
Data Science — одна из самых востребованных профессий в IT. Она продолжает набирать обороты, хотя отдельной дисциплиной наука о данных стала сравнительно недавно. В эту субботу делимся большим, насыщенным материалом, который поможет узнать или вспомнить о ключевых этапах становления профессии, а освоить её можно здесь.
Придание смысла данным имеет долгую историю и обсуждается учёными, статистиками, библиотекарями, компьютерщиками и другими специалистами на протяжении многих лет. Проследим эволюцию термина «наука о данных», его использование, попытки дать ему определение и связанные термины.
Термин «Data Science» появился совсем недавно [оригинал статьи на английском языке опубликован Forbes в 2013 году] для обозначения новой профессии, которая должна осмыслить огромные хранилища больших данных.
1962 год. В статье «Будущее анализа данных» Джон В. Тьюки пишет:
«Долгое время я считал себя статистиком, интересующимся выводами от частного к общему. Но по мере наблюдения за развитием математической статистики, у меня возникали вопросы и сомнения <…> Я пришёл к выводу, что мой главный интерес заключается в анализе данных <…>
Анализ данных и те разделы статистики, которые его придерживаются, должны… приобрести черты [отдельной] науки, а не математики <…> Анализ данных по своей сути — эмпирическая наука <…> Насколько жизненно важным и насколько значимым… является появление электронного компьютера с хранимыми программами?
Во многих случаях ответ может удивить: «важным, но не жизненно важным», хотя в других случаях нет сомнений в том, что компьютер был "жизненно важным"».
В 1947 году Тьюки ввёл термин «бит», который Клод Шеннон использовал в своей работе 1948 года «Математическая теория связи».
В 1977 году Тьюки публикует книгу Exploratory Data Analysis («Разведывательный анализ данных»), утверждая, что необходимо уделять больше внимания использованию данных, чтобы выдвигать гипотезы для тестирования, а также что разведывательный анализ данных и подтверждающий анализ данных «могут и должны работать бок о бок».


1974 год. Петер Наур публикует Concise Survey of Computer Methods («Краткий обзор компьютерных методов») в Швеции и США. Книга представляет собой обзор современных методов обработки данных, которые используются в широком спектре приложений. Текст строится вокруг понятия данных, как оно определено Международной федерацией по обработке информации (IFIP) в путеводителе по определениям и понятиям обработки данных:
«[Данные — это] представление фактов или идей в формализованном виде, способное передаваться или управляться с помощью какого-либо процесса».
В предисловии книги читатель узнаёт, что на конгрессе IFIP в 1968 году был представлен план курса под названием «Даталогия, наука о данных и процессах данных, её место в образовании»; а также факт, что термин «наука о данных» (data science) используется свободно.
Наур предлагает следующее определение науки о данных: «Наука о работе с данными после их установления, в то время как связь данных с тем, что они представляют, делегируется другим областям [науки] и наукам».
1977 год. Как отдел Международного института статистики (ISI) учреждена Международная ассоциация статистических вычислений (IASC).
«Миссия IASC заключается в том, чтобы объединить традиционную статистическую методологию, современные компьютерные технологии и знания экспертов в данной области в целях преобразования данных в информацию и знания».

1989 год. Григорий Пятецкий-Шапиро организовал и возглавил первый семинар по обнаружению знаний в базах данных (KDD). В 1995 семинар стал ежегодной конференцией ACM SIGKDD Conference on Knowledge Discovery and Data Mining.
Сентябрь 1994 года. BusinessWeek публикует статью с анонсом на обложке о «Маркетинге баз данных»:
«Компании собирают горы информации о вас, обрабатывают её, чтобы предсказать, насколько вероятно, что вы купите товар. Затем они используют эти знания для составления маркетингового сообщения, точно выверенного, чтобы заставить вас сделать это <…>
Всплеск энтузиазма, вызванный ранее распространением сканеров штрих-кода в 1980-х, закончился всеобщим разочарованием: компании были слишком ошеломлены огромным количеством данных, чтобы сделать с этой информацией нечто полезное <…> Тем не менее многие компании считают, что у них нет другого выбора, кроме как смело ступить в границы маркетинга на основе баз данных».
