
Сотрудники ECOMMPAY IT Ярослав Саган и Николай Нестеренко на конференции HighLoad++2019 рассказали об архитектурном решении для компактного хранения логов в ClickHouse.
На основе их доклада я сделал статью с расшифровкой, так как тема оказалась полезной.
(Ярослав Саган) Мы расскажем о том, как делали архитектуру для компактного хранения логов в ClickHouse; как прикручивали Kibana для просмотра логов, их фильтрации и аналитики. А также расскажем, с какими трудностями столкнулись и что у нас получилось в итоге.
Видео:

Несколько слов скажу о компании:
- Мы работаем в IT-подразделении компании «Ecommpay». Это международный платежный провайдер и прямой эквайер.
- Компания обеспечивает прием платежей и проведение выплат, как при помощи банковских карт, так и с помощью других платежных методов.
- У нас работает более 700 человек в 7 странах мира.
- Это очень ответственная сфера, потому что мы работаем с деньгами, причем преимущественно с чужими деньгами. Поэтому нам необходимо постоянно следить за работой наших сервисов, чтобы уметь оперативно реагировать на различные возникающие проблемы, а также чтобы постфактум иметь возможность знать, когда и какие операции мы совершали. Ежедневно у нас проходит более миллиона транзакций и по всем необходимо сохранять данные.

За последние несколько месяцев данные хранятся в горячем хранилище для оперативного доступа, а именно в ELK стеке. Затем старые индексы отстреливаются, пакуются и все это переезжает в холодное хранилище.
И сегодня мы расскажем об эксперименте, который мы поставили в RND-отделе для хранения, анализа логов в ClickHouse и Kibana.
(Николай Нестеренко) Все началось с того, что наша инфраструктура, основанная на Elastic, перестала справляться с теми объемами данных, которые начали ей поступать. Ежедневно на миллионы транзакций у нас пишутся миллионы логов. И все это занимает до несколько терабайтов в Elastic в день. И в итоге наши хранилища для оперативного доступа выросли где-то до 80 терабайтов.
И, к сожалению, это негативно сказалось на скорости их работы. У нас начали тормозить запросы в Elastic. Стали жаловаться пользователи. И в итоге мы решили попробовать научиться хранить логи более компактно и более эффективно с ними работать, но при этом не потеряв в функциональности, что для нас очень важно.

И вместо Elastic мы решили взять ClickHouse по следующими причинам:
- Из-за очень высокой скорости работы. Наверное, это самая быстрая из доступных СУБД.
- Из-за эффективного сжатия данных.
- Из-за большого числа агрегатных функций, которые могли бы в дальнейшем нам пригодиться для анализа и мониторинга логов.
- Кроме этого, у нас уже был схожий опыт по замене Elastic на ClickHouse. Мы сделали свою версию Jaeger. Это распределенный трейсер на базе OpenTracing с хранилищем данных в ClickHouse. Результат нас устроил и по скорости работы, и по объему базы. Все было хорошо. И что-то подобное мы хотели бы иметь и для логов.

Но у ClickHouse есть некоторые ограничения:
- В процессе работы нам сильнее всего мешала жесткая схема данных. Т. е. нам нужно думать о структуре хранимых типов данных.
- Всего один разреженный индекс на таблицу.
- ClickHouse плохо справляется с частыми вставками в него.
Есть еще один момент, по которому ClickHouse не может выступать полноценной заменой для Elastic. И нам это нужно учесть. О чем идет речь, как вы думаете?
Полнотекстовый поиск.
Да, но мы его мы коснемся немножко дальше.

(Ярослав Саган) Прежде чем кидаться на амбразуру и внедрять ClickHouse для хранения логов, нужно понять, чем для нас полезна Kibana и какие сценарии использования есть у нас в компании.
В первую очередь, конечно, это просмотр логов. Мы хотим логи видеть, смотреть на них, читать их. Это очевидно.

Логи у нас пишутся структурированно и в формате JSON. Помимо текста сообщения там могут быть дополнительные атрибуты. Например, информация о том, где и когда была сделана запись, имя хоста, PID процесса. Это может пригодиться системным администраторам для выборки всех логов с какого-то сервера по его имени.
Фильтрации бывают разные. Фильтрация тоже нужна.
Поиск и особенно полнотекстовый поиск нужен в первую очередь саппорту. К ним чаще всего обращаются для выяснения деталей по той или иной транзакции. Например, если она зависла или платеж был отклонен. А если платеж был отклонен, то по какой причине. Или когда платежная система затупила, к ним приходят с этим вопросом.
Основной кейс для техподдержки заключается в поднятии всех логов по определенной транзакции по номеру. Причем номер транзакции может быть в одном из нескольких текстовых полей. Местоположение этих данных четко не детерминировано. К тому же поиск может быть не только по этим полям, поиск может быть по имени нашего клиента, по платежной системе. Вариантов масса. Поиск нужен.
Помимо поиска нам также важно следить за состоянием нашей системы и интегрированных с ней платежных систем. Это уже задача на стыке технических и бизнесовых сфер. Например, нам важно знать, сколько за единицу времени у нас инициируется новых транзакций. И все это в срезе по клиенту, по платежной системе. Или сколько транзакций доходят до финальных статусов и какие это статусы вообще.
Такого рода информация сама по себе уже полезна. Но двойной профит от ее использования есть, если видеть это все в динамике. Т. е. если количество инициируемых транзакций падает либо количество успешных уменьшается, а количество declines при этом растет, то это все сигнализирует о том, что где-то есть проблема: либо на нашей стороне, либо на стороне платежной системы. И ее нужно отдельно исследовать, и обратить на нее внимание.
Получается, что Kibana всем хороша, кроме того, что она не умеет работать с ClickHouse. И нужно понять, есть ли какие-то альтернативы, способные работать с ClickHouse, но обладающие хотя бы частично той же функциональностью, что и Kibana.
(Николай Нестеренко) Мы можем взять Grafana или приспособить что-то более узкоспециализированное типа LogHouse, например. Но, к сожалению, ни одна из рассмотренных нами альтернатив, а их очень мало, нам не подходит по функциональности: где-то в области поиска, где-то в области мониторинга нам чего-то не хватает.
А со стороны Kibana у нас уже давно работают и саппорт, и тестировщики, и аналитики. Она всех всем устраивает. И по возможности нас просили ее оставить. В итоге мы решили, что так было бы удобней всего. И нам нужно научить Kibana работать с ClickHouse.

Для этого мы рассмотрели 2 возможных способа. Можно сделать свой форк, как мы делали с Jaeger, но это очень непросто. Во-первых, сама Kibana очень большая, а, во-вторых, она совершенно не приспособлена для добавления в нее новых источников данных. Там во многих местах завязано на Elastic, так что был риск влезть в это и обратно уже не вылезти никогда.
А, во-вторых, если в будущем мы захотим проапдейтить свою Kibana, то все эти изменения нужно будет продублировать там тоже. Это очень неудобно.

И поэтому мы решили идти по другому пути и сделать независимый адаптер, чтобы вывести в него весь функционал. Такое решение легче будет и разработать, и сопровождать. А также переход на новые версии Kibana для нас будет не таким болезненным.
Однако есть и минус. У нас будут временные потери в адаптере при конвертации данных между разными форматами. Но, в принципе, этим можно и пренебречь. Запросы идут не слишком часто, а логов много, так что на фоне работы в ClickHouse этот overhead у нас просто затеряется.
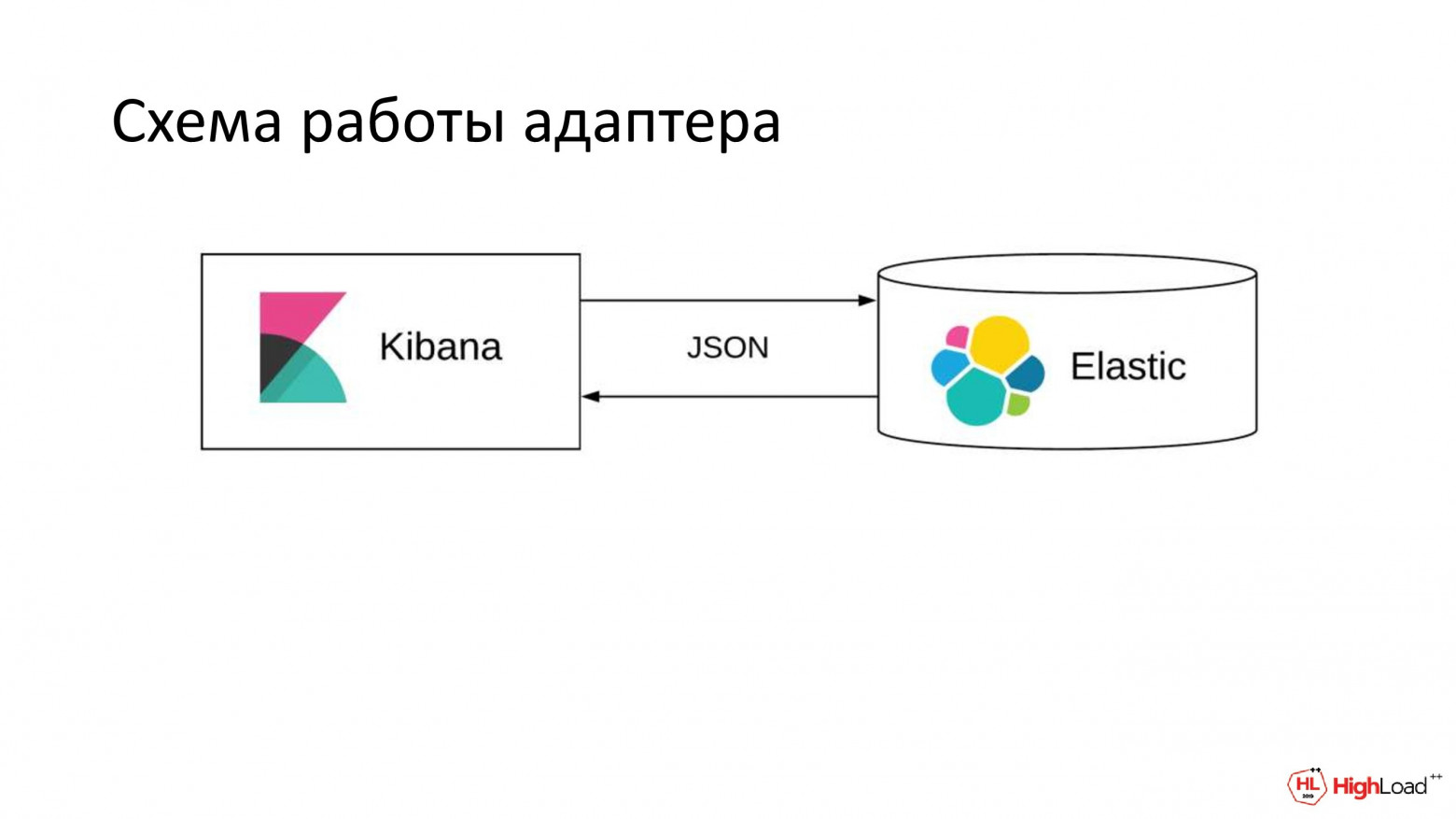
Вот такая схема у нас сейчас есть. Чтобы разбить эту связку, нам достаточно в конфигурационном файле Kibana заменить один параметр. Он указывает, на какой адрес нам слать запросы в Elastic.

