В отделе продаж можно услышать аббревиатуру ABC: Always Be Closing, что означает заключение сделки с покупателем. Последнее десятилетие породило еще одну аббревиатуру ABCD: Always Be Collecting Data.
Мы используем Google для почты, карт, фотографий, хранилищ, видео и многого другого. Мы используем Twitter, чтобы читать поток сознания одного президента. Мы используем Facebook для обмена сообщениями и… ну, почти все. Но наши родители пользуются им. Мы используем TikTok… Понятия не имею, зачем.
На самом деле, оказывается, что большинство из вышеперечисленного бесполезно… Ничего подобного, суть в том, что мы их используем. Мы их используем, и они бесплатны. В экономике XXI века, если вы не платите за товар, вы являетесь товаром.
Итак, короче говоря, я хотел выяснить, насколько корпорация Alphabet, владелец Google, обо мне знает. Крошечная доля, я посмотрел на историю геолокации. Я никогда не отключал службы определения местоположения, потому что ценил комфорт выше конфиденциальности. Плохая идея.
Загрузите ваши данные
Чтобы загрузить все данные, которые Google собрал о вас, перейдите на takeout.google.com и выберите то, что вас интересует. Боюсь, что жесткий диск моего ноутбука недостаточно велик, чтобы загрузить все, поэтому я выбрал только историю местоположений. Только эти данные составляют почти 300 МБ в формате JSON.
Если вы не хотите скачивать все, вы можете смотреть его в режиме реального времени. Facebook также собирает данные о вашем местоположении, которые вы можете увидеть здесь. Также доступна опция загрузки. У меня 1,4 МБ, намного меньше, но ваш размер может отличаться. Имея эти данные, давайте как-нибудь их проанализируем.
Войдите в Jupyter Notebook
В 2020 году парсинг JSON и построение красивых графиков называется наукой о данных. Я хочу быть ученым! Прежде чем мы начнем, нам понадобятся некоторые важные инструменты: Python, Jupyter Notebook и некоторые модули для обработки данных:
brew install python3 pip3 install jupyter pandas geopandas matplotlib descartes
Теперь давайте запустим Jupyter Notebook с помощью jupyter notebookкоманды (это было неожиданно…) Jupyter — это, по сути, визуальный REPL, поддерживающий Python и несколько других языков. Это очень удобно для исследования данных и может создавать приятно выглядящие документы, сочетающие код, текст и визуализацию. Все в вашем веб-браузере.
Разбор файла местоположения JSON
Google предоставляет гигантский массив JSON, который выглядит примерно так:
"locations" : [ { "timestampMs" : "1387457266881", "latitudeE7" : 521490489, "longitudeE7" : 208043723, "accuracy" : 15 }, { "timestampMs" : "1387457271865", "latitudeE7" : 521490030, "longitudeE7" : 208044464, "accuracy" : 10, "activity" : [ { "timestampMs" : "1387457280733", "activity" : [ { "type" : "STILL", "confidence" : 77 }, { "type" : "UNKNOWN", "confidence" : 20 }, { "type" : "IN_VEHICLE", "confidence" : 2 } ] } ] }
Примерно то, что вы ожидаете, широта / долгота (умноженная на 10 7), отметка времени и точность. Кроме того, некоторые точки данных содержат дополнительные метаданные о действиях, которые, по мнению Google, вы выполняли в этом месте. С вероятностью 77% я стоял на месте. Загрузим этот огромный файл в память и немного очистим его:
import pandas as pd import numpy as np import geopandas as gp import shapely.geometry as sg import datetime as dt from matplotlib import cm from matplotlib.lines import Line2D def extract_activity(record): try: return record["activity"][0]["activity"][0]["type"] except: return "MISSING" def parse_json(json): points = [sg.Point(xy) for xy in zip(json.locations.apply(lambda x: x["longitudeE7"] / 10000000), json.locations.apply(lambda x: x["latitudeE7"] / 10000000))] df = gp.GeoDataFrame(geometry=points) locations = json.locations df["timestamp"] = locations.apply(lambda x: pd.to_datetime(x["timestampMs"], unit='ms')) df["accuracy"] = locations.apply(lambda x: x["accuracy"]) df["velocity"] = locations.apply(lambda x: x.get("velocity", None)) df["heading"] = locations.apply(lambda x: x.get("heading", None)) df["altitude"] = locations.apply(lambda x: x.get("altitude", None)) df["activity"] = locations.apply(extract_activity) return df %time df = parse_json(pd.read_json("Location history.json"))
Я зарабатываю на жизнь парсингом и очисткой JSON. Однако в области науки о данных это называется извлечением признаков. Мне это нравится гораздо больше. Хорошо, технически это не то, что есть извлечение функций, но мне от этого легче. По сути, я анализирую координаты shapely.geometry.Point широты и долготы в структуре данных, анализирую временные метки и пытаюсь извлечь активность, если таковая имеется. Ничего фантастического. Это дает таблицу (или, я бы сказал, DataFrame) с… 1 миллионом наблюдений за 8 лет. Страшный. Смотреть на эти необработанные данные бессмысленно, очевидно, мы хотели бы нанести их на карту реального мира!
Построение карты мира
Оказывается, нам нужен так называемый шейп-файл с границами для рисования. Я где-то их нашел и после многих итераций сумел нарисовать раздавленную карту мира:
# http://thematicmapping.org/downloads/world_borders.php world = gp.read_file('./TM_WORLD_BORDERS-0.3/TM_WORLD_BORDERS-0.3.shp') def draw_map(df, box): box_only = df[df.geometry.within(box)] minx, miny, maxx, maxy = box.bounds base = world.plot(color='white', edgecolor='silver', figsize=(16,16)) base.set_xlim(minx, maxx) base.set_ylim(miny, maxy) ax = box_only.plot(ax=base, marker='o', markersize=8)
df представляет собой DataFrame наблюдение за местоположением, а box представляет собой интересующий нас прямоугольник. Это будет поддерживать масштабирование в будущем. Вот результат:
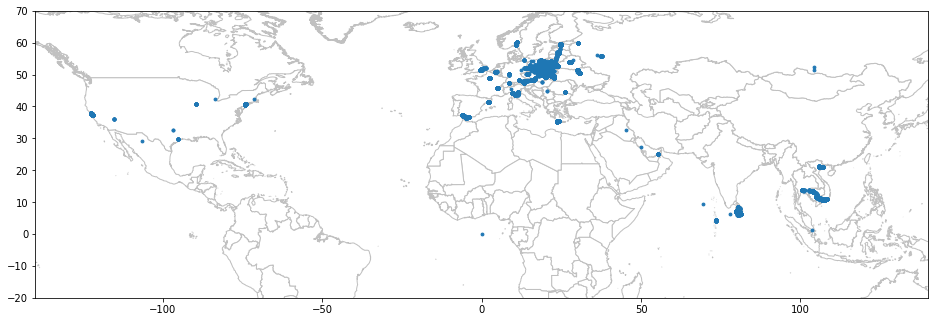
Это что-то. Меня больше всего беспокоит то, что мои данные относятся к 2013–2020 годам. Я посетил некоторые из этих мест много лет назад, в то время как в других местах есть данные только вчера. Было бы здорово как-то отличить поездки из далекого прошлого от совсем недавних. Например, используя разные цвета. Более того, вместо того, чтобы статически назначать несколько цветов месяцам и годам, я предпочел бы иметь гладкую палитру, которая динамически подстраивается под данные. Это заняло у меня некоторое время, но вот улучшенная версия:
def seconds(timestamp): return timestamp.to_pydatetime().timestamp() def calculate_pal(df2, cmap): min_ts = seconds(df2.timestamp.min()) max_ts = seconds(df2.timestamp.max()) return df2.timestamp.apply(lambda ts: cmap((seconds(ts) - min_ts) / (max_ts - min_ts))).tolist() def compute_legend(df, ax, cmap, steps): vals = [x / (steps - 1) for x in range(steps)] custom_lines = [Line2D([0], [0], color=cmap(step), lw=4) for step in vals] labels = [df.timestamp.quantile(step).strftime("%Y-%m-%d") for step in vals] ax.legend(custom_lines, labels, loc="lower right") def draw_map(df, box): box_only = df[df.geometry.within(box)] minx, miny, maxx, maxy = box.bounds base = world.plot(color='white', edgecolor='silver', figsize=(16,12)) base.set_xlim(minx, maxx) base.set_ylim(miny, maxy) cmap = cm.get_cmap('viridis') pal = calculate_pal(box_only, cmap) ax = box_only.plot(ax=base, marker='o', color=pal, markersize=8) compute_legend(box_only, ax, cmap, 5)
calculate_pal() назначает цвет каждой точке данных в зависимости от ее положения на временной шкале. Самые старые точки темно-синие / фиолетовые. Самые новые желтые с зеленым между ними. Мне также удалось построить динамичную легенду. Хватит, покажи мне карту!
draw_map(df, sg.box(-140, -20, 140, 70))
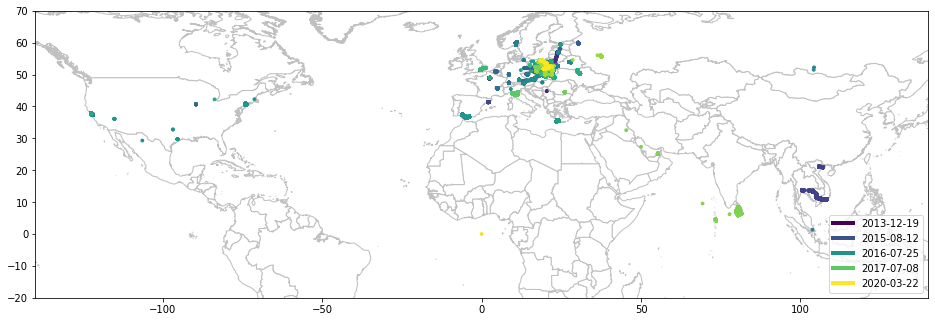
Давайте изучим мои локации!
Как видите, я, скорее всего, живу где-то в центральной Европе. Давайте немного увеличим масштаб:
draw_map(df, sg.box(-10, 30, 50, 70))
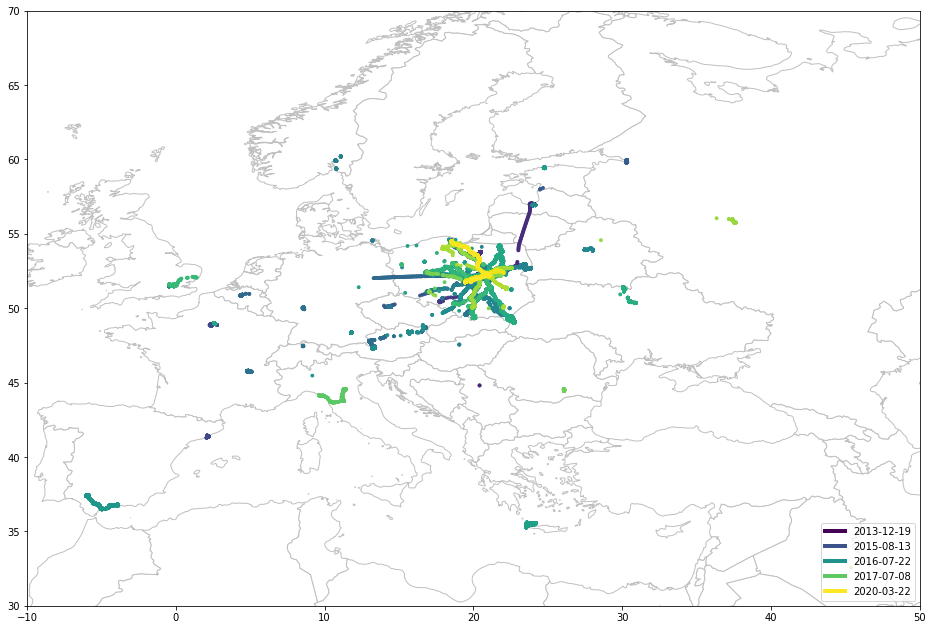
Ага, это Польша прямо посередине. Увеличение:
draw_map(df, sg.box(14, 49, 24, 55))
Хорошо, надеюсь, вы знаете, где находится Польша, но найти ее столицу не так-то просто. Как видите, я живу в Варшаве, откуда начинаются все мои путешествия. Эта звездчатая структура символизирует различные поездки и каникулы. Например минимум три поездки на север по берегу моря. Прямые линии - это два раза, когда я забыл выключить GPS в самолете. Хорошо, давай посмотрим, где я живу:
draw_map(df, sg.box(20.6, 52, 21.3, 52.5))

Ой, извините, это была картина Джейсона Поллока. Вот что я имел в виду:
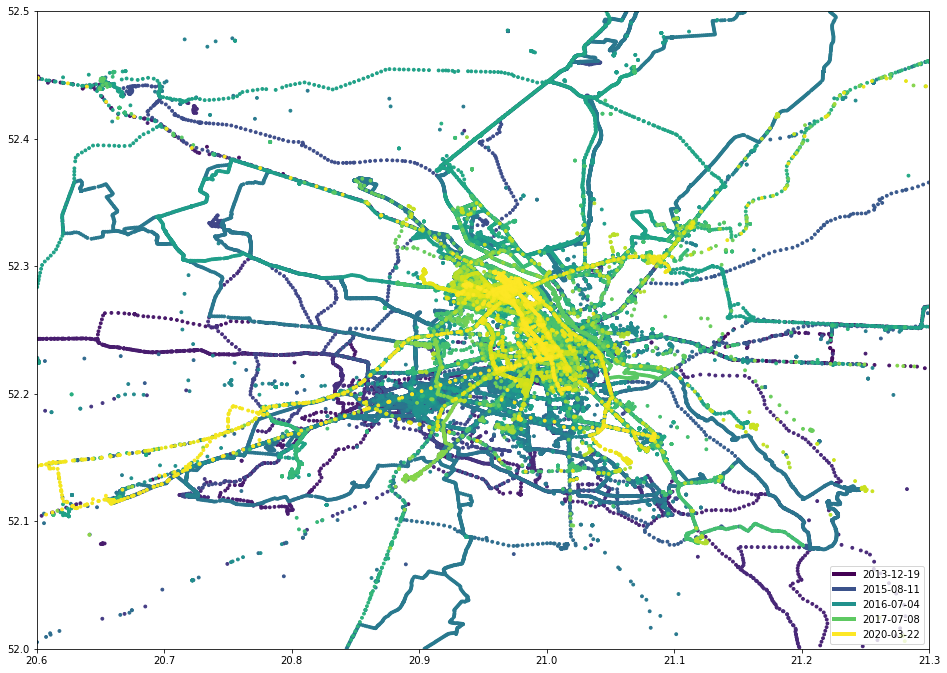
При небольшом увеличении можно увидеть три горячие точки: север, юго-запад и центрально-восток. Они представляют мою текущую и предыдущую квартиру, а также центр города, где я работаю:
draw_map(df, sg.box(20.88, 52.17, 21.05, 52.32))
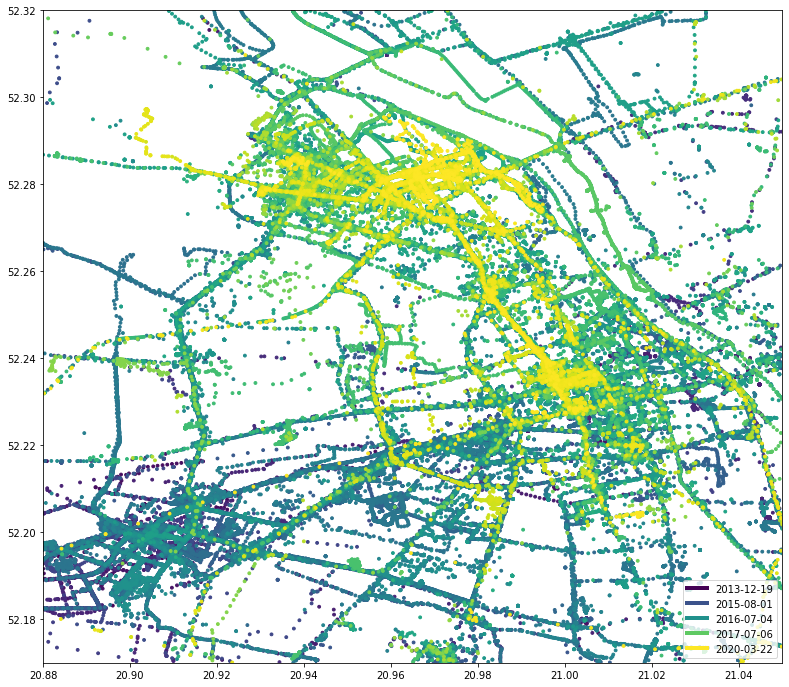
Извлекаем информацию об активностях
Мы также извлекали информацию об активностях, помните? Вы хотите видеть только точки данных, обозначенные как IN_VEHICLE (на автобусе или за рулем автомобиля)?
draw_map(df[df.activity == 'IN_VEHICLE'], sg.box(20.88, 52.17, 21.05, 52.32))
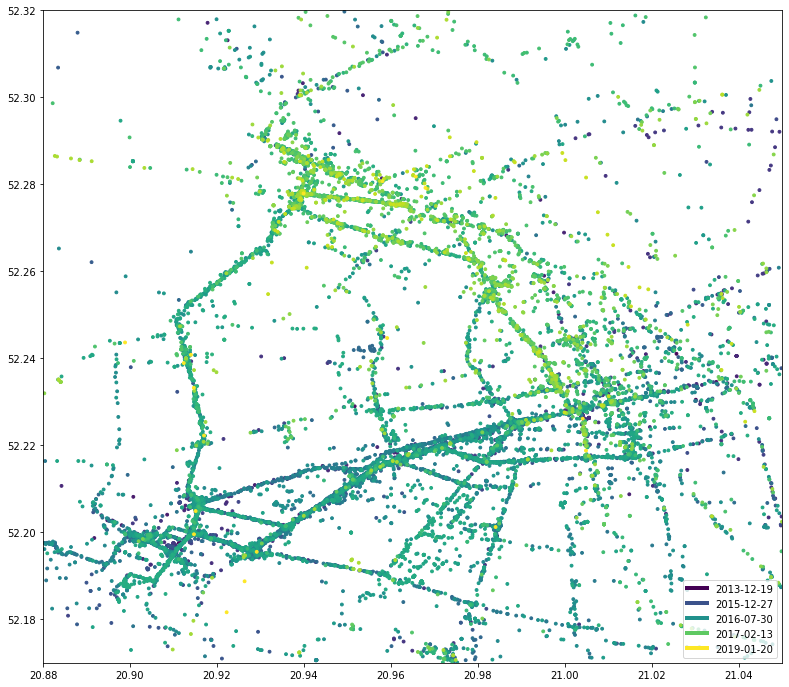
Посмотрите, насколько отличается карта, если ON_FOOT учитывать только активность:
draw_map(df[df.activity == 'ON_FOOT'], sg.box(20.88, 52.17, 21.05, 52.32))
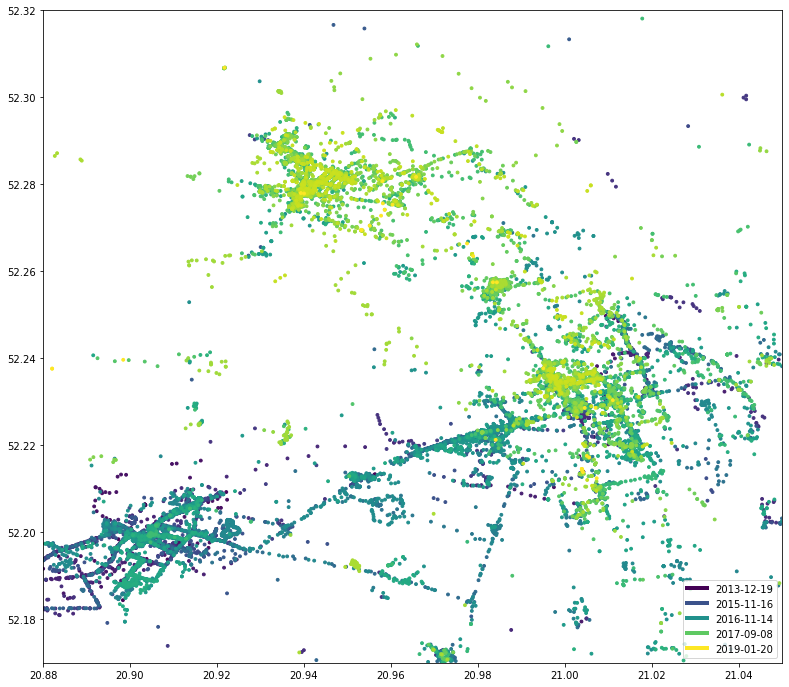
В этом есть смысл, я использую автобус или машину, чтобы ехать на большие расстояния, тогда как пешие прогулки больше сосредоточены на одной области. Если не считать треугольника в нижней половине… (?) Примерно в 2016 году (посмотрите легенду) я пробегал около 10 км от офиса до квартиры. И Google это знает.
Больше информации
Вот так выглядит квартал вокруг моей предыдущей квартиры:
draw_map(df, sg.box(20.88, 52.17, 20.93, 52.22)) draw_map(df, sg.box(20.895, 52.19, 20.915, 52.21))
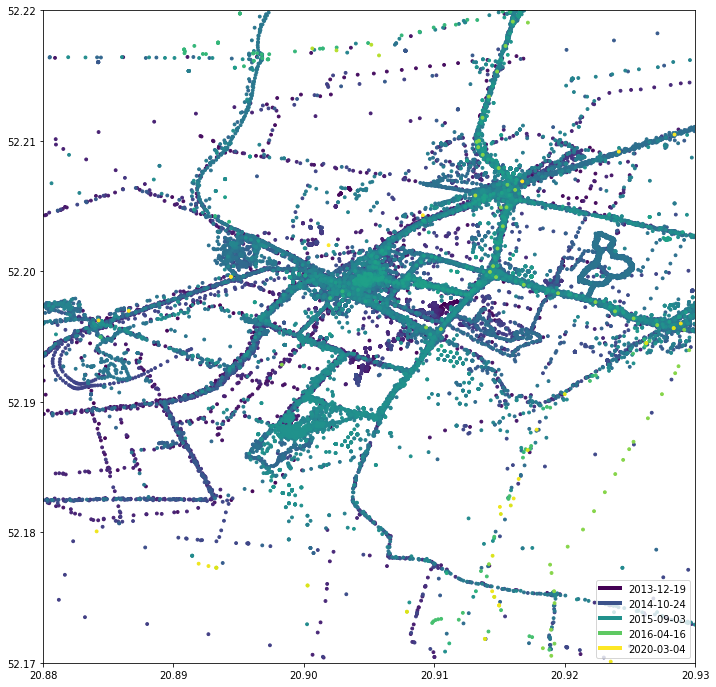
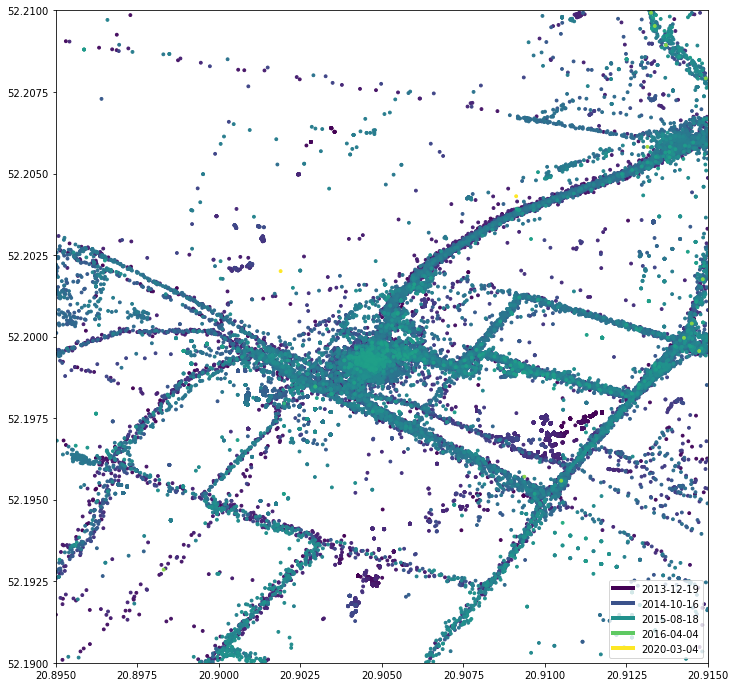
Вы можете ясно видеть, где находится моя квартира, а также каждую улицу. Еще одна интересная находка: я переехал из этого места примерно в 2016 году. Однако с 2020 года очень мало желтых точек. Оказывается, поблизости есть железнодорожный путь, которым я пользуюсь, когда еду в Краков, Познань или Гданьск.Хорошо, а как насчет путешествий и отпусков? Смотреть необработанные данные GPS приятнее, чем семейные фотографии! Это фантастическая конференция JCrete (un):
draw_map(df, sg.box(23.4, 35.15, 24.3, 35.65))
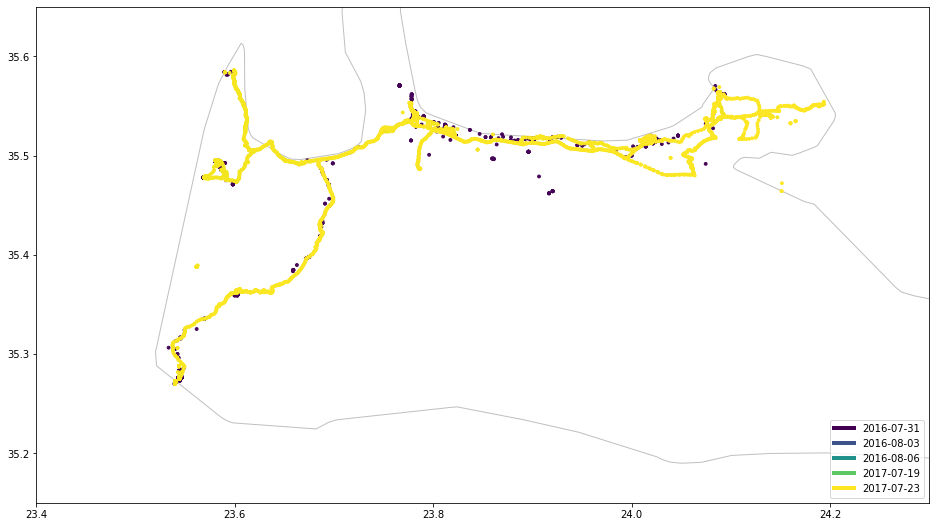
Судя по всему, я был там дважды в 2016 и 2017 годах, однако в 2016 году данные намного ограниченнее. Имеет смысл, поскольку с 2017 года мобильный роуминг стал практически бесплатным в Европейском Союзе, поэтому у моего телефона было гораздо больше возможностей шпионить за моим местоположением. Годом ранее я большую часть времени был офлайн. Еще интересные карты: отдых на Шри-Ланке:

… И Таиланд / Камбоджа / Вьетнам:
draw_map(df, sg.box(95, 6, 112, 17))
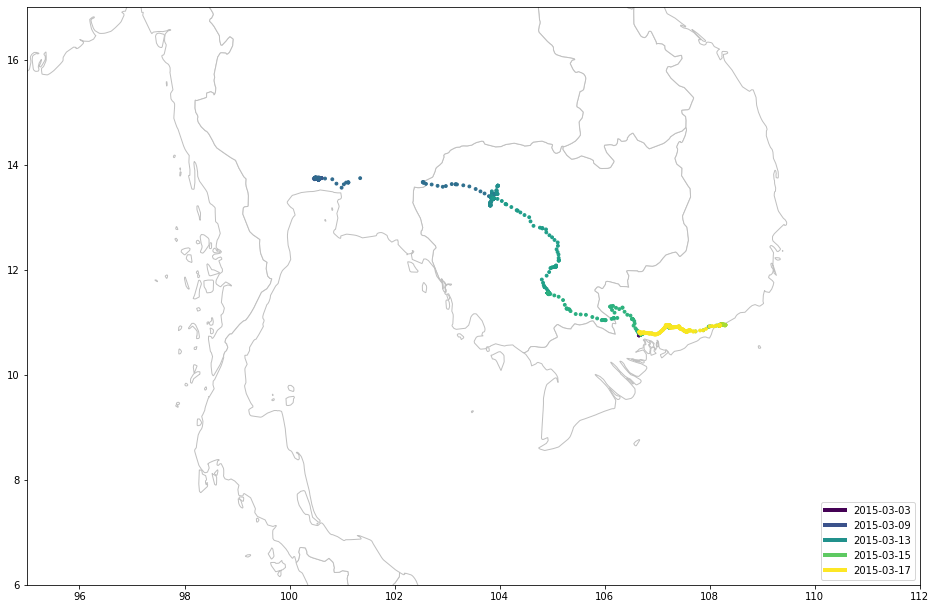
Как видите, я люблю гулять во время отпуска.
Сколько данных собирал Google за день?
Один миллион точек данных за 8 лет составляет в среднем несколько сотен местоположений, собираемых ежедневно. Однако он сильно варьируется. Я хотел найти дни, когда Google собирал намного больше данных:
def dt_to_date(dt): return dt.date() def aggregate_by(df, fun): tuples = [(activity, df[df.activity == activity].groupby(df.timestamp.apply(fun)).activity.agg('count')) for activity in df.activity.drop_duplicates()] return pd.DataFrame(dict(tuples)) by_day = aggregate_by(df, dt_to_date) by_day.plot(figsize=[20,10])
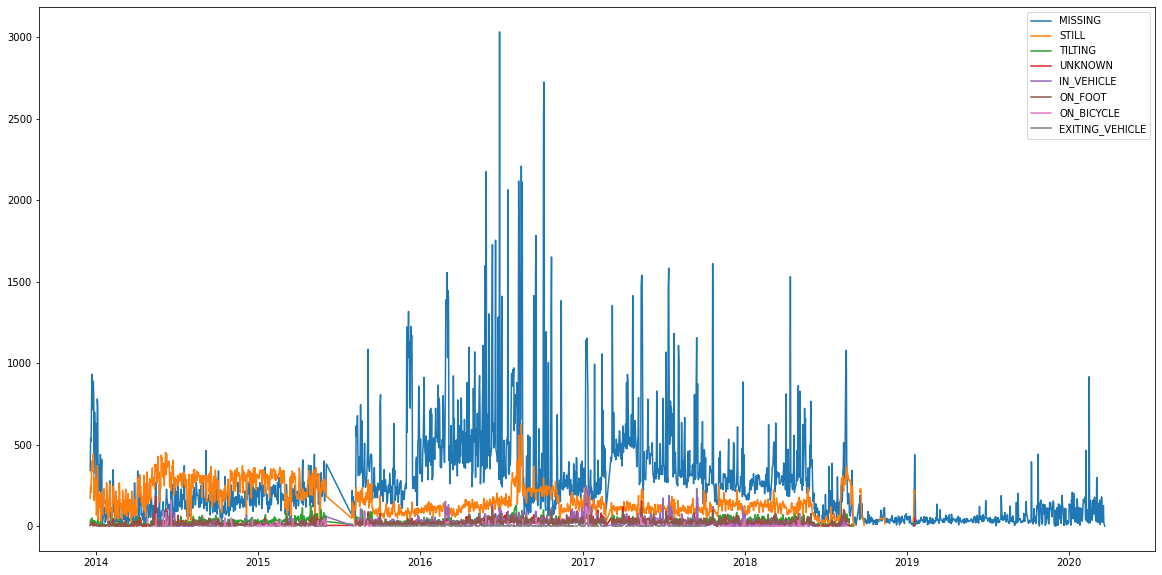
Святой дым, 3 тысячи наблюдений 28 июня 2016 года! Разделим это по часам:
busy_day = df[df.timestamp.apply(dt_to_date) == dt.date(2016, 6, 28)] busy_day.groupby(busy_day.timestamp.dt.hour).agg('count').geometry.plot.bar(figsize=[12, 9])
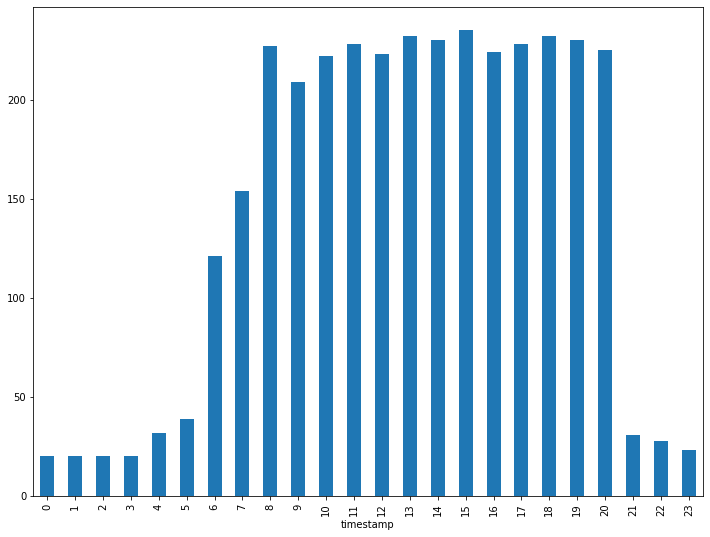
Почти 250 точек данных всего за час!
Гистограмма высоты
И последнее, но не менее важное: давайте посмотрим на гистограмму моей высоты с течением времени:
df.altitude.plot.hist(figsize=[20,10], bins=200, log=True)
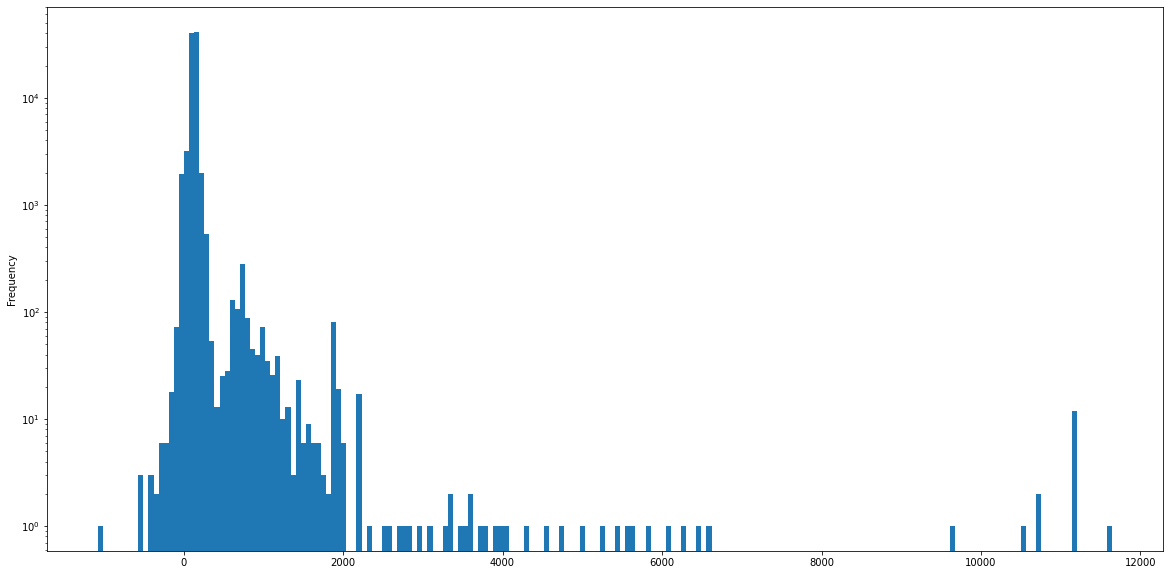
Обратите внимание на логарифмическую шкалу. Режим около 130 метров, что имеет смысл - я живу в Варшаве. Кроме того, я очень редко бываю на высоте более 2000 метров - опять же, самая высокая гора в Польше находится на высоте 2499 метров над уровнем моря. Все, что выше, либо за границей, либо измерения внутри самолета.
Выводы
Хорошо, рисование кучи диаграмм, очевидно, не делает меня специалистом по данным. Но все равно выглядит круто. Кроме того, удручает то, сколько данных мы готовы отдать. Имейте в виду, что это лишь малая часть того, что есть у одной из многих корпораций. Полный Notebook, включая все изображения, доступен на GitHub. Конечно, за исключением необработанных данных о местоположении, потому что я ценю свою конфиденциальность...