1996 год. Члены Международной федерации классификационных обществ (IFCS) собрались в Кобе, Япония, на свою конференцию, которую проводили раз в два года. Тогда впервые термин «наука о данных» был включён в название конференции: «Наука о данных, классификация и связанные с ней методы».
IFCS основали в 1985 году шесть классификационных обществ по странам и языкам классификации, одно из которых, The Classification Society (Общество классификации), основали в 1964 году. Классификационные общества в своих публикациях по-разному используют термины «анализ данных» (data analysis), «добыча данных» (data mining) и «наука о данных» (data science).

1996 год. Усама Файяд, Григорий Пятецкий-Шапиро, и Падрейк Смит публикуют статью «От добычи данных до обнаружения знаний в базах данных» (From Data Mining to Knowledge Discovery in Databases). Они пишут:
«Историчес��и понятие поиска полезных закономерностей в данных получило различные названия, включая добычу данных, извлечение знаний, обнаружение информации, сбор информации [information harvesting], археологию данных и извлечение паттернов из данных <…>
По нашему мнению, KDD [обнаружение знаний в базах данных] относится к общему процессу обнаружения полезных знаний из данных в целом, а добыча данных относится к определённому этапу этого процесса.
Добыча данных — это применение конкретных алгоритмов для извлечения закономерностей из данных <…> дополнительные шаги в процессе KDD, такие как подготовка данных, выборка данных, очистка данных, включение соответствующих априорных знаний и правильная интерпретация результатов добычи, необходимые для обеспечения получения полезных знаний из данных.
Слепое применение методов анализа данных (справедливо критикуемое в статистической литературе как драгирование данных) может быть опасным занятием, легко приводящим к обнаружению бессмысленных и бесполезных закономерностей».

1997 год. В своей инаугурационной лекции на должность профессора Гарри К. Карвера Джефф Ву (на момент написания статьи работал в Технологическом институте Джорджии) призывает переименовать статистику в науку о данных, а статистиков — в учёных, изучающих данные [data scientists].

1997 год. Запущен журнал «Добыча данных и обнаружение знаний» (Data Mining and Knowledge Discovery); обратный порядок двух терминов в названии отражает, что «добыча данных» становится более популярным способом обозначения «извлечения информации из больших баз данных».
Декабрь 1999 года. Якоб Захави цитируется в статье «Добыча данных в поисках самородков знаний» (Mining Data for Nuggets of Knowledge) в Knowledge@Wharton:
«Обычные статистические методы хорошо работают с небольшими наборами данных. Однако современные базы данных могут содержать миллионы строк и десятки столбцов <…>
Масштабируемость является огромной проблемой в области добычи данных. Другой технической проблемой является разработка моделей, которые могут лучше анализировать данные, выявлять нелинейные связи и взаимодействие между элементами <…>
Возможно, придётся разработать специальные инструменты добычи данных для решения проблем, связанных с веб-сайтами».
2001 год. Уильям С. Кливленд публикует работу «Наука о данных: план действий по расширению технических областей статистики» (Data Science: An Action Plan for Expanding the Technical Areas of the Field of Statistics).
Это план «расширения основных направлений технической работы в области статистики». Он амбициозен и предполагает значительные изменения, а изменённая область будет называться «наукой о данных».
Кливленд рассматривает предлагаемую новую дисциплину в контексте компьютерных наук и современной работы в области добычи данных:
«…выгода от аналитики данных была ограничена, потому что знания учёных в области компьютерных наук о том, как думать [в аналитике данных] и подходить к аналитике данных, ограничены, так же как и знания статистиков о вычислительных средах.
Слияние баз знаний создаст мощную силу для инноваций. Это свидетельствует о том, что статистикам сегодня следует обращаться за знаниями к вычислительной технике, как в прошлом наука о данных обращалась к математике.
<…> кафедры науки о данных должны иметь преподавателей, которые посвящают свою карьеру достижениям в области вычислений с данными и устанавливают партнёрские отношения с учёными в области компьютерных наук».