Вот такую схему мы хотели бы иметь. У нас есть внешний адаптер. Мы решили назвать его Kibouse. Он будет брать данные из Kibana; разбирать их и строить на их основе один или несколько SQL-запросов; идти с ними в ClickHouse, брать данные и отдавать в ClickHouse ответ, в понятной для нее форме.
Elastic в этом случае нам, в принципе, уже не нужен, разве что можно импортировать из него настройки для Kibana. Они хранятся там в отдельном индексе: графики, дашборды, индексы.
Но даже в этом случае связь с Elastic нам нужна будет только один раз, т. е. при первом запуске, а затем мы его выключаем.

(Ярослав Саган) И чтобы научить Kibana работать с ClickHouse, т. е. чтобы хоть как-то подойти к этому «снаряду», нам необходимо реализовать следующее:
Научиться доставлять логи для ClickHouse.
Запустить Kibana таким образом, чтобы она за данными ходила в ClickHouse.
В том числе и настройки свои тянула оттуда же.
Реализовать некоторую часть функционала Elastic.

Начнем с доставки логов. Логи у нас пишут в файлы. И дальше идут до Logstash. Logstash можно трактовать как некий префильтр, в котором можно предварительно сделать обработки по логу; докинуть дополнительные атрибуты, если нужно. И также здесь нужно подготовить данные для вставки в ClickHouse.
Но следует учесть некоторые особенности нового хранилища.
Во-первых, это строгая схема хранения данных, строгая типизация в ClickHouse. Логи лучше писать и хранить структурированно. И у себя мы, например, разбираем вложенный JSON и сразу раскладываем по колонкам будущей таблички. Дополнительно генерируем здесь уникальный id и уточняем timestamp. Все это пригодится затем для Kibana при запросах от нее.
Другая особенность вытекает из того, что основной и, наверное, наиболее функциональный вид движков для работы с данными в ClickHouse – это семейство MergeTree. Какая там есть особенность?
Много вставок.
Правильно. Дело в том, что при inserts данные там не пишутся в какой-нибудь Main table и лог записей тоже не ведется. Данные пишутся сразу на диск по колонкам, а в фоне уже происходит слияние сортированных кусков.
Из этого следует, что оптимально сделать только вставку батчами, не чаще, чем раз в секунду. В противном случае постоянные вставки и слияние будут насиловать диск. И это все приведет к тому, что на определенном этапе вся система встанет. А логи у нас пишутся постоянно, при этом в них есть данные, содержащие информацию о финансовых транзакциях, т. е. терять мы ничего не хотим, не можем.

Поэтому мы выбрали способ гарантированной доставки через Kafka.
С некоторых пор, по-моему, стараниями Cloudflare механизм наполнения ClickHouse’ных табличек через Kafka встроен в ядро ClickHouse.
Как это работает? Logstash при помощи нативного плагина пишет данные в Kafka. А на стороне ClickHouse одноименный движок Kafka вычитывает эти данные. Движок Kafka – это даже не совсем табличка. Это, скорее, консьюмер в консьюмер-группе. Данных он в себе не хранит. Мы можем обратиться к нему как к табличке и сделать select всех заполненных данных, выбрать их, но такая операция не будет идемпотентной и следующий select уже данных не вернет, просто потому, что offset закомитился и ушел дальше по partition.
Именно поэтому здесь на схеме присутствует материализованное view. Его основная задача – получить данные из … Kafka и положить уже в конечные MergeTree-табличку.
Чем еще нравится такая схема? Тем, что можно достаточно просто увеличить проходимость по доставке логов. Мы можем сделать не одну ноду ClickHouse, а сделать из нее кластер. При добавлении дополнительной ноды в этот кластер, новая нода будет также поллить (poll?) из своего partition в Kafka данные. Это все легко масштабируется.
Еще один плюс. Мы можем относительно безболезненно терять эти ноды в кластере. Если она упала по какой-то причине или мы сами ее захотели выключить, то ничего страшного не произойдет. Произойдет просто ребаланс на стороне Kafka. И те partitions, которые обслуживались раньше упавшей нодой, перейдут на другую. И для консьюмера этих логов, для потребителя внешне ничего не изменится.
В общем, мы записали данные в MergeTree-табличку. Данные там индексируются по timestamp, потому что нам не нужны все логи всегда. Как правило, мы хотим их видеть за какой-то период времени. И, к счастью, Kibana такой интервал нам присылает в каждом из запросов.

(Николай Нестеренко) Логи мы храним. Теперь можно запускать саму Kibana. А для этого ей надо эмулировать связь с Elastic. Дело в том, что ежесекундно она шлет в него несколько запросов. Условно, это все разные healthcheck. Их у нас штук 10 или 15 разных. Но ни сами эти запросы, ни ответы на них со временем не меняются.
Мы можем это все у себя сохранить и по мере надобности отдавать в Kibana уже сразу готовый ответ.

Также для удобства настройки тоже лучше импортировать из Elastic в ClickHouse, так как в ClickHouse нет операций delete и update. Чтобы с настройками можно было что-то в реальном времени делать, например, апдейтить их из графического интерфейса Kibana, мы используем специальный движок. Он называется CollapsingMergeTree. Он умеет удалять одинаковые строки, отличающиеся одним специальным атрибутом. Обычно его называют sign. И он может иметь 2 значения: 1 или -1. И при merge две одинаковые строке с разным sign у нас схлопываются.
А selects мы делаем с ключевым словом FINAL, чтобы иметь сразу обработанные данные, не дожидаясь очередного merge. Так делать не рекомендуют из-за того, что FINAL плохо влияет на скорость выборки. Но для нас это не критично, т. к. в настройках мало данных обычно. А также сами запросы идут не слишком часто, так что мы можем себе это позволить. Это самый удобный способ для работы с движками такого типа.
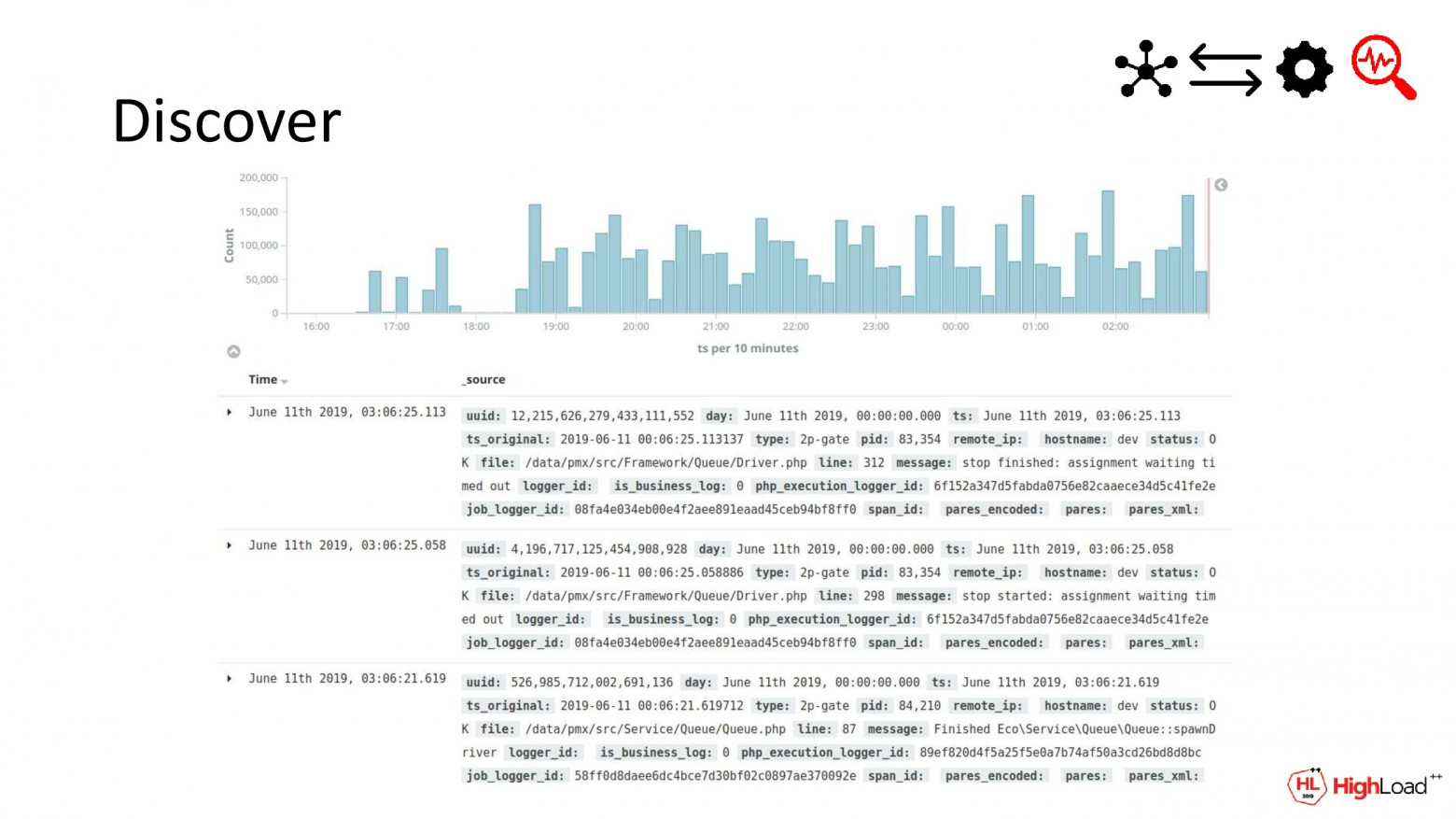
(Ярослав Саган) Вот мы запустили Kibana. Направили запросы от нее в наш адаптер, который прикинулся Elastic. И теперь нужно перейти к реализации необходимой функциональности Elastic.
В частности, нужно как-то уметь отображать во вкладке Discover в Kibana логи. Там мы показываем логи за какой-то период либо по условию, либо без него. Например, мы хотим здесь отобразить логи, отфильтрованные по имени хоста.

(Николай Нестеренко) И делается это несложно. У себя в адаптере мы разбираем JSON в формате Elastic. И строим на его основе один SQL-запрос. По индексу определяем целевую таблицу; по query – условия выборки; по sort – порядок сортировки и по size – число записей. И идем с этим в ClickHouse
Но еще в Elastic можно было брать данные сразу из нескольких индексов по шаблону. В ClickHouse это тоже можно сделать. Для этого мы берем движок Merge. Он умеет выбирать данные сразу из нескольких таблиц с именами, удовлетворяющими регулярному выражению. Правда, в отличие от Elastic структура у этих таблиц должна быть у всех одинаковой.

(Ярослав Саган) Но есть несколько проблем.
Первая – это то, что у нас не получится полноценно использовать индексы в ClickHouse. Дело в том, что на одну табличку там возможен только один индекс. А он у нас уже есть, он у нас по timestamp. Получается, что при фильтрации по имени хоста ClickHouse придется вычитать все логи за интервал и пройтись по ним. Он это сделает, но индекс не задействует.
Вторая – это то, что в ClickHouse нет полнотекстового поиска, т. к. инструмент предназначен несколько для других целей. Но такая функциональность нам нужна, поэтому нужно что-то с этим делать.

(Николай Нестеренко) И мы решаем обе эти проблемы на базе обратного индекса.
Обратный или инвертированный индекс – это такая структура данных, в которой можно по слову найти все записи, в которых это слово содержится. Например, слева у нас есть логи. Чтобы сформировать по ним обратный индекс, нам надо разобрать их все на слова и записать эти слова по одному в новую табличку, т. е. слово и идентификатор лога и т. д.

Индексируется это все по словам. И если мы захотим что-то найти в основных логах, например, все записи, в которых есть 2 слова: «А» и «Б», то вначале мы идем в обратный индекс и выбираем из него все идентификаторы логов, для которых у нас выполняется 2 условия. Во-первых, на каждый идентификатор у нас в таблице должно быть 2 разных слова. Uniq (word_id) – это тоже самое, что и count distinct (word_id) в обычном SQL. Во-вторых, эти два слова могут быть или «А», или «Б».
Таким образом мы находим все логи, в которых есть эти два слова и неважно в каком месте, и в каком порядке. Главное, чтобы они там были.
Искать можно и по одному слову, но в этом случае это будет что-то типа аналога для встроенных в СУБД индексов просто для ускорения поиска.

Это все в теории, а на практике нам еще нужно индексировать все входящие логи.
Вот такая схема у нас сейчас есть для доставки.

Мы добавляем в нее еще один процесс. Он называется Indexer. Его задача вычитывать логи из Kafka и разбирать их на слова.
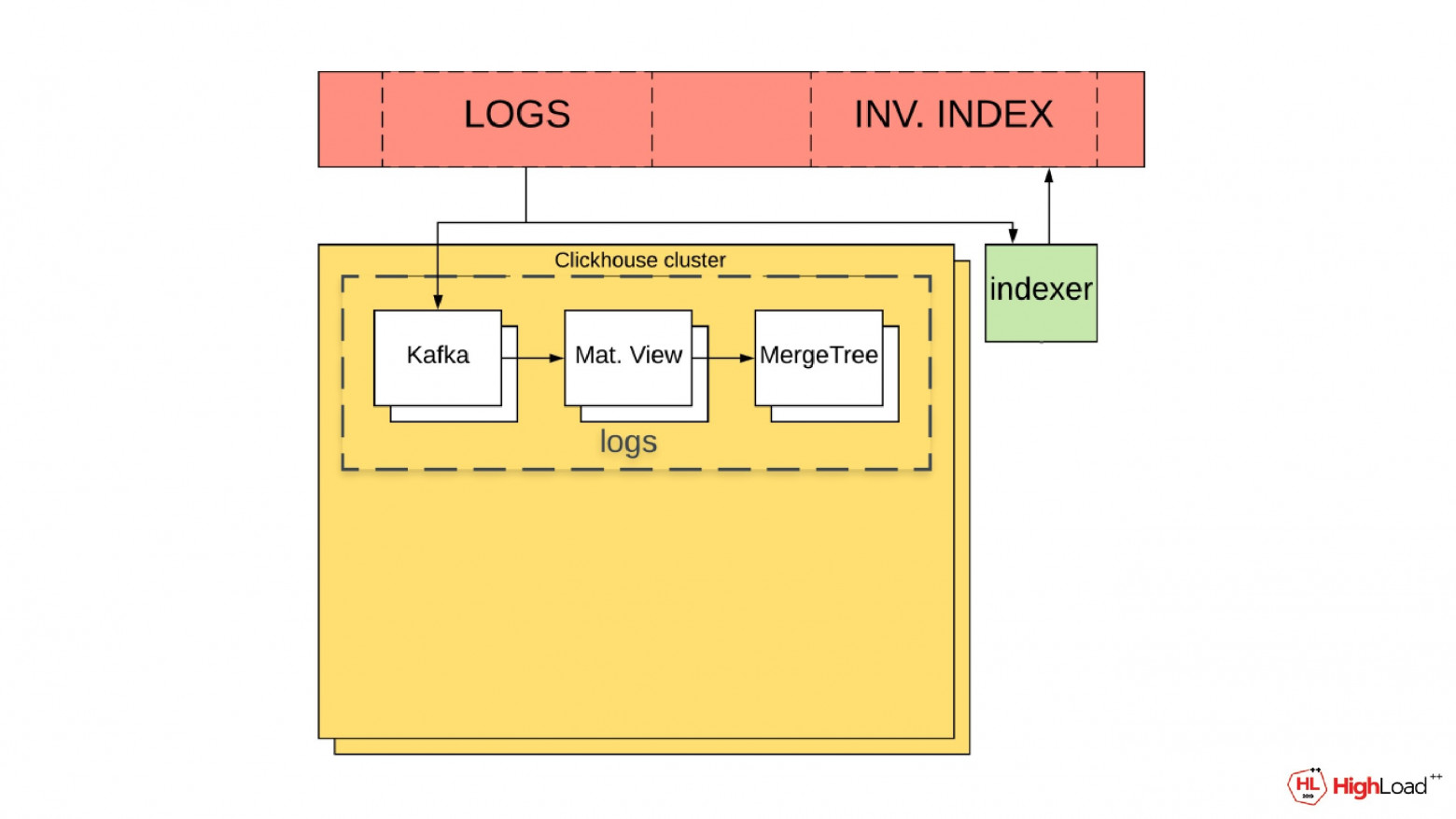
А затем в новый топик для инвертированного индекса он запишет слово, идентификатор лога, timestamp лога и колонку, в которой это слово нам встретилось.
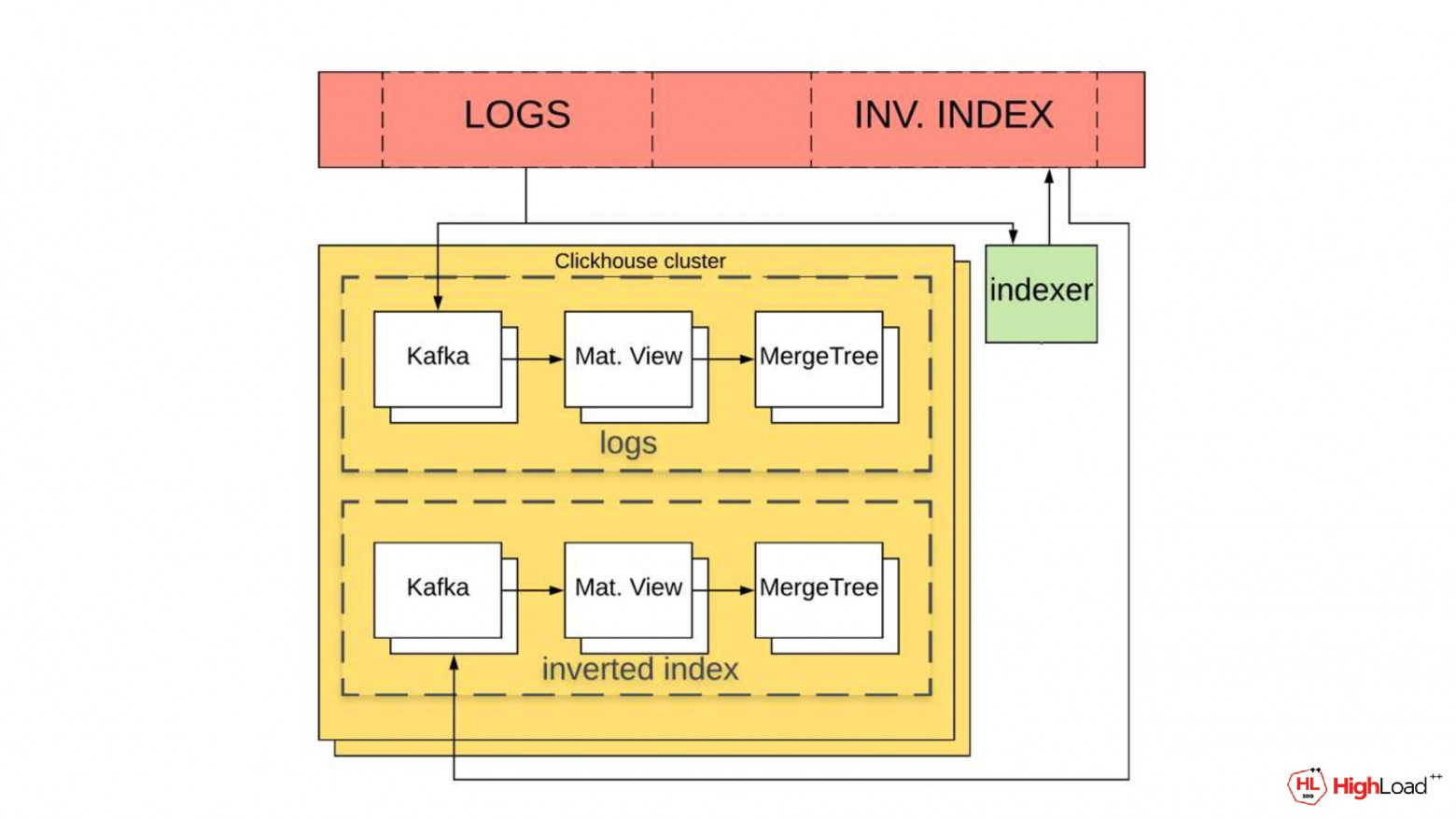
А из Kafka по той же схеме, что и логи, данные запишутся в ClickHouse.
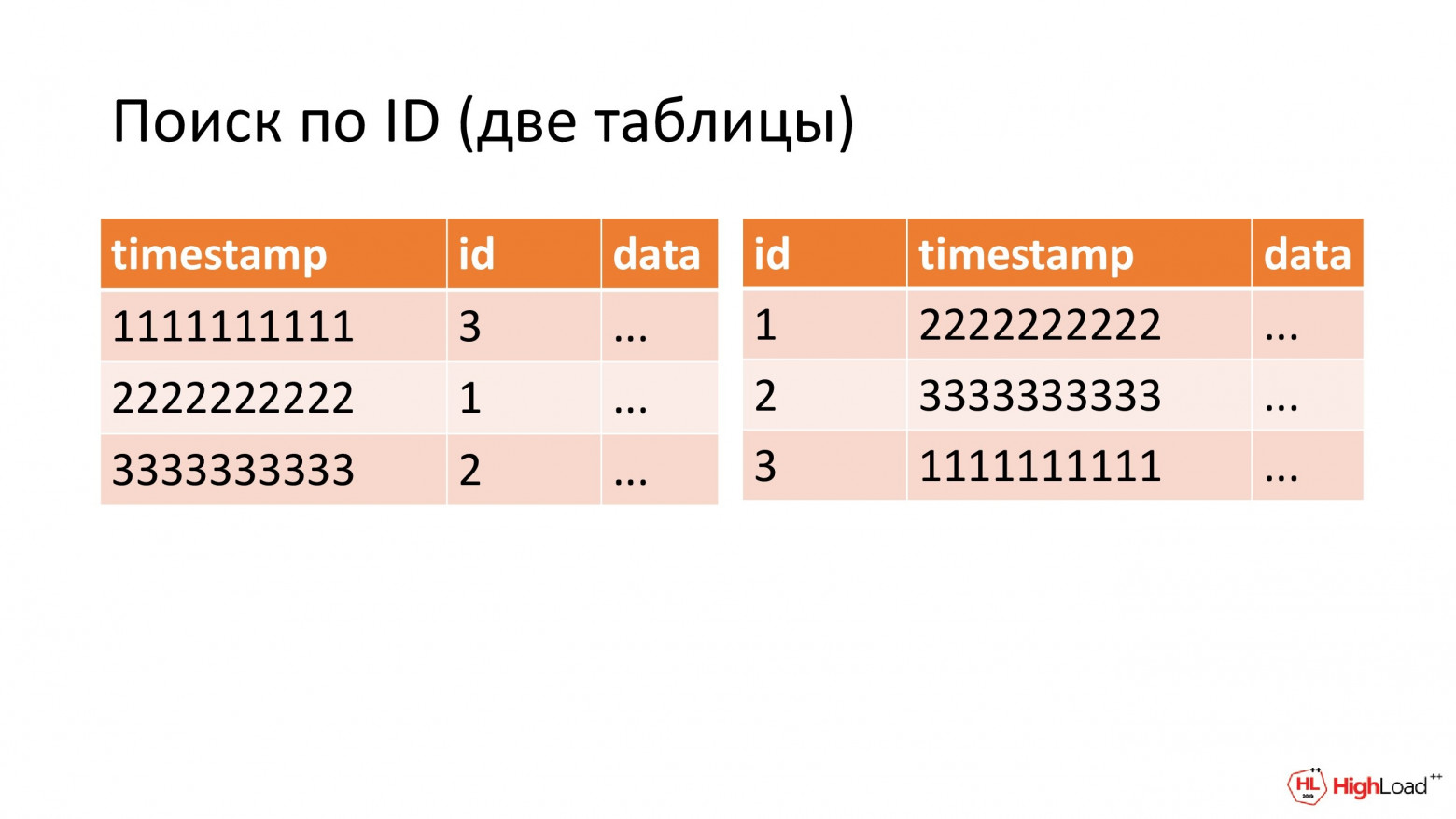
(Ярослав Саган) Чтобы эффективно использовать такой обратный индекс, надо как-то научиться быстро искать в логах записи по их идентификаторам.
Так как мы говорили, что индекс уже есть и он по timestamp, то для того чтобы сделать новый индекс по id, как вариант, можно использовать вторую табличку.
Она будет содержать те же самые данные, но другой индекс. И я здесь специально говорю «табличку», а не материализованный view, потому что в ClickHouse нет поддержки каскадных материализованных views. Нельзя сделать mat view на табличку, которая бы уже сама запопулитилась из mat view. А первое материализованное представление у нас уже есть по схеме доставки логов.
Вот у нас есть 2 таблички. Первая проиндексирована по timestamp, вторая проиндексирована по id. Чем такой вариант плохой?
Дублирование.
Да, получается дублирование чересчур избыточное.
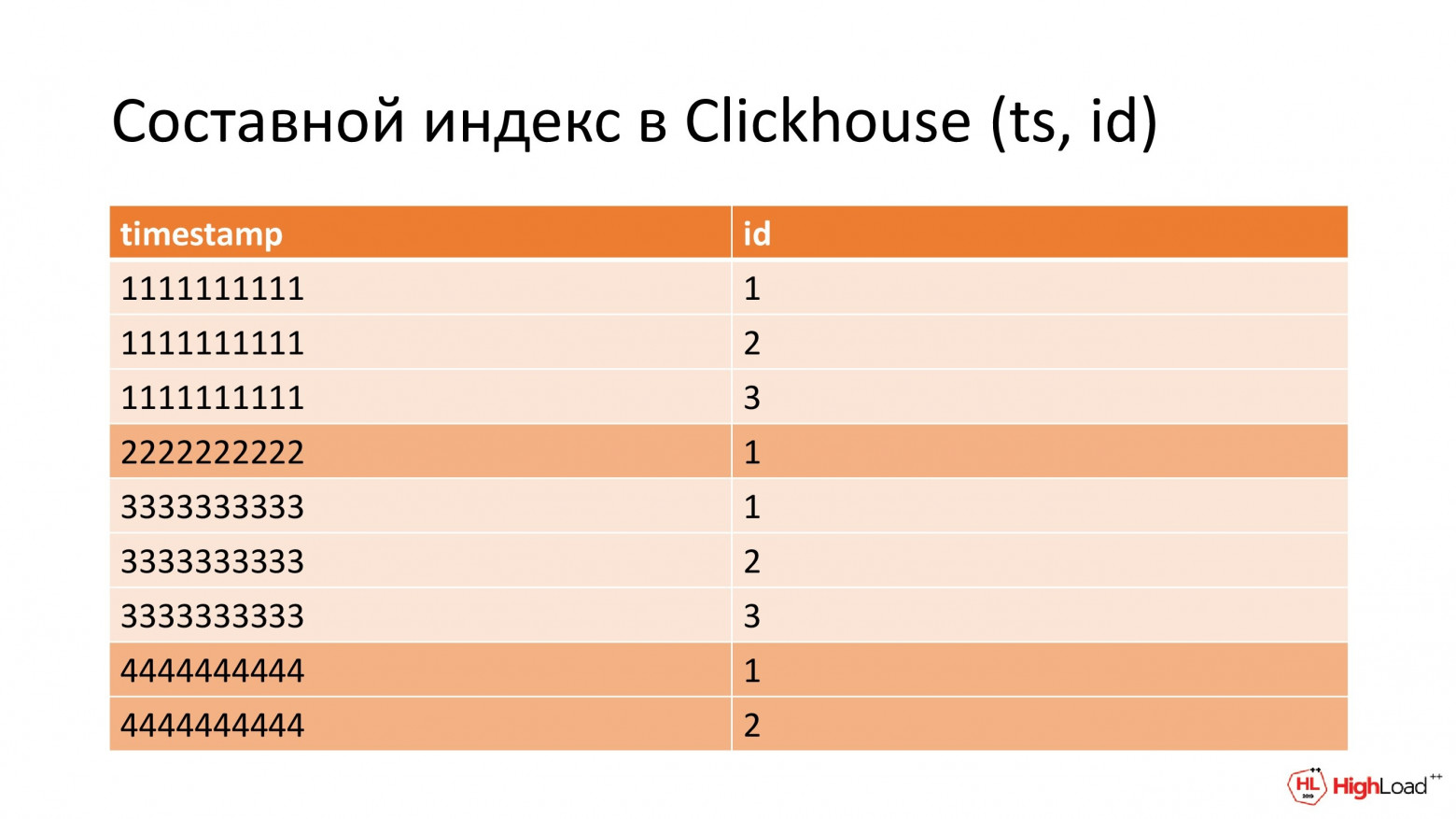
Другой вариант – это использовать составной индекс по timestamp и идентификатору. Его можно представить в виде списка, отсортированного сначала по первому атрибуту, а затем внутри сегмента с одинаковым timestamp отсортированный по id.
Чтобы при поиске по идентификатору этот индекс был задействован, нам нужно явно указать timestamp. Однако на момент такого поиска этой информации еще нет.

Выход – сохранять лог 2 раза. Первый раз с нормальным временем, второй с синтетическим, т. е. нулевым. И тогда при поиске по идентификатору нужно будет просто в условии указать, что timestamp=0, и мы проскочим первый атрибут, и задействуем вторую часть индекса.
Такой вариант, возможно, лучше, чем полное дублирование табличек, но он тоже весьма затратный по памяти, особенно, если учитывать, что ClickHouse по-разному сжимает данные в зависимости от индекса.
Так мы опытным путем установили, что проиндексированные данные по id занимают место на диске раза в 2 или 3 раза больше, чем индексированные данные по timestamp. И в конечном счете получится, что на один мегабайт логов нам пришлось бы хранить до 10 мегабайтов вспомогательных данных. Так себе решение, нужно как-то улучшать.
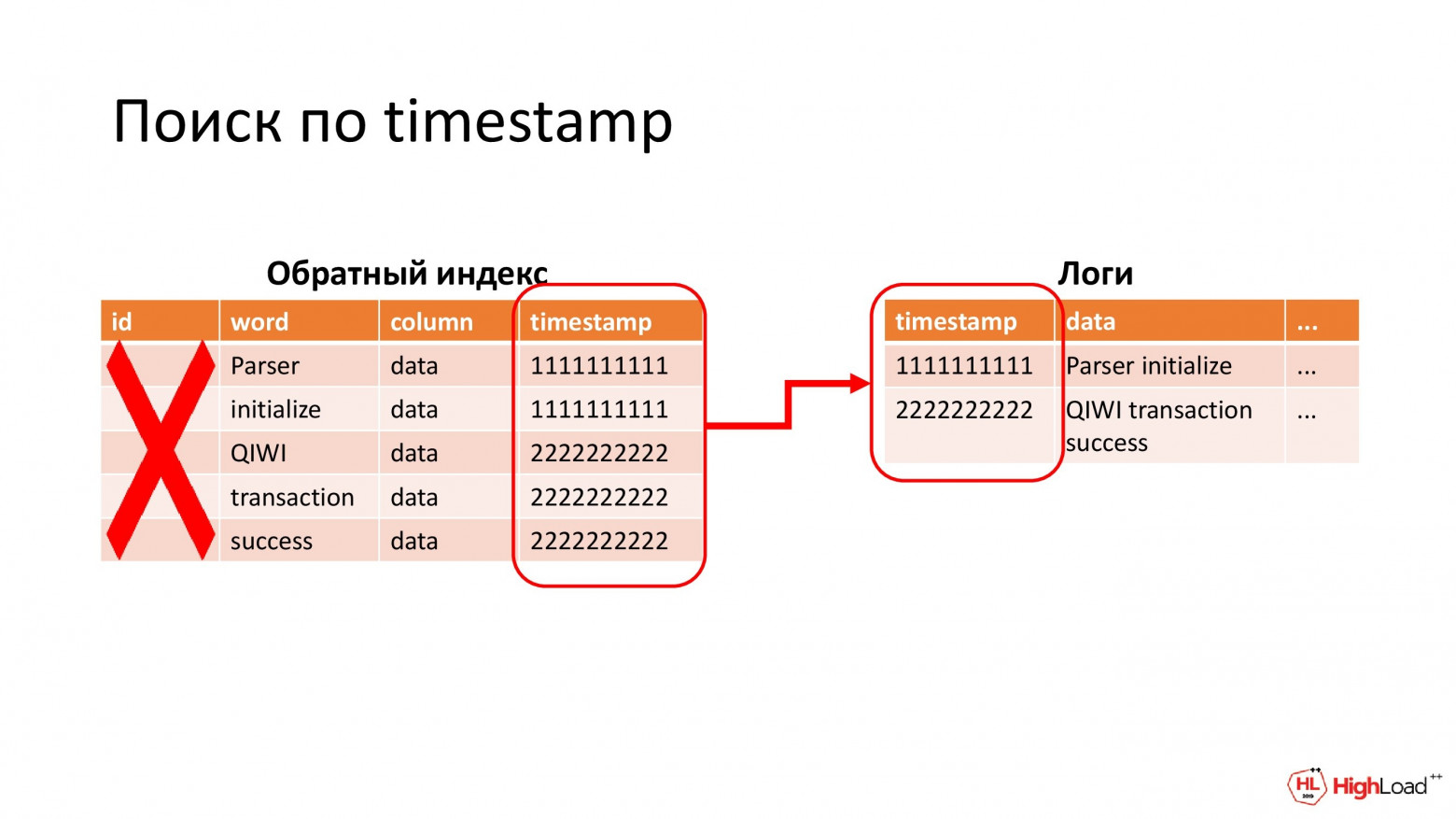
(Николай Нестеренко) Мы стали это все оптимизировать. И вначале хотелось бы избавиться от дубликатов. Для этого мы решили пойти на компромисс и отказаться от выборки из обратного индекса идентификаторов логов вообще. Т. е. вместо этого в записи мы это идентифицируем по их timestamp.
Это будет работать, если timestamp сделать максимально точным: до микро, а лучше до наносекунд. Кстати, мы это в Logstash делаем. И в этом случае вероятность того, что 2 лога окажутся на одном временном интервале, очень мала. Но если это все-таки произойдет, то лишние мы отсеем на более позднем этапе, т. е. уже перед отправкой ответа.
Зато, во-первых, мы избавляемся от дубликатов. Во-вторых, можем не хранить в обратном индексе атрибут с id.
Это не все наши оптимизации.
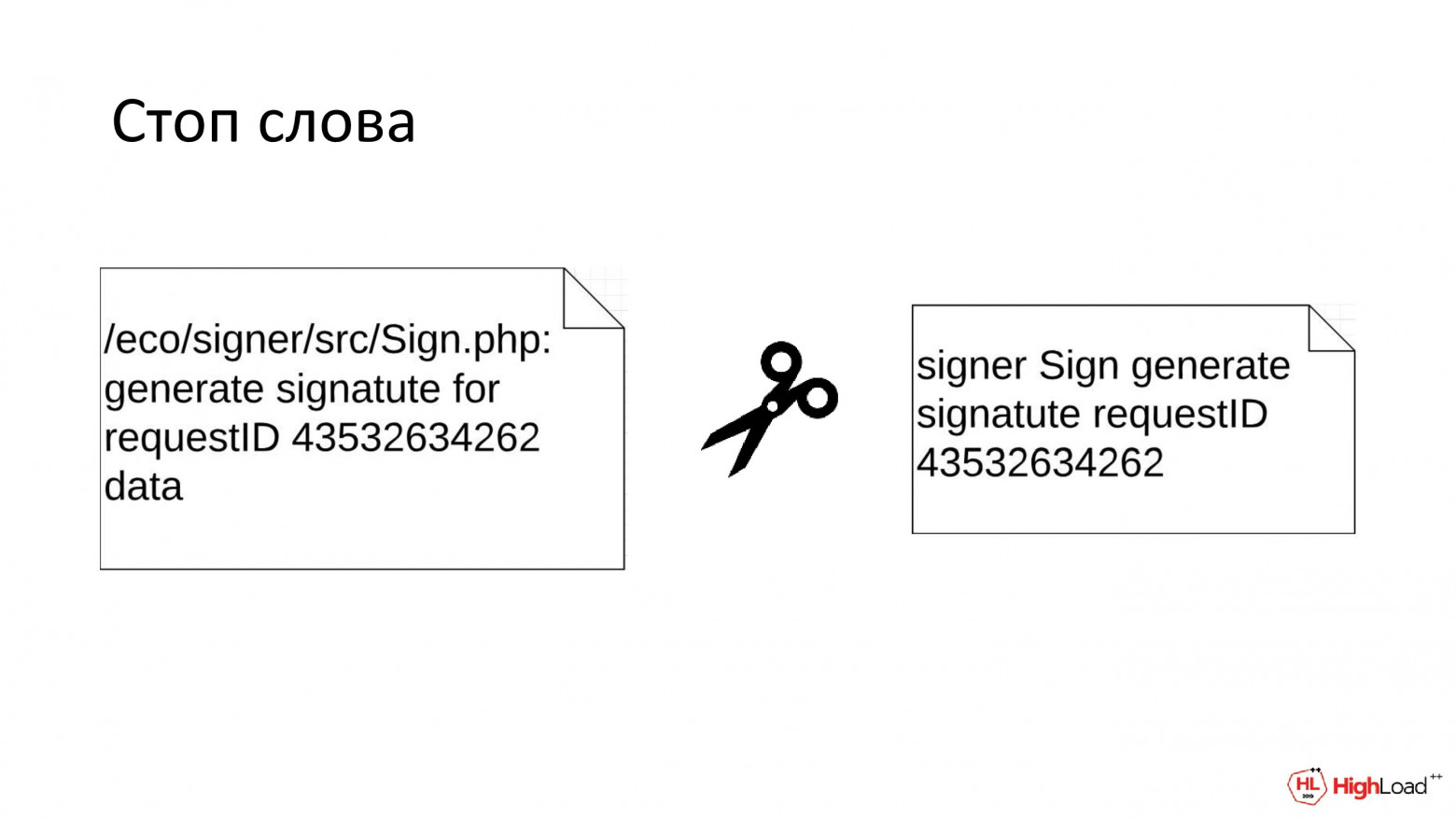
Еще можно не индексировать самые часто встречающиеся слова. В нашем случае это: eco, signer, src, php и т. д. Мы считаем, что они есть во всех записях и исключаем из обратного индекса.
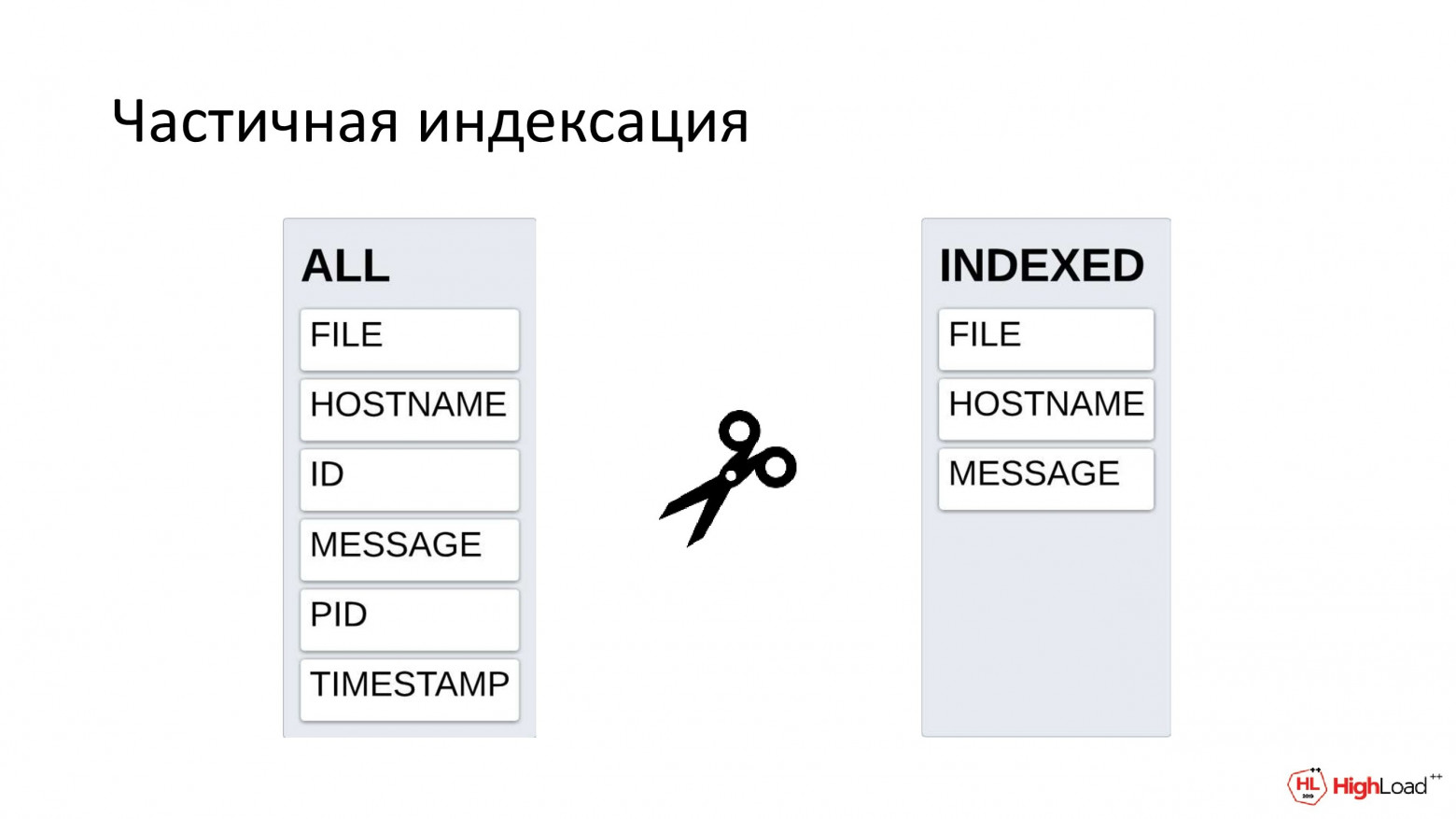
Исключать можно не только слова. Исключать можно целые атрибуты. И в итоге оставить только те из них, в которых у нас реально что-то ищут, особенно с использованием полнотекстового поиска.
Все это вместе дало нам определенный результат. На 1 мегабайт логов мы храним не 10, а 2 мегабайта вспомогательных данных. Это все еще, конечно, не очень, но уже лучше, чем в Elastic выходило по памяти и по месту.

Вот такая у нас схема индекса. Здесь еще важно увидеть, что слова мы храним не в строках, а используем UInteger. Это еще одна микрооптимизация для уменьшения объема базы. Известно, что числа сжимаются лучше, чем строки. И поэтому все слова перед записью хэшируем, используя для этого встроенный в ClickHouse cityHash64.
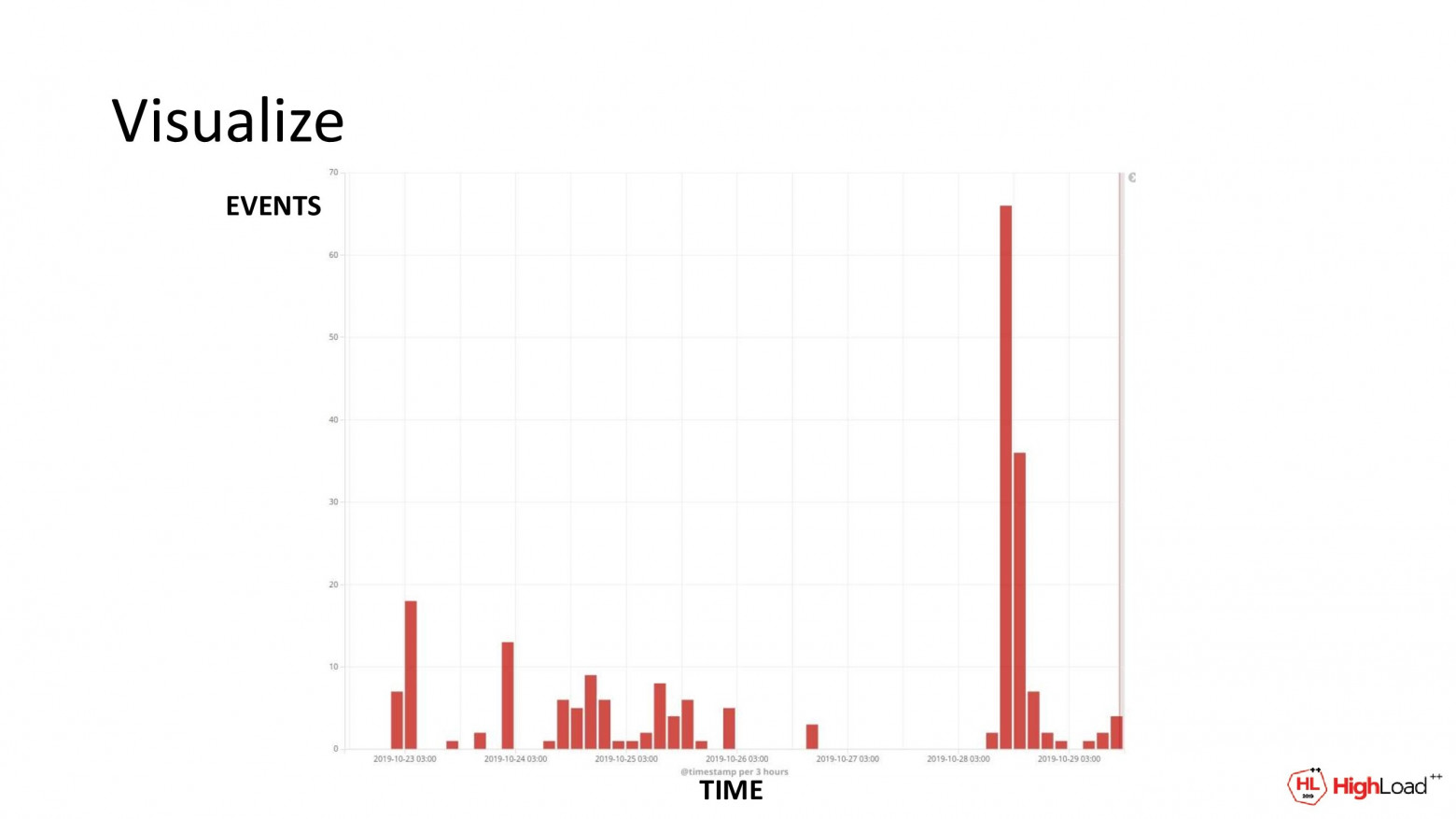
Кроме поиска нам еще и мониторинг нужен для того, чтобы следить за состоянием и нашего сервиса, и внешних платежных систем. И для этого у нас есть графики на вкладке Visualize.
Вот один из них. Здесь изображено число сетевых ошибок на единицу времени, возникающее между ядром процессинга и адаптером внешних платежных систем. У нас он называется Plus.
Ошибки мы определяем по наличию в логах специальных слов-маркеров. Здесь это response from plus и code 4. Т. е. если эти слова в логах есть, то значит у нас где-то была ошибка.
Здесь видно, что у нас был сбой в сети. Из-за этого резко выросло число ошибок. Но затем все снова вернулось в норму.
Таких графиков у нас очень много, но в целом они все типовые. Это временные ряды с числом записей, удовлетворяющие определенным условиям на интервалах времени.
В Elastic это делают с помощью агрегации date histogram, в ClickHouse мы для этого используем функции count и countIf. If говорит о том, что считаем только логи, удовлетворяющие определенным условиям. Это нам нужно для фильтров.
Условием может выступать и подзапрос. Например, для этого графика мы используем результаты выборки из обратного индекса по этим словам-маркерам: response from plus, code 4.

В целом наши запросы выглядят вот так. Вначале мы определяем, какие фильтры удовлетворяет наша запись, а затем, на какой временной интервал она приходится.
Для этого мы делим ее timestamp на фиксированную длину интервала на графике. Затем мы группируем по этому значению, чтобы высчитать статистику по всем логам на этом временном интервале.
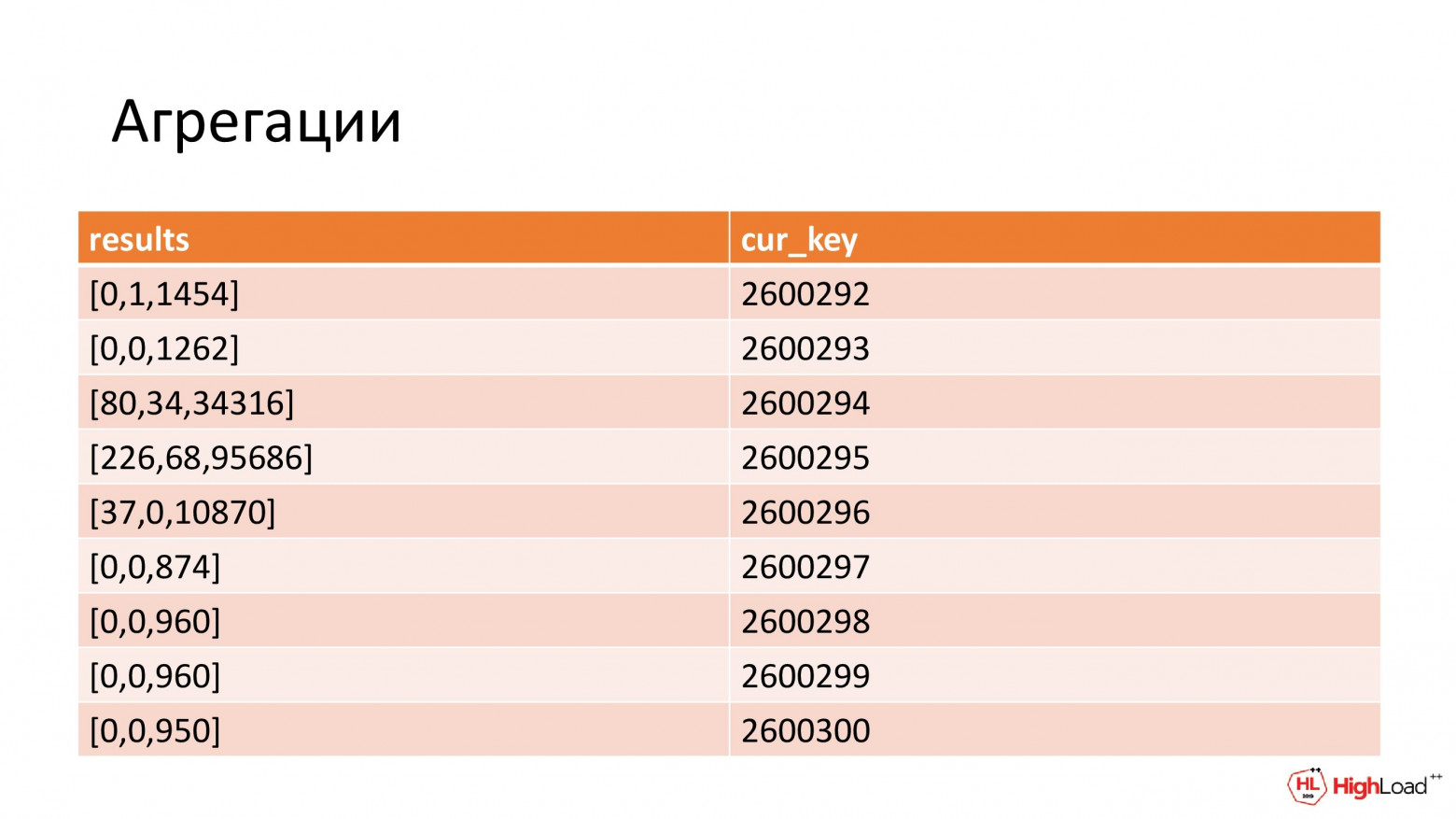
В результате у нас образуется вот такая выборка. По числу справа мы группировали. И с ее помощью можно восстановить границы интервала. А слева у нас статистика по фильтрам: по первому, второму и т. д. И в конце общее число записей. Общее число нужно для Kibana, чтобы она строила непрерывные графики. Т. е. в Elastic всегда при агрегировании есть и общее число, и по бакетам в фильтрах, а нам это нужно эмулировать.
По функциональности – это все, что нам было нужно. И поэтому на этом мы пока что остановились.
(Ярослав Саган) Давайте подведем итоги по тем действиям, которые мы совершили. И попробуем замапить на основные задачи, которые мы ставили изначально перед собой.
Организовать надежную доставку логов. Мы сделали это через Kafka. Получилось гарантированно, надежно. Нам нравится.
Эмулировать связь с Elasticsearch. Мы в Kibana поправили конфигурационный url, направили его на наш адаптер, который прикинулся Elasticsearch, а на самом деле входит в ClickHouse и настройки свои хранит там же.
По функциональности Elastic мы сделали поиск на основе обратного индекса. Обратный индекс у нас не простой, а свой. Мы там используем не идентификаторы, а timestamps в качестве идентифицирующей сущности. Затем мы индексируем не все колонки, которые там есть, а только те, которые нам нужны. И индексируем не все слова. Часто употребляемые слова мы не индексируем, считаем, что они есть во всех логах.

https://github.com/ITECOMMPAY/kibouse
Код адаптера мы заопенсорсили и выложили на GitHub в name space компании. Можете посмотреть.

Что можно сказать по итогам? На основе сделанного прототипа мы пришли к выводу, что идея использовать ClickHouse в качестве хранилища для логов имеет право на существование. Технически это реализуемо. И у этого есть свои плюсы.
В первую очередь по занимаемому месту. У нас логи в ClickHouse занимают в 2,5-3 раза меньше места, чем те же самые логи в Elasticsearch.
Что касается скорости работы, то здесь однозначный выигрыш получить не удалось. Почему? Потому, когда у нас много записей, это все работает медленно.
И оптимальный кейс для поиска для ClickHouse – это поиск по ключам, например, по номеру транзакции. В таком случае у нас найдется несколько десятков записей. Данных будет обработано немного. И практически все еще отсеется на начальном этапе при обращении к обратному индексу. В этом случае в 4-5, а иногда и до 10 раз лучше, чем в Elasticsearch. Но если условия для поиска более общие и данных найдется много, то в таком случае Kibana сработает медленней Elastic где-то раз в 5.
К плюсам Elasticsearch можно еще отнести то, что он прекрасно работает из коробки. А такая система требует дополнительной настройки и определенной дисциплины работы с этим дальше. Нужно заранее определить схему логов, решить, что именно будем индексировать и в дальнейшем всему этому следовать, чтобы следить за типами, не искать по неиндексированным колонкам, не искать по всем колонкам. Такие есть ограничения. С этим надо как-то жить.
В общем, нужно сказать, что это решение не для всех. Очень многое зависит от того, какие сценарии работы с поиском, с логами есть и от объема данных, который вы под логи себе определили.
Если в вашем случае снижение объема данных в 2-3 раза приведет к существенному уменьшению COST (Стоимости) на содержание такой инфраструктуры, то, возможно, этот вариант для вас. Если вы пользуетесь поиском и ищете небольшие группы записей, а еще лучше даже отдельные записи, то получите большой выигрыш по скорости.
В других условиях результат может сильно отличаться. Поэтому думайте, решайте, взвешивайте все «за» и «против», после этого определяйтесь.

Вопросы
Привет! Спасибо за доклад! Актуальная тема. Вы только самое главное не рассказали, а именно, как вы в JSON укладываете объект. Это первый вопрос. А второй вопрос о том, что делать, когда данные меняют тип.
(Ярослав Саган) У нас логи в обычном виде имеют вложенную структуру JSON, но так как мы не хотим использовать nested тип в ClickHouse, то мы их мапим на конечную колонку. Т. е. если объект имеет название «А», а у подобъекта имя «Б», то у нас будет отдельная колонка, которая будет называться А_Б. Мы ее в plain вид для ClickHouse распределяем.
Что делать, если меняется схема логов? В Elastic это было просто, здесь придется alter. Других вариантов нет, т. е. alter на табличку.
Т. е. если int там шел, а потом string отошел в этом же поле, то вы будете alter делать?
Да, это неудобно, согласен, но какие-то более другие крутые штуки здесь не придумаешь.
В какой момент детектите? Пришло первое поле другого типа, вы сразу alter запускаете или руками делаете?
Нет, мы заранее определяемся. Когда у нас начинают идти логи определенного типа, сменяют они тип или нет, стопорим это все, альтерим и тогда запускаем.
Команда, которая пишет логи, не обязательно вам скажет, что она поменяла тип. Неожиданно может прийти какой-то новый тип.
Да. Сразу отвечу немножко дальше. Система, которую мы сделали, у нас в прототипе. Какого-то production uses case нет, поэтому таких деталей и нет, как с этим дальше работать.
У меня был вопрос еще по поводу структуры. Когда вы вытащили из ClickHouse все данные, вы их потом в эту структуру просто из названия столбцов собираете назад, чтобы в Kibana отдать?
Да.
(Николай Нестеренко) У нас в коде есть мапинг через теги. Мы в Go это писали. И у нас висят теги: имя в ClickHouse, имя в Kibana.
(Ярослав Саган) Если с Go работали, то там можно представить ClickHouse’ную табличку в виде обычной структуры. А то, как она будет выглядеть в Kibana, как она должна сохраняться в ClickHouse, — это все делается через теги в этой структуре.
Спасибо!
Здравствуйте! Спасибо за доклад! У меня вопросов очень много было. Вы сказали, что нельзя сделать mat view поверх mat view, но это можно сделать.
Да, мы можем сделать материализованное view, но оно не будет наполняться данными. Т. е. физически нам его сделать никто не запретит.
И оно заполняется данными.
Mat view на табличку, которая сама запопулитилась из mat view?
Да.
Не работало это раньше. Есть issues на это на GitHub. Они писали, что когда-нибудь, может быть, сделаем. Не знаю, может быть, уже сделали.
(Николай Нестеренко) Обновляться там оно не будет. Все логи, что там были, в mat view будут, а если что-то новое уже…
(Ярослав Саган) Они сразу при создании появятся там.
Смотря что вы используете для Nginx. От этого зависит. Если у вас там replacingmergetree, то да, это не будет работать. Это был следующий вопрос о том, что вы используете. После Kafka у вас идет mat view, да?
Да, идет обычный ReplacingMergeTree.
Хорошо. Еще один вопрос. Вы сказали, что в timestamps лучше хранить наносекунды, но в ClickHouse все хранится максимум до секунды. Что вы делаете с этим? Там datetime 64.
Мы не datetime используем. У нас Int64 длинный и все.
Спасибо!
Спасибо за доклад! Я услышал, что ваш саппорт ходит в Kibana и ищет там по transaction id. Мне кажется, что это uses case для бэк-офиса. У вас есть бэк-офис?
У нас есть бэк-офис. У нас запросы прилетают в саппорт из разных мест. И Kibana может пользоваться не только саппорт, а и аналитики, поэтому предугадать кейс, кто туда зайдет и будет этим пользоваться, нельзя. Саппорт – это собирательный образ.
Спасибо за доклад! Я хотел бы узнать, насколько ресурсоемкая вся система и насколько стабильна по употреблению ресурсов? Не случается ли выжирания сети? Не случается ли выжирания диска? Бывают ли какие-то неожиданные пики?
Нет, не случается такого. Если у вас нет Kafka в вашем конкуре, то вам определенно нужно будет ее поднять. И это дополнительные ресурсы. У нас она была, мы ее просто задействовали. По памяти, по диску получится эффективней, чем хранить все в Elasticsearch, поэтому не сильнее, чем было бы там.
Кстати, по доставке логов, если вам не захочется использовать Kafka и хочется разобраться можно ли сделать это надежно, есть и другие варианты. Я знаю, что Altinity сделали плагин для Logstash, который пишет непосредственно в Kafka. Но мы его не пробовали, потому что нам не показалось это надежным. Там есть какие-то сценарии работы в случае, если не получилось записать и есть какие-то retry-очереди. Можно попробовать. Мы в эту сторону особо не копали, потому что сразу определились с тем, как хотим доставлять туда логи.
Здравствуйте! Насколько я понял, Elasticsearch вас полностью устраивал, но не устраивала производительность и из-за этого вы пришли к этому решению? Я сейчас тоже занимаюсь тестированием производительности. У меня 72 ядра, 380 гигабайт памяти. И я стабильно 100 000 строчек логов в секунду индексирую. Там 5 терабайт логов, я их индексирую за 12-16 часов на одном сервере. Какие у вас мощности были? Какие скорости? Не пиковые, а чтобы нагрузился по максимуму и работал несколько часов.
По индексу дневному, как Коля говорил, у нас получалось до 80 терабайт. Сколько это в секунду получалось логов, не скажу.
Как мы пришли к светлой мысли, чтобы использовать ClickHouse для логов? Изначально, когда возникла проблема с Elastic, с ELK стеком, ее начали решать по двум фронтам. Админы ее пытались решить по-своему, мы попробовали в эту сторону копнуть. Мы сделали прототип. Когда мы его сделали, наши администраторы поставили 6-ую версию Elastic, 6 Kibana, доехали новые еще железки, и получилось, что с этим стало более-менее можно жить. Поэтому вот эта вся история про ClickHouse, она у нас в резервном канале и замерла. Потому что мы более-менее научились жить с Elastic, который стал быстрее и, может быть, из-за новых железок.
Я тестировал Elastic версии 7.2. Но я еще смотрю, что у вас есть Logstash, т. е. у вас FileBeat, Logstash и Elastic. Logstash – это отдельная такая штука, которая жрет одну треть точно. Если его ставить туда, где Elastic, то там адский ад. Если его не использовать, а научиться как-то FileBeat применять… А я просто в Unix вынес Logstash на сами хосты. Он там отжирает память, но вроде они живы. И сам Elastic достаточно шустро индексирует.
Возможно, такое решение помогло в том числе и нашим админам. Потому что я знаю точно стоял Logstash на мастер ноде, которая должна была следить за всем в Elastic’овом кластере раньше. С переходом на новую версию и с новыми железками Logstash вынесли оттуда. Это сильно облегчило жизнь.
Спасибо!
Здравствуйте! Спасибо за доклад! Как я понял, вы логи раскладываете по колонкам, правильно?
Да.
В ClickHouse есть функция для работы с JSON. Так как логи у вас JSON, то можно было их сразу в одной колонке хранить и потом выбирать оттуда. Не думали об этом?
Мы знаем о таком варианте, но мы так не делали, потому что фильтрация по какой-то колонке была все равно не медленней, чем это бы сделал ClickHouse. А ClickHouse мог сделать медленно. Так и в ClickHouse можно искать по лайку, но это такой себе поиск.
Тогда бы вы ушли от строгой схемы данных. Можно было бы лить.
Возможно, некоторые колонки, которые имеют еще в себе вложенные структуры, можно было бы вынести для такой схемы. Но не пробовали. Просто такой необходимости не возникло.
Понятно. Спасибо!
Немного рекламы: На платформе https://rotoro.cloud/ вы можете найти курсы с практическими занятиями:

