HWU64-30 около 30 секунд. Наименьшая скорость ответа у Watson — 180 мс, наибольшая у Cognigy — 600 мс. У остальных систем она колеблется в районе 280 мс.
Что дальше
Признаться, мы вошли во вкус и уже планируем новые сравнения. Собираемся оценить качество распознавания интентов на русском языке. Из упомянутых систем его поддерживают AutoFAQ.ai, Cognigy и Dialogflow и Watson, через универсальную языковую модель.
Было бы интересно узнать, как коррелируют точность и значения уверенности, которые выдают системы, выяснить, как ведут себя системы, если данных для обучения не хватает (one-shot learning). А также, подсчитать, сколько времени уходит на обучение, если на один интент приходится более 1 тысячи примеров.
Мы изучим опыт коллег, проведем собственные замеры и расскажем о новых результатах в следующей статье.