2001 год. Лео Брейман публикует книгу «Статистическое моделирование: две культуры» (Statistical Modeling: The Two Cultures):
«Существуют две культуры в использовании статистического моделирования для получения выводов из данных. В первой предполагается, что данные генерируются заданной стохастической моделью данных. Вторая же использует алгоритмические модели и рассматривает механизм данных как неизвестный.
Статистическое сообщество придерживается первого подхода почти всегда. Эта приверженность привела к неактуальной теории, сомнительным выводам и не позволила статистикам работать над большим количеством интересных текущих проблем.
Алгоритмическое моделирование как в теории, так и на практике быстро развивается в областях за пределами статистики. Оно может использоваться как на больших сложных наборах данных, так и в качестве более точной и информативной альтернативы моделированию на небольших наборах данных. Если наша цель как отрасли науки — использовать данные для решения проблем, то нам нужно отказаться от исключительной зависимости от моделей данных и использовать более разнообразный набор инструментов».

Апрель 2002 года. Запуск Data Science Journal, публикующего работы по «управлению данными и базами данных в науке и технологиях». Сфера журнала включает описание систем данных, их публикацию в интернете, приложения и юридические вопросы. Журнал издаётся Комитетом по науке о данных для науки и технологий (CODATA) Международного совета по науке (ICSU).
Январь 2003 года. Начало работы Journal of Data Science:
«Под "наукой о данных" мы понимаем практически всё, что имеет отношение к данным: их сбор, анализ, моделирование… <…> Но самая важная часть — это применение данных. Этот журнал посвящён применению статистических методов в целом <…> Журнал Journal of Data Science станет платформой для всех работников сферы данных, где они смогут представить свои взгляды и обменяться идеями».
Май 2005 года. Томас Х. Дэвенпорт, Дон Коэн и Эл Джейкобсон публикуют отчёт «Конкуренция на основе аналитики» Исследовательского центра навыков работы Бэбсоновского колледжа, который описывает «появление новой формы конкуренции, основанной на широком применении аналитики и данных, а также на принятии решений на основе фактов <…>
Вместо конкуренции по традиционным факторам компании начинают использовать статистический и количественный анализ и прогнозирование как основные элементы конкурентной борьбы».
Исследование было позже опубликовано Дэвенпортом в Harvard Business Review (январь 2006 года) и расширено (совместно с Жанной Дж. Харрис) до книги Competing on Analytics: The New Science of Winning (март 2007).
В России издавалась под названием «Аналитика как конкурентное преимущество. Новая наука побеждать».
Сентябрь 2005 года. Национальный научный совет (NSF) (США) публикует «Долговременные собрания цифровых данных: включение исследований и образования в XXI веке». Одна из рекомендаций отчёта гласит:
«NSF, работая в партнёрстве с управляющими собраний [данных] и сообществом в целом, должен действовать ради развития и совершенствования карьеры специалистов Data Science и обеспечения т��го, чтобы исследовательское предприятие включало достаточное количество высоквалифицированных специалистов по работе с данными».
В отчёте даётся следующее определение специалистов по работе с данными:
«Специалисты в области информации и информатики, инженеры и программисты баз данных и программного обеспечения, эксперты по дисциплинам, кураторы и эксперты-аннотаторы, библиотекари, архивисты и другие специалисты, которые имеют решающее значение для успешного управления собранием цифровых данных».
2007 год. В Университете Фудань, Шанхай, Китай, создан Исследовательский центр даталогии и науки о данных.
Здесь мы видим разделение понятий «даталогия» и «Data Science».
В 2009 году два научных сотрудника Центра, Янъюн Чжу и Юнь Сюн, публикуют статью «Введение в даталогию и науку о данных», в которой говорится:
«В отличие от естественных и общественных наук даталогия и наука о данных как объект своих исследований рассматривают данные в киберпространстве. Это новая наука». Центр проводит ежегодные симпозиумы по даталогии и Data Science.

Июль 2008 года. JISC публикует итоговый отчёт об исследовании, которое было проведено по его заказу, чтобы «изучить и дать рекомендации по роли и карьерному росту специалистов по работе с данными и сопутствующему предложению специализированных навыков курирования данных для исследовательского сообщества».
«В заключительном отчёте исследования «Навыки, роль и структура карьеры изучающих данные учёных, а также кураторы: оценка нынешних практик и нужды будущего» учёные, изучающие данные, определяются как «люди, которые работают там, где проводятся исследования — или, в случае персонала центра обработки данных, в тесном сотрудничестве с создателями данных — и могут быть вовлечены в творческий поиск и анализ, предоставляя другим возможность работать с цифровыми данными, и разработки в области технологий баз данных».
Здесь мы сознательно не используем кальку дата-сайентисты, поскольку определение термина дата-сайентист ещё не сформировано до конца [прим. ред.].
Январь 2009 года. Опубликован отчёт Межведомственной рабочей группы по цифровым данным для Комитета по науке Национального совета по науке и технологиям Использование силы цифровых данных для науки и общества. В нём говорится:
«Нации необходимо определить дисциплины и специалистов, а также способствовать появлению новых дисциплин и специалистов, компетентных в решении сложных и динамичных проблем сохранения цифровых данных, устойчивого доступа, повторного использования и перепрофилирования данных.
Во многих дисциплинах наблюдается появление нового типа экспертов в области науки о данных и управления ими, которые работают в компьютерных, информационных науках и науках о данных, а также в других областях. Эти люди являются ключевыми для нынешнего и будущего успеха научного предприятия. Однако они часто не получают признания за свой вклад, а их карьера ограничена».
Январь 2009 года. Хэл Вэриан, главный экономист Google, рассказывает в McKinsey Quarterly: «Я постоянно говорю, что в ближайшие десять лет самой сексуальной профессией будет статистика.
Люди думают, что я шучу, но кто бы мог подумать, что компьютерная инженерия станет самой сексуальной профессией 1990-х годов?
Умение брать данные, понимать их, обрабатывать, извлекать из них ценность, визуализировать, передавать — это будет очень важный навык в ближайшие десятилетия <…>
Потому что сейчас у нас действительно есть практически бесплатные, вездесущие данные.
Поэтому дополнительным дефицитным фактором является способность понимать эти данные и извлекать из них ценность <…>
Я думаю, что эти навыки — способность получать доступ, понимать и передавать информацию, полученную в результате анализа данных, — будут чрезвычайно важны. Управляющие должны иметь возможность самостоятельно получать доступ к данным и понимать их».
Март 2009 года. Кирк Д. Борн и другие астрофизики представили для Десятилетнего обзора «Astro — 2010» работу «Революция в астрономическом образовании: Data Science для масс»:
«Обучение следующего поколения тонкому искусству разумного понимания данных необходимо для успеха науки, сообществ, проектов, агентств, бизнеса и экономики. Это справедливо как для специалистов (учёных), так и для неспециалистов (всех остальных): общественности, преподавателей и студентов, рабочих.
Специалисты должны изучать и применять новые методы исследования науки о данных, чтобы продвинуть наше понимание Вселенной. Неспециалистам необходимы навыки информационной грамотности как продуктивным членам рабочей силы XXI века, интегрирующей основополагающие навыки для обучения на протяжении всей жизни в мире, где все больше доминируют данные».
Май 2009 года. Майк Дрисколл пишет в статье «Три сексуальных навыка гиков данных» (the three sexy skills of data geeks):
«…с наступлением эпохи данных те, кто умеет моделировать, обрабатывать и наглядно представлять данные — назовите нас статистиками или гиками данных — горячий товар». В августе 2010 Дрисколл продолжит книгу «Семь секретов успешных исследователей данных» (the seven secrets of successful data scientists).
Июнь 2009 года. Натан Яу пишет в статье «Восход Data Scientist» (Rise of the Data Scientist):
«Как мы все уже читали, главный экономист Google Хэл Вэриан в январе прокомментировал, что следующей сексуальной профессией в ближайшие 10 лет будет статистика. Очевидно, что я от всей души согласен с этим. Чёрт возьми, я бы сделал ещё один шаг вперёд и сказал, что они сексуальны сейчас — умственно и физически. Однако, если бы вы продолжили читать интервью Вэриана, то узнали бы, что под статистиком он подразумевал человека, способного извлекать информацию из больших массивов данных и затем представлять что-то полезное для неспециалистов в области данных <…>
[Бен] Фрай <…> утверждает необходимость создания совершенно новой области, объединяющей навыки и таланты из часто разобщённых областей знаний <…>[информатика; математика, статистика и добыча данных; графический дизайн; визуализация информации и взаимодействие человека и компьютера]. И после двух лет освещения визуализации на FlowingData кажется, что сотрудничество между областями становится все более распространённым, но, что более важно, вычислительный информационный дизайн становится всё ближе к реальности. Мы видим, как дата-сайентисты — люди, которые могут делать всё это, — выделяются из общей массы».
Обратите внимание на разные регистры понятия Data Scientist. С 2008 года и, как минимум, по 2011 год люди продолжали осторожничать и писать термин в кавычках, курсивом, прописными буквами, хотя в заголовке могли встретиться заглавные.
Статья выше, по-видимому, — осознанная попытка сделать стандартом заглавные буквы. В оригинале её заголовок — Rise of the Data Scientist, а термин data scientist выделен курсивом в попытке определения. Поэтому здесь уместен перевод в виде кальки, чтобы отразить замысел автора, обособить термин. [прим. ред.].
Июнь 2009 года. Трой Садковски создаёт группу data scientists group на LinkedIn как дополнение к своему сайту datasceintists.com, который позже стал datascientists.net.
Февраль 2010 года. Кеннет Кукиер пишет в специальном отчёте The Economist «Данные, данные везде»:
«…Появился новый вид специалистов — дата-сайентист, который сочетает в себе навыки программиста, статистика, рассказчика, чтобы извлекать золотые слитки, скрытые под горами данных».
Июнь 2010 года. Майк Лукидес пишет в статье «Что такое наука о данных?»:
«Учёные, изучающие данные, сочетают в себе предприимчивость с терпением, готовностью к постепенному созданию продуктов данных, способностью к исследованию и итерационному поиску решения.
Они по своей сути междисциплинарны. Они могут решать все аспекты проблемы, от сбора исходных данных и их обработки до формулирования выводов. Они могут мыслить нестандартно, придумывая новые способы рассмотрения проблемы, или работать с очень широко определёнными проблемами: здесь много данных, что вы можете из них сделать?»
Сентябрь 2010 года. Хилари Мейсон и Крис Уиггинс пишут в статье «Таксономия Data Science»:
«…мы подумали, что было бы полезно предложить одну возможную таксономию… того, чем занимается специалист в Data Science, примерно в хронологическом порядке:
Получить, очистить, изучить, смоделировать и понять <…> Наука о данных — это, несомненно, смесь хакерского искусства <…> статистики и машинного обучения… знаний в области математики и в области данных, чтобы анализ был интерпретируемым <…> Она требует творческих решений и непредвзятости в научном контексте».

Сентябрь 2010 года. Дрю Конвей пишет в статье «Диаграмма Венна для Data Science»:
«…человек должен многому научиться, стремясь стать полностью компетентным специалистом Data Science. К сожалению, простым перечислением текстов и учебников эти узлы не распутать. Поэтому, пытаясь упростить дискуссию и добавить собственные мысли к тому, чем уже переполнен рынок идей, я представляю диаграмму Венна науки о данных <…> хакерские навыки, знание математики и статистики, а также предметный опыт».
Май 2011 года. Пит Уорден пишет в статье «Почему термин "наука о данных" ошибочен, но полезен» (Why the term "data science" is flawed but useful):
«Не существует общепринятой границы того, что входит в рамки науки о данных или не входит в них. Является ли это просто причудливым ребрендингом статистики? Я так не думаю, но у меня также нет полного определения. Я считаю, что недавнее обилие данных породило нечто новое в мире, и, когда я смотрю вокруг, я вижу людей с общими чертами, которые не вписываются в традиционные категории.
Эти люди, как правило, работают за пределами узких специальностей, которые доминируют в корпоративном и институциональном мире, занимаясь всем — от поиска данных, их масштабной обработки, визуализации и написания истории об этих данных.
Они также, похоже, начинают с изучения того, что данные могут им рассказать, а затем выбирают интересные нити, то есть начинают не с традиционного подхода учёного, который сначала выбирает проблему, а затем находит данные, чтобы пролить на неё свет».
Май 2011 года. Дэвид Смит пишет в статье «"Наука о данных": что в имени тебе моём?» ("Data Science": what's in a name?):
«Термины "Data Science" и "Data Scientist" вошли в обиход всего чуть больше года назад, но за это время они успели получить широкое распространение: многие компании сейчас нанимают "дата-сайентистов", а под заголовком "наука о данных" проводятся целые конференции.
Но, несмотря на широкое распространение, некоторые сопротивляются переходу от более традиционных терминов, таких как "статистик", количественный аналитик или "аналитик данных" <…>
…Я думаю, "наука о данных" лучше описывает то, чем мы на самом деле занимаемся: сочетание хакерства, анализа данных и решения проблем».
Июнь 2011 года. Мэтью Дж. Грэм на семинаре «Астростатистика и добыча данных в больших астрономических базах данных» с докладом «Искусство науки о данных» (The Art of Data Science) сказал:
«Чтобы процветать в новой, насыщенной данными среде науки XXI века, нам нужно развивать новые навыки <…> Нам нужно понять, каким правилам подчиняются [данные], как они символизируются и передаются и каковы их отношения с физическим пространством и временем».
Сентябрь 2011 года. Харлан Харрис пишет в статье «Data Science, закон Мура и денежный мяч»:
«Наука о данных определяется как то, что делают "Data Scientist".
О том, чем занимаются специалисты в Data Science, очень хорошо рассказано, это включает в себя все этапы: сбор и обработку данных, применение статистики, машинного обучения и связанных с ними методов, интерпретацию, передачу и визуализацию результатов. Кто такие дата-сайентисты — возможно, более фундаментальный вопрос
Мне нравится идея, что Data Science определяется её практиками, что это карьерный путь, а не категория деятельности. В разговорах с людьми мне кажется, что люди, считающие себя специалистами Data Science, обычно имеют эклектичные карьерные пути, которые в некотором смысле могут показаться бессмысленными».
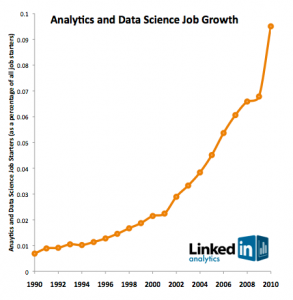
Сентябрь 2011. Доктор Джанурджай Патил пишет в «Создание команд в науке о данных»:
«В 2008 году мы с Джеффом Хаммербахером (@hackingdata) сели за стол, чтобы поделиться опытом создания групп данных и аналитики в Facebook и LinkedIn. Во многом эта встреча положила начало науке о данных как отдельной профессиональной специализации: мы поняли, что по мере роста наших организаций нам обоим придётся решать, как называть людей в наших командах.
Слово "бизнес-аналитик" оказалось слишком узким. На эту должность претендовал термин "аналитик данных", но мы посчитали, что это название может ограничить возможности людей. В конце концов, многие люди в наших командах обладали глубокими инженерными знаниями.
Учёный-исследователь было разумным названием должности в таких компаниях, как Sun, HP, Xerox, Yahoo и IBM. Однако мы чувствовали, что большинство учёных-исследователей работали над проектами, которые были футуристическими и абстрактными, а работа велась в лабораториях, изолировананных от команд по разработке продуктов.
Могут пройти годы, прежде чем лабораторные исследования повлияют на ключевые продукты, если вообще повлияют. Вместо лабораторных исследований наши команды сосредоточились на работе над приложениями для работы с данными, которые могли бы оказать немедленное и масштабное влияние на бизнес. Термин, который показался наиболее подходящим, — дата-сайентист: для тех, кто использует данные и науку, чтобы создать нечто новое».
Сентябрь 2012 года. Том Дэвенпорт и доктор Джанурджай Патил публикуют статью «Data Scientist: самая сексуальная профессия XXI века» в Harvard Business Review.
Такова краткая история науки о данных, а начать карьеру в Data Science или ML вы можете на наших курсах:
Также вы можете перейти на страницы из каталога, чтобы увидеть, как мы готовим специалистов в других направлениях.

Профессии и курсы
Data Science и Machine Learning
Python, веб-разработка
Мобильная разработка
Java и C#
От основ — в глубину
А также:

